1.redis简介
1.1简介
Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
1:Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
2:Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存
储。
3:Redis支持数据的备份,即master-slave模式的数据备份。
1.2Redis 优势
redis性能极高 -- (10万~100万+ QPS),微秒级响应,mysql较慢(通常 几千~几万 QPS),毫秒级响
应(依赖索引和硬件)
丰富的数据类型 -- Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子 -- Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性
的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
丰富的特性 -- Redis还支持 publish/subscribe, 通知, key 过期等等特性。
1.3Redis与其他key-value存储有什么不同?
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。
Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数
据量不能大于硬件内存。
在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简
单,这样Redis可以做很多内部复杂性很强的事情。
同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
1.4Redis 数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted
set:有序集合)。
1.5哈希槽的基本概念
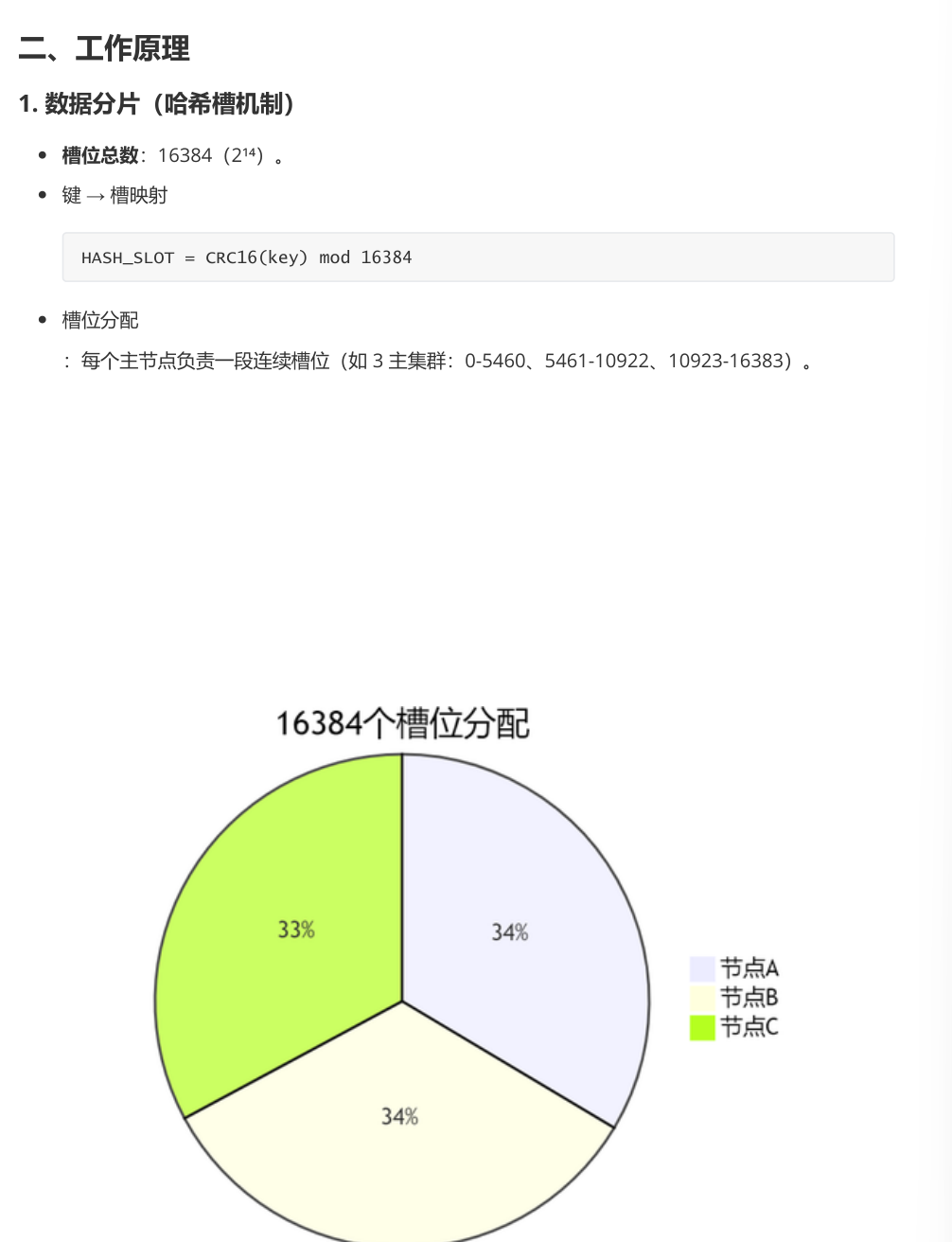
槽的数量
Redis集群将整个键空间划分为16384个哈希槽(0-16383),这是经过权衡后确定的固定数量
数据映射规则
通过HASH_SLT = CRC16(key) mod 16384公式计算键对应的槽号,确保相同key会始终映射到同一槽。
数据分布与节点管理
节点分配机制
每个集群节点负责部分槽的集合(如节点A负责0-5000,节点B负责5001-10000)
动态迁移与扩容
槽的分配支持在线调整,但相比传统哈希取余算法,迁移数据量更可控
1.6 Redis常见应用场景
Redis 凭借其高性能、丰富的数据结构和灵活的部署方式,已成为现代应用架构中的关键组件。除了大家
熟知的缓存功能,Redis 在众多业务场景中都能发挥重要作用。本文将系统梳理 Redis 的常见使用场景,
深入分析每种场景的技术实现和最佳实践,帮助开发者充分发挥 Redis 的价值。
一、热点数据缓存
这是 Redis 最经典的应用场景。在电商、社交等高频访问场景中,将热点数据(如商品详情、用户信
息)缓存到 Redis,可大幅降低数据库压力,提升系统响应速度。
实现要点:
缓存策略:采用 Cache-Aside 模式(先查缓存,未命中再查数据库并更新缓存)
过期控制:设置合理的 TTL(生存时间),避免缓存数据长期不更新
缓存键设计:使用业务前缀 + 唯一标识,如product:info:1001
空值处理:对查询不到的数据缓存空值(短 TTL),防止缓存穿透
二、分布式锁
在分布式系统中,多个服务实例需要协同操作共享资源时,分布式锁是保证数据一致性的关键机制。
Redis 的SET NX命令天然适合实现分布式锁。
实现要点:
加锁:使用SET key value NX PX 30000(不存在则设置,过期时间 30 秒)
解锁:通过 Lua 脚本原子性判断并删除锁,避免误删
续期:对长时间运行的任务,需定时延长锁的有效期
重试机制:获取锁失败时,实现合理的重试策略
三、计数器与限流
Redis 的原子递增命令INCR非常适合实现计数器功能,结合过期时间可实现接口限流。
典型应用:
文章阅读量、视频播放次数统计
接口访问频率限制(如每分钟最多 100 次请求)
秒杀活动中的库存计数
四、排行榜系统
Redis 的 Sorted Set(有序集合)数据结构完美适配排行榜需求,支持按分数实时排序。
适用场景:
商品销量榜、用户积分榜
游戏排行榜(如分数、通关时间)
实时投票结果展示
五、分布式会话
在分布式系统中,使用 Redis 存储用户会话信息,可实现多服务实例间的会话共享。
实现优势:
会话信息集中存储,服务水平扩展无压力
支持设置过期时间,自动清理无效会话
可实现会话共享,提升用户体验
六、消息队列
利用 Redis 的 List 数据结构可实现简单的消息队列,适合对消息可靠性要求不高的场景。
实现方式:
生产者:使用LPUSH将消息推入队列
消费者:使用BRPOP阻塞式获取消息(避免轮询)
支持多个消费者协同工作,实现负载均衡
七、位图应用
Redis 的 Bitmap(位图)是一种节省空间的二进制数据结构,适合存储大量布尔值信息。
典型场景:
用户签到记录(如一年内的签到情况)
活跃用户统计(如最近 7 天活跃用户)
权限标记(如用户拥有的权限集合)
八、地理信息存储
Redis 的 GEO 数据结构专门用于存储和操作地理坐标信息,适合 LBS(基于位置的服务)场景。
应用场景:
附近的人 / 店铺查询
地理位置标记与距离计算
区域内的实体搜索
1.6 Redis特性
速度快:10WQPS,基于内存,C语言实现
单线程
持久化
支持多种数据结构
支持多种编程语言
功能丰富:支持Lua脚本,发布订阅,事务,pipeline等功能
简单:代码短小精悍(单机核心代码只有23000行左右),单线程开发容易,不依赖外部库,使用
简单
主从复制
支持高可用和分布式
1.6.1 单线程
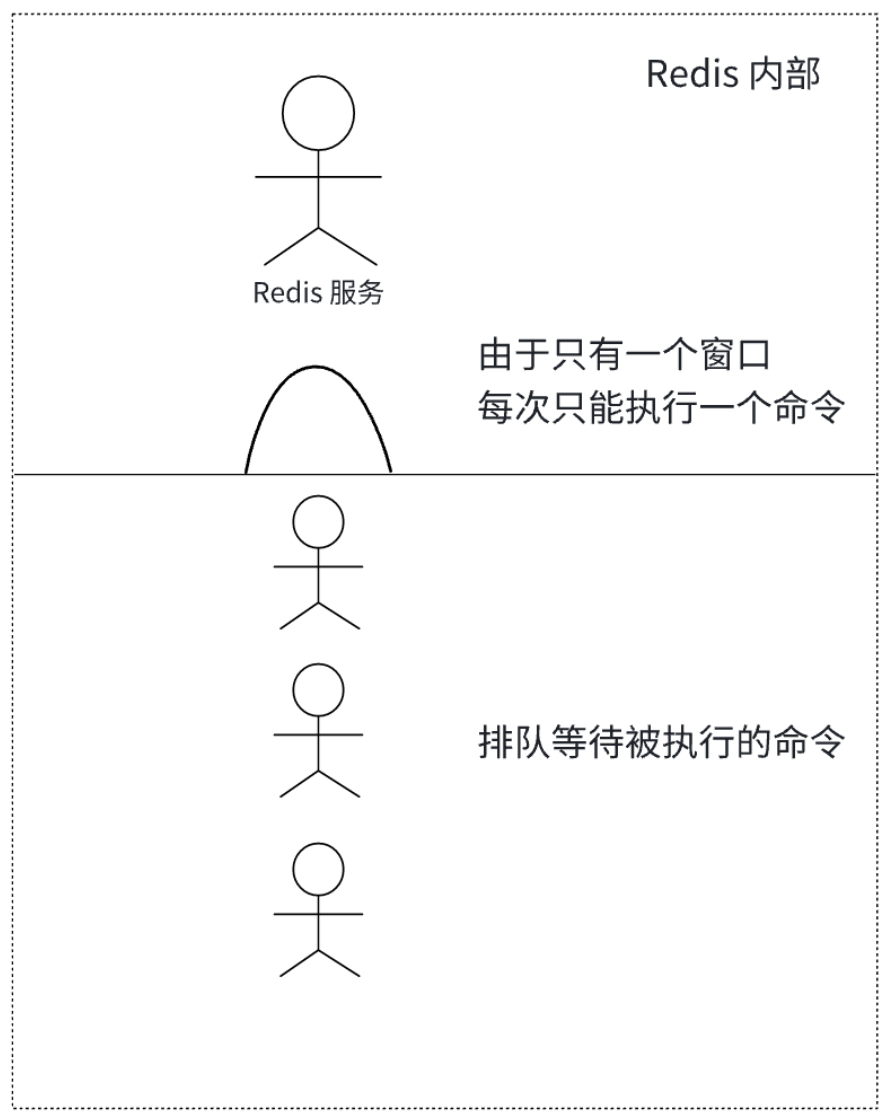
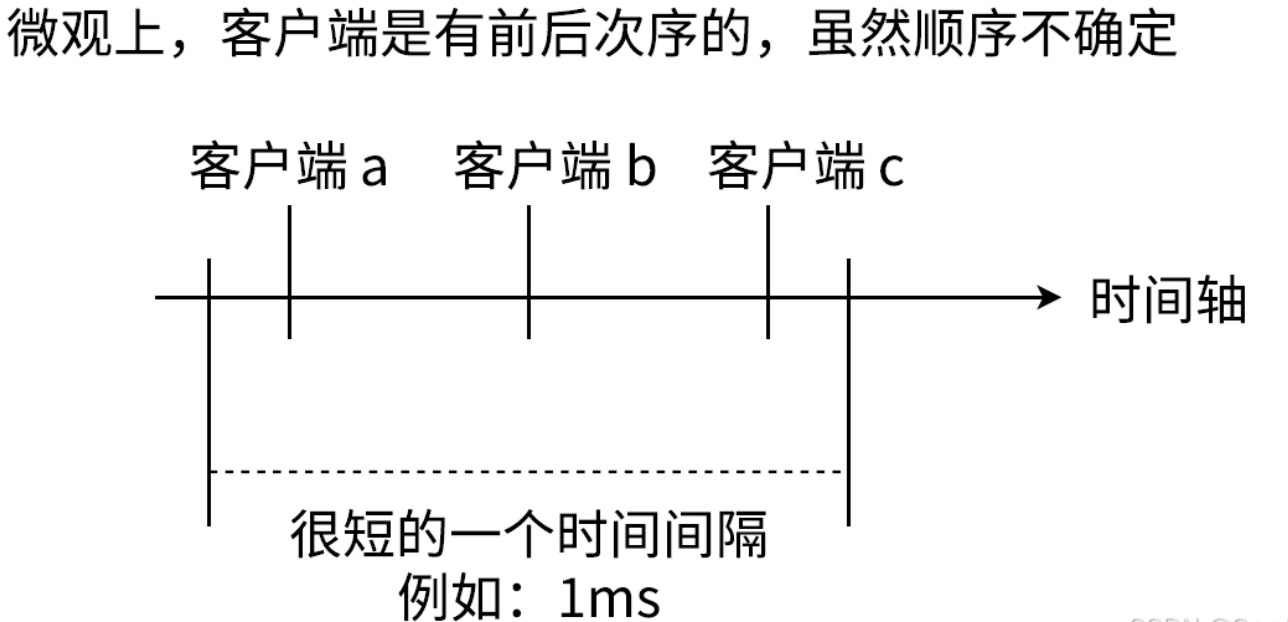
Redis6.0版本前一直是单线程方式处理用户的请求
-
Redis 的操作访问内存;数据库是访问硬盘
-
Redis核心功能,比数据库的核心功能更简单
数据库对于数据的插入删除查询... 都有更复杂的功能支持,这样的功能势必要花费更多的开
销。
比如,针对插入删除,数据库中的各种约束,都会使数据库做额外的工作(分组,联合查
询...)
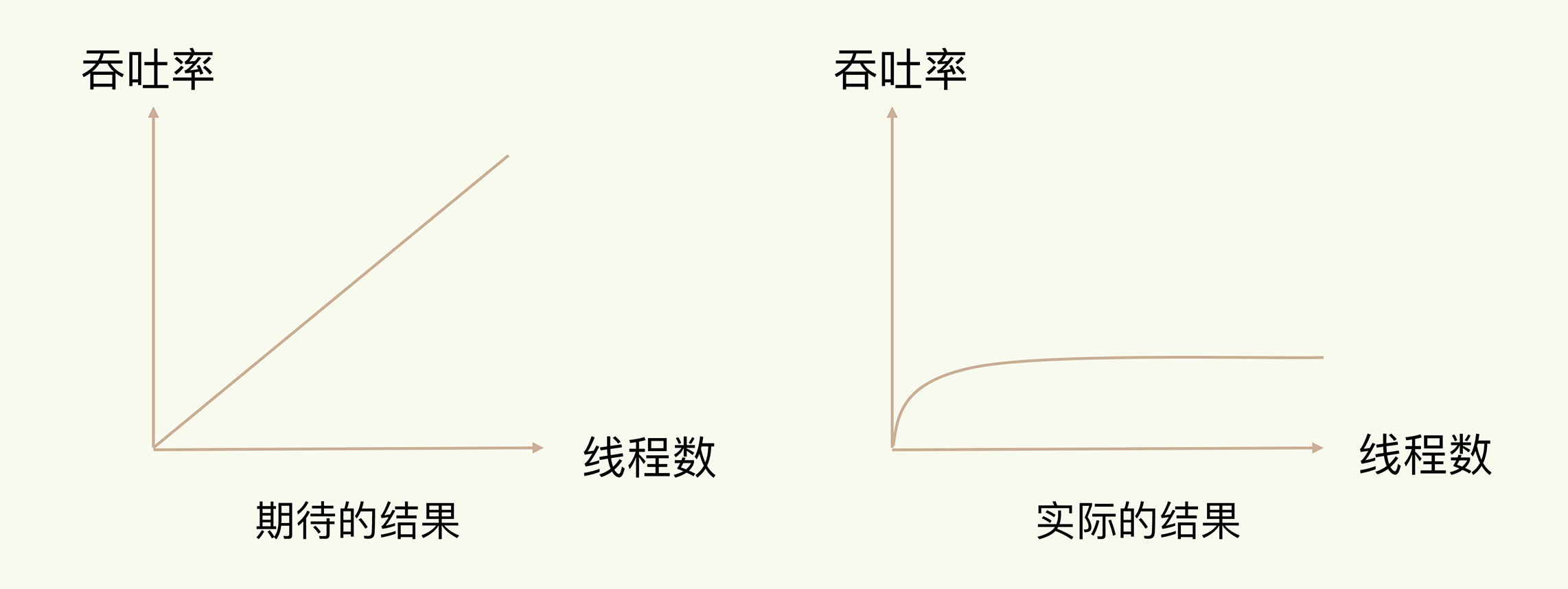
- 单线程模型,避免了一些不必要的线程竞争开销
Redis 每个基本操作都是短平快,就是简单操作一下内存数据,不是什么特别消耗 CPU 的操
作,就算搞多个线程,提升也不大
- 处理网络 IO 的时候,使用了 epoll 这样的 IO多路复用
IO多路复用
本质上是让我们一个线程,管理多个 socket
针对 TCP 来说,服务器这边每次要服务一个客户端,都需要给这个客户端安排一个 socket ,通过这个
socket 来和客户端进行通信
一个服务器要服务多个客户端,同时就有很多个 socket 。这些 socket 上都是无时无刻都在传输数据
吗?还是大部分时间都是闲置的?
很多情况下,每个客户端和服务器之间的通信也没那么频繁。此时这么多 socket 大部分时间都是
静默的,上面是没有数据需要传输的。
同一时刻,只有少数 socket 是活跃的,这就是我们使用 IO复用的重大前提
最开始介绍 TCP 服务器的时候,有一个版本就是每个客户端都分配一个线程==>客户端多了,线程
就多了,系统开销就大了
基于上述的这些原因,就搞了"IO多路复用",一个线程来处理多个 socket
操作系统,给程序员提供的机制,提供了一套 API,内部的功能都是操作系统内核实现的
Linux 上提供的 IO多路复用,主要是三套 API:select 、poll 、epoll
1.6.2 epoll
比如你今晚,你想吃烧烤,你妈想吃饺子,你爸想吃炒菜
- 你自己去买,先买烧烤,等;再买饺子,等;再买炒菜,等;完成。------>单线程,花的时间是最多
的
- 你们三个一起去买,各买各的,分别等;完成------>多线程,花的时间会缩短很多,等待的时间是三
者最大值,系统开销也会更大
- 你自己去买,你先去买烧烤,给老板说"好了叫我";再去买饺子,给老板说"好了叫我";再去买炒
菜,给老板说"好了叫我",此时一个线程同时等待三份饭------>IO 多路复用的方案,此时等待的时间
相比于多线程方案,相差不大,但是只需要一个线程就可以了
最关键的就是老爸能够喊我,哪个客户端来数据了,操作系统就能通知到应用程序
服务器开发中最主流的方案,尤其是 IO多路复用中的 epoll
epoll 相当于时间通知/回调机制 select 是你自己再几个摊位之间不停地问,没人提醒你
如果这三件事都是交互特别频繁的,还是老老实实多搞几个线程靠谱,一个线程容易忙不过来
C++ 可以直接使用 Linux 原生的 epoll API
Java 可以使用 NIO (标准库提供的一组类,底层就是封装了 epoll )
注意事项:
一次只运行一条命令
避免执行长(慢)命令:keys *,flushall, flushdb, slow lua script, mutil/exec,operate bigvalue(collection)
其实不是单线程:早期版本是单进程单线程,3.0版本后实际还有其它的线程,实现特定功能,如:fysnc
file descriptor,close file descriptor
1.6.3 缓存实现过程
计算机系统中的三层存储结构

计算机系统中,默认有两种缓存
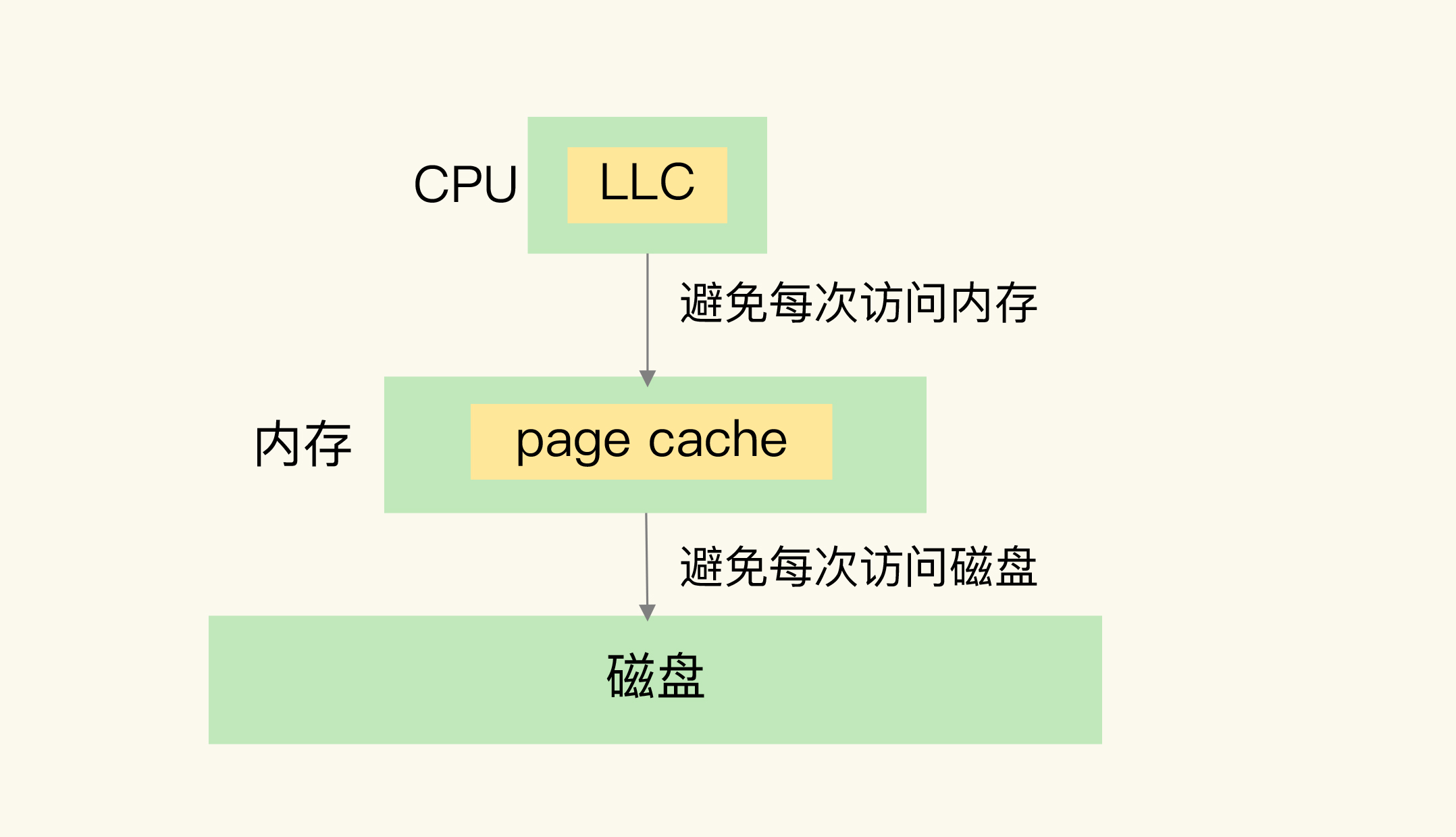
缓存的第一个特征:在一个层次化的系统中,缓存一定是一个快速子系统,数据存在缓存中时,能避免
每次从慢速子系统中存取数据。
缓存的第二个特征:缓存系统的容量大小总是小于后端慢速系统的,我们不可能把所有数据都放在缓存
系统中。
1.6.4 Redis 缓存处理请求的两种情况
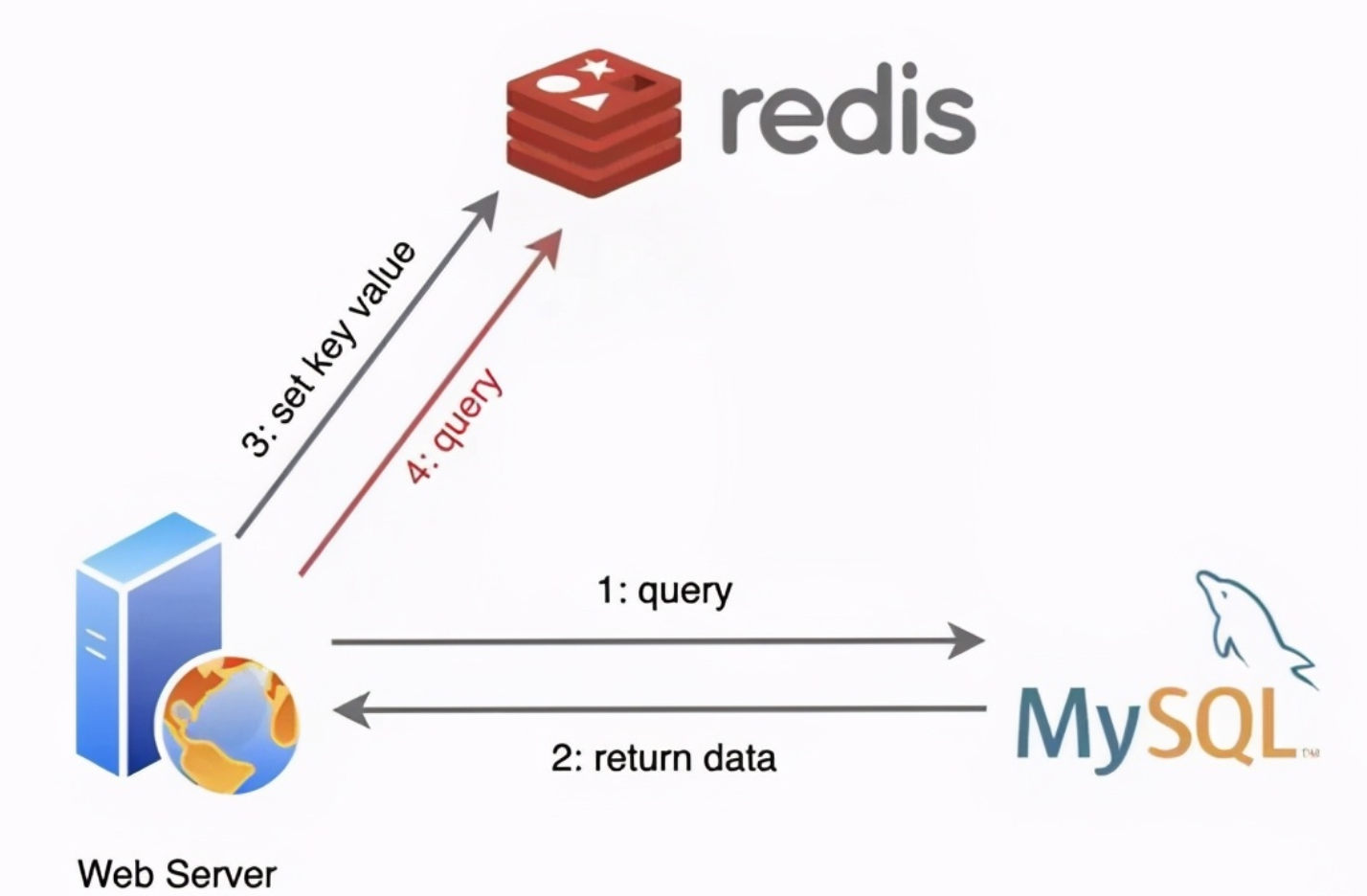
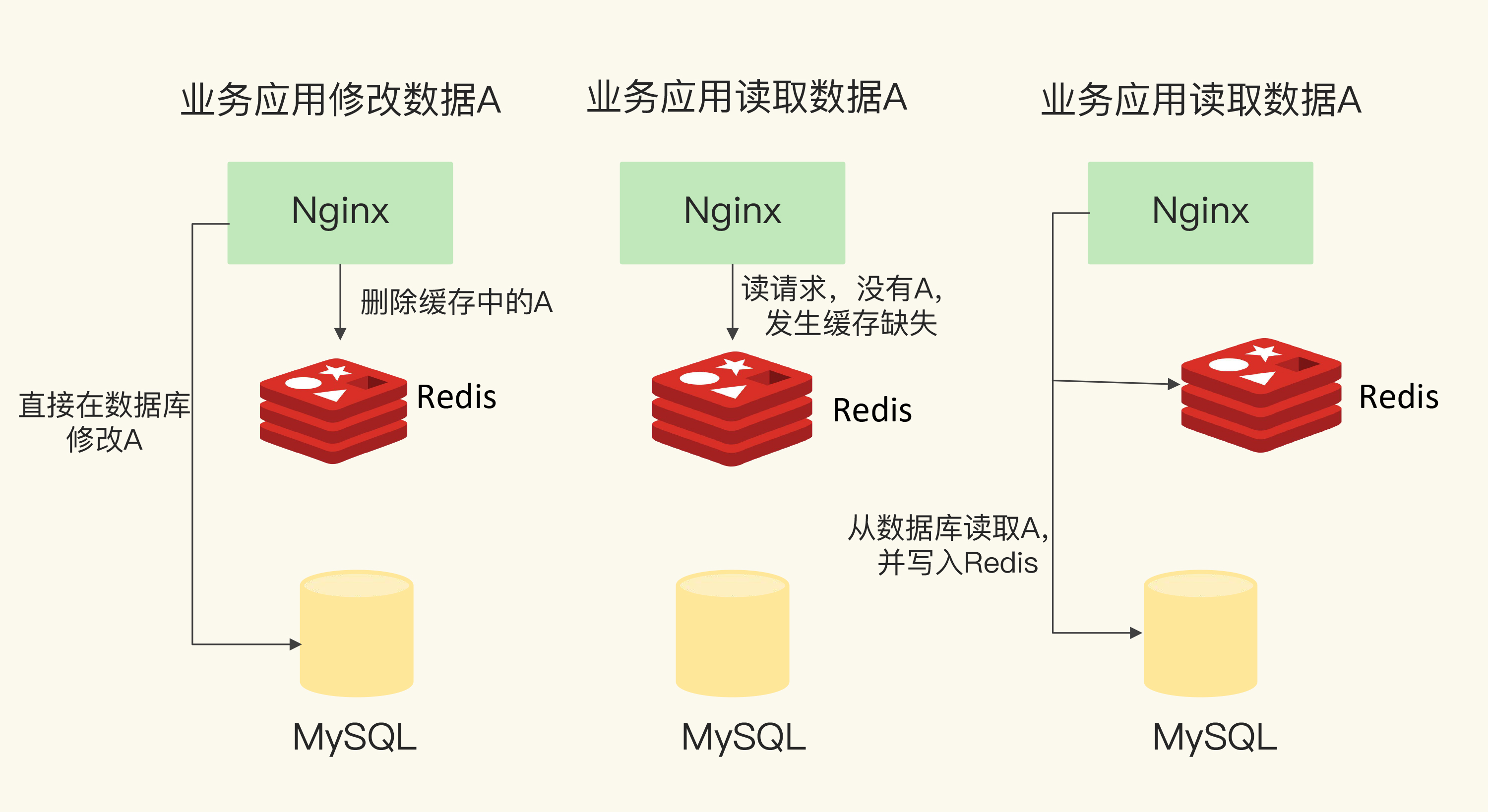
把 Redis 用作缓存时,我们会把 Redis 部署在数据库的前端,业务应用在访问数据时,会先查询 Redis中是否保存了相应的数据。此时,根据数据是否存在缓存中,会有两种情况。
缓存命中:Redis 中有相应数据,就直接读取 Redis,性能非常快。
缓存缺失:Redis 中没有保存相应数据,就从后端数据库中读取数据,性能就会变慢。而且,一旦
发生缓存缺失,为了让后续请求能从缓存中读取到数据,我们需要把缺失的数据写入 Redis,这个
过程叫作缓存更新。缓存更新操作会涉及到保证缓存和数据库之间的数据一致性问题。发生缓存命中或缺失时,应用读取数据的情况
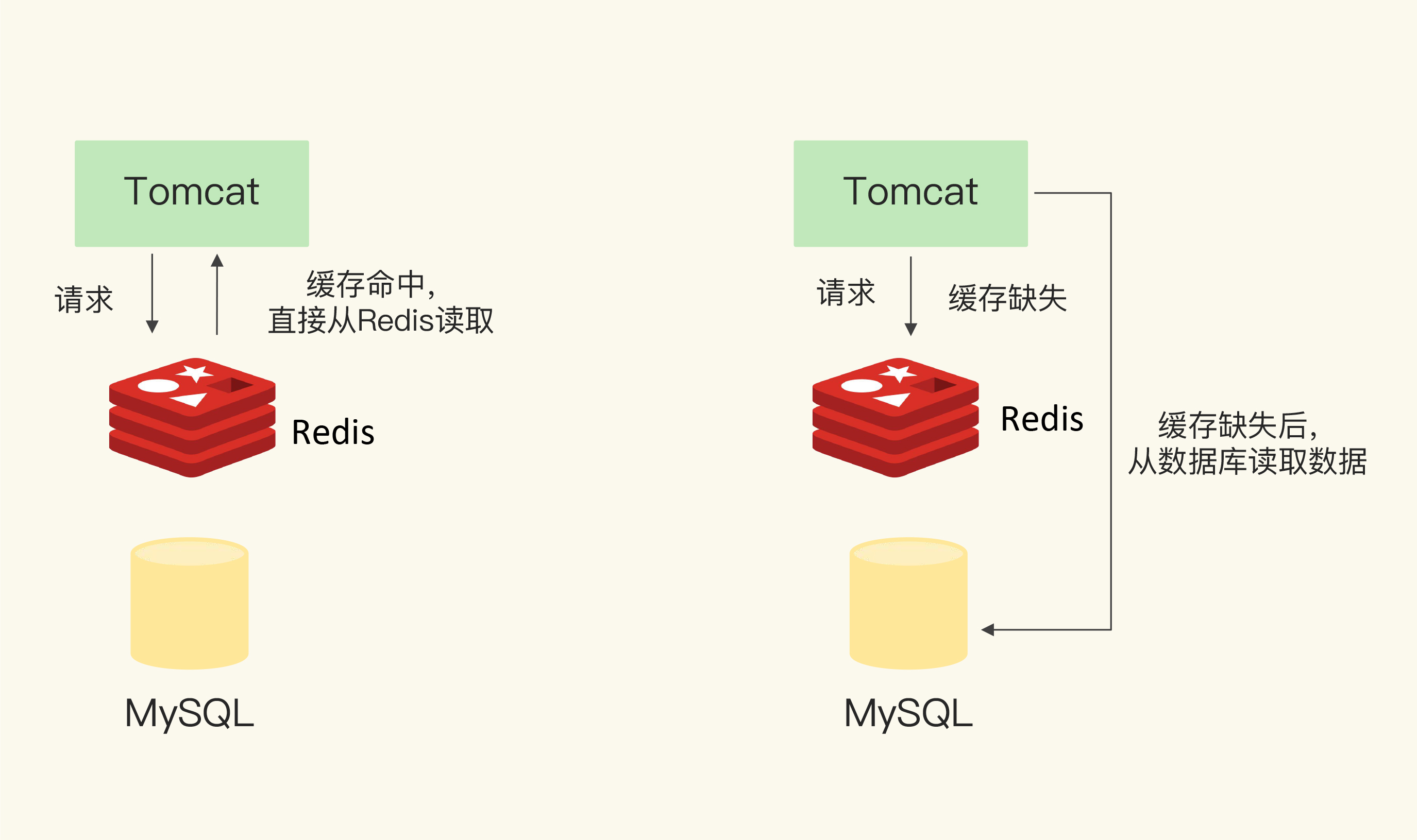
使用 Redis 缓存时,我们基本有三个操作:
- 应用读取数据时,需要先读取 Redis;
- 发生缓存缺失时,需要从数据库读取数据;
- 发生缓存缺失时,还需要更新缓存。
Redis 作为旁路缓存的使用操作
Redis 是一个独立的系统软件,和业务应用程序是两个软件,当我们部署了 Redis 实例后,它只会被动地
等待客户端发送请求,然后再进行处理。所以,如果应用程序想要使用 Redis 缓存,我们就要在程序中
增加相应的缓存操作代码。所以,我们也把 Redis 称为旁路缓存,也就是说,读取缓存、读取数据库和
更新缓存的操作都需要在应用程序中来完成。
那么,使用 Redis 缓存时,具体来说,我们需要在应用程序中增加三方面的代码:
- 当应用程序需要读取数据时,我们需要在代码中显式调用 Redis 的 GET 操作接口,进行查询;
- 如果缓存缺失了,应用程序需要再和数据库连接,从数据库中读取数据;
- 当缓存中的数据需要更新时,我们也需要在应用程序中显式地调用 SET 操作接口,把更新的数据写入缓存。
为了使用缓存,Web 应用程序需要有一个表示缓存系统的实例对象 redisCache,还需要主动调用 Redis
的 GET 接口,并且要处理缓存命中和缓存缺失时的逻辑,例如在缓存缺失时,需要更新缓存。
1.6.5 缓存的类型
按照 Redis 缓存是否接受写请求,我们可以把它分成只读缓存和读写缓存。
1.6.5.1 只读缓存
当 Redis 用作只读缓存时,应用要读取数据的话,会先调用 Redis GET 接口,查询数据是否存在。而所有的数据写请求,会直接发往后端的数据库,在数据库中增删改。对于删改的数据来说,如果 Redis 已经缓存了相应的数据,应用需要把这些缓存的数据删除,Redis 中就没有这些数据了。
当应用再次读取这些数据时,会发生缓存缺失,应用会把这些数据从数据库中读出来,并写到缓存中。
这样一来,这些数据后续再被读取时,就可以直接从缓存中获取了,能起到加速访问的效果。
只读缓存直接在数据库中更新数据的好处是,所有最新的数据都在数据库中,而数据库是提供数据可靠性保障的,这些数据不会有丢失的风险
1.6.5.2 读写缓存
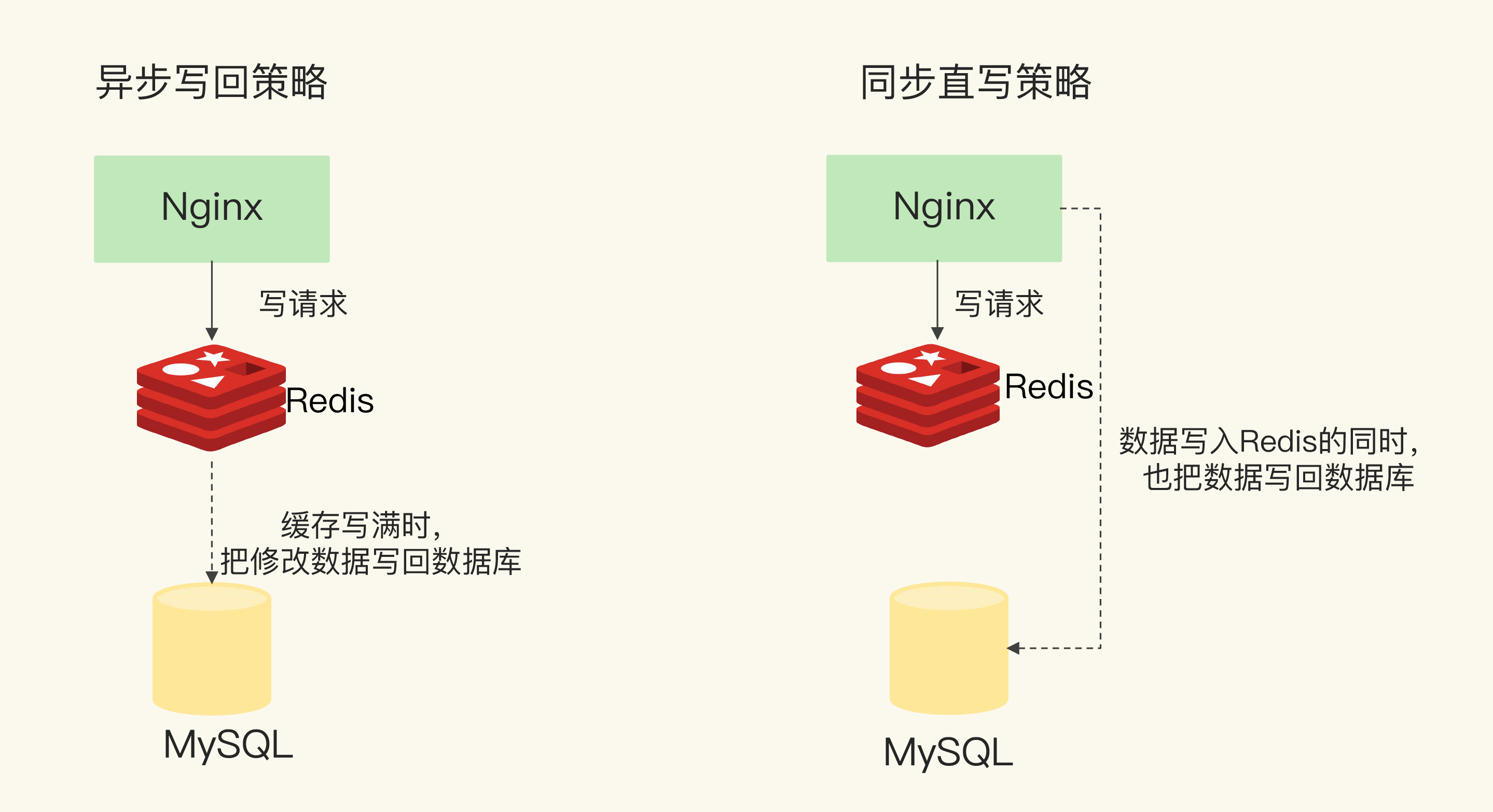
对于读写缓存来说,除了读请求会发送到缓存进行处理(直接在缓存中查询数据是否存在),所有的写请求也会发送到缓存,在缓存中直接对数据进行增删改操作。
但是,和只读缓存不一样的是,在使用读写缓存时,最新的数据是在 Redis 中,而 Redis 是内存数据库,一旦出现掉电或宕机,内存中的数据就会丢失。
根据业务应用对数据可靠性和缓存性能的不同要求,我们会有同步直写和异步写回两种策略。其中,同步直写策略优先保证数据可靠性,而异步写回策略优先提供快速响应。
同步直写是指,写请求发给缓存的同时,也会发给后端数据库进行处理,等到缓存和数据库都写完数据,才给客户端返回。
而异步写回策略,则是优先考虑了响应延迟。此时,所有写请求都先在缓存中处理。等到这些增改的数据要被从缓存中淘汰出来时,缓存将它们写回后端数据库。
同步直写和异步写回
小结
缓存的两个特征,分别是在分层系统中,数据暂存在快速子系统中有助于加速访问;缓存容量有限,缓存写满时,数据需要被淘汰。而 Redis 天然就具有高性能访问和数据淘汰机制,正好符合缓存的这两个特征的要求,所以非常适合用作缓存。
Redis 作为旁路缓存的特性,旁路缓存就意味着需要在应用程序中新增缓存逻辑处理的代码。
1.6.6 缓存穿透,缓存击穿和缓存雪崩
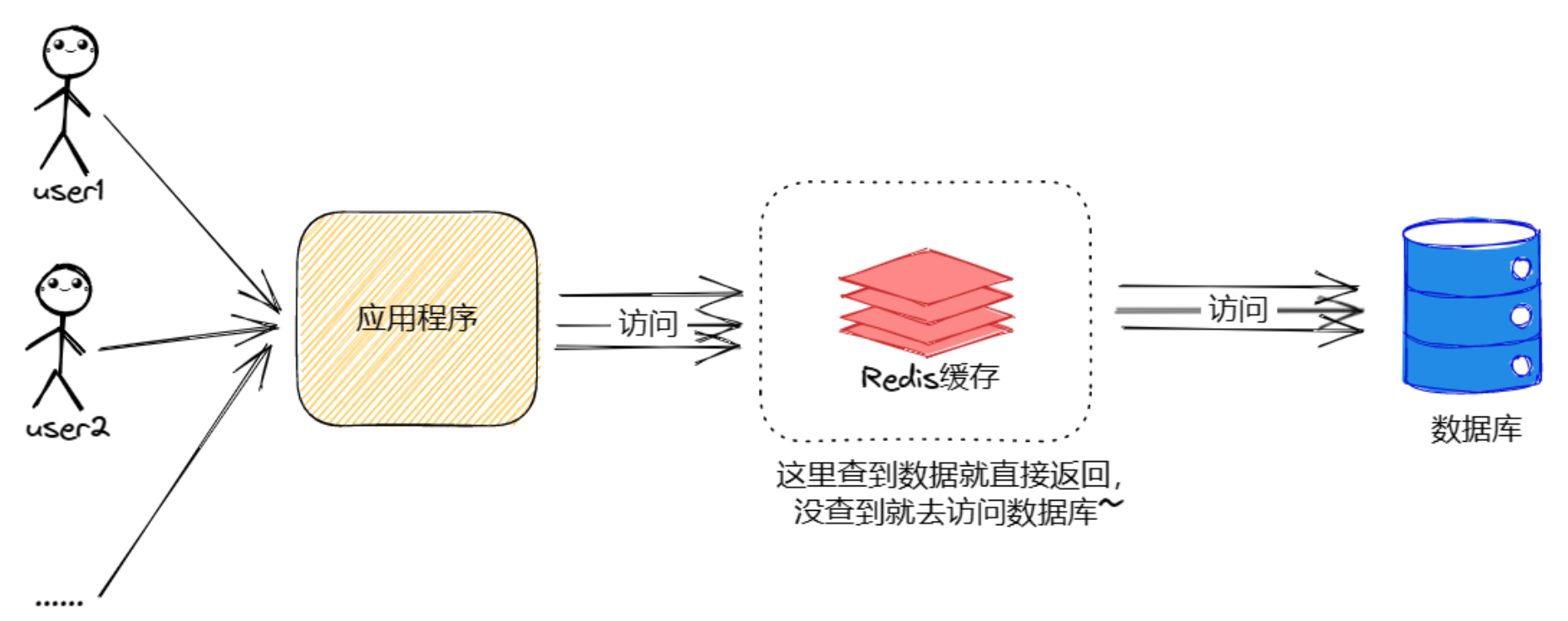
在程序中,没有缓存的时候,调用流程是这样的:
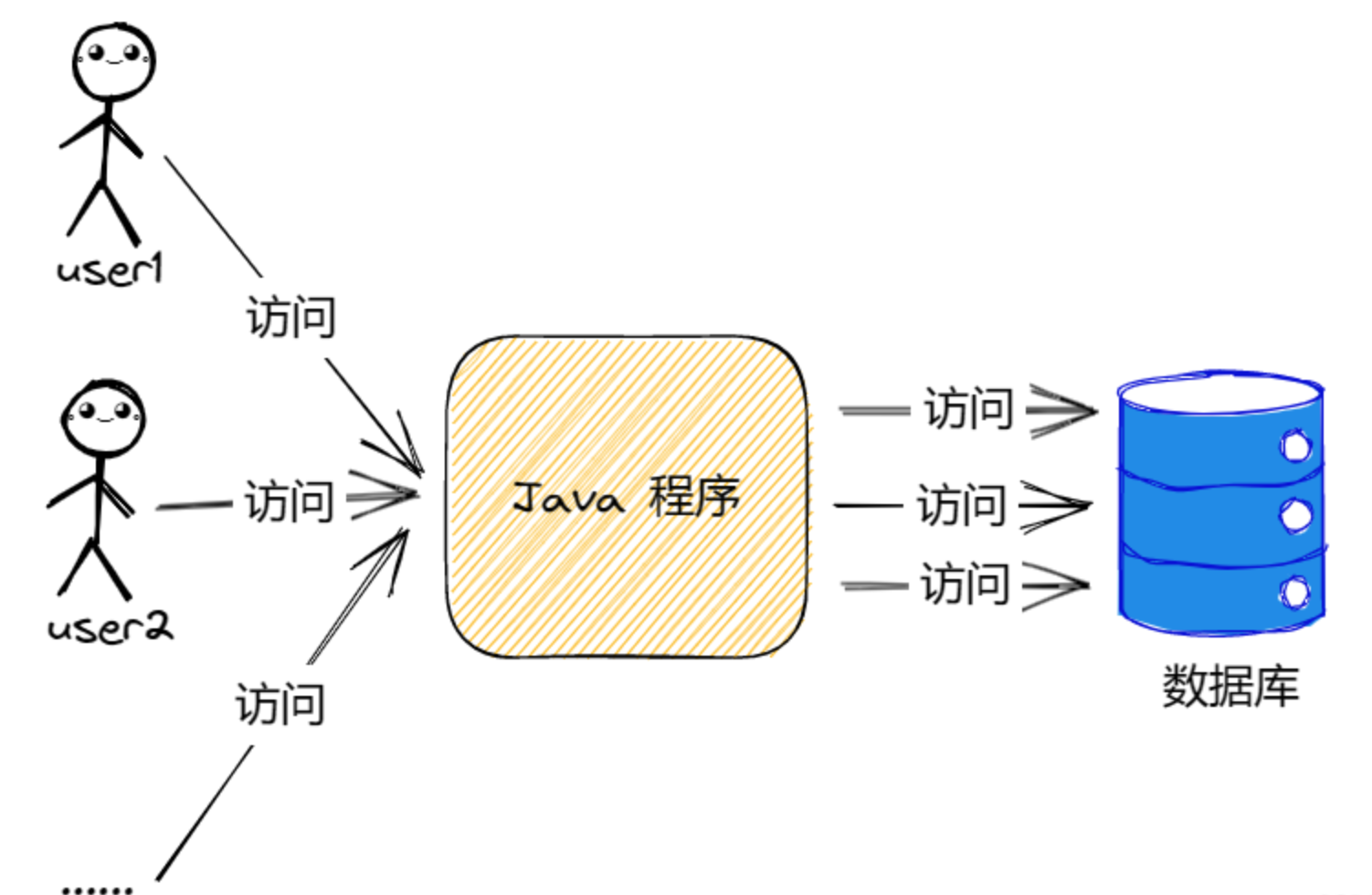
当我们加入缓存以后,程序就会变成以下样子:
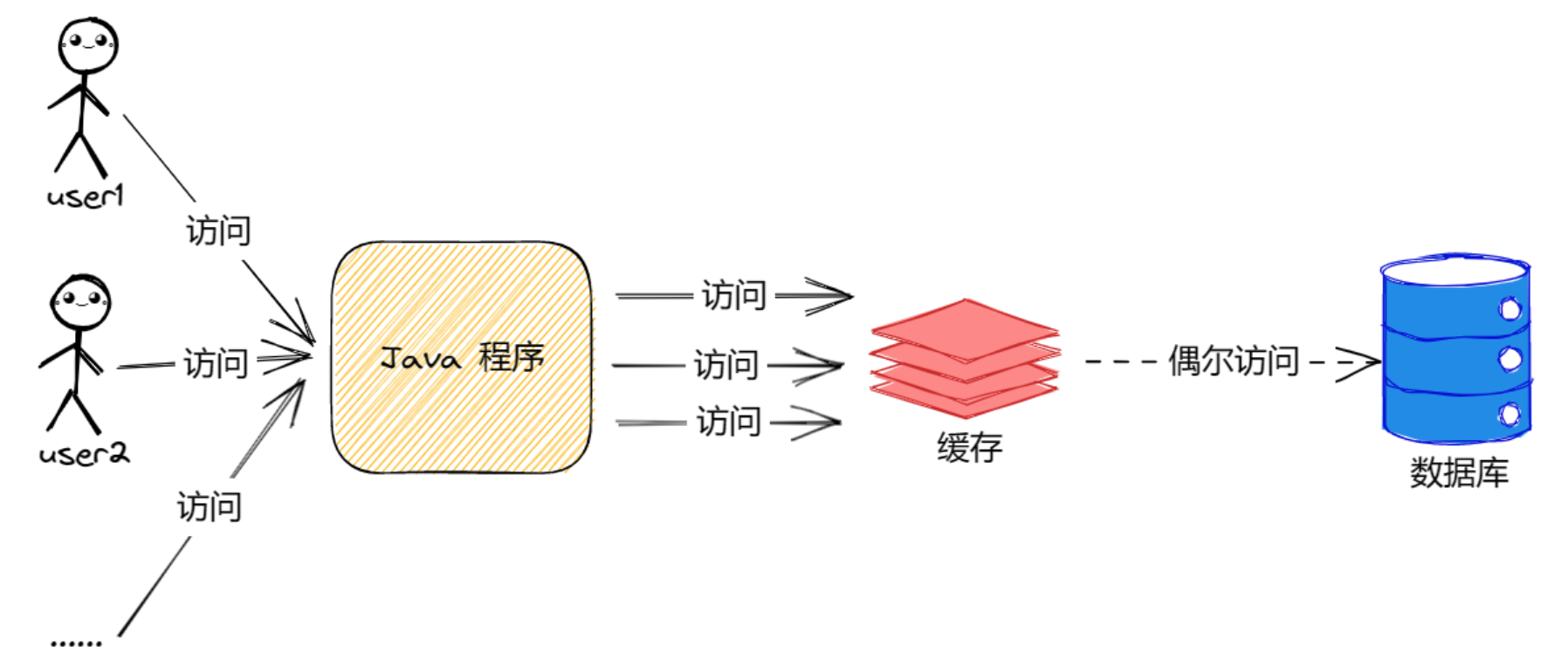
加入缓存之后,程序不直接调用数据库,而是先调用缓存,当缓存中存在数据就直接返回,当缓存中没有数据才去查询数据库大大降低了数据库的压力,加快了程序响应的速度。
缓存的优点
相对于数据库而言,缓存的操作性更高效,原因有以下几点:
- 缓存一般使用 key-value 查询数据的,不需要想数据库那样还有查询条件。
- 缓存的数据存储在内存中,而数据库的数据是存储在磁盘中的,内存的操作性能远远大于磁盘。
- 缓存更容易实现分布式部署(一台服务器变成多台相连的服务器集群),而数据库比较难实现分布式部署,缓存的性能更容易平行扩展。
缓存的分类
缓存可以分为以下两类:
本地缓存 :也叫单机缓存,也就是说在一台服务器上缓存,因此只适用于当前系统。
分布式缓存 :用来应用在分布式系统中的缓存。分布式系统就是将一套服务器部署到多台服务器,
通过负载(通常是 Nginx)分发将用户的请求按照一定的规则分发到不同服务器上,如下图:
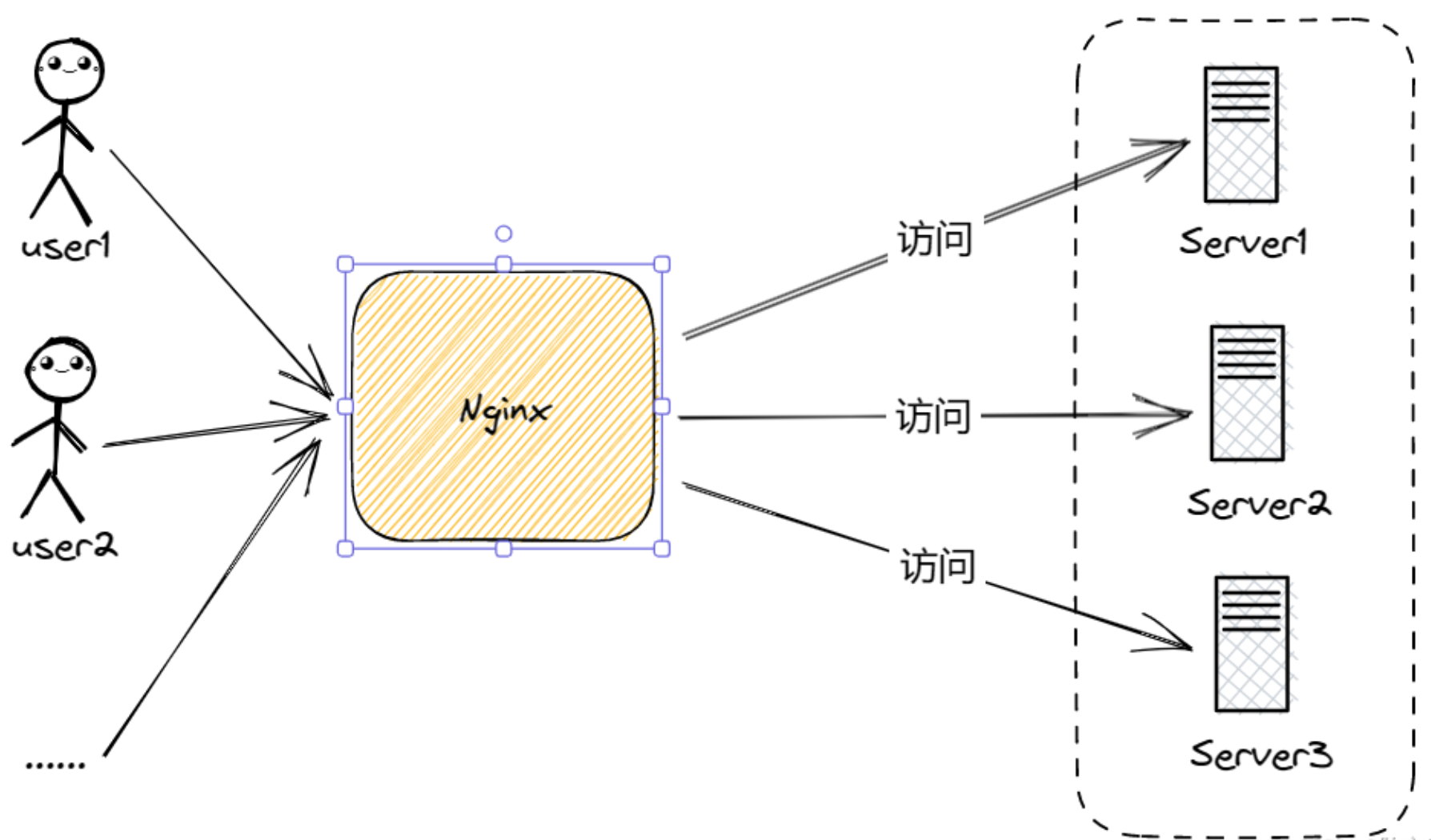
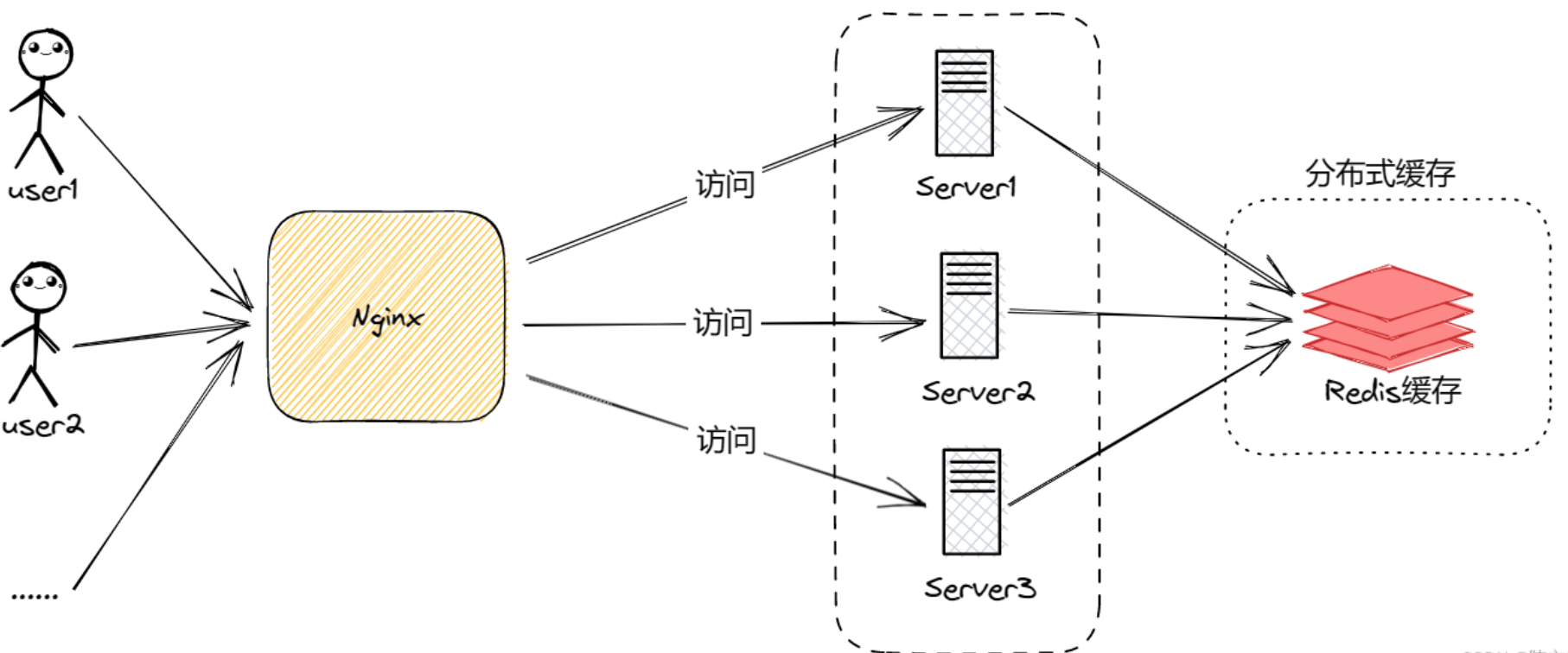
在上图加入分布式缓存后变成下图:
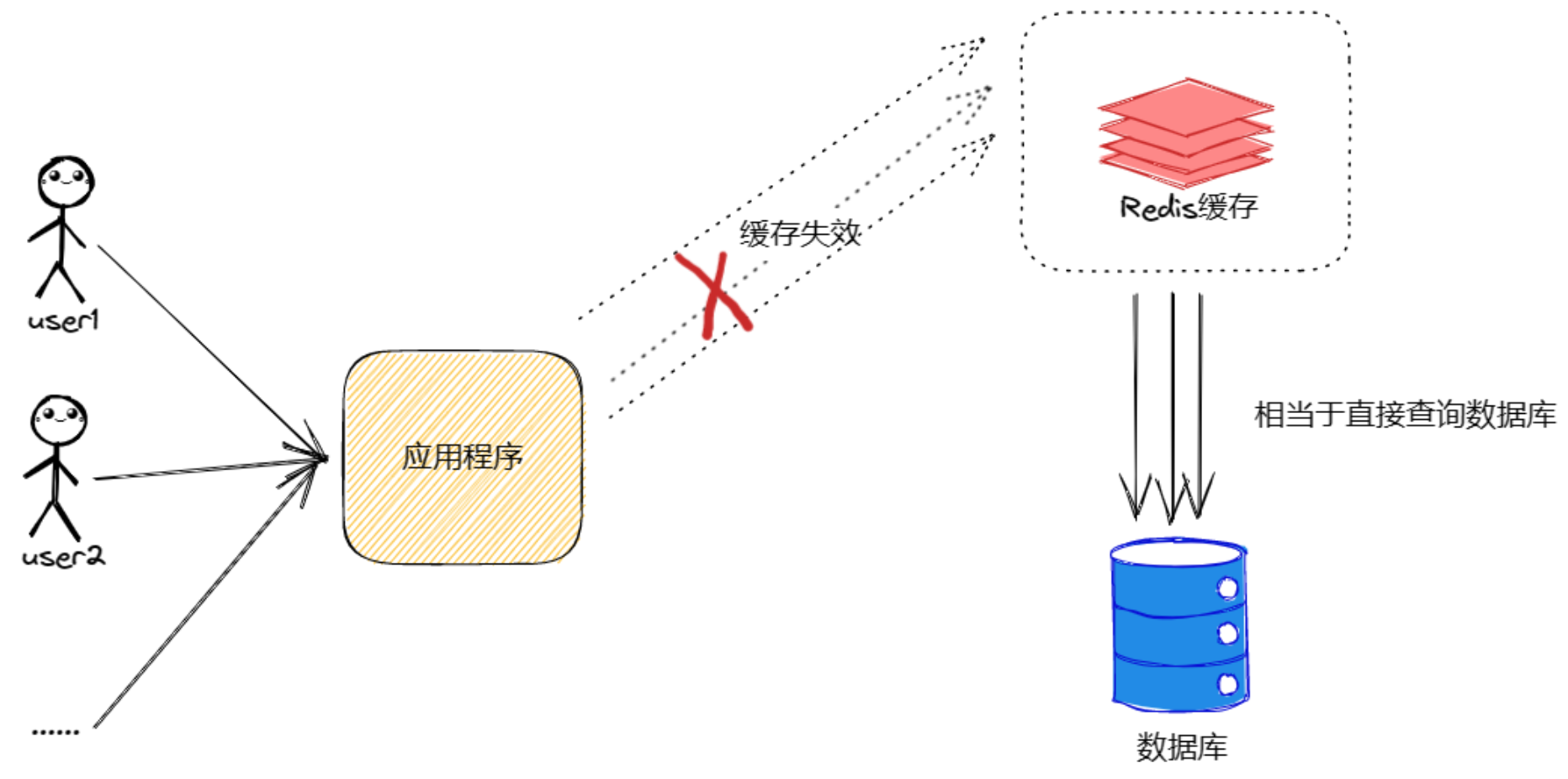
雪崩问题
1.定义
指缓存层由于大面积失效(如同一时间批量过期)或缓存服务宕机,导致所有请求瞬间涌入数据库,导致数据库崩溃的现象。
2. 通俗理解
想象一个游乐场,所有出口的闸机(Redis)同时坏了或者同时过期了,几千人一下子全部冲向检票口,大门(数据库)瞬间被挤爆。
3. 发生场景
-
批量 Key 同时过期:例如电商首页促销,1000 个商品商品的缓存都设置了 10 分钟 过期,时间一到,1000 个请求同时打库。
-
Redis 集群宕机:Redis 挂了,请求无路可走,直接穿透到 DB。
4. 后果
系统级故障,服务不可用,数据库压力达到峰值甚至挂掉。
我们来对比一下正常情况与缓存雪崩情况:
正常情况:
雪崩情况:
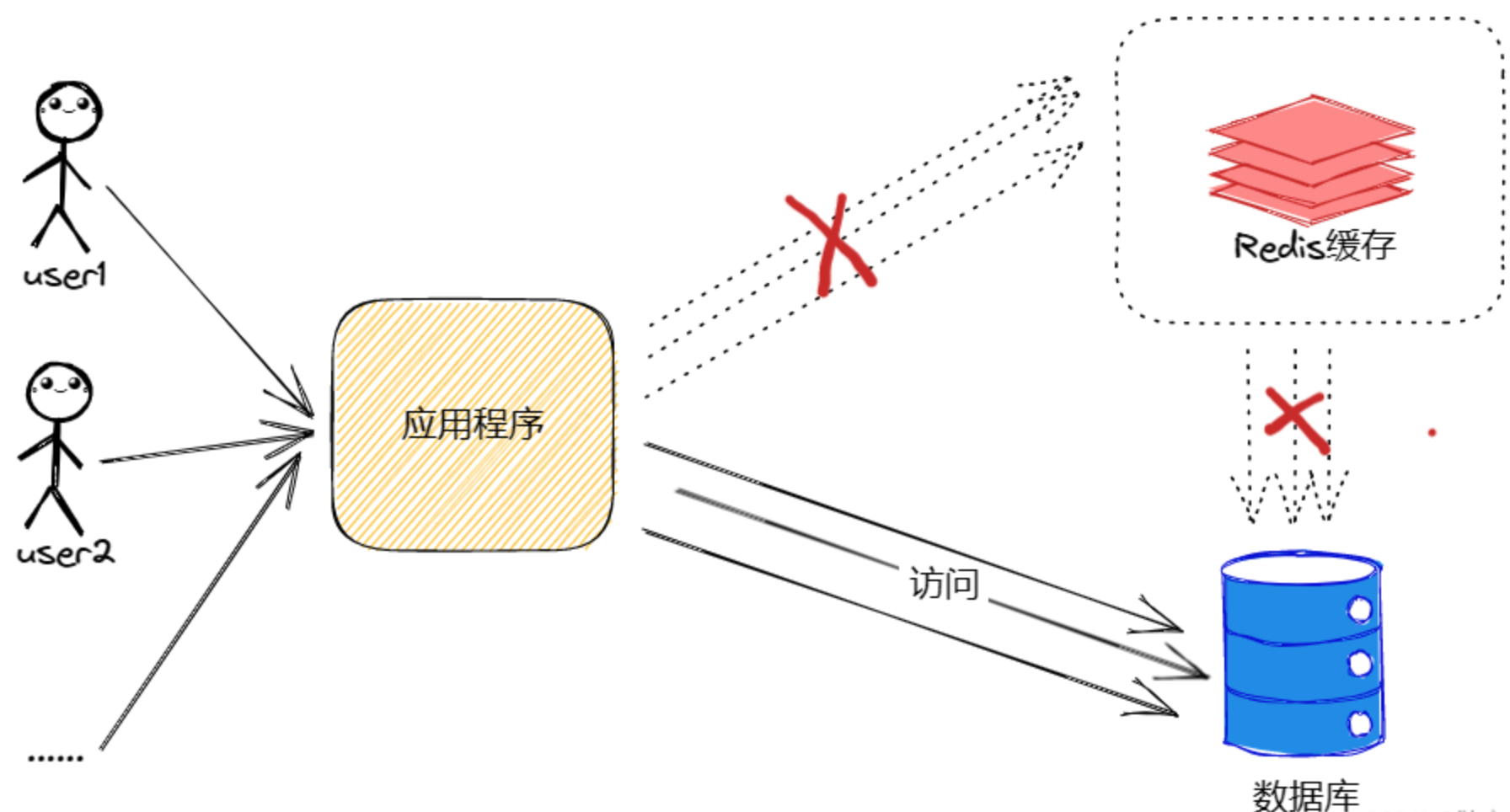
如何解决缓存雪崩问题
解决方案
-
过期时间加随机值 :给 Key 的过期时间加个随机范围(如 10分钟 + 1~5分钟),打散过期时间,避免集体爆炸。
-
搭建高可用集群 :Redis 多主多从,哨兵模式,避免单点故障。
-
服务限流熔断 :使用 Sentinel 或 Hystrix 限制并发数,保护数据库。
4.多级缓存:本地缓存 (Guava) + Redis,即使 Redis 挂了,本地还有数据。
缓存穿透
- 定义
指查询一个根本不存在的数据(缓存中没有,数据库中也没有)。因为缓存不缓存空值,所以每次请求都会绕过缓存直接去查数据库。
- 通俗理解
你拿着一张假身份证去游乐场检票,检票员(Redis)看了一眼说没这张票,就让你去后台查(数据库)。后台查了半天也没有,就让你回去了。结果来了一万个拿着假身份证的人,都去后台折腾,后台累坏了。
- 发生场景
攻击者恶意查询 user_id = -1 或不存在的商品 ID。业务代码 Bug 导致反复查无效 Key。
- 后果
无效请求反复打击数据库,导致 DB 资源浪费,甚至被 DOS 攻击打挂。
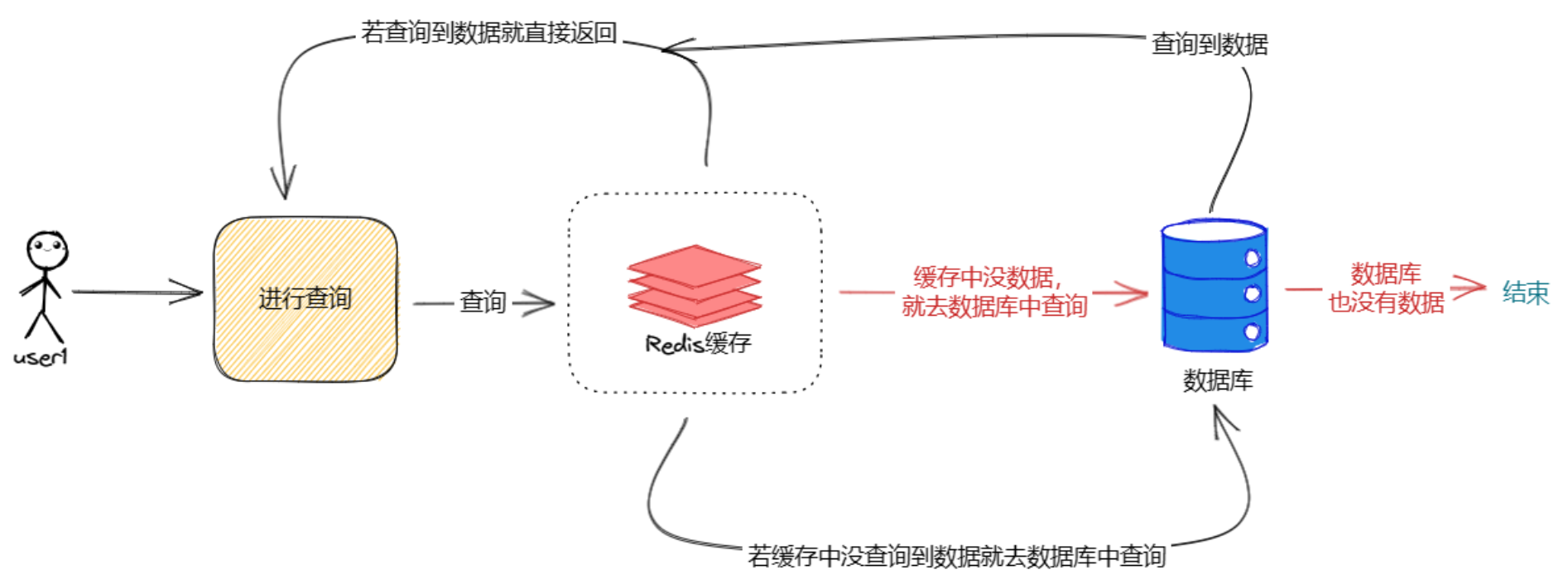
红色表示缓存穿透的执行路径,可以看出缓存穿透会给数据库造成巨大的压力。
如何解决缓存穿透问题
有以下几种解决方案:
- 接口层增加校验,如用户鉴权校验,ID做基础校验,id<=0的直接拦截
- 缓存空结果:对查询的空结果也进行缓存,如果是集合,可以缓存一个空的的集合,如果是缓存单个对象,可以字段标识来区分,避免请求穿透到数据库。
- 布隆过滤器处理:将所有可能对应的数据为空的 key 进行统一的存放,并在请求前做拦截,避免请求穿透到数据库(这样的方式实现起来相对麻烦,比较适合命中不高,但是更行不频繁的数据)。
缓存击穿
1. 定义
指热点 Key(访问量极大的 Key)在某个时刻过期,此时恰好有大量并发请求同时打过来。因为缓存中没有,这些请求都会去查询数据库。
- 通俗理解
游乐场只有一个 VIP 通道(热点 Key),这个通道刚好关闭了(过期了),但此时有一万人正排队等着通过,结果大家一拥而上,把通道旁边的闸机(数据库)挤坏了。
- 发生场景
秒杀活动、热点新闻爆发。某个商品缓存刚好过期,瞬间 10w QPS 涌入。
- 区别(重点!)
雪崩是大面积(很多 Key 一起挂)。
击穿是单点(一个热点 Key 挂了,但它很重要)。
- 后果
针对特定库表的攻击,导致该表压力剧增,响应变慢甚至拖垮。
如何解决缓存击穿问题
有以下几种解决方案:
加锁排队:和处理缓存雪崩的加锁类似,都是在查询数据库的时候加锁排队,缓存操作请求以此来减少服务器的运行压力。
设置永不过时:对于某些经常使用的缓存,我们可以设置为永不过期,这样就能保证缓存的稳定性,但要注意在数据更改后,要及时更新此热点缓存,否则就会造成查询结果误差。
1.7 Pipeline流水线
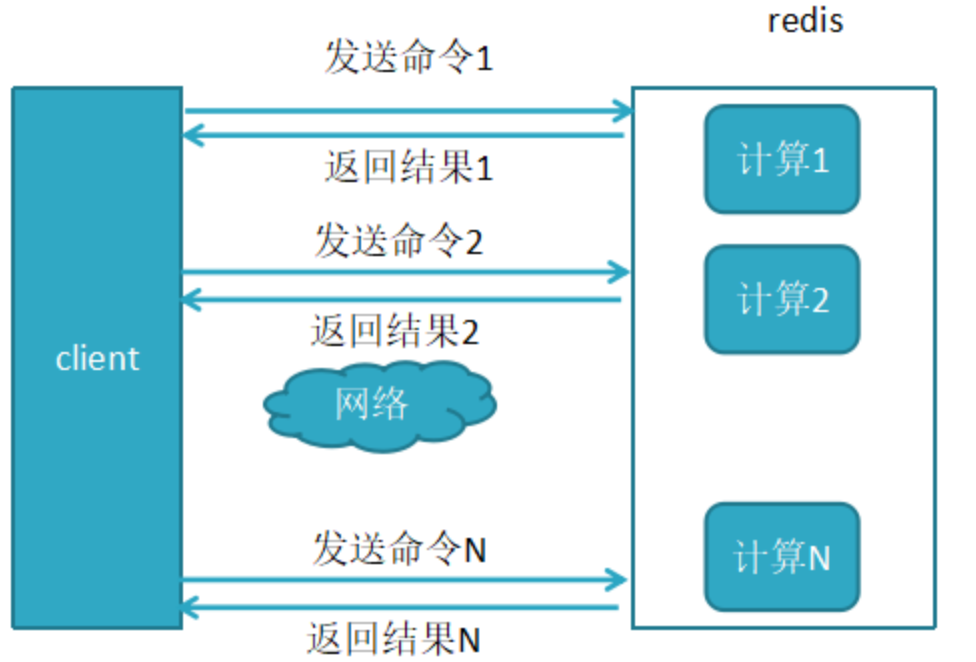
redis客户端执行一条命令分4个过程:
发送命令-〉命令排队-〉命令执行-〉返回结果
这个过程称为Round trip time(简称RTT, 往返时间),mget mset有效节约了RTT,但大部分命令(如hgetall,并没有mhgetall)不支持批量操作,需要消耗N次RTT ,这个时候需要pipeline来解决这个问题
Redis提供了批量操作命令(例如mget、mset等),有效地节约RTT。但大部分命令是不支持批量操作的,例如要执行n次hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。Redis的客户端和服务端
可能部署在不同的机器上。例如客户端在北京,Redis服务端在上海,两地直线距离约为1300公里,那么1次RTT时间=1300×2/(300000×2/3)=13毫秒(光在真空中传输速度为每秒30万公里,这里假设光纤为光速的2/3),那么客户端在1秒内大约只能执行80次左右的命令,这个和Redis的高并发高吞吐特性背道而驰。
Pipeline(流水线)机制能改善上面这类问题,它能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序
未使用pipeline执行N条命令
没有使用Pipeline执行了n条命令,整个过程需要n次RTT
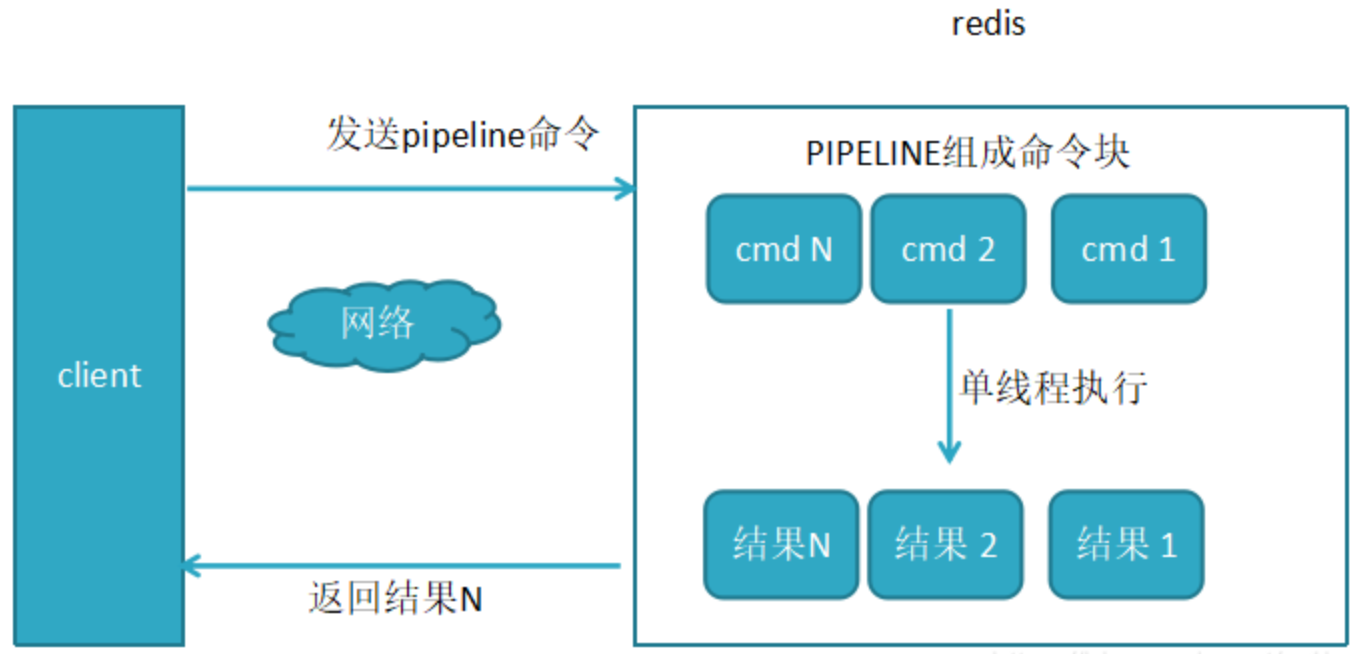
使用pipeline执行N条命令
使用Pipeline执行了n次命令,整个过程需要1次RTT。Pipeline并不是什么新的技术或机制,很多技术上都使用过。而且RTT在不同网络环境下会有不同,例如同机房和同机器会比较快,跨机房跨地区会比较慢。Redis命令真正执行的时间通常在微秒级别,所以才会有Redis性能瓶颈是网络这样的说法。
俩者性能对比
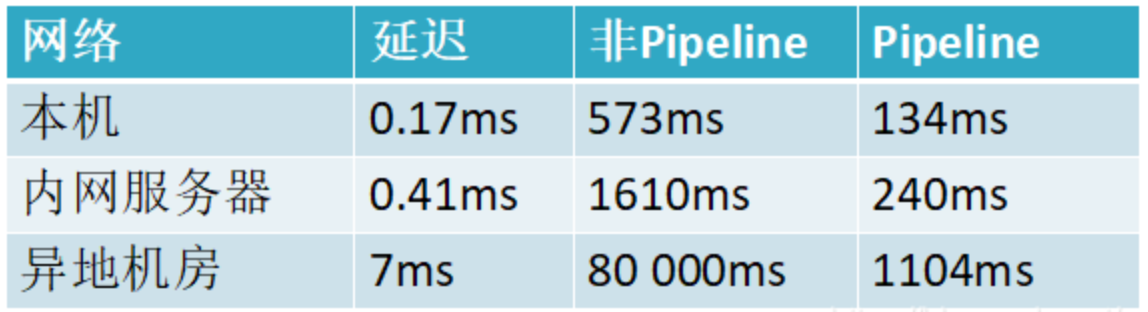
小结:这是一组统计数据出来的数据,使用Pipeline执行速度比逐条执行要快,特别是客户端与服务端的网络延迟越大,性能体能越明显。
1.8 redis的安装
centos7 redis源码安装
#安装依赖包
root@localhost \~# yum install tcl gcc gcc-c++ -y
#解压redis安装包
root@localhost \~# tar zxvf redis-6.2.14.tar.gz -C /usr/local/
#编译安装
root@localhost \~# cd /usr/local/redis-6.2.14/
root@localhost redis-6.2.14#make && make install
#启动并放在后台运行
root@localhost redis-6.2.14# redis-server redis.conf &
#查看启动端口
root@localhost redis-6.2.14# netstat -antp | grep 6379
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN
7751/redis-server 1
tcp6 0 0 ::1:6379 :::* LISTEN
7751/redis-server 1
#客户端进入
root@localhost redis-6.2.14# redis-cli
127.0.0.1:6379>
centos 8 yum安装
centos stream 8 由appstream仓库提供,centos7需要配置epel仓库
root@localhost \~# dnf info redis
安装redis
root@localhost \~# dnf install -y redis
设置服务开机自启并启动
root@localhost \~# systemctl enable redis --now
#查看redis-server监听6379端口
root@localhost \~# ss -tunlp
root@localhost \~# pstree -p | grep redis
root@localhost \~# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> info
Server
redis_version:5.0.3
redis_git_sha1:00000000
...
开启Redis多实例
root@localhost \~# redis-server --port 6380
#查看6380是否监听成功
root@localhost \~# ss -ntl
root@localhost \~# redis-cli -p 6380
127.0.0.1:6380> ping
PONG
Redis配置文件说明
Redis 默认使用端口号 6379
root@localhost \~# vim /etc/redis.conf
69 bind 127.0.0.1 #Redis 仅监听本地回环地址 127.0.0.1,这意味着只有本机可以连接Redis。若需远程访问,应改为 bind 0.0.0.0(但务必配合密码使用)。
88 protected-mode yes #启用保护模式。当 Redis 未设置密码且未明确绑定到特定 IP(或绑定了外网 IP)时,只允许来自 127.0.0.1 和 ::1 的连接。这是防止未授权访问的安全机制。
92 port 6379 #Redis 监听 TCP 端口 6379(默认端口)。
101 tcp-backlog 511 #设置 TCP 连接全队列(completed connection queue)的最大长
度为 511。高并发场景下可能需要调大,并同步调整系统参数 /proc/sys/net/core/somaxconn
113 timeout 0 #客户端空闲连接超时时间为 0,表示永不因空闲而断开连接。
130 tcp-keepalive 300 #每 300 秒(5 分钟)向客户端发送一次 TCP keepalive 探测包,用
于检测死连接。
136 daemonize no #Redis 不作为守护进程运行,而是以前台方式启动(适合容器化部署或
手动调试)。
147 supervised no #不与操作系统进程管理器(如 systemd 或 upstart)集成。
158 pidfile /var/run/redis_6379.pid #指定 Redis 主进程 PID 写入的文件路径。注意:该目录
需存在且 Redis 进程有写权限。
166 loglevel notice #日志级别设为 notice,记录重要信息(如启动、关闭、持久化事件),
适合生产环境。
171 logfile /var/log/redis/redis.log #日志输出到指定文件
/var/log/redis/redis.log。确保该路径可写。
186 databases 16 #Redis 启动时创建 16 个逻辑数据库(编号 0 到 15),可通过
SELECT <dbid> 切换。
194 always-show-logo yes #在启动redis时是否显示或在日志中记录记录redis的logo
RDB 快照持久化策略
218 save 900 1 #900 秒内至少有 1 个 key 变更 → 触发 bgsave
219 save 300 10 #300 秒内至少有 10 个 key 变更 → 触发 bgsave
220 save 60 10000 #60 秒内至少有 10000 个 key 变更 → 触发 bgsave
stop-writes-on-bgsave-error yes #如果后台 RDB 保存失败(如磁盘满),Redis 将拒绝写入操
作,防止数据丢失未被察觉。
rdbcompression yes #对 RDB 文件中的字符串值启用 LZF 压缩,节省磁盘空间(推
荐开启)。
rdbchecksum yes #在 RDB 文件末尾添加 CRC64 校验和,提高文件损坏检测能力
(性能损耗约 10%)。
dir /var/lib/redis #指定 Redis 工作目录。RDB 文件、AOF 文件等都将存储在此
目录下。必须是目录路径(不能是文件)。
dbfilename dump.rdb #RDB默认文件名
replica-serve-stale-data yes #当从节点(replica)与主节点失联时,仍可继续响应客户端请
求(可能返回过期数据)。若设为 no,则除部分管理命令外均返回错误。
replica-read-only yes #从节点默认为只读模式,禁止客户端在其上执行写命令(防止数
据不一致)。
repl-diskless-sync no #主节点在全量同步时,先将 RDB 文件写入磁盘,再发送给从节
点(而非直接通过 socket 流式传输)。
repl-diskless-sync-delay 5 #当启用 repl-diskless-sync yes 时,主节点等待 5 秒再
开始传输,以便更多从节点能加入批量同步。
replica-priority 100 #从节点优先级(供 Redis Sentinel 选主使用)。数值越小优
先级越高;设为 0 表示永不参与选主。
requirepass foobared #设置 Redis 访问密码为 foobared,客户端需先执行 AUTH foobared 才能操作。
maxclients 10000 # 最大客户端连接数
appendonly no # 禁用 AOF 持久化(仅使用 RDB)
appendfilename "appendonly.aof" # AOF 文件名(当前未生效)
appendfsync everysec # 若启用 AOF,每秒 fsync 一次(平衡性能与安全)
no-appendfsync-on-rewrite no # RDB/AOF 重写期间仍执行appendfsync
config命令实现动态修改配置
config命令用于查看当前redis配置,以及不重启redis服务实现动态更改redis配置等Caution
不是所有配置都可以动态修改,且此方法无法持久化保存
auto-aof-rewrite-percentage 100 # AOF 文件比上次重写后增长 100%时触发重写
auto-aof-rewrite-min-size 64mb # AOF 文件至少 64MB 才触发自动重写
aof-load-truncated yes # 启动时若 AOF 被截断,尝试加载并继续启动
aof-use-rdb-preamble yes # AOF 重写使用 RDB 前导(混合持久化,加快恢复)
lua-time-limit 5000 # Lua 脚本最大执行时间(毫秒)
slowlog-log-slower-than 10000 # 慢查询阈值:10000 微秒(10 毫秒)
slowlog-max-len 128 # 慢查询日志最多保留 128 条
latency-monitor-threshold 0 # 延迟监控阈值(0 = 关闭)
notify-keyspace-events "" # 键空间通知事件(空 = 禁用)
hash-max-ziplist-entries 512 # Hash 使用 ziplist 编码的最大元素数
hash-max-ziplist-value 64 # Hash 使用 ziplist 编码的单个field/value 最大字节数
list-max-ziplist-size -2 # List 的 quicklist 每个
ziplist 节点最大为 8KB(-2)
list-compress-depth 0 # List 的 quicklist 压缩深度(0= 不压缩)
set-max-intset-entries 512 # Set 使用 intset 编码的最大整数元素数
zset-max-ziplist-entries 128 # Sorted Set 使用 ziplist 编码的最大元素数
zset-max-ziplist-value 64 # Sorted Set 使用 ziplist 编码的单个 member/score 最大字节数
hll-sparse-max-bytes 3000 # HyperLogLog 稀疏表示最大字节数(超过转稠密)
stream-node-max-bytes 4096 # Stream 单个节点最大字节数
stream-node-max-entries 100 # Stream 单个节点最大消息条数
activerehashing yes # 启用渐进式 rehash,避免卡顿
client-output-buffer-limit normal 0 0 0 # 普通客户端输出缓冲区无限制
client-output-buffer-limit replica 256mb 64mb 60 # 从节点:硬限 256MB,软限 64MB持续 60 秒则断开
client-output-buffer-limit pubsub 32mb 8mb 60 # Pub/Sub 客户端:硬限 32MB,软限 8MB 持续 60 秒则断开
hz 10 # 后台任务每秒执行 10 次(如过期key 清理)
dynamic-hz yes # 动态调整 hz(连接多时自动提高)
aof-rewrite-incremental-fsync yes # AOF 重写时增量 fsync(每 32MB刷一次)
rdb-save-incremental-fsync yes # RDB 保存时增量 fsync(每 32MB刷一次)
案例:版本差异
redis 7支持动态修改端口
127.0.0.1:6379> config set port 8888
OK
redis 5不支持动态修改端口
127.0.0.1:6379> config set port 8888
(error) ERR Unsupported CONFIG parameter: port
设置客户端连接密码
设置连接密码
127.0.0.1:6379> CONFIG SET requirepass 123456
OK
查看连接密码
root@localhost \~# redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface
may not be safe.
127.0.0.1:6379> CONFIG GET requirepass
"requirepass"
"123456"
获取当前配置
奇数行为键,偶数行为值
127.0.0.1:6379> CONFIG GET *
"dbfilename"
"dump.rdb"
"requirepass"
"123456"
......
查看bind
127.0.0.1:6379> CONFIG GET bind
"bind"
"127.0.0.1"
Redis5.0有些设置无法修改,Redis6.2.14版本支持修改bind
127.0.0.1:6379> CONFIG SET BIND 0.0.0.0
(error) ERR Unsupported CONFIG parameter: BIND
127.0.0.1:6379> config set bind 0.0.0.0
OK
设置Redis使用最大内存容量
查看默认配置
127.0.0.1:6379> CONFIG GET maxmemory
"maxmemory"
"0"
默认以字节为单位
127.0.0.1:6379> CONFIG SET maxmemory 10086
OK
127.0.0.1:6379> CONFIG GET maxmemory
"maxmemory"
"10086"
也可以写单位
127.0.0.1:6379> CONFIG SET maxmemory 1G
OK
127.0.0.1:6379> CONFIG GET maxmemory
"maxmemory"
"1000000000"
慢查询
许多存储系统(例如MySQL)提供慢查询日志帮助开发和运维人员定位系统存在的慢操作。所谓慢查询
日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息
(例如:发生时间,耗时,命令的详细信息)记录下来,Redis也提供了类似的功能。
一条客户端命令声明周期如下:
1)发送命令
2)命令排队
3)命令执行
4)返回结果
两点说明:
-
慢查询发生在第三阶段
-
客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因数
多慢算慢?--->超出阈值就算慢
1000us(微秒)=1ms(毫秒)
root@localhost \~# vim /etc/redis.conf
995 slowlog-log-slower-than 1 #单位为us,指定超过1us即为慢的指令,默认值为10000us
999 slowlog-max-len 1024 #指定只保存最近的1024条慢记录,默认值为128
root@localhost \~# systemctl restart redis
查看慢日志的记录条数
root@localhost \~# redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface
may not be safe.
127.0.0.1:6379> SLOWLOG LEN
(integer) 5
127.0.0.1:6379> SLOWLOG GET
- (integer) 5 #项目唯一ID
(integer) 1770892970 #unix时间戳
(integer) 3 #执行耗时(微秒)
- "SLOWLOG" #执行的命令
"LEN"
"127.0.0.1:56406" #客户端IP和端口
""
...
清空慢日志
127.0.0.1:6379> SLOWLOG RESET
OK
RAIDS持久化
什么是 Redis 持久化?
Redis 作为一个键值对内存数据库(NoSQL),数据都存储在内存当中,在处理客户端请求时,所有操作都
在内存当中进行,如下所示

这样做有什么问题呢?其实,只要稍微有点计算机基础知识的人都知道,存储在内存当中的数据,只要
服务器关机(各种原因引起的),内存中的数据就会消失了。
不仅服务器关机会造成数据消失,Redis 服务器守护进程退出,内存中的数据也一样会消失。
对于只把 Redis 当缓存来用的项目来说,数据消失或许问题不大,重新从数据源把数据加载进来就可以了。
但如果直接把用户提交的业务数据存储在 Redis 当中,把 Redis 作为数据库来使用,在其放存储重要业务数据,那么 Redis 的内存数据丢失所造成的影响也许是毁灭性。
为了避免内存中数据丢失,Redis 提供了对持久化的支持,我们可以选择不同的方式将数据从内存中保存到硬盘当中,使数据可以持久化保存。
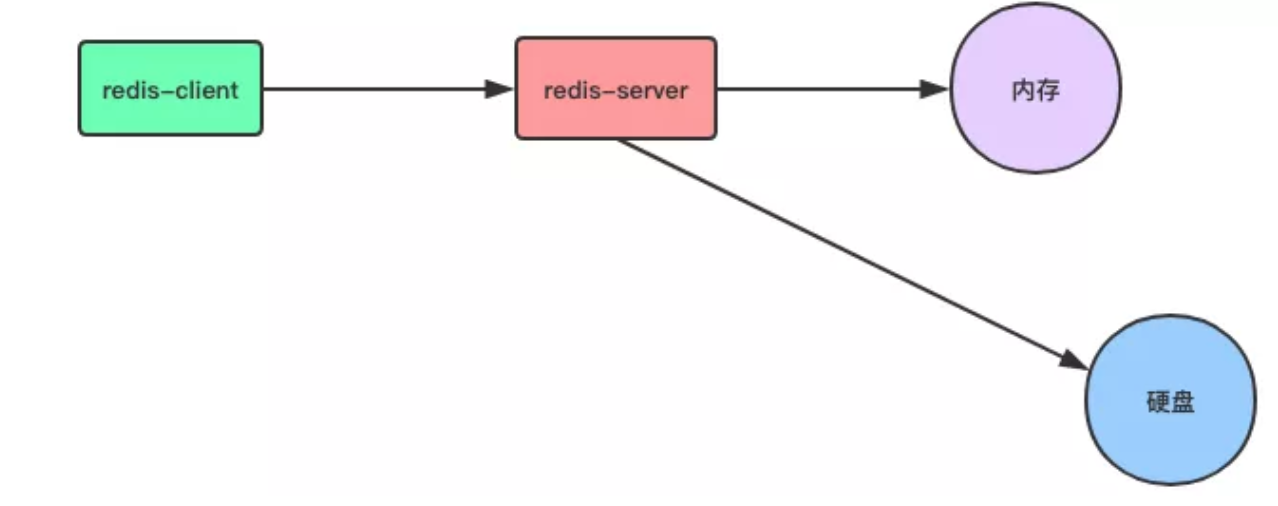
Redis 提供了 RDB 和 AOF 两种不同的数据持久化方式:
- RDB:Redis DataBase
- AOF:Appen-only File
RDB
RDB 是一种快照存储持久化方式,具体就是将 Redis 某一时刻的内存数据保存到硬盘的文件当中,默认保存的文件名为 dump.rdb,而在 Redis 服务器启动时,会重新加载 dump.rdb 文件的数据到内存当中恢复数据。
开启 RDB 持久化方式
开启 RDB 持久化方式很简单,客户端可以通过向 Redis 服务器发送 save 或 bgsave 命令让服务器生成RDB 文件,或者通过服务器配置文件指定触发 RDB 条件。
save 命令:是一个同步操作
同步数据到磁盘上
127.0.0.1:6379> save
OK
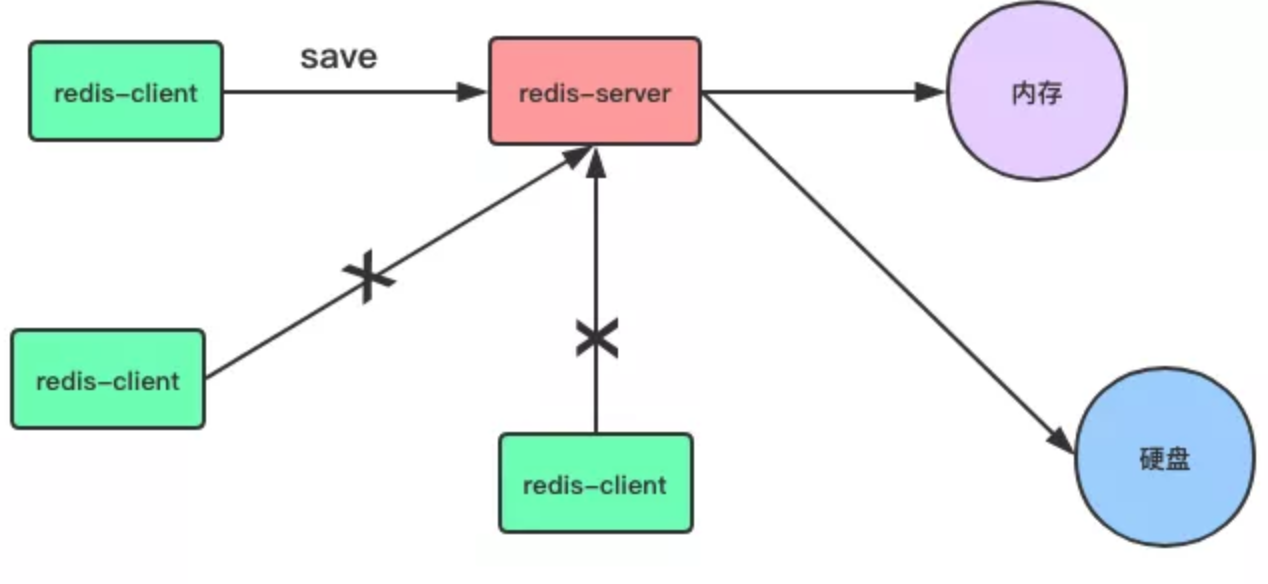
当客户端向服务器发送 Save 命令请求进行持久化时,服务器会阻塞 Save 命令之后的其他客户端的请求,直到数据同步完成。
如果数据量太大,同步数据会执行很久,而这期间 Redis 服务器也无法接收其他请求,所以,最好不要在生产环境使用 Save 命令。
范例:save执行过程会使用主进程进行快照
查看默认进程
root@localhost \~# pstree -p | grep redis-server ; ll -h /var/lib/redis
|-redis-server(2104)-+-{redis-server}(2105)
| |-{redis-server}(2106)
| `-{redis-server}(2107)
total 4.0K
-rw-r--r-- 1 redis redis 92 Feb 21 17:58 dump.rdb
执行save
root@localhost \~# redis-cli
127.0.0.1:6379> debug populate 5000000 #这是 Redis 的一个调试命令(debug
command),用于快速生成大量测试数据,这个命令不会触发持久化(AOF / RDB 不会记录它,因为它属于
调试命令)。
OK
(5.99s)
127.0.0.1:6379> save
OK
(5.07s)
再开个窗口
root@localhost \~# pstree -p | grep redis-server ; ll -h /var/lib/redis
|-redis-server(2104)-+-{redis-server}(2105)
| |-{redis-server}(2106)
| `-{redis-server}(2107)
total 64M
-rw-r--r-- 1 redis redis 92 Feb 21 17:59 dump.rdb
-rw-r--r-- 1 redis redis 51M Feb 21 17:59 temp-2104.rdb #主进程号2104
Bgsave:与 Save 命令不同,Bgsave 命令是一个异步操作。
异步保存数据到磁盘上
127.0.0.1:6379> bgsave
Background saving started
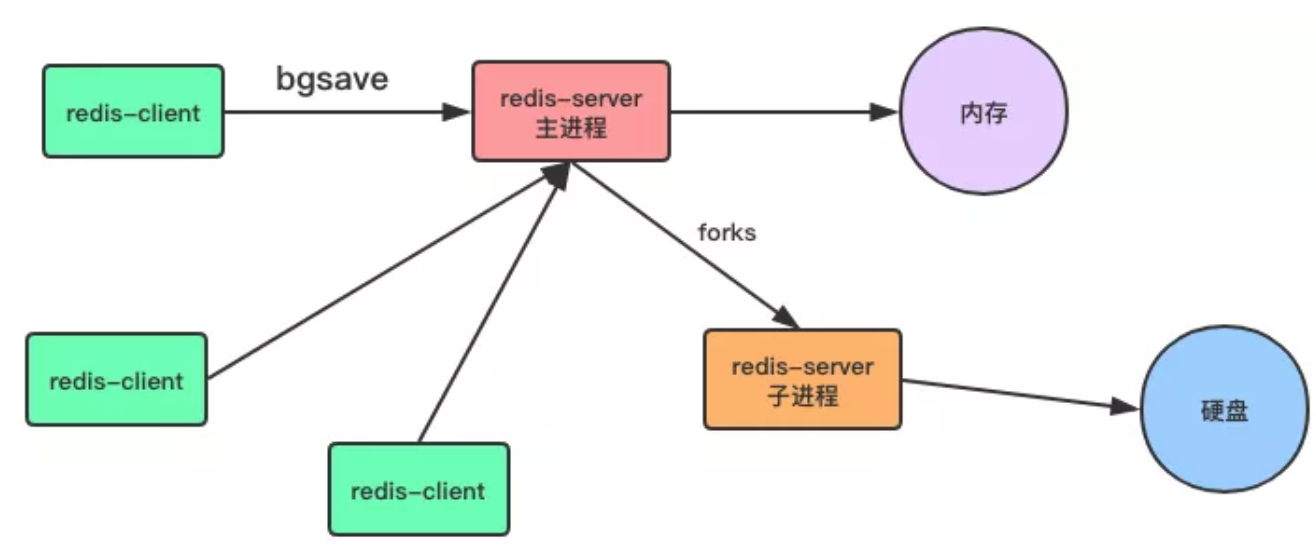
当客户端发服务发出 bgsave 命令时,Redis 服务器主进程会 Forks 一个子进程来数据同步问题,在将数据保存到 RDB 文件之后,子进程会退出。
所以,与 save 命令相比,Redis 服务器在处理 Bgsave 采用子线程进行 IO 写入。
而主进程仍然可以接收其他请求,但 Forks 子进程是同步的,所以 Forks 子进程时,一样不能接收其他请求。
这意味着,如果 Forks 一个子进程花费的时间太久(一般是很快的),Bgsave 命令仍然有阻塞其他客户的请求的情况发生
服务器配置自动触发:除了通过客户端发送命令外,还有一种方式,就是在 Redis 配置文件中的 Save 指
定到达触发 RDB 持久化的条件,比如【多少秒内至少达到多少写操作】就开启 RDB 数据同步。
例如我们可以在配置文件 redis.conf 指定如下的选项:
以下是默认值
root@localhost \~# vim /etc/redis.conf
218 save 900 1 # 900秒内修改了1个KEY即触发保存RDB
219 save 300 10 # 300秒内修改了10个KEY即触发保存RDB
220 save 60 10000 # 60秒内修改了10000个KEY即触发保存RDB
这种通过服务器配置文件触发 RDB 的方式,与 Bgsave 命令类似,达到触发条件时,会 Forks 一个子进程进行数据同步。
范例:手动执行备份RDB
root@localhost \~# redis-cli
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> debug populate 5000000
OK
(8.99s)
127.0.0.1:6379> get key:0
"value:0"
127.0.0.1:6379> get key:1
"value:1"
127.0.0.1:6379> get key:2
"value:2"
127.0.0.1:6379> get key:499999
"value:499999"
127.0.0.1:6379> get key:5000000
(nil)
127.0.0.1:6379> bgsave
Background saving started
#再开个窗口
root@localhost \~# pstree -p | grep redis-server ; ll -h /var/lib/redis
|-redis-server(2104)-+-redis-server(2266)
| |-{redis-server}(2105)
| |-{redis-server}(2106)
| `-{redis-server}(2107)
total 191M
-rw-r--r-- 1 redis redis 127M Feb 21 17:54 dump.rdb
-rw-r--r-- 1 redis redis 62M Feb 21 17:55 temp-2266.rdb #新开了个子进程
2266
RDB 文件
前面介绍了三种让服务器生成 RDB 文件的方式,无论是由主进程生成还是子进程来生成,其过程如下:
生成临时 RDB 文件,并写入数据。
完成数据写入,用临时文代替代正式 RDB 文件。
删除原来的 DB 文件。
RDB 默认生成的文件名为 dump.rdb,当然,我可以通过配置文件进行更加详细配置。
241 rdbcompression yes # 是否压缩rbd文件
253 dbfilename dump.rdb # rdb文件的名称
263 dir /var/lib/redis # rdb文件保存目录
RDB的几个优点:
- 与 AOF 方式相比,通过 RDB 文件恢复数据比较快。
- RDB 文件非常紧凑,适合于数据备份。
- 通过 RDB 进行数据备份,由于使用子进程生成,所以对 Redis 服务器性能影响较小。
RDB 的几个缺点:
- 如果服务器宕机的话,采用 RDB 的方式会造成某个时段内数据的丢失,比如我们设置 10 分钟同步一次或 5 分钟达到 1000 次写入就同步一次,那么如果还没达到触发条件服务器就死机了,那么这个时间段的数据会丢失。
- 使用 Save 命令会造成服务器阻塞,直接数据同步完成才能接收后续请求。
- 使用 Bgsave 命令在 Forks 子进程时,如果数据量太大,Forks 的过程也会发生阻塞,另外,Forks子进程会耗费内存。
AOF(Append-only file)
与 RDB 存储某个时刻的快照不同,AOF 持久化方式会记录客户端对服务器的每一次写操作命令,并将这些写操作以 Redis 协议追加保存到以后缀为 AOF 文件末尾。
在 Redis 服务器重启时,会加载并运行 AOF 文件的命令,以达到恢复数据的目的。
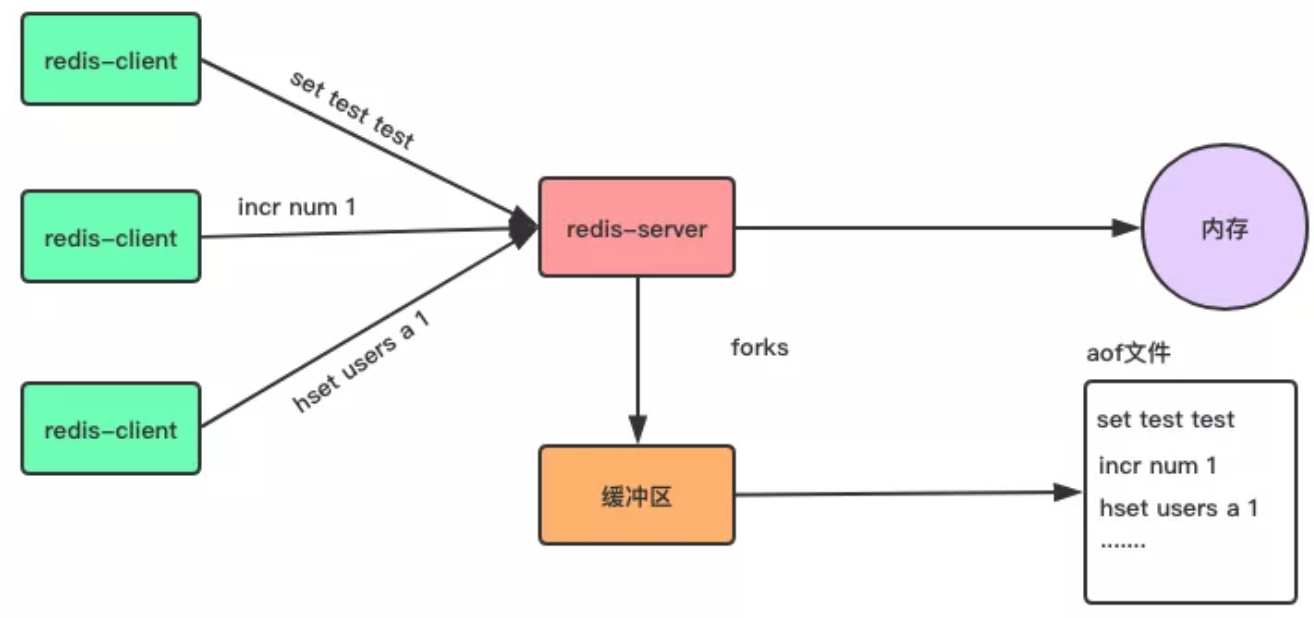
①开启 AOF 持久化方式
Redis 默认不开启 AOF 持久化方式,我们可以在配置文件中开启并进行更加详细的配置,如下面的
redis.conf 文件:
aof机制默认关闭
699 appendonly no
aof文件名
703 appendfilename "appendonly.aof"
写入策略,always表示每个写操作都保存到aof文件中,也可以是everysec或no
729 appendfsync everysec
默认不重写aof文件
751 no-appendfsync-on-rewrite no
保存目录
dir /var/lib/redis
错误开启AOF功能,会导致数据丢失
注意:AOF模式默认是关闭的,第一次开启AOF后,并重启服务生效后,会因为AOF的优先级高于RDB,而AOF默认没有数据文件存在,从而导致所有数据丢失
root@localhost \~# redis-cli
127.0.0.1:6379> dbsize
(integer) 5000000
root@localhost \~# vim /etc/redis.conf
699 appendonly yes #修改此行
root@localhost \~# systemctl restart redis
root@localhost \~# redis-cli
127.0.0.1:6379> dbsize
(integer) 0
正确启用AOF功能,防止数据丢失
root@localhost \~# ll /var/lib/redis/
total 4
-rw-r--r-- 1 redis redis 127M Feb 21 17:27 dump.rdb
root@localhost \~# redis-cli
127.0.0.1:6379> config get appendonly
"appendonly"
"no"
127.0.0.1:6379> config set appendonly yes #自动触发AOF重写,会自动备份所有数据
到AOF文件
OK
127.0.0.1:6379> config get appendonly
"appendonly"
"yes"
root@localhost \~# ll /var/lib/redis/
total 8
-rw-r--r-- 1 redis redis 127M Feb 21 17:29 appendonly.aof
-rw-r--r-- 1 redis redis 127M Feb 21 17:29 dump.rdb
root@localhost \~# vim /etc/redis.conf
699 appendonly yes #修改此行
验证
root@localhost \~# systemctl restart redis
root@localhost \~# redis-cli
127.0.0.1:6379> DBSIZE
(integer) 5000000
②三种写入策略
在上面的配置文件中,我们可以通过 appendfsync 选项指定写入策略,有三个选项:
appendfsync always
appendfsync everysec
appendfsync no
lways :客户端的每一个写操作都保存到 AOF 文件当中,这种策略很安全,但是每个写操作都有 IO 操作,所以也很慢。
everysec :appendfsync 的默认写入策略,每秒写入一次 AOF 文件,因此,最多可能会丢失 1s 的数据。
no:Redis 服务器不负责写入 AOF,而是交由操作系统来处理什么时候写入 AOF 文件。更快,但也是最不安全的选择,不推荐使用。
③AOF 文件重写
AOF重写是通过读取服务器当前的数据库状态来实现的。
假设我对redis执行了下面六条命令
rpush list "A"
rpush list "B"
rpush list "C"
rpush list "D"
rpush list "E"
rpush list "F"
那么服务器为了保存当前 list键 的状态,会在AOF文件中写入上述六条命令。
而我现在要对 AOF 进行重写的话,其实最高效最简单的方式不是挨个读取和分析现有AOF文件中的这六条命令。
而是直接从数据库中读取键 list 的值,然后用一条命令:rpush list "A" "B" "C" "D" "E" "F" ,可
以直接代替原 AOF 文件中的六条命令。
命令由六条减少为一条,重写的目的就达到了。
两种重写方式 :通过在 redis.conf 配置文件中的选项 no-appendfsync-on-rewrite 可以设置是否开启重写。
这种方式会在每次 Fsync 时都重写,影响服务器性能,因此默认值为 no,不推荐使用。
默认不重写aof文件
no-appendfsync-on-rewrite no
客户端向服务器发送 bgrewriteaof 命令,也可以让服务器进行 AOF 重写。
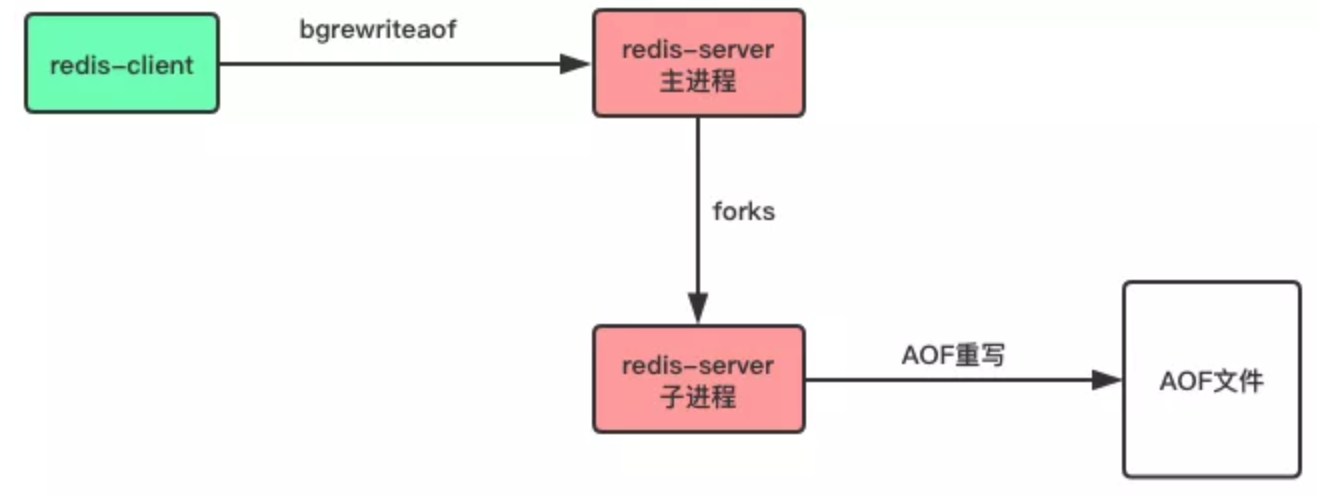
重写 AOF 文件的好处:
压缩 AOF 文件,减少磁盘占用量。
将 AOF 的命令压缩为最小命令集,加快了数据恢复的速度。
③AOF 文件损坏
在写入 AOF 日志文件时,如果 Redis 服务器宕机,则 AOF 日志文件文件会出格式错误。
在重启 Redis 服务器时,Redis 服务器会拒绝载入这个 AOF 文件,可以通过以下步骤修复 AOF 并恢复数据:
- 备份现在 AOF 文件,以防万一。
- 使用 redis-check-aof 命令修复 AOF 文件,该命令格式如下:
修复aof日志文件
root@localhost \~# redis-check-aof --fix /var/lib/redis/appendonly.aof
重启 Redis 服务器,加载已经修复的 AOF 文件,恢复数据。
AOF 的优点:
AOF 只是追加日志文件,因此对服务器性能影响较小,速度比 RDB 要快,消耗的内存较少。
AOF 的缺点:
AOF 方式生成的日志文件太大,即使通过 AFO 重写,文件体积仍然很大。
恢复数据的速度比 RDB 慢。
选择 RDB 还是 AOF 呢?
通过上面的介绍,我们了解了 RDB 与 AOF 各自的优点与缺点,到底要如何选择呢?
通过下面的表示,我们可以从几个方面对比一下 RDB 与 AOF,在应用时,要根据自己的实际需求,选择
RDB 或者 AOF。
其实,如果想要数据足够安全,可以两种方式都开启,但两种持久化方式同时进行 IO 操作,会严重影响服务器性能,因此有时候不得不做出选择。
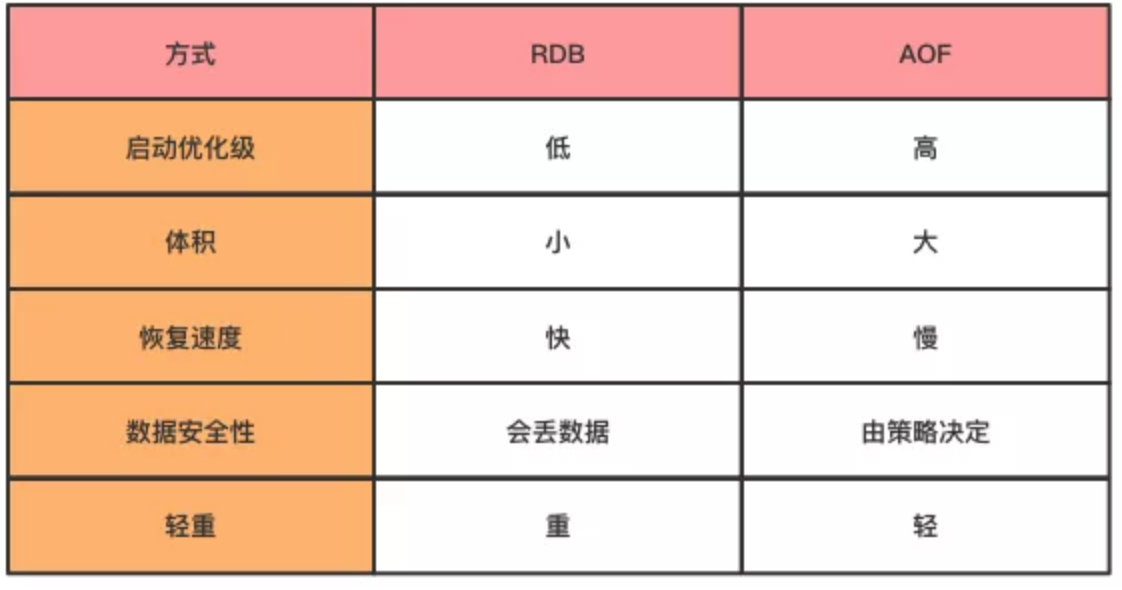
当 RDB 与 AOF 两种方式都开启时,Redis 会优先使用 AOF 日志来恢复数据,因为 AOF 保存的文件比
RDB 文件更完整。
小结:如果你只是单纯把 Redis 作为缓存服务器,那么可以完全不用考虑持久化。
但是,在如今的大多数服务器架构中,Redis 不单单只是扮演一个缓存服务器的角色,还可以作为数据库,保存我们的业务数据,此时,我们则需要好好了解有关 Redis 持久化策略的区别与选择。
客户端连接Redis
root@localhost \~# redis-cli
安装的相关程序介绍
root@localhost \~# ll /usr/bin/redis-*
-rwxr-xr-x 1 root root 656280 Oct 20 2021 redis-benchmark #性能测试程序
lrwxrwxrwx 1 root root 12 Oct 20 2021 redis-check-aof -> redis-server
#AOF文件检查程序
lrwxrwxrwx 1 root root 12 Oct 20 2021 redis-check-rdb -> redis-server
#RDB文件检查程序
-rwxr-xr-x 1 root root 827608 Oct 20 2021 redis-cli
#客户端程序
lrwxrwxrwx 1 root root 12 Oct 20 2021 redis-sentinel -> redis-server
#哨兵程序,软连接到服务器端主程序
-rwxr-xr-x 1 root root 1800864 Oct 20 2021 redis-server
#服务端主程序
客户端程序redis-cli
默认本机无密码连接
redis-cli
远程客户端连接,注意:Redis没有用户的概念
redis-cli -h <Redis服务器IP> -p <PORT> -a <PASSWORD> --no-auth-warning
Redis常用命令
**info #**显示当前节点redis运行状态信息
127.0.0.1:6379> INFO
Server
redis_version:5.0.3
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:9529b692c0384fb7
redis_mode:standalone
os:Linux 4.18.0-553.6.1.el8.x86_64 x86_64
arch_bits:64
......
只显示指定部分内容,INFO命是分段的
只显示INFO内容# Server这一段
127.0.0.1:6379> INFO Server
Server
redis_version:5.0.3
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:9529b692c0384fb7
redis_mode:standalone
os:Linux 4.18.0-553.6.1.el8.x86_64 x86_64
......
root@localhost \~# redis-cli info Cluster
Cluster
cluster_enabled:0
select
切换数据库,相当于MySQL的USE DBNAME指令
root@localhost \~# redis-cli
127.0.0.1:6379> info cluster
Cluster
cluster_enabled:0
127.0.0.1:6379> select 0
OK
127.0.0.1:6379> select 1
OK
127.0.0.1:63791> select 15
OK
127.0.0.1:637915> select 16
(error) ERR DB index is out of range
127.0.0.1:637915>
注意:在Redis cluster模式下不支持多个数据库
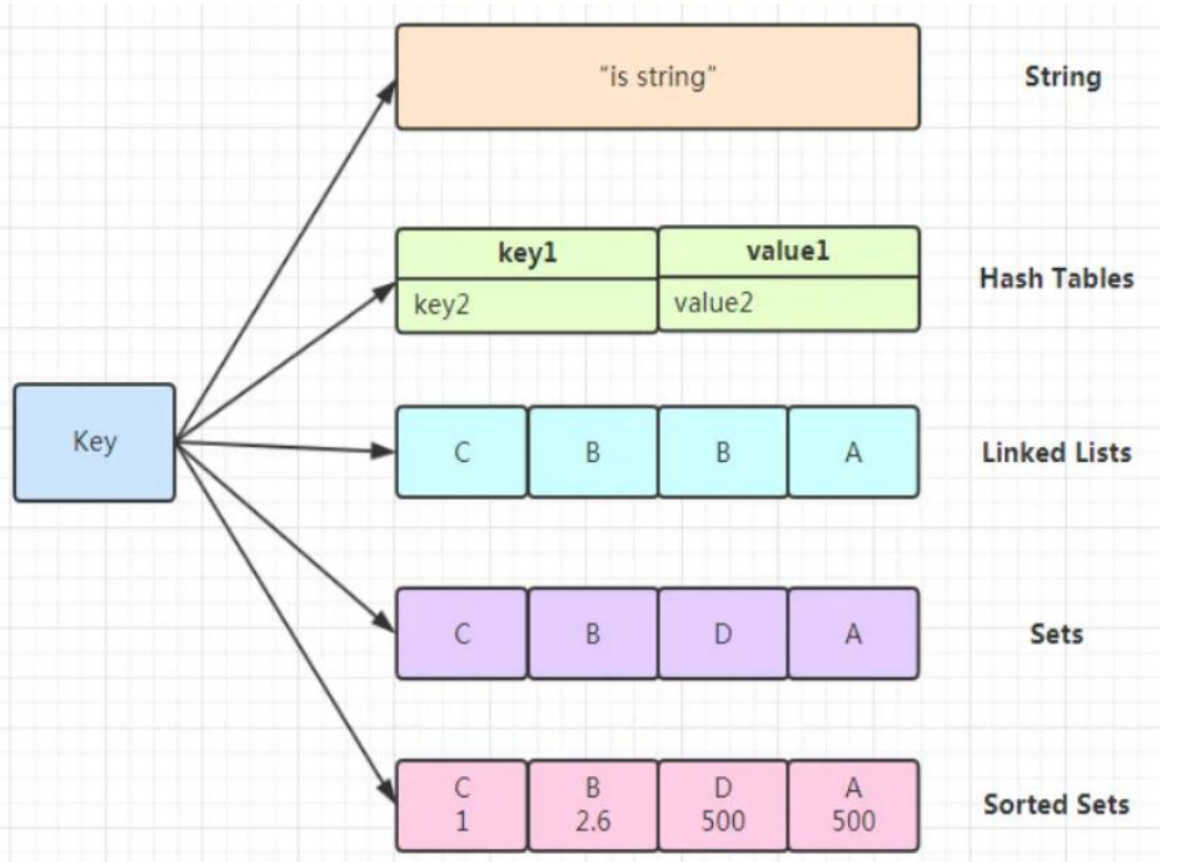
Redis数据类型
Redis是一个非关系型数据库(NoSQL),它是一种Key-Value型的NoSQL。Redis所有的key(键)都是字符串。对应的value(值)的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset(Sorted set)、Hash。
- string(字符串): 基本的数据存储单元,可以存储字符串、整数或者浮点数。
- hash(哈希):一个键值对集合,可以存储多个字段。
- list(列表):一个简单的列表,可以存储一系列的字符串元素。
- set(集合):一个无序集合,可以存储不重复的字符串元素。
- zset(sorted set:有序集合): 类似于集合,但是每个元素都有一个分数(score)与之关联。
字符串string
字符串是一种最基本的Redis值类型。Redis字符串是二进制安全的,这意味着一个Redis字符串能包含任意类型的数据,例如:一张JPEG格式的图片或者一个序列化的Ruby对象。一个字符串类型的值最多能存储512M字节的内容。Redis中所有key都是字符串类型的。此数据类型最为常用
|-------------------------------------------------------------|------------------------|
| 命令 | 说明 |
| SET key value EX seconds PX milliseconds NX\|XX | |
| GET key | 获取 key 的值 |
| SETEX key seconds value | 设置并指定过期时间(秒) |
| SETNX key value | 仅当 key 不存在时设置(用于分布 式锁) |
| INCR key | 将 key 中的数字加 1 |
| INCRBY key increment | 将 key 中的数字增加指定值 |
| DECR / DECRBY | 减操作 |
| MSET key1 value1 key2 value2 ... | 批量设置 |
| MGET key1 key2 ... | 批量获取 |
创建一个key
set指令可以创建一个key并赋值,使用格式
#不论key是否存在,都设置
127.0.0.1:6379> set key1 value1 #设置键key1,值value1
OK
127.0.0.1:6379> get key1 #查看键key1的值
"value1"
127.0.0.1:6379> type key1 #判断类型
string
127.0.0.1:6379> set title ceo ex 3 #设置自动过期时间3s
OK
127.0.0.1:6379> set name wang #设置键name,值wang
OK
127.0.0.1:6379> get name #查看键name的值
"wang"
127.0.0.1:6379> get title #3s后查看键title
(nil)
127.0.0.1:6379> get NAME #前面赋值的键是小写name,区分大小写
(nil)
127.0.0.1:6379> set NAME li #赋值大写NAME,li
OK
127.0.0.1:6379> get NAME #大写NAME对应li
"li"
127.0.0.1:6379> get name #小写name对应wang
"wang"
127.0.0.1:6379> setnx title coo #只有键title不存在值时,赋值coo
(integer) 1
127.0.0.1:6379> get title
"coo"
127.0.0.1:6379> setnx title ceo #只有键title不存在值时,赋值ceo
(integer) 0
127.0.0.1:6379> get title #由于键title存在值,未更新
"coo"
127.0.0.1:6379> set title ceo xx #只有键已经存在,才操作
OK
127.0.0.1:6379> get title
"ceo"
127.0.0.1:6379> get age
(nil)
127.0.0.1:6379> set age 20 xx #没有age这个键,不操作
(nil)
127.0.0.1:6379> get age
(nil)
查看一个key的值
127.0.0.1:6379> get key1
"value1"
get只能查看一个Key的值
127.0.0.1:6379> get name age
(error) ERR wrong number of arguments for 'get' command
删除key
127.0.0.1:6379> DEL key1
(integer) 1
127.0.0.1:6379> DEL key1 key2
(integer) 0
批量设置多个key
127.0.0.1:6379> MSET key1 value1 key2 vaule2
OK
批量获取多个key
127.0.0.1:6379> MGET key1 key2
"value1"
"vaule2"
127.0.0.1:6379> KEYS n*
- "name"
127.0.0.1:6379> KEYS *
"name"
"key1"
"NAME"
"title"
"key2"
追加key的数据
127.0.0.1:6379> APPEND key1 " append new value"
(integer) 22
127.0.0.1:6379> get key1
"value1 append new value"
设置新值并返回旧值
127.0.0.1:6379> set name wang
OK
127.0.0.1:6379> getset name xiyangyang
"wang"
127.0.0.1:6379> get name
"xiyangyang
返回字符串key对应值的字节数
127.0.0.1:6379> set name wang
OK
127.0.0.1:6379> STRLEN name #返回字节数
(integer) 4
127.0.0.1:6379> APPEND name " teng"
(integer) 9
127.0.0.1:6379> get name
"wang teng"
127.0.0.1:6379> STRLEN name
(integer) 9
判断key是否存在
127.0.0.1:6379> set name wang ex 10
OK
127.0.0.1:6379> EXISTS name #10秒内
(integer) 1
127.0.0.1:6379> EXISTS name age #10秒内
(integer) 2 #返回值为2,表示存在2个key,0表示不存在
127.0.0.1:6379> EXISTS name #10秒后
(integer) 0
获取key的过期时长
ttl key 查看key的剩余生存时间,如果key过期后,会自动删除
-1 返回值表示永不过期,默认创建的key是永不过期,重新对key赋值,也会从有剩余生命周期变成永不过期
-2 返回值表示没有此key
num key的剩余有效期
127.0.0.1:6379> ttl key
(integer) -2
127.0.0.1:6379> TTL key1
(integer) -1
127.0.0.1:6379> set name wang EX 100
OK
127.0.0.1:6379> TTL name
(integer) 97
127.0.0.1:6379> TTL name
(integer) 92
127.0.0.1:6379> SET name li #重新设置,默认永不过期
OK
127.0.0.1:6379> TTL name
(integer) -1
127.0.0.1:6379> SET name wang EX 200
OK
127.0.0.1:6379> TTL name
(integer) 198
127.0.0.1:6379> get name
"wang"
重置key的过期时长
127.0.0.1:6379> TTL name
(integer) 97
127.0.0.1:6379> EXPIRE name 1000
(integer) 1
127.0.0.1:6379> TTL name
(integer) 996
取消key的过期时长
127.0.0.1:6379> TTL name
(integer) 957
127.0.0.1:6379> PERSIST name
(integer) 1
127.0.0.1:6379> TTL name
(integer) -1
数字递增
利用INCR命令簇(INCR,DECR,INCRBY,DECRBY)来把字符串当作原子计数器使用。
INCR key 将 key 中的数字加 1
INCRBY key increment 将 key 中的数字增加指定值
127.0.0.1:6379> set num 10
OK
127.0.0.1:6379> INCR num
(integer) 11
127.0.0.1:6379> get num
"11"
127.0.0.1:6379> INCR num
(integer) 12
127.0.0.1:6379> get num
"12"
数字递减
127.0.0.1:6379> set num 10
OK
127.0.0.1:6379> DECR num
(integer) 9
127.0.0.1:6379> get num
"9"
数字增加
将key对应的数字加decrement(可以是负数)。如果key不存在,操作之前,key就会被置为0。如果key的value类型错误或者是个不能表示成数字的字符串,就返回错误。这个操作最多支持64位有符号的正型数字。
127.0.0.1:6379> SET mykey 10
OK
127.0.0.1:6379> INCRBY mykey 5
(integer) 15
127.0.0.1:6379> get mykey
"15"
127.0.0.1:6379> INCRBY mykey -10
(integer) 5
127.0.0.1:6379> get mykey
"5"
127.0.0.1:6379> INCRBY nokey1 5
(integer) 5
127.0.0.1:6379> get nokey1
"5"
数字减少
decrby可以减小数值(也可以增加)
127.0.0.1:6379> SET mykey 10
OK
127.0.0.1:6379> DECRBY mykey 8
(integer) 2
127.0.0.1:6379> get mykey
"2"
127.0.0.1:6379> DECRBY mykey -20
(integer) 22
27.0.0.1:6379> get mykey"22"
127.0.0.1:6379> DECRBY nokey2 3
(integer) -3
127.0.0.1:6379> get nokey2
"-3"
127.0.0.1:6379> get name
"wang"
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
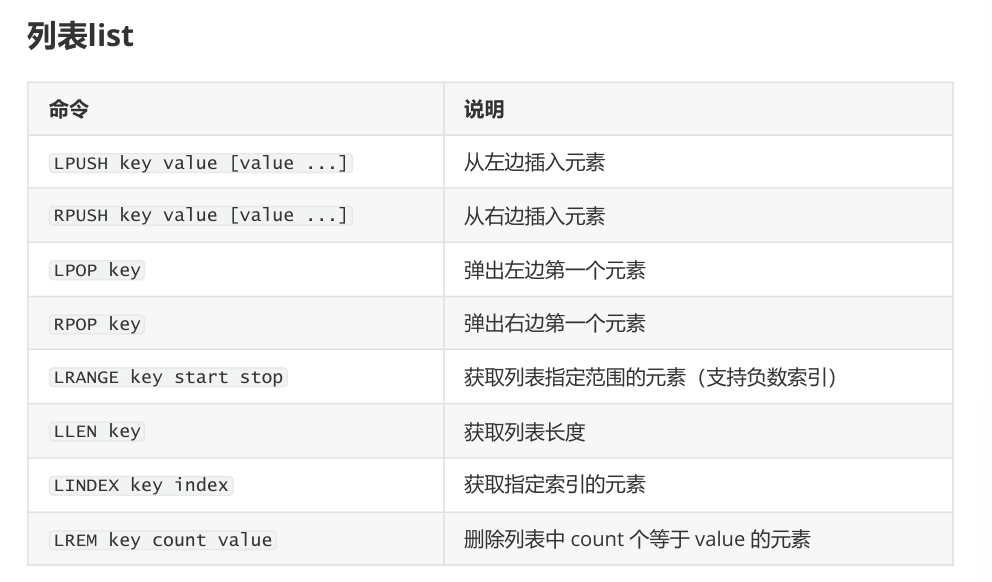

Redis列表实际就是简单的字符串数组,按照插入顺序进行排序
支持双向读写,可以添加一个元素到列表的头部(左边)或者尾部(右边),一个列表最多可以包含2^32-1=4294967295个元素
每个列表元素用下标来标识,下标0表示列表的第一个元素,以1表示列表的第二个元素,以此类推。
也可以使用负数下标,以-1表示列表的最后一个元素,-2表示列表的倒数第二个元素,元素值可以重复,常用于存入日志等场景,此数据类型比较常用
列表特点
- 有序
- 可重复
- 左右都可以操作
创建列表和数据
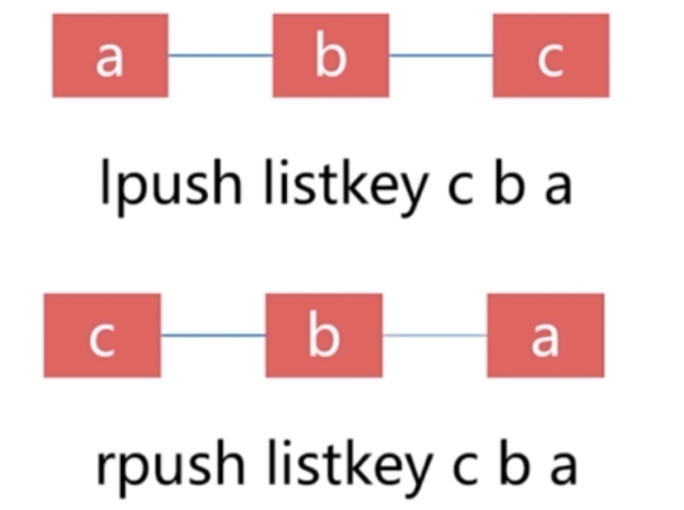
从左边添加数据,已添加的需向右移
127.0.0.1:6379> LPUSH phone xiaomi apple huawei
(integer) 3
127.0.0.1:6379> TYPE phone
list
127.0.0.1:6379> RPUSH id 18 19 20
(integer) 3
127.0.0.1:6379> type id
list
列表追加新数据
127.0.0.1:6379> LPUSH list1 tom
(integer) 1
从右边添加数据,已添加的向左移
127.0.0.1:6379> RPUSH list1 jack
(integer) 2
获取列表长度
127.0.0.1:6379> LLEN list1
(integer) 2
获取列表指定位置元素数据
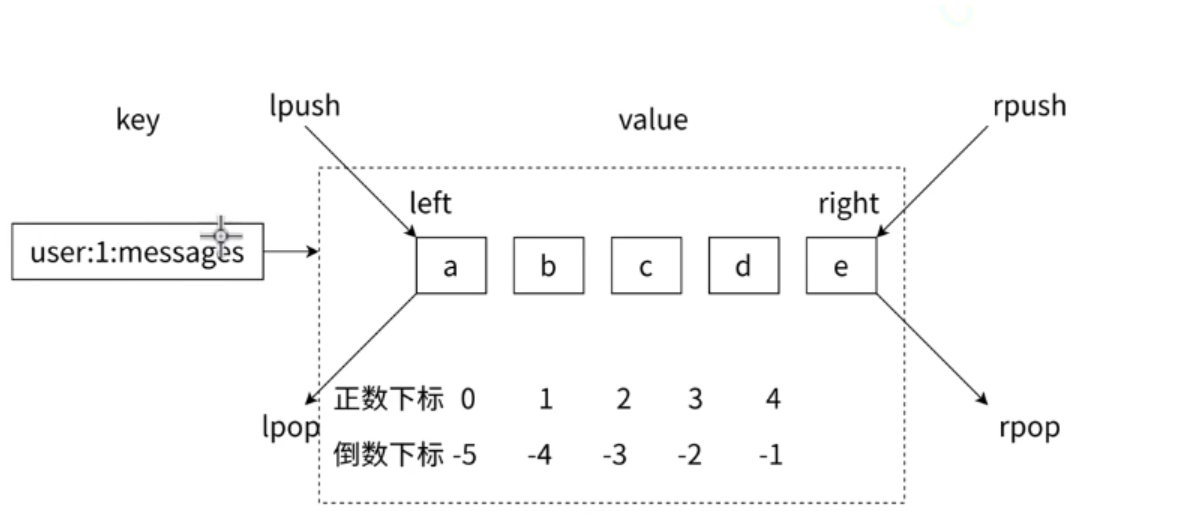
127.0.0.1:6379> LPUSH list2 a b c d
(integer) 4
127.0.0.1:6379> LINDEX list2 0 #获取0编号的元素
"d"
127.0.0.1:6379> LINDEX list2 3 #获取最后一个的元素
"a"
127.0.0.1:6379> LRANGE list2 1 2
"c"
"b"
127.0.0.1:6379> LRANGE list2 0 3
"d"
"c"
"b"
"a"
127.0.0.1:6379> LRANGE list2 0 -1
"d"
"c"
"b"
"a"
127.0.0.1:6379> RPUSH list3 a b c d e
(integer) 5
127.0.0.1:6379> LINDEX list3 0
"a"
127.0.0.1:6379> LRANGE list3 0 -1
"a"
"b"
"c"
"d"
"e"
修改列表指定索引值
127.0.0.1:6379> RPUSH list4 a b c d e f
(integer) 6
127.0.0.1:6379> LRANGE list4 0 -1
"a"
"b"
"c"
"d"
"e"
"f"
127.0.0.1:6379> lset list4 2 cloud
OK
127.0.0.1:6379> LRANGE list4 0 -1
"a"
"b"
"cloud"
"d"
"e"
"f"
删除列表数据
127.0.0.1:6379> LPUSH list5 a b c d
(integer) 4
127.0.0.1:6379> lrange list5 0 3
"d"
"c"
"b"
"a"
127.0.0.1:6379> lpop list5 #弹出左边第一个元素,即删除第一个
"d"
127.0.0.1:6379> lrange list5 0 3
"c"
"b"
"a"
127.0.0.1:6379> RPOP list5 #弹出右边第一个元素,即删除最后一个
"a"
127.0.0.1:6379> lrange list5 0 3
"c"
"b"
#LTRIM对一个列表进行修剪(trim),让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删
127.0.0.1:6379> RPUSH list6 a b c d e
(integer) 5
127.0.0.1:6379> lrange list6 0 -1
"a"
"b"
"c"
"d"
"e"
127.0.0.1:6379> LTRIM list6 2 3
OK
127.0.0.1:6379> lrange list6 0 -1
"c"
"d"
删除list
127.0.0.1:6379> DEL list1
(integer) 1
127.0.0.1:6379> EXISTS list1
(integer) 0
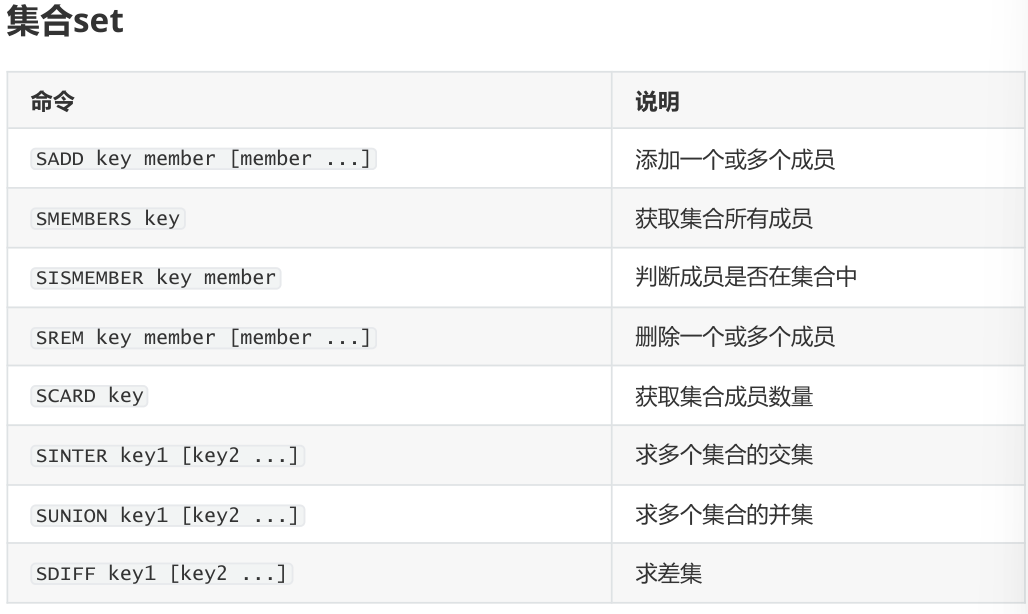
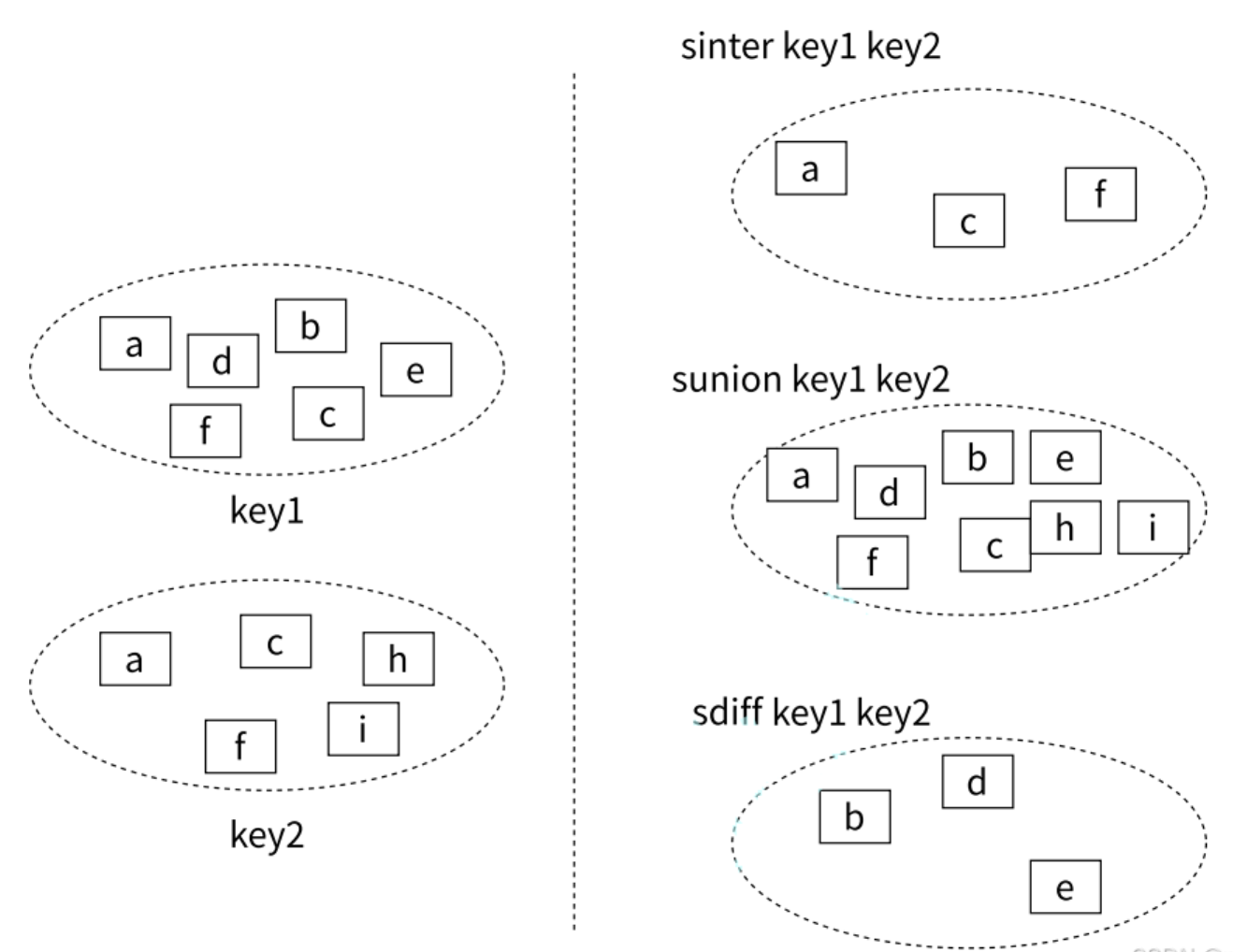
Set是一个无序的字符串合集
同一个集合中的每个元素是唯一无重复的
支持在两个不同的集合中对数据进行逻辑处理,常用于取交集,并集,统计等场景,例如:实现共同的朋友
集合特点
- 无序
- 无重复
- 集合间操作
创建集合
127.0.0.1:6379> SADD set1 v1
(integer) 1
127.0.0.1:6379> SADD set2 v2 v4
(integer) 2
127.0.0.1:6379> TYPE set1
set
127.0.0.1:6379> TYPE set2
set
集合中追加数据
追加时,只能追加不存在的数据,不能追加已经存在的数值
127.0.0.1:6379> SADD set1 v2 v3 v4
(integer) 3
127.0.0.1:6379> SADD set1 v2 #已存在的value,无法再添加
(integer) 0



实现排名
127.0.0.1:6379> ZADD course 90 linux 99 go 60 python 50 cloud
(integer) 4
127.0.0.1:6379> ZRANGE course 0 -1 #正序排序后显示集合内所有的key,按score从小到大显示
"cloud"
"python"
"linux"
"go"
127.0.0.1:6379> ZREVRANGE course 0 -1 #倒序排序后显示集合内所有的key,score从大到
小显示
"go"
"linux"
"python"
"cloud"
127.0.0.1:6379> ZRANGE course 0 -1 WITHSCORES #正序显示指定集合内所有key和得分
情况
"cloud"
"50"
"python"
"60"
"linux"
"90"
"go"
"99"
127.0.0.1:6379> ZREVRANGE course 0 -1 WITHSCORES #倒序显示指定集合内所有key和得分
情况
"go"
"99"
"linux"
"90"
"python"
"60"
"cloud"
"50"
查看集合的成员个数
127.0.0.1:6379> ZCARD course
(integer) 4
127.0.0.1:6379> ZCARD zset1
(integer) 4
127.0.0.1:6379> ZCARD zset2
(integer) 5
基于索引查找数据
127.0.0.1:6379> ZRANGE course 0 2
"cloud"
"python"
"linux"
127.0.0.1:6379> ZRANGE course 0 10 #超出范围不报错
"cloud"
"python"
"linux"
"go"
127.0.0.1:6379> ZRANGE zset1 1 3
"v2"
"v3"
"v4"
127.0.0.1:6379> ZRANGE zset1 0 2
"v1"
"v2"
"v3"
127.0.0.1:6379> ZRANGE zset1 2 2
- "v3"
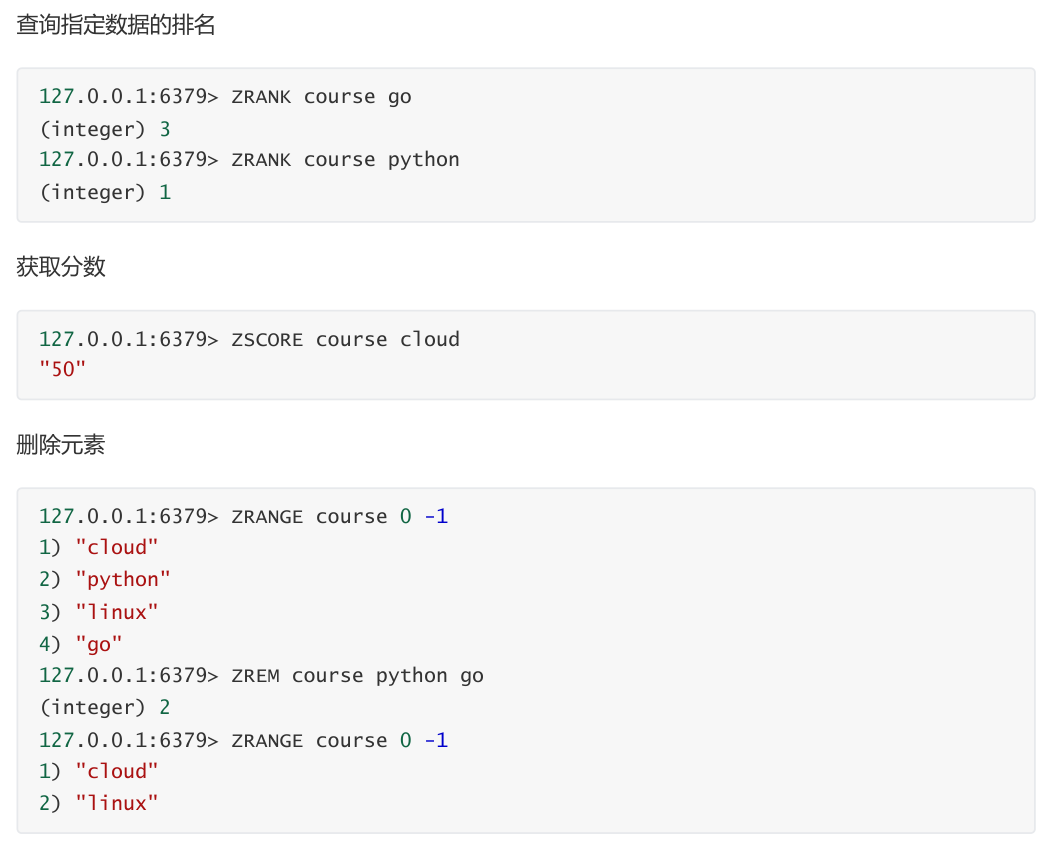
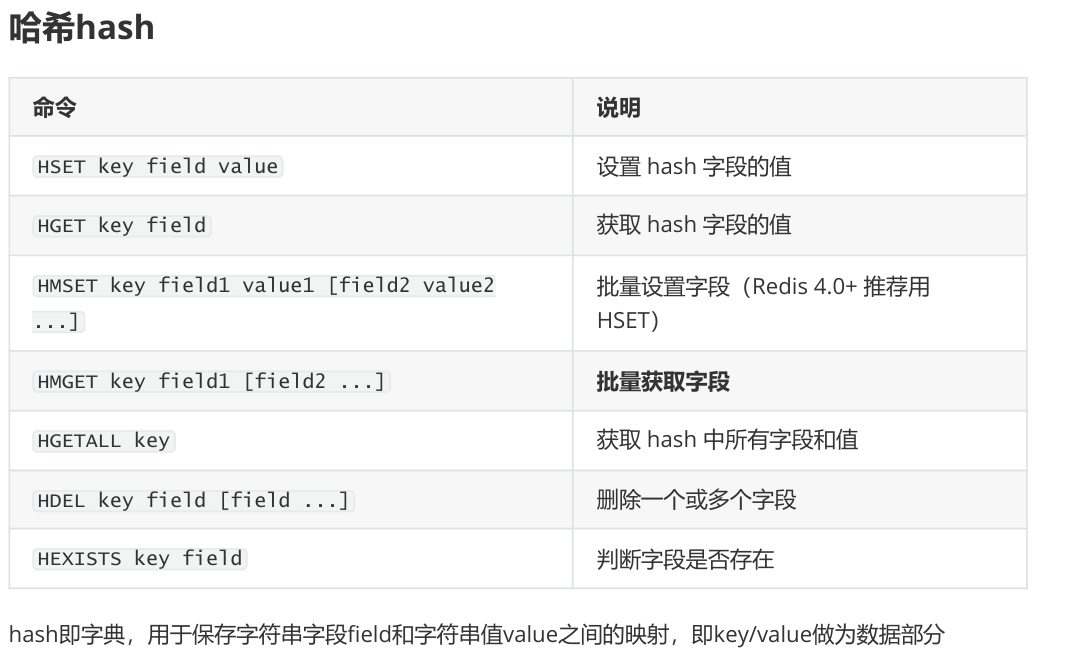
创建hash

批量设置hash key的多个field和value

删除hash
127.0.0.1:6379> DEL 9527
(integer) 1
127.0.0.1:6379> EXISTS 9527
(integer) 0
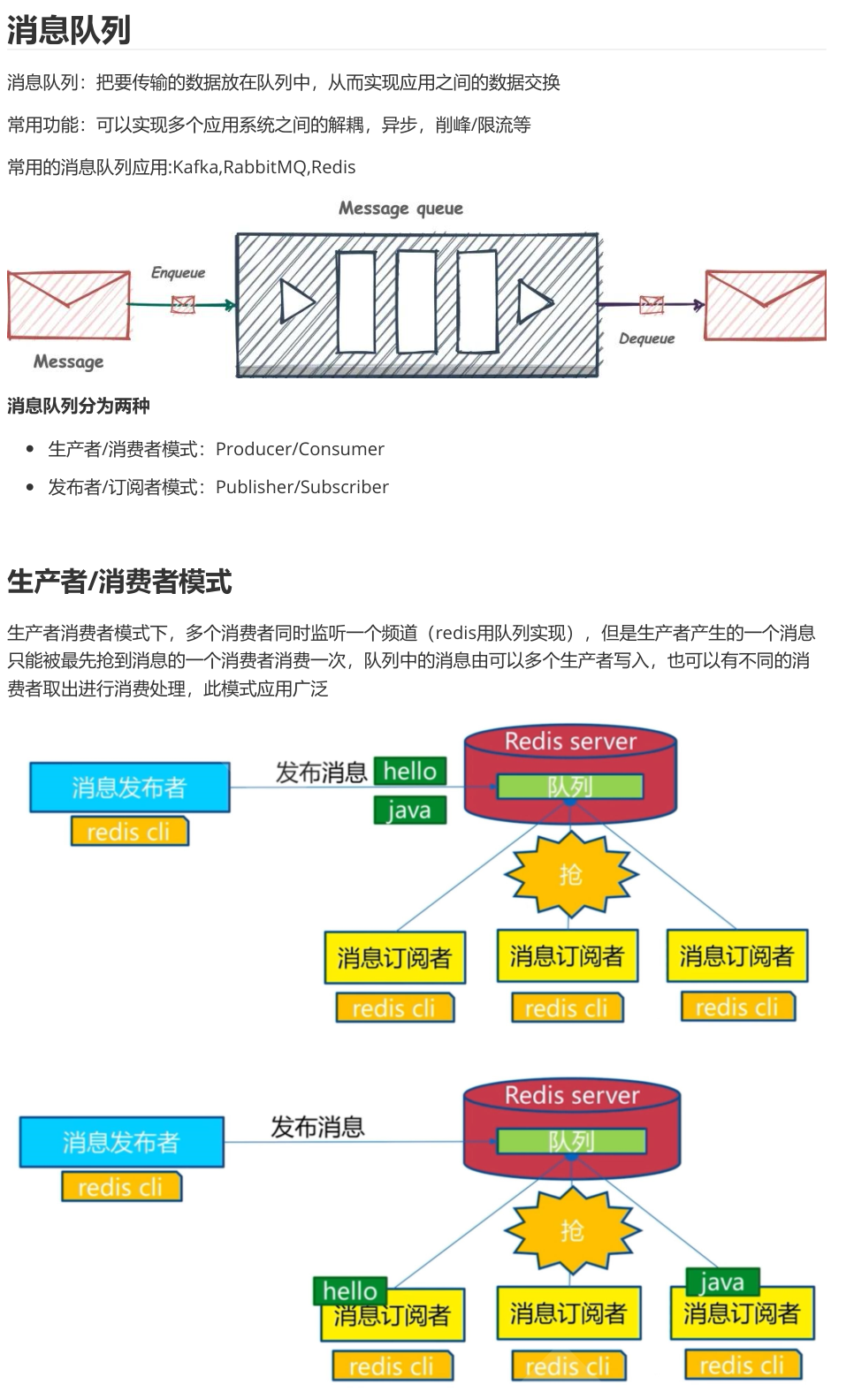
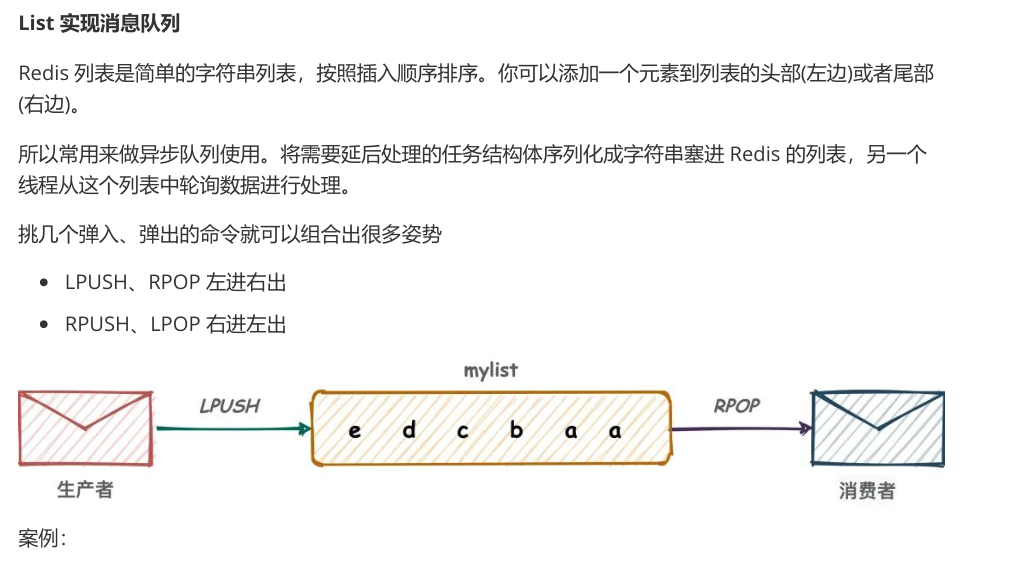
案例:
生产者生成消息
root@localhost \~# redis-cli
127.0.0.1:6379> LPUSH haizeiwang jishu1
(integer) 1
127.0.0.1:6379> LPUSH haizeiwang jishu2
(integer) 2
127.0.0.1:6379> LPUSH haizeiwang jishu3
(integer) 3
127.0.0.1:6379> LPUSH haizeiwang jishu4
(integer) 4
127.0.0.1:6379> LPUSH haizeiwang jishu5
(integer) 5
获取所有消息
127.0.0.1:6379> LRANGE haizeiwang 0 -1
"jishu5"
"jishu4"
"jishu3"
"jishu2"
"jishu1"
消费者消费消息
127.0.0.1:6379> RPOP haizeiwang #基于实现消息队列的先进先出原则,从管道的右侧
消费
"jishu1"
127.0.0.1:6379> RPOP haizeiwang
"jishu2"
127.0.0.1:6379> RPOP haizeiwang
"jishu3"
127.0.0.1:6379> RPOP haizeiwang
"jishu4"
127.0.0.1:6379> RPOP haizeiwang
"jishu5"
127.0.0.1:6379> RPOP haizeiwang
(nil)
验证队列消息消费全部消费完成
127.0.0.1:6379> LRANGE haizeiwang 0 -1
(empty list or set)
即时消费问题
通过 LPUSH,RPOP 这样的方式,会存在一个性能风险点,就是消费者如果想要及时的处理数据,就要在程序中写个类似 while(true) 这样的逻辑,不停的去调用 RPOP 或 LPOP 命令,这就会给消费者程序带来些不必要的性能损失。
所以,Redis 还提供了 BLPOP、BRPOP 这种阻塞式读取的命令(带 B-Bloking的都是阻塞式),客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。这种方式就节省了不必要的 CPU 开销。
- LPUSH、BRPOP 左进右阻塞出
- RPUSH、BLPOP 右进左阻塞出
生产者生成消息
127.0.0.1:6379> LPUSH haizeiwang jishu1 jishu2 jishu3 jishu4 jishu5
(integer) 5
获取所有消息
127.0.0.1:6379> LRANGE haizeiwang 0 -1
"jishu5"
"jishu4"
"jishu3"
"jishu2"
"jishu1"
消费者消费消息
127.0.0.1:6379> BRPOP haizeiwang 10
"haizeiwang"
"jishu1"
127.0.0.1:6379> BRPOP haizeiwang 10
"haizeiwang"
"jishu2"
127.0.0.1:6379> BRPOP haizeiwang 10
"haizeiwang"
"jishu3"
127.0.0.1:6379> BRPOP haizeiwang 10
"haizeiwang"
"jishu4"
127.0.0.1:6379> BRPOP haizeiwang 10
"haizeiwang"
"jishu5"
消费的时候已经没有消息了,10秒内再开一个窗口使用命令LPUSH haizeiwang jishu6产生新消息
127.0.0.1:6379> BRPOP haizeiwang 10 #如果将超时时间设置为 0 时,即可无限等待,直
到弹出消息
"haizeiwang"
"jishu6"
(2.73s)
127.0.0.1:6379>
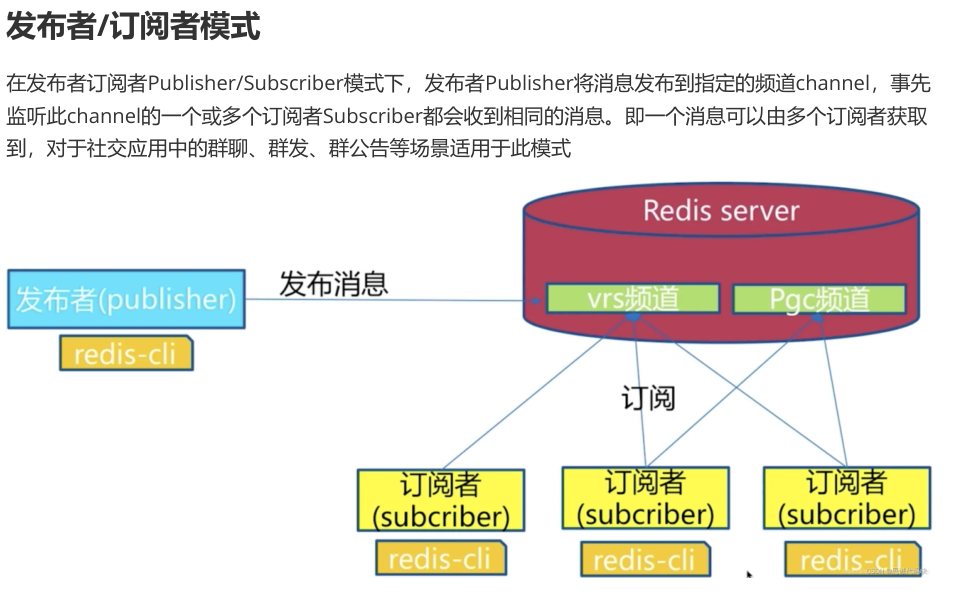
案例:
订阅者订阅频道
#窗口A:
root@localhost \~# redis-cli
127.0.0.1:6379> SUBSCRIBE douluodalu #订阅者事先订阅指定的频道,之后
发布的消息才能收到
Reading messages... (press Ctrl-C to quit)
"subscribe"
"douluodalu"
(integer) 1
#窗口B:
127.0.0.1:6379> SUBSCRIBE douluodalu haizeiwang #订阅多个频道
Reading messages... (press Ctrl-C to quit)
"subscribe"
"douluodalu"
(integer) 1
"subscribe"
"haizeiwang"
(integer) 2
"message"
"douluodalu"
"fuhuoba,wodeairen"
发布者发布消息
#窗口C:
127.0.0.1:6379> PUBLISH douluodalu fuhuoba,wodeairen
(integer) 2 #订阅者个数2个
127.0.0.1:6379> PUBLISH haizeiwang 5danglufei
(integer) 1
各个订阅者都能收到消息
#窗口A:
root@localhost \~# redis-cli
127.0.0.1:6379> SUBSCRIBE douluodalu
Reading messages... (press Ctrl-C to quit)
"subscribe"
"douluodalu"
(integer) 1
"message"
"douluodalu"
"fuhuoba,wodeairen"
#窗口B
root@localhost \~# redis-cli
127.0.0.1:6379> SUBSCRIBE douluodalu haizeiwang
Reading messages... (press Ctrl-C to quit)
"subscribe"
"douluodalu"
(integer) 1
"subscribe"
"haizeiwang"
(integer) 2
"message"
"douluodalu"
"fuhuoba,wodeairen"
"message"
"haizeiwang"
"5danglufei"
订阅所有频道
127.0.0.1:6379> PSUBSCRIBE *
订阅匹配的频道
127.0.0.1:6379> PSUBSCRIBE douluo*



从主节点写入数据,数据会被同步到从节点
master节点配置
127.0.0.1:6379> set name laogao
OK
salve01,slave02查看同步过来了
127.0.0.1:6379> get name
"laoxxx"
删除主从同步:
在从节点执行REPLICAOF NO ONE 或 SLAVEOF NO ONE指令可以取消主从复制
取消复制会断开和master的连接而不再有组从复制关联,但不会清除slave上已有的数据
新版
127.0.0.1:6379> REPLICAOF NO ONE
旧版
127.0.0.1:6379> SLAVEOF NO ONE


总结:哨兵模式是 Redis 实现 自动高可用 的标准方案,适用于对可用性要求高、但无需数据分片的业务场景。对于超大规模集群,应考虑 Redis Cluster。



配置
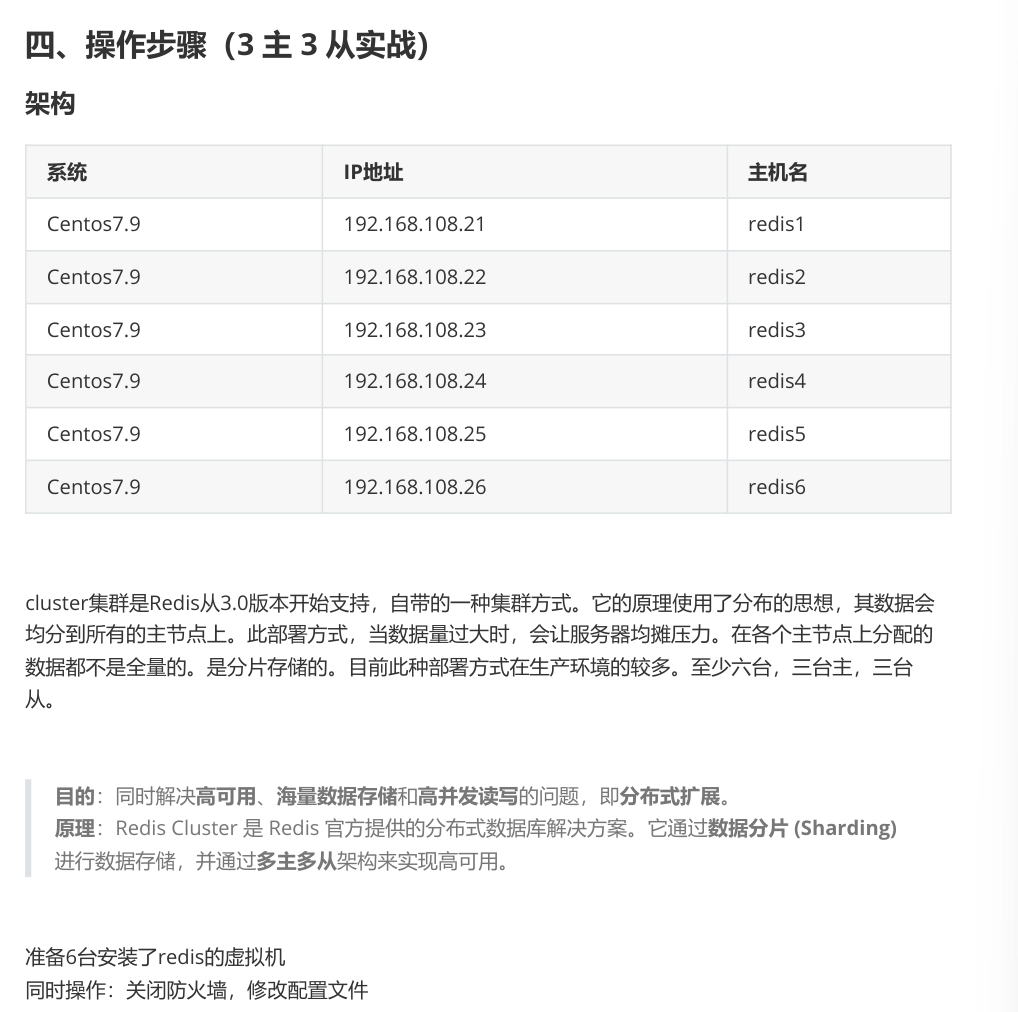
所有主机操作
#安装依赖包
root@localhost \~# yum install tcl gcc gcc-c++ -y
#解压redis安装包
root@localhost \~# tar zxvf redis-6.2.14.tar.gz -C /usr/local/
#编译安装
root@localhost \~# cd /usr/local/redis-6.2.14/
root@localhost redis-6.2.14# make && make install
#修改配置文件
root@redis1 \~# cd /usr/local/redis-6.2.14/
root@localhost redis-6.2.14# vim redis.conf
#监听地址
75 bind 0.0.0.0 -::1
#启动cluster集群
1387 cluster-enabled yes
#启动Redis
root@localhost redis-6.2.14# redis-server redis.conf &
#查看启动端口
root@redis1 redis-6.2.14# netstat -anpt | grep redis
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN
55036/redis-server
tcp 0 0 0.0.0.0:16379 0.0.0.0:* LISTEN
55036/redis-server
tcp6 0 0 ::1:6379 :::* LISTEN
55036/redis-server
tcp6 0 0 ::1:16379 :::* LISTEN
55036/redis-server
任意一台即可
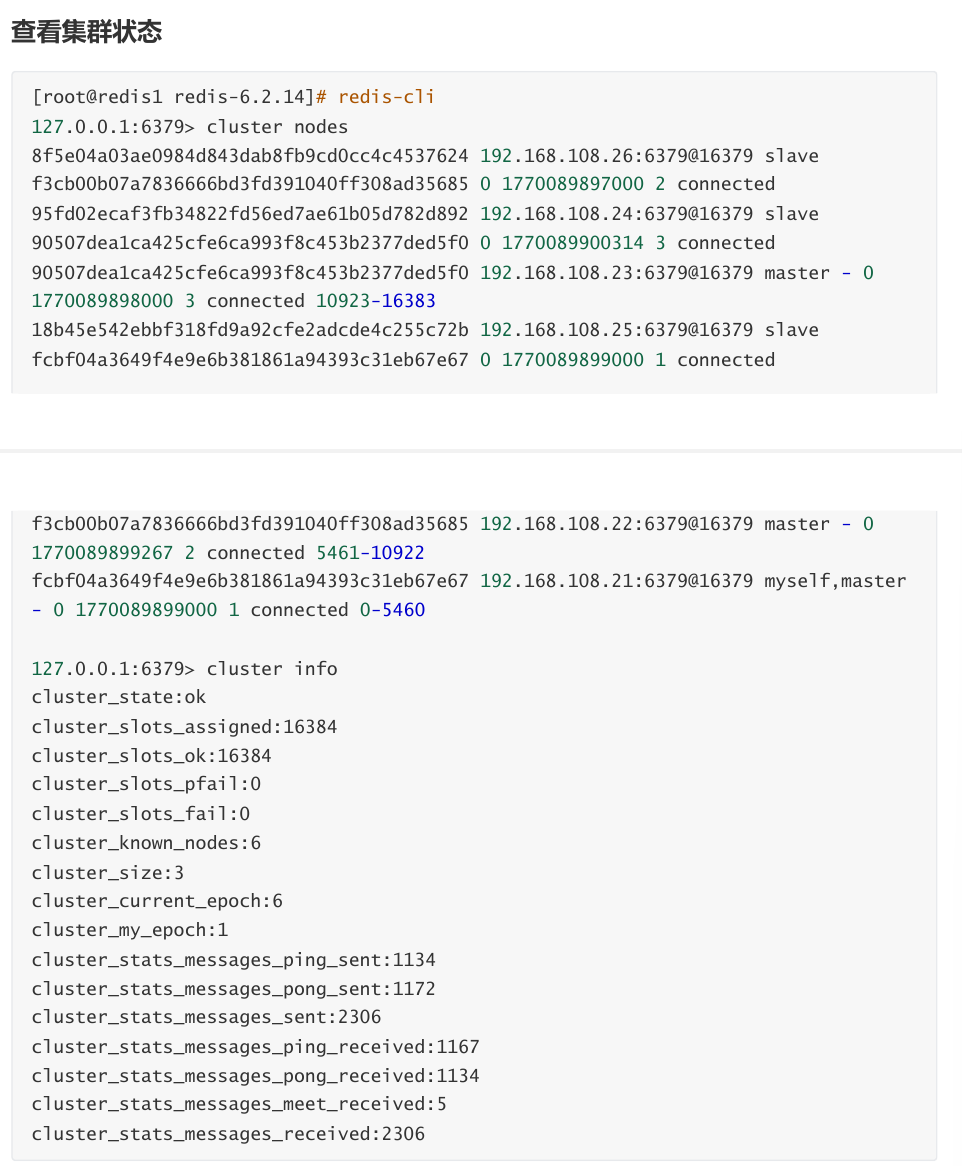
root@redis1 redis-6.2.14# redis-cli --cluster create 192.168.108.21:6379
192.168.108.22:6379 192.168.108.23:6379 192.168.108.24:6379 192.168.108.25:6379
192.168.108.26:6379 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master0 -> Slots 0 - 5460
Master1 -> Slots 5461 - 10922
Master2 -> Slots 10923 - 16383
Adding replica 192.168.108.25:6379 to 192.168.108.21:6379
Adding replica 192.168.108.26:6379 to 192.168.108.22:6379
Adding replica 192.168.108.24:6379 to 192.168.108.23:6379
M: fcbf04a3649f4e9e6b381861a94393c31eb67e67 192.168.108.21:6379
slots:0-5460 (5461 slots) master #0-5460是负责槽位0-5064,
(5461 slots) 是共5461个槽位
M: f3cb00b07a7836666bd3fd391040ff308ad35685 192.168.108.22:6379
slots:5461-10922 (5462 slots) master
M: 90507dea1ca425cfe6ca993f8c453b2377ded5f0 192.168.108.23:6379
slots:10923-16383 (5461 slots) master
S: 95fd02ecaf3fb34822fd56ed7ae61b05d782d892 192.168.108.24:6379
replicates 90507dea1ca425cfe6ca993f8c453b2377ded5f0
S: 18b45e542ebbf318fd9a92cfe2adcde4c255c72b 192.168.108.25:6379
replicates fcbf04a3649f4e9e6b381861a94393c31eb67e67
S: 8f5e04a03ae0984d843dab8fb9cd0cc4c4537624 192.168.108.26:6379
replicates f3cb00b07a7836666bd3fd391040ff308ad35685
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
55036:M 03 Feb 2026 11:35:48.414 # configEpoch set to 1 via CLUSTER SET-CONFIG-
EPOCH
>>> Sending CLUSTER MEET messages to join the cluster
55036:M 03 Feb 2026 11:35:48.445 # IP address for this node updated to
192.168.108.21
Waiting for the cluster to join
55036:M 03 Feb 2026 11:35:49.510 * Replica 192.168.108.25:6379 asks for
synchronization
......
root@redis1 redis-6.2.14# 55036:M 03 Feb 2026 11:35:53.476 # Cluster state
changed: ok