这篇题为 《Large Language Diffusion Models》(LLaDA) 的论文是自然语言处理(NLP)和生成式AI领域的一项突破性研究。它由中国人民大学高瓴人工智能学院和蚂蚁集团的研究团队共同完成。
这篇论文的核心价值在于:它打破了"只有自回归模型(ARM,即从左到右逐词预测)才能实现大语言模型(LLM)核心能力"的固有认知。 研究团队从零开始训练了一个80亿(8B)参数的扩散模型(Diffusion Model)------LLaDA,证明了扩散模型在规模化、上下文学习(In-context learning)和指令遵循(Instruction-following)方面,完全可以媲美甚至在某些维度超越当前主流的自回归大模型(如 LLaMA-3)。
以下是对该论文的详细深度解读:
一、 研究背景与核心动机
- 当前范式的统治地位与痛点:
目前的LLM(如GPT-4, LLaMA)几乎全部基于自回归模型(Autoregressive Models, ARM) ,即"下一个词预测"(Next-token prediction)。虽然非常成功,但这种从左到右的单向生成机制导致了一个著名的缺陷------逆向诅咒(Reversal Curse)。例如,模型知道"A是B",却无法反向推理出"B是A";能顺背诗词,却无法倒背或根据下一句写上一句。 - 作者的核心洞察:
作者提出一个深刻的问题:LLM的强大能力(涌现能力、规模法则),到底是来源于"自回归(从左到右)"这种特殊形式,还是来源于"生成式建模原则"(即用海量数据优化极大似然估计)+"强大的Transformer架构"?
作者认为是后者。因此,如果用其他生成式框架(如扩散模型)来做语言建模,只要符合上述原则,也应该能具备LLM的能力。
二、 LLaDA 的核心机制
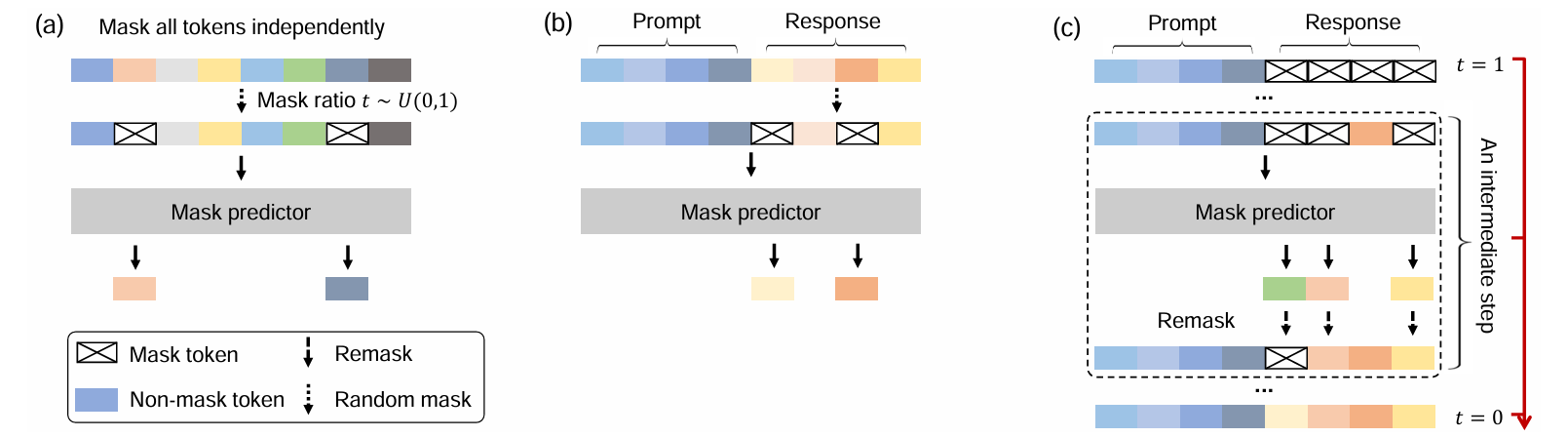
- 图1:LLaDA整体架构。a) 预训练:LLaDA在文本上进行训练,所有token以相同比例
t ~ U[0,1]被独立随机掩码。b) 监督微调(SFT):仅对回复部分的token进行掩码处理。c) 采样:LLaDA模拟从t=1(全掩码)到t=0(无掩码)的扩散过程,每一步通过灵活的重掩码策略同时预测所有掩码位置。
LLaDA 没有采用生成图像时常用的连续加噪扩散,而是采用了掩码离散扩散模型(Masked Diffusion Model, MDM)。
- 前向过程(加噪/掩码):
给定一段真实的文本序列,模型在时间步 t∈0,1t \in 0,1t∈0,1 内,随机将文本中的Token替换为[MASK](掩码)。t=0t=0t=0 时是完整无缺的文本,t=1t=1t=1 时文本100%被掩码覆盖。 - 逆向过程(去噪/生成):
训练一个 Transformer 作为掩码预测器(Mask Predictor) 。与传统的因果掩码(Causal Mask,只能看前面的词)不同,LLaDA的Transformer不使用因果掩码 ,它可以双向 看到序列中所有未被Mask的词,然后同时预测所有被Mask的词。 - 预训练(Pre-training):
- 规模:8B 参数,从头开始在 2.3万亿(2.3T)个Token的语料上训练(耗费 13万 H800 GPU小时)。
- 目标:优化模型对Mask token的交叉熵损失。这在数学上被证明是模型对数似然的变分下界,属于原则性的概率生成建模。
- 监督微调(SFT):
为了让模型学会对话,作者使用450万条问答对进行SFT。训练时,提示词(Prompt)保持可见,只对回答(Response)部分进行随机掩码,让模型学习在给定Prompt的情况下复原Response。 - 推理与采样(Inference):
生成文本时,不是从左到右逐字生成。而是:- 设定一个全
[MASK]的序列。 - 模型一次性预测所有的字。
- 根据置信度,保留一部分确定性高的字,把确定性低的字重新掩码(Remasking)。
- 重复上述过程,直到所有
[MASK]都变成真实的字。
- 设定一个全
三、 核心实验结果与发现
论文进行了极其详尽的实验,对比了相同规模的自回归模型(ARM)以及开源界的标杆 LLaMA系列。
1. 规模法则(Scalability)被验证
在 102010^{20}1020 到 102310^{23}1023 FLOPs 的计算预算下,LLaDA的性能随着算力的增加而稳步提升,其Scaling Law 曲线与自回归模型几乎完全一致 ,甚至在 MMLU 和 GSM8K(数学)任务上,LLaDA 的增长势头比 ARM 更猛。
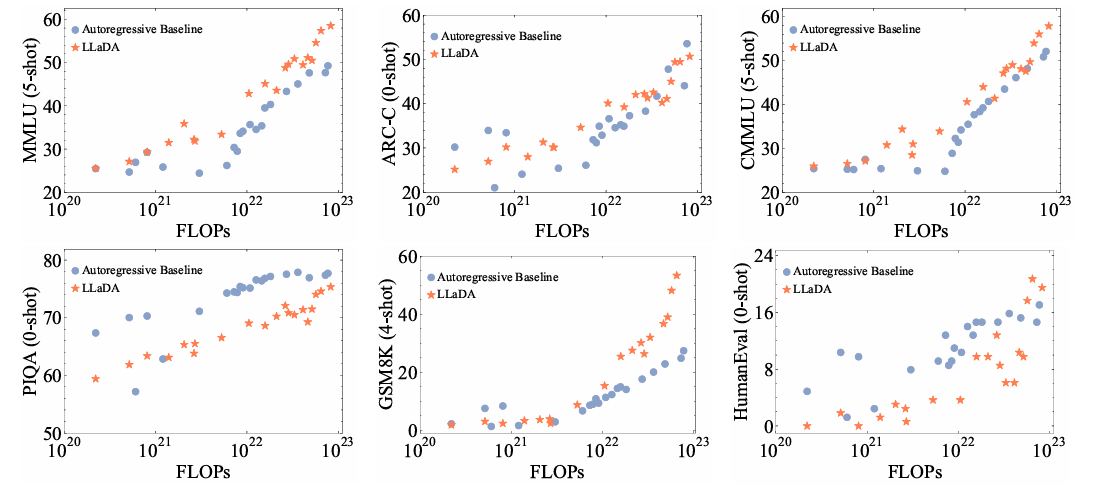
- 图2:LLaDA的可扩展性。在不断增加的预训练计算量(FLOPs)下,评估了在相同数据上训练的LLaDA与自回归模型(ARM)基线的性能。LLaDA展现出强劲的可扩展性,在六项任务上与自回归模型的整体性能相当。
2. 基础能力比肩 LLaMA-3 8B
在零样本/少样本学习(Zero/few-shot)的15个标准基准测试中:
- LLaDA 8B 预训练模型全面超越了 LLaMA-2 7B。
- LLaDA 8B 预训练模型总体媲美了 LLaMA-3 8B,尤其在数学(Math, GSM8K)和中文(CMMLU, C-Eval)任务上表现出优势。
3. 惊艳的指令遵循与多轮对话能力
在经过SFT之后,LLaDA 展现出了和GPT类似的聊天能力。这在非自回归模型中是史无前例的。论文附带的Case Study展示了它可以进行流畅的多轮对话、跨语言翻译、写代码和做数学题。

4. 彻底打破"逆向诅咒"
为了测试双向推理能力,作者构建了一个"中国古诗词补全"任务:
- 前向(给上一句,接下一句): GPT-4o 准确率 82.7%,LLaDA 51.8%。
- 逆向(给下一句,推上一句): GPT-4o 暴跌至 34.3%,而 LLaDA 高达 45.6% (几乎与前向能力持平)。
结论: 由于LLaDA是全局双向建模,它对待所有位置的Token是一视同仁的,天生免疫自回归模型从左到右带来的逆向思维缺陷。
5. 灵活的生成效率控制
自回归模型必须逐字生成,而 LLaDA 可以通过**调整采样步数(Sampling Steps)**来平衡质量与速度。实验表明,设置较少的步数时,它能以比LLaMA-3更快的速度生成,且保持相当的性能。同时,因为不需要维护庞大的 KV Cache,其显存占用更加稳定。
四、 论文的重大贡献与学术意义
- 范式转移(Paradigm Shift): 整个AI界都在疯狂卷"Next-token prediction",这篇论文敲响了另一扇门,证明了"Diffusion is all you need for LLM"是完全可行的。
- 解决固有缺陷: 完美展示了双向注意力在解决知识逆向调用(Reversal Curse)上的天然优势,这对于需要复杂逻辑回溯、定理证明、多维度规划的AGI任务具有重大启示。
- 开源生态贡献: 作为一个8B级别的非自回归大模型,其性能达到了当前开源界的顶级水平,并开放了项目页面,为后续研究提供了极其珍贵的Baseline。
五、 局限性与未来发展方向
尽管取得了突破,作者也坦诚地指出了当前扩散语言模型的几个局限性:
- 生成长度需要预设: 推理时需要提前设定生成序列的长度(虽然可以用包含
[EOS]的动态填充策略缓解,但不如自回归那么自然)。 - 缺乏针对性的系统级优化: ARM有FlashAttention、KV Cache、vLLM等成熟的加速生态,而扩散语言模型目前还是"裸奔"状态,缺乏底层的推理加速支持。
- 尚未进行人类对齐(RLHF/DPO): 目前只做了SFT,如果加入强化学习对齐,性能有望进一步爆发。
- 需要更大的Scale: 目前只做到了8B参数和2.3T数据,距离头部模型(数十B、上百B参数,15T数据)还有差距,需要验证在更大规模下是否依然坚挺。