一、核心主线:贯穿所有知识点的完整链路
这条链路里的关键环节,环环相扣:
C源码 → 编译 → .o目标文件(ELF可重定位) → 链接(含动/静态库) → 可执行ELF文件 → 进程创建(内核数据结构初始化) → 加载(映射到物理内存) → CPU执行
每个环节的输出,都是下一个环节的输入,没有前一步的铺垫,后一步就无法进行。
二、阶段拆解:每个环节的核心知识点 + 前后衔接
阶段 1:编译阶段(源码 → .o 目标文件)
对应:ELF 格式基础
- 编译输出:每个
.c文件会被编译成一个.o目标文件,格式为ELF 可重定位文件(ET_REL)。 - 核心结构:
.o文件里已经包含了按数据类型划分的Section(节):.text:编译后的机器指令代码.data:初始化的全局 / 静态变量.rodata:只读常量(如字符串)- 符号表、重定位表:用于后续链接阶段的符号解析
- 关键结论:所有
.o、.so、可执行文件,本质都是 ELF 格式,这是它们能被链接、加载的基础( "为什么.o 可以形成.so 或可执行程序")。
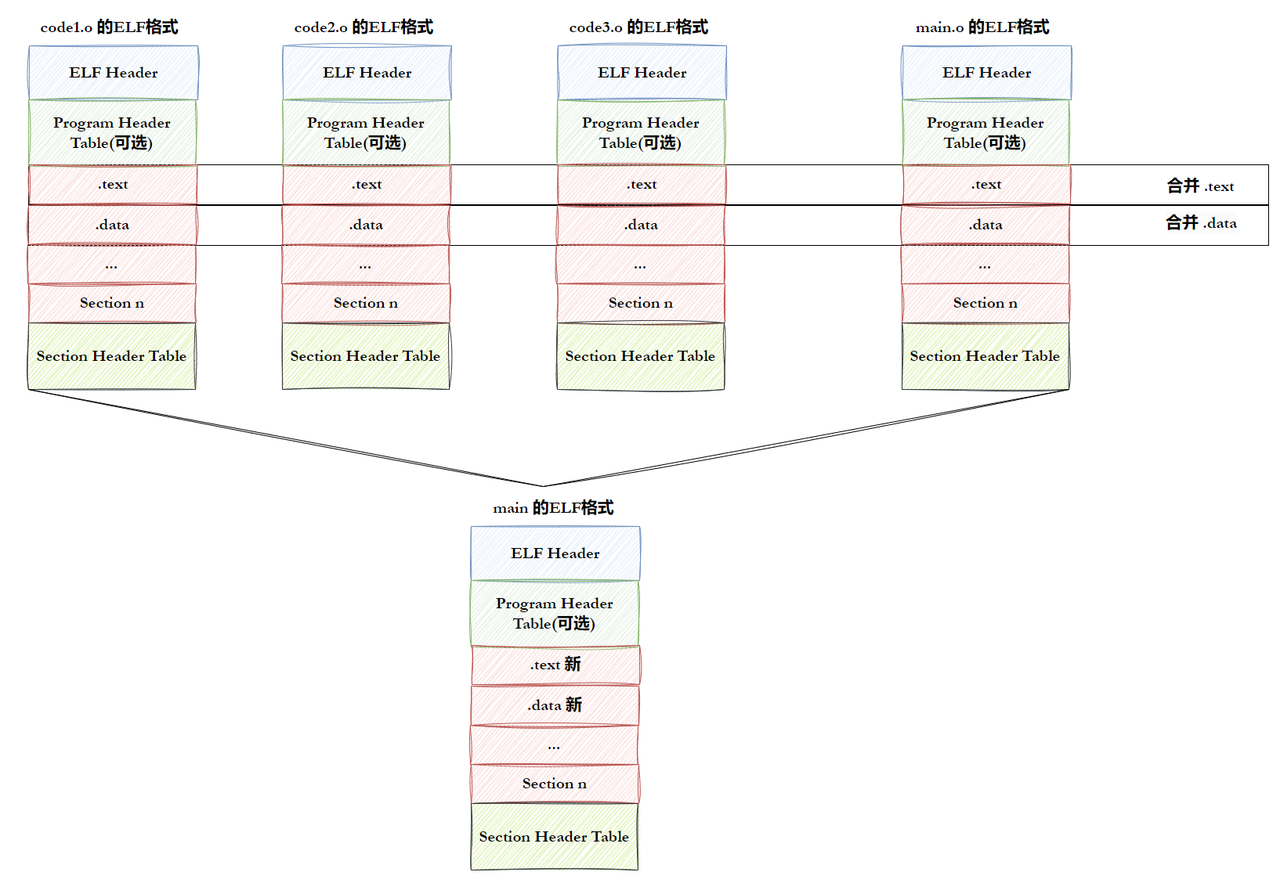
阶段 2:链接阶段(.o + 库 → 可执行 ELF 文件)
**对应你学的:动静态库链接规则、ELF 程序头、虚拟地址的 "静态规划"**这是整个链路的核心,链接器做了两件关键的事:
(1)动静态库的链接规则(第一个问题的核心结论)
| 场景 | 链接行为 | 核心逻辑 |
|---|---|---|
同时存在.so和.a |
默认优先链接动态库(.so) |
GCC 默认 "动态优先" 策略 |
加-static选项 |
强制链接所有静态库(.a),必须存在所有依赖的静态库 |
强制全静态链接,生成无依赖的可执行文件 |
只提供动态库(.so) |
只能动态链接,加-static会报错 |
找不到对应的静态库,无法静态链接 |
只提供静态库(.a) |
只能静态链接,其他库仍可动态链接 | 找不到动态库,自动回退静态链接 |
2)ELF 文件的生成与虚拟地址规划( "编译器也要参与虚拟地址空间")
链接器不仅是合并代码,更是按照操作系统的 ABI 规范,完成了虚拟地址的静态规划:
- 合并 Section :把所有
.o文件中同类型的 Section(比如所有.text、.data)合并成一个大的 Section,形成可执行文件的代码段、数据段等。 - 分配虚拟地址 :给每个合并后的 Section 分配虚拟地址(比如
.text默认从0x400000开始),写入 ELF 文件中,包括:Entry point address:程序入口的虚拟地址(CPU 执行的第一条指令地址,比如你笔记里的0x1060)- 所有指令 / 数据的地址引用(比如
call 0x666中的目标地址,就是函数的虚拟地址)
- 生成
Program Headers(程序头表) :把每个 Section 的虚拟地址、权限、大小等信息写入这个表,这是后续操作系统加载程序的 "蓝图"(呼应你笔记里的readelf -l输出):VirtAddr:Section 在虚拟地址空间的起始虚拟地址Flags:Section 的内存权限(R = 读、W = 写、E = 执行)LOAD类型:标记需要加载到内存的段
关键结论:
程序在磁盘上还没加载的时候,就已经有了虚拟地址,这个地址是链接器在编译阶段就规划好的,物理地址要等加载后才会分配。
阶段 3:进程创建与虚拟地址空间初始化
对应:进程地址空间、task_struct/mm_struct、逻辑地址 vs 虚拟地址当你执行程序时,内核会先创建一个进程,完成虚拟地址空间的初始化:
- 创建进程的内核数据结构
task_struct:进程控制块,每个进程唯一对应一个,记录进程的所有信息mm_struct:内存描述符,是进程虚拟地址空间的 "管理者",包含了虚拟地址空间的所有字段(start_code/end_code、start_data/end_data、start_stack等)
mm_struct的初始化数据来源 (呼应你笔记里的核心问题)✅ 全部来自 ELF 文件的Program Headers!内核会读取Program Headers中的信息,设置mm_struct中各个段的虚拟地址范围,完成虚拟地址空间的初始化。- 关键概念辨析:进程地址空间、虚拟地址、逻辑地址
| 概念 | 本质 | 关系 |
|---|---|---|
| 进程地址空间 | 操作系统为每个进程提供的独立、平坦的虚拟地址范围(32 位系统为 0~4GB) | 虚拟地址的 "容器",定义了地址的布局规则 |
| 虚拟地址 | 进程地址空间中的具体地址编号,程序运行时使用的地址 | 进程地址空间的 "具体门牌",贯穿程序的整个生命周期 |
| 逻辑地址 | 段式管理下 "段基址 + 偏移量" 组成的地址 | Linux 平坦模式下,所有段的基址都设为 0,因此逻辑地址 = 虚拟地址(呼应你笔记里的 "0 + 偏移量") |
关键结论:
进程地址空间是操作系统和编译器共同遵守的规范:编译器按规范规划虚拟地址,操作系统按规范实现虚拟地址空间,两者缺一不可。
阶段 4:加载阶段(磁盘 ELF → 物理内存)
对应你学的:Section to Segment 映射、页表、虚拟地址→物理地址映射 内核初始化好进程的虚拟地址空间后,加载器会根据Program Headers的LOAD段信息,完成程序的加载:
- Section to Segment 映射(你
readelf -l的核心输出) 加载器会把多个权限相同的 Section ,合并成一个Segment(段):- 比如
.text(r-x)和.rodata(r--),权限都是只读,会被合并成一个只读可执行的Segment - 比如
.data(rw-)和.bss(rw-),权限都是可读写,会被合并成一个可读写的Segment - 为什么要合并?因为内存是按页(通常 4KB)管理的,页的权限必须统一,合并后可以减少内存碎片,提高加载效率。
- 比如
- 建立虚拟地址到物理地址的映射
- 内核为每个
Segment分配物理内存页 - 创建页表项,把
Program Headers中的VirtAddr(虚拟地址)映射到对应的物理内存地址 - 根据
Segment的Flags设置虚拟地址的内存权限,防止非法访问
- 内核为每个
- 关键结论程序加载到物理内存后,指令和数据的地址依然是虚拟地址,只是页表把它们映射到了物理地址上,进程本身完全感知不到物理地址的存在。
阶段 5:运行阶段(CPU 执行指令)
对应你学的:EIP、CR3、MMU 地址转换 进程启动后,CPU 会从程序入口地址开始执行指令,整个过程的核心是虚拟地址到物理地址的硬件自动转换:
- CPU 侧的虚拟地址发起
EIP寄存器:存放下一条要执行的指令的虚拟地址 (比如入口地址0x1060,或call 0x666的目标地址),所有 CPU 发出的地址都是虚拟地址CR3寄存器:存放当前进程的页表基址,进程切换时会更新 CR3,确保 CPU 使用当前进程的页表
- MMU 的地址转换(硬件自动完成)
MMU(内存管理单元):CPU 内部的硬件模块,核心作用是把虚拟地址转换成物理地址,这个过程对操作系统透明- 转换流程:
EIP的虚拟地址 → MMU 结合CR3的页表 → 查询到对应的物理地址 → 发送给物理内存读取指令
- 指令执行的闭环 物理内存中读取的指令,其内部的目标地址依然是虚拟地址(比如
call 0x666),执行后会更新EIP,重复上述转换过程,直到程序退出。
三、核心概念大辨析(彻底理清易混点)
| 概念 | 本质 | 关键区别 |
|---|---|---|
| ELF 格式 | Linux 下二进制文件的标准格式,可重定位 / 可执行 / 共享库都是它 | 不是可执行文件的专利,所有目标文件、库、可执行文件都遵循 |
| Section(节) | ELF 文件中按数据类型划分的内容块,链接器视角 | 存在于文件中,服务于链接过程 |
| Segment(段) | 加载器把多个同权限 Section 合并成的逻辑单元,运行时视角 | 不是文件中真实存在的,是内存加载的逻辑分组 |
| 虚拟地址 | 进程视角的逻辑地址,程序运行时使用 | 贯穿程序生命周期,编译阶段就已确定 |
| 物理地址 | 内存硬件的真实地址,只有加载后才分配 | 进程不可感知,由内核和页表管理 |
| 进程地址空间 | 操作系统为进程提供的独立虚拟地址范围 | 虚拟地址的容器,由 OS 和编译器共同规范 |
四、终极闭环总结:整个链路的设计逻辑
为什么 Linux 程序要走这么复杂的流程?核心是为了实现这几个关键目标:
- 代码复用与模块化 :通过链接库(动 / 静态)实现代码复用,
.o文件的 ELF 格式让链接合并成为可能。 - 进程隔离与安全:每个进程有独立的虚拟地址空间,互不干扰,页表实现了内存隔离和权限控制。
- 内存高效管理:Section 合并成 Segment,按页管理内存,减少碎片,提高内存利用率。
- 地址透明性:程序始终使用虚拟地址,不用关心物理内存的分配,操作系统和硬件自动完成转换,简化了程序设计。
整个链路里,编译器 / 链接器负责 "规划" 虚拟地址,操作系统负责 "实现" 虚拟地址空间,硬件负责 "转换" 虚拟地址到物理地址,三者配合,形成了一个完美的闭环,支撑了 Linux 系统中所有进程的运行。