本节聚焦「如何训练」:先对齐常用术语,再依次说明激活函数、训练循环、反向传播与自动求导。
机器学习中的关键术语及其含义
神经元及神经网络
一种模仿生物神经网络的结构和功能的数学模型或计算模型,按照一定的规则将多个神经元连接起来的网络。
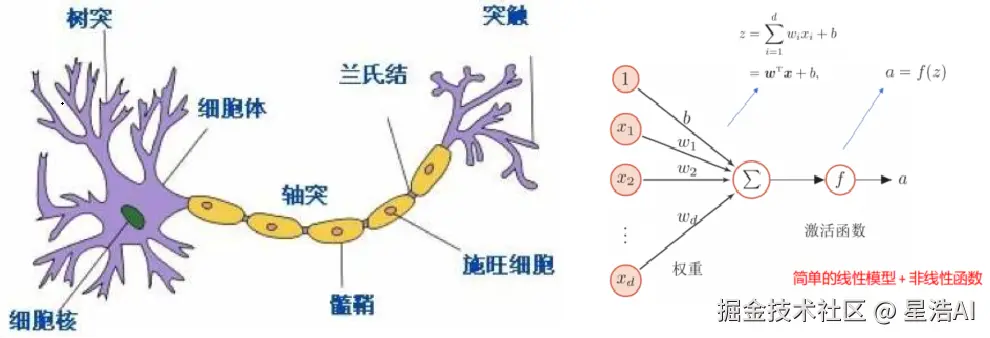
神经网络是一种运算模型,由大量的节点(或神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激活函数。
多层感知机
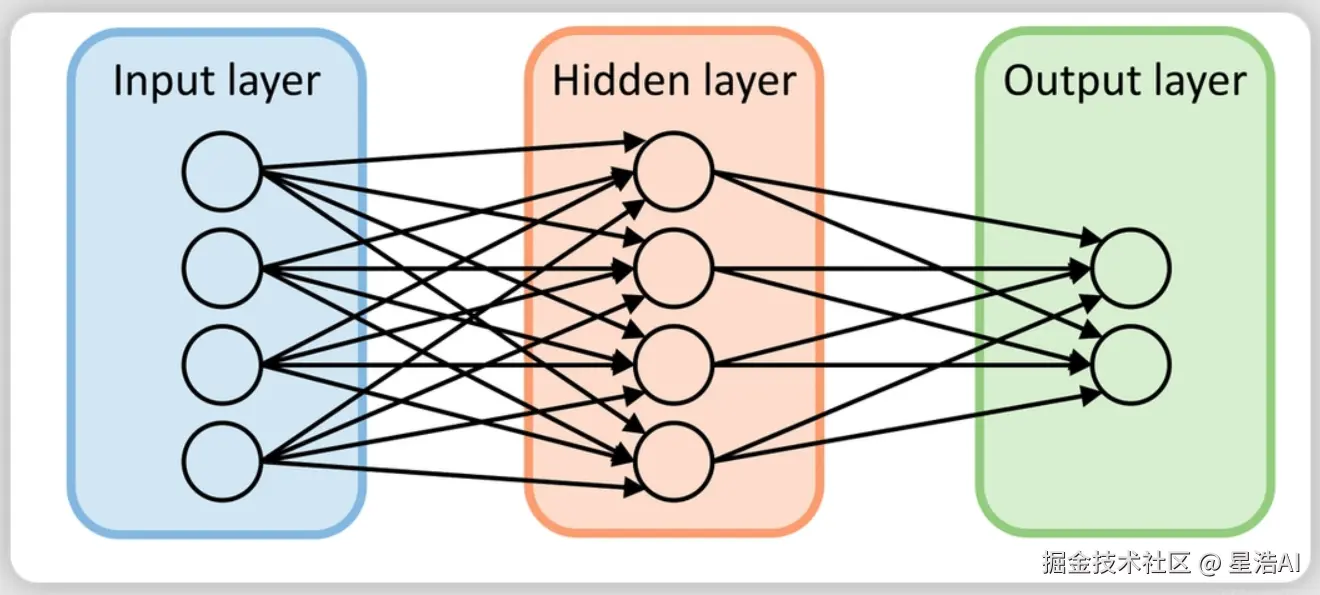
多个神经元可以组合一起,形成多层感知机。
多层感知器(Multi-Layer Perceptron,MLP):
通过叠加多层全连接层来提升网络的表达能力。相比单层网络,多层感知器有很多中间层的输出并不暴露给最终输出,这些层被称为隐含器(Hidden Layers)。
关键术语
- 样本\*:
样本是数据集中的单个实例或数据点,通常由一组特征(自变量)和一个标签(因变量)组成。
举例:房价预测中,一个样本可能包含房屋的面积、位置、房龄等特征,以及对应的房价标签。
- 标签\*:
标签是与样本关联的目标值或类别,用于监督学习中指导模型学习。
举例:情感分析中,每条评论文本对应一个情感类别标签(如「正面」「负面」或「中性」),模型学习根据文本预测该标签。
- 目标函数
是模型训练过程中优化的目标,通常由损失函数构成,用于衡量模型的性能。
举例:在线性回归中,目标函数是最小化均方误差(MSE)。
- 损失函数 用于量化模型预测值与真实值之间的差异,用来衡量单个样本中计算值与标签值的差异。
举例:在分类问题中,常用的损失函数是交叉熵损失。
- 特征\*
通过机器学习算法从数据中学习到的数学表示,用于模型的输入。
通俗来讲:数据经过神经网络运算之后所输出的结果,就是特征。
- 模型
通过机器学习算法从数据中学习到的数学表示,用于对新数据进行预测。
- 训练数据\*
用于训练机器学习模型的数据集,通常包含输入特征和对应的标签。训练集:验证集:测试集7:1:2
- 测试数据
用于评估模型在未知数据上表现的数据集。
- 正则化
用于防止模型过度拟合的技术和手段
- 学习率\*
学习率是一个超参数,学习率是训练过程中控制参数更新的重要因素。
过大的学习率可能导致模型无法收敛,而过小的学习率则会导致训练过程缓慢。(学习率决定学习速度)
- Epoch
即轮次,模型训练过程中对整个训练数据进行一次完整的遍历。
- 超参数 超参数是在训练之前设置的参数,用于控制学习过程和模型结构。
举例:学习率、批量大小、神经网络的层数和每层的神经元数量等都是常见的超参数。
- 数据分布
训练的过程就是找到一个函数,能够匹配数据的分布的过程。
非线性激活函数
- 激活函数 人工神经网络中的一个关键组件,负责将神经元的输入信号转换为输出信号,从而引入非线性特性。
说白了,就是给神经网络提供非线性能力的函数,把直线变成一条曲线。
激活函数对模型至关重要:引入非线性、增强表达能力、控制输出范围、促进梯度传播、模拟生物神经元的激活机制。
- 常见的激活函数
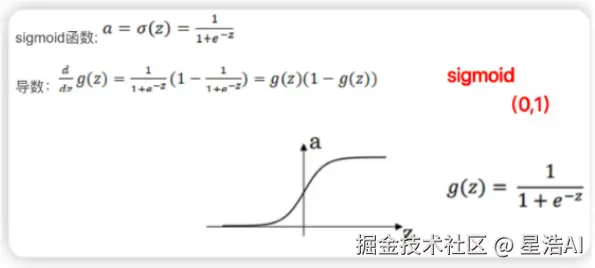
- Sigmoid函数:将输入映射到 (0,1) 之间,常用于二分类问题,容易导致梯度消失问题。
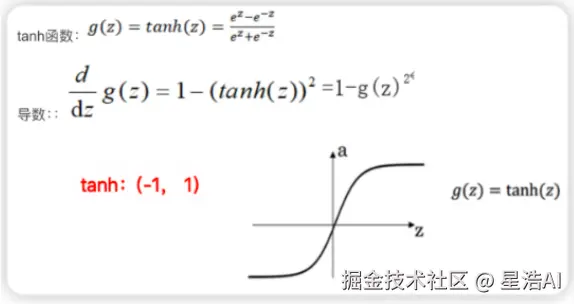
- Tanh函数:将输入映射到 (-1,1) 之间,解决了 Sigmoid 的零均值问题,但仍存在梯度消失问题。
- ReLU函数:将输入为正时输出输入值,输入为负时输出 0,计算简单且能够有效缓解梯度消失问题,但可能导致"神经元死亡"问题。
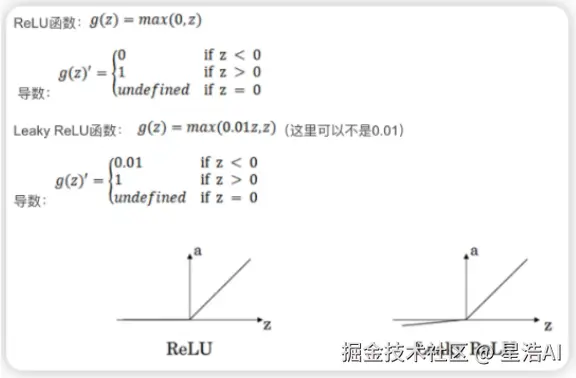
- Softmax函数:将输入映射为概率分布,常用于多分类问题的输出层。

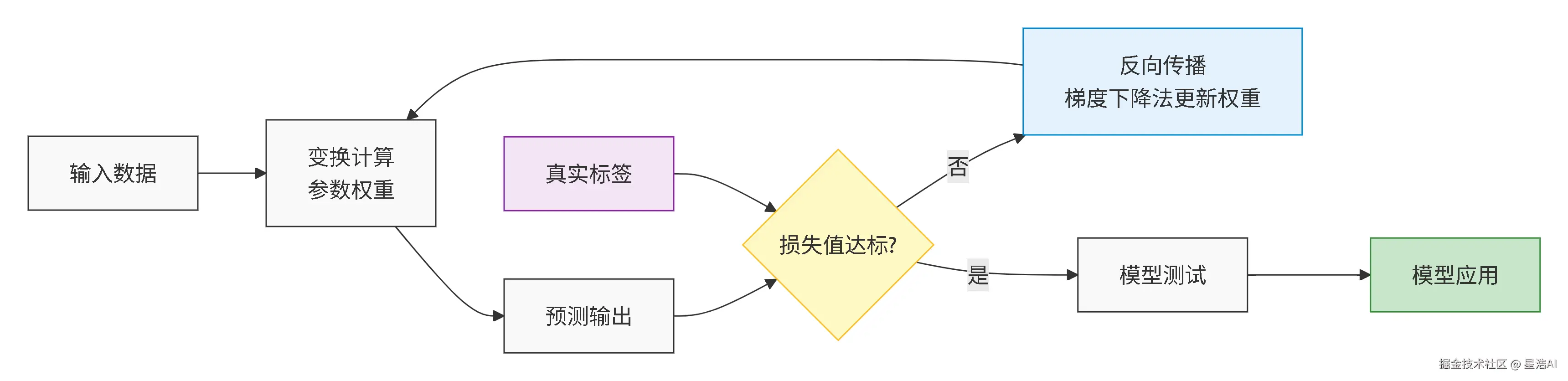
模型训练过程
-
Step 1:定义网络结构 确定网络的层数、每层神经元数量、激活函数等。
-
Step 2:初始化模型参数 随机初始化权重 ( W ) 和偏置 ( b )。
-
Step 3:循环训练(直到损失值达标)
| 子步骤 | 名称 | 说明 |
|---|---|---|
| 3.1 | 执行前向传播 | 输入数据经过网络逐层计算,得到预测输出 |
| 3.2 | 计算损失函数 | 将预测输出与真实标签对比,计算损失值 |
| 3.3 | 执行反向传播 | 根据损失值计算各层参数的梯度 |
| 3.4 | 更新权值 | 使用梯度下降法更新权重和偏置 |
- Step 4:模型测试与应用 损失值达标后,进行模型测试,最后投入应用。
反向传播机制
用一个实际例子来理解机器学习和反向传播:
猜数字的游戏。现在我心中确定了一个1到100的数,请你猜猜它是什么?
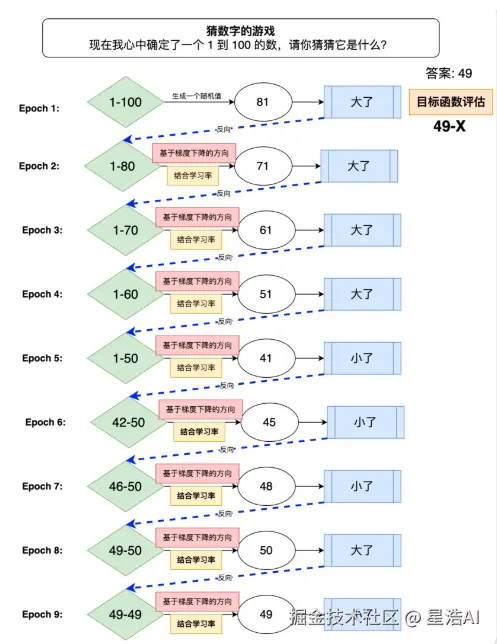
学习率的影响
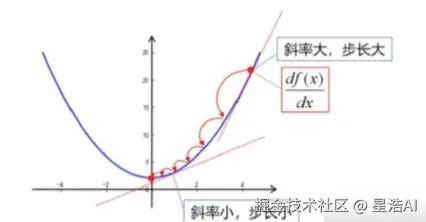
- 梯度下降法 步长太小,迭代次数多,收敛慢。 步长太大,引起震荡,可能无法收敛。
前向计算、反向传播
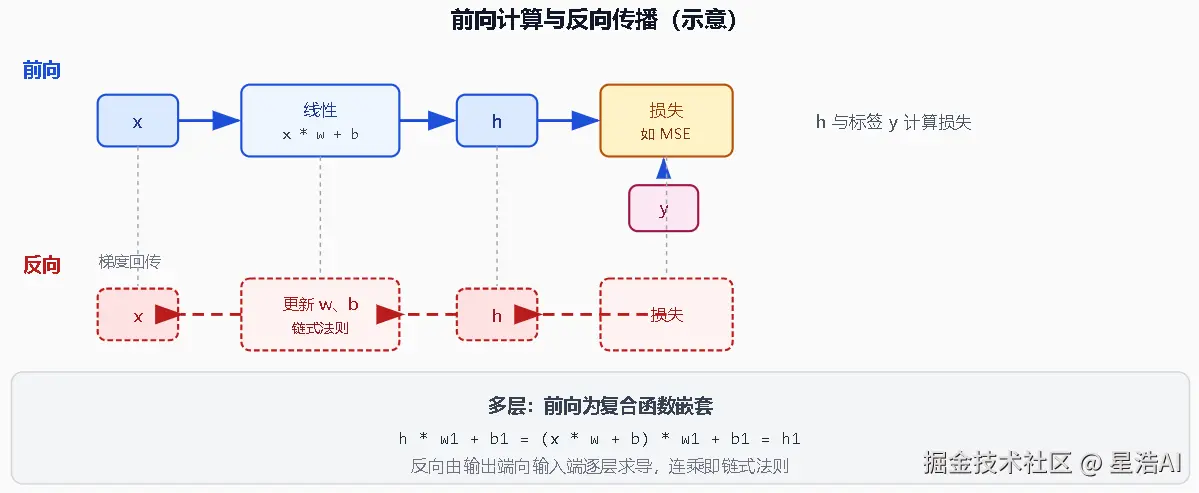
前向计算(模型推理)
将数据输入到模型,得到输出的过程。
ini
x * w + b = h反向传播(模型训练)
根据模型输出的结果,结合数据对应的标签,得到损失,再通过损失求解正确的参数(w, b)。
ini
loss = mean((h - y) ^ 2)下面是一个最小可运行的"手写前向 + 反向 + 参数更新"示例(两层网络,ReLU激活):
python
import numpy as np
batch_size, dim_in, hidden_layer, dim_out = 64, 1000, 100, 10
x = np.random.randn(batch_size, dim_in)
y = np.random.randn(batch_size, dim_out)
w1 = np.random.randn(dim_in, hidden_layer)
w2 = np.random.randn(hidden_layer, dim_out)
learning_rate = 1e-6
for t in range(500):
# 前向计算
h = x.dot(w1)
h_relu = np.maximum(h, 0)
y_pred = h_relu.dot(w2)
# 计算损失
loss = np.square(y_pred - y).sum()
print(t, loss)
# 反向传播(手推梯度)
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h < 0] = 0
grad_w1 = x.T.dot(grad_h)
# 参数更新
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2如果使用 PyTorch,可以把梯度计算交给 autograd 自动完成:
python
import torch
batch_size, dim_in, hidden_layer, dim_out = 64, 1000, 100, 10
x = torch.randn(batch_size, dim_in)
y = torch.randn(batch_size, dim_out)
w1 = torch.randn(dim_in, hidden_layer, requires_grad=True)
w2 = torch.randn(hidden_layer, dim_out, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
y_pred = x.mm(w1).clamp(min=0).mm(w2) # 前向
loss = (y_pred - y).pow(2).sum()
print(t, loss.item())
loss.backward() # 反向:自动求导
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_()
w2.grad.zero_()最终目标
模型输出的 h 和 y 非常接近,loss 很小,我们需要求解 loss 最小时对应的参数 w, b。
loss 不能为 0,只能无限逼近于 0。
梯度下降算法(SGD)
Adam 优化器可以自行动态调整学习率。
在工程实践中,常见写法是使用优化器统一管理参数更新:
python
import torch
model = torch.nn.Sequential(
torch.nn.Linear(1000, 100),
torch.nn.ReLU(),
torch.nn.Linear(100, 10),
)
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
x = torch.randn(64, 1000)
y = torch.randn(64, 10)
for t in range(500):
y_pred = model(x)
loss = loss_fn(y_pred, y)
print(t, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()多层模型的前向计算其实就是复合函数嵌套:
css
h * w1 + b1 = (x * w + b) * w1 + b1 = h1反向求导的时候就是复合函数的求导,遵循链式法则。
自动求导
自动求导不仅能处理固定结构的网络,也能处理"每次前向结构都可能变化"的动态计算图。
常见的计算机程序求导方法可以归纳为四种:数值微分、符号求导、前向模式自动求导(Forward Mode AD)、反向模式自动求导(Reverse Mode AD)。
深度学习训练中最常用的是反向模式自动求导,也就是我们常说的反向传播。
自动求导的进阶:动态图与参数共享
下面通过一个例子说明:输入层和输出层固定,但中间层会随机重复 0~3 次;同一个中间层参数会被重复使用(参数共享)。
python
import random
import torch
class DynamicNet(torch.nn.Module):
def __init__(self, n_in, n_hidden, n_out):
super().__init__()
self.input_linear = torch.nn.Linear(n_in, n_hidden)
self.middle_linear = torch.nn.Linear(n_hidden, n_hidden) # 参数共享层
self.output_linear = torch.nn.Linear(n_hidden, n_out)
def forward(self, x):
# 固定的输入变换
h_relu = self.input_linear(x).clamp(min=0)
y_pred = self.output_linear(h_relu)
# 每次前向随机决定中间层重复次数(动态图)
for _ in range(random.randint(0, 3)):
h_relu = self.middle_linear(h_relu).clamp(min=0)
y_pred = self.output_linear(h_relu)
return y_pred
batch_size, dim_in, hidden_layer, dim_out = 64, 1000, 83, 10
x = torch.randn(batch_size, dim_in)
y = torch.randn(batch_size, dim_out)
model = DynamicNet(dim_in, hidden_layer, dim_out)
criterion = torch.nn.MSELoss(reduction="sum")
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
for t in range(500):
y_pred = model(x)
loss = criterion(y_pred, y)
print(t, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()这个例子说明:在 PyTorch 中,计算图是在前向过程中动态构建的,因此可以直接使用 Python 的循环和条件语句来控制网络结构。
讨论
为什么模型的效果一直停滞不前?
- 优化器选择不合适:参数更新方向或步长控制不佳,导致收敛慢或训练不稳定。
- 损失函数选择不合适:与任务目标不匹配,模型即使在优化,也难以朝正确方向改进。
神经元越多,网络深度越大,效果越好吗?
不一定。更大的模型通常拥有更强表达能力,但效果取决于数据规模与质量、正则化策略、优化方法和计算资源。
当数据不足或训练策略不当时,盲目增大网络反而更容易过拟合、训练不稳定,甚至导致效果下降。
文中部分图片来自于网络。