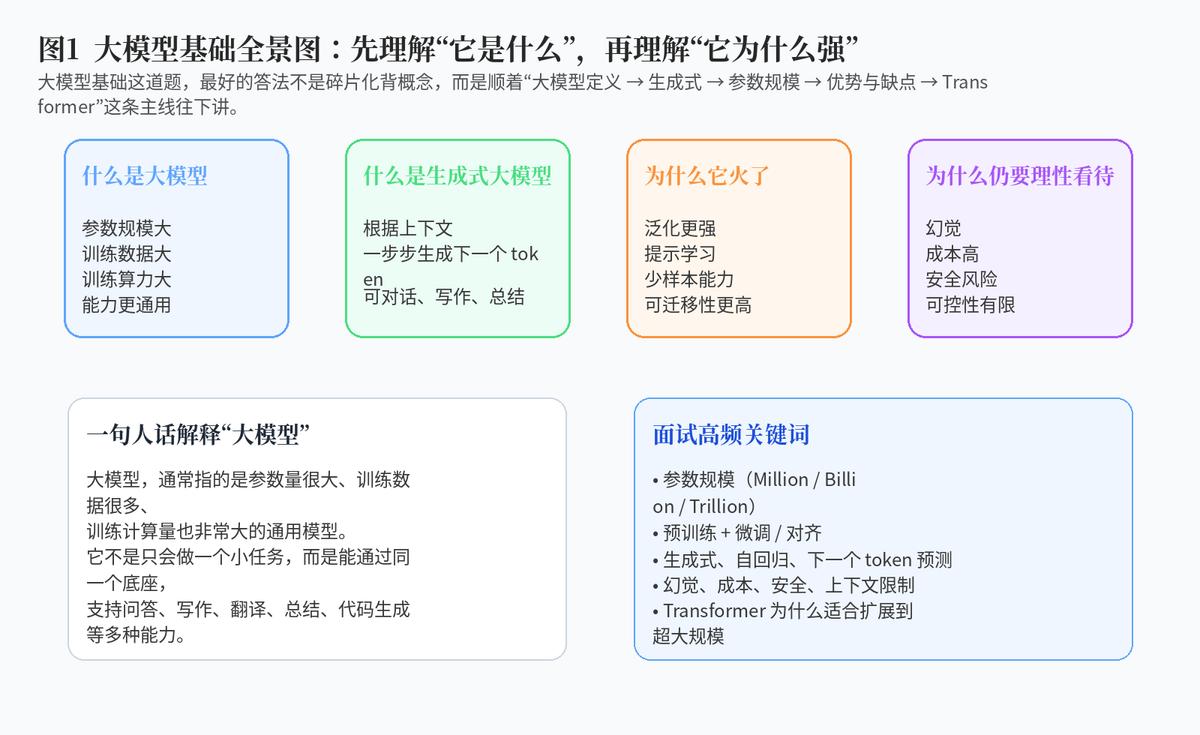
1. 什么是大模型?它与传统深度学习模型的区别在哪里?
1.1 先用一句通俗的话解释"大模型"
大模型,通常指的是参数规模很大、训练数据很多、训练算力消耗也非常大的通用模型。它不只是为了做单一任务而训练出来的,而是希望先通过大规模预训练学到通用能力,再通过提示词、微调或者对齐方法,把能力迁移到很多不同任务上。
所以大模型的关键不只是"更大",而是"大规模预训练 + 更通用的能力边界"。
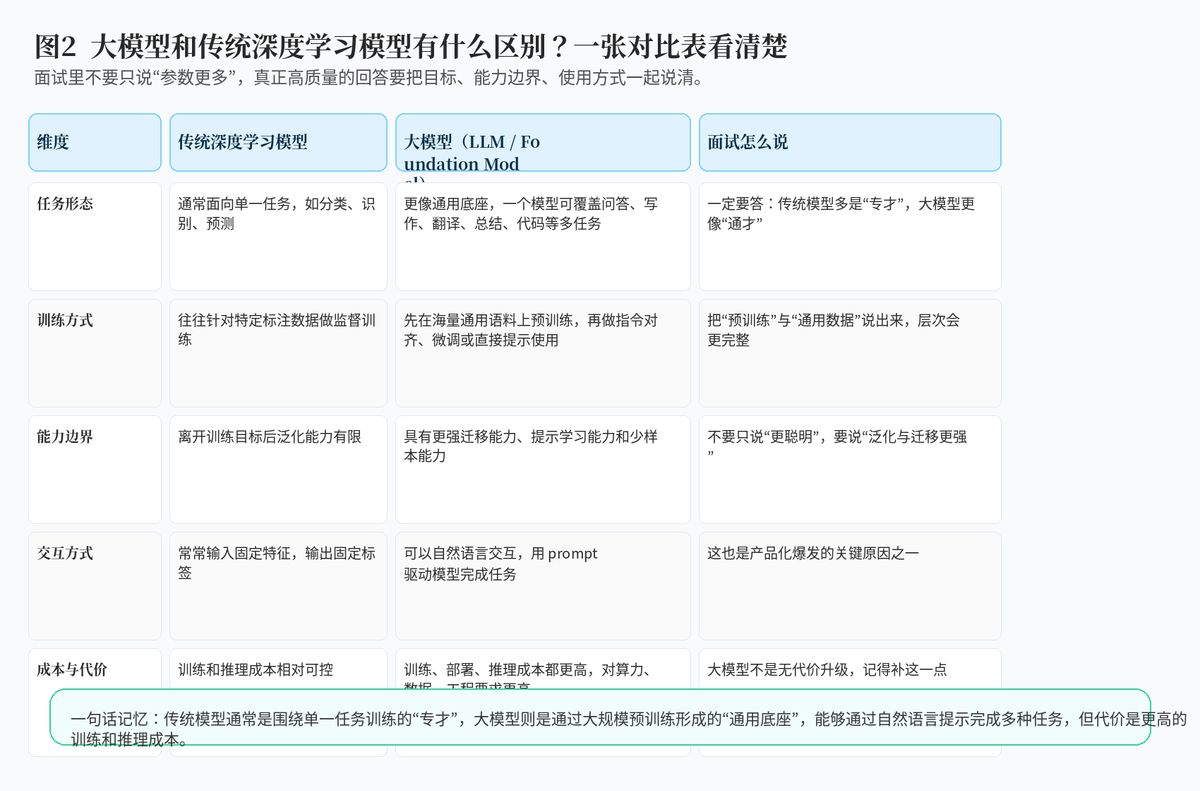
1.2 它和传统深度学习模型最大的区别是什么?
传统深度学习模型往往更像"专才",例如专门做情感分类、图像识别或者点击率预测,一个模型服务一个核心任务。而大模型更像"通才底座",一个模型可以在很多任务之间切换。
这种差别不是只靠参数量带来的,更重要的是训练范式发生了变化:传统模型更多围绕特定标注数据训练,大模型则通常先在海量通用语料上预训练,再通过指令、对齐、微调等方式适配任务。
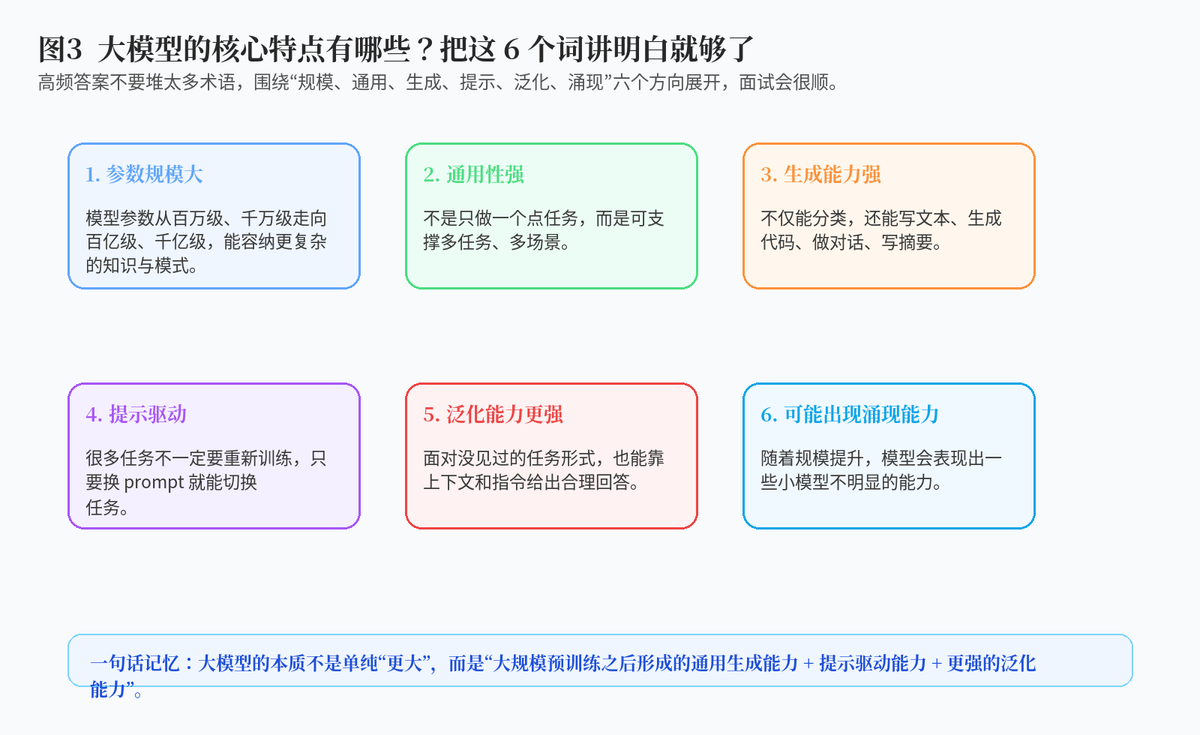
2. 大模型的核心特点有哪些?请举例说明。
2.1 参数规模大,但"更大"不是唯一结论
大模型最直观的特点当然是参数多,从千万级、亿级,逐步走向百亿级、千亿级,甚至更高。这意味着模型能够容纳更复杂的表达模式和更多的统计规律。
但只说"参数大"还不够。面试里更好的答法是进一步说:参数规模大带来了更强的表达能力,但最终效果还与训练数据质量、训练 token 数量、对齐方法和工程系统密切相关。
2.2 通用性、生成性、提示驱动能力更强
大模型的第二个特点,是能力更加通用。它既能做问答,也能做写作、翻译、摘要、代码生成、信息抽取等。第三个特点,是生成能力更强,很多任务已经不再只是"分类",而是"直接把答案写出来"。第四个特点,是提示驱动能力,也就是很多任务不必重新训练,只靠 prompt 就能切换工作模式。
2.3 泛化更强,有时会表现出涌现能力
随着模型规模、数据规模和训练计算规模提升,模型往往会表现出更强的少样本学习、任务迁移和上下文学习能力。有些能力在小模型上并不明显,但在大规模模型上会更突出,这也是大家常说的"涌现能力"。
3. 什么是生成式大模型?
3.1 "生成式"三个字怎么理解?
所谓生成式大模型,核心不是"判断它属于哪一类",而是"把答案直接生成出来"。比如当你问一个问题时,模型不是从几个固定标签里选一个,而是会一段一段地写出回答;当你让它写摘要时,它也不是提取一个编号,而是直接生成摘要文本。
这就是为什么大模型看起来更像在"交流"。因为它输出的不只是一个标签,而是一连串 token 组成的内容。
3.2 自回归生成是最常见的底层逻辑
生成式大模型中非常常见的一类,是自回归语言模型。它的生成过程很像"续写":先根据已有上下文预测下一个 token,再把这个 token 拼回上下文,继续预测下一个 token,如此循环,直到生成结束。
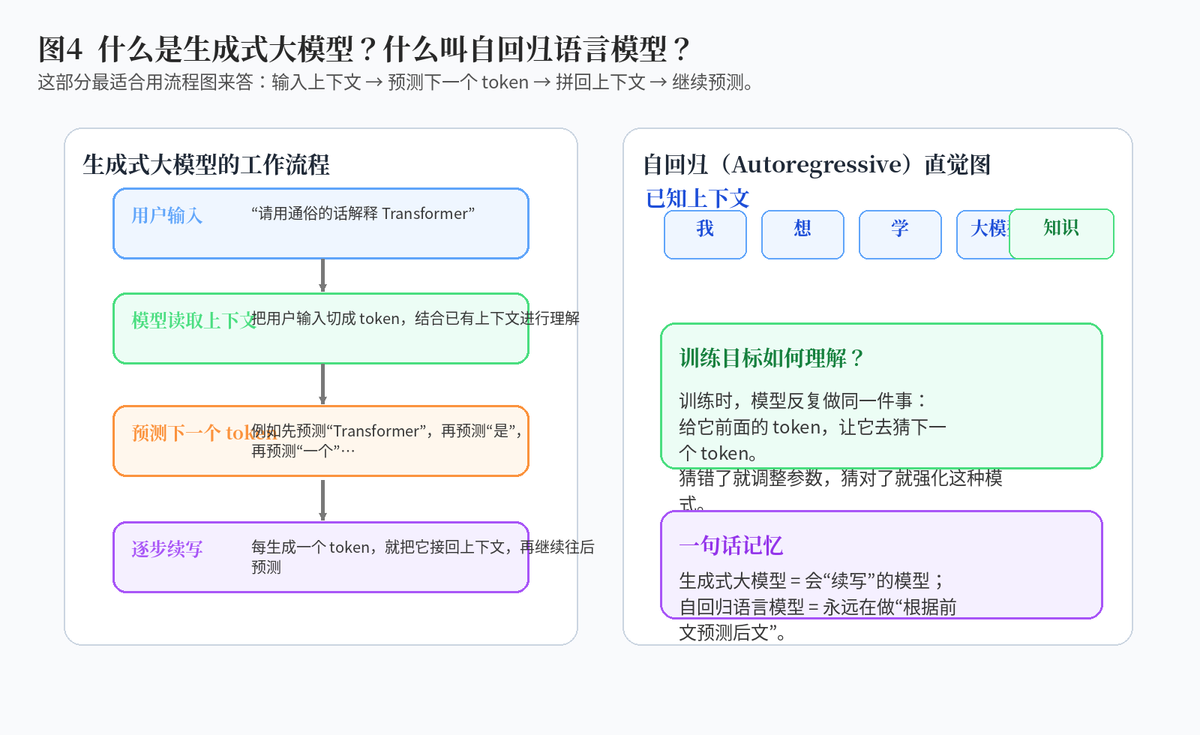
4. 自回归语言模型的训练目标是什么?
4.1 用最容易理解的话来说
自回归语言模型的训练目标,就是:给模型前面的内容,让它去预测下一个 token。
例如,给模型"今天 天气 很",它要去猜后面最可能是"好";给模型"人工 智能 正在",它要去猜后面最可能是"发展"或其他合适内容。训练时,这个动作会在海量文本上不断重复。
4.2 为什么这个目标很强?
因为看似只是"猜下一个 token",但如果想猜得准,模型就必须尽量学会词义、语法、上下文关系、常识、风格、领域表达,甚至任务格式。也就是说,这个训练目标虽然简单,却能逼着模型学习非常丰富的语言规律。
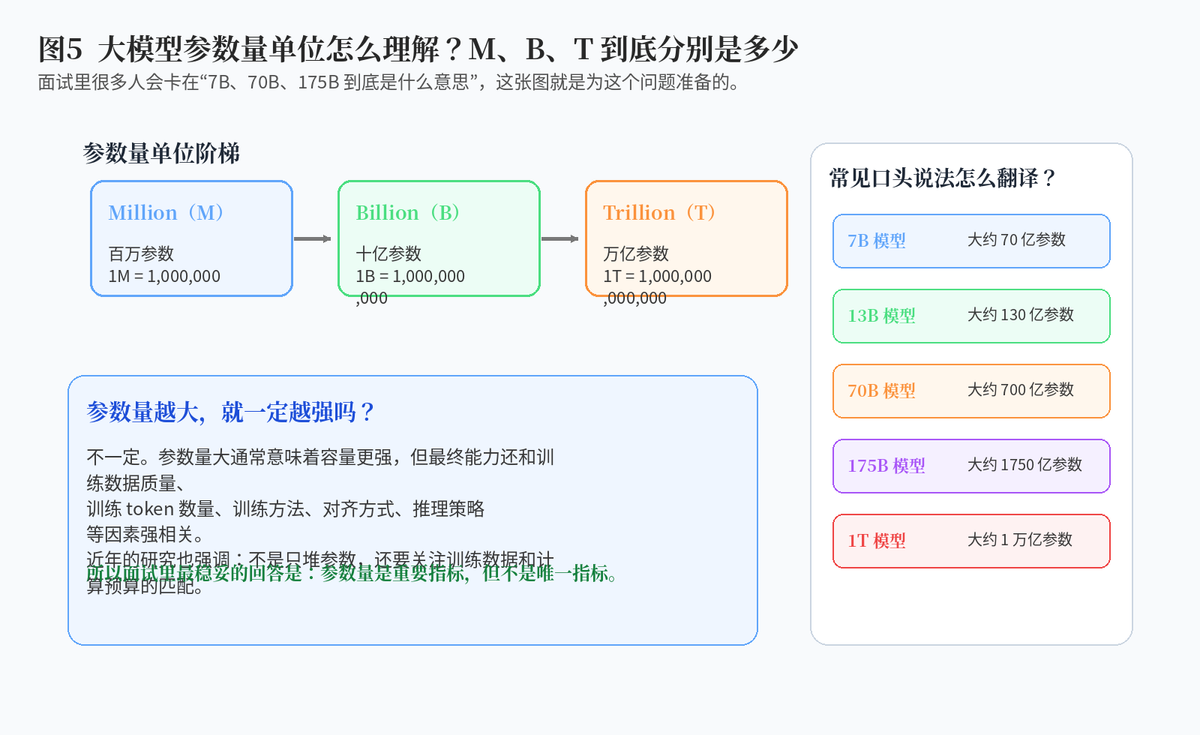
5. 大模型参数量单位
5.1 M、B、T 分别是什么意思?
在大模型语境下,常见的参数量单位有 M、B、T。M 表示 Million,也就是百万;B 表示 Billion,也就是十亿;T 表示 Trillion,也就是万亿。
例如,7B 模型表示大约 70 亿参数,70B 模型表示大约 700 亿参数,175B 模型表示大约 1750 亿参数。
5.2 参数量是不是越大越好?
参数量大通常意味着模型容量更大,但并不是唯一决定因素。现在大家已经越来越强调:模型大小、训练数据、训练 token 数量和计算预算之间要平衡。也就是说,不能只盯着参数量看强弱。
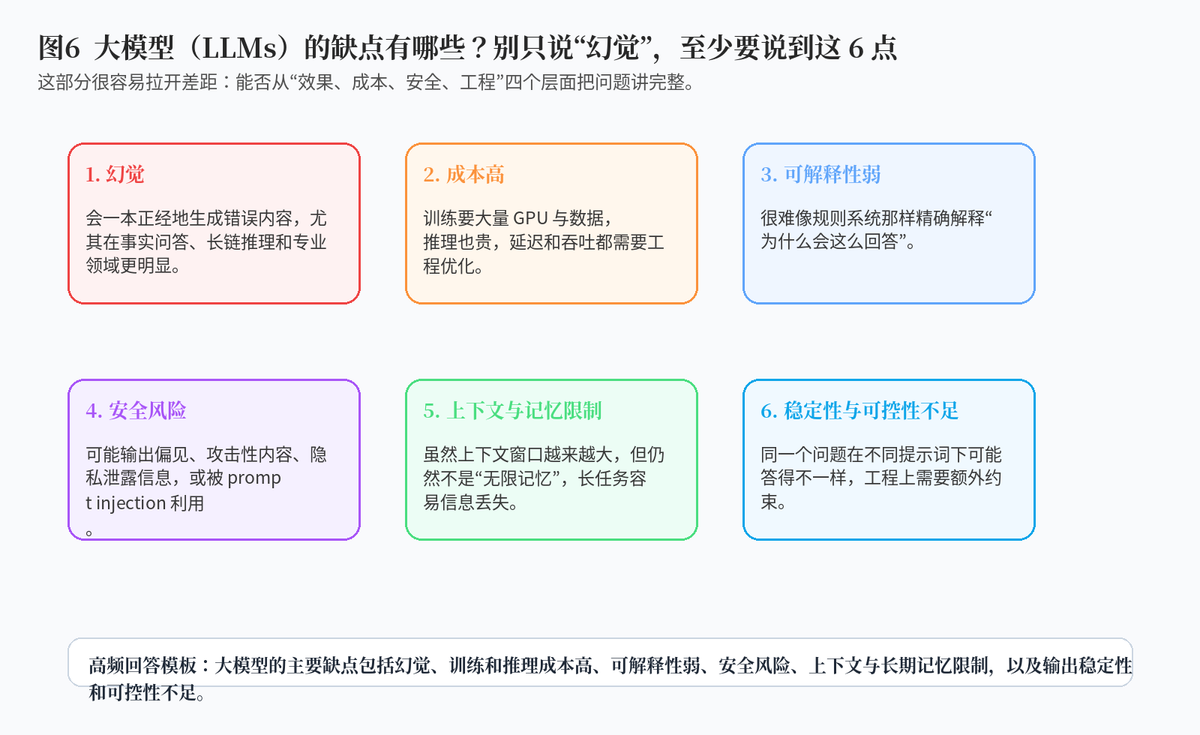
6. 大模型(LLMs)的缺点?
6.1 最常被提到的是幻觉
大模型最大的典型问题之一,是幻觉。也就是模型可能用非常自信、非常流畅的方式说出错误内容。尤其在事实性问答、专业知识领域、长链条推理场景里,这个问题更明显。
6.2 训练和推理成本都很高
大模型很强,但也很贵。训练阶段需要大量 GPU、海量数据和复杂的分布式系统;部署阶段,推理延迟、吞吐量、显存占用、服务稳定性也都需要工程优化。
6.3 安全、稳定性、可控性也都是现实问题
除了幻觉和成本,大模型还面临安全风险、偏见、隐私泄露、上下文限制、输出不稳定、可解释性不足等问题。面试里如果能从"效果、成本、安全、工程"四个层面展开,会显得明显更成熟。
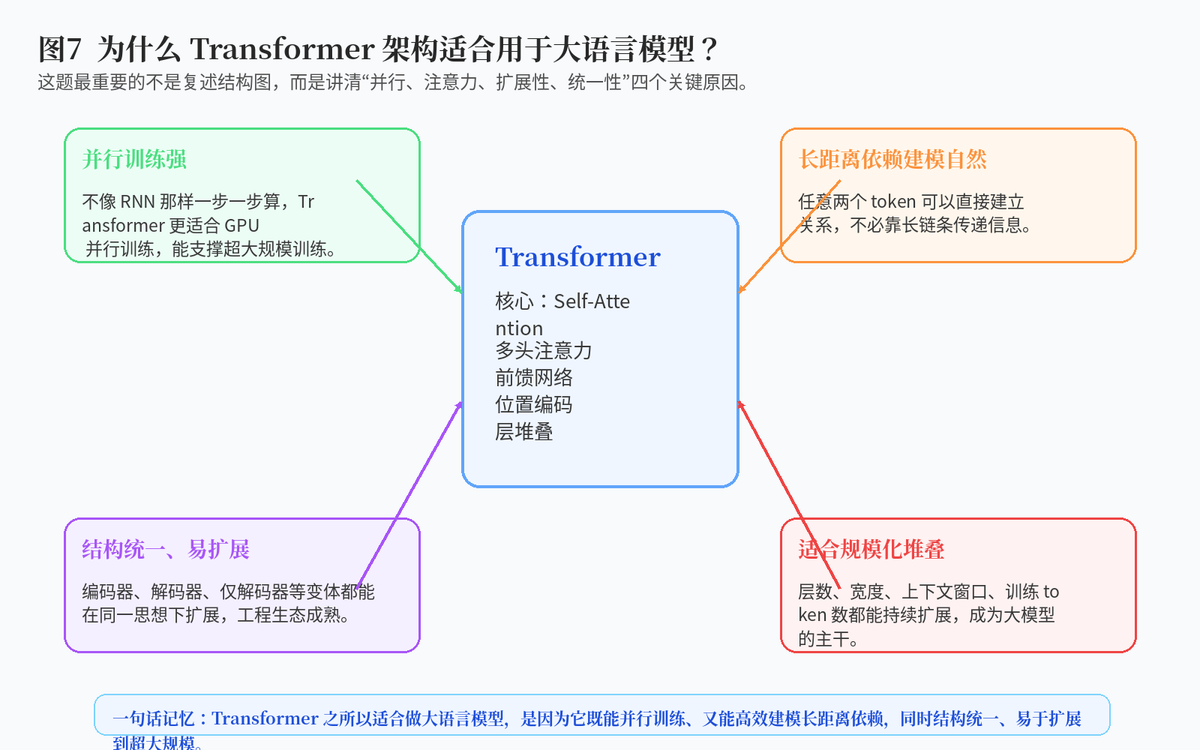
7. 为什么 Transformer 架构适合用于大语言模型?
7.1 并行训练能力强
相比 RNN 那种一步一步按时间展开的结构,Transformer 的一个巨大优势是并行计算能力更强。因为它不依赖前一步状态的串行传递,所以更容易利用 GPU 和分布式系统做大规模训练。
7.2 更擅长建模长距离依赖
Transformer 通过 Self-Attention,让任意两个 token 之间可以直接建立关系。这比传统循环结构更适合处理长文本和复杂上下文,也更有利于语言建模。
7.3 结构统一,易于扩展
Transformer 不只是效果好,它还非常"工程友好":结构统一、可堆叠、可扩展,能够自然发展出 Encoder-only、Decoder-only、Encoder-Decoder 等多种变体,这也是它成为大模型主干架构的重要原因。
8. 面试高频追问,建议这样回答
8.1 什么是大模型?它与传统深度学习模型的区别在哪里?
答:大模型通常指参数规模大、训练数据大、训练算力大的通用模型。它和传统深度学习模型的区别,不只是更大,更在于它通常先经过大规模预训练,形成通用能力,再通过提示词、微调等方式适配多任务,因此更像通用底座,而不是单任务模型。
8.2 大模型的核心特点有哪些?
答:核心特点包括参数规模大、通用性强、生成能力强、提示驱动、泛化能力更强,以及在更大规模下可能出现的涌现能力。
8.3 什么是生成式大模型?
答:生成式大模型是指能够根据输入上下文直接生成内容的模型,不只是输出固定标签,而是一步步生成 token,形成完整回答。
8.4 自回归语言模型的训练目标是什么?
答:训练目标是根据前面的上下文预测下一个 token。生成时也是不断重复这个过程,所以它本质上就是一种"续写模型"。
8.5 大模型参数量单位
答:M 表示百万,B 表示十亿,T 表示万亿。例如 7B 表示大约 70 亿参数。参数量是重要指标,但不是唯一指标。
8.6 大模型(LLMs)的缺点?
答:主要缺点包括幻觉、训练和推理成本高、安全风险、可解释性不足、上下文与记忆限制,以及输出稳定性和可控性不足。
8.7 为什么 Transformer 架构适合用于大语言模型?
答:因为 Transformer 并行训练能力强,能高效建模长距离依赖,结构统一且易于扩展,所以非常适合做超大规模语言模型。

9. 总结:真正高质量的回答,不是背名词,而是讲清逻辑链
如果把这组题浓缩成一句话,那就是:大模型是一类通过大规模预训练获得通用能力的模型,它比传统模型更通用、更会生成、更擅长通过提示词完成任务;很多生成式大模型采用自回归语言建模方式训练;它的强大建立在大规模参数、数据和算力之上,但也伴随着幻觉、成本和安全等问题,而 Transformer 则是支撑其规模化训练的关键架构。
面试里最能体现理解深度的,不是你能背多少缩写,而是你能否把"定义 → 特点 → 训练目标 → 参数规模 → 缺点 → 架构原因"这条线讲顺。只要这条逻辑线顺了,回答就会显得很专业。
附:30 秒面试快答模板
"大模型通常指参数规模大、训练数据大、训练算力大的通用模型。它和传统深度学习模型的区别,不只是更大,而是具有更强的通用性、生成能力和提示驱动能力。生成式大模型通常采用自回归语言模型的训练目标,也就是根据前文预测下一个 token。参数单位里,M 是百万,B 是十亿,T 是万亿。大模型的缺点包括幻觉、成本高、安全风险和可控性不足。Transformer 之所以适合做大模型,是因为它并行训练能力强、能建模长距离依赖,而且结构统一、易于扩展。"