基本信息
题目:LiLoc: Lifelong Localization using Adaptive Submap Joining and Egocentric Factor Graph
作者:Yixin Fang, Yanyan Li, Kun Qian, Federico Tombari, Yue Wang, Gim Hee Lee
年份:2024
方向:LiDAR Localization、Lifelong Localization、多 Session 定位、因子图优化、长期定位
核心关键词:Lifelong Localization、Multi-session Mapping、Adaptive Submap Joining、Egocentric Factor Graph、Relocalization、Incremental Localization、Scan Match Factor、Joint Factor Graph Optimization
是否开源:论文中给出了 GitHub 地址,并说明代码将公开。
一句话总结:
LiLoc 是一个面向长期定位任务的图优化框架,它通过维护一个中心 Session 作为先验地图,再让后续子 Session 在已知区域重定位、未知区域增量定位,并利用自适应子图拼接和 Egocentric Factor Graph 将 IMU、LiDAR odometry、scan-to-map 先验约束统一优化,从而提升多 Session 长期定位的精度和稳定性。
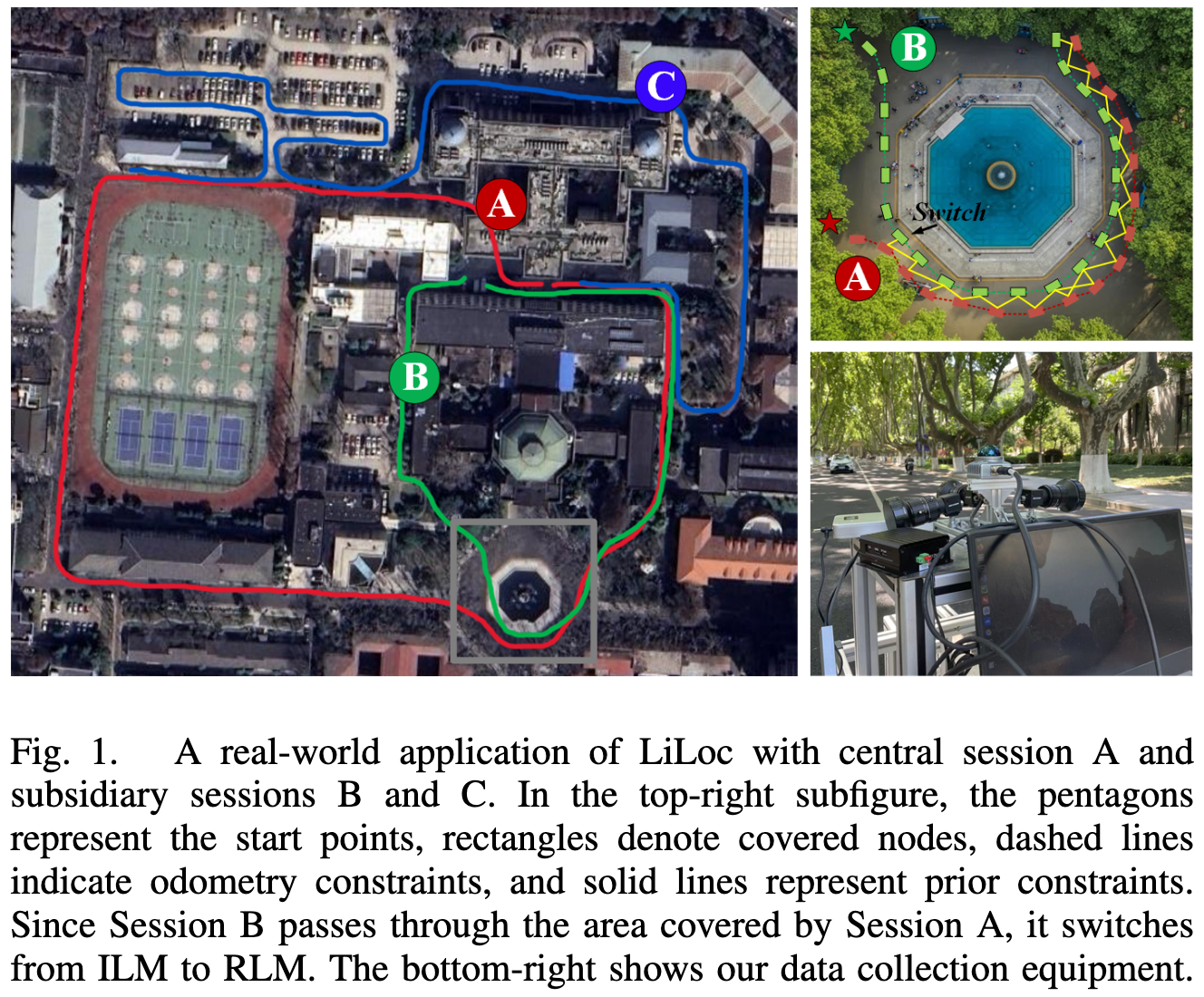
Introduction
长期定位是移动机器人在真实场景中必须解决的问题。机器人并不是只在一次建图后就结束任务,而是会多次回到同一片区域,甚至在环境发生变化后继续运行。例如地下矿区、工业园区、仓储物流、校园道路、长期巡检等场景,都要求机器人能够利用过去的地图,同时适应当前环境的变化。
传统 LiDAR SLAM 或 LiDAR-Inertial Odometry 方法,例如 LOAM、LIO-SAM、FAST-LIO2,通常更关注单次 Session 内部的里程计估计和建图精度。这类方法在单次运行中表现很好,但当任务变成长期多 Session 定位时,会遇到几个问题:
-
先验地图可能很大,直接维护完整大地图会增加内存和匹配开销。
-
当前环境和历史地图之间可能存在差异,直接使用 scan-to-map 结果作为强约束容易引入错误。
-
机器人可能既会经过历史地图覆盖区域,也会进入历史地图没有覆盖的新区域。
-
多 Session 之间的位姿关系不仅需要对齐,还需要在优化层面合理融合。
LiLoc 的核心动机就是解决这些问题。它不是单纯提出一个新的 LiDAR odometry,而是把问题提升到 lifelong localization 的系统层面:如何在已有中心地图的基础上,让后续多次运行都能够稳定、准确地定位,并且在需要时更新地图。
研究问题与目标
本文关注的问题可以概括为:
在长期、多 Session、部分环境变化的场景中,如何利用已有中心 Session 的先验地图,实现后续子 Session 的稳定定位、重定位和增量更新?
具体目标包括:
-
建立一个适合长期定位的中心 Session 与子 Session 交互机制。
-
避免直接维护超大规模全局地图,降低先验地图使用成本。
-
在已知区域使用先验约束提升定位精度。
-
在未知区域允许系统进入增量定位模式,继续扩展先验地图。
-
将 IMU、LiDAR odometry、scan matching 先验约束统一到因子图中进行联合优化。
-
避免过度信任 scan-to-map 配准结果,降低错误先验对定位的负面影响。
主要贡献
论文的主要贡献可以归纳为四点。
第一,提出了一个面向长期定位的图优化框架 LiLoc。
LiLoc 使用一个中心 Session 保存先验知识,后续子 Session 根据是否与先验地图重叠,在 Relocalization Mode 和 Incremental Localization Mode 之间切换。这样系统既可以在旧区域利用先验约束提升精度,也可以在新区域继续增量扩展地图。
第二,提出 Adaptive Submap Joining 自适应子图拼接策略。
论文没有直接使用完整大地图进行定位,而是将中心 Session 划分为多个 prior submap。每个 submap 包含一定数量的关键帧和位姿节点。系统根据当前子 Session 的位置,动态选择或更新相关 submap。这样可以减少内存占用,同时保证先验地图具有时效性。
第三,提出 Egocentric Factor Graph,即 EFG。
EFG 将 IMU preintegration factor、LiDAR odometry factor 和 scan match factor 统一放入联合因子图中优化。相比直接把 scan-to-map 结果作为当前位姿的强约束,LiLoc 的设计更谨慎:它会把先验约束传播到多个相关的 prior pose nodes 上,并根据配准误差设置权重。
第四,提出基于 overlap 的模式切换机制。
系统根据当前扫描和最近 prior submap 的重叠程度,在 RLM 和 ILM 之间切换。重叠度足够高时进入重定位模式,使用先验地图约束当前位姿;重叠度不足时进入增量定位模式,系统继续生成新的 submap 并更新先验数据库。
分析:
LiLoc 的创新并不在于单个低层残差形式,而在于长期定位系统设计。它把先验地图管理、初始化、因子图融合、模式切换四个问题串成了一个完整 pipeline,这一点对实际机器人系统很重要。
Related Works
论文主要对比和关联了以下几类工作。
1. 单 Session LiDAR SLAM / LIO
LOAM 通过提取平面和边缘特征进行 LiDAR odometry 和 mapping。LIO-SAM 在因子图中紧耦合 LiDAR 和 IMU。FAST-LIO2 使用 IESKF 和直接点云匹配提升实时性和精度。
这类方法的问题是:它们主要解决单次建图或单次定位问题,并不直接处理长期多 Session 场景下的先验地图更新、地图复用和环境变化。
2. Global Localization
MCL 和 BBS 等方法可以用于全局定位。它们适合解决初始位姿不确定的问题,但在大规模 3D LiDAR 场景中,计算成本和鲁棒性仍然是挑战。
3. Map-based Localization
HDL-Loc、Fastlio-Loc 等方法通过将当前 scan 和 prior map 匹配来修正 odometry。它们可以利用先验地图,但常见问题是:scan-to-map 配准结果可能受环境变化影响。如果直接把这个结果作为强约束,可能导致定位漂移甚至错误收敛。
4. Factor Graph Assisted Localization
Block-Loc 和一些 range-inertial localization 方法开始把 scan matching factor 加入因子图,通过优化提升定位稳定性。但论文认为,这些方法对 scan matching 约束的不确定性处理仍然不够充分,容易过度依赖先验配准结果。
分析:
LiLoc 和这些方法的区别在于,它不是简单地"当前帧匹配先验地图",而是把先验地图中的相关位姿节点也纳入约束传播过程。也就是说,它试图让先验约束以更合理的形式进入联合优化,而不是把 scan-to-map 配准结果直接当成绝对真值。
Method
系统整体框架
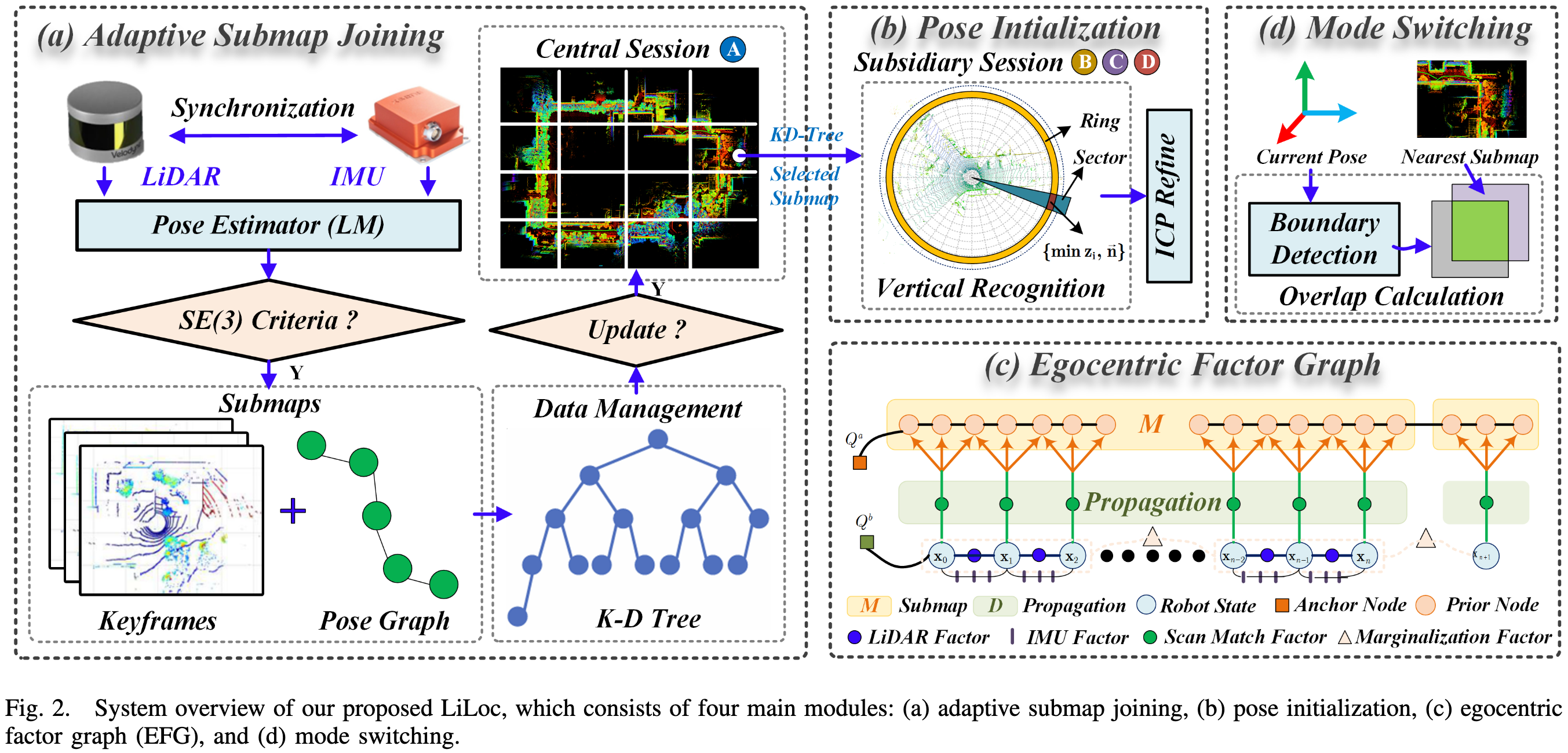
LiLoc 由四个核心模块组成:
-
Adaptive Submap Joining
-
Coarse-to-Fine Pose Initialization
-
Egocentric Factor Graph
-
Mode Switching
论文第 3 页 Fig. 2 给出了完整系统框架。整体流程可以理解为:
中心 Session 建立 prior submap database
↓
子 Session 输入 LiDAR 和 IMU
↓
通过 coarse-to-fine 方法获得初始位姿
↓
根据 overlap 判断进入 RLM 或 ILM
↓
RLM 中选择先验 submap 并构建 scan match factor
↓
ILM 中生成新 submap 并更新先验数据库
↓
EFG 联合优化 IMU、LiDAR odometry、scan matching 约束
↓
输出当前优化位姿
这个框架的重点在于:先验地图不是静态使用的,而是被动态管理;定位模式不是固定的,而是根据场景覆盖关系自动切换;scan matching 不是简单加边,而是通过 propagation model 加入联合图优化。
核心模块一:Adaptive Submap Joining
Adaptive Submap Joining 的作用是管理中心 Session 中的先验地图。
论文将中心 Session 的关键帧和位姿节点划分成多个 submap。每个 submap 最多包含一定数量的关键帧,论文中设定最大关键帧数量为 20,同时还设置了平移阈值 20 m。当关键帧数量达到上限,或者当前位姿相对上一个 submap 的末端位姿平移超过阈值时,就生成新的 submap。
该模块包含三个操作:
1. Generate
在中心 Session 中,根据关键帧数量和 SE(3) 位姿距离生成 prior submap。每个 submap 保存局部关键帧点云和对应 pose graph 信息。
2. Select
当子 Session 运行在已知区域,也就是 RLM 模式时,系统根据当前位姿在 prior pose kd-tree 和 submap centroid kd-tree 中搜索最近的先验节点和先验 submap。
3. Update
当子 Session 进入未知区域,也就是 ILM 模式时,系统不再强行使用已有 prior submap,而是根据当前运行结果生成新的 submap,并更新先验数据库。
分析:
这个模块解决的是长期定位系统中非常实际的问题:先验地图既不能完全固定,也不能无限膨胀。LiLoc 通过 submap 级别的动态管理,让系统在已知区域"复用地图",在未知区域"扩展地图"。
核心模块二:Coarse-to-Fine Pose Initialization
子 Session 要想进入中心 Session 的全局坐标系,首先需要一个较好的初始位姿。LiLoc 使用 coarse-to-fine 的初始化策略。
整体过程为:
-
给定一个粗略初始位姿。
-
根据粗略位姿选择最相关的 prior submap。
-
将当前 keyframe 点云转换到极坐标表示。
-
将点云划分为方位角 sector 和半径 ring。
-
使用类似 Scan Context 的垂直结构描述方式进行候选关键帧识别。
-
从 prior submap 中找到最相似的候选 keyframe。
-
使用 ICP 进一步细化初始位姿。
论文中的初始化实验显示,该方法在精度和时间之间取得了较好平衡。相比 FPFH + RANSAC、FPFH + Teaser、FPFH + Quatro 等方法,LiLoc 初始化速度明显更快;相比 BBS++,精度接近但耗时略高。
论文中 Table I 的结果可以概括为:
| 方法 | xyz 误差 | rpy 误差 | F-Score | 时间 |
|---|---|---|---|---|
| FPFH + RANSAC | 0.33 m | 0.12 rad | 0.24 | 56.36 s |
| FPFH + Teaser | 0.19 m | 0.10 rad | 0.17 | 35.50 s |
| FPFH + Quatro | 0.14 m | 0.11 rad | 0.16 | 31.62 s |
| BBS | 5.00 m | - | - | 9.82 s |
| BBS++ | 0.05 m | - | - | 0.87 s |
| Ours | 0.07 m | 0.08 rad | 0.12 | 1.63 s |
分析:
这部分的设计比较工程化。它不是直接在全局地图里做昂贵搜索,而是在选中的 submap 内做候选识别和 ICP refinement,从而减少搜索空间。对长期定位系统来说,初始化模块很关键,因为后续因子图优化通常依赖较合理的初值。
核心模块三:Egocentric Factor Graph
EFG 是 LiLoc 的核心。它将多个传感器和先验信息放入统一因子图中优化。
论文中的优化目标可以理解为:
当前子 Session 的位姿估计,不仅要满足 IMU 运动约束和 LiDAR odometry 约束,还要在 RLM 模式下满足来自中心 Session 的 scan matching 先验约束。
EFG 主要包含三类因子。
1. IMU Preintegration Factor
IMU preintegration 用于在相邻关键帧之间提供高频运动预测。它约束旋转、位置和速度,并联合优化 IMU bias。
作用:
-
提供短时间内的运动连续性。
-
支持点云去畸变。
-
提供 LiDAR odometry 的初始估计。
-
在点云退化场景中增强状态估计稳定性。
2. LiDAR Odometry Factor
当新的 LiDAR scan 到来时,系统先利用 IMU preintegration 进行点云去畸变,然后使用 ikd-tree 管理地图点。对于新的 keyframe,系统搜索近邻点并构建点到局部平面的距离残差,再通过 LM 算法求解当前 LiDAR 位姿。
作用:
-
估计子 Session 内部相邻关键帧之间的相对运动。
-
为局部因子图提供主要几何约束。
-
保证即使在没有 prior map 的区域,系统仍能进行增量定位。
3. Scan Match Factor
这是 LiLoc 相比其他 map-based localization 方法最值得关注的部分。
传统做法通常是:将当前 scan 与 prior map 配准,得到一个相对位姿,然后直接把这个相对位姿作为当前节点的约束加入因子图。
问题是:scan-to-map 配准并不总是可靠。环境变化、动态物体、遮挡、结构重复、初值误差都可能导致配准误差。如果把错误的 scan matching 结果当成强约束,系统反而会被先验地图拉偏。
LiLoc 的做法是引入 propagation model。
具体来说,系统先用 NDT 计算当前 scan 在全局坐标系下的配准变换,然后在 prior pose tree 中搜索最近的 3 个 prior pose nodes。接着系统计算当前 scan 和这些 prior keyframes 的 registration fitness score,并将 scan matching 约束分配到多个相关 prior nodes 上,同时根据配准误差设置噪声权重。
这样做的好处是:
-
不把先验约束集中压到一个单点上。
-
让当前图和先验图之间形成更多边。
-
用 registration error 调整约束可信度。
-
降低错误 scan matching 对当前位姿的破坏。
-
更适合环境变化下的长期定位。
分析:
这部分是 LiLoc 最核心的创新。它的思想不是"有 prior map 就强行相信 prior map",而是"让 prior constraint 以带不确定性的形式参与联合优化"。这对长期定位非常重要,因为长期场景中先验地图一定会老化,当前观测和历史地图之间一定会存在差异。
核心模块四:Mode Switching
LiLoc 支持两种模式:
1. RLM:Relocalization Mode
当当前 scan 与最近 prior submap 的 overlap 足够高时,系统进入 RLM。在这个模式下,说明机器人正在经过已有地图覆盖区域,因此可以利用 prior submap 构建 scan match factor,提高定位精度。
2. ILM:Incremental Localization Mode
当当前 scan 与 prior submap 的 overlap 不足时,系统进入 ILM。在这个模式下,说明机器人可能进入了先验地图未覆盖区域,因此系统不再强行使用 prior constraints,而是基于自身 LiDAR-Inertial Odometry 继续增量定位,并生成新的 submap 更新数据库。
论文使用 overlap ratio 判断模式切换,阈值设为 0.7。
分析:
这个设计很实用。长期定位系统最大的难点之一是"什么时候该相信先验地图,什么时候不该相信先验地图"。LiLoc 用 overlap 来判断模式,虽然方法比较简单,但可以避免系统在未知区域仍然强行与历史地图匹配。
Experiments
论文在两个公开数据集和一个自采数据集上进行了实验:
-
NCLT
-
M2DGR
-
Custom dataset
对比方法包括:
-
LIO-SAM
-
FAST-LIO2
-
HDL-Loc
-
Fastlio-Loc
-
Block-Loc
评价指标主要包括:
-
xyz RMSE
-
xyz rpy RMSE
-
time cost
-
pose initialization error
-
ICP fitness score
-
multi-session localization success / failure
单 Session 实验分析
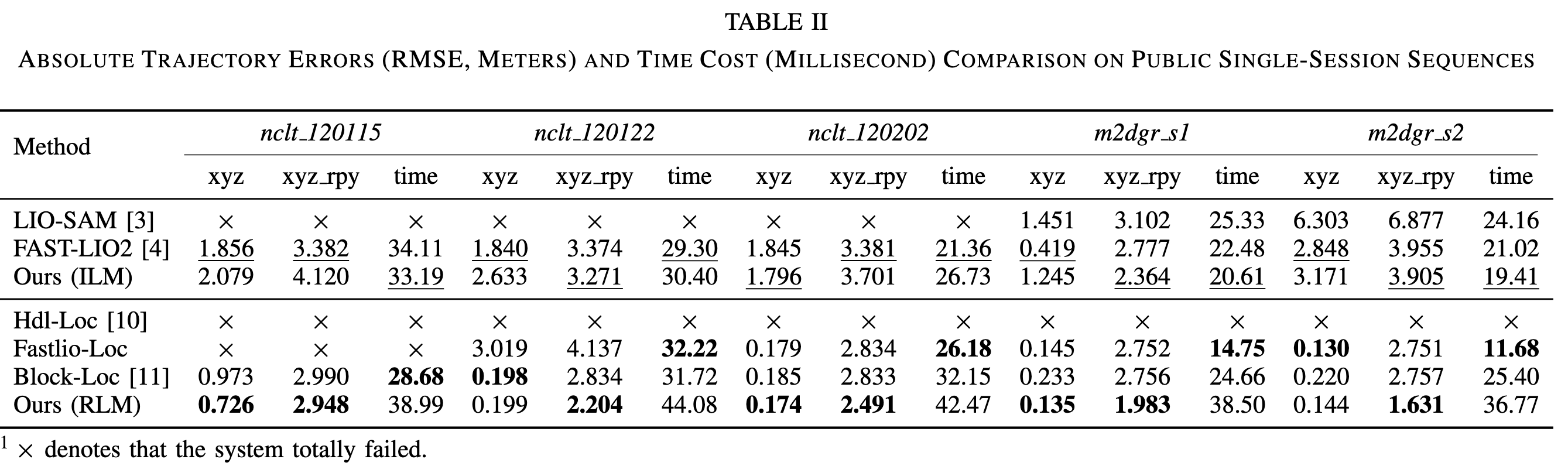
在 ILM 模式下,LiLoc 更接近一个 LiDAR-Inertial Odometry 系统。实验中 FAST-LIO2 在部分序列上表现稳定且效率高,而 LiLoc 的 ILM 表现整体与主流 LIO 方法接近。
在 RLM 模式下,LiLoc 的优势更明显。它利用 prior submap 和 EFG 中的 propagation model,在多个公开序列上取得了比 HDL-Loc、Fastlio-Loc、Block-Loc 更好的 xyz 和 xyz rpy 精度。
从 Table II 可以看到,LiLoc 在 RLM 下的定位精度通常优于 Block-Loc。例如在多个 NCLT 和 M2DGR 序列中,LiLoc 的 xyz RMSE 能达到 0.1 m 到 0.7 m 量级,表现比较稳定。
但同时,RLM 模式下 LiLoc 的时间成本也更高。这是因为它需要进行 joint factor graph optimization,并构建更多 prior constraints。
分析:
LiLoc 的精度收益主要来自两个方面:
-
使用 prior map 提供全局约束。
-
通过 propagation model 更合理地利用 scan matching 约束。
但精度提升不是免费的,代价是优化耗时增加。
多 Session 实验分析
多 Session 实验是这篇论文最重要的验证部分。
论文在 NCLT 和自采数据集上进行多 Session 定位实验。结果显示,HDL-Loc 和 Block-Loc 在部分多 Session 场景中会失败,因为它们不能灵活切换到 ILM;Fastlio-Loc 虽然速度较快,但稳定性不足;LiLoc 由于支持 RLM / ILM 自动切换,在多 Session 场景中表现更可靠。
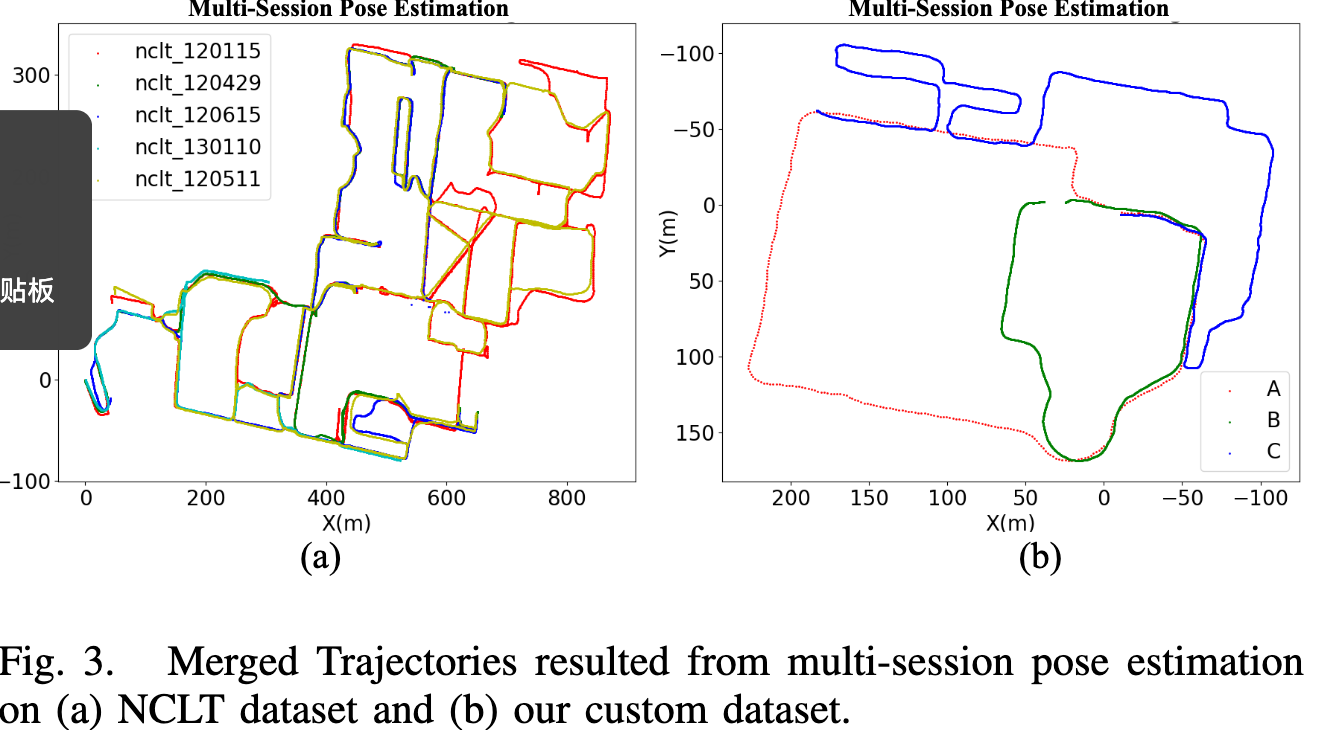
论文第 5 页 Fig. 3 展示了多 Session 轨迹融合结果,第 6 页 Fig. 4 展示了 NCLT 和自采数据集上的 merged maps。可以看到,不同 Session 的轨迹和点云地图被统一到了中心 Session 的全局坐标系中。右侧局部细节图用于说明不同 Session 点云之间的对齐质量。

Table III 中还对 active prior nodes 数量进行了分析。结果显示,prior nodes 数量过少时,系统可能失败或精度下降;prior nodes 数量更多时,定位精度通常更好,但时间成本也会增加。
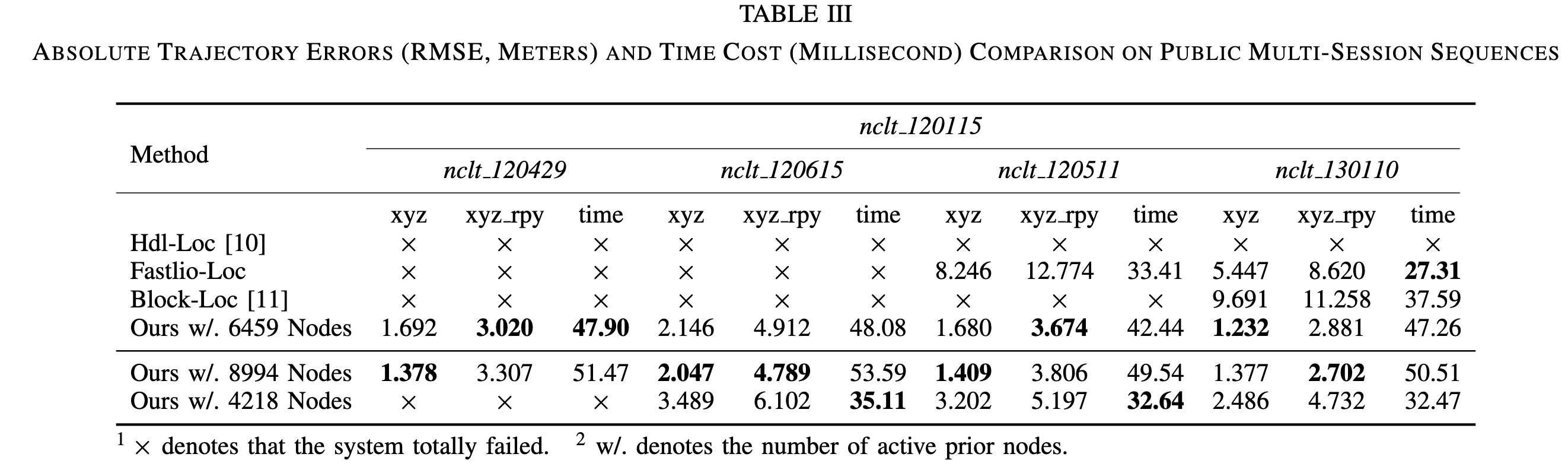
分析:
这说明 LiLoc 的 prior knowledge 数量和质量对性能非常关键。它不是一个完全不依赖先验地图规模的方法,而是通过 submap joining 和 kd-tree 管理来尽量控制先验使用成本。
Time Cost 分析
论文第 6 页 Fig. 5 展示了 LM solver 和 EFG 中 JFGO 的耗时变化。作者指出 JFGO 大约需要 10-20 ms,相比部分 baseline 会稍慢。
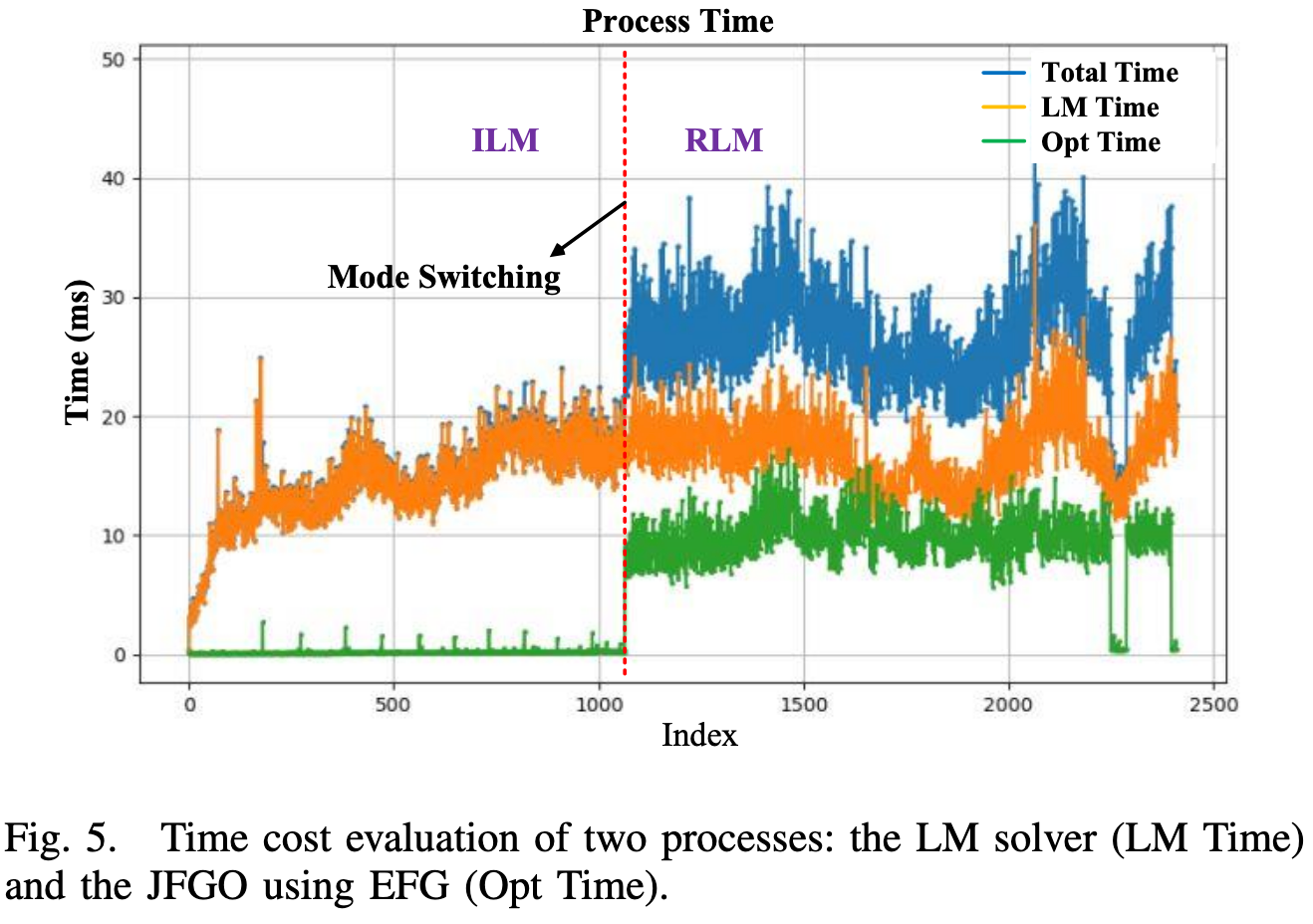
这个结果说明 LiLoc 是一个偏精度和鲁棒性的长期定位框架,而不是极限轻量化方法。对于长期定位、多 Session 任务来说,这个时间成本可能是可以接受的;但如果部署到资源受限平台,例如低功耗 ARM 或无人机板载计算平台,则需要进一步优化。
创新点总结
创新点一:长期定位任务建模更完整
LiLoc 没有只做单帧 scan-to-map localization,而是从 multi-session lifelong localization 的角度建模问题。中心 Session 提供先验知识,子 Session 根据场景覆盖情况选择重定位或增量定位。
这一点很适合真实机器人长期运行。
创新点二:Adaptive Submap Joining
论文通过 submap 级别管理 prior map,而不是直接加载完整大地图。这种设计兼顾了地图复用、地图更新和内存控制。
对长期定位来说,这比单纯维护全局点云地图更合理。
创新点三:EFG 中的 propagation model
传统 scan matching factor 往往直接把当前 scan 与 prior map 的配准结果作为约束。LiLoc 则把这个约束传播到多个相关 prior pose nodes,并根据 registration fitness score 设置噪声权重。
这个设计可以看作对 prior constraint 的不确定性建模,减少错误先验导致的定位漂移。
创新点四:RLM / ILM 自动切换
LiLoc 通过 overlap 判断当前是否处于已有地图覆盖区域。已知区域使用 RLM,未知区域使用 ILM。这使系统可以同时处理重定位和新区域增量建图。
创新点五:系统工程完整度较高
论文不是只提出一个模块,而是把初始化、地图管理、因子图优化、模式切换、边缘化、实验验证都串起来,形成了完整系统。
论文优势
1. 面向实际长期定位问题
很多 SLAM 方法只关注单次运行精度,但 LiLoc 关注的是多 Session 长期定位,这更接近真实机器人部署需求。
2. 先验地图使用方式更合理
LiLoc 没有盲目使用完整 prior map,而是通过 submap joining 动态选择相关先验。这种方式更适合大规模环境。
3. 对 scan matching 约束的不确定性处理更充分
Propagation model 是本文最有价值的设计之一。它避免了直接相信 scan-to-map 配准结果,使先验约束更加柔性。
4. 支持已知区域和未知区域
RLM / ILM 模式切换使系统不仅可以在历史地图中定位,也可以在新区域继续运行并更新地图。
5. 多 Session 实验验证充分
论文不仅做了单 Session 对比,还做了多 Session 轨迹和地图融合实验,这与 lifelong localization 的任务目标一致。
6. 指标设计适合作为论文对比对象
论文使用 xyz RMSE、xyz rpy RMSE、time cost、初始化误差、F-Score、多 Session 成功率等指标,比较适合作为长期定位或地图复用类论文的对比基准。
对自己论文可以借鉴的地方
如果这篇论文是你论文中主要的方法和指标对比对象,可以重点借鉴以下几个方面。
1. 任务定义方式
LiLoc 将 lifelong localization 定义为一个 central session + subsidiary sessions 的多 Session 定位问题。这个定义很清晰,适合在论文中作为长期定位任务的背景描述。
可以借鉴的表述是:
给定一个中心 Session 的先验地图和位姿图,目标是在后续子 Session 中持续估计机器人在中心坐标系下的 LiDAR 位姿,并在必要时更新先验地图。
2. 对比指标
可以参考 LiLoc 的指标体系:
| 指标 | 含义 | 适用场景 |
|---|---|---|
| xyz RMSE | 平移误差 | 定位精度评价 |
| xyz rpy RMSE | 平移 + 姿态综合误差 | 6DoF 定位评价 |
| time cost | 单帧处理时间 | 实时性评价 |
| initialization xyz / rpy | 初始位姿估计误差 | 全局初始化评价 |
| F-Score | 点云配准质量 | 初始化或 scan matching 评价 |
| success / failure | 系统是否失效 | 多 Session 鲁棒性评价 |
| active prior nodes | 先验节点数量 | 地图规模影响分析 |
3. Baseline 选择
LiLoc 对比了 SLAM、LIO 和 localization 方法。自己的论文如果也是长期定位方向,可以考虑类似分组:
-
LIO baseline:LIO-SAM、FAST-LIO2
-
Map-based localization baseline:HDL-Loc、Fastlio-Loc
-
Factor graph prior map localization baseline:Block-Loc
-
自己的方法
这样对比逻辑比较完整:既能证明在单 Session 下不差,也能证明在多 Session 和 prior map 使用上有优势。
4. Ablation 设计
LiLoc 对 active prior nodes 数量进行了实验分析。自己的论文可以进一步设计更完整的消融:
-
去掉 mode switching
-
去掉 prior constraint
-
直接 scan matching factor vs propagation factor
-
固定 submap vs adaptive submap
-
不同 prior map size
-
不同 overlap threshold
-
不同 dynamic scene ratio
这样可以更清楚地说明每个模块带来的贡献。
5. 系统图表达方式
论文第 3 页 Fig. 2 的系统图值得借鉴。它把四个模块分区展示,每个模块只表达核心输入输出关系。自己的论文中也可以采用类似方式,把系统分成:
-
Prior map management
-
Initialization
-
Local odometry
-
Prior factor construction
-
Graph optimization
-
Mode switching
论文不足
1. 对初始粗位姿仍有依赖
LiLoc 的 coarse-to-fine initialization 需要一个 coarse pose estimate。虽然后续有 vertical recognition 和 ICP refinement,但如果初始位姿偏差过大,或者环境结构高度重复,初始化仍可能失败。
改进方向:
可以引入更全局的 place recognition,例如 Scan Context、M2DP、OverlapNet、LCDNet 或学习型点云描述子,降低对粗位姿的依赖。
2. Overlap-based mode switching 比较简单
论文使用 overlap ratio 判断 RLM 和 ILM,阈值设置为 0.7。这种规则简单有效,但可能对 submap 尺寸、定位误差、场景开阔程度比较敏感。
例如在长走廊、稀疏场景、结构重复区域中,overlap 高不一定代表 scan matching 可靠;overlap 低也不一定表示应该放弃 prior map。
改进方向:
可以把 overlap、NDT fitness、ICP residual、局部几何退化程度、历史模式稳定性一起作为模式切换依据,构建 uncertainty-aware switching。
3. 对动态环境的处理还不够充分
LiLoc 使用 registration fitness score 调整 scan matching factor 的噪声,这可以一定程度上降低错误配准影响。但论文没有显式处理动态物体、长期结构变化、遮挡变化等问题。
改进方向:
可以加入动态点剔除、语义分割、长期稳定结构提取、change detection,尽量只使用稳定结构构建 prior constraints。
4. 计算成本相对更高
RLM 模式下需要进行 prior submap 查询、scan matching factor 构建以及 joint factor graph optimization,因此耗时高于一些轻量级 localization 方法。论文中也提到 JFGO 约为 10-20 ms,并且 RLM 表格中的整体 time cost 相对更高。
改进方向:
可以引入局部图裁剪、稀疏先验节点选择、GPU 加速、并行 scan matching、固定 lag smoother 或增量式优化策略。
5. Prior nodes 数量对性能影响较明显
Table III 显示 active prior nodes 数量会影响多 Session 定位结果。节点太少时,系统可能失败;节点更多时精度更好,但时间成本增加。这说明系统对 prior map 覆盖和节点选择策略仍然敏感。
改进方向:
可以设计自适应 prior node selection 策略,根据当前不确定性、环境复杂度和计算预算动态选择先验节点数量。
6. 实验还可以更全面
论文已经包含 NCLT、M2DGR 和自采数据集,但对于 lifelong localization 来说,还可以增加更多长期变化维度,例如季节变化、施工变化、动态障碍密集场景、大规模地下场景、跨设备 LiDAR 场景等。
此外,论文主要报告 RMSE 和时间,缺少内存占用、CPU 使用率、地图增长率、失败率统计、重定位成功率等工程指标。
改进方向:
在后续工作中可以补充:
-
memory cost
-
CPU usage
-
map size growth
-
relocalization success rate
-
localization recovery time
-
failure case analysis
-
robustness under environmental change
7. 多机器人扩展仍未完成
论文结论中提到未来会扩展到 multi-robot exploration,但当前系统主要还是 central session 与 subsidiary session 的单机器人长期定位框架。
改进方向:
可以进一步研究分布式因子图、多机器人地图合并、通信受限条件下的 submap sharing、多机器人冲突约束处理等问题。
可以改进的研究方向
结合论文内容,我认为后续可以从以下方向扩展。
1. Uncertainty-aware Prior Factor
当前 propagation model 使用 registration fitness score 调整噪声,但这个不确定性仍然比较启发式。可以考虑从 NDT Hessian、ICP covariance、局部几何退化指标中估计更严格的配准协方差。
2. Switchable Constraint / Robust Kernel
在因子图中加入 switchable constraint 或 dynamic covariance scaling,让系统自动判断某个 prior factor 是否可信。如果先验约束与当前 odometry 严重冲突,可以自动降低其权重甚至关闭。
3. Semantic Stable Landmark
长期定位最可靠的约束通常来自稳定结构,例如墙面、柱子、路缘、建筑立面,而不是车辆、行人、临时障碍。可以通过语义分割或长期观测频率提取稳定 landmark,再构建 prior constraints。
4. Hierarchical Map Management
目前 LiLoc 使用 submap 和 kd-tree 管理先验地图。进一步可以构建层次化地图:
-
global place descriptor layer
-
submap retrieval layer
-
local geometric matching layer
-
factor graph constraint layer
这样可以更好地兼顾全局检索和局部优化。
5. Learning-based Place Recognition
Coarse-to-fine initialization 可以加入学习型点云检索模型,提升在弱结构、重复结构和大初值误差下的定位成功率。
6. 更完整的长期 Benchmark
如果自己的论文要与 LiLoc 对比,可以设计更强的 lifelong benchmark,不只比较 RMSE,还比较:
-
多次运行后的地图增长情况
-
跨时间定位一致性
-
环境变化下的鲁棒性
-
无 prior 覆盖区域的恢复能力
-
从 ILM 切回 RLM 的稳定性
-
长时间运行的内存和 CPU 曲线
总结
LiLoc 是一篇系统性较强的长期定位论文。它的重点不是提出一个全新的 LiDAR odometry 前端,而是围绕 lifelong localization 的实际需求,设计了一个包含先验地图管理、位姿初始化、联合因子图优化和模式切换的完整框架。
论文最值得关注的创新是 Egocentric Factor Graph 中的 propagation model。它没有直接把 scan-to-map 配准结果当作强约束,而是将先验约束传播到多个相关 prior pose nodes,并根据 registration fitness score 调整噪声。这种处理方式更符合长期定位中"先验地图有用,但不一定完全可靠"的现实情况。
从实验结果看,LiLoc 在 RLM 和多 Session 场景中表现较好,尤其适合作为长期定位、多 Session 定位、先验地图辅助定位类论文的主要对比对象。它的不足主要在于对初始粗位姿仍有依赖、模式切换机制较简单、动态环境处理不足、计算成本偏高,以及 prior node 数量对性能影响明显。
如果在自己的论文中借鉴 LiLoc,可以重点学习它的任务建模方式、指标设计、baseline 选择、系统图表达和多 Session 实验设置。同时,也可以针对它的不足设计改进方法,例如不确定性感知先验因子、鲁棒约束开关、动态物体剔除、层次化地图管理和更完整的长期定位 benchmark。
整体来看,LiLoc 的价值在于:它把长期定位中的几个关键工程问题串成了一个完整系统,并通过因子图方式对先验约束进行更合理的融合。对于做长期定位、地图复用、多 Session SLAM 或 prior map localization 的研究来说,这篇论文非常值得作为方法对比和指标设计参考。