导读
过去几年,很多团队做浏览器自动化时,都会遇到一个很现实的问题:
脚本明明能跑,页面也能打开,但只要进入登录、搜索、下单、表单提交、内容访问等稍微敏感一点的流程,就很容易触发验证码、风控拦截、访问异常,甚至直接被判定为自动化流量。
这背后并不只是 navigator.webdriver 一个字段的问题。
现代反机器人系统早就不再只看"你是不是用了 Playwright / Puppeteer / Selenium",而是在综合判断一个浏览器环境是否像真实用户:
你的 Canvas 输出是否异常?
WebGL、GPU、字体、插件、屏幕参数是否一致?
TLS 指纹、网络时序、WebRTC、CDP 行为是否露出自动化痕迹?
鼠标轨迹、输入节奏、滚动行为是否像真人?
最近开源项目 CloakBrowser 受到不少关注,它给出的思路不是继续在 JavaScript 层"打补丁",也不是简单改几个启动参数,而是把浏览器指纹修补推进到 Chromium C++ 源码层。项目 README 中描述,它是围绕自定义 Chromium 二进制构建的 Python / JavaScript 封装,并支持作为 Playwright / Puppeteer 的替代入口使用。
这件事对测试开发、自动化工程和 AI Agent 浏览器操作,都是一个值得拆开的技术信号。
目录
-
自动化浏览器为什么越来越容易被识别
-
CloakBrowser 的核心思路:不是伪装脚本,而是改浏览器本身
-
它解决的不是验证码,而是"浏览器环境一致性"
-
从测试开发视角看,它真正有价值的地方
-
为什么源码级补丁比 JS 注入更难被识别
-
自动化测试、爬虫、AI Agent 的边界会怎么变化
-
工程落地要注意什么
1. 自动化浏览器为什么越来越容易被识别?
很多人对浏览器自动化的理解,还停留在以前:
用 Playwright 打开页面;
定位元素;
点击按钮;
填写表单;
抓取内容;
跑完关闭。
但在真实业务系统里,浏览器自动化已经不是单纯的"页面操作问题",而是一个完整的环境可信度问题。
现在的风控系统通常会从多个层面判断请求是否可信:
| 检测层级 | 常见信号 |
|---|---|
| 浏览器 API | navigator.webdriver、plugins、languages、permissions |
| 渲染指纹 | Canvas、WebGL、AudioContext、字体渲染 |
| 设备环境 | GPU、屏幕尺寸、硬件并发数、内存信息 |
| 网络特征 | TLS 指纹、HTTP/2 行为、代理特征、WebRTC IP |
| 自动化行为 | CDP 调用、鼠标轨迹、键盘输入、滚动节奏 |
| 会话画像 | Cookie、localStorage、历史访问、持久化 profile |
| 风险评分 | reCAPTCHA v3、Turnstile、FingerprintJS、BrowserScan 等 |
也就是说,一个自动化脚本即使写得很稳定,只要浏览器环境露出"不像真实用户"的痕迹,依然会被识别。
这也是为什么很多人会遇到一种情况:
本地调试正常,放到服务器就异常;
普通页面能访问,关键流程就触发验证;
换了代理也不行,因为问题不只在 IP;
明明 headless 关闭了,还是被识别为自动化。
自动化浏览器正在从"能不能操作页面",进入"能不能构造可信浏览器环境"的阶段。
2. CloakBrowser 的核心思路:不是伪装脚本,而是改浏览器本身
CloakBrowser 比较有代表性的地方在于,它不是在页面加载后注入一段 JS 去覆盖浏览器字段,而是修改 Chromium 源码,再编译成自定义浏览器二进制。
项目说明中提到,它通过源码级 C++ 补丁处理 GPU、屏幕、用户代理、硬件报告等浏览器指纹信息,而不是依赖 JavaScript 注入或配置级修改。(GitHub1)
这就形成了一个很重要的差异:
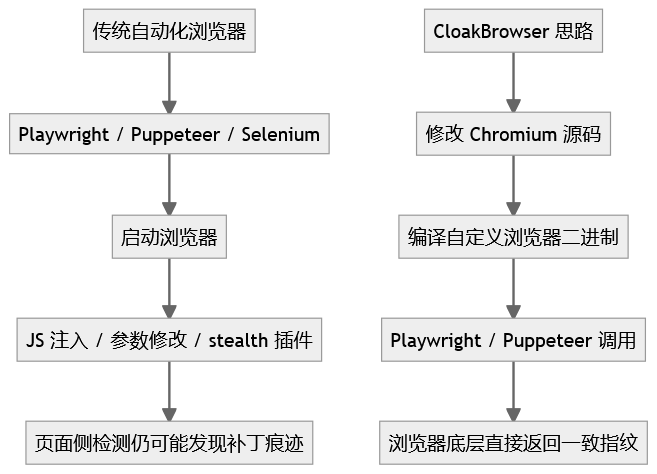
传统 stealth 工具更像是在浏览器外面贴一层"伪装膜"。
CloakBrowser 更像是把浏览器底层返回的数据结构、渲染行为、自动化信号本身做了改造。
这也是它被关注的原因。
3. 它解决的不是验证码,而是"浏览器环境一致性"
很多人看到这类项目,第一反应会把它理解成"验证码绕过工具"。
这个理解其实不准确,也不建议这样表达。
CloakBrowser 项目本身也明确说明:它不提供验证码破解服务,也不内置代理轮换;它的目标是减少验证码出现的概率,而不是解决验证码本身。(GitHub1)
从工程角度看,它真正处理的是三件事:
第一,减少自动化浏览器的明显异常信号。
例如常见的 webdriver 标识、HeadlessChrome 暴露、插件列表异常、window.chrome 缺失、CDP 自动化痕迹等。
第二,提高浏览器指纹之间的一致性。
很多自动化环境的问题不是某一个字段错了,而是多个字段组合起来不合理。
比如:
UA 显示 Windows,但字体像 Linux;
GPU 信息和平台不匹配;
语言、时区和代理出口 IP 不一致;
Canvas、WebGL、Audio 指纹之间缺乏稳定关联;
同一个会话每次都像新设备。
第三,让自动化行为更接近真实用户行为。
项目资料中提到,CloakBrowser 支持 humanize 行为模拟,包括鼠标曲线、键盘输入时机、滚动模式等;也支持持久化配置文件、代理时区语言匹配、WebRTC IP 处理等能力。
这些能力的目标,本质上是让自动化环境从"脚本执行器"更接近"真实浏览器会话"。
4. 为什么源码级补丁更有技术含量?
过去常见的 stealth 方案,通常有三类:
第一类是启动参数级修改。
例如关闭某些自动化特征、修改 UA、禁用某些 blink features。
第二类是 JS 注入。
在页面初始化前注入脚本,重写 navigator、plugins、permissions、webdriver 等对象。
第三类是驱动层规避。
例如修改 WebDriver 行为、调整 CDP 调用、隐藏自动化控制痕迹。
这些方案能解决一部分问题,但也有明显短板:
页面越早检测,越容易抢在注入前发现异常;
浏览器更新后,补丁容易失效;
JS 覆盖可能留下 getter、descriptor、prototype 等不自然痕迹;
字段改了,但底层渲染输出不一致;
多个信号之间很难保持整体一致性。
CloakBrowser 的思路是把补丁放到 Chromium 源码层,这意味着某些值不是"页面上被临时改写",而是浏览器底层直接返回修改后的结果。
这就是它与 playwright-stealth、puppeteer-extra-plugin-stealth、undetected-chromedriver 这类工具的主要区别。
可以简单理解为:
| 方案 | 修改层级 | 优点 | 问题 |
|---|---|---|---|
| 启动参数 | 浏览器启动配置 | 简单、轻量 | 覆盖范围有限 |
| JS 注入 | 页面运行时 | 灵活、易扩展 | 容易被检测注入痕迹 |
| 驱动规避 | 自动化协议层 | 能处理部分 CDP/WebDriver 信号 | 维护成本高 |
| 源码级补丁 | 浏览器二进制层 | 指纹更底层、更一致 | 构建和维护难度高 |
所以它的价值不只是"能不能过某个检测网站",而是代表自动化浏览器进入了更底层的工程竞争。
5. 它的能力可以怎么理解?
从资料来看,CloakBrowser 的能力可以分成五层。

第一层:源码级指纹补丁。
项目资料中提到,它覆盖 Canvas、WebGL、音频、字体、GPU、屏幕、WebRTC、网络时序、自动化信号、CDP 输入行为等多个方向。
第二层:自动化框架兼容。
它不是重新发明一套自动化 API,而是尽量兼容 Playwright / Puppeteer 的调用方式。对已有自动化工程来说,这意味着迁移成本相对低。
第三层:行为拟人化。
现代风控不只看浏览器参数,也看行为轨迹。比如鼠标是否瞬移,输入是否瞬间完成,滚动是否机械。
第四层:会话持久化。
真实用户不是每次打开页面都像一个全新设备。Cookie、localStorage、缓存、字体、服务工作线程等,都会逐渐形成用户画像。
第五层:部署一致性。
本地、Docker、VPS、CI 环境中的浏览器差异,往往是自动化稳定性的来源之一。CloakBrowser 试图通过统一二进制和封装层降低这种差异。
6. 从测试开发视角看,它真正值得关注什么?
如果只是把 CloakBrowser 理解成"采集工具",就把它看窄了。
对测试开发来说,它更值得关注的是三个方向。
方向一:反自动化检测本身也需要测试
很多业务系统都有风控、登录保护、异常访问识别、验证码策略、设备指纹策略。
但这些策略往往很难测试。
因为普通自动化脚本太容易被识别,导致测试结果失真。
例如:
我们想验证正常用户是否被误伤;
想验证不同设备环境下的风险评分;
想验证风控系统对 headless、代理、异常行为的识别能力;
想回归测试验证码策略是否过度拦截;
想做自动化巡检,但又不希望巡检脚本被错误识别为异常访问。
这类场景下,浏览器指纹一致性测试会成为一个新的测试方向。
方向二:AI Agent 浏览器操作需要更真实的执行环境
现在很多 Agent 框架都开始接入浏览器:
让 Agent 自动打开网页;
读取页面内容;
填写表单;
点击按钮;
完成后台操作;
执行跨系统流程。
但是 Agent 只要进入真实网站,就会遇到一个问题:
它不是在"读 HTML",而是在和真实浏览器、真实风控、真实交互系统打交道。
如果浏览器环境本身一眼就像自动化工具,Agent 的执行能力就会被限制。
所以未来 AI Agent 的浏览器执行环境,大概率会从"能跑"升级到"可信、稳定、可观测、可回放"。
方向三:自动化测试要重新理解"用户环境"
以前写 UI 自动化,大家关注的是:
元素定位稳不稳;
等待策略合不合理;
断言是否完整;
数据是否可控;
流程是否可复用。
但在复杂业务系统里,未来还要关注:
浏览器指纹是否合理;
测试环境与真实用户环境是否一致;
自动化行为是否影响业务风控判断;
CI 环境是否与本地执行结果一致;
不同代理、时区、语言、字体、GPU 环境是否导致结果差异。
这其实是测试工程的一个升级:从页面自动化,走向浏览器环境工程。
7. 这类项目也有明显边界
CloakBrowser 这类项目虽然技术上很有讨论价值,但不能把它神化。
第一,反机器人检测是持续对抗,不存在永久通关。
项目说明中也提到,检测是一场军备竞赛,源码级补丁更难检测,但并非不可能。(GitHub1)
第二,浏览器指纹不是唯一因素。
真实业务风控还会看:
IP 信誉;
账号历史;
访问频率;
行为路径;
业务数据;
设备关系;
登录状态;
支付与交易风险;
异常请求模式。
浏览器环境再像真人,如果业务行为不合理,依然会被识别。
第三,源码级浏览器带来供应链风险。
这类项目通常会下载自定义浏览器二进制。
工程团队必须关心:
二进制来源是否可信;
是否有签名和校验;
是否可审计;
是否允许进入企业内网;
是否符合公司安全规范。
项目资料中提到其二进制下载会进行 SHA-256 校验,并提供 GPG、Sigstore、Docker 镜像签名等供应链验证方式。(GitHub1)
第四,要注意合法合规边界。
自动化浏览器可以用于测试、监控、兼容性验证、数据质量检查、内部系统巡检、AI Agent 实验等正当场景。
但未经授权的大规模采集、绕过访问控制、撞库、批量注册、薅羊毛、规避平台风控等行为,都不应该被技术文章鼓励。
所以更建议把它放在"自动化工程与风控测试"的语境里讨论,而不是放在"绕过检测"的语境里传播。
8. 一个值得关注的变化:自动化框架正在从 API 竞争走向环境竞争
过去浏览器自动化框架的竞争,主要在 API 层:
谁的定位更方便;
谁的等待机制更稳定;
谁的跨浏览器支持更好;
谁的调试体验更强;
谁的录制回放更完善。
Playwright 之所以快速流行,就是因为它在这些方面做得足够工程化。
但 CloakBrowser 代表的是另一个方向:
未来的浏览器自动化竞争,不只是谁的 API 好用,而是谁能提供更真实、更一致、更可靠的执行环境。
这对测试开发来说是一个很重要的信号。
因为自动化测试的稳定性,很可能不再只是脚本稳定性,而是:
浏览器稳定性;
环境一致性;
指纹可信度;
网络链路一致性;
用户画像连续性;
行为模拟自然度;
风控系统兼容性。
换句话说,自动化测试正在从"操作页面"变成"模拟真实用户环境"。
9. 对测试开发有哪些启发?
启发一:不要只把 UI 自动化理解成元素点击
页面自动化只是表层。
真正复杂的系统里,自动化脚本会和浏览器内核、网络协议、风控策略、用户画像、行为分析共同作用。
如果只会写点击和断言,很难处理真实业务里的复杂问题。
启发二:浏览器指纹可以成为新的测试知识点
未来测试开发需要理解:
Canvas 指纹;
WebGL 指纹;
TLS 指纹;
WebRTC 泄露;
CDP 自动化信号;
headless 与 headed 差异;
字体与 GPU 环境差异;
代理 IP 与语言时区一致性。
这些知识以前偏安全、爬虫、风控,现在正在进入测试工程视野。
启发三:AI Agent 测试会更依赖真实浏览器环境
当 Agent 开始操作网页、后台、SaaS 系统、企业内部平台时,仅仅 mock 页面是不够的。
我们需要测试:
Agent 是否能稳定理解页面;
是否能在动态页面中正确操作;
是否会被风控误判;
是否能处理验证码、登录态、异常弹窗;
是否能在真实浏览器环境中完成任务闭环。
浏览器环境工程,会成为 Agent 测试的重要基础设施。
启发四:企业内部系统也需要"反误伤测试"
很多企业只关注"能不能拦住机器人",但忽略了另一个问题:
会不会误伤正常用户?
会不会误伤自动化巡检?
会不会误伤内部测试任务?
会不会误伤海外用户、代理网络、特殊设备用户?
这类问题如果没有自动化测试体系,很难稳定回归。
10. 写在最后
CloakBrowser 受到关注,不只是因为它宣称通过了多项检测,也不只是因为它能替换 Playwright。
更重要的是,它暴露了一个趋势:
浏览器自动化正在进入更深的技术层。
过去我们讨论自动化,更多讨论脚本、定位、断言、并发、报告。
现在我们必须讨论浏览器内核、指纹一致性、网络时序、行为模型、环境画像、供应链安全和风控测试。
对测试开发来说,这不是简单多学一个工具,而是要意识到:
未来的自动化能力,不再只是"我能不能点到按钮"。
而是:
我能不能构建一个足够真实、足够稳定、足够可观测、足够合规的用户执行环境。
这才是 CloakBrowser 这类项目真正值得研究的地方。