数据操作
我们已经学会了数据表的创建、数据类型、约束、字符集的设置以及数据的增删改查操作;但是这些还远远不够,现在我们需要学习为数据表插入大量数据,对查询的数据进行筛选、分组、排序或限量
复制表结构和数据
在开发时,如果我们需要创建一个与已有数据表相同表结构的数据表时,可以通过以下语句
create table 表名 like 旧表名;上述代码仅从已有数据表中复制一份相同的表结构,并不会复制表中保存的数据。
如果我们想复制已有的表数据 ,我们可以用关键字insert和select,注意这种操作要求获取数据和插入数据的表结构相同。
insert into 数据表名 select [字段列表|*] from 数据表名2;解决主键冲突
在对数据表插入数据时,若表中的主键含有实际意义,在插入数据的时候必须确保对应主键是否存在以避免出现主键冲突的情况。
主键冲突的解决方法分为两种:
-
主键冲突更新
-
主键冲突替换
1. 主键冲突更新
当插入数据的过程中发生主键冲突,就用新数据更新已有字段 ,通过关键字ON DUPLICATE KEY UPDATE实现:
insert into 数据表名 values on duplicate key update 字段名=值,...;
insert into my_goods(id,name,content,keyword)
values(20,'橡皮','修正书写错误','文具')
on duplicate key update name='橡皮',content='修正书写错误',keyword='文具';更新逻辑的好处在于可以自定义更新逻辑,防止数据丢失。
2. 主键冲突替换
当插入数据的过程中发生了主键冲突,则删除这条记录并重新插入。通过关键字replace实现
replace into 数据表名 values (值列表);REPLACE和ON DUPLICATE KEY UPDATE都可以解决主键冲突问题,但replace更适合插入数据字段比较多的情况。
清空数据
MySQL中利用关键字TRUNCATE清空指定数据表的全部数据。
truncate table 数据表名;
truncate和delete的区别:
-
实现方式不同 :truncate 本质上是先执行删除(DROP)数据表操作,再根据表结构文件(.frm)重新创建数据表的方式清空数据表;而delete是逐条删除数据表中的记录。
-
执行效率不同:在面对大型数据集时,truncate的执行效率更高。
-
删除数据的范围不同:truncate只能用于清空表中所有记录,而delete可以通过where指定删除满足条件的记录。
-
对auto_increment的字段影响不同:truncate清空数据以后,再次向表中添加数据时,自动增长字段会从默认初始值开始 ;而delete语句删除记录时不影响自动增长值。
去除重复记录
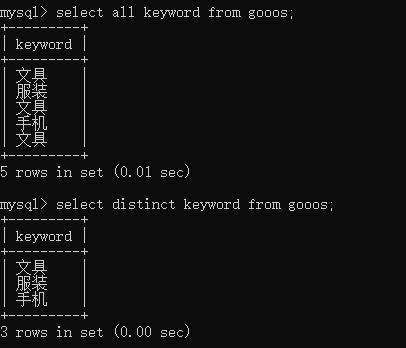
当你查询的结果中,出现多条所有字段值完全相同 的记录时,使用关键字distinct会自动只保留 1 条,剔除所有重复的行,避免你拿到的结果里有大量冗余的重复数据,便于实现数据清洗、结果唯一性校验、统计分析等工作。
排序与限量
排序
在项目开发时,为了使查询的数据结果满足用户需求,通常需要对查询出的数据进行上升或下降的排序(比如商品销量榜),MySQL提供了两种排序方式:单字段排序和多字段排序。
1. 单字段排序
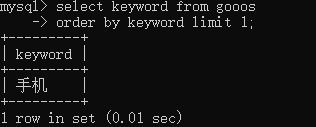
查询时仅按照一个指定字段进行升序或降序排序。可以使用关键字ORDER BY完成,ORDER BY可以对数字、日期、字符串等类型进行排序。
select *|{字段列表} from 数据表
order by 字段名 [asc|desc];ASC表示升序,DESC表示降序,ORDER BY默认值为ASC。
2.多字段排序
当在开发中需要根据多个条件对查询的数据进行排序时,可以采用多字段排序。
select *|{字段列表} from 数据表名
order by 字段名1[ASC|DESC],字段名2[ASC|DESC]...; 多字段排序首先按照字段名1进行排序,当字段名1的值相同时,再按照字段名2进行排序。
select id,name,price from goods
order by id,price desc;值得一提的是,如果某条字段的值为NULL ,则系统会把它看作是最小的值。
限量
MySQL中提供了一个关键字LIMIT可以限定记录的数量,避免一次查询出大量数据,浪费系统效率。
select 字段列表 from 数据表
[where条件] [order by字段 asc|desc]
limit 记录数; 记录数表示限定获取的最大记录数量;注意,再关键字limit后面加可选项OFFSET表示偏执量,用于设置从哪条记录开始展示,第一条记录偏执量为0,以此类推。
分组
在MySQL中,可以使用GROUP BY根据一个或多个字段进行分组,字段值相同的为一组,对于分组的数据可以使用HAVING进行条件筛选。
一般来讲,分组的目的是在对表中每一组进行相关聚合统计(配合聚合函数使用)。
1. 分组统计
select 字段 from 数据表
[where条件] group by 字段名;select获取的字段列表只能是group by分组的字段,或者是使用了聚合函数的非分组字段。
比如说通过聚合函数MAX()获取每个分类下商品最高价格
select category,MAX(price) from goods group by category;上述语句根据category进行分组,然后获取每个分组下商品的最高价格。
2. 分组排序
在MySQL中,默认为分组操作字段提供了升序排序的功能,因此在分组时可以按照指定字段进行升序或降序的排列。
select 字段 from 数据表
[where条件]
group by 字段名 ASC|DESC;分组排序的实现不需要order by,直接在后面添加ASC或者DESC就可以。
3. 统计筛选
当对查询的数据进行分组操作时,可以使用HAVING根据条件对数据进行筛选
select 字段 from 数据表
[where ...]
group by 字段
having 条件表达式;having和where的区别:
-
where操作是把数据从磁盘存储到内存中,而having是对已存放到内存的数据进行操作
-
having位于group by语句之后,where位于group by语句之前
-
having关键字后可以使用聚合函数而where不可以。
select score,comment_count from goods
group by score,,comment_count
having count(*)=2;
首先根据score进行分组,然后根据comment_count进行分组,分组后利用having筛选商品数量等于2的数据信息。
别名
在MySQL执行查询操作时,可以使用关键字AS为获取的字段设置别名。
select category as c,MAX(price) as max_p from goods
group by c having c = 3;聚合函数
在对数据进行分组统计时,经常需要结合MySQL提供的聚合函数。
|---------|-------------------------|
| 函数 | 说明 |
| COUNT() | 返回查询到的数据的数量,不统计为NULL的数据 |
| SUM() | 返回查询到的数据的总和 |
| AVG() | 返回查询到的数据的平均值 |
| MAX() | 返回查询到的数据的最大值 |
| MIN() | 返回查询到的数据的最小值 |
在COUNT()、SUM()、AVG()、MAX()、MIN()函数中可以在参数前添加distinct表示对不重复的数据进行操作,当COUNT()中参数被设置为" * "时,表示统计符合条件的所有数据。
统计所有用户的平均年龄
SELECT AVG(age) AS avg_age FROM user;统计用户的最大年龄
SELECT MAX(age) AS max_age FROM user;统计用户的最小年龄
SELECT MIN(age) AS min_age FROM user;最后注意
-
所有聚合函数(count(*)除外)都会自动忽略NULL值,如果你要把 NULL 值当成 0 计入计算,用IFNULL() 函数把 NULL 转换成 0
-
SELECT子句里的字段,要么是聚合函数,要么必须出现在group by的分组字段中