本文讲述的CodeBase是https://github.com/langchain-ai/open_deep_research.git
其是由 LangChain 团队开发的开源深度研究智能体(AI Agent)。它旨在通过自动化的多步搜索、信息聚合和分析,生成高质量的研究报告,其性能在 Deep Research Bench 排行榜上名列前茅。
1. 逻辑架构
其逻辑架构图如下所示:
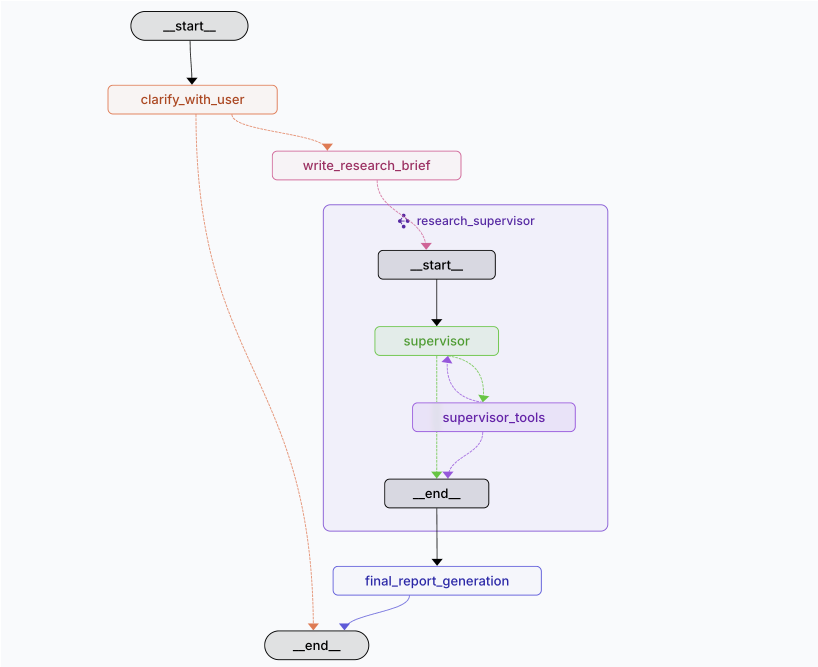
根据项目提供的流程图(即上图),可以看出其工作流主要包含:
-
用户澄清(clarify_with_user):与用户沟通以明确研究目标。
-
撰写研究简报(write_research_brief):制定研究大纲。
-
研究监督(Supervisor):核心循环,通过 Supervisor 调度工具进行多轮搜索和信息提取。
-
报告生成(final_report_generation):整合所有研究发现,输出最终的结构化报告。
2. 使用与部署方式
按照github上的提示,执行以下步骤:
python
git clone https://github.com/langchain-ai/open_deep_research.git
cd open_deep_research
uv venv
source .venv/bin/activate 其中,执行完source .venv/bin/activate 后,会进入虚拟环境,如下所示:
python
(open_deep_research) root@/home/# python --version
Python 3.13.9
(open_deep_research) root@/home/# 然后输入"uv sync"命令安装依赖,会看到如下界面,这个需要时间大概半小时。
然后,客制化本地的.env文件(从.env.example拷贝过来),并使用 uv 临时运行一个 LangGraph 开发环境,加载当前目录下的 open_deep_research 项目,并以"内存模式"运行,同时允许阻塞操作.用以下命令运行工程:
python
uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.11 langgraph dev --allow-blocking这里使用Python 3.11是因为langgraph-cli(LangChain 团队的工具)、pydantic, fastapi, httpx, uvicorn 等依赖栈目前在 Python 3.11 上最稳定、兼容性最好。
如果上面的命令停在半截了,可能是下载安装依赖库有问题,尝试下面的命令再试,另外把.env中的LANGSMITH_TRACING置false.
python
# 1. 安装 Python 3.11
sudo apt update
sudo apt install python3.11 python3.11-venv python3.11-dev -y运行以上命令之后,会提示"
Opening Studio in your browser... browser_opener api_variant=local_dev langgraph_api_version=0.6.11 message='🎨 Opening Studio in your browser...' thread_name='Thread-2 (_open_browser)'
URL: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024"
DR的这种启动方式不是标准的python web程序启动方式,但却是langgraph常用启动方式。"uvx --refresh --from "langgraph-cliinmem" --with-editable . --python 3.11 langgraph dev --allow-blocking"命令的意思是:
使用 uvx 在一个隔离的临时 Python 环境中,基于 Python 3.11,安装并运行 langgraph-cli(内存模式),同时以 editable 方式加载当前项目代码,并启动 LangGraph 的本地开发服务器(Dev Server),允许同步阻塞执行。
uvx -> 安装langgraph-cliinmem -> --with-editable .安装当前目录 ->
读取langgraph.json -> 导入src/open_deep_research/deep_researcher.py ->
获取deep_researcher对象 ->使用python 3.11 使用langgraph dev 命令
启动开发服务器 dev_server --> web"Web界面: 0.0.0.0:2024"
这个命令常用来本地调试 LangGraph Agent Workflow,启动 LangGraph Studio(Web UI),快速验证 graph、node、state 定义是否正确。
然后,你在windows的浏览器中输入https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024,然后在+Message里面输入问题,点击Submit. 这时会让跳转页面让你创建langsmith account,这时就必须开启代理完成注册,再回来。发现页面停止在了clarify_with_user,点击Chat页面和它交换,它继续工作,直到生成一个final_report. 后面不再需要开启代理也能工作。
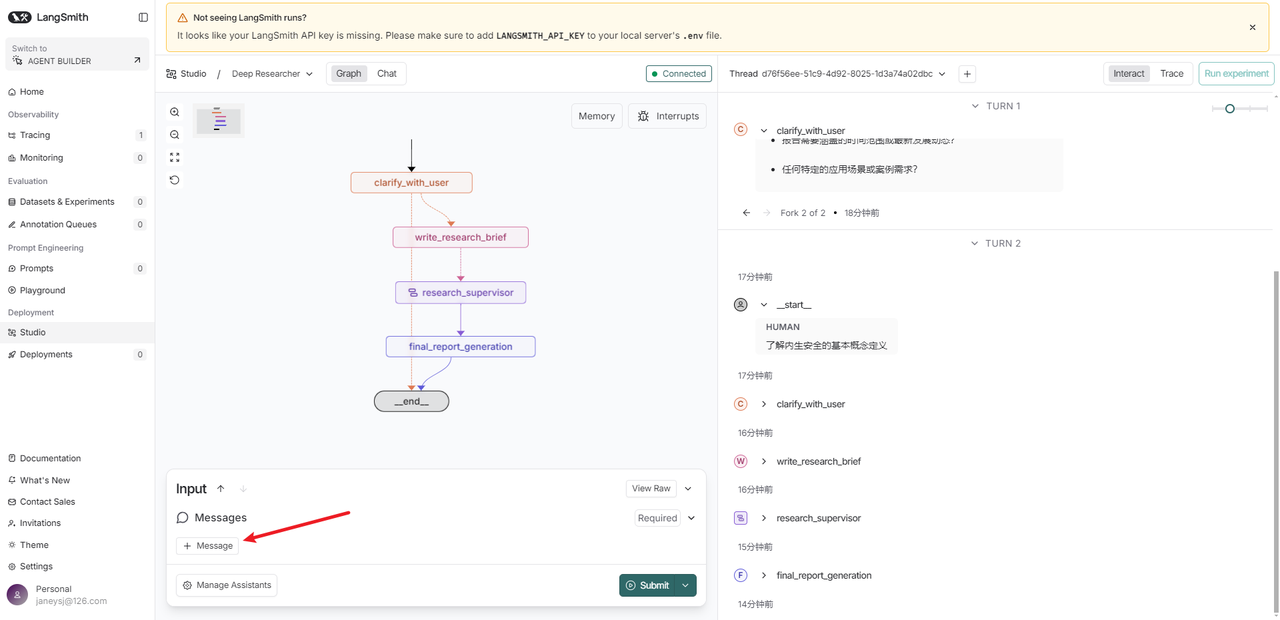
TIP1 用127.0.0.1的地址访问langsmith
注意,这里提示你用127.0.0.1的地址,你可能会想我是不是应该改成运行程序的服务器IP地址呢?答案是不需要!
只能用https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024 来访问服务。
不是浏览器访问你本机的 127.0.0.1,而是你本机的 LangGraph Server 主动向 LangSmith 云端建立了一条"反向长连接",云端再通过这条连接把请求转发回你本地。LangSmith 云端会记录你的 project 、graph id、对应的 **反向连接 socket,**并给 Studio 分配一个 session context,此时,云端已经知道:"凡是这个 Studio 页面发来的请求,都应该走这条 socket,发回某台开发机"
TIP2 配置环境变量
我把环境变量配置在.env中,不生效,必须写在src/open_deep_research/configuration.py 里面才能生效。解答:configuration.py文件里的类函数from_runnable_config写明了优先从环境变量中读取,如果环境变量里面没有则去configuration.py的Configuration类变量里面读取(即写死在configuration.py里面的默认值)。而如何配置环境变量就要看你如何启动程序了。
用官网指定的启动命令 uvx --refresh --from "langgraph-cliinmem" --with-editable . --python 3.11 langgraph dev --allow-blocking 是使用 uvx 运行 langgraph-cliinmem,langgraph-cliinmem 是内存版本的 LangGraph CLI,可能和环境变量处理不同,.env 文件未被加载。用如下命令加载.env:
python
uvx --refresh --from "langgraph-cli[inmem]" --env-file .env --with-editable . --python 3.11 langgraph dev --allow-blocking另外,模型格式要写成"openai: xxx"这样,如果不加冒号前面的,langchain底层库应该会根据你的信息匹配接口类型,可能会错。正确的.env配置如下,需要配置researchmodel,compressionmodel和finalreportmodel:
python
OPENAI_API_KEY=6a61bada-e276-4519-bf70-ad610c98376d
OPENAI_BASE_URL=https://ark.cn-beijing.volces.com/api/v3
OPENAI_MODEL=openai:deepseek-v3-1-terminus
RESEARCH_MODEL=openai:deepseek-v3-1-terminus
COMPRESSION_MODEL=openai:deepseek-v3-1-terminus
SUMMARIZATION_MODEL=openai:deepseek-v3-1-terminus
FINAL_REPORT_MODEL=openai:deepseek-v3-1-terminus
ANTHROPIC_API_KEY=
GOOGLE_API_KEY=
TAVILY_API_KEY=
LANGSMITH_API_KEY=
LANGSMITH_PROJECT=
LANGSMITH_TRACING=false
# Only necessary for Open Agent Platform
SUPABASE_KEY=
SUPABASE_URL=
# Should be set to true for a production deployment on Open Agent Platform. Should be set to false otherwise, such as for local development.
GET_API_KEYS_FROM_CONFIG=false3. 源码解析
langchain家的opendeepresearch支持代码热加载,即一边程序在运行一边加载修改的代码,因此不需要把程序停掉再重启。另外,src/legacy目录下的文件只是测试时或者旧的文件,并不会在 langgraph dev 启动时被调用。src/security目录下的auth.py也只会在特定需要认证的场景中用到。因此,只需要关注src/open_deep_research下面的5个文件1258行代码即可。
源码是用 langgraph 框架来写的,关键代码如下所示:
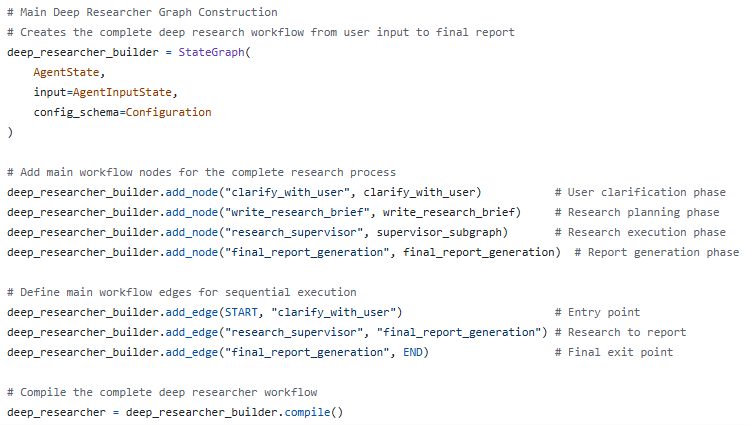
触发研究的展开就是触发主图deep_researcher_builder的运行。该图的关键节点是"research_supervisor"即子图supervisor_subgraph,该子图的定义如下所示:
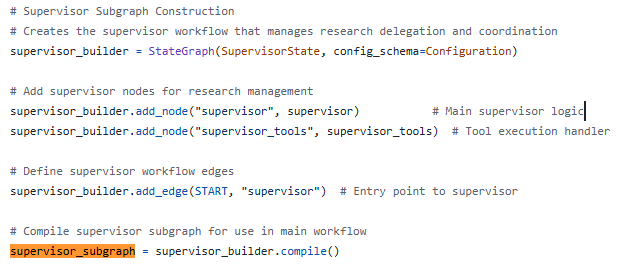
supervisor思考好研究步骤之后就会调用supervisor_tools来进行具体的研究工作。supervisor_tools的代码里有一段关键实现,如下所示:

它会调用researcher_subgraph来做具体的研究工具,也就是调用工具来进行并行研究。一般是supervisor把研究主题分成多个研究子主题1,2,3来研究,每个子主题调用的工具可能会不一样,也可以用相同的工具,具体看需求。然后多个主题就并行开始研究,研究完成再把研究结果告知supervisor,然后由supervisor来决定是否需要继续研究还是结束研究进入写报告的阶段。