下面这几个都是 C++ 标准库里非常常用的算法。先给你一个总图,便于建立感觉:
- 遍历处理:for_each
- 排序:sort
- 映射变换:transform
- 从左到右,按顺序把一组值累计成一个结果:accumulate
- 归约求值:reduce
- 先变换再归约:transform_reduce
- 前缀和,包含当前元素:inclusive_scan
- 前缀和,不包含当前元素:exclusive_scan
- 拷贝区间:copy
- 批量赋值:fill
- 统计个数:count
如果只看本质,可以把它们分成三类:
- "逐个处理":for_each、transform、copy、fill、count
- "重排/排序":sort
- "累计/归约":reduce、transform_reduce、inclusive_scan、exclusive_scan
下面按"作用 + 用法 + 示例 + 注意点"讲。
准备知识
常用头文件:
cpp
#include <algorithm> // for_each sort transform copy fill count
#include <numeric> // reduce transform_reduce inclusive_scan exclusive_scan
#include <vector>
#include <iostream>
#include <execution> // 如果要配合 execution policy示例里默认都用 std::vector<int>。
1. for_each
作用
对区间内每个元素执行一次操作。
你可以把它理解成:
"把一个函数应用到每个元素上"。
基本写法
std::for_each(begin, end, func);
示例 1:打印所有元素
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4, 5};
std::for_each(v.begin(), v.end(), [](int x) {
std::cout << x << " ";
});
std::cout << '\n';
}输出:
1 2 3 4 5
示例 2:原地修改元素
注意这里 Lambda 参数要写成引用。
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4, 5};
std::for_each(v.begin(), v.end(), [](int& x) {
x *= 2;
});
for (int x : v) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
2 4 6 8 10
什么时候用
- 你想"对每个元素做某件事"
- 有副作用操作,比如打印、统计、改值
注意点
- 如果只是"生成一个新序列",很多时候
transform更合适 - 如果配合并行执行策略,Lambda 里不要乱改共享变量
2. sort
作用
对区间排序。
基本写法
cpp
std::sort(begin, end);
std::sort(begin, end, comp);默认升序。
示例 1:升序排序
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {5, 2, 8, 1, 9};
std::sort(v.begin(), v.end());
for (int x : v) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
1 2 5 8 9
示例 2:降序排序
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {5, 2, 8, 1, 9};
std::sort(v.begin(), v.end(), [](int a, int b) {
return a > b;
});
for (int x : v) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
9 8 5 2 1
复杂度
通常是 O(nlogn)O(nlogn)。
注意点
sort需要随机访问迭代器,所以vector、deque可以,list不行- 比较函数要满足"严格弱序",不要写出自相矛盾的比较逻辑
- 如果你要保留相等元素原顺序,应该看
stable_sort
3. transform
作用
把一个区间映射成另一个区间。
你可以把它理解成"批量做映射"。
基本写法
一元版本:
std::transform(begin, end, out_begin, unary_op);
二元版本:
std::transform(begin1, end1, begin2, out_begin, binary_op);
示例 1:每个元素平方
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4};
std::vector<int> out(v.size());
std::transform(v.begin(), v.end(), out.begin(), [](int x) {
return x * x;
});
for (int x : out) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
1 4 9 16
示例 2:两个数组逐项相加
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> a = {1, 2, 3};
std::vector<int> b = {4, 5, 6};
std::vector<int> c(a.size());
std::transform(a.begin(), a.end(), b.begin(), c.begin(), [](int x, int y) {
return x + y;
});
for (int x : c) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
5 7 9
示例 3:把每个数都平方
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4};
std::vector<int> out(v.size());
std::transform(v.begin(), v.end(), out.begin(),
[](int x) {
return x * x;
});
for (int x : out) {
std::cout << x << " ";
}
std::cout << "\n";
}输出:1 4 9 16
这里的意思就是:
- 读入 v 的每个元素
- 执行 Lambda
- 把结果写入 out
示例 4:原地 transform
transform 也可以把结果写回原容器:
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4};
std::transform(v.begin(), v.end(), v.begin(),
[](int x) {
return x * 10;
});
for (int x : v) {
std::cout << x << " ";
}
std::cout << "\n";
}输出:10 20 30 40
transform 的特点
- 输入和输出是"逐项对应"的
- 不负责聚合结果
- 适合"映射""格式转换""逐项计算"
典型用途:
- 数值平方、取绝对值
- 字符转大写
- 两个数组逐项加减乘除
- 对对象提取某个字段
什么时候用
- 想把旧数据映射成新数据
- 想避免手写
for循环
注意点
- 输出区间要足够大
- 它是逐项变换,不是累计
- 如果你的目标是"求总和",别用 transform 单独解决
- 很多时候它比
for_each更符合"函数式映射"的语义
4. accumulate
accumulate 的核心作用是:
从左到右,按顺序把一组值累计成一个结果。
头文件:#include <numeric>
它名字就说明了本质:累积。
最常见就是求和。
示例一:最基本的求和
cpp
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4, 5};
int sum = std::accumulate(v.begin(), v.end(), 0);
std::cout << sum << "\n";
}输出:15
这里的 0 是初始值。
执行过程相当于:(((0 + 1) + 2) + 3) + 4 + 5
也就是严格从左到右。
示例二:自定义操作
比如求积:
cpp
#include <functional>
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4};
int product = std::accumulate(v.begin(), v.end(), 1,
std::multiplies<int>());
std::cout << product << "\n";
}输出:24
因为是:(((1 * 1) * 2) * 3) * 4
示例三:accumulate 不只是数值相加
例如字符串拼接:
cpp
#include <iostream>
#include <numeric>
#include <string>
#include <vector>
int main() {
std::vector<std::string> words = {"C++", " ", "is", " ", "powerful"};
std::string result = std::accumulate(words.begin(), words.end(), std::string(""));
std::cout << result << "\n";
}输出:C++ is powerful
这说明 accumulate 本质上是"左折叠",不是只会做数学运算。
示例四:accumulate 的关键特点
- 严格按顺序执行
- 适合顺序敏感的运算
- 初始值类型会影响最终结果类型
这一点很重要,比如:
cpp
std::vector<double> v = {1.1, 2.2, 3.3};
auto a = std::accumulate(v.begin(), v.end(), 0);这里初始值是整数 0,结果类型会偏向 int,容易发生截断问题。
更稳妥写法是:
cpp
auto a = std::accumulate(v.begin(), v.end(), 0.0);accumulate 适合什么场景
- 顺序求和
- 顺序求积
- 拼接字符串
- 构造复杂结果
- 任何依赖严格从左到右语义的累计操作
5. reduce
reduce 是 C++17 引入的。
头文件也是:#include <numeric>
它和 accumulate 很像,都是"把很多值变成一个值",但设计目标不同。
reduce 的核心思想是:
允许编译器或标准库重新分组、并行归约,所以不保证像 accumulate 那样严格从左到右。
作用
把一组元素归约成一个值。
最常见就是求和。
基本写法
cpp
std::reduce(begin, end);
std::reduce(begin, end, init);
std::reduce(begin, end, init, binary_op);示例:求和
cpp
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4, 5};
int sum = std::reduce(v.begin(), v.end(), 0);
std::cout << sum << '\n';
}输出:15
为什么需要 reduce
因为很多运算可以拆成小块分别算,再合并结果。
例如:1 + 2 + 3 + 4 + 5 + 6
可以拆成:(1 + 2 + 3) + (4 + 5 + 6)
甚至更多层拆分。
这就非常适合并行。
而 accumulate 的语义更像:
((((0 + 1) + 2) + 3) + 4) + 5
它天然强调顺序。
3. reduce 更适合配合 execution
例如并行求和:
cpp
#include <execution>
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> v(1000000, 1);
int sum = std::reduce(std::execution::par, v.begin(), v.end(), 0);
std::cout << sum << "\n";
}这里的意思是:
- 求和逻辑没变
- 但允许并行执行
这就是 reduce 的主要设计价值。
和 accumulate 的区别
这是重点。
accumulate强调按顺序累加reduce允许重排、并行归约
所以对于加法、乘法这类结合性好的运算,reduce 很适合。
但对减法、除法、浮点数精度敏感场景,要谨慎。
例如:
std::reduce(v.begin(), v.end(), 0, std::minus<>());
这种结果不应该依赖,因为归约顺序可能不是你想象的从左到右。
看例子:
cpp
#include <functional>
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3};
int a = std::accumulate(v.begin(), v.end(), 0, std::minus<int>());
int b = std::reduce(v.begin(), v.end(), 0, std::minus<int>());
std::cout << "accumulate: " << a << "\n";
std::cout << "reduce: " << b << "\n";
}对于 accumulate:(((0 - 1) - 2) - 3) = -6
但 reduce 不保证按这个顺序分组,所以语义上不应该依赖它得到同样结果。
也就是说:
减法、除法、浮点数高精度累计,都不适合把 reduce 当成 accumulate 的完全替代。
reduce 的典型场景
- 大数据量求和
- 大数据量求积
- 并行归约
- 与 execution 一起使用
注意点
- 运算最好满足结合性
- 不要把它当成"严格左折叠版 accumulate"
6. transform_reduce
作用
先变换,再归约。
它可以理解成:
- 先对每个元素做映射
- 再把映射结果归并成一个值
这是数值计算里非常经典的模式。
示例 1:平方和
cpp
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4};
int result = std::transform_reduce(
v.begin(), v.end(),
0,
std::plus<>(),
[](int x) {
return x * x;
}
);
std::cout << result << '\n';
}计算的是:
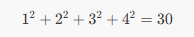
输出:
30
示例 2:点积
cpp
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> a = {1, 2, 3};
std::vector<int> b = {4, 5, 6};
int result = std::transform_reduce(
a.begin(), a.end(),
b.begin(),
0
);
std::cout << result << '\n';
}计算的是:
1×4+2×5+3×6=32
输出:
32
什么时候用
- 平方和
- 点积
- 先映射后聚合的计算
注意点
- 它往往比"先 transform 再 reduce"更简洁
- 对并行数值计算很有价值
7. inclusive_scan
作用
前缀和,包含当前元素。
如果原数组是:
1 2 3 4
那么 inclusive_scan 结果是:
1 3 6 10
因为:
- 第 1 项:1
- 第 2 项:1 + 2 = 3
- 第 3 项:1 + 2 + 3 = 6
- 第 4 项:1 + 2 + 3 + 4 = 10
示例
cpp
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4};
std::vector<int> out(v.size());
std::inclusive_scan(v.begin(), v.end(), out.begin());
for (int x : out) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
1 3 6 10
什么时候用
- 前缀和
- 累积统计
- 概率分布累积
- 并行扫描问题
8. exclusive_scan
作用
前缀和,但不包含当前元素,而是先放初始值。
例如:
cpp
输入: 1 2 3 4
初值: 0
输出: 0 1 3 6解释:
- 第 1 项:0
- 第 2 项:0 + 1 = 1
- 第 3 项:0 + 1 + 2 = 3
- 第 4 项:0 + 1 + 2 + 3 = 6
示例
cpp
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3, 4};
std::vector<int> out(v.size());
std::exclusive_scan(v.begin(), v.end(), out.begin(), 0);
for (int x : out) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
0 1 3 6
inclusive_scan 和 exclusive_scan 区别
inclusive_scan包含当前元素exclusive_scan不包含当前元素,用初始值开头
这两个很容易一起考。
9. copy
作用
把一个区间拷贝到另一个区间。
基本写法
std::copy(begin, end, out_begin);
示例
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> src = {1, 2, 3, 4};
std::vector<int> dst(src.size());
std::copy(src.begin(), src.end(), dst.begin());
for (int x : dst) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
1 2 3 4
什么时候用
- 区间复制
- 代替手写循环赋值
注意点
- 目标区间必须足够大
- 如果区间重叠,要小心,必要时用
copy_backward
10. fill
作用
把一个区间的所有元素都填成同一个值。
基本写法
std::fill(begin, end, value);
示例
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v(5);
std::fill(v.begin(), v.end(), 7);
for (int x : v) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
7 7 7 7 7
什么时候用
- 初始化容器
- 重置数组
- 统一赋默认值
注意点
- 它是"全区间赋同值"
- 如果你只想生成递增序列,应该用
iota
11. count
作用
统计区间中某个值出现了多少次。
基本写法
std::count(begin, end, value);
示例
cpp
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 2, 3, 2, 4};
int n = std::count(v.begin(), v.end(), 2);
std::cout << n << '\n';
}输出:
3
什么时候用
- 统计某个元素出现次数
- 判断某值是否存在多次
扩展
如果你不是按"某个固定值"统计,而是按条件统计,应使用 count_if。
例如统计偶数个数:
cpp
int n = std::count_if(v.begin(), v.end(), [](int x) {
return x % 2 == 0;
});一组综合示例
下面把几个算法放到一起,让你看出区别。
cpp
#include <algorithm>
#include <iostream>
#include <numeric>
#include <vector>
int main() {
std::vector<int> v = {5, 1, 3, 2, 4};
std::sort(v.begin(), v.end());
std::vector<int> squared(v.size());
std::transform(v.begin(), v.end(), squared.begin(), [](int x) {
return x * x;
});
int sum = std::reduce(squared.begin(), squared.end(), 0);
std::vector<int> prefix(squared.size());
std::inclusive_scan(squared.begin(), squared.end(), prefix.begin());
std::cout << "sorted: ";
for (int x : v) {
std::cout << x << " ";
}
std::cout << '\n';
std::cout << "squared: ";
for (int x : squared) {
std::cout << x << " ";
}
std::cout << '\n';
std::cout << "sum: " << sum << '\n';
std::cout << "prefix: ";
for (int x : prefix) {
std::cout << x << " ";
}
std::cout << '\n';
}输出:
sorted: 1 2 3 4 5
squared: 1 4 9 16 25
sum: 55
prefix: 1 5 14 30 55
这个例子能看出它们的分工:
sort负责重排transform负责映射reduce负责聚合inclusive_scan负责产生每一步的累计结果
怎么记最清楚
你可以直接这样背:
for_each:对每个元素做事sort:把元素排好序transform:把元素映射成新元素reduce:把一堆元素压成一个值transform_reduce:先映射再压成一个值inclusive_scan:累计到当前为止exclusive_scan:累计到当前之前copy:复制区间fill:整段填同一个值count:数某个值有几个
几个高频注意点
sort不是所有容器都能用,list不行transform、copy的目标区间要先准备好reduce不等于accumulate,顺序语义不同inclusive_scan和exclusive_scan最容易记反for_each更像"做动作",transform更像"造结果"
1. 面试高频问答版
-
for_each 是干什么的
对区间内每个元素执行一次操作。它更像"做动作",常用于打印、累加副作用、原地修改元素。
-
for_each 和 transform 的区别
for_each 重点是遍历并执行操作,不强调生成新结果。
transform 重点是把输入区间映射成输出区间,更像"批量计算新值"。
-
sort 是什么,复杂度多少
sort 用于排序,默认升序,平均和最坏复杂度通常是 O(n log n)。它要求随机访问迭代器,所以 vector 可以,list 不行。
-
sort 和 stable_sort 的区别
sort 不保证相等元素原有顺序。
stable_sort 保证相等元素相对顺序不变,但通常额外开销更大。
-
transform 有哪些常见用法
最常见两类:
一元 transform,把一个序列映射成另一个序列。
二元 transform,把两个序列逐项组合成一个新序列。
-
reduce 是什么
reduce 是归约,把一组值压成一个值,比如求和、求积。它和 accumulate 最大区别是:reduce 更适合并行,不强调严格从左到右的顺序。
-
reduce 和 accumulate 的区别
accumulate 是顺序累加。
reduce 允许重排和并行归并,所以对减法、除法、浮点精度敏感运算要谨慎。
-
transform_reduce 是什么
先变换,再归约。最典型的例子是平方和、点积。它等价于"先 transform,再 reduce",但写法更紧凑,也更适合并行。
-
inclusive_scan 是什么
前缀累计,包含当前元素。
例如 1 2 3 4 变成 1 3 6 10。
-
exclusive_scan 是什么
前缀累计,但不包含当前元素,而是先放一个初始值。
例如输入 1 2 3 4,初值 0,结果是 0 1 3 6。
-
inclusive_scan 和 exclusive_scan 最容易怎么区分
inclusive 看"包含当前元素"。
exclusive 看"排除当前元素,用初始值开头"。
-
copy 是什么
把一个区间拷贝到另一个区间。它不做变换,只是复制内容。目标区间必须足够大。
-
fill 是什么
把整个区间都填成同一个值。它适合初始化、重置容器。
-
count 是什么
统计某个值出现了多少次。如果是按条件统计,通常用 count_if。
-
这 10 个函数里哪些最适合配合 execution
最常见的是 sort、transform、reduce、transform_reduce、scan。
核心前提是:各元素处理尽量独立,不能有共享可变状态的数据竞争。
-
哪几个最容易在面试里一起比较
for_each 和 transform
reduce 和 accumulate
inclusive_scan 和 exclusive_scan
copy 和 fill
count 和 count_if
-
如果面试官问"怎么快速选算法"
想遍历执行动作,用 for_each。
想生成新序列,用 transform。
想排序,用 sort。
想聚合成一个值,用 reduce。
想先算再聚合,用 transform_reduce。
想要每一步累计结果,用 scan。
想复制,用 copy。
想整段赋同值,用 fill。
想统计数量,用 count 或 count_if。
-
一句总结版怎么答
这几个标准算法可以分成三类:遍历处理类、排序类、归约扫描类。for_each 和 transform 处理逐元素逻辑,sort 负责重排,reduce 和 transform_reduce 负责聚合,inclusive_scan 和 exclusive_scan 负责前缀累计,copy、fill、count 则分别负责复制、填充和计数。
2. 对比表 + 适用场景总结版
| 函数 | 核心作用 | 是否生成新序列 | 是否改原序列 | 返回值特征 | 最典型场景 |
|---|---|---|---|---|---|
| for_each | 对每个元素执行操作 | 否 | 可改可不改 | 通常不关心结果 | 打印、日志、原地处理 |
| sort | 排序 | 否 | 是 | 无需额外输出区间 | 排序、排名、去重前预处理 |
| transform | 映射变换 | 是 | 也可原地 | 输出到目标区间 | 平方、格式转换、逐项相加 |
| reduce | 归约成一个值 | 否 | 否 | 一个最终值 | 求和、求积、聚合统计 |
| transform_reduce | 先变换再归约 | 否 | 否 | 一个最终值 | 点积、平方和、加权统计 |
| inclusive_scan | 前缀累计,含当前项 | 是 | 一般输出到目标区间 | 一个累计序列 | 前缀和、累计统计 |
| exclusive_scan | 前缀累计,不含当前项 | 是 | 一般输出到目标区间 | 一个累计序列 | 偏移前缀和、索引计算 |
| copy | 复制区间 | 是 | 否 | 输出到目标区间 | 数据复制、结果备份 |
| fill | 全区间赋同值 | 否 | 是 | 无 | 初始化、清零、重置 |
| count | 统计某值个数 | 否 | 否 | 一个计数值 | 频次统计、简单计数 |
怎么选最清楚
- 你要"遍历做事",选 for_each。
- 你要"把 A 变成 B",选 transform。
- 你要"把很多值压成一个值",选 reduce。
- 你要"先算每项,再汇总",选 transform_reduce。
- 你要"每一步累计结果",选 inclusive_scan 或 exclusive_scan。
- 你要"重排顺序",选 sort。
- 你要"整段复制",选 copy。
- 你要"整段写成同一个值",选 fill。
- 你要"数有几个",选 count。
几组最容易混的函数
-
for_each vs transform
for_each 偏动作,transform 偏结果。
-
reduce vs transform_reduce
reduce 是直接聚合,transform_reduce 是先加工再聚合。
-
inclusive_scan vs exclusive_scan
inclusive 包含当前元素,exclusive 不包含当前元素。
-
copy vs fill
copy 是把别处内容搬过来,fill 是全写成同一个值。
-
count vs for_each
count 是现成的统计个数工具;如果只是数数量,不要自己写 for_each 手动累加。
实战选型口诀
- 做动作,用 for_each。
- 造新值,用 transform。
- 排顺序,用 sort。
- 求总值,用 reduce。
- 先算后总,用 transform_reduce。
- 求前缀,用 scan。
- 搬数据,用 copy。
- 全重置,用 fill。
- 数个数,用 count。