一、前言
在大数据时代,数据采集是数据分析的第一步。对于初学者来说,爬虫技术往往从静态网页起步,但现代Web应用大量采用前后端分离架构,数据通过Ajax接口 动态加载。这种场景下,传统的BeautifulSoup解析HTML往往力不从心,必须转向API接口分析 与JSON数据解析。
本文将以 Scrape Center图书网站 为实战目标,深入讲解如何:
- 分析动态网站的API接口规律
- 使用
requests库构造请求并处理SSL证书问题 - 解析嵌套JSON数据结构
- 实现列表页+详情页的两级爬取策略
- 使用
pandas进行数据清洗与持久化存储
目标站点特点: 该网站是一个典型的单页应用(SPA),页面内容由JavaScript渲染,数据通过RESTful API接口返回JSON格式,非常适合练习接口型爬虫技术。
二、网站分析与接口探测
2.1 网站首页概览
首先打开目标网站 https://spa5.scrape.center/,可以看到一个精美的图书展示页面:
观察发现: 页面加载后,图书信息并非直接写在HTML源码中,而是通过异步请求获取。这意味着我们需要打开浏览器开发者工具(F12),切换到Network → XHR 面板,分析背后的数据接口。
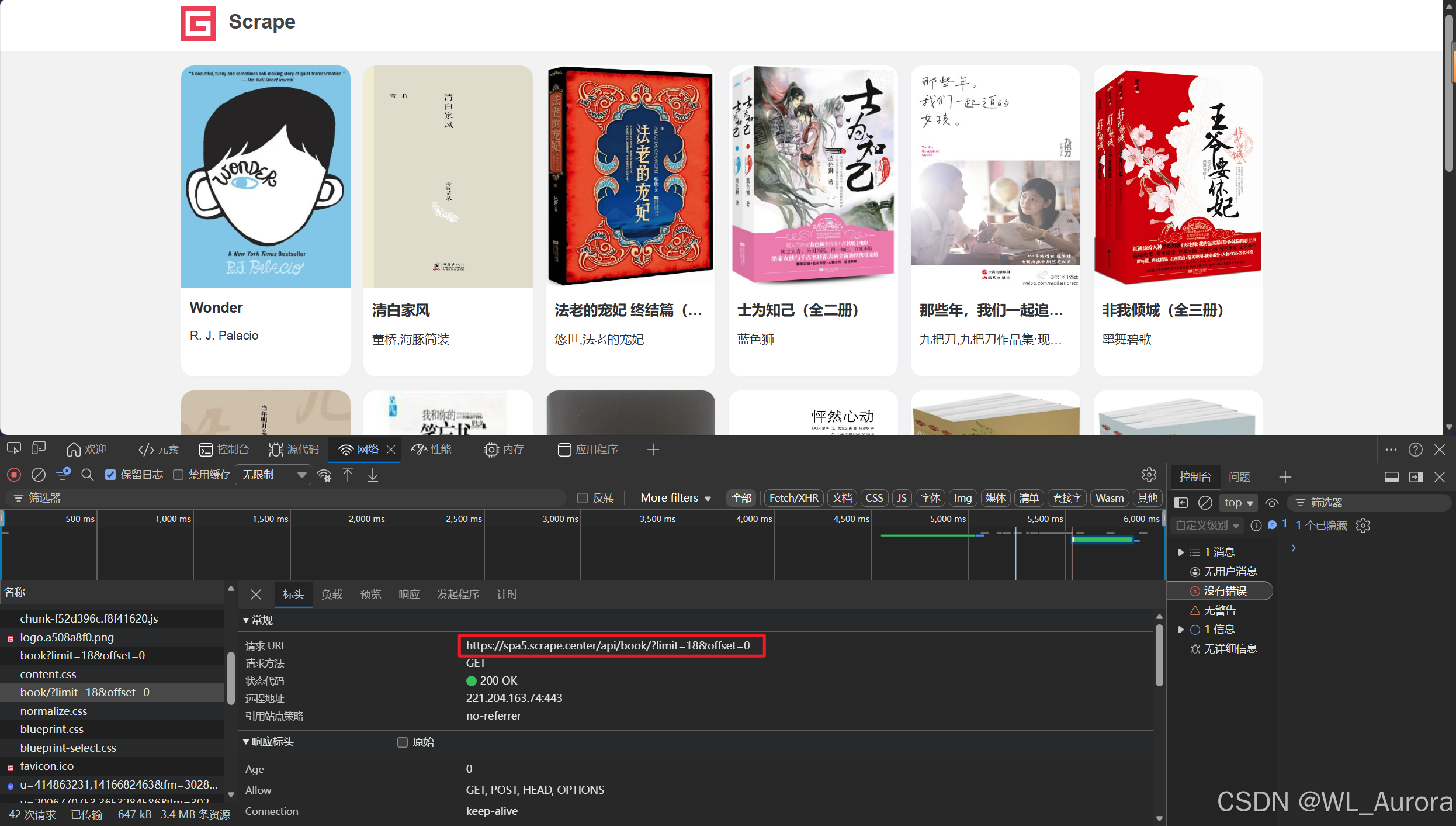
2.2 接口规律分析
通过抓包分析,我们可以发现两个核心API:
| 接口类型 | URL格式 | 说明 |
|---|---|---|
| 列表接口 | https://spa5.scrape.center/api/book/?limit={数量}&offset={偏移量} |
返回图书列表,含基础信息 |
| 详情接口 | https://spa5.scrape.center/api/book/{id}/ |
返回单本图书的详细信息 |
分页参数逻辑:
limit:每页返回的图书数量(实测为18条/页)offset:数据偏移量,第1页offset=0,第2页offset=18,以此类推
这种偏移量分页(Offset-based Pagination)是RESTful API中最常见的分页方式之一,相比页码分页更加灵活,但也需要注意边界条件判断。
2.3 返回数据结构剖析
列表接口返回的JSON结构如下(已简化):
json
{
"count": 1000,
"results": [
{
"id": "1",
"name": "解忧杂货店",
"authors": ["东野圭吾"],
"score": "8.5",
"price": 39.5,
"cover": "https://.../cover.jpg"
}
]
}详情接口返回更丰富的字段:
json
{
"id": "1",
"name": "解忧杂货店",
"authors": ["东野圭吾"],
"tags": ["小说", "日本文学", "治愈"],
"url": "https://spa5.scrape.center/detail/1",
"introduction": "...",
"comments": [...]
}关键洞察: id字段是连接列表页与详情页的枢纽 。列表页获取id,再拼接详情页URL获取完整数据------这是典型的两级爬取架构。
三、代码实现与深度解析
3.1 完整源码
python
import json
import pandas as pd
import requests
import urllib3
# ========================================
# 第一部分:环境配置与初始化
# ========================================
# urllib3.disable_warnings() 的作用是禁用由 urllib3 引发的 SSL 证书验证警告。
# 目标站点使用了自签名证书或证书链不完整,直接请求会抛出 InsecureRequestWarning。
# 在生产环境中,建议配置正确的证书路径而非直接禁用,此处仅为学习目的。
urllib3.disable_warnings()
# 初始化数据容器:采用"列式存储"策略,每个字段维护一个列表
# 这种设计便于最后直接构建 DataFrame,比逐行追加字典效率更高
book_ids = [] # 图书ID
names = [] # 书名
authors_list = [] # 作者(可能有多位,需处理为字符串)
urls = [] # 详情页链接
themes = [] # 主题标签
# 构造请求头:模拟真实浏览器行为,绕过基础的UA检测反爬机制
# 现代反爬系统会检查User-Agent、Accept-Language等字段的一致性
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/133.0.0.0 Safari/537.36 Edg/133.0.0.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Referer': 'https://spa5.scrape.center/'
}
# ========================================
# 第二部分:分页爬取逻辑
# ========================================
RECORDS_PER_PAGE = 18 # 每页记录数,与接口limit参数保持一致
MAX_PAGES = 3 # 控制爬取页数,避免对目标服务器造成过大压力
page = 0 # 页码计数器
while page < MAX_PAGES:
# 计算偏移量:offset = 页码 × 每页数量
# 这种分页方式的优势在于可以灵活调整起始位置,支持"断点续爬"
offset = page * RECORDS_PER_PAGE
# 构造列表页API地址:使用f-string进行参数拼接,清晰直观
list_url = f'https://spa5.scrape.center/api/book/?limit={RECORDS_PER_PAGE}&offset={offset}'
print(f"\n{'='*50}")
print(f"正在爬取第 {page + 1} 页,偏移量 offset={offset}")
print(f"请求URL: {list_url}")
print(f"{'='*50}")
# 发送GET请求:
# verify=False 跳过SSL证书验证(学习用途)
# timeout参数建议添加,防止网络波动导致程序卡死
try:
response = requests.get(
list_url,
headers=headers,
verify=False,
timeout=10
)
response.raise_for_status() # 检查HTTP状态码,4xx/5xx会抛出异常
except requests.RequestException as e:
print(f"请求失败: {e}")
break
# 解析JSON响应:requests内置的.json()方法比json.loads(response.text)更简洁
# 但底层原理相同:将JSON字符串反序列化为Python字典
data = response.json()
# 边界条件判断:如果results为空列表,说明已到达最后一页,优雅退出循环
if not data.get('results'):
print("未获取到数据,可能已到达最后一页,爬取结束。")
break
# ========================================
# 第三部分:列表页数据提取 + 详情页递归爬取
# ========================================
# 遍历当前页的每一本图书
for book_item in data['results']:
# 提取列表页已有字段
book_id = book_item['id']
book_name = book_item['name']
# 作者字段处理技巧:
# 接口返回的是列表类型,如 ["东野圭吾"] 或 ["刘慈欣", "韩松"]
# 需要转换为字符串,同时清洗换行符、单引号等噪音字符
book_authors = str(book_item['authors'])\
.replace('[', '')\
.replace(']', '')\
.replace("'", "")\
.replace('\\n', '')\
.strip()
print(f"\n[列表页] ID: {book_id} | 书名: {book_name} | 作者: {book_authors}")
# 将列表页数据暂存到容器
book_ids.append(book_id)
names.append(book_name)
authors_list.append(book_authors)
# ========================================
# 详情页爬取:基于ID拼接URL,实现"由浅入深"的数据获取
# ========================================
detail_url = f'https://spa5.scrape.center/api/book/{book_id}/'
try:
detail_response = requests.get(
detail_url,
headers=headers,
verify=False,
timeout=10
)
detail_response.raise_for_status()
except requests.RequestException as e:
print(f"详情页请求失败 ID={book_id}: {e}")
# 失败时填充空值,保证数据结构完整性,避免后续DataFrame构建时报错
urls.append('')
themes.append('')
continue
# 解析详情页JSON
detail_data = detail_response.json()
# 提取详情页特有字段
book_url = detail_data.get('url', '') # 使用.get()提供默认值,防止KeyError
# 主题标签同样为列表类型,需做字符串转换与清洗
book_theme = str(detail_data.get('tags', []))\
.replace('[', '')\
.replace(']', '')\
.replace("'", "")\
.strip()
print(f"[详情页] URL: {book_url} | 主题: {book_theme}")
urls.append(book_url)
themes.append(book_theme)
# 页码递增,准备下一页
page += 1
# 礼貌爬取:在页与页之间添加短暂延迟,降低服务器负载,避免触发频率限制
# 实际生产环境中建议使用 random.uniform(1, 3) 随机延时,模拟人类行为
# import time; time.sleep(1)
# ========================================
# 第四部分:数据整合与持久化
# ========================================
print(f"\n{'='*50}")
print(f"爬取完成!共获取 {len(names)} 条图书记录")
print(f"{'='*50}")
# 使用字典构造"列式数据",键为列名,值为列表(DataFrame的标准输入格式)
book_dict = {
"链接": urls,
"书名": names,
"作者": authors_list,
"主题": themes,
}
# 构建DataFrame:pandas会自动对齐各列长度,进行向量化操作
work = pd.DataFrame(book_dict)
# 数据持久化:保存为制表符分隔的txt文件
# sep='\t' 使用制表符分隔,Excel可直接打开且不会混淆内容中的逗号
# index=False 不保存行索引,保持数据整洁
# encoding='utf-8' 确保中文不乱码
output_file = 'books_list.txt'
work.to_csv(output_file, sep='\t', index=False, encoding='utf-8')
print(f"\n数据已保存至: {output_file}")
print("预览前5条数据:")
print(work.head())3.2 核心设计思想解析
(1)两级爬取架构
本案例采用了**"列表页→详情页"**的两级爬取策略,这是工业爬虫中最常见的模式之一:
列表页API ── 获取ID列表 ── 循环拼接详情API ── 获取完整数据优势:
- 减少单次请求的数据传输量(列表页轻量,详情页丰富)
- 降低服务器压力,避免一次性返回过多数据导致超时
- 便于实现断点续传:如果中断,只需记录当前处理到的ID
(2)数据清洗策略
接口返回的authors和tags字段均为Python列表类型,直接存储会导致数据格式混乱。我的处理策略是:
python
# 原始数据:['东野圭吾'] 或 ['刘慈欣', '韩松']
# 转换后:"东野圭吾" 或 "刘慈欣, 韩松"这里使用了防御性编程 :str()转换 + replace()清洗 + strip()去空白,确保即使接口返回格式微调,代码也能健壮运行。
(3)异常处理机制
代码中在每个网络请求点都设置了try-except块:
- 列表页失败:直接退出循环,避免无效重试
- 详情页失败:填充空字符串,保证DataFrame列长度一致,不中断整体流程
这种**"优雅降级"**思想在实际生产中至关重要------爬虫面对的是不可靠的网络环境,必须假设每一步都可能失败。
四、运行效果展示
4.1 控制台输出
程序运行时的控制台输出如下,可以清晰看到两级爬取的流程:
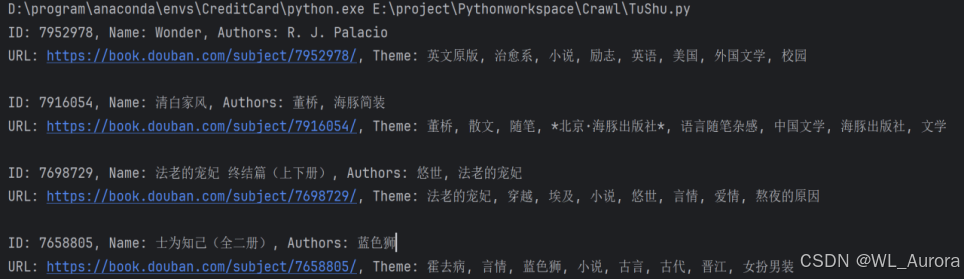
输出特征:
- 每页请求前有清晰的分隔线与页码提示
- 列表页与详情页数据分行展示,便于调试时定位问题
- 实时打印进度,长任务执行时给予用户反馈
4.2 最终数据文件
爬取完成后,生成的books_list.txt文件用Excel打开后效果如下:
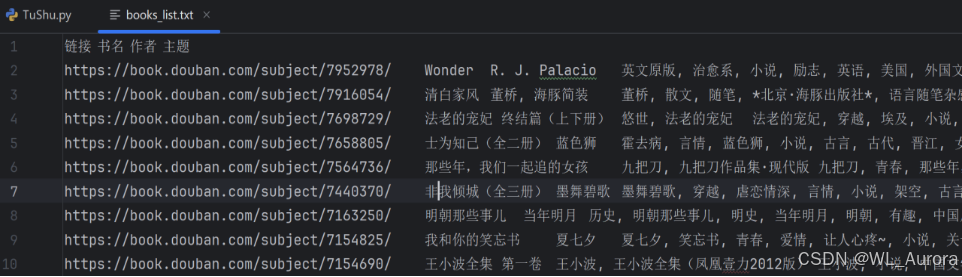
文件特点:
- 制表符分隔,Excel自动识别为表格
- 中文显示正常(UTF-8编码)
- 无行索引干扰,数据纯净可直接用于后续分析
五、进阶思考与优化方向
5.1 性能优化:异步并发
当前代码采用同步串行 请求,详情页逐个获取效率较低。当数据量达到数千条时,建议使用aiohttp实现异步并发:
python
import aiohttp
import asyncio
async def fetch_detail(session, book_id):
url = f'https://spa5.scrape.center/api/book/{book_id}/'
async with session.get(url) as response:
return await response.json()据测试,异步模式可将爬取效率提升5-10倍,特别适合此类I/O密集型任务。
5.2 反爬对抗策略
虽然本站点为学习用途未设置强反爬,但实际场景中需要考虑:
- 请求频率控制 :使用
time.sleep(random.uniform(1, 3))模拟人类操作间隔 - IP代理池:高频率请求时轮换代理IP
- 请求头轮换:定期更换User-Agent,甚至模拟完整的浏览器指纹
5.3 数据存储升级
当数据量增大时,txt/CSV文件的管理变得困难,建议升级存储方案:
| 场景 | 推荐方案 | 优势 |
|---|---|---|
| 结构化数据 < 10万条 | SQLite | 轻量级,无需单独部署 |
| 大规模数据 + 分析 | MySQL/PostgreSQL | 支持复杂查询与索引 |
| 非结构化/文档型 | MongoDB | 灵活存储JSON原生数据 |
六、总结
通过本次实战,我们完整掌握了接口型爬虫的核心技术栈:
- 接口分析能力:学会使用浏览器开发者工具抓取Ajax请求,分析URL规律与参数含义
- JSON解析技巧:理解Python字典/列表的嵌套结构,熟练进行数据提取与清洗
- 两级爬取架构:掌握"列表页获取ID → 详情页获取完整数据"的经典模式
- 工程化思维:异常处理、数据校验、礼貌爬取等生产级代码习惯
如果本文对你有帮助,欢迎点赞、收藏、关注!有任何问题欢迎在评论区留言讨论。