一、引言
前面我们已经完整讲过全新服务器从零搭建、部署运行大模型的全套流程,今天咱们就在这个基础上,继续往下做关键一步:给服务器配置独立显卡,打通 GPU 硬件加速能力。本次实操同样基于 openEuler 22.03 (LTS-SP4) 服务器系统,整体复盘带大家走完RTX 4090 独显适配全流程:从系统内核与发行版信息查看、硬件显卡识别,到禁用系统自带开源驱动、安装编译所需依赖,再到NVIDIA官方驱动编译部署、安装过程常见报错故障排查;驱动装好后,接着完成PyTorch GPU版本环境搭建、大模型AI框架依赖版本冲突修复,最后补上服务器必备的中文字体安装,解决后续绘图可视化中文乱码问题。
整个流程从前置检查、实操步骤到问题排错、环境验证全部覆盖,流程贴合真实服务器落地场景,语言通俗易懂,不管是做服务器运维的同学,还是做大模型、AI开发的小伙伴,都可以照着一步步操作,快速完成RTX 4090显卡适配与深度学习运行环境搭建。

二、系统信息查询
在进行显卡适配前,需先确认服务器内核版本、系统发行版信息,为后续驱动安装提供基础依据。
1. 查看Linux内核信息
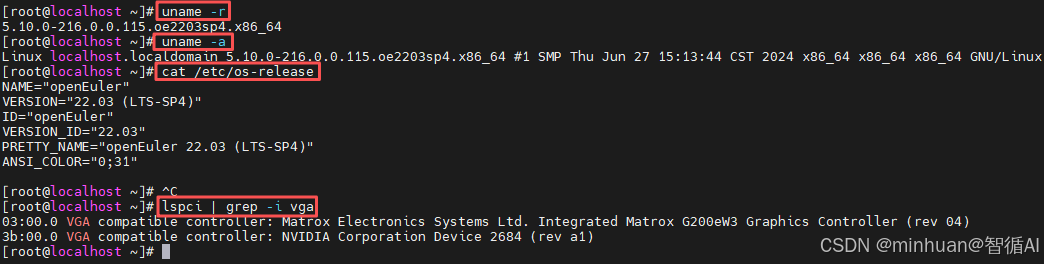
uname是查看系统内核最核心的命令,支持精准查询内核版本与全量信息:
bash
# 仅输出内核版本号(核心参数)
uname -r
# 输出全量内核信息(架构、主机名、系统版本等)
uname -a2. 区分系统版本类型
Linux系统版本分为两类,是驱动安装的关键依据:
- 发行版版本:操作系统发行商版本,如openEuler、Ubuntu、CentOS;
- 内核版本:Linux系统核心程序版本,驱动编译必须匹配对应内核,负责管理系统的核心功能。
3. 查看openEuler发行版信息
执行以下命令查看系统详细版本:
bash
cat /etc/os-release本服务器输出关键信息:
NAME="openEuler"
VERSION="22.03 (LTS-SP4)"
ID="openEuler"
VERSION_ID="22.03"
PRETTY_NAME="openEuler 22.03 (LTS-SP4)"
- 输出中的PRETTY_NAME或NAME和VERSION_ID字段就是对应发行版的名称和版本;
- 以上输出说明,我们现在的操作系统是 openEuler 22.03 (LTS-SP4)
三、NVIDIA显卡硬件识别
首先确认服务器已通过PCIe总线识别RTX 4090显卡,确保硬件无异常,在控制台输入以下命令:
bash
lspci | grep -i vga如果输出中包含 "NVIDIA Corporation" 或 "RTX 4090" 字样,说明硬件已被识别,可以继续。
本服务器正常输出:
03:00.0 VGA compatible controller: Matrox Electronics Systems Ltd. Integrated Matrox G200eW3 Graphics Controller (rev 04)
3b:00.0 VGA compatible controller: NVIDIA Corporation Device 2684 (rev a1)
输出说明:
- NVIDIA Corporation Device 2684 为 RTX 4090 显卡设备 ID,证明硬件已被系统识别;
- 此时显卡处于无驱动状态,需继续安装官方驱动。
四、NVIDIA驱动安装流程
由于openEuler是服务器操作系统,安装显卡驱动时必须先处理内核依赖和冲突驱动,否则安装会失败。
1. 安装编译依赖工具
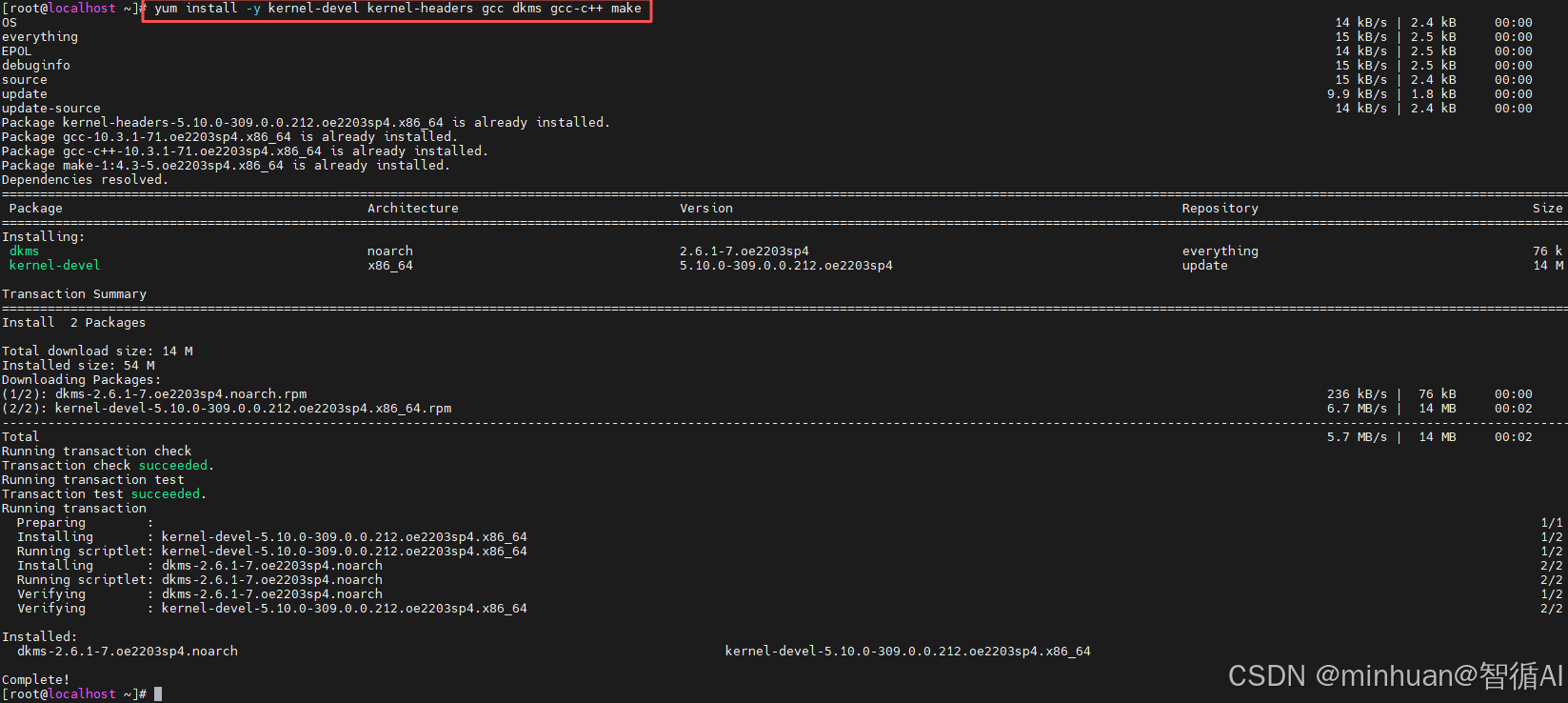
NVIDIA驱动需要编译内核模块,必须安装内核头文件、编译器等依赖,直接执行以下命令:
bash
yum install -y kernel-devel kernel-headers gcc dkms gcc-c++ make完整执行过程参考如下,输出Complete表示安装完成!
2. 禁用Nouveau开源驱动
这是最容易出错的一步,openEuler默认搭载Nouveau开源显卡驱动,与NVIDIA官方驱动冲突,必须彻底禁用,否则驱动安装失败。
步骤 1:编辑黑名单配置文件
选择以下任一文件编辑,推荐第二个,避免系统文件覆盖:
bash
# 方式1(系统默认黑名单)
vi /usr/lib/modprobe.d/dist-blacklist.conf
# 方式2(自定义专用黑名单,推荐)
vi /etc/modprobe.d/blacklist-nouveau.conf步骤 2:添加禁用配置
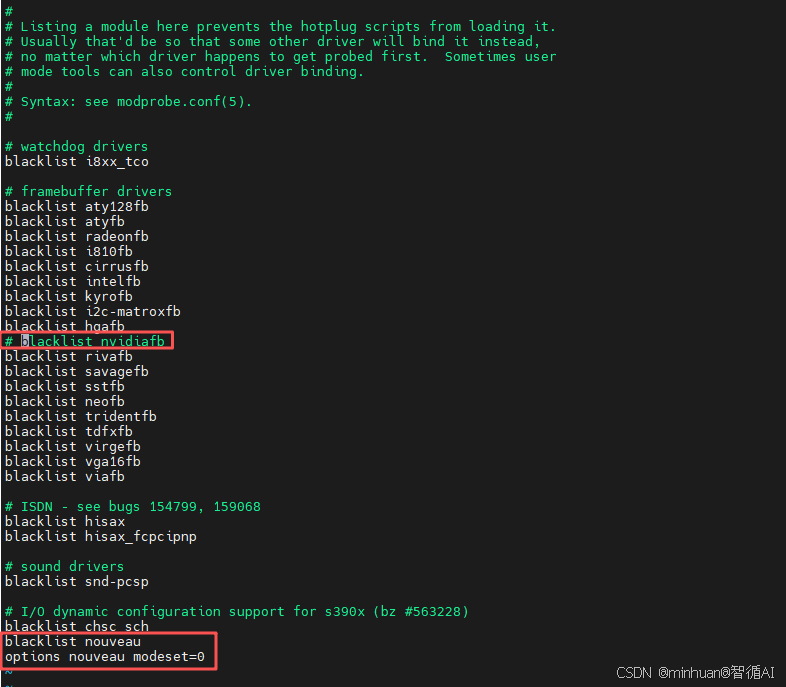
在文件末尾添加以下内容,禁用Nouveau驱动:
bash
blacklist nouveau
options nouveau modeset=0注意:若文件中存在blacklist nvidiafb,请注释或删除,避免干扰驱动安装。
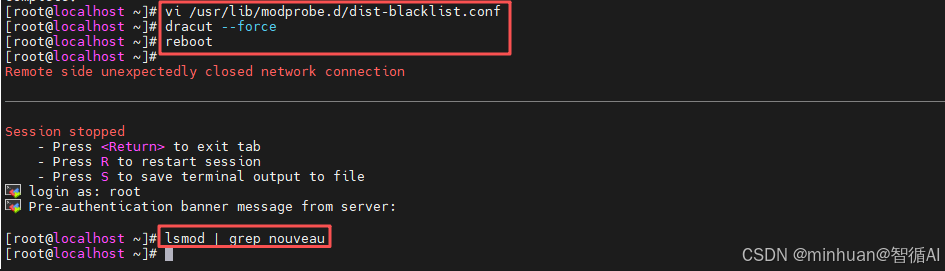
步骤 3:重建系统镜像(关键步骤)
修改配置后必须重建 initramfs 镜像,否则重启后开源驱动仍会加载:
bash
dracut --force步骤 4:重启服务器
bash
reboot步骤 5:验证禁用结果
重启后执行以下命令,无任何输出代表禁用成功:
bash
lsmod | grep nouveau完整步骤执行命令参考:
3. 安装NVIDIA官方驱动
3.1 驱动选择并下载
首先登陆官网首页,直接可以看到手动驱动搜索,搜索对应型号的驱动,GeForce RTX 4090选择如下:
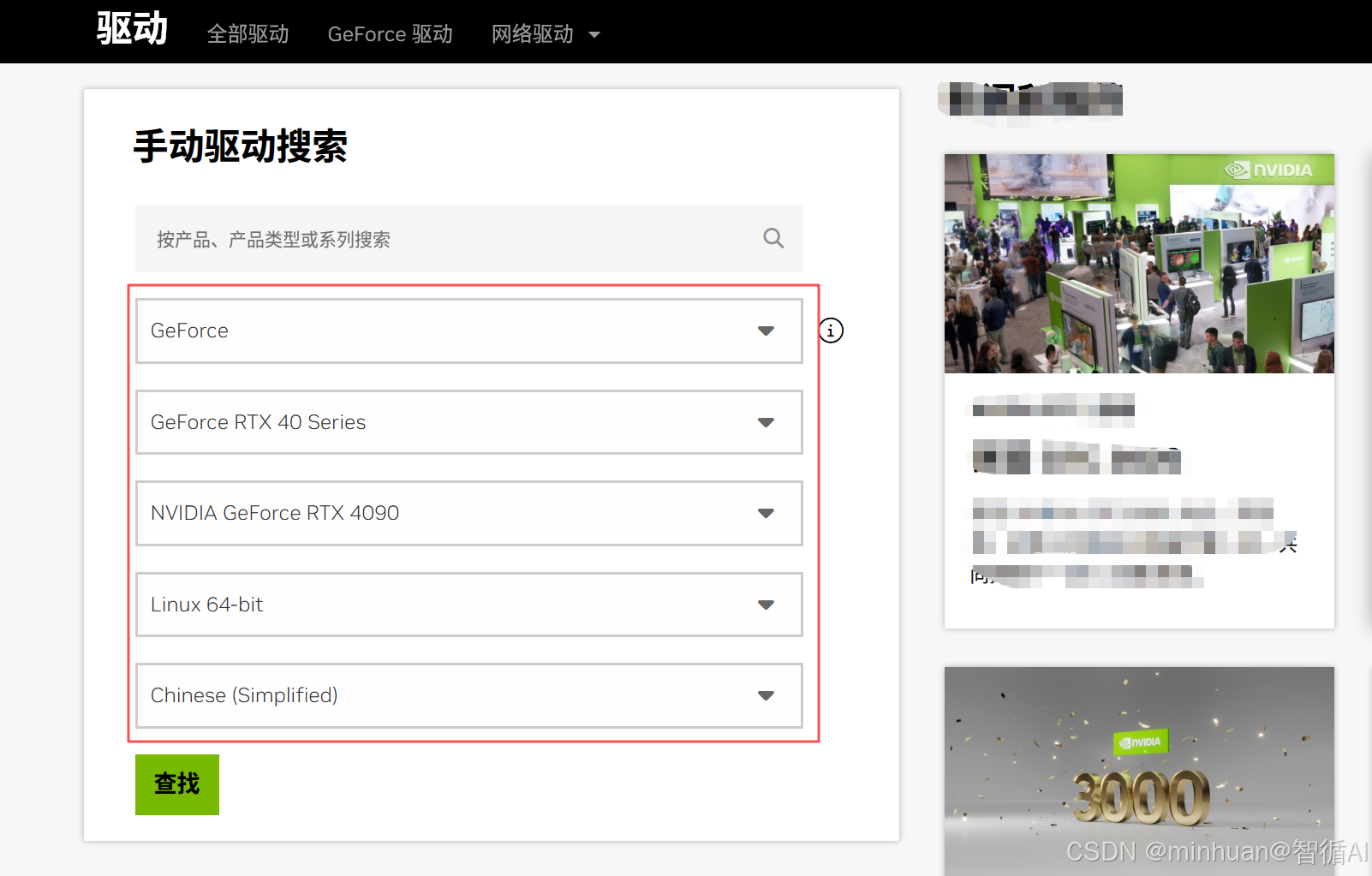
在驱动列选择驱动,根据日期可以选择最新的,建议选择最新版的前一个版本会更稳定;
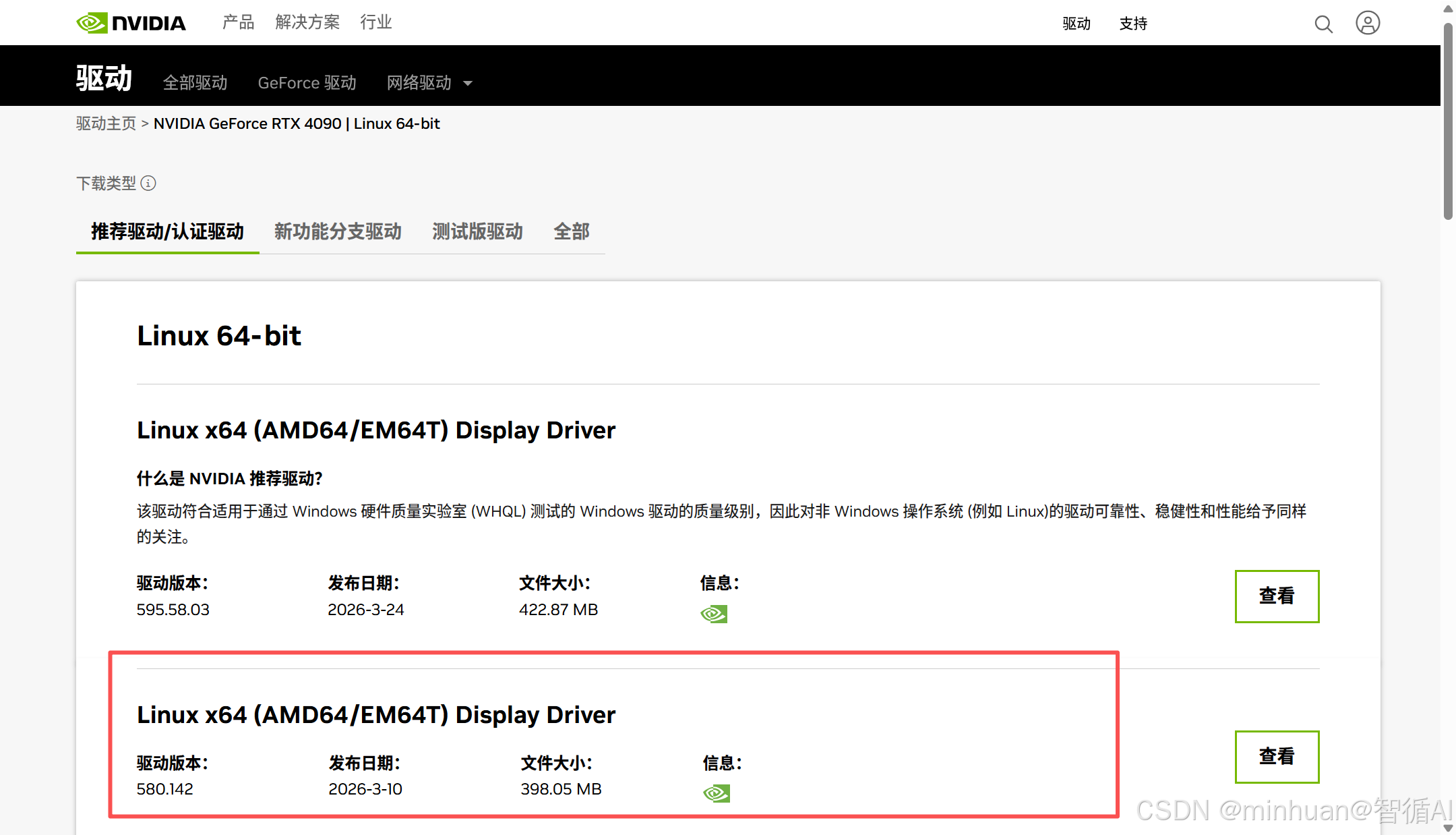
点击"查看",进入详细页,查看详细说明,确认后即可点击"下载"按钮进行下载了。
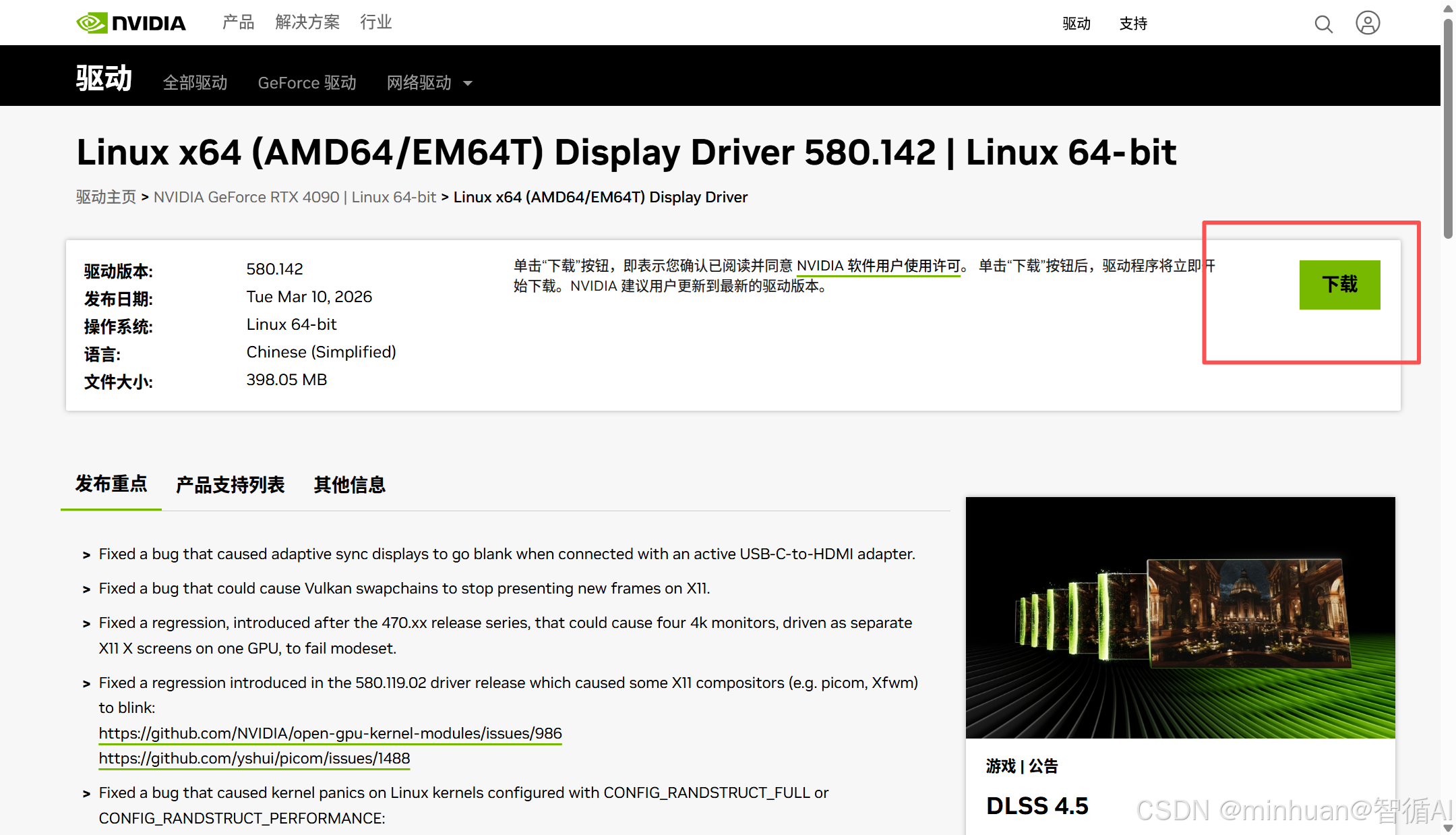
将从NVIDIA官网下载对应显卡的Linux驱动.run文件,如我们应用的NVIDIA-Linux-x86_64-580.142.run上传到服务器上,我们暂存在home目录中;
3.1 执行安装命令
- 1. 赋予驱动文件执行权限:
bash
chmod +x NVIDIA-Linux-x86_64-*.run- 2. 服务器环境专用安装命令
bash
./NVIDIA-Linux-x86_64-*.run --no-opengl-files参数说明:--no-opengl-files 表示不安装OpenGL文件,避免覆盖系统默认库,防止桌面环境冲突,适配服务器无桌面环境。
4. 驱动安装交互配置说明
安装过程中会出现关键交互选项,按以下选择确保稳定性:
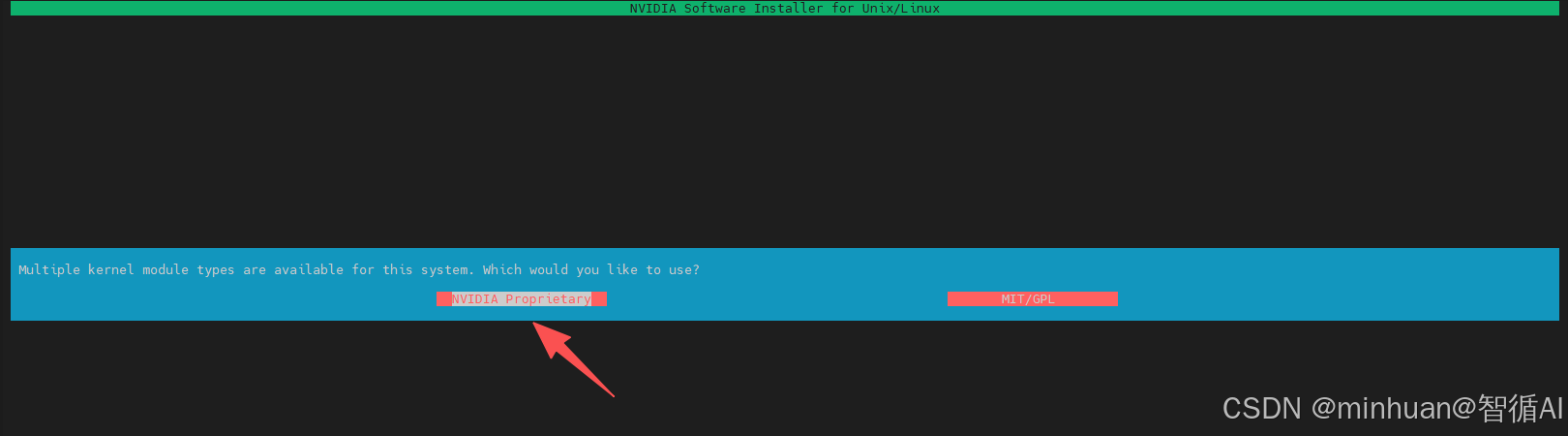
4.1 内核模块类型选择
提示:Multiple kernel module types are available for this system. which would you like to use? 表示NVIDIA 驱动安装程序在询问你想用哪种类型的内核模块。
NVIDIA 驱动现在有两种形式:
- **1. NVIDIA Proprietary(专有驱动):**这是NVIDIA标准的闭源驱动。虽然它包含一些开源组件,如GSP固件,但核心部分是专有的。这是绝大多数用户、游戏玩家和AI开发者的标准选择,兼容性最好,功能最全。
- **2. MIT/GPL(开源内核模块):**这是NVIDIA推出的完全开源的内核模块,主要针对数据中心卡和部分新架构显卡。虽然RTX 4090支持这种模式,但在桌面端或通用计算场景下,它的兼容性和稳定性目前不如专有驱动成熟。
直接选择 NVIDIA Proprietary(专有驱动):
这是默认选项,也是最稳妥、最推荐的选择。它能确保RTX 4090获得最好的兼容性和性能。
4.2 内核模块编译
看到 "Building kernel modules" 时,安装程序正在进行整个过程中最关键、也是最容易报错的一步,正在现场编译一个专门适配当前系统的驱动程序。
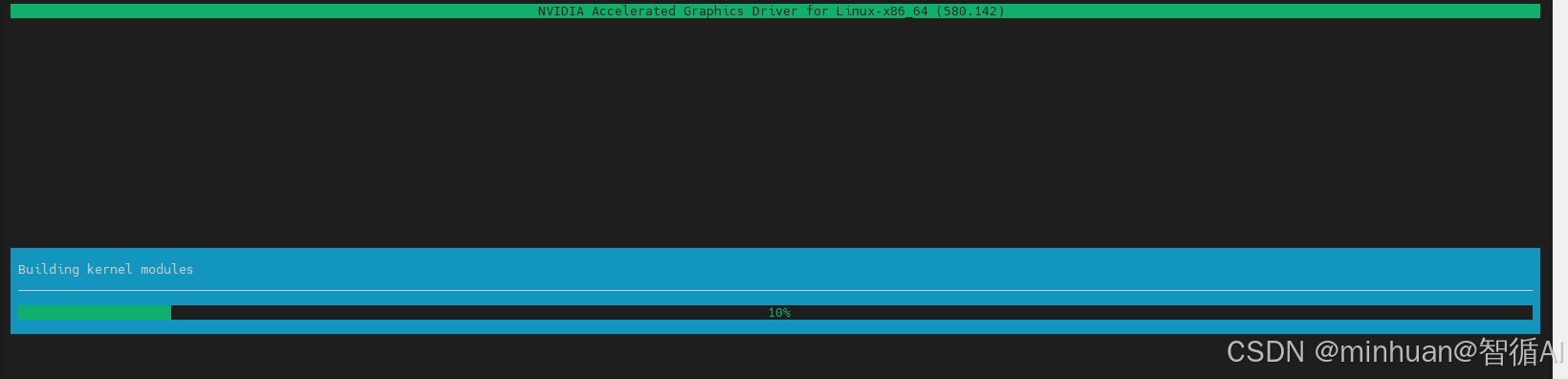
4.3 安装故障排查
果不其然,这一步出现了一个错误提示:
ERROR: Installation has failed. Please see the file '/var/log/nvidia-installer.log' for details. You may find suggestions on fixing installation problems in the README available on the Linux driver download page at nvidia com.
提示安装失败,这在Linux下安装显卡驱动时很常见。提示日志/var/log/nvidia-installer.log文件中有详细说明,日志记录是解决问题的关键,我们去日志里面看看具体描述;
4.3.1 查看错误日志,定位原因
首先,我们需要知道具体是什么导致了失败。执行以下命令查看日志的末尾部分,通常错误信息就在最后:
bash
sudo tail -n 100 /var/log/nvidia-installer.log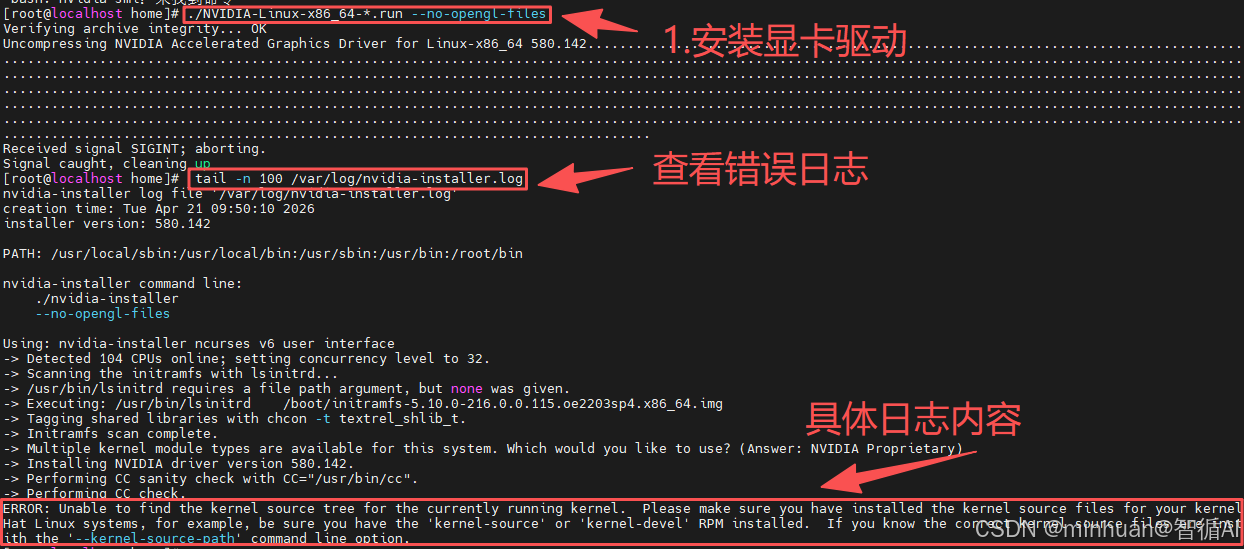
根据查询到的日志,问题非常明确:
- ERROR: Unable to find the kernel source tree for the currently running kernel.
这个错误的意思是,安装程序无法找到与当前正在运行的内核版本相匹配的内核源代码文件。NVIDIA驱动需要这些文件来编译它自己的内核模块。这是一个非常常见的问题,解决起来也很直接。我们按照以下步骤操作;
4.3.2 异常处理解决方案
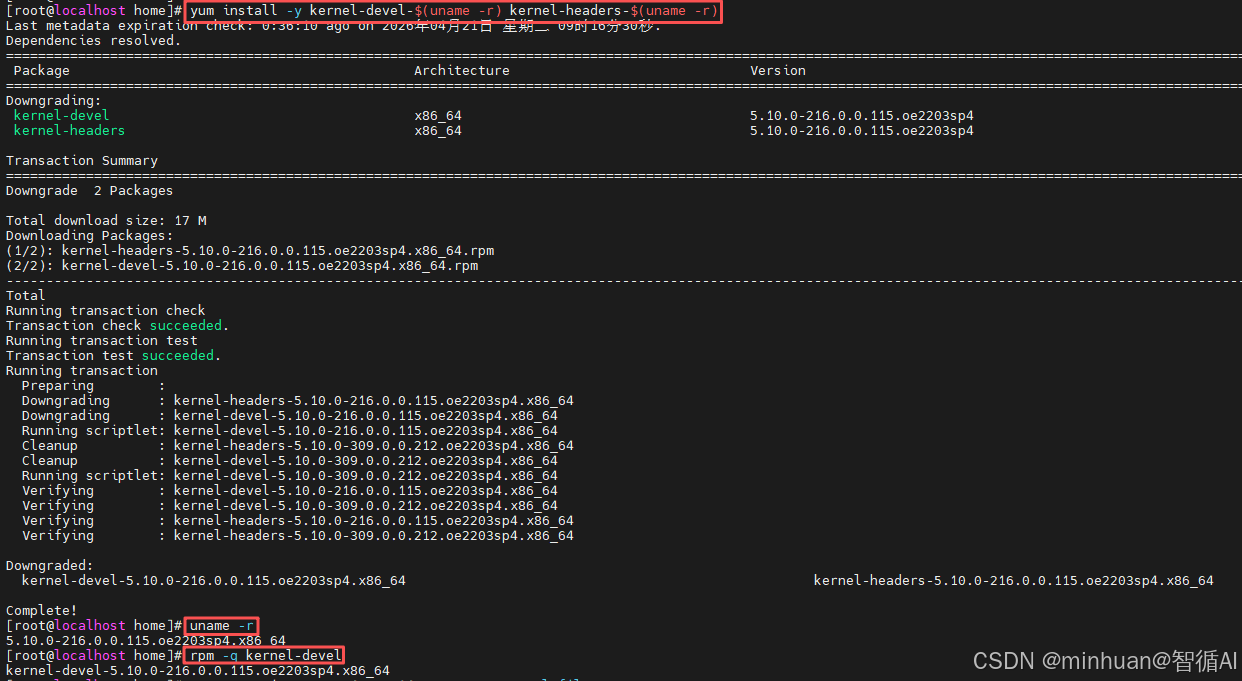
- 1. 安装精准匹配当前内核的开发包:
我们需要安装一个名为kernel-devel的软件包,并且它的版本必须和当前的内核版本完全一致。在终端中直接运行下面这条命令。它会自动获取我们当前的内核版本,并安装对应的kernel-devel和kernel-headers包。
bash
yum install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r)- 2. 验证安装是否成功
安装完成后,建议验证版本是否真的匹配。分别运行以下两条命令,确保输出的版本号完全相同。
bash
# 查看当前内核版本
uname -r
# 查看已安装kernel-devel版本
rpm -q kernel-devel- 3. 版本一致后,重新执行驱动安装命令。
确认kernel-devel安装无误后,就可以重新执行NVIDIA驱动的安装命令了。
sudo ./NVIDIA-Linux-x86_64-580.142.run --no-opengl-files
4.3.3 通用安装失败排查
安装失败时,查看日志定位问题:
- sudo tail -n 100 /var/log/nvidia-installer.log,重点关注包含ERROR或Failed的行;
常见错误及解决:
- gcc not found:重新安装gcc gcc-c++ make;
- kernel headers do not match:重新安装匹配内核头文件;
- Nouveau is in use:重新执行禁用Nouveau全流程。
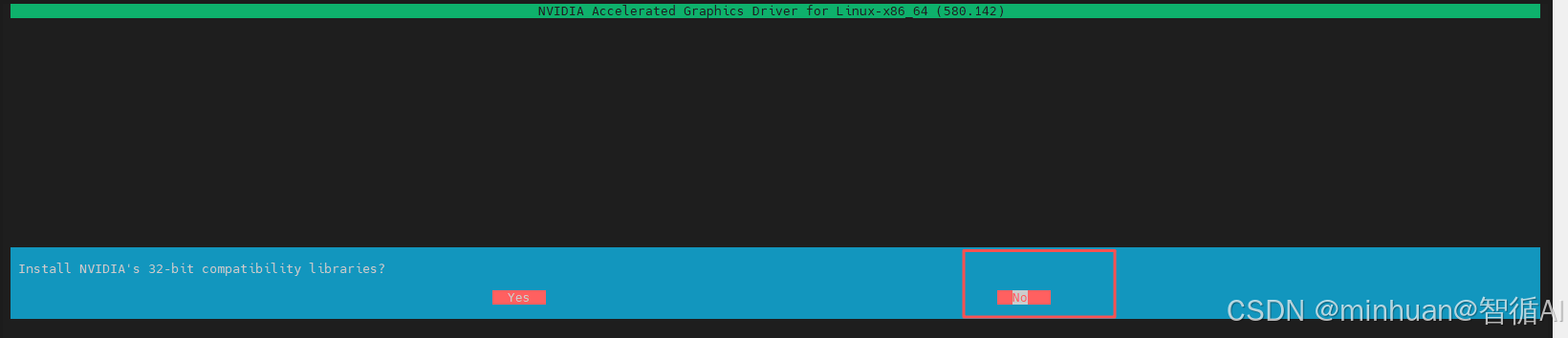
4.4 32位兼容库安装
重新开始安装后,经过了以上正常的步骤,会有一个新的提醒:Install NVIDIA's 32-bit compatibility libraries;
- 直接选择 No。服务器环境通常不需要32位库,除非我们在服务器上要运行32位程序或玩老游戏,否则服务器环境不需要,选了反而可能因为缺少依赖报错。
到此,已经正常完成了安装操作,驱动程序正常安装完毕!
5. 驱动安装成功验证
驱动安装完成后,执行以下命令进行验证,如果能看到类似下图的表格内容,说明RTX 4090驱动安装成功:
bash
nvidia-smi正常输出参考:
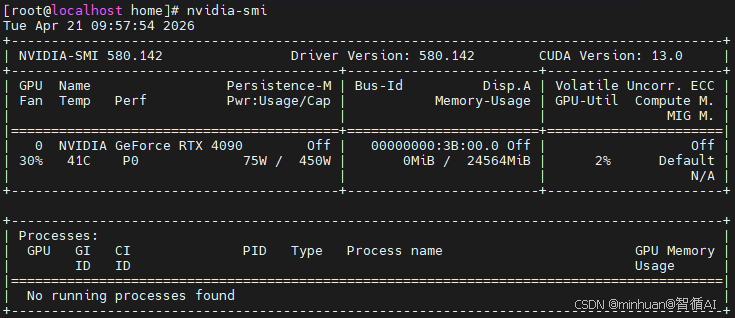
成功标志:显示RTX 4090显卡型号、CUDA版本、显存使用率、驱动版本等信息。
五、PyTorch GPU版本部署
显卡驱动安装完成后,配置 PyTorch GPU 环境,支持 CUDA 加速。
1. 卸载旧版本PyTorch
bash
python3.11 -m pip uninstall torch torchvision torchaudio -y2. 国内镜像安装GPU版PyTorch
这里有一个细节要注意,通常我们通过官方的镜像地址安装:python3.11 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
但经常会出现TimeoutError: The read operation timed out 的错误,说明服务器的网络在连接官方 PyPI源下载PyTorch时超时了。因为PyTorch的包非常大,通常1GB-2GB,直接从官方服务器下载在国内很容易因为网络波动而中断。
解决这个问题非常简单,只需要切换到国内镜像源即可,使用清华镜像 + CUDA12.1专用命令,为了确保安装的是GPU版本,我们必须明确告诉pip要下载支持CUDA的包。推荐使用以下命令,这是PyTorch官方推荐的GPU安装命令,配合清华源加速:
bash
python3.11 -m pip install torch torchvision torchaudio --index-url https://pypi.tuna.tsinghua.edu.cn/simple --find-links https://download.pytorch.org/whl/cu121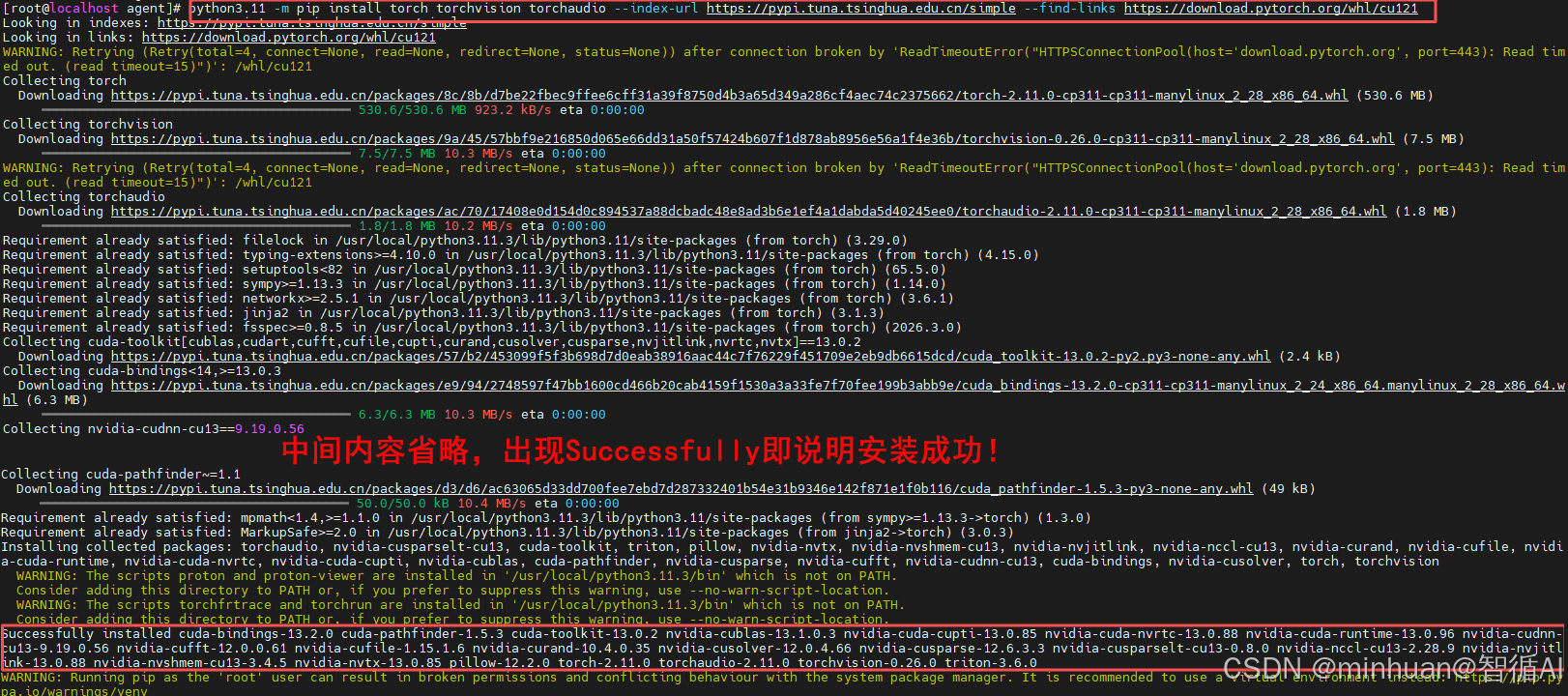
3. 验证GPU环境
进入Python交互环境,执行以下代码:
python
import torch
# 打印PyTorch版本
print(torch.__version__)
# 打印CUDA版本,非None则为GPU版本
print(torch.version.cuda)
# 验证GPU是否可用,True为成功
print(torch.cuda.is_available())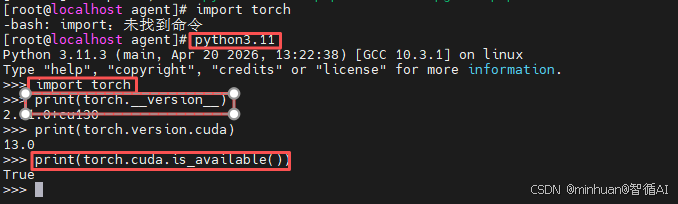
- 如果torch.version.cuda 显示类似13.0,且 is_available() 为 True,那么恭喜你,彻底搞定了!
- 如果还是 None,请务必检查是否还有旧的CPU版本残留,可以用 pip uninstall torch 卸载干净重装。
六、完整示例应用实践
1. ChatGLM2-6B GPU推理API服务
示例基于ChatGLM2-6B大模型部署本地GPU推理API服务。核心流程:使用ModelScope下载模型,自动检测GPU并以float16精度加载(节省显存);通过FastAPI框架提供 /chat 对话接口。
关键配置包括:
- device_map="auto" 自动分配层到GPU;
- low_cpu_mem_usage=True 降低内存占用;
- 添加模型加载状态检查确保服务健壮性。
ChatGLM2-6B大模型的GPU显存要求约13GB+,需确保CUDA环境配置正确。适用于需要本地化部署大模型进行实时对话的业务场景。
python
# 1. 导入需要的库
from fastapi import FastAPI, HTTPException
from transformers import AutoTokenizer, AutoModel, AutoConfig
import torch
import uvicorn
from modelscope import snapshot_download
import warnings
warnings.filterwarnings("ignore")
# --- 修改点 1: 显式定义全局变量 ---
model = None
tokenizer = None
model_name = "ZhipuAI/chatglm2-6b"
cache_dir = "/home/model"
# 2. 初始化FastAPI应用
app = FastAPI(title="ChatGLM2-6B 本地API", description="基于ChatGLM2-6B模型的本地化部署接口")
# 3. 加载模型和Tokenizer
# 注意:这部分代码在脚本启动时会立即执行
print(f"正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
print(f"正在加载模型,路径: {local_model_path}")
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
# 修复ChatGLM配置兼容性问题
config = AutoConfig.from_pretrained(local_model_path, trust_remote_code=True)
if not hasattr(config, 'max_length'):
config.max_length = config.seq_length if hasattr(config, 'seq_length') else 8192
# 使用AutoModel加载
try:
# 强制使用GPU运行
if not torch.cuda.is_available():
raise RuntimeError("❌ 未检测到GPU,请确保CUDA环境配置正确")
print(f"🎮 检测到GPU: {torch.cuda.get_device_name(0)}")
print(f"📊 GPU显存: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.2f} GB")
model = AutoModel.from_pretrained(
local_model_path,
config=config,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto" # 自动分配层到GPU
)
# 确认模型在GPU上
device = next(model.parameters()).device
print(f"✅ 模型加载成功!当前设备: {device}")
except Exception as e:
print(f"❌ 加载失败: {e}")
model = None
# 4. 定义API接口
@app.post("/chat", summary="ChatGLM2-6B对话接口")
def chat(question: str):
# --- 修改点 2: 增加健壮性检查 ---
if model is None:
raise HTTPException(status_code=500, detail="模型未加载,请检查服务器启动日志")
try:
# 处理用户输入
# ChatGLM2 的 chat 方法会自动处理 history
response, history = model.chat(tokenizer, question, history=[])
return {"question": question, "answer": response}
except Exception as e:
raise HTTPException(status_code=500, detail=f"推理出错: {str(e)}")
# 5. 启动API服务
if __name__ == "__main__":
print("启动API服务,访问地址: http://0.0.0.0:8000")
uvicorn.run(app, host="0.0.0.0", port=8000)2. 模型加载异常处理
示例初次运行,经常会遇到插件缺失、参数配置错误、插件版本兼容性问题,我们列举几个常见的异常分析说明,重点在于处理的方式;
2.1 device_map 错误提示:
*
Passing along a `device_map` requires `low_cpu_mem_usage=True`
解决方案:将 low_cpu_mem_usage=False 改为 True,这是使用device_map="auto"的必要条件。
调整后模型会分片加载到GPU,降低内存峰值,如果有多卡,会自动处理多GUP分配;
2.2 accelerate依赖错误提示:
Using `low_cpu_mem_usage=True` or a `device_map` requires Accelerate: `pip install accelerate`
解决方案:安装accelerate依赖库,执行以下命令:
bash
python3.11 -m pip install accelerate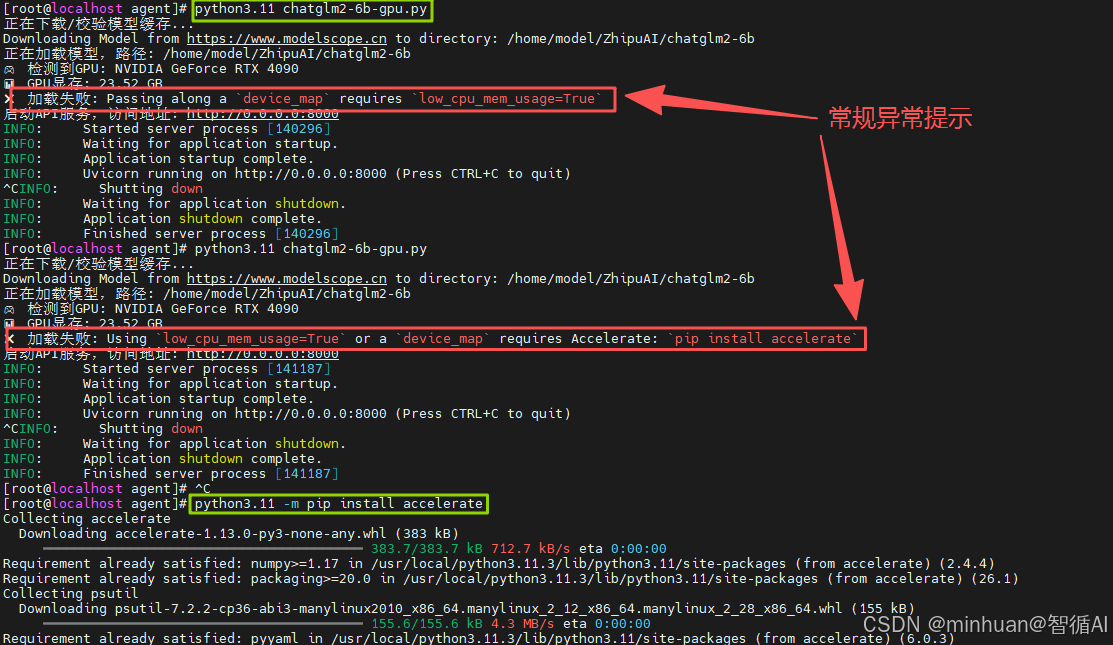
2.3 版本兼容性错误提示:
ImportError: huggingface-hub>=0.16.4,<1.0 is required... but found huggingface-hub==1.11.0
这是插件版本兼容性问题,经常会遇到,在不同的模型版本中也经常出现,说的很明确,我们仔细分析:
- 需求方:transformers 库要求 huggingface-hub 的版本必须在 0.x 系列(大于 0.16.4 且小于 1.0)。
- 现状:我们当前安装的 huggingface-hub 版本是 1.11.0。
- 原因:huggingface-hub 发布了大版本更新(1.0+),其中可能包含破坏性变更,而我们安装的 transformers 版本尚未适配这个新主版本。
解决方案:降级huggingface-hub
- 我们需要将huggingface-hub降级到符合要求的版本。最稳妥的方法是将其降级到0.x系列的最新稳定版。
- 为了保险起见,直接指定一个已知兼容的稳定版本,例如0.25.0:
bash
python3.11 -m pip install huggingface-hub==0.25.0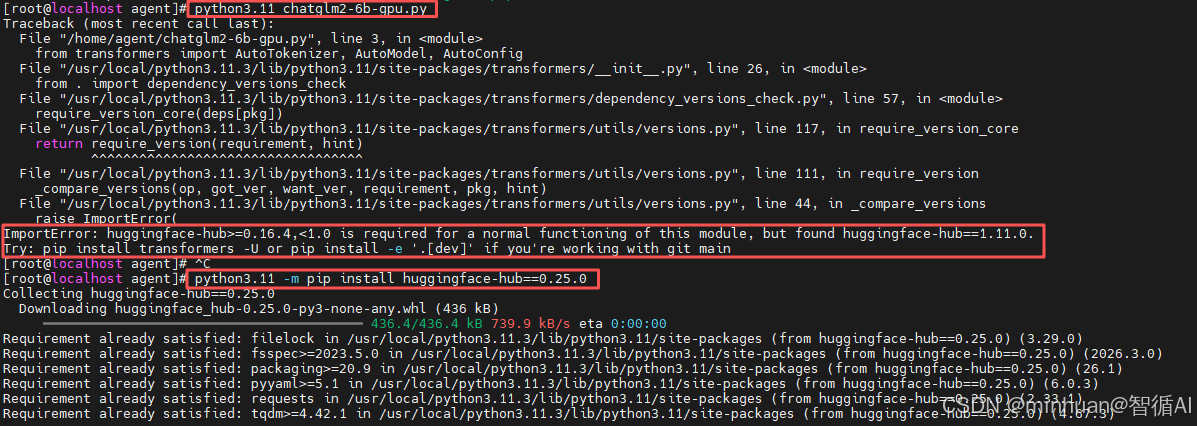
2.4 插件缺失错误提示:
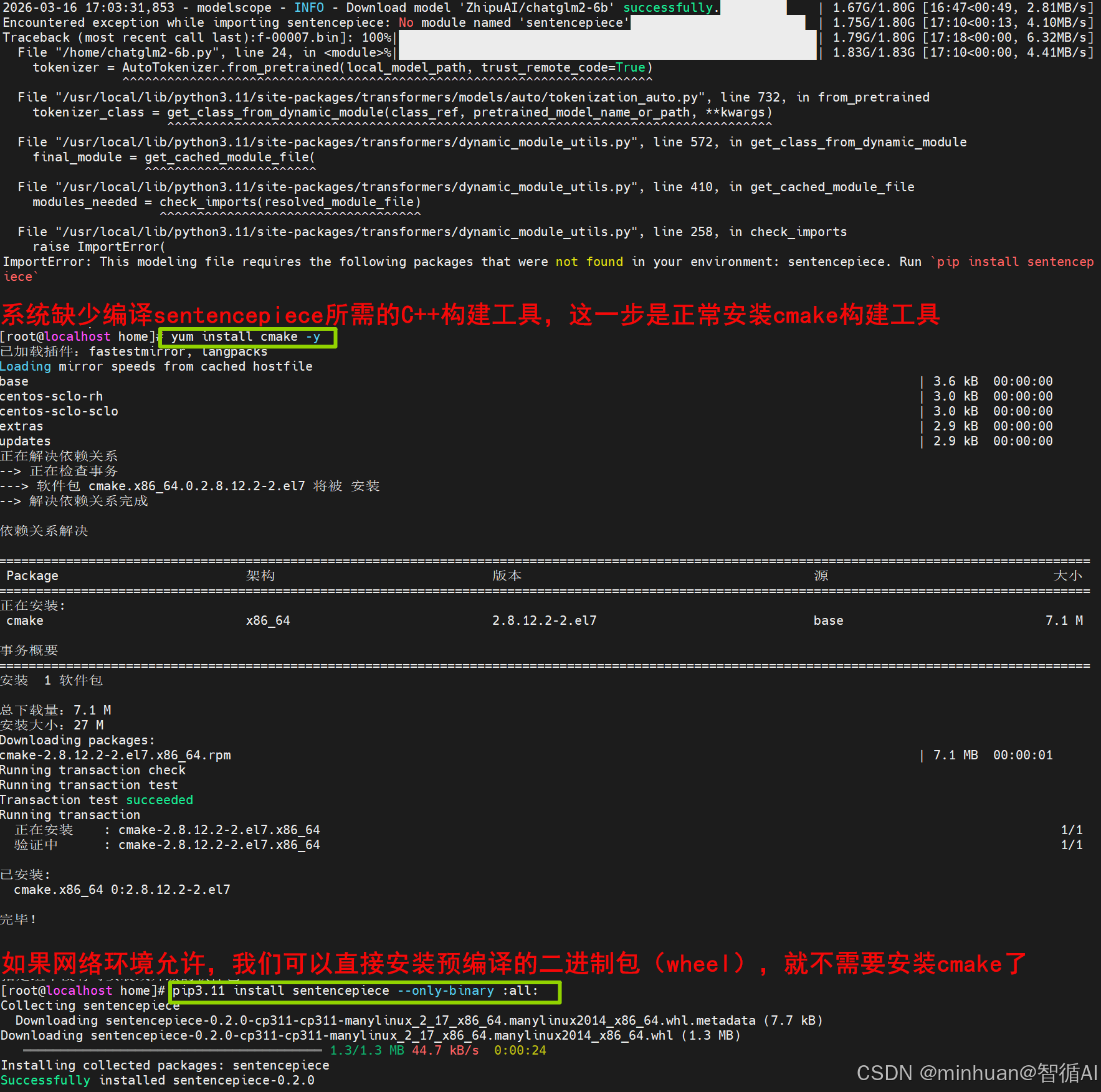
importError This modeling file requires the following packages that were not found in your environment: sentencepiece. Run `pip install sentencepiece`
这个错误表明系统缺少编译sentencepiece所需的C++构建工具,特别是cmake和g++,pip试图从源码编译sentencepiece,但发现系统中没有cmake(报错:cmake: 未找到命令),导致编译失败。
如果网络环境允许,我们也可以尝试直接安装预编译的二进制包(wheel),这样就不需要cmake了。但在某些特定的Linux版本或Python版本下,可能没有对应的预编译包,必须走上面的源码编译流程,详细如下图中的执行说明;
3. 接口服务正常启动
在层层错误处理完成后,模型正常加载,服务也正常启动,提供外部调用;

4. 显卡运行状态查看
服务正常启动后,我们可以通过nvidia-smi命令查看显卡的运行状态:
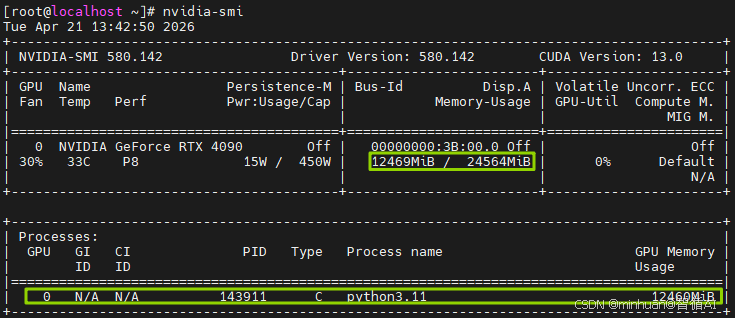
4.1 驱动与硬件状态
NVIDIA-SMI 580.142 | Driver Version: 580.142 | CUDA Version: 13.0
- 驱动版本 580.142:这是NVIDIA官方驱动版本,已成功安装并运行;
- CUDA Version: 13.0:代表驱动支持的最高CUDA版本,后续PyTorch等AI框架可直接使用。
4.2 核心硬件与负载信息
GPU 0: NVIDIA GeForce RTX 4090
温度: 33°C | 风扇转速: 30% | 功耗: 15W / 450W
显存占用: 12469MiB / 24564MiB (约12GB/24GB)
GPU利用率: 0%
- 显卡是RTX4090,完整24GB显存已被识别;
- 温度33°C、功耗15W,说明当前负载极低,散热和供电都正常;
- 显存占用约12GB,而GPU利用率 0%,说明显存被占用的进程并未真正跑满计算单元,大概率是大模型刚加载完模型权重,还未开始推理或训练。
4.3 显存占用的进程
GPU 0 | PID 143911 | 进程名: python3.11 | 显存占用: 12460MiB
- 占用12GB显存的进程是python3.11,也就是我们当前运行的Python程序;
- 结合显存大小来看,这是一个加载了约12GB模型权重的大模型推理任务;
- 进程 PID(143911)可用于后续管理:
- 想终止进程:kill -9 143911
- 查看进程详情:ps -ef | grep 143911
4.4 其他关键细节
- Persistence-M: Off:持久模式未开启,对当前任务无影响,服务器环境下可按需开启;
- Compute M.: Default:默认计算模式,适配通用AI计算场景;
- Disp.A: Off:无显示输出,符合服务器无桌面环境的特点。
七、服务器中文字体安装
解决matplotlib等工具中文乱码问题,安装开源中文字体,这里要注意安装的系统级字体包,不是Python包,不能用pip安装。
bash
# openEuler/CentOS/RHEL系列执行
yum install wqy-microhei-fonts -y如果是非以上系列的系统,参考以下方式安装:
-
- 先确认系统的发行版,通过命令识别:cat /etc/os-release
-
- 然后根据结果选择:
bash
# Debian/Ubuntu安装方式
apt update
apt install fonts-wqy-microhei
# Arch安装方式
pacman -S wqy-microhei
#Fedora安装方式
dnf install wqy-microhei-fonts接着运行以下命令清除matplotlib缓存:
bash
rm -rf ~/.cache/matplotlib
八、总结
服务器安装最大的感悟就是细节决定成败,从最开始的系统信息查询、硬件识别,到驱动安装、PyTorch GPU环境配置、框架依赖排错,再到最后验证显卡状态,整个过程走下来,发现最容易踩坑的不是安装本身,而是那些看不见的前置条件:比如内核版本必须和kernel-devel严格对应、Nouveau驱动必须彻底禁用、PyTorch 安装时国内网络容易超时,甚至huggingface-hub的版本冲突都可能让我们功亏一篑。这些细节在教程里看着简单,实际操作时每一步都可能出问题,必须耐下心看日志、查报错。
给正在做类似配置的大伙们一个建议:所有依赖安装尽量和系统环境对齐,不要盲目追求最新版本;最后,遇到报错别慌,按流程一步步排查,比反复重装要高效得多。