🔥 CrewAI 实战:构建多 Agent 协作团队
🔍 引言
在 AI 时代,单一 Agent 已经难以应对复杂的多步骤任务。多 Agent 协作系统通过角色分工、任务编排,让多个 AI 智能体像团队一样协同工作。本文将带你从零开始构建一个基于 CrewAI 的多 Agent 协作系统,实现研究员、分析师、报告撰写员的分工协作。
🎯 项目亮点
| 特性 | 实现方式 | 技术亮点 |
|---|---|---|
| 🤖 多角色分工 | CrewAI Agent | 专业化角色定义 |
| 🔄 任务编排 | CrewAI Task | 顺序执行与上下文传递 |
| 🛠️ 工具集成 | BaseTool | 统一工具调用 |
| 📊 数据处理 | SQLite + Pandas | 结构化数据查询 |
| 📧 报告输出 | 文件写入 | 自动化报告生成 |
| 🤖 LLM 集成 | DeepSeek API | 高效推理能力 |
🏗️ 整体架构
flowchart TB
subgraph CrewAI["CrewAI Multi-Agent 系统"]
subgraph Agents["Agent 角色层"]
R[Researcher<br/>研究员]
A[Analyst<br/>分析师]
W[Writer<br/>撰写员]
end
subgraph Tasks["Task 任务层"]
RT[Research Task<br/>研究任务]
AT[Analysis Task<br/>分析任务]
WT[Write Task<br/>撰写任务]
end
subgraph Tools["Tool 工具层"]
TS[TavilySearch<br/>网络搜索]
WE[Weather<br/>天气查询]
DQ[DatabaseQuery<br/>数据库查询]
CA[Calculator<br/>计算器]
FW[FileWriter<br/>文件写入]
end
subgraph LLM_Lary["LLM 层"]
LLM[DeepSeek V4<br/>推理引擎]
end
end
RT --> TS
RT --> WE
RT --> DQ
AT --> CA
WT --> FW
R --> RT
A --> AT
W --> WT
Agents --> LLM_Lary
RT --> |context| AT
AT --> |context| WT
classDef task fill:#e1f5fe,stroke:#01579b,stroke-width:1px;
classDef crewAI fill:#fff9c4,stroke:#fbc02d,stroke-width:1px;
classDef agents fill:#e8f5e9,stroke:#2e7d32,stroke-width:1px;
class Tasks task;
class CrewAI crewAI;
class Agents agents;
🚀 核心功能实现
1. 工具定义
在 CrewAI 中,工具通过继承 BaseTool 类实现,每个工具需要定义 name、description 和 _run 方法:
python
from crewai.tools import BaseTool
import math
import requests
import sqlite3
import pandas as pd
class Calculator(BaseTool):
name: str = "Calculator"
description: str = "执行数学计算,输入纯数学表达式,如 '2+3*4'。"
def _run(self, expression: str) -> str:
"""执行数学计算,输入纯数学表达式,如 '2+3*4'。"""
allowed = set("0123456789.+-*/() ")
if not all(c in allowed for c in expression):
return "Error: 表达式包含非法字符"
try:
return str(eval(expression, {"__builtins__": {}}, math.__dict__))
except Exception as e:
return f"Error: {str(e)}"
class Weather(BaseTool):
name: str = "Weather"
description: str = "查询指定城市的实时天气,输入城市中文名,如 '北京'。"
def _run(self, city: str) -> str:
"""查询指定城市的实时天气,输入城市中文名,如 '北京'。"""
geo_url = f"https://geocoding-api.open-meteo.com/v1/search?name={city}&count=1"
geo_data = requests.get(geo_url).json()
if not geo_data.get("results"):
return f"未找到城市 {city}"
lat = geo_data["results"][0]["latitude"]
lon = geo_data["results"][0]["longitude"]
weather_url = f"https://api.open-meteo.com/v1/forecast?latitude={lat}&longitude={lon}¤t_weather=true"
w_data = requests.get(weather_url).json()
cur = w_data["current_weather"]
return f"{city}当前温度 {cur['temperature']}°C,风速 {cur['windspeed']} km/h"
class DatabaseQuery(BaseTool):
name: str = "DatabaseQuery"
description: str = "执行SQL查询,可查询 sales 表(含 product, amount, date 字段)。"
def _run(self, query: str) -> str:
"""执行SQL查询,可查询 sales 表(含 product, amount, date 字段)。"""
init_db()
try:
conn = sqlite3.connect("sales.db")
df = pd.read_sql_query(query, conn)
conn.close()
if df.empty:
return "查询结果为空"
return df.to_string(index=False)
except Exception as e:
return f"查询出错: {e}"
class FileWriter(BaseTool):
name: str = "FileWriter"
description: str = "将内容写入文件,例如 'report.md'。"
def _run(self, filename: str, content: str) -> str:
"""将内容写入文件,例如 'report.md'。"""
try:
with open(filename, "w", encoding="utf-8") as f:
f.write(content)
return f"成功写入文件: {filename}"
except Exception as e:
return f"写入失败: {e}"2. Agent 角色定义
2.1 LLM 配置
python
from crewai import LLM
llm = LLM(
model="deepseek/deepseek-v4-pro", # 模型名称
base_url="https://api.deepseek.com", # API 基础地址
temperature=0, # 温度参数(0-1,越低越确定性)
reasoning_effort="high", # 推理深度
)2.2 Agent 参数详解
python
from crewai import Agent
researcher = Agent(
role="资深研究员", # 角色名称
goal="利用网络搜索、数据库、天气等工具收集和分析信息,输出关键发现。", # 目标
backstory="你是一个全栈研究员,能使用各种工具获取实时数据、查询内部系统。", # 背景故事
tools=[tavily_search, Weather(), DatabaseQuery(), Calculator()], # 分配的工具
verbose=True, # 是否输出详细日志
allow_delegation=False, # 是否允许委派任务
llm=llm # 指定的 LLM
)
analyst = Agent(
role="高级数据分析师",
goal="处理研究员获得的原始数据,进行计算、对比,提炼出有价值的洞察。",
backstory="你是数据专家,擅长从表格和数字中看出趋势。",
tools=[Calculator()],
verbose=True,
allow_delegation=False,
llm=llm
)
writer = Agent(
role="报告撰写员",
goal="根据分析师的洞察,撰写结构清晰、语言流畅的Markdown报告,并保存文件。",
backstory="你是一名技术文档工程师,追求简洁与严谨。",
tools=[FileWriter()],
verbose=True,
allow_delegation=False,
llm=llm
)Agent 完整参数表:
| 参数 | 类型 | 必需 | 说明 |
|---|---|---|---|
role |
str | ✅ | Agent 的角色名称,定义其在团队中的职能 |
goal |
str | ✅ | Agent 的目标,驱动其行为决策 |
backstory |
str | ✅ | Agent 的背景故事,增强角色一致性 |
tools |
listBaseTool | ❌ | 分配给 Agent 的工具列表 |
llm |
LLM | ❌ | 指定使用的语言模型 |
verbose |
bool | ❌ | 启用详细日志输出,默认 False |
allow_delegation |
bool | ❌ | 允许 Agent 委派任务给其他 Agent |
max_iter |
int | ❌ | 最大迭代次数,默认 20 |
max_rpm |
int | ❌ | 每分钟最大请求数 |
memory |
bool | ❌ | 启用记忆功能,默认 True |
cache |
bool | ❌ | 启用工具结果缓存,默认 True |
respect_context_window |
bool | ❌ | 尊重上下文窗口限制,默认 True |
3. 任务编排
python
from crewai import Task
research_task = Task(
description="""
1. 使用 search 工具搜索"2026年5月全国天气趋势"。
2. 使用 weather 工具查询"北京"和"深圳"的当前天气。
3. 使用 database_query 查询所有销售记录。
请将以上三项结果整理为一份要点列表。
""",
expected_output="一份包含天气趋势、两个城市实时天气、销售记录表的要点列表。",
agent=researcher
)
analysis_task = Task(
description="""
根据研究员提供的数据:
- 计算总销售额(用计算器)。
- 简单评论天气是否可能影响销售(例如高温或暴雨与销售额的关系)。
""",
expected_output="包含总销售额和一个简短天气影响评述的文本。",
agent=analyst,
context=[research_task] # 依赖研究员的任务输出
)
write_task = Task(
description="""
基于分析师的结论,撰写一份名为 weather_sales_report.md 的Markdown报告。
标题:《天气与销售关联分析报告》
内容需包含:数据概览、天气情况、销售总额、影响简评。
""",
expected_output="完整的Markdown报告。",
agent=writer,
output_file="weather_sales_report.md",
context=[analysis_task]
)Task 完整参数表:
| 参数 | 类型 | 必需 | 说明 |
|---|---|---|---|
description |
str | ✅ | 任务的详细描述 |
expected_output |
str | ✅ | 期望的输出格式/内容 |
agent |
Agent | ✅ | 执行此任务的 Agent |
context |
listTask | ❌ | 前置任务列表,用于上下文传递 |
output_file |
str | ❌ | 输出文件路径 |
tools |
listBaseTool | ❌ | 任务专用工具(覆盖 Agent 工具) |
async_execution |
bool | ❌ | 是否异步执行,默认 False |
config |
dict | ❌ | 任务特定配置 |
callback |
function | ❌ | 任务完成回调函数 |
4. Crew 组装与执行
python
from crewai import Crew, Process
crew = Crew(
agents=[researcher, analyst, writer], # Agent 列表
tasks=[research_task, analysis_task, write_task], # Task 列表
process=Process.sequential, # 执行流程
verbose=True, # 日志级别
memory=True, # 启用记忆
embedder={ # 嵌入配置
"provider": "openai",
"model": "text-embedding-3-small"
},
share_crew=True # 共享 Crew 实例
)
result = crew.kickoff()
print("最终输出:\n", result)Crew 完整参数表:
| 参数 | 类型 | 必需 | 说明 |
|---|---|---|---|
agents |
listAgent | ✅ | Agent 列表 |
tasks |
listTask | ✅ | Task 列表 |
process |
Process | ❌ | 执行流程:sequential/hierarchical/parallel |
verbose |
int | ❌ | 启用详细日志输出,默认 False |
memory |
bool | ❌ | 启用 Crew 级别记忆,默认 False |
embedder |
dict | ❌ | 嵌入模型配置 |
planning |
bool | ❌ | 启用任务规划,默认 False |
planning_llm |
LLM | ❌ | 规划使用的 LLM |
max_rpm |
int | ❌ | 全局每分钟请求数限制 |
language |
str | ❌ | 输出语言,默认 "zh" |
step_callback |
function | ❌ | 每步执行后的回调 |
share_crew |
bool | ❌ | 共享 Crew 实例 |
Process 执行模式:
| 模式 | 说明 | 适用场景 |
|---|---|---|
Process.sequential |
顺序执行 | 任务有明确先后依赖 |
Process.hierarchical |
层级管理 | 需要 Manager Agent 协调 |
Process.parallel |
并行执行 | 任务相互独立可同时执行 |
📦 依赖与环境配置
安装依赖
bash
pip install crewai crewai-tools langchain-core python-dotenv requests pandas环境变量配置(.env)
tex
TAVILY_API_KEY=your_tavily_api_key
DEEPSEEK_API_KEY=your_deepseek_api_key💡 使用示例
运行命令
bash
python main.py执行流程
sequenceDiagram
participant User as 用户
participant Researcher as 研究员
participant Analyst as 分析师
participant Writer as 撰写员
User->>Researcher: 启动任务
Researcher->>Researcher: 搜索天气趋势
Researcher->>Researcher: 查询北京天气
Researcher->>Researcher: 查询深圳天气
Researcher->>Researcher: 查询销售数据
Researcher-->>Analyst: 返回综合要点列表
Analyst->>Analyst: 计算总销售额
Analyst->>Analyst: 分析天气影响
Analyst-->>Writer: 返回分析结论
Writer->>Writer: 撰写 Markdown 报告
Writer->>Writer: 保存 weather_sales_report.md
Writer-->>User: 返回完整报告
输出示例
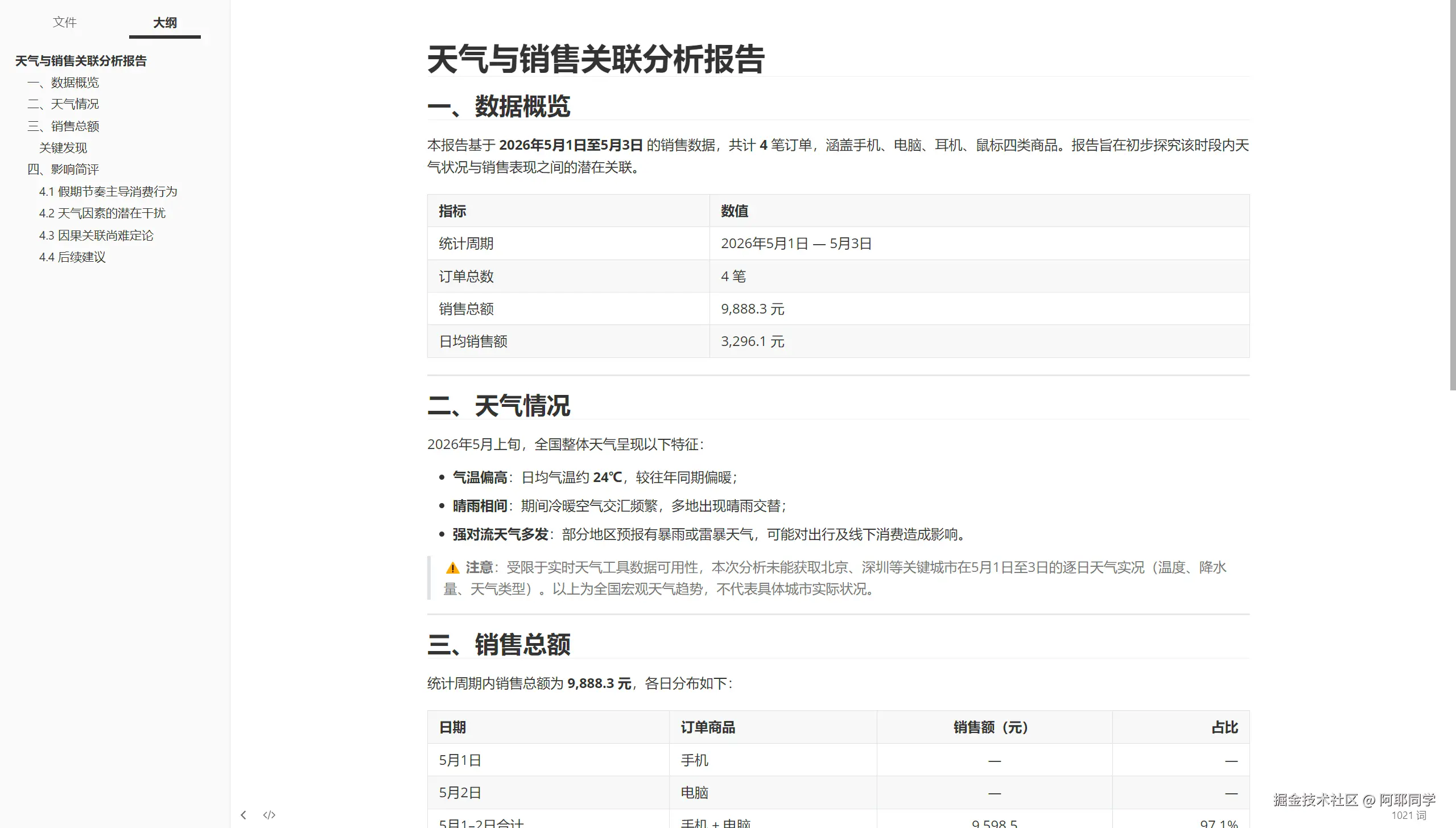
🔧 核心技术解析
1. Agent 角色设计原则
| 原则 | 说明 |
|---|---|
| 专业化 | 每个 Agent 只负责一个领域 |
| 职责清晰 | 通过 role 和 goal 明确定位 |
| 工具匹配 | 根据职责分配必要的工具 |
| 可追溯 | 通过 verbose 模式追踪执行过程 |
| LLM 独立 | 每个 Agent 可使用独立的 LLM |
2. 任务上下文传递
CrewAI 通过 context 参数实现任务间数据传递:
python
analysis_task = Task(
...,
context=[research_task] # 研究员的输出作为分析师的输入
)flowchart LR
R[Researcher<br/>研究输出] -->|context| A[Analyst<br/>分析输入]
A[Analyst<br/>分析输出] -->|context| W[Writer<br/>撰写输入]
3. 工具权限控制
每个 Agent 只分配必要的工具:
| Agent | 工具权限 | 理由 |
|---|---|---|
| 研究员 | 搜索、天气、数据库、计算器 | 需要收集各种数据源 |
| 分析师 | 仅计算器 | 专注于数据分析 |
| 撰写员 | 仅文件写入 | 专注于输出生成 |
4. LLM 集成策略
flowchart TB
subgraph LLM配置["LLM 配置选项"]
A[全局 LLM<br/>Crew 级别]
B[独立 LLM<br/>Agent 级别]
C[规划 LLM<br/>Planning 级别]
end
A --> |所有 Agent 默认使用| Crew
B --> |特定任务优化| Agents
C --> |任务规划| Planning
🚀 技术洞察
1. 角色分工的重要性
多 Agent 的核心价值在于分工协作:
- 研究员:负责信息收集(外部搜索、数据库查询)
- 分析师:负责数据处理和洞察提炼
- 撰写员:负责结构化输出
2. BaseTool vs @tool 装饰器
CrewAI 推荐使用 BaseTool 类而非 LangChain 的 @tool 装饰器:
| 特性 | BaseTool | @tool 装饰器 |
|---|---|---|
| 集成度 | CrewAI 原生 | 需适配 |
| 类型提示 | 完整支持 | 部分支持 |
| 缓存机制 | 内置 | 需额外配置 |
| 异步支持 | 支持 | 需适配 |
📊 性能优化建议
| 优化方向 | 具体措施 |
|---|---|
| 任务并行化 | 将可并行的任务设置为并行执行 |
| 结果缓存 | 启用 cache=True 缓存重复查询结果 |
| 工具选择优化 | 根据 Agent 角色精简工具列表 |
| 日志级别控制 | 生产环境降低 verbose 级别 |
| 异步执行 | 使用 async_execution=True 支持异步工具调用 |
| 上下文窗口 | 启用 respect_context_window=True 避免溢出 |
| 记忆管理 | 合理使用 memory=True 平衡性能和资源 |
🎯 总结与展望
本文要点
- ✅ 使用 CrewAI 构建多 Agent 协作系统
- ✅ 定义专业化的 Agent 角色(研究员、分析师、撰写员)
- ✅ 实现任务编排与上下文传递
- ✅ 集成多种工具(搜索、天气、数据库、计算器)
- ✅ 自动生成结构化报告
- ✅ 配置 DeepSeek LLM 实现高效推理
未来方向
- 🔄 动态角色分配:根据任务自动选择合适的 Agent
- 🧠 角色沟通:Agent 之间可以直接沟通
- 📊 性能监控:追踪每个 Agent 的执行效率
- 🔒 权限管理:细粒度的工具访问控制
- 📱 UI 界面:可视化展示多 Agent 协作过程
📮 互动交流
如果你有任何问题或想法,欢迎在评论区留言!如果觉得本文对你有帮助,请点赞、收藏、关注三连支持一下~