
欢迎阅读**【LLM推理】专栏系列**文章,在首个系列,我们将带来大模型智能推理方向开源项目Kthena技术解析:
★【第一期】《Kthena 核心原语:ModelServing CRD 如何定义分布式推理的"新标准"?》
★【第二期】《Kthena Router:插件架构解析及Benchmark测试》(本文)
★【第三期】《Kthena AutoScaling:深度解析 Kthena 如何通过"语义感知弹性"重塑 AI 推理成本》
本文深入分析 Kthena Router 中 ScorePlugin(评分插件) 模块的系统设计与实现。该模块利用可配置、可插拔的架构,实现了推理请求的多维度评分和智能路由。我们将详细探讨目前已实现的六种 ScorePlugin,并构建一个基于 DeepSeek-R1-Distill-Qwen-7B 模型的标准化基准测试环境,评估不同调度策略在长、短系统提示词(System Prompt)场景下的性能表现。

实验结果表明,在长系统提示词场景 下,"KVCacheAware 插件 + Least Request 插件"的组合实现了 2.73 倍的吞吐量提升 ,并将 TTFT(首字延迟)降低了 73.5%。这显著优化了整体推理服务性能,验证了缓存感知调度对于长文本推理的核心价值。
1. 背 景
随着大语言模型(LLM)推理需求的爆炸式增长,如何高效利用 GPU 资源并降低延迟成为核心挑战。传统的负载均衡器(如简单轮询或随机分发)在处理 LLM 推理请求时显得捉襟见肘,因为它们无法感知后端的实时负载、KV Cache 状态以及预填充(Prefill)与解码(Decode)分离的复杂需求。
Kthena 作为一个云原生、高性能的 LLM 推理路由与调度系统,通过其 ScorePlugin 机制提供了灵活的流量管理能力。
2. ScorePlugin 架构设计
ScorePlugin 采用插件化设计,允许用户根据业务场景自由组合不同的评分逻辑。
type ScorePlugin interface {
Name() string
Score(ctx *Context, pods []*datastore.PodInfo) map[*datastore.PodInfo]int
}每个插件会根据特定的指标为候选后端(Pod)打分,Router 最终汇总这些分数并选择得分最高的节点转发请求。
目前 Kthena 实现了以下六种核心插件:
① GPU Cache Usage Plugin: 实时监控 Pod 的 GPU 显存缓存使用率,优先调度到使用率较低的节点以降低显存溢出风险。
**② Least Request Plugin:**通过优先将任务调度到已缓存所需数据的节点,显著降低数据传输开销并缩短大模型等任务的启动延迟。
③ Least Latency Plugin: 根据监控到的首字延迟(TTFT)和单字生成延迟(TPOT)指标进行打分,优先选择性能表现更优的 Pod。
④ KVCacheAware Plugin :核心插件。 它通过计算请求的提示词(Prompt)与后端 Pod 中已缓存内容的匹配度进行评分。匹配度越高,得分越高。这能极大提高 KV Cache 复用率,减少 Prefill 阶段的计算量。
⑤ Prefix Cache Plugin: 利用字节级前缀匹配算法和 LRU 淘汰机制,优先选择具有最长前缀匹配记录的 Pod 以提升缓存效率。
⑥ Random Plugin: 在候选节点中随机选择,适用于对调度要求不高的简单场景。
3. ScorePlugin 插件实现细节
3.1 GPU Cache Usage 插件(GPU 缓存使用率插件)
一种基于 GPU 显存缓存利用率 的资源感知型调度策略。
算法原理:
-
实时监控每个 Pod 的 GPU 缓存使用率 (
GPUCacheUsage)。 -
评分函数:
Score = (1.0 - GPUCacheUsage) x 100
-
优先选择 GPU 缓存占用较低 的 Pod,从而降低显存溢出(OOM)的风险。
适用场景: 显存资源受限或显存压力较大的环境。
3.2 Least Request 插件(最少请求插件)
一种基于 活动请求队列长度 的负载均衡策略。
▍算法原理:
-
监控指标:
-
正在运行的请求数:
RequestRunningNum -
等待队列长度:
RequestWaitingNum
-
-
基础负载计算:
base = RequestRunningNum + 100 x RequestWaitingNum
-
归一化评分:
score = ((maxScore - baseScores[info]) / maxScore) x 100
▍关键设计细节:
-
将等待队列的权重因子设置为 100,旨在严厉惩罚已有请求堆积的 Pod。
-
实现 动态负载感知 的均衡分布。
3.3 Least Latency 插件(最低延迟插件)
一种以 推理延迟指标 为驱动的性能导向型调度策略。
▍算法原理:
-
监控指标:
-
TTFT (Time To First Token,首字延迟)
-
TPOT (Time Per Output Token,单位输出 Token 延迟)
-
-
归一化处理:
ScoreTTFT = (MaxTTFT - CurrentTTFT)/ (TTFT - MinTTFT)x 100 ScoreTPOT = (MaxTPOT - CurrentTPOT)/(MaxTPOT - MinTPOT)x 100 -
最终加权评分:
Score = α x ScoreTTFT + (1 - α) x ScoreTPOT
▍配置参数:
TTFTTPOTWeightFactor:0.5 # TTFT 权重因子 α3.4 KVCacheAware 插件(KV 缓存感知插件)
一种利用 KV 缓存命中率 的高级 缓存感知调度策略。
技术亮点:
-
Token 级语义匹配:使用特定模型的 Tokenizer 进行精确分词。
-
分布式缓存协同:通过 Redis 实现跨 Pod 的状态同步。
-
优化连续块匹配算法:最大限度提高缓存命中率。
算法工作流:
① 分词阶段 (Tokenization)
输入 → 模型特定 Tokenizer → Token 序列 [t₁, t₂, ..., tₙ]② 分块切割 (Block Segmentation)
Token 序列 → 固定大小的数据块 [B₁, B₂, ..., Bₘ]
数据块大小:128 tokens(可配置)③ 哈希生成 (Hash Generation)
对每个 Bᵢ 计算:Hash(Bᵢ) = SHA256(Bᵢ) → hᵢ④ 分布式缓存查询
Redis 管道查询:
针对每个 hᵢ → 获取 {Pod₁: 时间戳₁, Pod₂: 时间戳₂, ...}⑤ 连续匹配评分
Score = (连续匹配的数据块数量 / 总块数) × 100配置示例:
blockSizeToHash:128 # Token 块大小
maxBlocksToMatch:128 # 最大处理块数Redis 键值结构:
Key Pattern: "matrix:kv:block:{model}@{hash}"
Value Structure:
{
"pod-name-1.namespace": "1703123456",
"pod-name-2.namespace": "1703123789"
}3.5 Prefix Cache 插件(前缀缓存插件)
一种基于 长前缀缓存 的感知调度策略。
架构设计:
-
三层映射 :
模型 (Model) → 哈希 (Hash) → Pod。 -
基于 LRU 的缓存淘汰:实现高效的内存管理。
-
Top-K 前缀匹配策略:返回具有最长前缀匹配的前 N 个 Pod。
主要特性:
-
字节级前缀匹配算法。
-
优化的内存级 LRU 实现。
-
缓存容量和候选 Pod 数量可配置。
3.6 Random 插件(随机插件)
一种 轻量级的随机负载均衡策略。
实现方式:
-
生成均匀分布的随机分数:
Score ~ Uniform(0, 100) -
采用线程安全的独立随机数生成器。
-
无状态设计,确保长期的负载分布均衡。
适用场景:
-
模式不明显的混合工作负载。
-
追求极低调度开销的轻量级部署。
-
作为性能对比的基准线(Baseline)。
4. 实验设计与性能评估
4.1 实验步骤
为了验证不同插件组合的实际效果
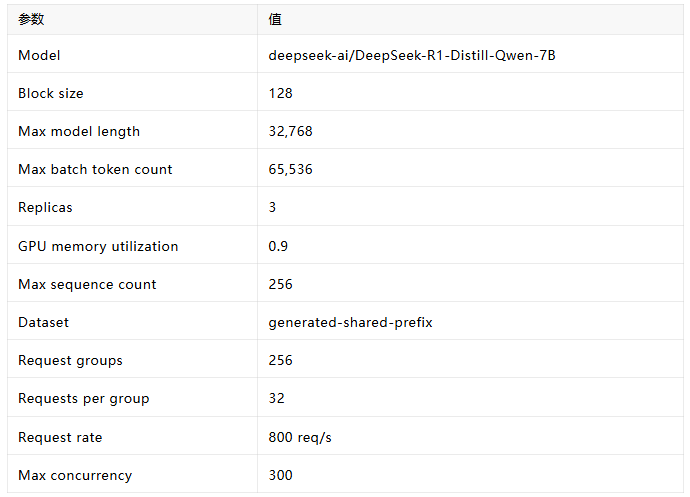
我们建立了一个标准化的测试环境:
表 1: 实验环境配置
4.2 性能测试结果分析
4.2.1 长系统提示词场景 (4096 tokens)
表 2: 性能指标 -- Long Prompt
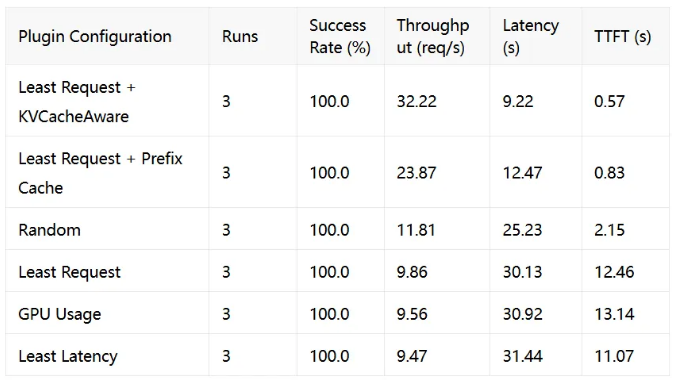
在处理具有长固定前缀(System Prompt)的并发请求时,KVCacheAware + Least Request 组合表现出了压倒性优势:
-
吞吐量 (Throughput): 提升了 2.73倍。由于大量请求命中了同一 Pod 上的缓存,避免了重复计算。
-
TTFT (首字延迟): 降低了 73.5%。缓存命中意味着 Prefill 阶段几乎瞬间完成,用户感知的响应速度极大提升。
4.2.2 短系统提示词场景 (256 tokens)
表 3: 性能指标 -- Short Prompt
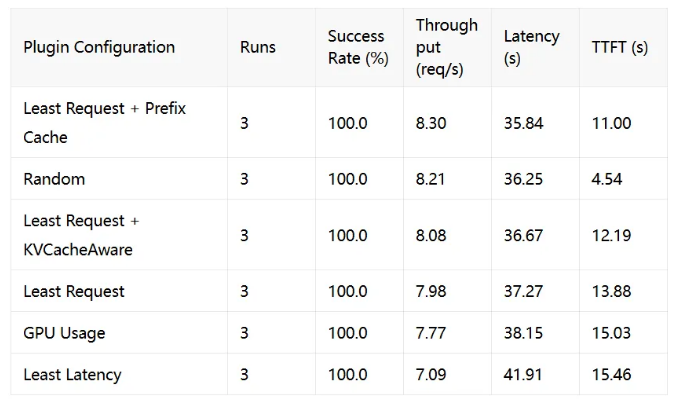
在短示词场景下,各插件表现相对平稳,但 Least Request 依然在保持负载均衡、防止单点过热方面优于传统的 RoundRobin。
5. 场景化部署建议
5.1 高缓存命中场景
推荐配置: KVCacheAware 插件(KV缓存感知) + Least Request 插件(最少请求)
适用用例:
-
智能客服机器人、代码生成以及类似的高度结构化工作负载。
-
带有长系统提示词(System Prompts)的多轮对话。
-
基于模板的内容生成服务。
5.2 常规负载均衡场景
推荐配置: Least Request 插件(最少请求) + Least Latency 插件(最低延迟)
适用用例:
-
具有多样化请求模式的通用推理服务。
-
需要公平分配资源的多租户环境。
-
实时交互式应用。
5.3 资源受限环境
推荐配置: GPU Cache Usage 插件(GPU缓存使用率)
适用用例:
-
显存(GPU Memory)有限的边缘计算部署。
-
对成本敏感的云端环境。
-
多个模型共享底层 GPU 资源的场景。
6. 总 结
Kthena 通过 ScorePlugin 机制,将原本复杂的推理调度逻辑拆解为可组合的模块。实验证明:
-
缓存感知 (KV Cache Awareness) 是提升 LLM 推理效率的关键,尤其是在 RAG(检索增强生成)和长文本场景中。
-
多插件协同(如 KVCache + Least Request)能够兼顾"缓存复用"与"负载均衡",达到最优的综合性能。
作为 Volcano 的子项目,Kthena 致力于将 Volcano 的调度优势从 AI 训练扩展到推理领域,为企业提供从训练到推理的完整全栈解决方案。
🌋 Kthena GitHub地址: https://github.com/volcano-sh/kthena
🌋 更多信息,欢迎访问 Volcano 官网: https://volcano.sh
欢迎Star★,Fork,来 Kthena 社区一起玩转LLM推理!