一、引言
玩过Linux服务器部署的都知道,这事特别熬人、格外劳心,尤其是碰上特定定制版本的Linux系统,各种环境兼容、配置坑点层出不穷,稍有不慎就卡死报错,出于习惯,每次部署一个环境,都是边部署边记录,好溯源产生问题的原因,避免总是在快完工时又推导重来;
今天就实打实分析一下完整记录全新Dell物理服务器,从硬件信息核查、多网卡网络配置,到Python源码编译搭建独立环境、各类依赖库逐层安装;再到大模型运行依赖补全、FastAPI接口服务部署、防火墙端口放行,最后解决库版本兼容适配的从零到一全落地流程。
全程基于openEuler系统实操整理,手到擒来,没有基础也能跟着一步步完成大模型本地部署和接口服务上线,同时把部署途中遇到的各类典型报错、踩坑细节和标准化解决方案都做了汇总,拿来就能直接复用,省去自己反复试错折腾的时间。

二、服务器基础信息核查
1. 系统及硬件基础信息查看
服务器上架后首先核查系统版本、硬件型号、内核架构,为后续环境适配提供依据,执行命令:
bash
hostnamectl输出显示:
Static hostname: n/a
Transient hostname: localhost
Icon name: computer-server
Chassis: server
Machine ID: 5881b658f8b64de6870f891347165aa1
Boot ID: 359007c379cb43039e129f6d3c7331fc
Operating System: openEuler 22.03 (LTS-SP4)
Kernel: Linux 5.10.0-216.0.0.115.oe2203sp4.x86_64
Architecture: x86-64
Hardware Vendor: Dell Inc.
Hardware Model: PowerEdge R740
关键信息解读:
- 操作系统:openEuler 22.03 (LTS-SP4)
- 系统内核:Linux 5.10.0-216.0.0.115.oe2203sp4.x86_64
- 架构:x86-64
- 硬件厂商:Dell Inc.
- 服务器型号:PowerEdge R740
2. CPU资源详细信息查看
通过lscpu命令查看CPU核心、型号、NUMA 节点、缓存及虚拟化支持,为编译、大模型推理算力评估提供参考:
bash
lscpu输出显示:
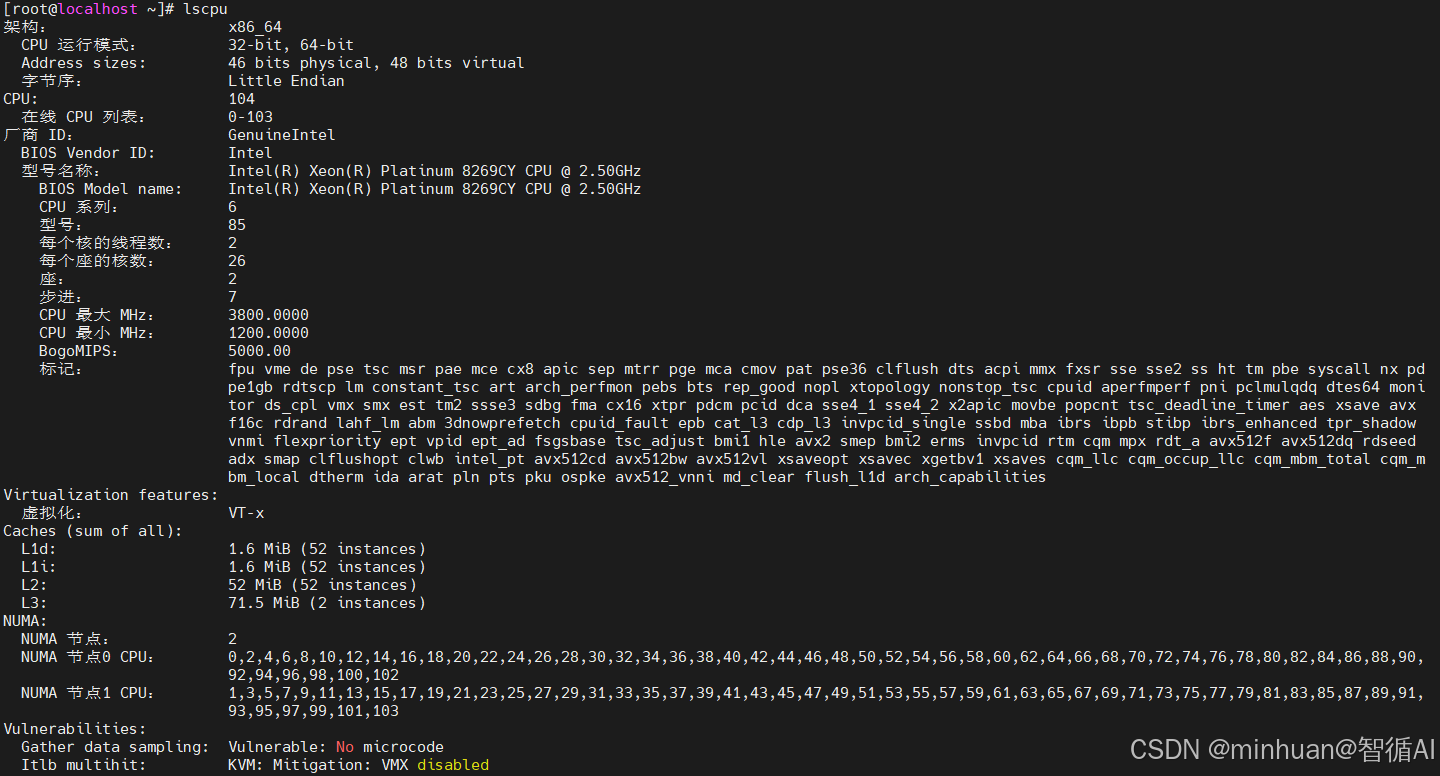
核心硬件参数摘要:
- CPU型号:Intel Xeon Platinum 8269CY @ 2.50GHz
- 总逻辑CPU:104核,双路26核,超线程开启
- 支持指令集:AVX512、VT-x 虚拟化、各类安全特性
- NUMA节点:2 节点,CPU物理资源分组明确
- 漏洞防护:系统已默认启用 Spectre、Retbleed 等漏洞mitigation策略
3. 内存信息查看
通过free命令可以显示系统的总内存、已用内存、空闲内存等信息,-h 选项表示以易读的格式(如MB、GB)显示信息。
bash
free -h输出显示:
total used free shared buff/cache available
Mem: 130924100 2529512 72613000 416676 57257444 128394588
Swap: 4194300 9312 4184988
核心硬件参数摘要:
- 总内存 (total):130924100KB,约124.8GB
- 已用内存 (used):2529512KB,约2.4GB
- 空闲内存 (free):72613000KB,约69.2GB
- 可用内存 (available):128394588KB,约122.4GB
- 总交换空间 (total swap):4194300KB,约4.0GB
- 已用交换空间 (used swap):9312KB,约9MB
三、多网卡识别与静态网络配置
物理服务器普遍配备多块物理网卡,需精准识别物理网线对应网卡名称,避免配置错误导致网络不通。
1. 查看全网卡列表
在终端输入ip addr命令,找到所有的网卡名称,一般服务器看配置会有多个网卡扣,看网卡的清单列表;
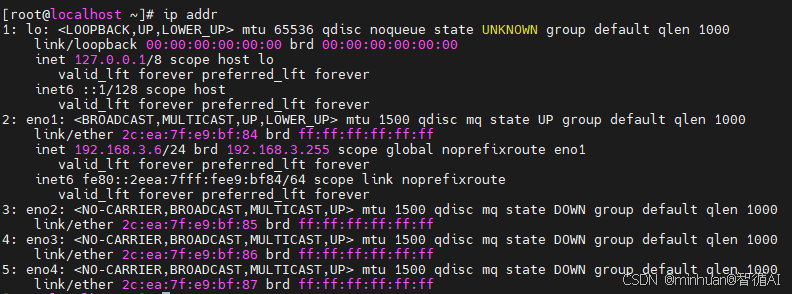
由以上可以看出,服务器有lo 、eno1、eno2、eno3、eno4、virbr0、virbr0-nic哪个是我们要设置的网卡呢,网卡的类型区分规则:
- eno1, eno2, eno3, eno4:是我们需要关注的物理网卡,是我们的配置目标。
- lo: 本地回环接口(Local Loopback),用于服务器内部通信,IP通常是127.0.0.1,不需要设置。
- virbr0, virbr0-nic: 虚拟网桥接口,通常由 KVM/QEMU 虚拟化软件自动生成,用于虚拟机内部 networking,不需要手动设置物理IP。
2. 多网卡物理端口精准定位
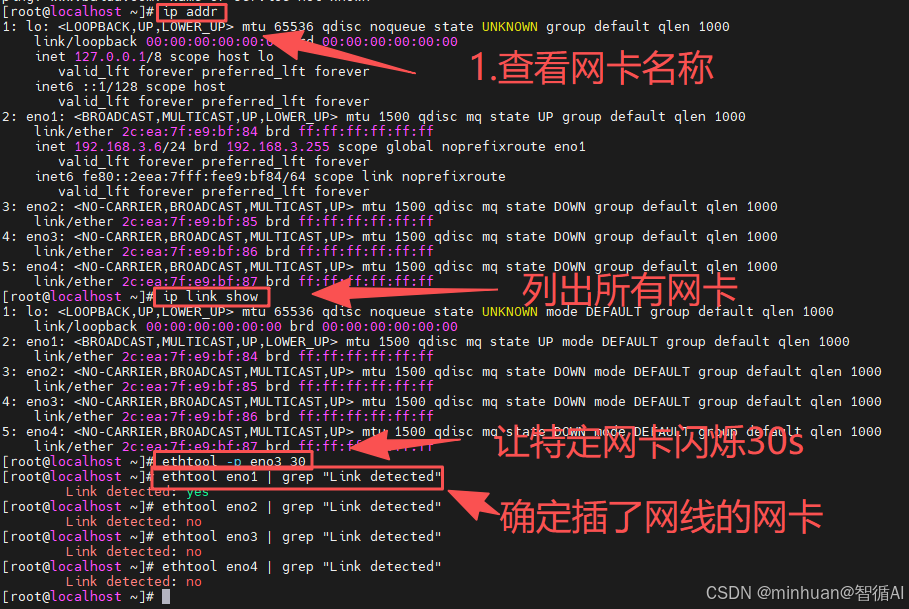
服务器网卡太多 如何确定插入的是哪个,在服务器拥有多个网卡,我们看到的这台服务器有4个,有的甚至有8个或更多,在这种情况下,要确定哪根网线插在哪个物理接口上,最可靠的方法是软硬结合:通过软件命令让特定的网卡闪烁或流量激增,然后去机房观察物理指示灯。
2.1 ethtool网卡指示灯闪烁定位
指定网卡强制闪烁30秒,这是最标准的方法,ethtool可以强制让特定网卡的物理指示灯快速闪烁,我们只需到机房观察物理端口灯光即可对应编号;
回顾我们的物理网卡eno1, eno2, eno3, eno4,例如我们测试eno3,让它闪烁30秒,执行命令格式:
bash
ethtool -p eno3 30-
- 执行后,该命令会阻塞终端30秒,期间eno3对应的物理灯会快速闪烁。
-
- 观察物理服务器:去机房找到对应服务器,看哪个端口的灯在快速闪烁,那个端口就是eno3。
2.2 检测网卡物理链路状态
在我们看到网卡对应的灯亮过后,插入网线,网卡指示灯会闪烁,同时我们也可以验证我们到底是插在了哪个网卡,确认网卡名称,通过以下命令逐个确认:
bash
ethtool eno1 | grep "Link detected"- Link detected: yes:表示该网卡已插入网线且物理连接正常。
- Link detected: no:表示该网卡没插网线或对面交换机没开。
结论:我们只需要设置那些显示 yes 的网卡。如果只有一个显示 yes,那就是它了。
3. 静态IP网络配置
假设我们通过以上步骤发现eno1是Link detected: yes,并且我们也决定用它来上网,那么我们要设置的网卡名称就是:eno1;
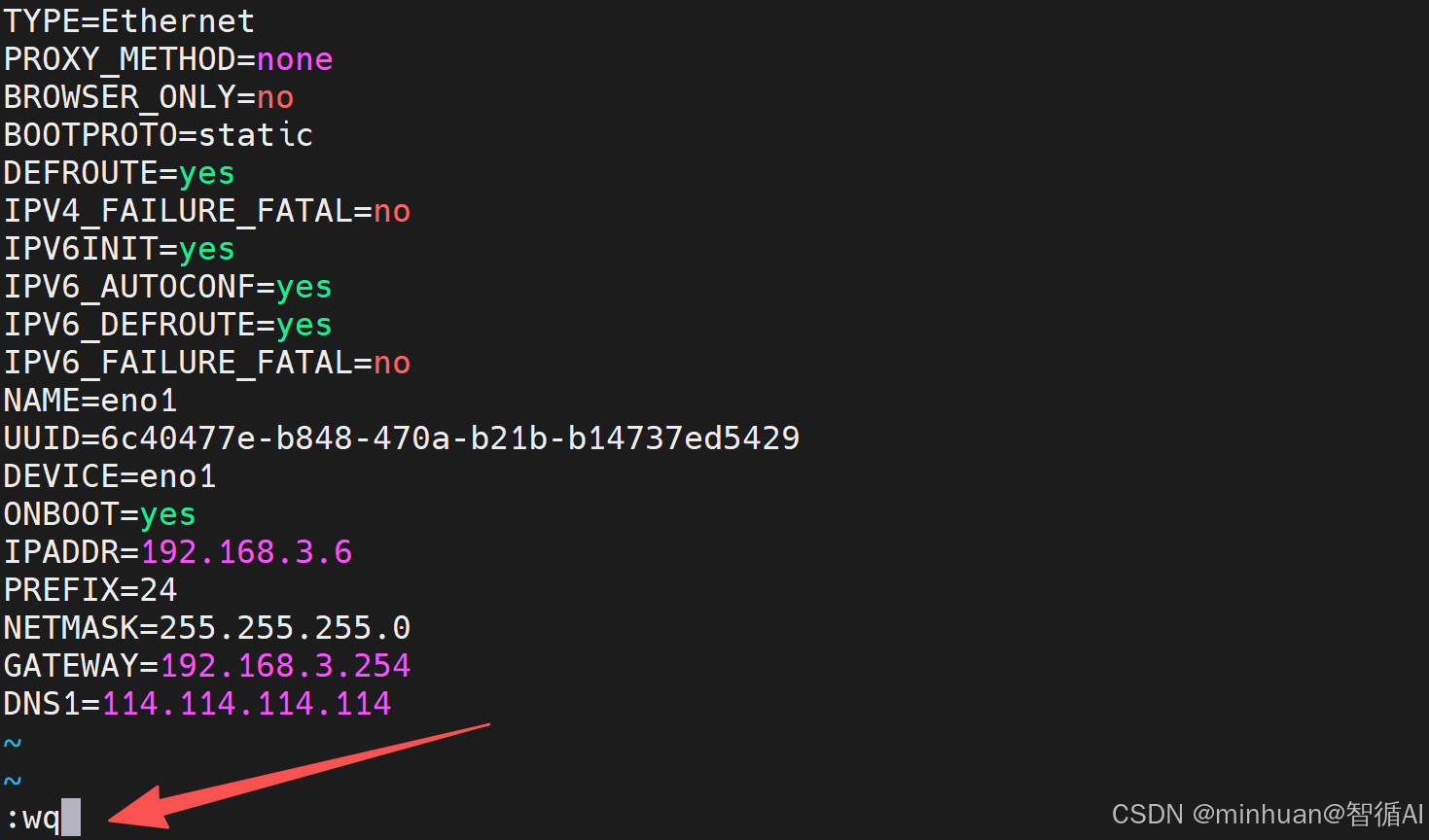
3.1 进入网卡配置文件目录,编辑对应网卡配置文件
bash
vi /etc/sysconfig/network-scripts/ifcfg-eno1配置文件的路径基本都是固定,唯一变化的区别就是最后eno1或eno2等等;
3.2 关键配置项修改
BOOTPROTO=static
ONBOOT=yes
IPADDR=内网静态IP
NETMASK=子网掩码
GATEWAY=网关地址
DNS1=公共DNS地址
3.3 Vim编辑器基础保存退出操作
在输入完成后保存退出命令:先按Esc,再接着输入冒号":" ,此时光标会跳到屏幕最下方,然后输入wq。
- w = write,表示保存
- q = quit,表示退出
屏幕底部应显示::wq,在vi或vim编辑器中,保存并退出的标准操作如下:
| 目的 | 按键顺序 (先按 Esc) | 说明 |
|---|---|---|
| 保存并退出 | Esc → :wq → Enter |
最常用,保存修改并离开 |
| 强制保存退出 | Esc → :wq! → Enter |
当文件是"只读"但你有权限强制覆盖时使用 |
| 不保存直接退出 | Esc → :q! → Enter |
慎用!放弃所有修改直接离开 |
| 仅保存不退出 | Esc → :w → Enter |
保存一下,继续编辑 |
| 仅退出不保存 | Esc → :q → Enter |
如果没修改过可以直接退;若修改过会报错,需用 :q! |
常用操作:
- 保存并退出:Esc → 输入:wq → 回车
- 强制只读保存退出:Esc → 输入:wq! → 回车
- 不保存退出:Esc → 输入:q! → 回车
**注意:**如果我们不小心配置错了网卡,比如配到了没插线的eno2,网络是不会通的,但也不会破坏现有网络,因为eno2本来就没通。如果发现不通,检查一下是不是配错了eno编号,或者网线其实插在eno3 上。
4. 网络服务重启适配
通常我们通过执行 systemctl restart network 命令来重启网络链接:
- 如果正常重启则可跳过此环节;
- 如果重启网络提示Failed to restart network.service: Unit network.service not found.
错误原因:
- CentOS 8/RHEL 8/openEuler 等新版系统弃用传统 network service 服务,改用 NetworkManager 管理网络。
解决方案:
- 1. 重启全局网络服务
bash
systemctl restart NetworkManager- 2. 精准重启单网卡
如果我们只想重启eno1网卡,使用nmcli是最快且不影响其他网络的方式:
bash
# 1. 先查看连接名称(NAME)
nmcli connection show
# 2. 关闭再开启指定连接(将<连接名>替换为eno1对应的NAME,通常也是eno1)
nmcli connection down <连接名>
nmcli connection up <连接名>
# 或者使用一条命令完成:
nmcli connection down eno1 && nmcli connection up eno1- 3. ping网络服务
- 重启完成后,再试试内网,如果有外网可以访问的,也可以拼外网地址尝试是否接通;
- 同时,ip设置好后我们可以通过命令"ip addr show eno1"看看网卡显示的状态;
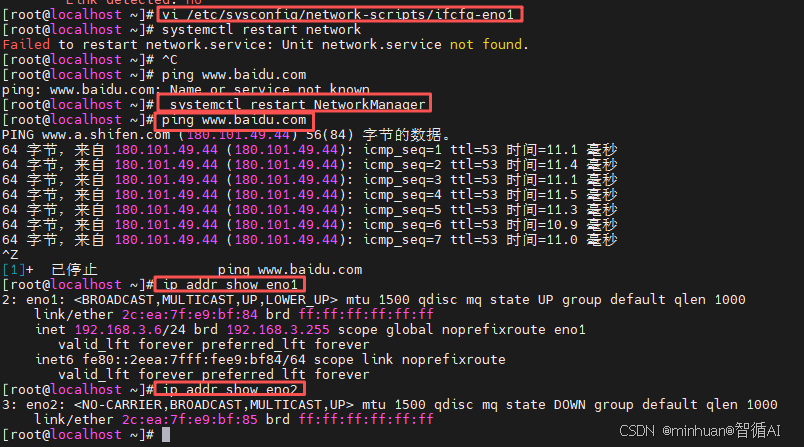
操作步骤总结:
-
- 编辑文件:vi /etc/sysconfig/network-scripts/ifcfg-eno1
-
- 修改 BOOTPROTO=static
-
- 添加 IPADDR, NETMASK, GATEWAY, DNS1
-
- 确保 ONBOOT=yes
-
- 重启网络:systemctl restart network
四、Python源码编译环境搭建
1. 安装包准备与解压
安装包的版本很多,我们特意选择了经常实用、比较稳定的3.11.3版本,在官网下载源代码压缩包Python-3.11.3.tar.xz文件,让后执行以下命令:
bash
# 解压源码包
tar -xf Python-3.11.3.tar.xz
# 进入解压后的目录
cd Python-3.11.3
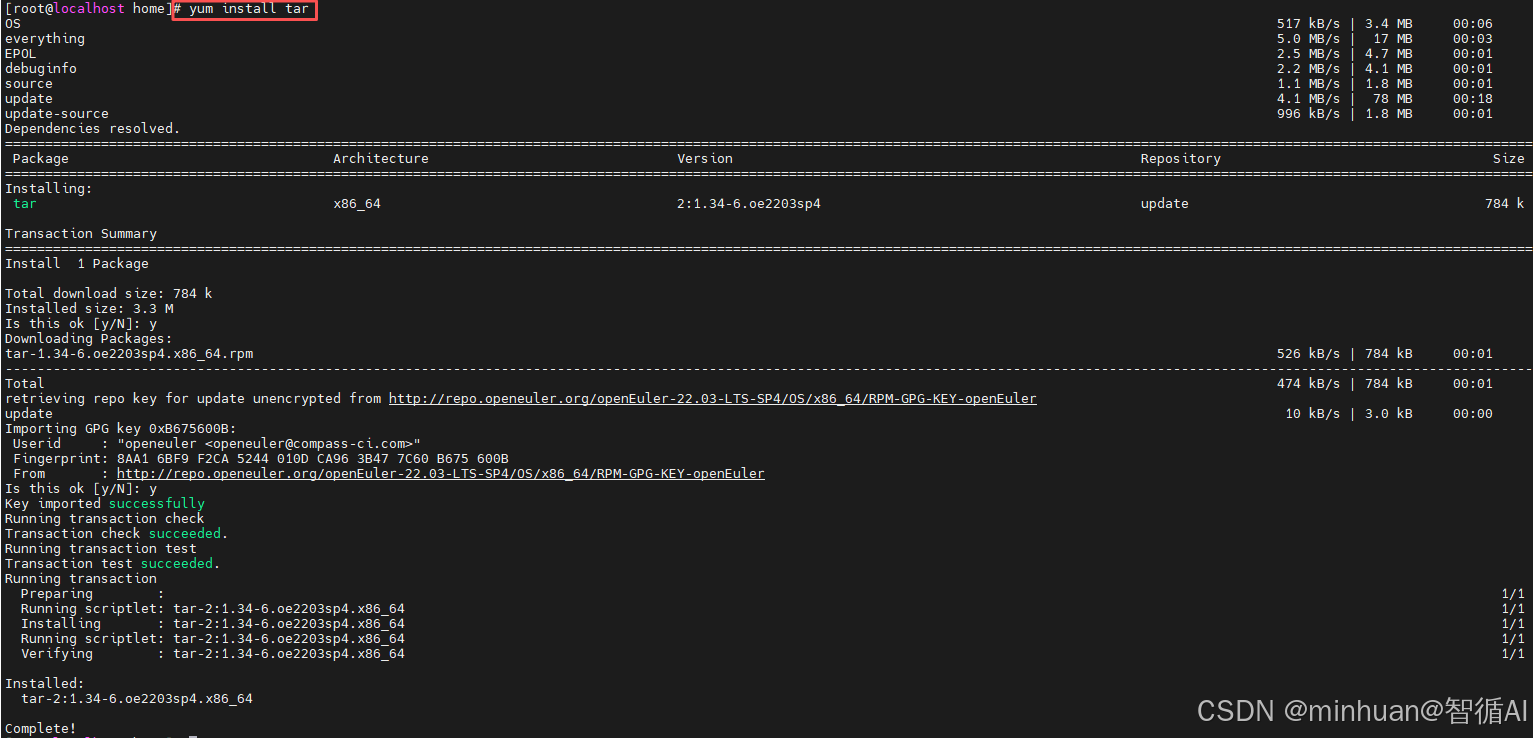
如果tar未找到命名,可以先按yum install tar执行安装;
2. 安装编译依赖环境
正常我们这一步一个是配置编译环境,但如果缺少依赖,会出现错误提示: error: no acceptable C compiler found in $PATH,如下图:
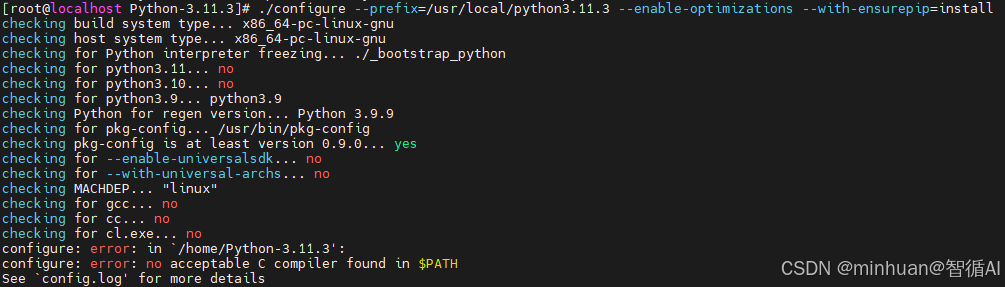
如果出现了,则按以下解决方案处理,首先说明这个错误configure: error: no acceptable C compiler found in $PATH 的意思是:你的系统中缺少C语言编译器(GCC)。
Python的源代码需要通过编译才能安装,而编译过程必须依赖GCC。此外,为了保证Python功能完整,如支持SSL、Zip 等,还需要安装一系列的开发库。按照以下步骤操作,一次性解决所有依赖问题:
2.1 安装编译工具和依赖库
请在终端执行以下命令(需要联网):
bash
# 一键安装 GCC、Make 等核心编译工具。
yum groupinstall "Development Tools" -y
bash
# 安装Python运行所需的各类开发头文件(如openssl-devel用于支持HTTPS,zlib-devel用于支持压缩)。
yum install -y gcc gcc-c++ make zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel libpcap-devel xz-devel libffi-devel
3. 源码配置与编译安装
这一步检查系统环境并生成Makefile。
3.1 配置编译参数
bash
./configure --prefix=/usr/local/python3.11.3 --enable-optimizations --with-ensurepip=install- --prefix: 指定安装路径,建议不要覆盖系统自带的python。
- --enable-optimizations: 开启优化,编译时间变长,但运行速度更快。
- --with-ensurepip=install: 确保安装 pip。
这一段执行的会比较长,如果结果没有明确报错,继续执行下一步;
3.2 多核加速编译
开始编译源代码。使用 -j$(nproc) 可以利用多核 CPU 加速编译过程。
bash
# 编译 (这步可能需要几分钟到十几分钟,取决于电脑性能)
make -j$(nproc)- nproc自动读取CPU核心数,充分利用服务器多核算力缩短编译时间。
- 同时也可替换成我们cpu的内核数,在不清楚时我们可以通过lscpu的命令获取cup内核数;
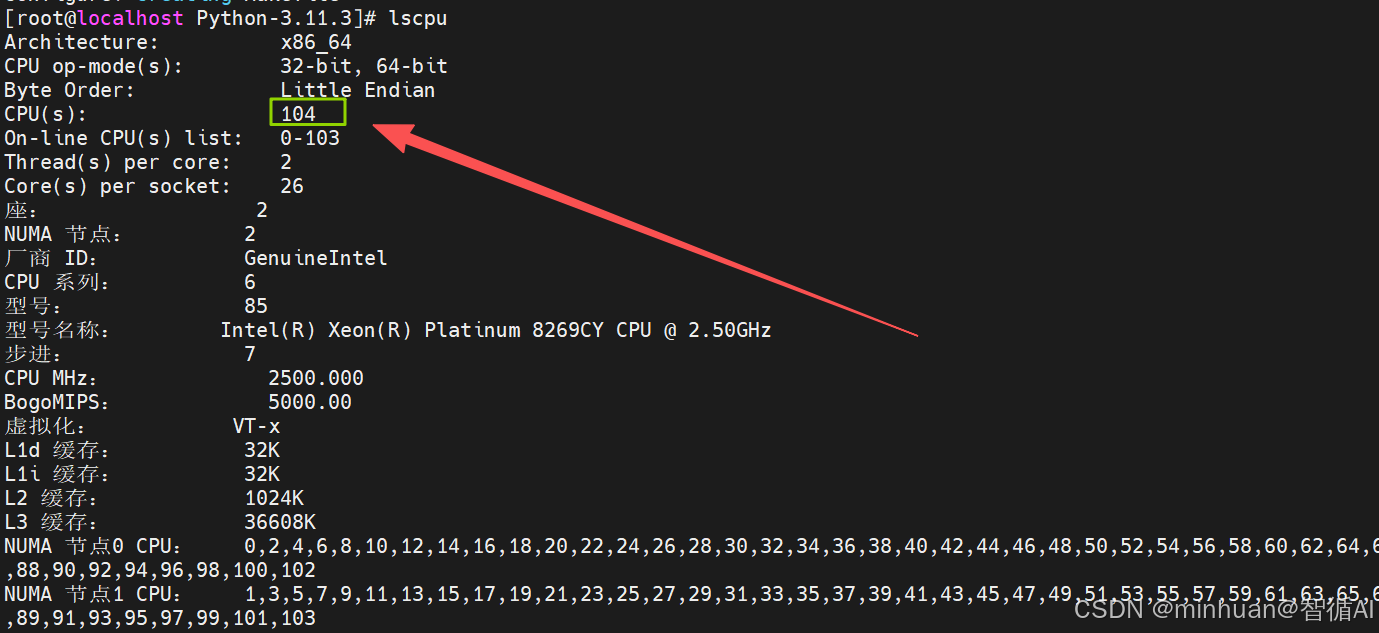
在获取到104内核数后,也可执行"make -j104":
3.3 安全安装 make altinstall
使用 altinstall 而不是 install。
- make install 会覆盖系统默认的python3命令,可能导致系统工具(如 yum)崩溃。
- make altinstall 只会安装为python3.11,保持系统安全。
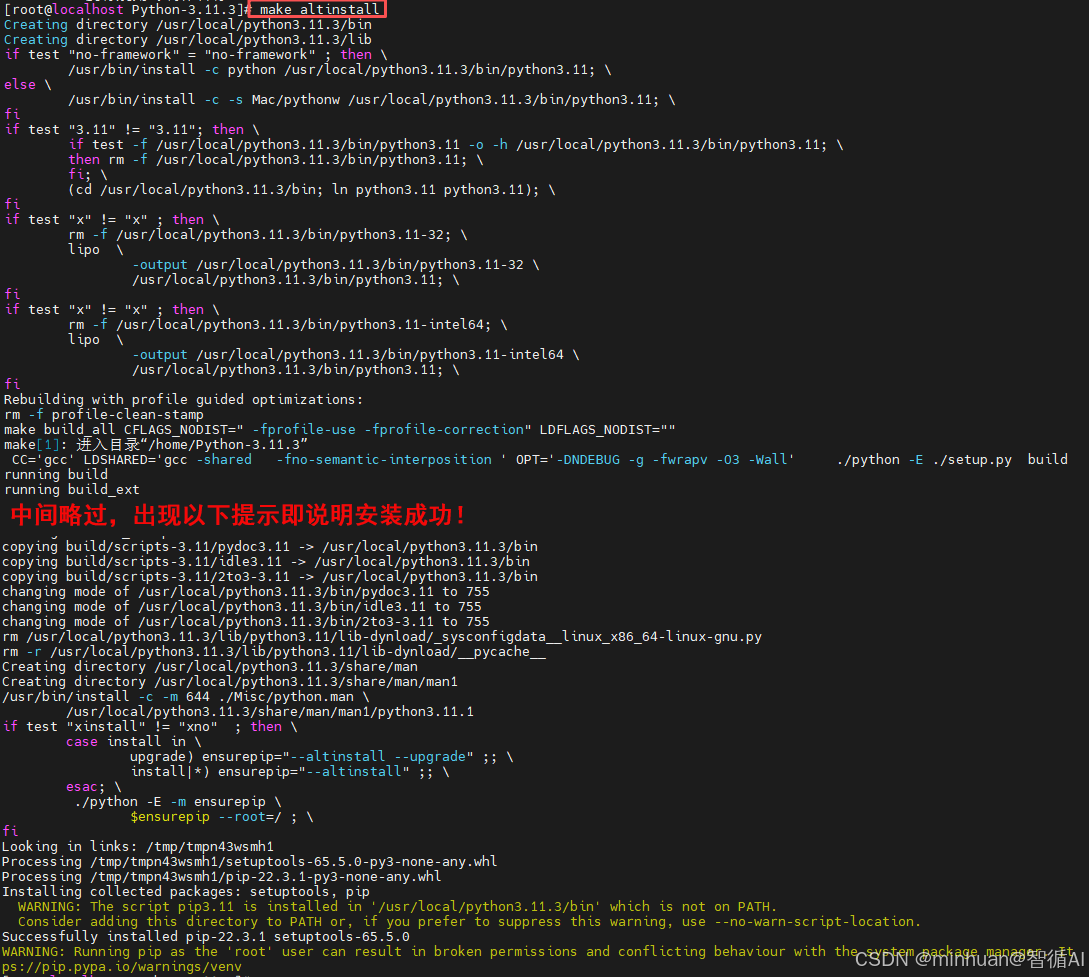
4. Python环境全局生效配置
安装完成后确认,如果完全忘记在哪编译的了,可以搜索系统中所有名为python3.11的可执行文件:
bash
find / -name "python3.11" -type f 2>/dev/null然后通过找到的路径来确认python的版本:
bash
/usr/local/python3.11.3/bin/python3.11 --version通过以上我们可以识别到python版本了,但都要带完整路径;
这是环境变量的问题,我们能通过长路径运行,说明Python已经成功安装了。报错"未找到命令"是因为系统不知道去 /usr/local/python3.11/bin/ 这个文件夹里找程序,它只会在默认的文件夹(如/usr/bin)里找。所以我们需要把这个路径告诉系统,配置全局识别。这里有两种方法:
方法一:建立软链接
这个方法相当于给Python 3.11创建一个"快捷方式"放到系统的通用目录下,这样我们在任何地方输入 python3.11都能找到它。请在终端执行以下命令:
bash
ln -s /usr/local/python3.11.3/bin/python3.11 /usr/bin/python3.11命令解释:
- ln -s:创建软链接(类似于 Windows 的快捷方式)。
- /usr/local/python3.11.3/bin/python3.11:刚才安装好的真实路径(源文件)。
- /usr/bin/python3.11:我们想让系统识别的快捷路径(目标位置)。
验证:
- 执行完上面那行命令后,直接输入:python3.11 --version
- 如果显示版本号,就大功告成了!

方法二:配置环境变量PATH
如果想让系统记住这个路径,可以把它加到配置文件里。
- 1. 编辑bash环境变量文件
bash
vi ~/.bashrc- 2. 添加路径:
- 按 i 键进入编辑模式,在文件最下面添加一行:
- export PATH=$PATH:/usr/local/python3.11.3/bin/python3.11
- 按 Esc 键,输入 :wq 保存并退出。
- 3. 让配置立即生效:
bash
source ~/.bashrc五、大模型运行环境适配
1. 基础运行示例参考
文件名称:download_model_linux.py
python
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
# 下载模型到./model文件夹
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "/home/model"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(local_model_path, trust_remote_code=True)
# 保存到本地
print("模型下载完成,已保存到/home/model文件夹")2. 多Python版本依赖冲突解决
在基础配置完成后,我们准备一个基础的python示例文件,运行py文件,根据提示补充缺失的插件即可;
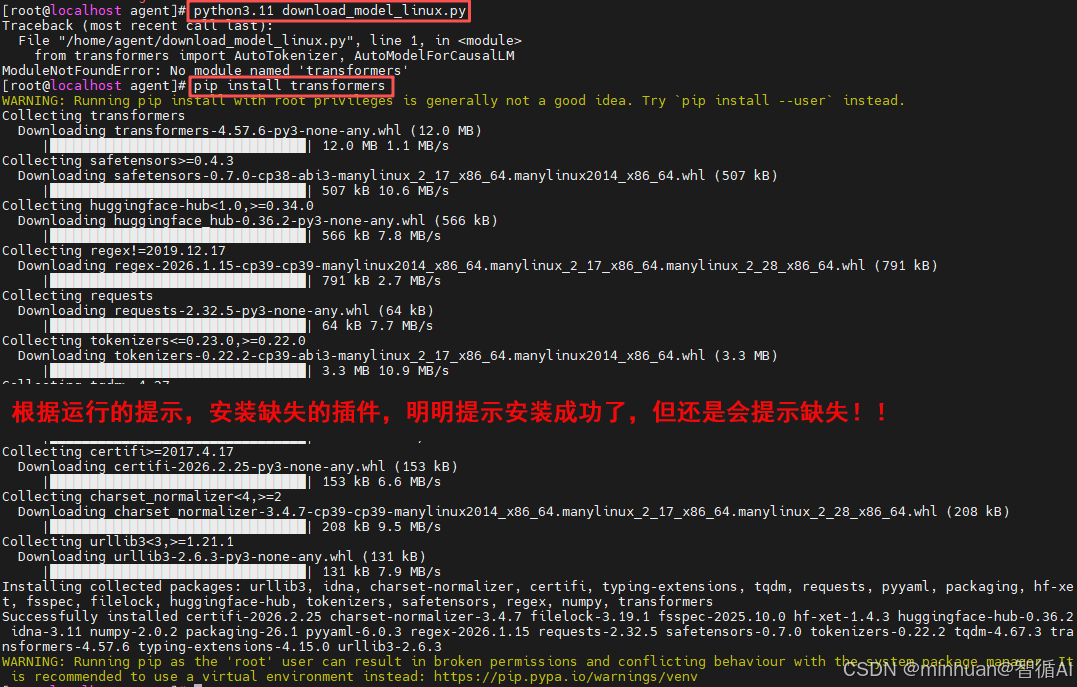
这里体现了一个问题,正常我们按pip来安装是没错的,这里我们安装成功后,还是会反复提示transformers未安装;这是一个典型的Python版本与环境不匹配问题:
- 首先我们需要确保安装库的Python版本和运行脚本的Python版本是同一个。
- 根据我们之前配置的路径,我们编译了的版本是Python3.11,但系统中还存在一个Python3.9。
我们可以使用以下命令解决冲突问题:强制使用Python 3.11 自带的pip 来安装库,由于我们已经为Python 3.11配置了软链接:
bash
python3.11 -m pip install transformers 注意:如果提示pip未安装,我们需要先运行python3.11 -m ensurepip 来安装pip。
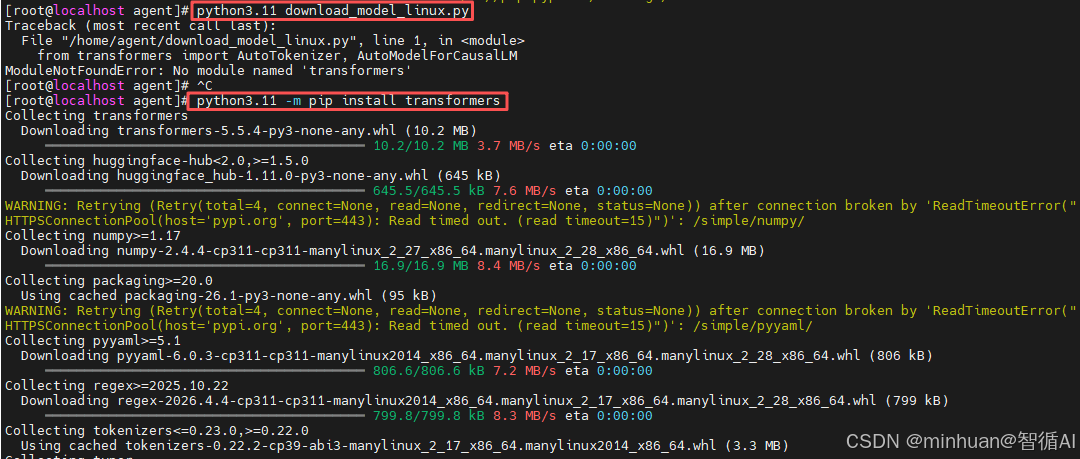
继续运行脚本文件,按提示补充插件,接下来补充modelscope模块;
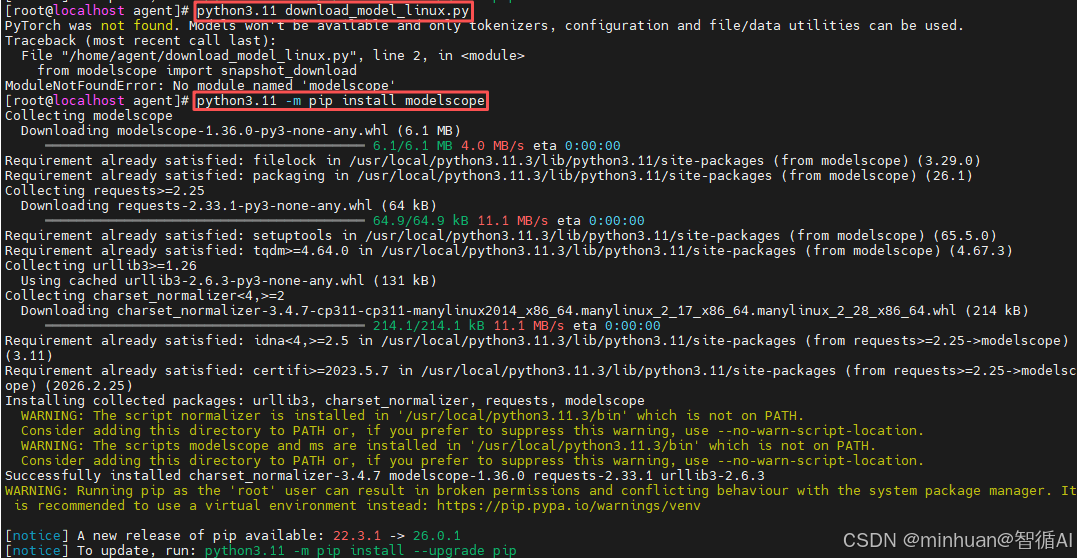
继续运行文件,在模块都齐全后,开始执行下载模型的任务;
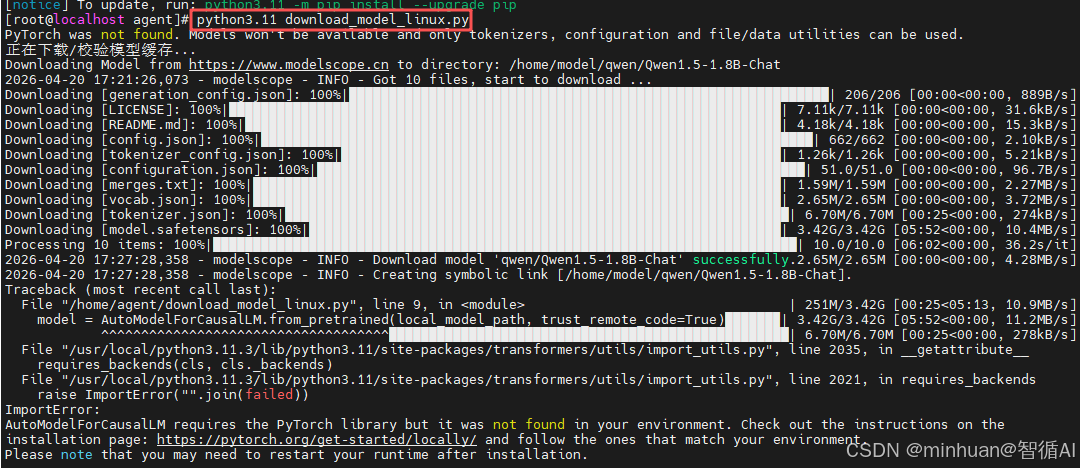
正常下载完成后,模型自动加载,服务启动;
3. PyTorch依赖安装
如果下载后运行出现ImportError:AutoModelForCausalLM requires the PyTorch library but it was not found in your environment.错误,这个错误非常明确:你的 Python 环境中没有安装 PyTorch。
虽然我们之前可能成功安装了 transformers 和 modelscope,但 AutoModelForCausalLM 是依赖 PyTorch 后端来加载和运行模型的。没有它,代码无法执行。
安装方案:
优先尝试安装预编译的CPU版本,不要使用 pip install torch 直接安装,这有时会触发源码编译,而是使用PyTorch官方推荐的索引地址,确保下载预编译好的二进制包(Wheel)。
运行以下命令:
bash
python3.11 -m pip install torch --index-url https://download.pytorch.org/whl/cpu说明:
- 上述命令安装的是CPU版本 的 PyTorch。如果我们的服务器没有NVIDIA GPU或者显卡驱动有问题,这是最稳妥的选择。
- 如果我们有NVIDIA GPU且驱动正常,想使用GPU加速,请先运行 nvidia-smi 确认驱动版本,然后去PyTorch官网查找对应的CUDA版本命令,建议先用CPU版本跑通代码。
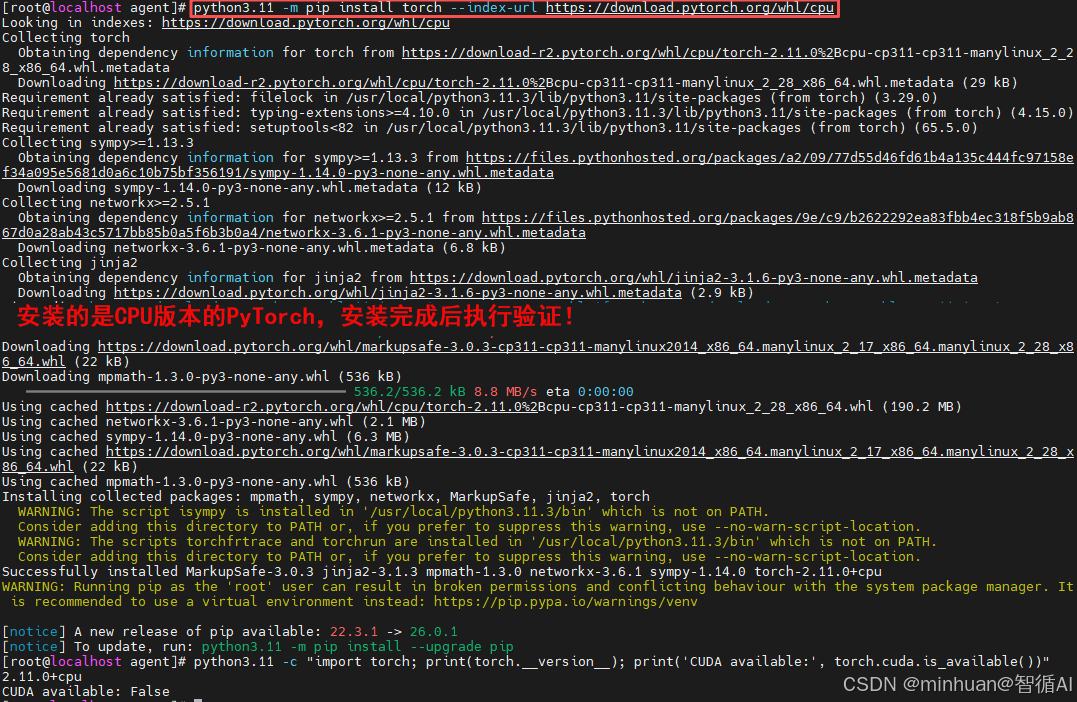
安装验证:
安装完成后,在终端运行以下Python命令验证是否成功:
bash
python3.11 -c "import torch; print(torch.__version__); print('CUDA available:', torch.cuda.is_available())"如果输出了版本号(如 2.x.x+cpu)且没有报错,说明安装成功,参考上图最后部分;
4. 接口服务依赖安装
4.1 模型加载调用示例参考
文件名称:api-use.py,加载模型,并提供chat接口外部访问;
python
# 1. 导入需要的库
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer
import uvicorn
from modelscope import snapshot_download
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "/home/model"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
# 生产在线的接口文档,访问方式"/docs"
from fastapi.openapi.docs import (
get_redoc_html,
get_swagger_ui_html,
get_swagger_ui_oauth2_redirect_html,
)
# 2. 初始化FastAPI应用(创建API服务)
app = FastAPI(title="本地大模型开放调用API", description="基于Qwen模型的本地化部署接口")
# 3. 加载模型和Tokenizer(关键:模型会自动下载并加载到CPU)
# AutoModelForCausalLM:加载对话模型权重,AutoTokenizer:处理文字(转换为模型能理解的格式)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(local_model_path, trust_remote_code=True)
# 4. 定义API接口(POST请求,接收用户提问,返回模型回答)
@app.post("/chat", summary="大模型对话接口")
def chat(question: str):
# 处理用户输入:将文字转换为模型能理解的张量
inputs = tokenizer(question, return_tensors="pt")
# 模型生成回答(max_length:回答最大长度,do_sample:是否随机生成,temperature:随机性程度)
outputs = model.generate(**inputs, max_length=512, do_sample=True, temperature=0.7)
# 将模型输出转换为文字
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 返回结果(JSON格式)
return {"question": question, "answer": answer}
# 5. 启动API服务(监听局域网IP,端口8000)
if __name__ == "__main__":
# host="0.0.0.0":允许局域网内所有设备访问,port=8000:端口号
uvicorn.run(app, host="0.0.0.0", port=8000)4.2 补充fastapi模块
- FastAPI是一个基于Python类型提示的高性能Web框架,非常适合构建现代API。
- 它原生支持异步编程,能自动生成交互式文档,开发效率极高且代码简洁。
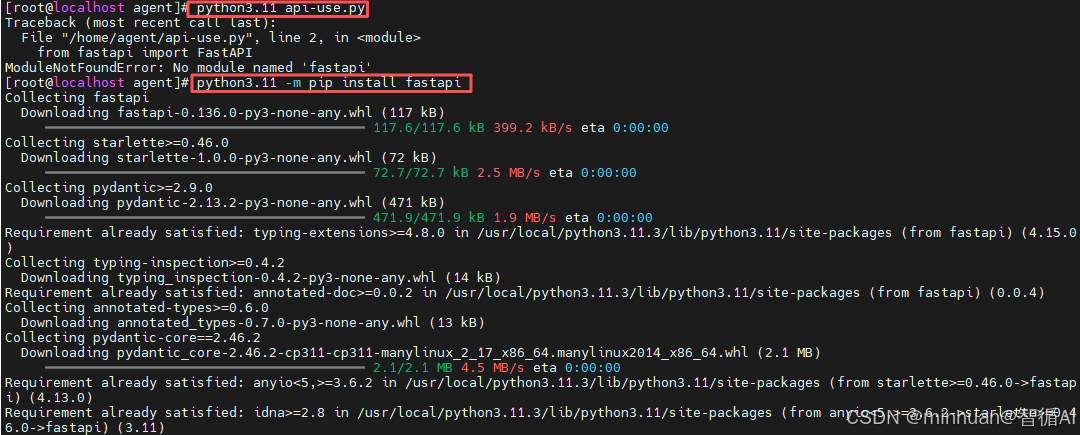
4.3 补充uvicorn模块
- Uvicorn是基于ASGI规范的高性能服务器,专为运行FastAPI等异步应用而生。
- 它底层采用uvloop事件循环,能轻松处理海量并发连接,提供极速响应体验。
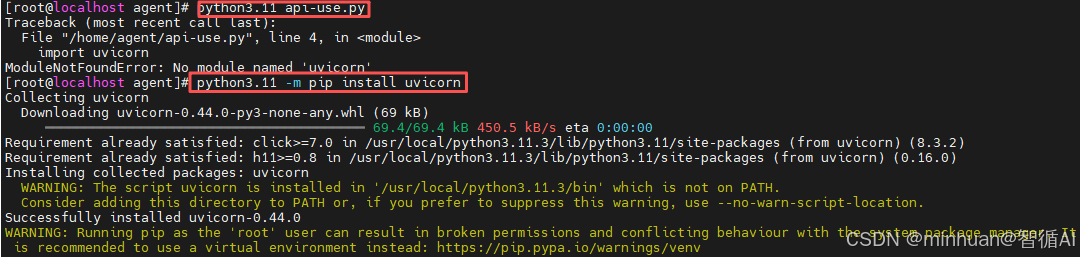
服务插件都已经安装完毕,重新启动服务,模型也正常启动,端口8000
六、接口服务部署与防火墙配置
模型服务启动,依赖全部安装完成后,启动FastAPI接口服务,默认监听8000端口。但在访问接口的过程中,出现了一个"Failed to connect to 192.168.3.6 port 8000 after 21024 ms: Could not connect to server"的错误;
1. 检查服务器防火墙
如果服务正在运行且监听 0.0.0.0,但仍然连不上,通常是服务器的防火墙拦截了外部请求。
bash
# 临时关闭防火墙测试(生产环境慎用)
systemctl stop firewalld
# 或者只开放 8000 端口
firewall-cmd --zone=public --add-port=8000/tcp --permanent
firewall-cmd --reload2. 接口连通性测试
使用curl命令测试大模型对话接口:
bash
curl -X POST "http://192.168.3.6:8000/chat?question=%E4%BB%80%E4%B9%88%E6%98%AF%E9%87%8F%E5%AD%90%E8%AE%A1%E7%AE%97%EF%BC%9F"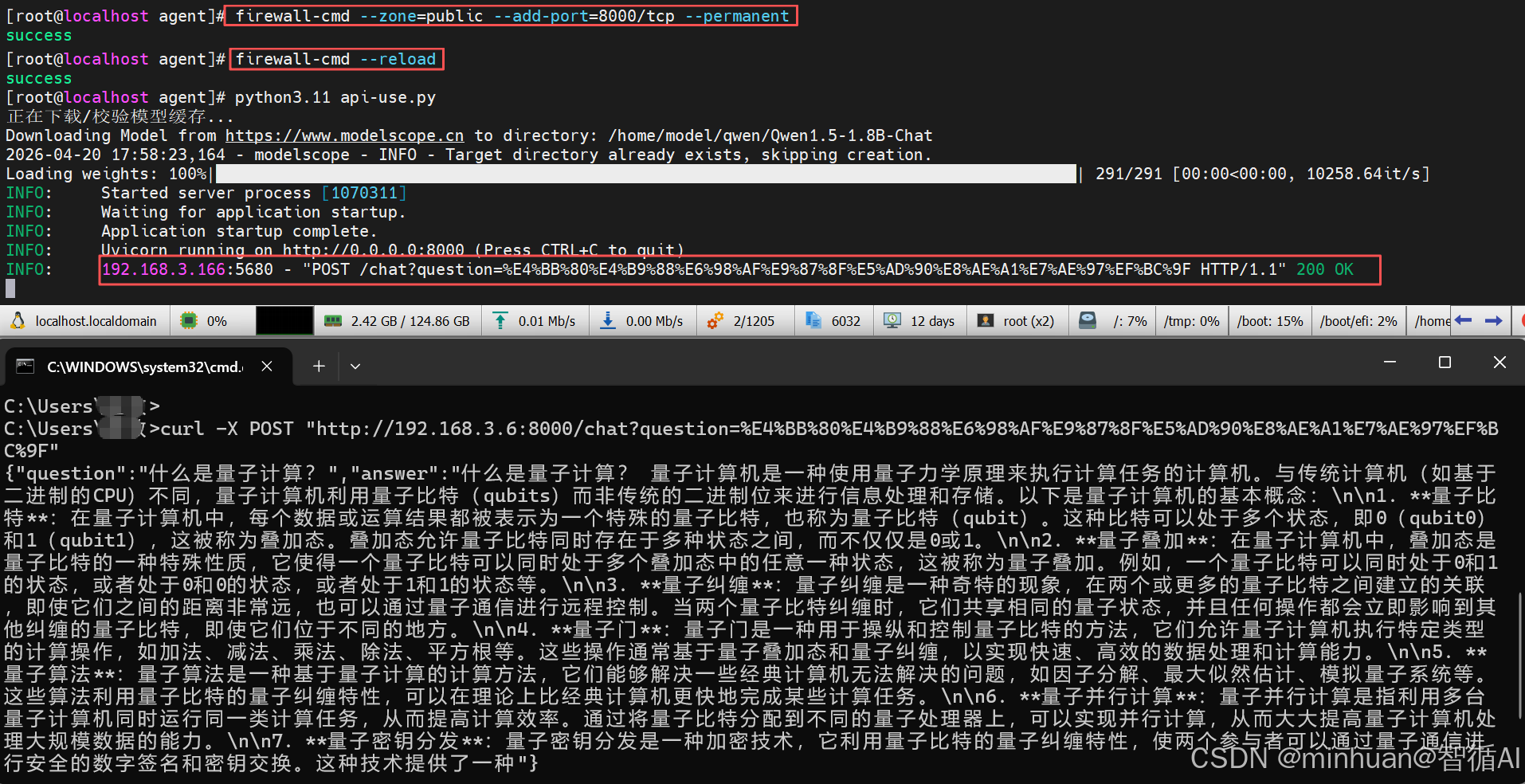
使用Postman工具进行调试:
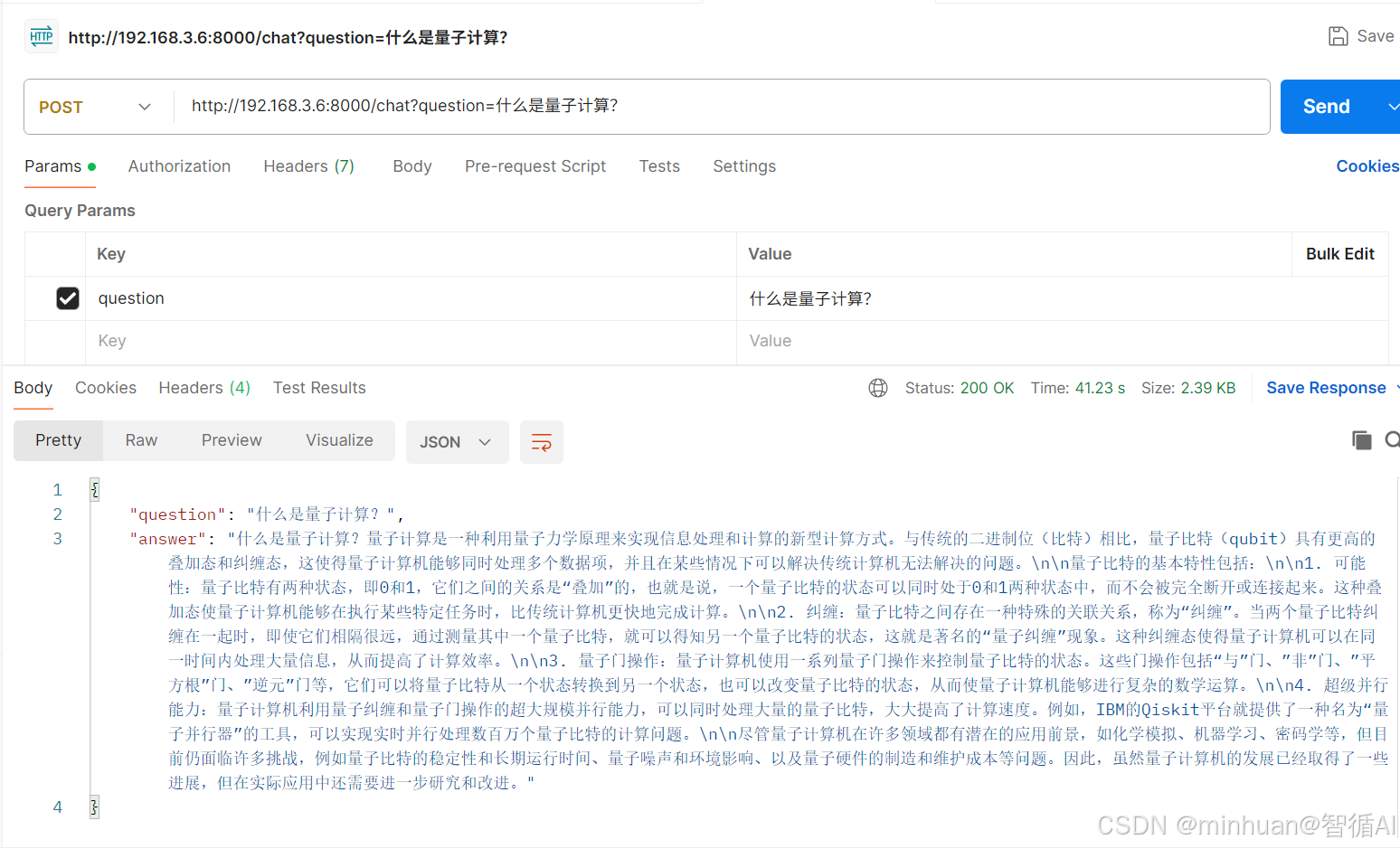
到这一步,整个服务器配置完成,模型加载成功,接口也成功实现调用!
七、总结
通过整篇梳理下来能明显感受到,Linux服务器环境搭建本身就十分繁琐费心,尤其是openEuler这类特定系统版本,相比常规CentOS 适配门槛更高,多网卡识别、编译依赖、版本兼容处处都是隐形坑。回顾这台服务器从零到一的全流程:从硬件信息核验、多网卡物理定位与静态网络配置,到源码编译安装Python独立环境,再到大模型依赖库补齐、PyTorch适配、FastAPI接口搭建,以及防火墙端口放行,每一步都是实际落地中必会遇到的真实场景。
我个人实操感悟:服务器部署最怕凭感觉操作,多网卡不要盲目乱配,多Python版本务必用对应版本的pip安装依赖,不然极易出现库安装成功却调用失效的问题;遇到报错不要盲目重装,优先从版本兼容、环境路径、依赖匹配三个方向排查。系统环境也在发生变化,经验也只是参考,技术就是个活学活用、融会贯通的持续过程,后续任意Linux服务器部署大模型,参考这个思路,都能快速上手、少走大量弯路。