wan2.1
3D Variational Autoencoders
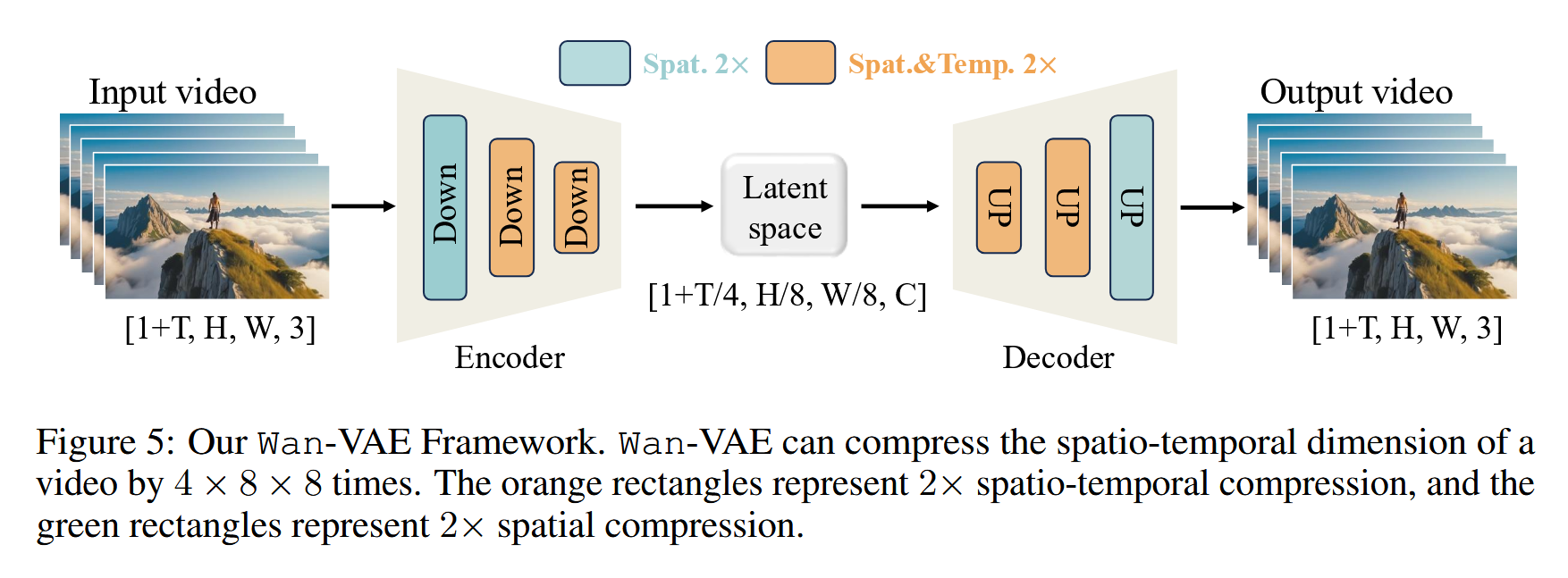
We propose a novel 3D causal VAE architecture, termed Wan-VAE specifically designed for video generation. By combining multiple strategies, we improve spatio-temporal compression, reduce memory usage, and ensure temporal causality. Wan-VAE demonstrates significant advantages in performance efficiency compared to other open-source VAEs. Furthermore, our Wan-VAE can encode and decode unlimited-length 1080P videos without losing historical temporal information, making it particularly well-suited for video generation tasks.
以下是 Wan-VAE 应对三大挑战的具体改进方案:
1. 挑战:复杂的时空关系难以捕捉
(视频天生具有空间和时间双重维度,特征极其复杂,难以兼顾。)
- 改进:时空解耦设计与深层特征接力。
Wan-VAE 放弃了将时间和空间捆绑处理的传统做法,采用解耦策略 分而治之。在网络的浅层,模型优先对时间维度进行压缩;到了网络深层,则停止时间压缩,将时间维度折叠后,利用 Attention 机制纯粹地专注处理空间维度的超高频细节(从而保证了 1080P 的清晰度)。为了防止时空拆分导致记忆断裂,模型在每一层残差网络中都内置了独立的缓存寄存器,确保深层复杂的空间语义依然能跨越时间块进行无损接力。
2. 挑战:高维度导致显存爆炸,难以支持长视频
(高分辨率多帧视频会带来灾难级的显存消耗和计算成本。)
- 改进:分块处理(Chunking)与 O(1)O(1)O(1) 恒定显存机制。
这是 Wan-VAE 支持"无限长"视频的核心底牌。模型采用了类似大语言模型(LLM)的思路,强制将长视频切分为极短的小块(例如 4 帧为一个 Chunk)进行"流水线"处理。因为模型在同一时刻只计算这一个小块,其显存占用被强行锁定,只与单个切块的大小有关,而与视频的总长度彻底脱钩。这种架构让处理 10 秒和处理 1 个小时的视频在显存占用上完全一样,从物理层面解决了长视频爆显存(OOM)的死局。
3. 挑战:因果性限制与分块处理产生的架构冲突
(既要严格遵守因果律"不能偷看未来",又要避免视频切块后画面闪烁、断层。)
- 改进:带状态交接的因果 3D 卷积。
普通的因果 3D 卷积虽然能防止未来信息泄露,但一旦视频被"切块",块与块的拼接处就会出现卡顿或抖动。Wan-VAE 重构了特征传递逻辑:它让每一次 3D 卷积运算不再是孤立的。在处理当前视频块的每一层网络时,模型都会自动提取并拼接入上一个时间块最后几帧的特征(Cache_T)。这种极其高密度的"无缝交接",巧妙化解了因果限制与切块断层之间的矛盾,让拼凑起来的视频在肉眼看来如同一次性生成般丝滑。
其实就是自回归的生成+使用上一个chunk的kv cache
Video Diffusion DiT
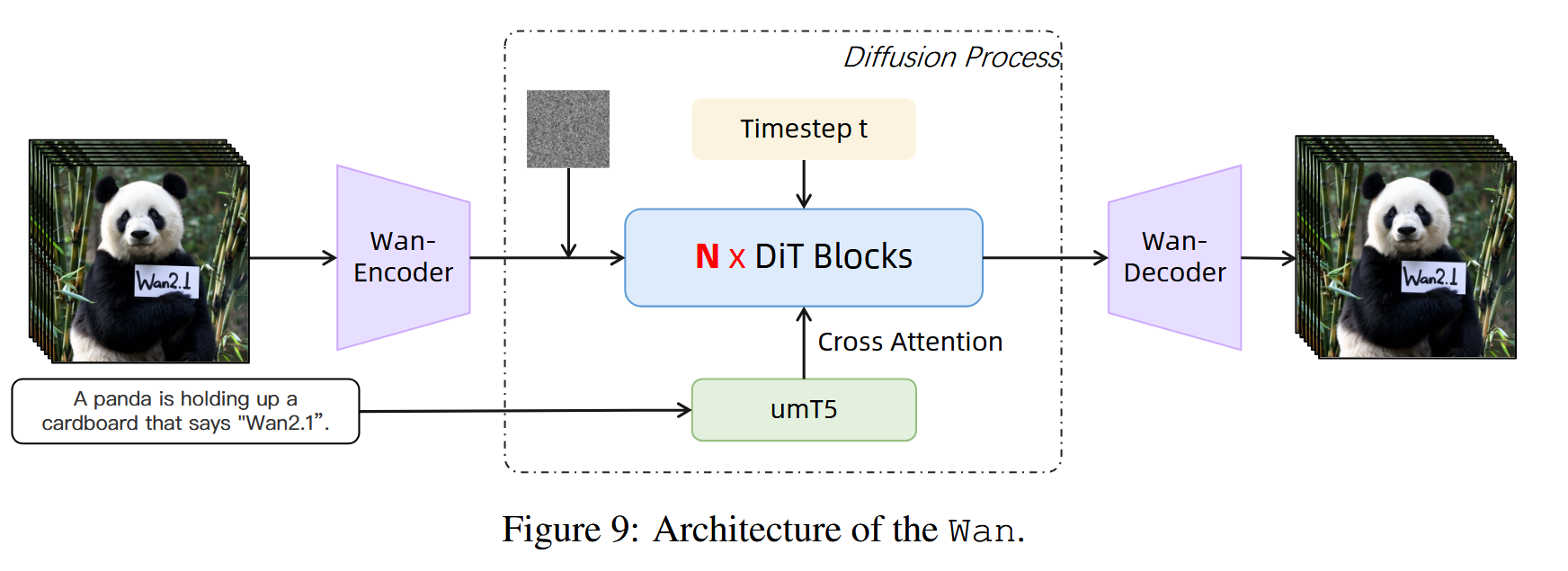
Wan2.1 is designed using the Flow Matching framework within the paradigm of mainstream Diffusion Transformers. Our model's architecture uses the T5 Encoder to encode multilingual text input, with cross-attention in each transformer block embedding the text into the model structure. Additionally, we employ an MLP with a Linear layer and a SiLU layer to process the input time embeddings and predict six modulation parameters individually. This MLP is shared across all transformer blocks, with each block learning a distinct set of biases. Our experimental findings reveal a significant performance improvement with this approach at the same parameter scale.
一、 宏观管线:数据的"三向奔赴"
Wan2.1 的 DiT 是一个纯粹在潜空间(Latent Space)中运作的生成引擎。它的宏观架构就是一个高度协同的数据处理工厂,主要接收三股信息流:
- 视觉特征流(来自 VAE):
- 输入的视频先经过我们之前讲过的 Wan-Encoder(3D-Causal-VAE),被压缩成极其致密的 3D 潜变量(Latent)。
- 在扩散/匹配过程中,这些潜变量会被加上噪声,作为 DiT 的主输入,DiT 的任务就是一层层剥离这些噪声。
- 文本语义流(来自 UMT5):
- 用户的 Prompt 不再使用常规的 CLIP,而是输入到 UMT5 语言模型中提取特征。
- 这些强大的多语言文本特征,会通过每一个 DiT Block 内部的 Cross-Attention(交叉注意力),像染色一样把语义指令注入到画面中。
- 时间步信息流(来自 Timestep ttt):
- 告诉模型当前处于去噪的哪一个阶段(是刚开始的大轮廓构建,还是最后的精细扣细节)。这部分信息通过"时间调制"机制(AdaLN)融入网络。
二、 核心设计哲学:"参数的极致压榨与重分配"
这才是 Wan2.1 DiT 架构最精髓的地方。它没有盲目去发明全新算子,而是遵循了一个极其实用主义的工程哲学:把好钢用在刀刃上。
1. 抛弃传统扩散,拥抱 Flow Matching(流匹配)
- 做法: 放弃了预测纯噪声的 DDPM/DDIM 范式,改为预测概率流的"向量场(Vector Field)"。
- 思路: 视频生成太庞大了,传统的去噪路径弯弯绕绕,收敛极慢。Flow Matching 提供了一条更直、更优化的数学路径(ODE 轨迹),这使得模型不仅训练更稳定,推理速度也更快。
2. 文本理解的升维:UMT5 的战略选择
- 做法: 使用 T5 Encoder(具体为多语言的 UMT5)。
- 思路: 视频生成对 Prompt 的指令跟随要求极高(比如"长镜头"、"逆光"、"人物向左走")。CLIP 模型虽然图文对齐好,但文本理解能力存在天花板。改用 LLM 级别的 T5 架构,直接赋予了模型原生的中英双语理解能力 和极其细腻的长文本推理能力。
3. "时间调制"的参数大挪移(最关键创新)
-
痛点: 传统的 DiT 架构中,为了让模型感知时间 ttt,每一个 Transformer Block 内部都要建一个庞大的 MLP 矩阵(把隐藏维度 DDD 映射为 6 个 DDD 维的控制向量)。在 40 多层的深层网络里,这会白白消耗数十亿的参数。
-
Wan2.1 的绝杀:共享与微调
-
共享 MLP: 在所有网络层外面,只建一个全局的 MLP 来处理时间 ttt 的初始映射。
-
独立 Bias: 在每个具体的 Block 里,只保留一组极小的、可学习的偏置项(Distinct set of biases)。
-
思路: 就像一栋大楼不需要在每个房间里都装一套复杂的主钟表齿轮(MLP),只需要在楼顶装一个大钟(共享 MLP),每个房间牵一根线拿个小表盘微调一下时差(Bias)即可。
三、 最终效果总结:这套设计的奇效是什么?
Wan2.1 技术报告里最值得回味的一句话就是:"在同等参数规模下,实现了显著的性能提升。"
通过上述的架构重组,尤其是时间调制模块的"参数大挪移",Wan2.1 团队成功地在 14B(140亿)参数的总预算中,硬生生抠出了几十亿的参数额度。
他们把这些省下来的算力和参数,全部砸进了网络里负责理解画面的 Self-Attention 和负责听懂人话的 Cross-Attention 中。
这就好比给一辆赛车做了极致的轻量化减重,然后把省下来的重量全换成了更大马力的发动机。外壳(总参数量)看起来没变,但它对复杂物理规律的模拟、对 1080P 高清细节的把控,以及对用户指令的服从度,都得到了跨越式的提升。
这就是 Wan2.1 DiT 模块看似"平平无奇",实则"招招致命"的系统工程之美!
QA
- 第一个 Chunk 的 Cache 会不会比别的短?
答:不仅是短,第一个 Chunk 根本没有 Cache! 你的怀疑完全正确,代码里对第一个块做了特殊处理(补零)。 - 只靠上一个 Chunk 的 Cache 怎么维持长程一致性?
答:因为维持长程一致性根本不是 VAE 的主业,那是 DiT(扩散大模型本体)的活儿! 加上 VAE 自身的多层级深度缓存,两者分工合作才搞定了长视频。
:
一、 第一个 Chunk 的 Cache 问题(
"对于第一个chunk,kv cache不就会比其他的短了吗?这看起来不太对啊。"
在代码层面,现实是这样的:
因果卷积代码,里面有一句非常关键的 if 判断:
python
if cache_x is not None and self._padding[4] > 0:
# ... 进行拼接 ...
else:
x = F.pad(x, padding) # 如果没有 cache,就直接补零(Padding Zero)对于第一个 Chunk(第 1~4 帧):
它前面没有视频了,所以传入的 cache_x 是 None。此时模型怎么做?它会用 0(黑屏/空张量) 来补齐前面缺失的 2 帧,凑够长度再卷积。
这在物理世界上是极其合理的:因为视频的第一帧,本来就不存在"历史运动"。 补零相当于告诉模型:"这是万物的起源,前面什么都没有,直接开始画吧。"
对于第二个及以后的 Chunk:
cache_x 有值了,模型就会拼接真实的物理特征。
为什么这不会导致模型错乱?
因为模型在训练的时候,就是这么被"喂"大的。它已经学到了一个规律:
- 遇到前面是
0的特征 →\rightarrow→ "哦,我是开头,我要凭空生成运动。" - 遇到前面是
真实特征→\rightarrow→ "哦,我是后续,我要顺着前面的轨迹动。"
所以长短不一非但不是 bug,反而是符合因果律的完美设计。
二、 长程一致性到底谁来管?(理清 VAE 与生成模型的分工)
只是使用上一个chunk的kv cache吗?那如何捕捉长视频生成的一致性?
这是一个非常经典的认知误区!我们需要把"视频大模型(DiT)"和"视频变分自编码器(VAE)"的角色彻底分开:
1. Wan-VAE 的真实身份是"解压软件",不是"编剧"
- VAE 的 Cache 机制(看前两帧),确实只能保证局部连续性(Local Continuity)。它的作用是:确保第 4 帧过渡到第 5 帧时,人物的动作是丝滑的,背景是不会闪烁的。
- VAE 不管"一分钟前男主穿红衣服,一分钟后男主还必须穿红衣服"这种高级逻辑。只要画面不抽搐,VAE 的任务就圆满完成了。
2. 长程一致性的真正大脑:DiT(Diffusion Transformer)
Wan2.1 的主体是一个巨大的 Transformer 生成模型。
- 在你输入文本 prompt 之后,是 DiT 本体在低维度的 Latent(潜空间)里排兵布阵。
- DiT 拥有全局注意力机制(Global Attention)或者极长窗口的注意力机制。它在生成这 1000 帧的特征序列时,第 1000 帧是可以直接"看到"第 1 帧的特征的。
- 因此,"长视频生成的一致性"是由 DiT 负责构思和锁定的。
3. VAE 深度 Cache 的"兜底"作用
虽然主要靠 DiT,但如果你让 VAE 分块去解压 DiT 生成的特征,VAE 如果不用 Cache,依然会把原本连贯的特征解压得稀碎。
此时,Wan-VAE 的 层级残差 Cache(每一层都有 Cache) 就发威了:
- DiT 已经规定好了第 1 块和第 2 块都是"红衣服男主"。
- 当 VAE 处理第 2 块时,它深层网络的 Cache 会继承第 1 块深层网络的"红衣服语义"状态。
- 这种极高密度的状态交接,配合 DiT 本身的全局规划,共同实现了"极其稳定、不闪烁、不失忆"的长视频。
Wan 2.2
Wan 2.2相比于 Wan 2.1 模型来说,该模型的整体架构变为了混合专家架构,整体参数量为 27B,推理时激活参数量为 14B,在推理成本与 2.1 模型相近的条件下得到了更高参数量。
模型共有三种,分别为文生视频 27B MoE 模型、图生视频 27B MoE 模型以及文/图生视频 5B Dense 模型。其中最后一种模型能够在单种架构中同时实现文生视频和图生视频两种不同的任务,且能在消费级显卡上运行。
1. 架构升级:从"单打独斗"到"阶段专家 (MoE)"
Wan 2.2 最大的变动是引入了时间步路由的混合专家架构(Temporal-aware MoE):
- 规模与效率的平衡 :模型总参数量提升至 27B ,但通过"分时段值班"机制,推理时激活参数量保持在 14B。这意味着在不增加显存开销的前提下,模型获得了近乎翻倍的表达能力。
- 高噪模型 (High-Noise Expert):专门负责去噪早期的"拓荒"工作,确立视频的全局结构、语义分布和大尺度的运动轨迹。该模块是从头训练(From scratch)的,以确保更强的物理规律建模能力。
- 低噪模型 (Low-Noise Expert):专门负责去噪后期的"精修"工作,在 Wan 2.1 权重的基础上进行后训练(Post-training),专注于光影纹理、高频细节和微小的动作平滑度。
2. VAE 突破:极限的空间压缩比 (16×16×4)
Wan 2.2 引入了全新的 Wan2.2-VAE,这是其能在消费级显卡上跑通高清视频的"核武器":
- 压缩率翻倍 :空间压缩比从 2.1 版本的 8×8 提升到了 16×16(时间维度维持 4 倍下采样)。
- 计算减负 :在处理 720P 视频时,送入 DiT 网络计算的特征序列长度缩减为原来的 1/4 。这显著降低了内存占用,使得 RTX 4090 也能流畅生成 720P@24fps 的视频。
3. 数据重塑:审美标签与暴力扩规模
为了解决视频生成中常见的"AI 感"和运动幅度过小的问题,Wan 2.2 在数据上做了深度工程:
- 审美精修 :引入了带有光影、构图、对比度、色调等详细标签的电影级审美数据,支持更精准的视觉风格控制。
- 规模飞跃 :训练数据量大幅增加,图像数据增长 65.6% ,视频数据增长 83.2%。
- 动态增强:这种海量数据的灌注,显著提升了模型在生成复杂、大幅度动作时的泛化能力和指令遵循度。
4. 任务集成:高效的混合 TI2V 模型
Wan 2.2 推出了一个 5B Dense(稠密)模型,它在功能上实现了高度集成:
- 单架构多任务:在同一个网络架构中同时实现了文生视频(T2V)和图生视频(I2V)任务。
- 学术/工业双兼容:由于采用了高压缩比 VAE,它在保持极快推理速度的同时,画质依然维持在 720P@24fps 的高标准,是目前研究和部署最理想的平衡点。
核心总结对照表
| 特性 | Wan 2.1 | Wan 2.2 |
|---|---|---|
| 底层架构 | 单阶段 Dense 架构 | 两阶段 MoE 架构 (27B/14B) |
| 空间压缩比 | 8 × 8 | 16 × 16 |
| 生成范式 | 单一权重处理全过程 | 高低噪模型分段激活 |
| 核心卖点 | 基础开源视频基座 | 电影级审美 + 复杂动作生成 |
| 硬件门槛 | 相对较高 | 4090 可跑 720P 极速版 |
简单来说,Wan 2.2 就像是将你的"实验室跑车"换装了 V12 引擎(27B 参数) ,但通过智能闭缸技术(MoE)和超轻量化车身(16×16 VAE),让它依然能跑在你那张"民用级"的 4090 显卡上,而且跑得更快、画得更美。