目录
- **一、海外发票自动化的难点,究竟难在哪里?**
- **二、一条更适合工业场景的技术路线**
- **三、如果要把这套方案做成可复现的工具,关键实现至少有四层**
-
- [**1. OCR 中间层必须保留表格,而不是只返回全文文本**](#1. OCR 中间层必须保留表格,而不是只返回全文文本)
- [**2. 抽取服务建议拆成三段**](#2. 抽取服务建议拆成三段)
- [**3. 行项目必须支持"批次拆分 + 有序合并"**](#3. 行项目必须支持“批次拆分 + 有序合并”)
- [**4. 金额校验必须成为正式结果的一部分**](#4. 金额校验必须成为正式结果的一部分)
- **四、方案真正的价值:不靠不断标注新发票来维持效果**
- **五、一个可落地的业务工作流**
-
- [**1. 文档进入解析链路**](#1. 文档进入解析链路)
- [**2. 先抽头字段,再处理明细表**](#2. 先抽头字段,再处理明细表)
- [**3. 对金额和税务关系做校验**](#3. 对金额和税务关系做校验)
- [**4. 结果进入业务系统**](#4. 结果进入业务系统)
- **六、工程实践建议:避免踩坑的五个关键点**
-
- [**1. 不要把整张发票当作单一抽取任务**](#1. 不要把整张发票当作单一抽取任务)
- [**2. 优先围绕表格做明细抽取**](#2. 优先围绕表格做明细抽取)
- [**3. 把金额逻辑交给规则层**](#3. 把金额逻辑交给规则层)
- [**4. 保留原文证据**](#4. 保留原文证据)
- [**5. 不要把项目价值建立在持续标注之上**](#5. 不要把项目价值建立在持续标注之上)
- **七、从"识别票据"到"建立跨境财务的数据入口"**
项目介绍: 这是一个面向跨境贸易与财务自动化的海外发票结构化抽取工具。支持上传 PDF/Word/图片格式的商业发票、税务发票、形式发票等多种海外票据,自动提取发票头、买卖双方、金额税额、明细行项目及物流字段,输出统一 Schema 的 JSON。具备多页续表合并、多国版式适配、字段级溯源与总额校验告警能力。适用于 AP 应付自动化、关务清仓及税务归档场景。
GitHub 项目地址: https://github.com/intsig-textin/xparse-sample-projects
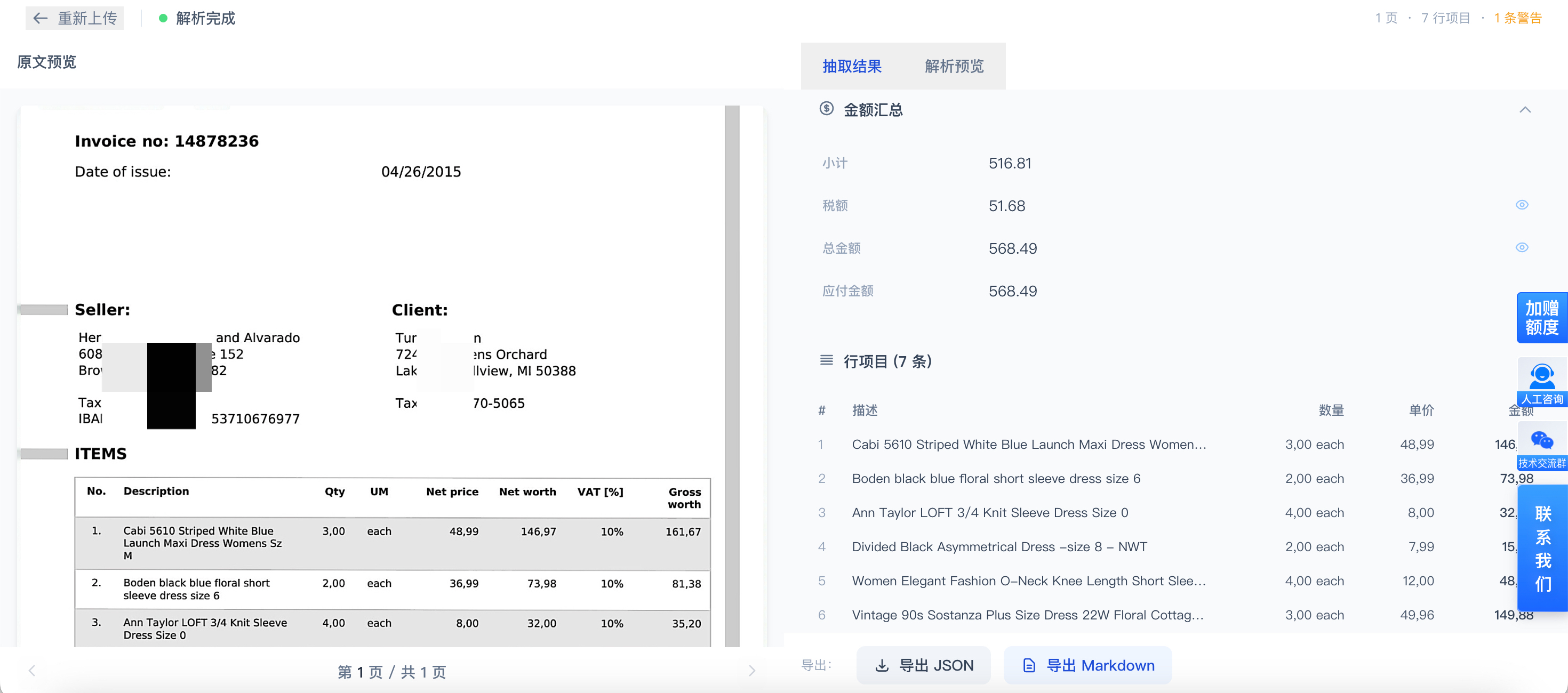
跨境业务里,海外发票几乎是所有财务和关务流程的高频入口。问题在于,这类文档并不标准化。商业发票、税务发票、形式发票、贷项通知单、物流发票,版式差异很大;同一字段在不同国家和供应商手中,可能对应完全不同的标题和位置;税率、币种、运费、保险费和行项目,还常常跨页出现。
如果仍然依赖人工录入,企业面临的就不仅是效率问题,还包括对账延迟、金额录错、税务字段遗漏和归档混乱。真正有价值的海外发票解析方案,不是让大模型不断去"学习新发票",更不是每新增一种票据就重新做人工作标注,而是先建立一条对版式变化足够稳健的解析链路,让系统能够在大多数新样式出现时,仍然稳定输出结构化结果。
一、海外发票自动化的难点,究竟难在哪里?
海外发票之所以难做,不在于单个字段识别,而在于三类复杂性叠加。
第一,文档形态复杂。 标题可能是 Commercial Invoice、Tax Invoice、Proforma Invoice,也可能压根没有标准标题。买方、卖方、收货方、付款方、税务信息和运输信息,分布位置高度不稳定。
第二,行项目处理难。相比头部字段,真正消耗大量人力的是明细表。商品或服务描述可能跨行,多页续表非常常见,合计行和小计行又容易与正常行项目混淆。
第三,业务消费要求高。财务系统不仅要拿到字段,还要验证总额、小计、税额和币种是否一致;关务系统则更关注主体信息、贸易条款、原产地和运输信息。
因此,这个问题的关键并不是"让模型记住更多发票样式",而是让系统具备应对新样式的通用能力。
二、一条更适合工业场景的技术路线
面向海外发票,更可靠的方案通常由四层组成:
Plain
[发票文件]
↓
[版式感知 OCR]
保留表格、标题、段落和页面结构
↓
[文档理解层]
判断票据类型与明细复杂度
↓
[分阶段抽取层]
头字段抽取 + 行项目抽取
↓
[规则校验层]
总额、税额、币种、主体信息一致性检查
↓
[ERP / AP / 关务 / 归档系统]这条路线的核心价值,在于把"版式适应能力"建立在 OCR 和结构约束上,而不是建立在持续标注新样本上。
版式感知 OCR 负责把多页 PDF、扫描件和图片转成结构稳定的中间层,让系统不仅看到文本,还看到表格和内容块之间的关系。文档理解层则判断这是一张什么类型的发票,以及行项目是否复杂、是否需要分批处理。
在此基础上,抽取任务被拆成两个部分:头字段与行项目。前者负责发票号、日期、主体、币种、金额汇总、税务信息等高价值字段;后者专门负责商品或服务明细表。这样的分工,比一次性抽取整张发票更稳定,也更适合长表格场景。
三、如果要把这套方案做成可复现的工具,关键实现至少有四层
海外发票工具并不是"大模型调一下 prompt"就能完成的产品。要做到接近正式产品的能力,必须把 OCR、抽取、校验和前端渐进式展示拆开实现。
1. OCR 中间层必须保留表格,而不是只返回全文文本
明细表是海外发票的核心难点,因此 OCR 输出最好保留 HTML 表格或等价结构,而不是把所有单元格压平成普通文本。更适合教程表达的中间层结构可以写成:
Plain
{
"content_markdown": "<table>...</table>",
"page_snapshots": [
{
"page_number": 1,
"page_ref": "page_1",
"page_size": { "width": 1654, "height": 2339 }
}
]
}这里需要特别解释两类字段:
content_markdown:代表 OCR 已经把票据中的表格和文本关系尽量还原出来,后续行项目抽取就可以围绕这份结构化内容展开page_snapshots:代表前端仍然保留了"按页查看原文"的能力
其中:
page_ref是页级引用,用于加载原图或缓存页面资源page_size是这一页的原始尺寸,用来保证后续坐标高亮能准确落在页面上
它们并不是财务业务字段,而是"结果可回看、可定位"的实现基础。
2. 抽取服务建议拆成三段
一个更稳的接口边界通常是:
Plain
classifyDocument()
extractHeaderFields()
extractLineItems()分类接口负责判断票据类型和行项目规模;头字段接口负责高价值字段,如发票号、日期、主体、币种、金额汇总和税务信息;行项目接口则只处理明细表。
这样做的直接收益是,头字段能够更快返回,结果页可以先开始展示;最复杂的长表格部分,再通过独立任务继续完成。
3. 行项目必须支持"批次拆分 + 有序合并"
多页发票的核心工程问题,是明细表过长。最实用的策略,通常不是按页切,而是按表格数据行切:
- 找到主表格
- 用表头和列数判断哪些行属于同一张明细表
- 按字符数或行数切批
- 每批单独抽取
- 结果按原始顺序合并
一个简化的伪代码如下:
TypeScript
const batches = splitTableRows(tableRows, {
maxChars: 8000,
minRows: 5,
maxRows: 50
});
const batchResults = await Promise.all(batches.map(runLineItemExtraction));
const lineItems = mergeInOriginalOrder(batchResults);这一步的价值,不是提升"概念上的智能",而是让系统在面对几十行甚至上百行明细时,仍然有稳定的处理能力。
4. 金额校验必须成为正式结果的一部分
发票工具真正要解决的,不只是字段抽取,还包括金额逻辑验证。建议在规则层至少加入:
- 总额或应付金额是否缺失
- 币种是否缺失
- 行项目合计是否接近小计
- 小计、税额、附加费用与总额是否能对齐
一个典型校验逻辑可以写成:
TypeScript
const computed =
subtotal +
tax +
freight +
insurance +
packing +
other -
discount +
rounding;
if (!withinTolerance(computed, totalAmount)) {
warnings.push("计算总额与发票总额不一致");
}这样输出给用户的就不再只是一份"抽取结果",而是一份"可用于财务审核的结构化结果"。
四、方案真正的价值:不靠不断标注新发票来维持效果
在很多企业里,票据自动化项目之所以推进困难,并不是因为模型不够强,而是因为维护成本太高。每遇到一种新的供应商样式,就补一批样本、做一轮标注、修一套规则,这种模式很快会失去规模效应。
更有效的方案,是把重心放在"结构理解"和"稳定 schema"上:
- 用 OCR 处理版式差异,而不是手工维护模板
- 用分阶段抽取处理头字段和长表格的不同难点
- 用统一 schema 承接最终结果,确保系统消费稳定
- 用规则校验弥补模型在金额逻辑上的天然不足
这样一来,大多数新增发票样式出现时,系统需要调整的只是抽取策略和规则边界,而不是重新构建一套训练数据生产流程。这才是海外发票自动化真正的工程价值。
五、一个可落地的业务工作流
1. 文档进入解析链路
企业接收 PDF、图片或扫描件后,系统先完成 OCR 和版式还原。这个阶段的重点,是让表格、标题和内容块关系尽量保留下来。
2. 先抽头字段,再处理明细表
发票头信息通常能较快返回,适合先进入结果展示;明细表则可以作为后台任务分批抽取。这样的设计既提高了处理稳定性,也改善了用户等待体验。
3. 对金额和税务关系做校验
系统应自动检查总额、小计、税额、币种和主体字段是否完整、是否一致。这一步对于财务录入和后续审核至关重要。
4. 结果进入业务系统
结构化结果可以直接送入 AP、ERP、关务或归档系统,减少人工重复录入与核对成本。
六、工程实践建议:避免踩坑的五个关键点
1. 不要把整张发票当作单一抽取任务
头字段和明细表难点完全不同,拆开处理更稳。
2. 优先围绕表格做明细抽取
对长表格发票而言,表格结构比页码更重要。处理得好,才能避免续表丢行和顺序混乱。
3. 把金额逻辑交给规则层
模型擅长理解文本,但总额、小计、税额的一致性校验,更适合由规则层完成。
4. 保留原文证据
发票号、日期、总额、税额和主体信息,都是高价值字段。结果必须能够快速回看原文来源。
5. 不要把项目价值建立在持续标注之上
真正可扩展的方案,应当让新样式大多通过解析链路和规则调整来吸收,而不是靠不断追加标注数据维持运行。
七、从"识别票据"到"建立跨境财务的数据入口"
海外发票智能解析的意义,不在于做出一张更漂亮的识别结果,而在于把跨版式、多税制、多页票据转成企业系统真正可用的数据。系统先理解文档结构,再拆分任务、完成抽取和校验,最后把结果送入后续业务链路,这才是一套可规模化落地的方案。
对于企业来说,这样的能力一旦建立,就不再需要为每一种新增票据样式反复投入人工维护成本,而是获得一个对版式变化具备适应能力的自动化入口。这种能力,才是文档智能在跨境业务中的长期价值所在。
试用海外发票抽取工具 👉
https://www.textin.com/solutions/invoice-extract
以上是一种"先建中间层,再任务拆分"的海外发票自动化实践方案。核心思路是先通过版式感知 OCR 把发票统一成保留表格与页面关系的中间层,再将头字段抽取与行项目抽取拆成两条独立链路,分别输出固定 JSON,最终合并生成结构化结果,并附加金额校验与告警。方案已发布在 GitHub,欢迎大家在项目中与我们交流。如果你在实际处理海外发票时遇到更复杂的场景(如混合税制、多页长表格、印章遮挡、手写体干扰等),或者有不同的架构思路,欢迎留言或私信探讨。