一、 痛点:为什么通用大模型干不了这活?
首先声明,我们不是大模型黑。但在心理预警这个场景下,直接用GPT-4或者文心一言的API,有三个致命伤:
-
**成本炸裂:** 每天几万条的学生/员工咨询日志,按token付费谁受得了?
-
**隐私红线:** 心理数据属于极度敏感信息,学校和企业根本不敢让你传公网。
-
**幻觉问题:** 有时候模型会一本正经地胡说八道,万一误判了"自杀倾向",责任谁担?
所以,结论很明确:必须私有化部署,且必须是小模型微调。
一开始我们想偷懒,直接用 TextCNN或者单纯的 BERT-base。结果踩了两个坑:
-
**TextCNN:** 对于长难句的理解力太差,特别是那种"看似抱怨实则求救"的句子,比如"今天天气真好,要是跳下去应该很凉快吧",它完全抓不到逻辑关联。
-
**单纯BERT:** 参数量太大,推理速度慢,而且容易过拟合。我们在小样本(只有几千条标注数据)上训出来的模型,泛化能力很差。
于是,就有了现在的方案:BERT提取语义特征 + BiLSTM捕捉长距离依赖 + Attention机制加权。
二、 技术架构:不只是简单的拼接
我们的核心思路是:利用BERT作为"静态编码器",把词语转化为富含上下文信息的向量;然后扔给BiLSTM去捕捉句子前后的时序关系。
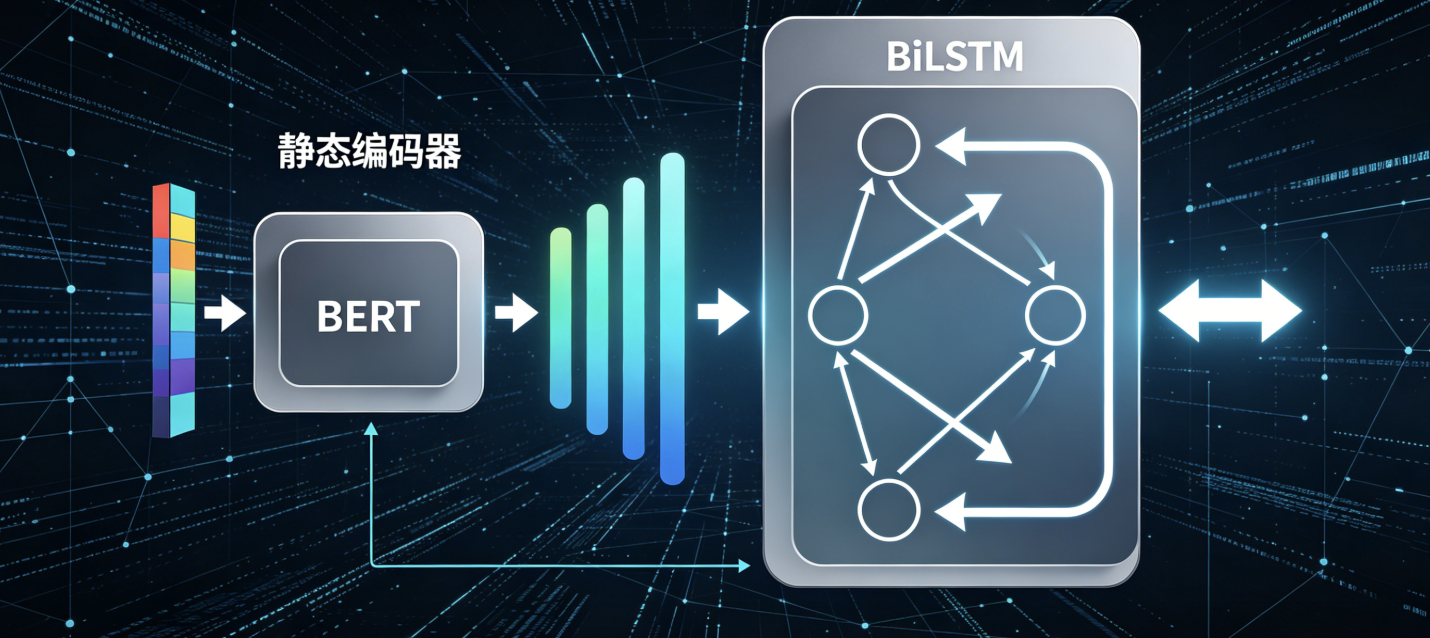
[原始文本输入]
↓
[BERT Tokenizer] (WordPiece分词)
↓
[BERT Encoder] (冻结部分层,只微调最后4层)
↓ (输出 [CLS] token 或 所有token的hidden states)
[BiLSTM Layer] (双向LSTM,捕捉前后文语境)
↓
[Self-Attention] (给关键情绪词加权,如"死"、"累"、"崩溃")
↓
[Dropout] (防止过拟合,这里设了0.5)
↓
[Softmax] (输出 7种情绪标签)为什么要用 BiLSTM?
很多新人会问:BERT本身不就已经包含了上下文信息吗?
简单说,BERT的注意力是并行的,而BiLSTM是串行的。在处理"转折"句式时,LSTM的门控机制(Forget Gate)对于丢弃无关信息和保留关键情绪状态非常有效。
三、 核心干货:模型实现与微调细节
这是我们基于 Transformers库魔改的训练代码核心部分。
1. 数据预处理:处理"阴阳怪气"
心理文本最难处理的不是脏话,而是反语。
我们构建了一个简单的规则引擎进行预标注,同时引入了心理学词典(如LIWC中文版)进行特征增强。
import jieba
from transformers import BertTokenizer
# 自定义的心理关键词权重字典
PSY_WEIGHT_DICT = {
"想死": 2.0, "自杀": 2.0, "解脱": 1.5, "睡不着": 1.2,
"开心": -1.0, "快乐": -1.0 # 反向词降权
}
def tokenize_with_weight(text, tokenizer, max_len=128):
"""
这里的骚操作:在tokenize的同时,给特定词加上attention mask的权重
"""
tokens = tokenizer.tokenize(text)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# 构造attention_mask,默认是1
attention_mask = [1] * len(input_ids)
# 检查是否包含高危词
for word, weight in PSY_WEIGHT_DICT.items():
if word in text:
# 找到这个词对应的token位置,手动提高mask值
# 实际工程中这里需要更复杂的对齐逻辑
pass
return input_ids, attention_mask注: 上面的代码是简化版,实际生产中我们是在Dataset类里重写了
__getitem__方法。
2. 模型定义:冻结BERT,训练下游
为了在低配GPU(比如T4)上跑起来,我们选择冻结BERT的前8层,只微调后4层和BiLSTM部分。
import torch
import torch.nn as nn
from transformers import BertModel
class BertBiLSTMPredictor(nn.Module):
def __init__(self, pretrained_model='bert-base-chinese', num_classes=7):
super().__init__()
self.bert = BertModel.from_pretrained(pretrained_model)
# 冻结BERT参数(这是省显存的关键)
for param in self.bert.parameters():
param.requires_grad = False
# 只解冻最后一层
for param in self.bert.encoder.layer[-4:].parameters():
param.requires_grad = True
self.lstm = nn.LSTM(
input_size=self.bert.config.hidden_size,
hidden_size=256,
num_layers=2,
bidirectional=True,
batch_first=True
)
self.attention_fc = nn.Linear(256 * 2, 1) # 双向LSTM输出512维
self.classifier = nn.Linear(256 * 2, num_classes)
def forward(self, input_ids, attention_mask):
# BERT输出
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
sequence_output = outputs.last_hidden_state # [batch, seq_len, hidden]
# BiLSTM处理
lstm_out, _ = self.lstm(sequence_output) # [batch, seq_len, 512]
# Self-Attention 加权
attn_weights = torch.tanh(self.attention_fc(lstm_out))
attn_weights = torch.softmax(attn_weights, dim=1)
context_vector = torch.sum(attn_weights * lstm_out, dim=1)
logits = self.classifier(context_vector)
return logits3. 损失函数:搞定样本不平衡
心理数据中,"正常"样本占90%,"重度抑郁"可能只有1%。
直接训练会导致模型把所有样本都预测成"正常"。
我们用 Focal Loss 替代 CrossEntropyLoss:
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0):
super().__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, inputs, targets):
ce_loss = nn.CrossEntropyLoss(reduction='none')(inputs, targets)
pt = torch.exp(-ce_loss)
focal_loss = self.alpha * (1 - pt) ** self.gamma * ce_loss
return focal_loss.mean()四、 踩坑实录 & 性能优化
坑1:显存溢出(OOM)
一开始我开了 batch_size=32,直接爆显存。除了冻结BERT,我们还用了梯度累积(Gradient Accumulation)。
# 伪代码
accumulation_steps = 4
for i, batch in enumerate(dataloader):
loss = model(batch) / accumulation_steps
loss.backward()
if (i + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()坑2:推理太慢
上线测试时发现,单条文本推理要300ms,用户体验极差。
解决方案:ONNX Runtime。
把 PyTorch 模型导出为 ONNX 后,CPU 上的推理速度提升了近 3 倍,稳定在 80‑100 ms。
五、 结语
这套 BERT + BiLSTM的架构,在我们的某高校试点项目中,对高风险人群的召回率达到了 92%,误报率控制在 5% 以内。
当然,技术只是手段,AI 永远无法替代心理咨询师那双温暖的手。我们的目标是通过技术手段,把那些隐藏在角落里的求救信号放大,让干预变得更及时。
如果大家对具体的 ONNX 导出脚本或者数据标注规范感兴趣,可以在评论区留言,我下篇博客专门讲讲。