目录
[1. 为什么从局域网开始](#1. 为什么从局域网开始)
[2. 局域网通信例子](#2. 局域网通信例子)
[二、MAC 地址](#二、MAC 地址)
[1. 什么是 MAC 地址](#1. 什么是 MAC 地址)
[2. 数据碰撞](#2. 数据碰撞)
[3. 同一网段通信流程](#3. 同一网段通信流程)
[1. 报头、载荷与报文](#1. 报头、载荷与报文)
[2. 段、报、帧](#2. 段、报、帧)
[3. 封装过程](#3. 封装过程)
[4. 分用过程](#4. 分用过程)
[1. 为什么需要 IP 地址](#1. 为什么需要 IP 地址)
[2. IP 地址](#2. IP 地址)
[3. 路由转发](#3. 路由转发)
[4. IP 与 MAC 的区别](#4. IP 与 MAC 的区别)
[5. IP 层屏蔽底层差异](#5. IP 层屏蔽底层差异)
一、局域网
在前文中,我们明确了协议的本质是结构化数据。然而,数据仅在内存中有序排列是不够的,它还需要穿越复杂的网络环境------包括电缆、路由器和交换机等设备------最终到达目标机器
本篇将从最基础的局域网(LAN)开始,逐步解析数据包如何在物理介质上实现 "第一跳" 传输
1. 为什么从局域网开始
网络通信遵循 "分而治之" 和 "局部连接" 的原则。实际上,无论数据包的目的地是哪,它离开发送端主机的第一步,都是在局域网内完成的。局域网是构成全球互联网的最小细胞,理解了局域网的内部通信,跨网络通信也就只是多个局域网之间的接力跳跃而已
以太网
在局域网的众多实现技术中,以太网占据着无可争议的主导地位
-
本质:以太网不仅仅指我们平时插的网线,它是一套完整的局域网通信标准(主要对应 OSI 模型中的物理层和数据链路层)
-
特性 :以太网的核心是一种广播式的通信方式。在同一个局域网内的所有主机,物理上都连接在同一个共享的通信介质(比如早期的总线或现在的交换机)上
2. 局域网通信例子
为了直观理解局域网的工作模式,我们可以看一个现实生活中的经典场景
想象一下,在一个有 50 名学生的教室里:
-
环境即媒介:教室里的空气就是通信介质,每个人的耳朵都在实时监听
-
广播发送:老师大声喊了一句:张三,把你写的作业交上来!
-
目标识别与过滤:
-
全体接收 :由于声音在空气中传播,教室内所有学生 其实都听到了这句话。这在网络中被称为广播
-
静默过滤:李四听到了,但他发现目标名字是 "张三" 而不是自己,于是他选择忽略,不予响应
-
精准响应:张三听到了,发现名字匹配成功,于是他站起来(做出响应)并将作业(数据载荷)交给老师
-
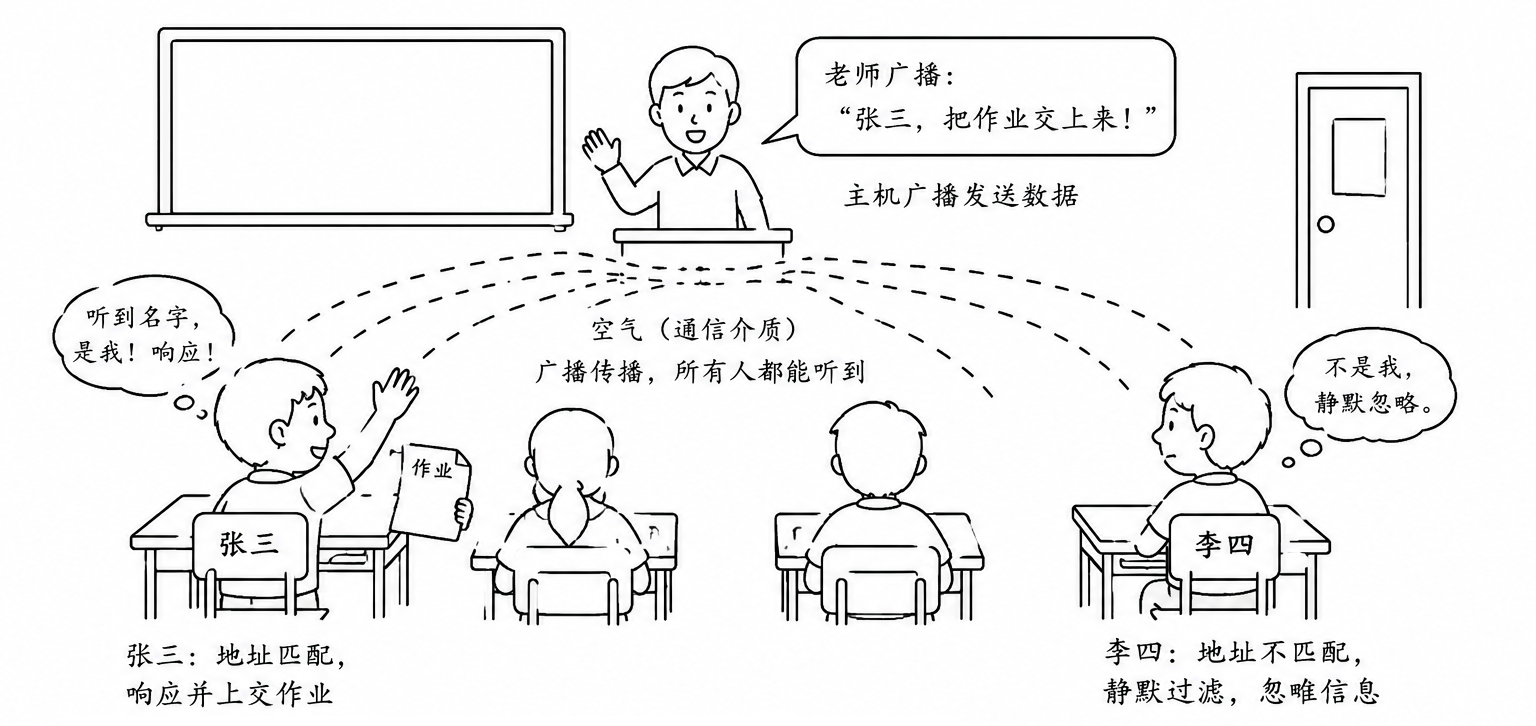
在这个例子中,"张三" 这个名字就充当了网络中的地址标识 。在局域网的底层,这个标识就是我们下一节要讲的 MAC 地址
二、MAC 地址
在局域网中如果所有设备都无序地发送信号,通信很快就会陷入混乱。为了确保通信有序进行,我们需要为每个网络设备分配唯一的标识符,并建立规范的通信协议
1. 什么是 MAC 地址
MAC 地址(Media Access Control Address),直译为媒体存取控制地址,它是网卡的物理身份证。它工作在数据链路层,负责在局域网内部精确地寻找目标
-
唯一性:每一块网卡在出厂时,都会被烧录一个全球唯一的 MAC 地址
-
格式:由 48 位二进制组成,通常用 12 位十六进制数表示(如 00:0c:29:4f:8b:36)
注意:MAC 地址和你的地理位置无关。无论你把电脑带到北京还是纽约,网卡的 MAC 地址永远不变,它唯一标识的是 "设备身份",而非 "物理位置"
2. 数据碰撞
什么是数据碰撞?
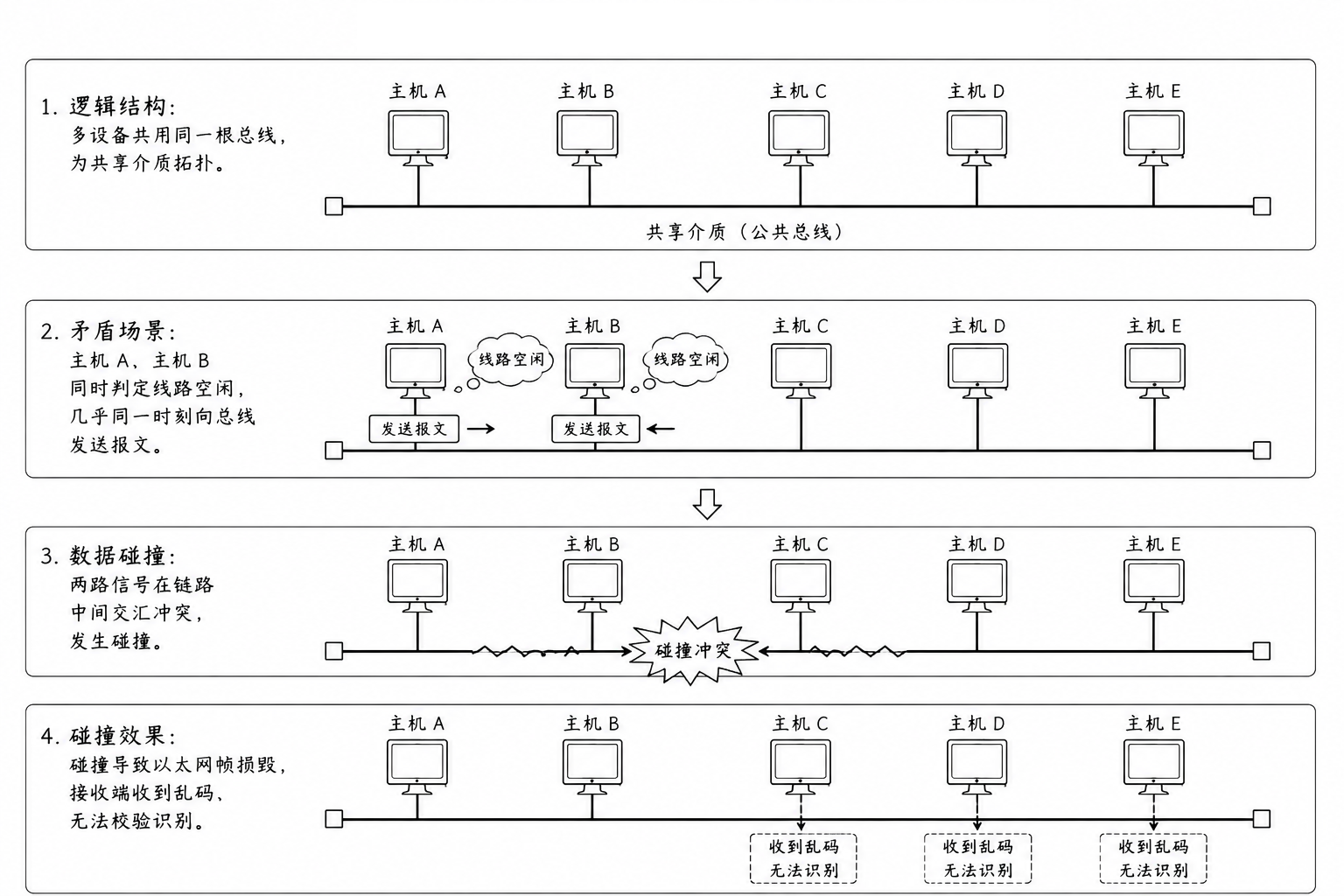
从网络传输的角度看,局域网(特别是早期的总线型网络)就像是一条单行道 ,但在同一时间内,这条路只允许一辆车(一个数据包)通行
产生原因
在逻辑上,我们把这种多台设备连接在同一根线上的结构称为共享介质
-
逻辑矛盾:当主机 A 认为线路空闲并开始发送报文时,主机 B 可能几乎在同一瞬间也认为线路空闲并发送了报文
-
数据损毁 :这两个报文在逻辑链路上发生碰撞。在接收方看来,收到的不再是完整的以太网帧,而是一串破碎的、无法校验通过的乱码
为了解决这个问题,诞生了两个重要的机制:
-
CSMA/CD:这是一种 "先听后发" 的礼貌通信机制。设备在发送数据前会先检测信道是否空闲;若在传输过程中检测到冲突,则会立即停止发送,等待一段随机时间后重新尝试
-
交换机 : 现代局域网已基本淘汰这种 "广播式" 通信模式。交换机会利用内置的 MAC 地址表,将数据精准地从发送方传输至接收方,有效避免了数据碰撞,使每台设备都能实现 "点对点" 通信
3. 同一网段通信流程
这是局域网通信最经典的过程。假设主机 A 要给主机 B 发送数据,而它们处于同一个局域网内:
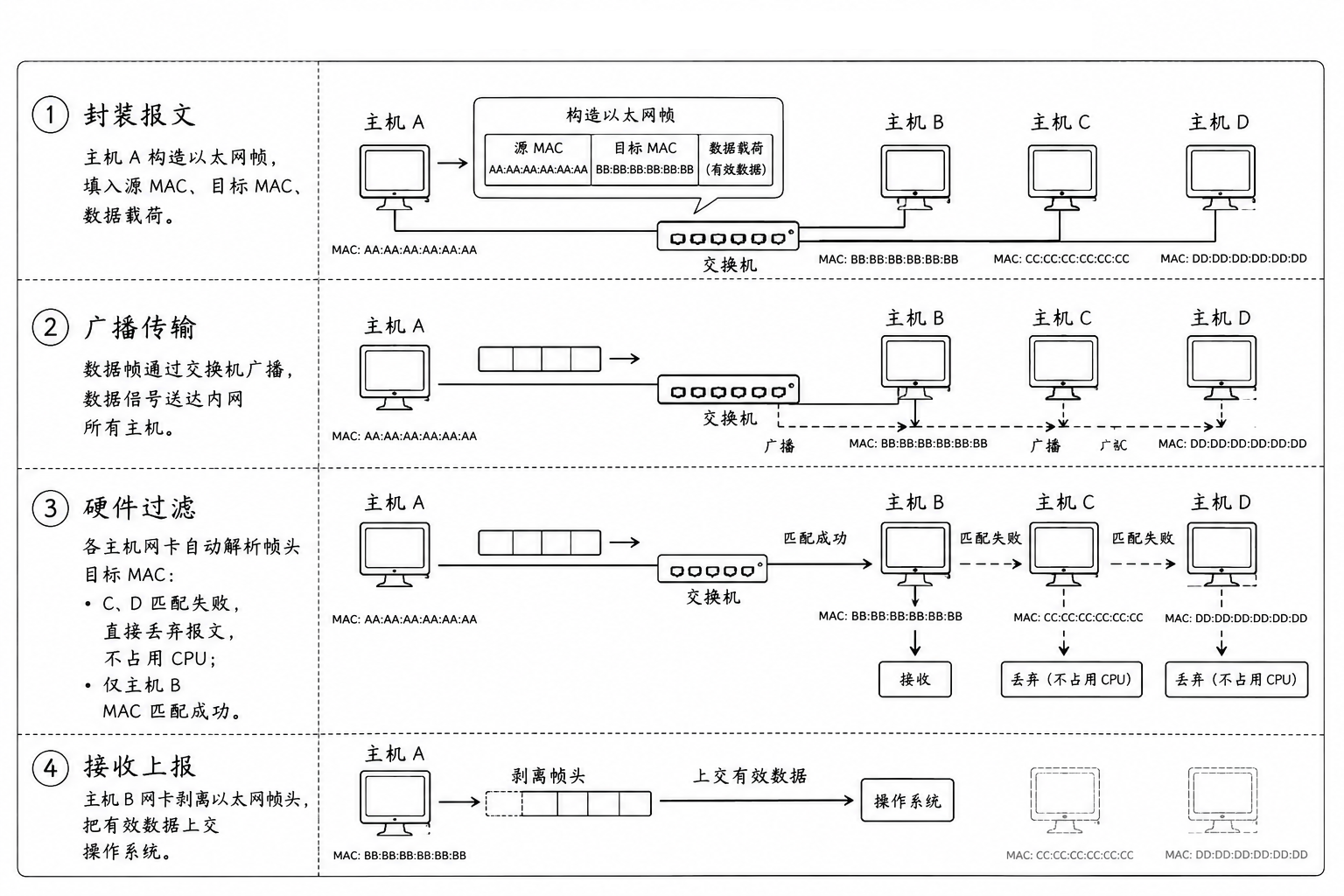
(1) 封装报文
主机 A 会构建一个以太网帧。在这个帧的头部,它会填入:
-
源 MAC 地址:A 自己的地址
-
目标 MAC 地址:B 的地址
-
数据载荷:真正要传输的内容
(2) 广播传输
虽然数据是发给 B 的,但物理信号会顺着电缆传送到局域网内的每一台主机(或者发给交换机由其扩散/转发)
(3) 硬件过滤
这是最关键的一步。局域网内的所有主机(C、D、E...)的网卡都会收到这个信号:
-
主机 C :网卡读取帧头部的 "目标 MAC",发现不是自己,直接丢弃。CPU 完全感知不到有数据包经过,没有任何系统开销
-
主机 D:同上,丢弃
-
主机 B:网卡发现 "目标 MAC" 与自己的 MAC 地址完全匹配!
(4) 接收并上报
主机 B 的网卡确认身份后,会剥离掉以太网帧的报头,将剩余的有效载荷(Data)向上递交给操作系统处理
三、封装与分用
掌握了局域网的 "交通规则" 后,让我们来看看数据在传输前是如何 "包装" 的。在网络通信中,数据不会以原始状态传输,必须经过精密的封装处理
1. 报头、载荷与报文
报头是协议栈每一层在处理数据时额外添加的控制信息
-
现实类比 :报头就像是快递盒上贴的那张面单。上面写着发件人、收件人、包裹重量、是否易碎、快递单号等。快递员不关心盒子里装的是什么,他只看面单上的地址来决定往哪送
-
技术本质:在 Linux 内核中,报头通常是一个定义的结构体。它包含了目标地址、源地址、协议类型、校验和等关键元数据
载荷(也叫有效载荷)是指被协议包裹的真实数据
-
现实类比 :载荷就是你真正寄给朋友的那件衬衫。对于快递公司来说,衬衫是载荷;对于收件人来说,衬衫才是他真正想要的东西
-
嵌套关系 :这是一个非常关键的逻辑------上一层的完整报文,是下一层的载荷
- 就像你把衬衫(载荷)装进礼品盒(报头 1),然后快递公司把整个礼品盒放入了一个更大的运输纸箱(报头 2)。对运输纸箱来说,里面的礼品盒整体就是它的载荷
报文 是对网络传输中一个完整数据单元的通用称呼
在应用层、传输层和网络层中,这些传输的数据统称为 "报文"。不过,为了体现各层的功能特性,工程师们为不同层级的报文赋予了专门的术语名称
2. 段、报、帧
在 TCP/IP 五层模型中,每一层产出的报文都有一个专属称谓
| 层次 | 报文称谓 | 英文名 | 说明 |
|---|---|---|---|
| 传输层 | 段 | Segment | 如 TCP 段。强调由于数据太长,被拆分成了多个片段 |
| 网络层 | 报 | Datagram | 如 IP 包。强调这是一个完整的、具有路径选择信息的逻辑单元 |
| 数据链路层 | 帧 | Frame | 如以太网帧。强调这是在物理线路上传输的一个个完整的电信号块 |
3. 封装过程
封装是数据从应用层 向物理层流动的过程。每一层协议栈都会在上一层交下来的数据前面加上自己的报头
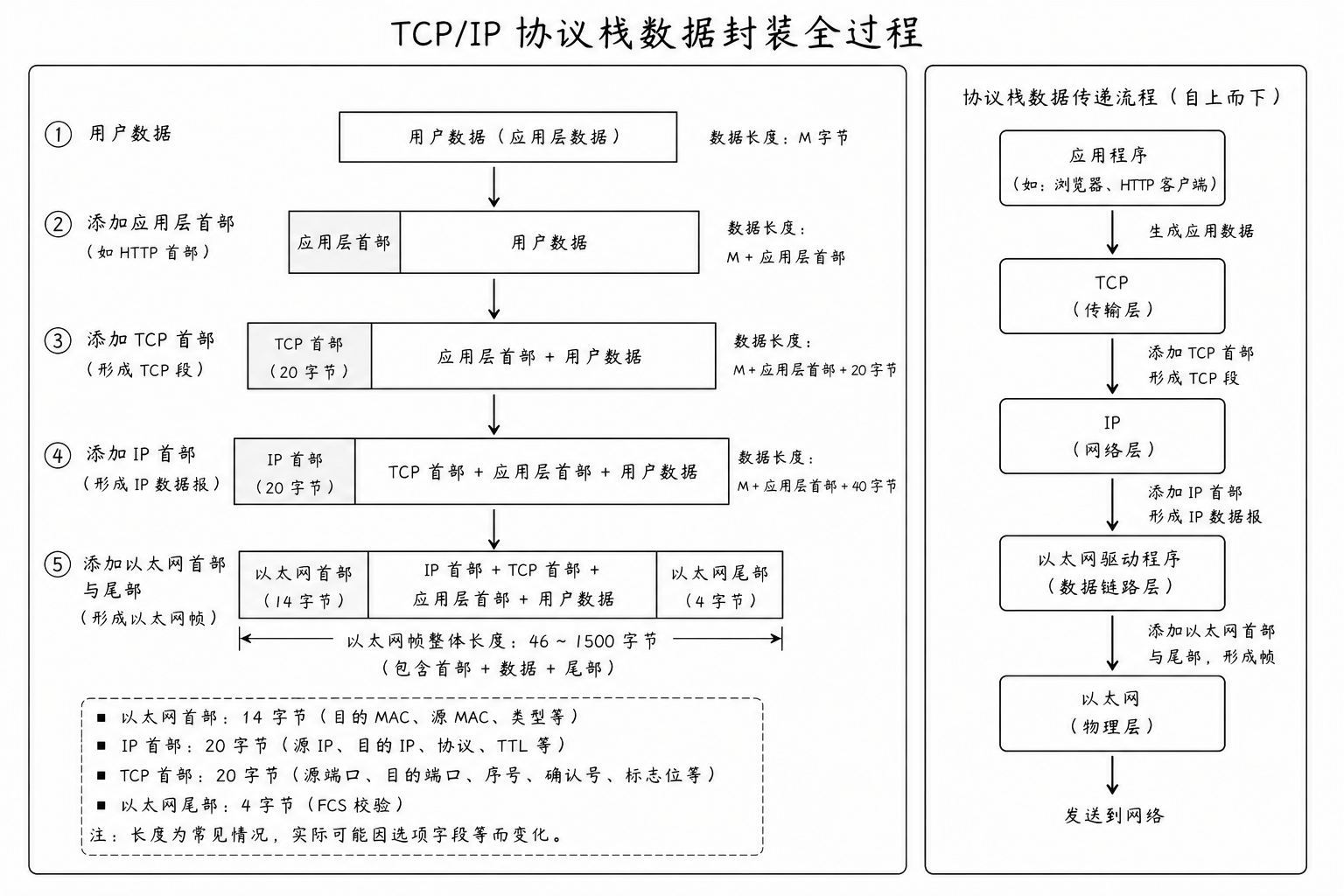
第一步:应用层
产生用户数据(User Data)。如果应用程序有自己的协议(如 HTTP),则加上应用层首部(Appl Header)
第二步:传输层
数据进入内核协议栈的 TCP/UDP 部分。加上 TCP 首部
此时的数据单元被称为 TCP 段。TCP 确保数据能找到对方机器上的正确程序
第三步:网络层
数据继续下交给 IP 协议。在 TCP 段前面加上 IP 首部
此时称为 IP 数据报。IP 首部最重要的信息是源 IP 和目的 IP,这决定了数据包的路由方向
第四步:数据链路层
IP 包进入以太网驱动程序
-
首部 :加上 以太网首部 (14 字节),包含源/目的 MAC 地址
-
尾部 :加上 以太网尾部 (4 字节),用于差错校验
这就是最终在网线上跑的 以太网帧
4. 分用过程
当一个以太网帧从网线进入网卡,分用过程就开始了。该过程的核心在于依据头部字段信息执行多级路由选择
(1) 链路层分用
以太网驱动程序首先接收到帧,剥离以太网首部。查看以太网首部中的帧类型字段
分流去向:
-
如果是 0x0800,说明载荷是 IP 数据报,丢给 IP 协议 处理
-
如果是 0x0806,说明是地址解析请求,丢给 ARP
-
如果是 0x8035,则丢给 RARP
物流中心的大门(驱动)打开,看一眼包裹外壳上的标志:是普通邮件(IP)、地址查询函(ARP)还是身份确认函(RARP)
(2) 网络层分用
IP 协议层接过包裹,剥离 IP 首部。查看 IP 首部中的协议字段
分流去向:
-
如果是 6,说明里面装的是 TCP 段
-
如果是 17,说明里面装的是 UDP 段
-
当然,也可能是 ICMP (ping 命令用的)或 IGMP(组播用的)
到了楼层分拣处,管理员拆开包裹看了一眼内层标签:这东西是要给 TCP 部门处理,还是给 UDP 部门处理?
(3) 传输层分用
TCP 或 UDP 协议层剥离自己的首部。查看首部中的目的端口号
分流去向:
-
如果是 80,交给 Web 服务器进程
-
如果是 22,交给远程登录进程
最后快递员进了办公楼,根据房号(端口号)把信件投递到具体的办公室(应用程序)里
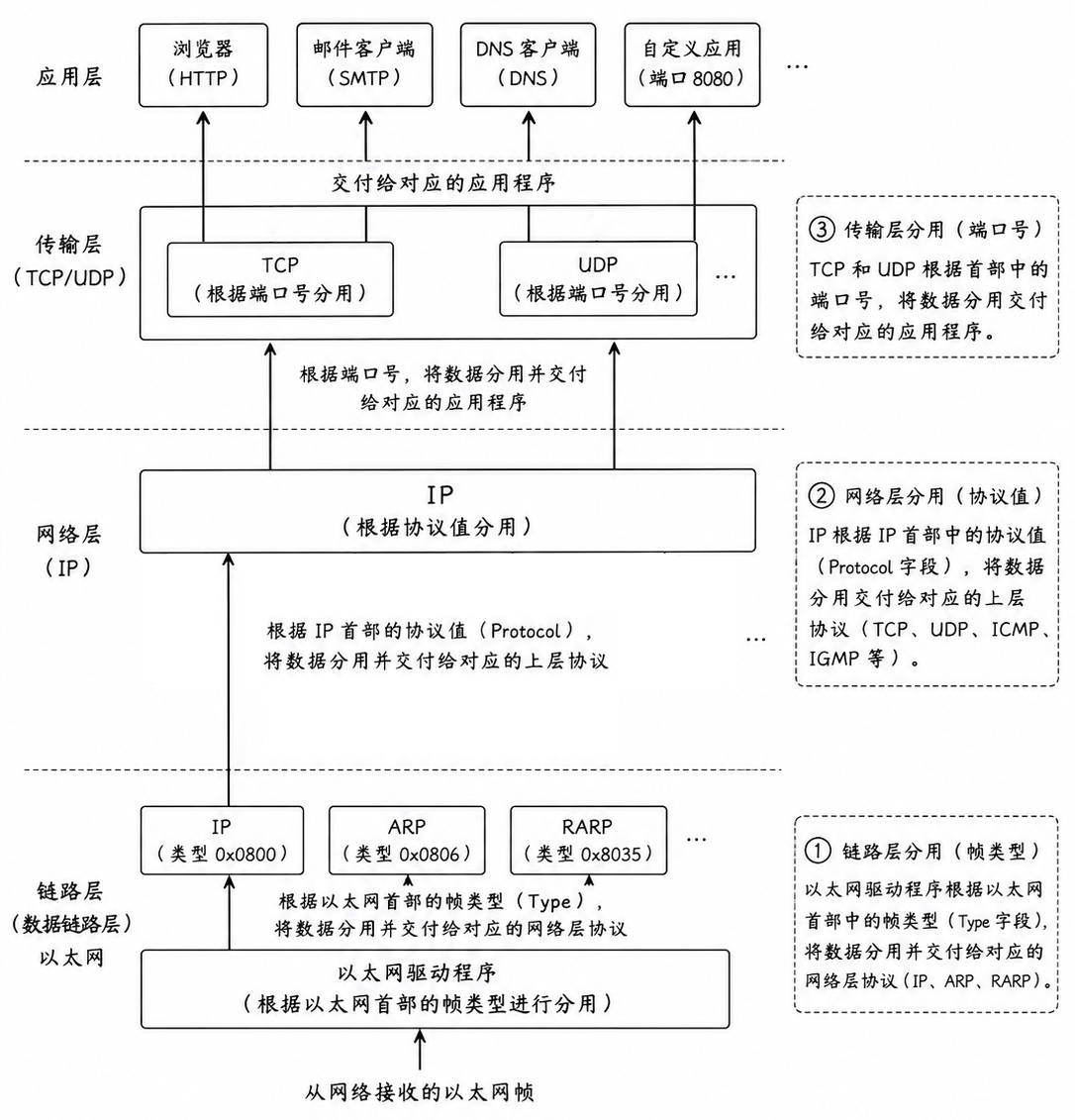
从图中我们可以看到,网络栈的结构像一棵倒长的树:
-
向下封装时,是从应用层的繁多分支汇聚到网卡这一个主干发出去
-
向上分用 时,是从网卡这一个入口进来,根据报头信息不断分流,最终准确地送达到成千上万个进程中的某一个
这就是为什么报头必不可少:如果没有报头里的这些 "类型" 和 "端口",内核面对原始二进制数据时将无从判断该将其交由哪个处理程序
四、跨网络通信
局域网通信如同教室点名,而跨网络通信则好比城市间快递寄送。此时仅靠 MAC 地址(类似身份证号)已不足够,必须借助更完善的寻址导航系统
1. 为什么需要 IP 地址
想象一下,如果你要给一个住在纽约的朋友寄信,你只在信封上写他的身份证号(MAC 地址),邮局(路由器)能送到吗?显然不能
-
MAC 地址的局限性:它只在当前局域网(同一网段)内有效。一旦超出该范围,物理地址将无法被识别
-
IP 地址的必要性 :我们需要一个能够体现地理位置 或网络拓扑结构的逻辑地址。IP 地址的作用是告诉网络设备:目标主机位于哪个远程子网中
2. IP 地址
在跨网络传输过程中,每经过一个路由器,MAC 地址都会被替换,但目的 IP 地址始终保持不变。IP地址就像导航指南,指引沿途所有网络设备将数据包准确送达目标逻辑网段的指定主机。若没有IP地址,互联网将退化为相互隔离的局域网,无法实现全球互联
如何查看 IP 地址?
作为开发者,查看 IP 是基本功。不同系统的命令有所区别:
-
Linux/macOS:
-
ip addr:这是现代 Linux 系统(iproute2 工具包)推荐的命令,信息最全
-
ifconfig:传统的网络配置查看工具(需要安装 net-tools)
-
-
Windows:
- ipconfig:在 CMD 或 PowerShell 中输入即可
在 Linux 系统中查看网络信息时,IPv4 地址通常显示为 inet 后的数字(如 192.168.1.5)。而 lo(loopback)接口对应的 127.0.0.1 是本地回环地址,专门用于本机进程间的通信
IPv4 与 IPv6
目前互联网正处于从 IPv4 向 IPv6 过渡的长跑阶段:
-
IPv4:长度 32 位(4 字节),通常写成点分十进制,如 192.168.0.1。总量约 43 亿个地址。听起来很多,但面对全球百亿级的智能设备,早已分发殆尽
-
IPv6 :长度128 位(16 字节),采用十六进制表示,如 240e:3b3:2a01...。总量号称可以为地球上的每一粒沙子都分配一个独立的 IP 地址。它彻底解决了地址荒,并自带更高的安全性和传输效率
为什么 IPv6 难推广?
尽管IPv4地址资源已耗尽,但全面过渡到 IPv6 仍面临多重现实挑战:
-
NAT:工程师们发明了 NAT 技术,让一个公网 IP 可以带着几百台局域网设备上网。这极大地缓解了 IPv4 的枯竭压力,导致大家觉得 "还能凑合过",动力不足
-
不向下兼容 : IPv6 是一套全新的协议,它和 IPv4 不兼容 。这意味着如果你的设备只支持 IPv6,你可能连不上只支持 IPv4 的老旧服务器。为了过渡,设备必须运行双栈,增加了技术复杂度
-
升级成本 : 全球数以亿计的路由器、交换机、防火墙以及各种古老的嵌入式设备,都需要升级固件甚至更换硬件才能支持 IPv6。对于运营商和企业来说,这是一笔天文数字般的开支
-
对普通用户来说,IPv4 也能刷视频、打游戏,IPv6 并没有带来某种 "非它不可" 的体验升级
3. 路由转发
在数据包跨越不同网络(经过多个路由器)的过程中:
-
目的 IP 地址: 始终保持不变。它代表了包裹最终要送达的终点
-
目的 MAC 地址: 在每一跳都会发生改变。它代表了包裹在当前局部路径下,下一站要交给谁
详细转发流程解析
假设主机 A(在上海局域网)要给主机 B(在伦敦局域网)发送一个数据包,中间经过路由器 R1 和 R2
第一步:主机 A 发出
主机 A 发现目标 IP 不在自己的局域网内,于是它决定把包交给 "默认网关"(路由器 R1)
-
封装报文:
-
源 IP / 目的 IP: A 的 IP / B 的 IP
-
源 MAC / 目的 MAC: A 的 MAC / R1 的 MAC
-
-
发送: 数据包通过物理线缆抵达 R1
第二步:路由器 R1 处理(第一跳)
R1 收到帧后,发现 "目的 MAC" 是自己,于是解包以太网头
-
拆解: R1 看到里面的 IP 头,发现目的 IP 是主机 B
-
查路由表: R1 查找路由表,发现要到达主机 B,下一站应该交给路由器 R2
-
重新封装: R1 会对数据包进行重新封装,为其更换新的以太网帧头
-
源 MAC: 变为 R1 的出口 MAC
-
目的 MAC: 变为 R2 的入口 MAC
-
IP 地址: 依然是 A 的 IP / B 的 IP
-
第三步:路由器 R2 处理(第二跳)
R2 重复 R1 的动作:
-
拆解: 剥掉 R1 封的 MAC 头,看 IP 头
-
查表: 发现目的 IP 就在自己直接连接的局域网里
-
重新封装:
-
源 MAC: 变为 R2 的出口 MAC
-
目的 MAC: 变为 最终目标主机 B 的 MAC
-
IP 地址: 还是 A 的 IP / B 的 IP
-
第四步:主机 B 签收
主机 B 收到帧,对比 MAC 地址一致,解包看到 IP 地址也一致,最后拆出载荷交给应用程序
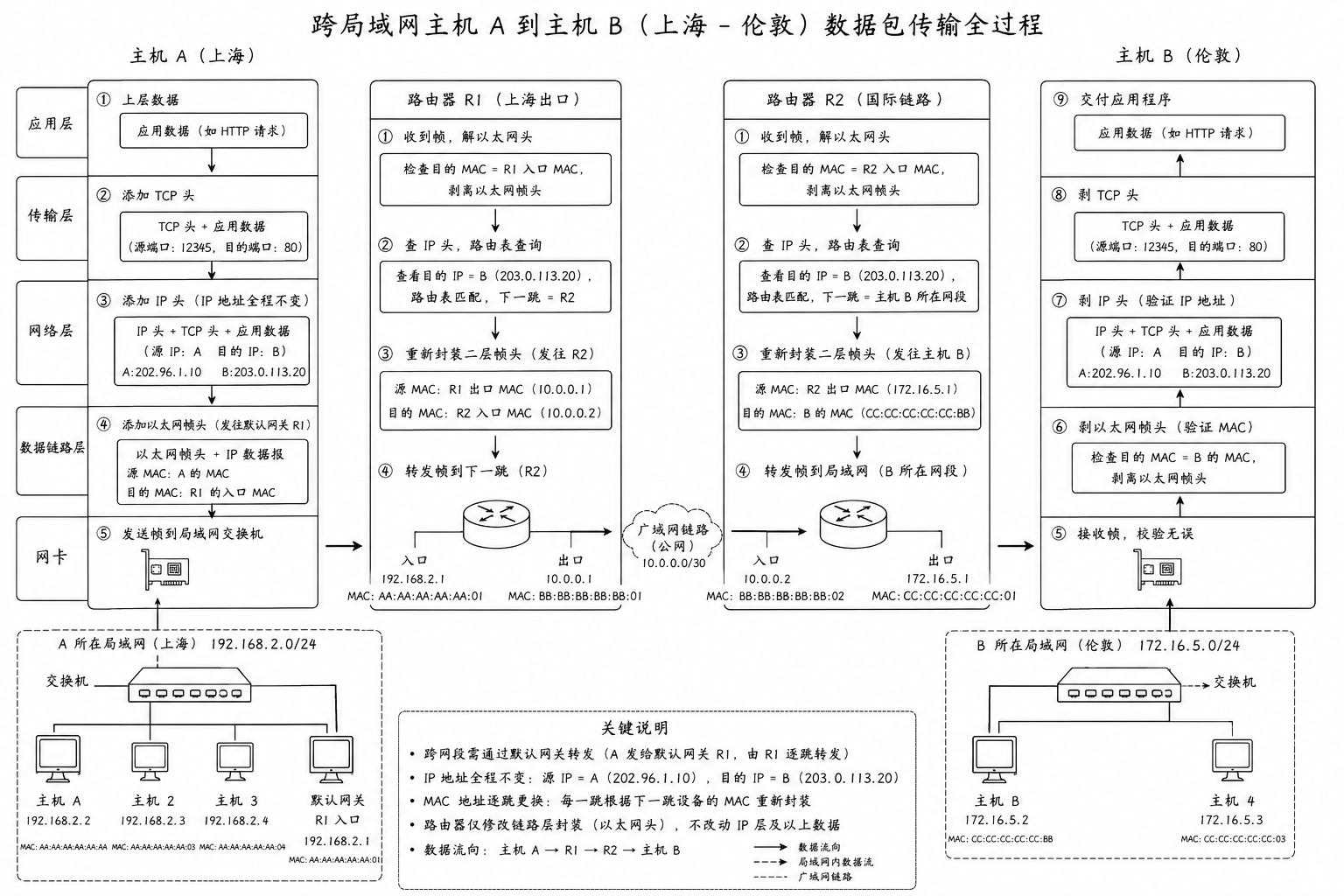
MAC 地址到底是怎么改变的
你或许会感到好奇:路由器怎么知道下一跳的 MAC 地址是什么?
-
剥离: 路由器接收数据后,会把旧的、已经完成使命的链路层报头(包含旧的 MAC 信息)直接扔掉
-
决策: 路由器根据目标 IP 地址,决定数据包该从哪个网口发出去,以及下一跳是谁
-
查询: 路由器会通过 ARP协议向对应网口发送查询请求,询问下一跳 IP 地址对应的 MAC 地址
-
**重组:**路由器在原始IP数据包前添加新的 MAC 头部
4. IP 与 MAC 的区别
| IP 地址 | MAC 地址 | |
|---|---|---|
| 所属层级 | 网络层 | 数据链路层 |
| 唯一性 | 逻辑唯一。在同一网络中必须唯一,但可以动态更换 | 物理唯一。网卡出厂时烧录,全球唯一 |
| 表现形式 | 点分十进制(如 192.168.1.1) | 十六进制(如 08:00:27:af:12:34) |
| 传输变化 | 全程不变。指引数据包最终去往何方 | 逐跳更换。每经过一个路由器就换成下一站的地址 |
| 核心作用 | 远程导航。负责跨网段的路径规划 | 近场识别。负责在同一局域网内寻找目标 |
| 分配方式 | 由网络管理员配置或 DHCP 服务器动态分配 | 由硬件厂商预先分配 |
为什么要这么设计?
你可能会问:既然 IP 地址能找到目标,为什么还要 MAC?或者既然 MAC 全球唯一,为什么不能直接用它寻址?
1. 只有 MAC 地址行不行?
不行。 MAC 地址是平面的、无规律的。想象一下,全球有几十亿台设备,如果没有 IP 地址这种按 "省-市-区" 划分的层级结构,路由器就得存储几十亿条记录。这就像在没有任何行政区划的情况下,要在全世界找一个身份证号为 110xxx... 的人,这根本无从下手
2. 只有 IP 地址行不行?
也不行。 IP 地址只是逻辑位置,它最终需要落脚到物理硬件上
-
在以太网中,网卡只认 MAC 地址
-
如果没有 MAC 地址,当你把数据发到局域网时,所有网卡都无法通过硬件电路快速判断这个包是不是给自己的,只能全部交给 CPU 处理,网络效率会极其低下
5. IP 层屏蔽底层差异
在现实世界中,底层的物理链路是极其复杂的:有的是电缆组成的以太网 ,有的是空气传输的 WiFi ,有的是深埋海底的光纤 ,甚至还有古老的令牌环网
这些底层硬件的帧格式、最大传输长度、寻址方式各不相同。但奇妙的是,作为程序员,我们写代码时只需要关心对方的 IP 地址,完全不需要知道数据是通过光纤还是卫星传过去的
这就是 IP 协议(网络层) 的功劳------它提供了统一的网络抽象
(1) 现实类比
在没有集装箱之前,码头工人需要处理散装的木桶、麻袋、木箱,每种货物装上火车或轮船的方式都不一样,效率极低
-
IP 数据报就是集装箱 :无论里面装的是 HTTP 网页还是 QQ 消息,也无论外面是用卡车运还是轮船运(底层链路),集装箱的大小和规格(IP 报文格式)是全球统一的
-
有了这层抽象,起重机(路由器)只需要识别集装箱上的编号(IP 地址),而不需要关心集装箱里面是什么,也不需要关心它是怎么被制造出来的
(2) Linux 的 "一切皆文件"
对于 Linux 开发者来说,这种 "屏蔽差异" 的思想再熟悉不过了
-
VFS (虚拟文件系统):在 Linux 中,你可能在使用 SSD、U 盘、甚至是网络存储。它们的底层驱动完全不同,但 Linux 通过 VFS 提供了一套统一的接口:open, read, write
-
IP 层就是网络的 VFS :底层网卡驱动千差万别,但内核协议栈在 IP 层将它们统一标准化。向上层提供了一个一致的视角:我只管把这个 IP 数据包交给下一跳,具体细节交由驱动处理
(3) 核心逻辑
IP 层主要通过以下三个关键机制实现其功能:
-
统一编址:不论你是手机、电脑还是路由器,只要接入互联网,就必须拥有一个逻辑上的 IP 地址,暂时抛弃复杂的 MAC 物理细节
-
统一封包格式 :所有的物理帧在进入 IP 层后,都会被解封装,提取出统一格式的 IP 数据报。在 IP 层看来,全世界的数据长得都一样
-
处理差异:如果底层的 WiFi 只能传 1500 字节,而光纤能传 4000 字节,IP 层会自动通过分片技术来适配这些物理差异,而不需要应用层程序员关心
IP 协议的设计体现了计算机科学中最核心的智慧:通过增加一个抽象层,可以解决绝大多数复杂性问题
总结
综上所述,从局域网通信、MAC 地址,到 IP 地址、封装与分用,再到跨网络路由转发,我们已经逐步梳理清楚了网络数据在协议栈中的基本流动过程
其中,MAC 地址负责局域网内的设备定位,IP 地址负责跨网络寻址,而 TCP/IP 协议栈则通过层层封装与解包,将复杂的网络通信拆分为多个职责清晰的模块共同协作完成
至此,我们已经能够站在协议栈视角,大致理解一条消息是如何从一台主机发送到另一台主机的。但进一步思考会发现:
应用程序究竟是如何接入TCP/IP协议栈,并真正向网络发送数据的?
这正是 Socket 编程要解决的问题
在下一篇中,我们将正式进入 Socket 编程预备阶段,开始认识网络字节序、端口号、socket 地址结构以及网络 API 的基本组织方式,为后续真正实现网络通信程序打下基础
