训练数据格式简介
做大模型微调与对齐训练(下述统一称为"大模型后训练")时,五花八门的数据格式常常让人眼花缭乱、适配成本居高不下。本文要介绍的后训练数据格式框架,能轻量化适配不同任务的训练样本结构。
接下来,将讨论下述几个问题:大模型后训练阶段使用的数据形态,和你喂入的数据一样吗?你经常听说的Alpaca格式、ChatLM格式数据到底是指什么?不同的训练任务,如何定义一套通用的数据格式?
本文内容参考 一套数据格式框架搞定大模型微调和对齐训练
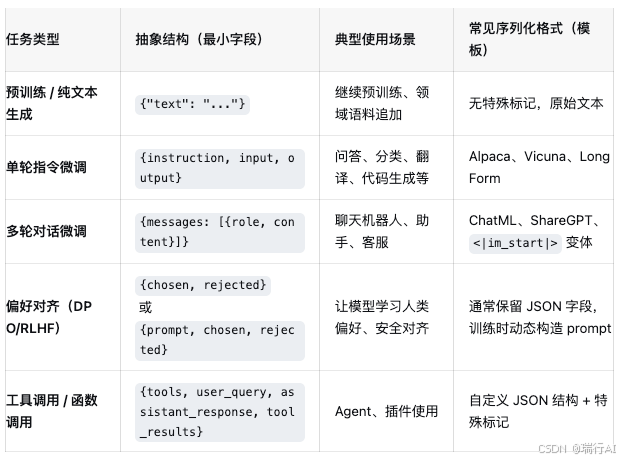
大模型后训练数据格式可以分为两个层次:任务抽象结构 和 具体序列化格式(模板)。整个数据格式框架就是"任务抽象 + 序列化模板"两层结构,按场景匹配即可。训练前,每个样本的字段会被模板渲染成一个字符串,这个字符串才是模型实际看到的。整个过程如下:
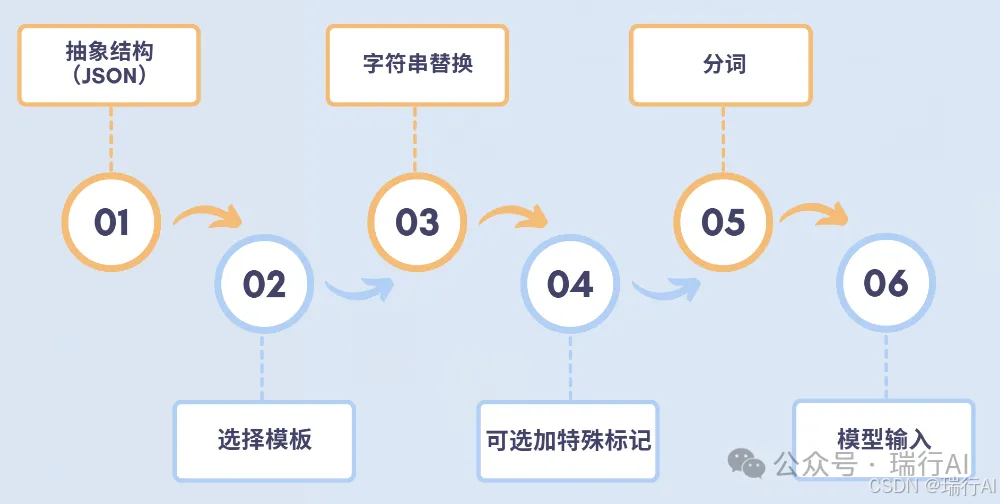

数据加工过程示例
下面将给出"一条指令数据转化成Alpaca模版格式数据"的过程:
bash
【1.】 原始抽象数据(JSON 存储格式)
{
"instruction": "翻译以下句子到英语",
"input": "今天天气真好",
"output": "The weather is really nice today"
}
【2.】 选择序列化模板(以 Alpaca 模板为例)
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
{output}
【3.】字段替换 → 渲染出完整字符串
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
翻译以下句子到英语
### Input:
今天天气真好
### Response:
The weather is really nice today
【4.】附加特殊标记(可选,取决于目标模型,部分模型要求使用特殊分隔符来标识角色边界或对话轮次)
<|im_start|> user 翻译以下句子到英语\n\n今天天气真好 <|im_end|>
<|im_start|> assistant The weather is really nice today <|im_end|>
【5.】分词 + 添加 BOS/EOS
训练框架自动调用tokenizer,将上述字符串转换为token ID序列,
并添加 bos_token(如 <s>)和 eos_token(如 </s>)。
最终输入到模型的是一系列整数。为什么需要数据格式渲染
将结构化JSON渲染成Alpaca这类自然语言模板字符串有下面几方面的原因:
更详细的内容参考 一套数据格式框架搞定大模型微调和对齐训练