背景
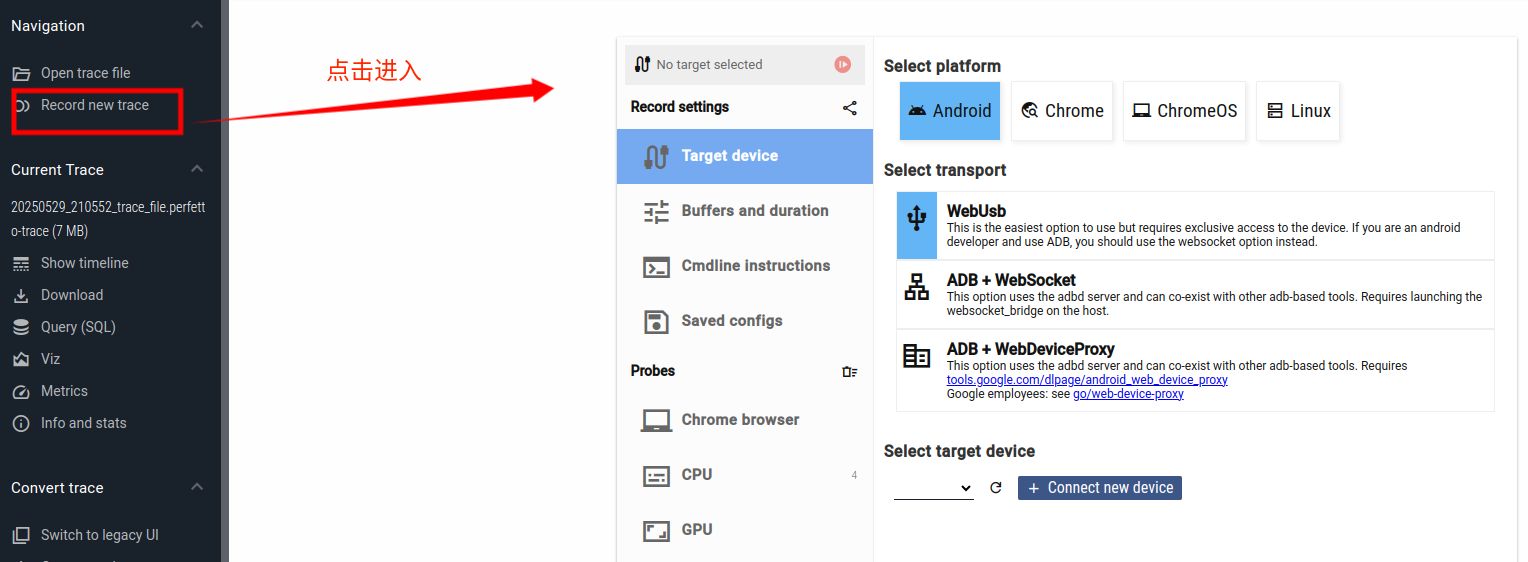
在性能优化中perfetto抓取的方式相对比较多,今天来介绍一下直接使用perfetto网页在chrome浏览器直接抓取方式
 同时也对一些日常分析Perfetto时候高频使用的一些sql进行整理输出。
同时也对一些日常分析Perfetto时候高频使用的一些sql进行整理输出。
如何chrome网页上直接抓取?**
因为用WebUsb方式无法发现自编译aosp模拟器的设备,所以通用一点方法,我们选着adb+websocket方式:
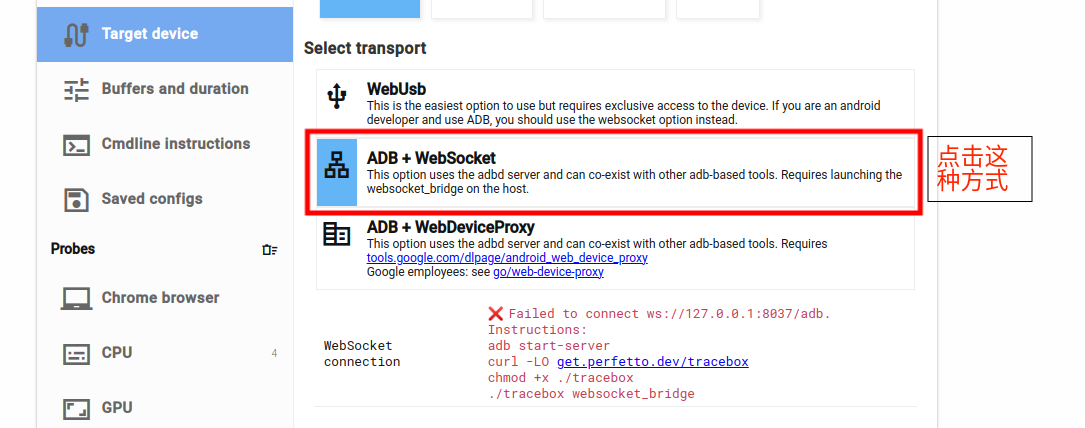
点击这种"ADB + WebSocket"方式后,发现有一堆错误提示,无法链接发现设备。
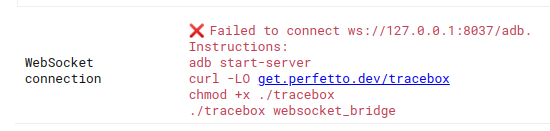
建议我们操作如下几步:
bash
adb start-server
curl -LO get.perfetto.dev/tracebox
chmod +x ./tracebox
./tracebox websocket_bridge上面其实看出,本质上就是下载个tracebox文件,然后执行这个tracebox文件既可以,但是下载这个tracebox文件一般国内网络都不行哈,所以这里可能又会阻碍一批人,不过这里马哥给大家提供一个 ubuntu 64位可以直接执行的文件
https://share.weiyun.com/djrDvGWU 密码:1q95lf
然后运行如下:
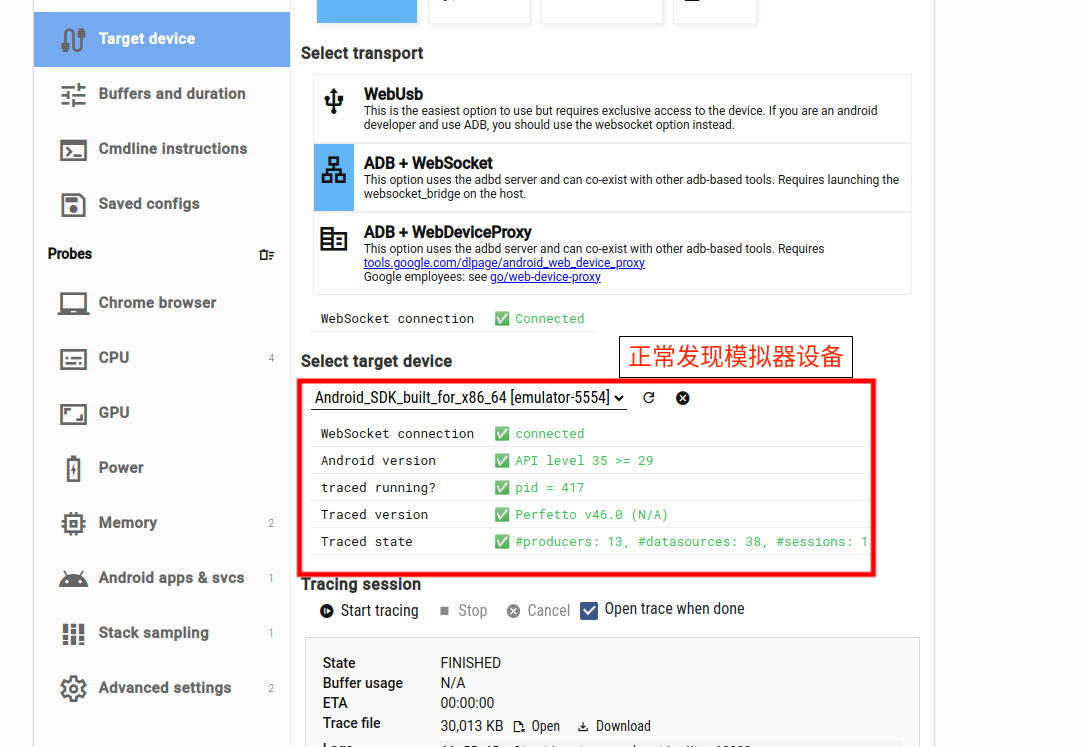
 这里刷新一些画面就可以看到我们的模拟器设备了,可以进行正常抓取了
这里刷新一些画面就可以看到我们的模拟器设备了,可以进行正常抓取了
抓取Perfetto数据如何保存本地?
在chrome网页抓取到相关的trace文件后,网页可以直接查看,也可以左上角看到文件名字,但是这个画面没有看到可以保存这个文件按钮。
因为抓的trace完全有可能要保存下来,或者等待下次再来分析,发送其他同学分析等,那么到底在哪里进行保存呢?
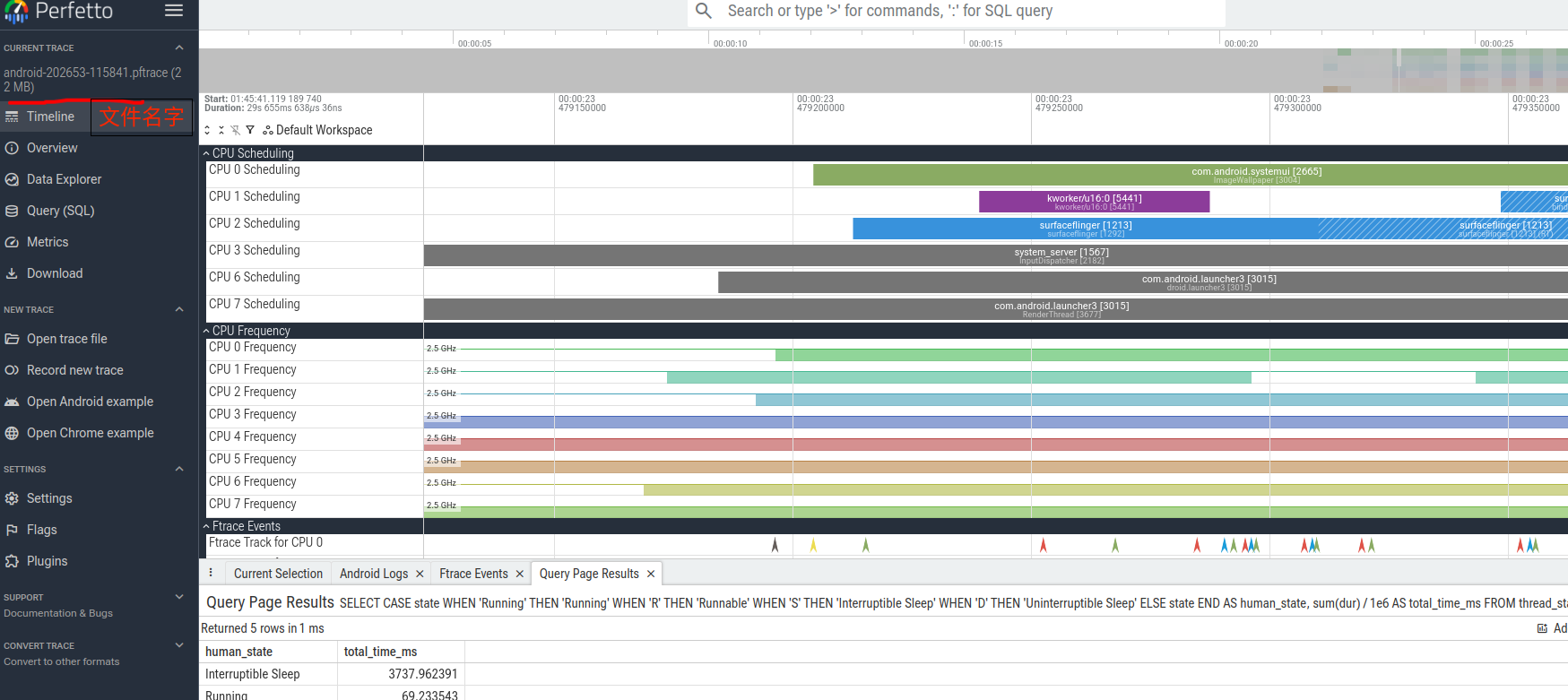
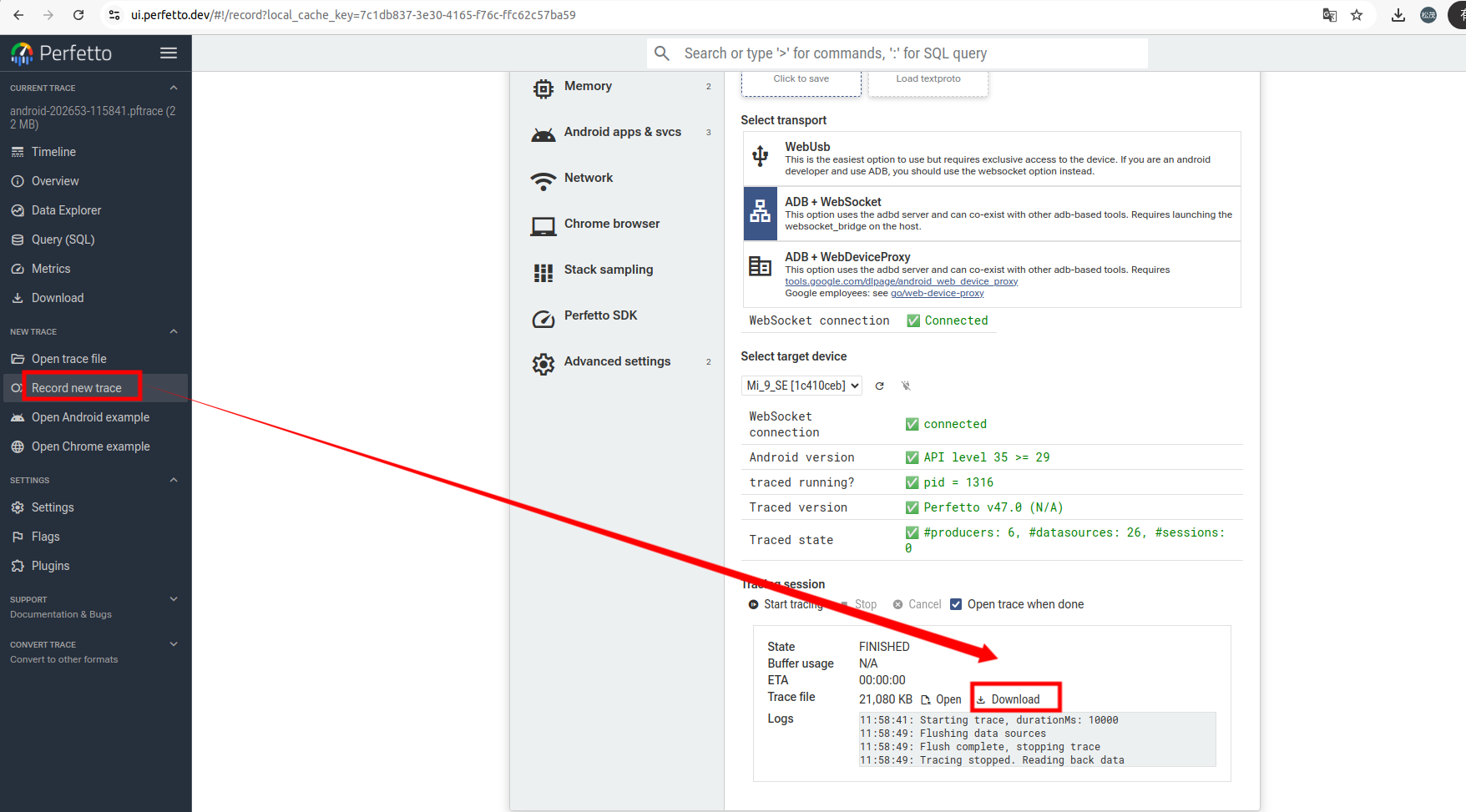
点击左侧的"Record new trace",然后点击Download既可以保存到本地
Pefetto量化分析常用的一些SQL分享
使用 SQL 进行量化分析
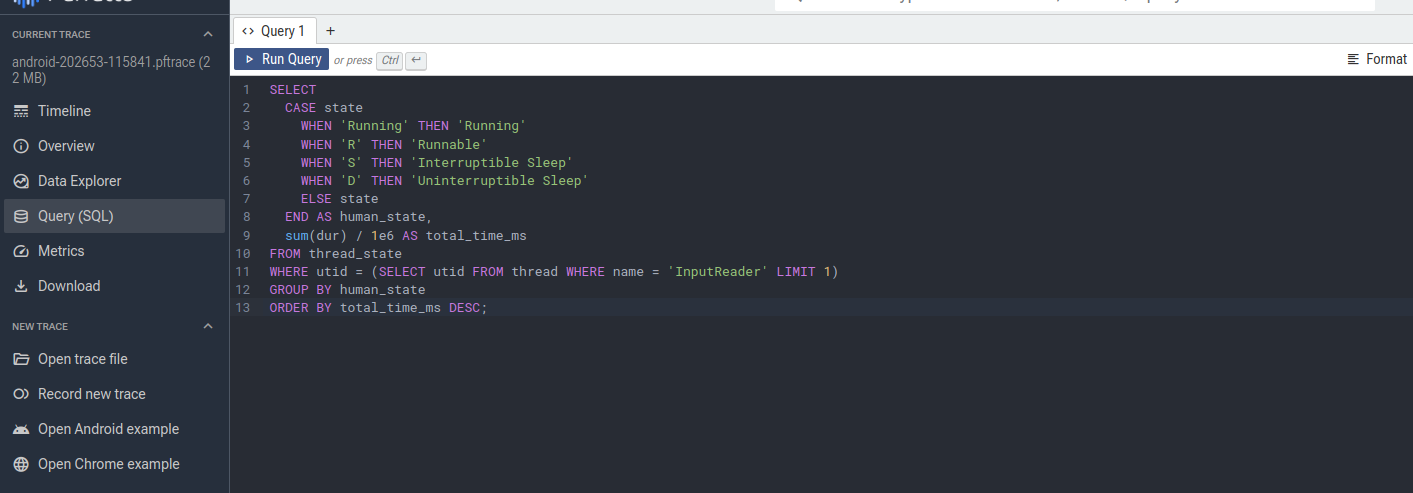
点击左边的Query既可以。
Perfetto 内置的 SQL 查询引擎是其强大功能之一,允许开发者对 Trace 数据进行精确的聚合、筛选和分析。以下是一些常用的 CPU 分析查询。
大家可能会有疑问?为啥一定要sql进行查询量化分析,直接看Perfetto分析不就好了么?
核心原因如下:
Perfetto直接看slice这种方式前提是Perfetto的项目时长都是比较有限,而且你已经有很明确的分析位置,很容易寻找到具体某个时间段瓶颈。
但是在实际性能优化中,你看要分析问题可能是一个时间段内的,比如某个线程的调度延时等,这种你抓某个时间点的就没有意义,必须要进行统计量化才可以减少方差波动等。
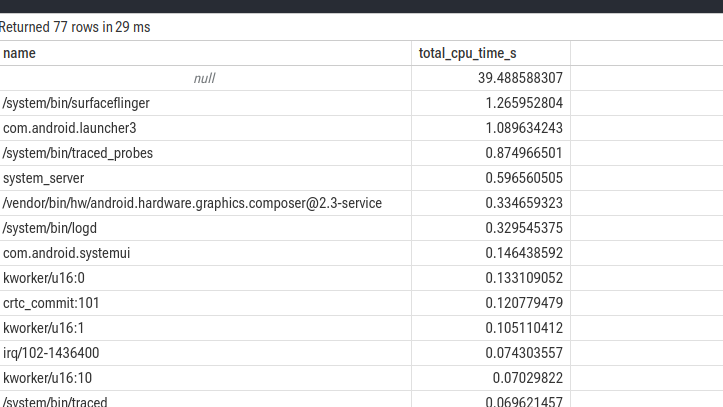
1. 计算各进程的 CPU 总时长
此查询统计每个进程在所有 CPU 上运行的总时长,按降序排列,用于快速定位消耗 CPU 资源最多的进程。
bash
SELECT
process.name,
sum(dur) / 1e9 AS total_cpu_time_s
FROM sched
JOIN thread ON sched.utid = thread.utid
JOIN process ON thread.upid = process.upid
GROUP BY process.name
ORDER BY total_cpu_time_s DESC;结果
2. 分析单个线程的时间状态分布
此查询基于 thread_state 表,可用于分析特定线程(示例为 InputReader)在各种状态下的时间分布,从而判断其主要瓶颈。
bash
SELECT
CASE state
WHEN 'Running' THEN 'Running'
WHEN 'R' THEN 'Runnable'
WHEN 'S' THEN 'Interruptible Sleep'
WHEN 'D' THEN 'Uninterruptible Sleep'
ELSE state
END AS human_state,
sum(dur) / 1e6 AS total_time_ms
FROM thread_state
WHERE utid = (SELECT utid FROM thread WHERE name = 'InputReader' LIMIT 1)
GROUP BY human_state
ORDER BY total_time_ms DESC;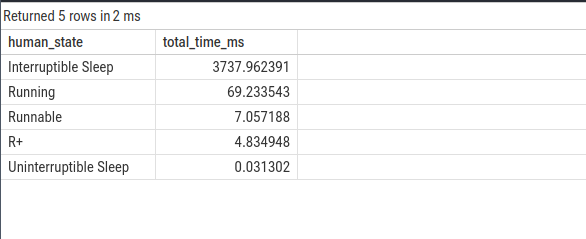
3. 查找特定时间段内 CPU 消耗最高的线程
此查询用于分析特定场景(如应用启动的 2-5s 时间段)中,消耗 CPU 时间最长的线程。
bash
SELECT
thread.name,
sum(dur) / 1e9 AS cpu_time_s
FROM sched
JOIN thread ON sched.utid = thread.utid
-- 时间戳单位为纳秒,可以自己加上 WHERE ts > 2e9 AND ts < 5e9 来取某一段时间
GROUP BY thread.name
ORDER BY cpu_time_s DESC
LIMIT 20;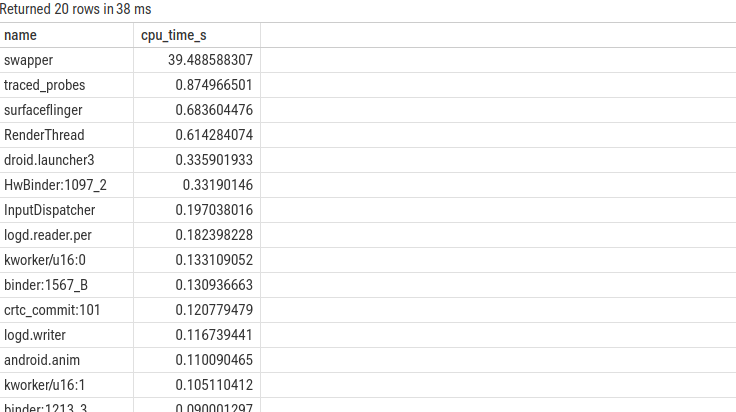
4. 查看线程在各 CPU 核心上的运行时间分布
此查询有助于了解一个线程的 CPU 亲和性,以及它是否在预期的大小核上运行。
bash
SELECT
cpu,
sum(dur) / 1e6 AS time_on_cpu_ms
FROM sched
WHERE utid = (SELECT utid FROM thread WHERE name = 'InputReader' LIMIT 1)
GROUP BY cpu
ORDER BY cpu;可以看出大部分时间在cpu0-1运行

更多fw实战开发干货,原文地址: