AgentSPEX:当 Agent 框架开始把"控制流"从 Python 里抠出来
核心摘要
我前阵子在维护一个 LangGraph 写的 Agent 项目,碰到一件挺尴尬的事------产品同学想把"先搜五个方向、然后并行总结、再写一份报告"这条链路改成"先搜十个方向、按主题聚类后再总结",结果他们打开 agent.py 看到一堆 StateGraph、add_conditional_edges、@tool 装饰器,直接关闭了文件。说实话,这种"把工作流逻辑钉死在 Python 里"的设计,在团队规模扩大之后就开始拖后腿。
UIUC 的 ScaleML 团队这篇 AgentSPEX 提出的方案很直接:把 Agent 的控制流、状态管理、子模块组合全部抠出来,用 YAML 写成可读的声明式规约,然后配一个完整的 Agent Harness 去执行------支持 Docker 沙箱、断点续跑、轨迹回放,甚至给你留了形式化验证的口子。在 7 个 benchmark 上(SciBench、ChemBench、AIME 2025、SWE-Bench Verified 等)相比 CoT 和 ReAct 都拿到了最高分,AIME 2025 直接打到了 100%。
但坦率讲,这篇论文真正打动我的不是这些榜单数字------这些榜里 CoT/ReAct 本来就不是合适的对手。真正值得琢磨的是它在 SWE-Bench 上做的"模型版本鲁棒性"实验:当 Claude-Opus 从 4.5 换到 4.6,mini-SWE-agent 掉了 1.2 个点,Live-SWE-agent 直接崩了 6.8 个点,而 AgentSPEX 只掉了 0.2 个点。这个数才是 YAML 解耦真正的价值所在。
论文信息
- 标题:AgentSPEX: An Agent SPecification and EXecution Language
- 作者:Pengcheng Wang*, Jerry Huang*, Jiarui Yao* (共同一作), Rui Pan, Peizhi Niu, Yaowenqi Liu, Ruida Wang, Renhao Lu, Yuwei Guo, Tong Zhang
- 机构:University of Illinois Urbana-Champaign(主力)、University of Wisconsin--Madison、Baylor College of Medicine
- arXiv :https://arxiv.org/abs/2604.13346
- 代码 :https://github.com/ScaleML/AgentSPEX
为什么需要又一个 Agent 框架
"ReAct 万能论"已经撑不住长程任务了
回到现状本身。今天大多数 Agent 框架走的是 ReAct 范式:一条 system prompt + 一条 instruction 扔给模型,剩下的就靠模型自己决定调什么工具、走什么分支、什么时候停。这套东西在演示 demo 和短链路任务上很好看,因为模型聪明,能凑合处理。
但只要任务变长------多轮检索、多文件改动、多步推理------ReAct 的几个老毛病就一起冒出来:
- 不可控:模型走偏了你没法干预,只能等它自己绕回来或者把步数耗完
- 不可复现:同样的 prompt 跑两次,决策树可能完全不一样
- 不可观测:哪一步用了什么 context,哪一步本应该 reset 上下文,全是黑盒
LangGraph 这类框架的代价:你必须用 Python 思维写 Agent
为了上结构化控制,业界早就推出了 LangGraph、DSPy、CrewAI 这些框架。它们做的事是好的------把工作流抽出来,做成 stateful graph,加分支、加循环、加 memory。
问题是:这些框架把工作流逻辑深度绑定到 Python 上。
我之前在 LangGraph 里写一个简单的"研究员 Agent",光是设置 StateGraph(GraphState)、add_node、add_conditional_edges、compile 这套样板代码就花了一下午。改一个分支条件要去 Python 里改函数返回值、改 conditional edge 的 router function。版本控制时 diff 出来一堆代码块,搞不清楚到底是工作流变了还是底层逻辑变了。
更关键的是:领域专家、产品经理、文档同学根本碰不了。这本来是 Agent 应该解决的问题------让懂业务的人能配置 Agent 行为------结果框架本身把这个口子又焊死了。
还有一个被低估的痛点:context rot
这个点论文在 Related Work 里提了一句但没展开,我觉得很重要。ReAct 范式天然要求模型把整条对话历史一直拖着走。任务越长,context 越臭。Lost in the middle、Context rot 这些问题已经被多篇论文测过了------长 context 不是越长越好,是越长越糊。
工程上的应对一般是写一堆 context truncation 的逻辑塞在 Python 代码里。但每个 step 该带哪些变量、该清空什么历史、子模块返回什么 summary,这些决策说到底属于"工作流设计",应该让你能在工作流声明里直接控制,而不是埋在 Python 函数里。
AgentSPEX 想解决的就是这堆问题。
AgentSPEX 是什么
一句话:用 YAML 写 Agent 工作流,配一个能跑能查能恢复的 Harness。
它的设计哲学就两条:
- 表达力够用------能覆盖常见的长程任务模式(分支、循环、并行、子模块),不需要回到 Python 改源码
- 简单可读------领域专家也能改、能看、能 diff
下面这张架构图把整套东西讲得很清楚:
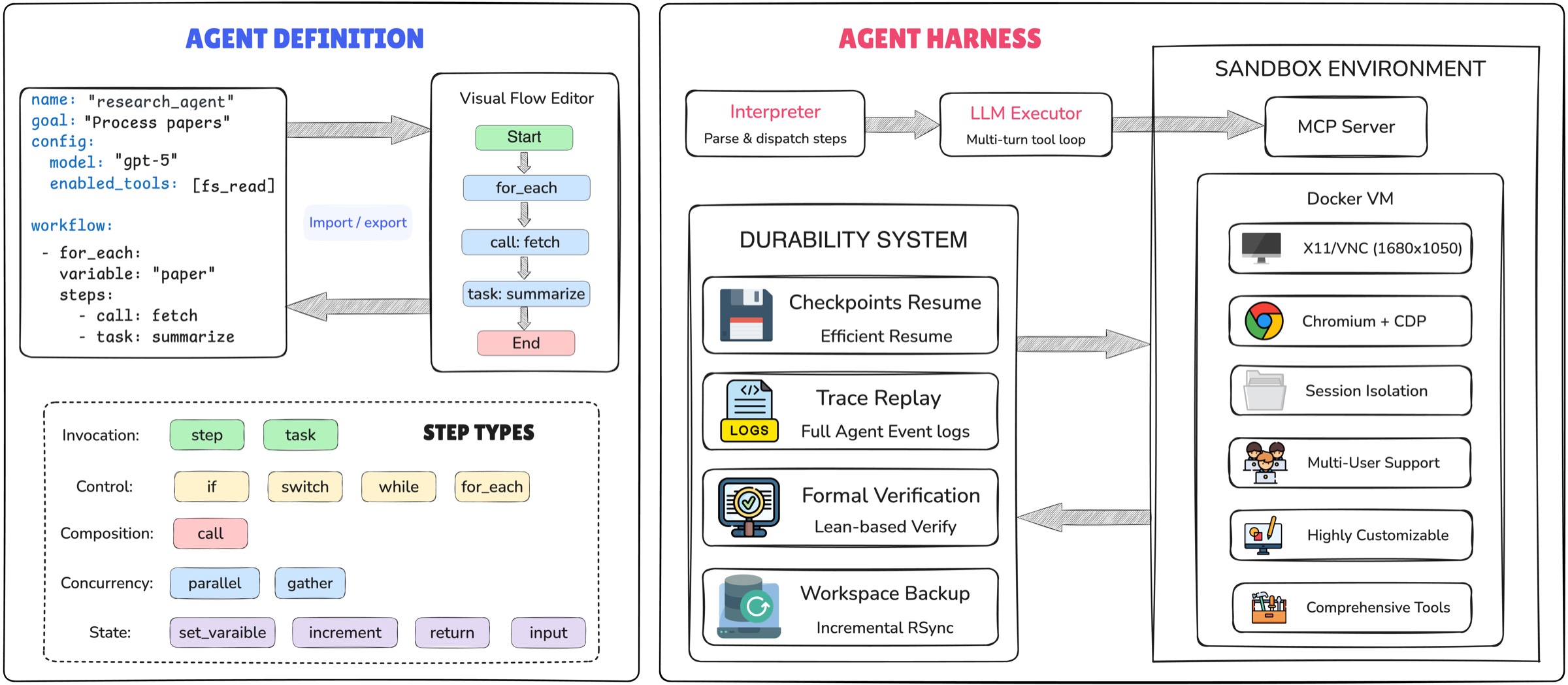
图1:左半边是用户视角------一个 YAML 文件就是一个 Agent,里面声明了 step/task、控制流(if/while/for_each)、组合(call)、并发(parallel/gather)、状态管理(set_variable/return)。右半边是执行视角------Interpreter 负责解析和分发,Executor 跑 LLM 多轮 tool 循环,Durability System 管断点和回放,Sandbox 提供隔离的 Docker 环境带 X11/VNC、Chromium、文件系统等。这套架构最核心的解耦就在于:左边的 YAML 是"做什么",右边的 Harness 是"怎么做",两者通过统一接口对接。
核心语言原语:薄、够用
YAML 里所有可用的关键字也就 11 个,全都在下面这张表里:
| 类别 | 关键字 | 说明 |
|---|---|---|
| 调用 | task |
开启一段全新对话(无历史) |
| 调用 | step |
在持久会话里继续一轮(带历史) |
| 控制流 | if / switch |
条件分支 |
| 控制流 | while |
带迭代上限的循环 |
| 控制流 | for_each |
遍历列表 |
| 组合 | call |
调用另一个 workflow 作为子模块 |
| 并发 | parallel / gather |
并发执行 |
| 状态 | set_variable |
给变量赋值 |
| 状态 | increment |
数值变量自增 |
| 状态 | input |
让用户介入 |
| 状态 | return |
返回值给上层 workflow |
这里有个设计选择我觉得挺漂亮:task vs step 的区分。
task = 开一段全新对话,模型从零开始处理这个 instruction,做完就返回结果,下一个 task 跟它没有上下文耦合。
step = 在已有的对话历史上继续推进一轮,模型能看到之前所有 messages。
这个二分法直接把"context 该不该带"这个决策从代码逻辑里拎出来,变成 YAML 里的关键字。你想 reset 上下文?写 task。你想让模型多轮推理?写 step。整个工作流的 context 流向一眼就看明白。
下面是论文里给的最小例子,一个"主题研究 + 写报告"的 Agent:
yaml
name: "research_assistant"
goal: "Research a topic and write a summary"
config:
model: "gpt-5.4"
enabled_tools: ["web_search", "file_write"]
parameters:
topic: "Enhancing LLM reasoning via RLHF"
file_path: "outputs/report.md"
workflow:
- task:
instruction: "Generate a list of search queries for {{topic}}"
save_as: "search_queries"
- call:
module: "modules/search_and_summarize.yaml"
parameters:
queries: "{{search_queries}}"
save_as: "paper_summary"
- task:
instruction: "Write a report at {{file_path}} based on these findings: {{paper_summary}}"注意几个细节:
- 变量用 Mustache 风格的
{``{topic}}引用 - 任何 step 的输出都可以
save_as: xxx存成命名变量 - 子模块通过
call调进来,传参传出参,跟函数调用一模一样 - 工具白名单在
config.enabled_tools里限定,避免 Agent 乱调
我看到这个语法的第一反应是------这跟 GitHub Actions 的 workflow YAML 几乎是一个味道。这其实是个好事:DevOps 领域已经验证过 declarative YAML workflow 这条路是 work 的,迁移到 Agent 领域是个挺自然的延伸。
统一抽象:skill 和 agent 是同一个东西
很多框架会把"技能"(tool / skill)和"agent"做成两种不同的实体。AgentSPEX 把这套合并了------任何 workflow 既可以独立运行,也可以作为子模块被 call 进来,也可以注册为一个 skill 让上层 Agent 动态选择调用。
这个设计在工程上的好处很大。我之前在做多 Agent 系统时碰到一个反复出现的问题:调试一个子 Agent 要先把它从父 Agent 里剥出来单独跑,剥出来要改一堆参数对接。AgentSPEX 这种"workflow 即一切"的设计天然规避了这个问题------子模块就是一个独立可跑的 workflow,你单独 run 它就行。
Visual Editor:双向同步的图形化编辑
光有 YAML 还不够,他们还做了一个可视化编辑器:
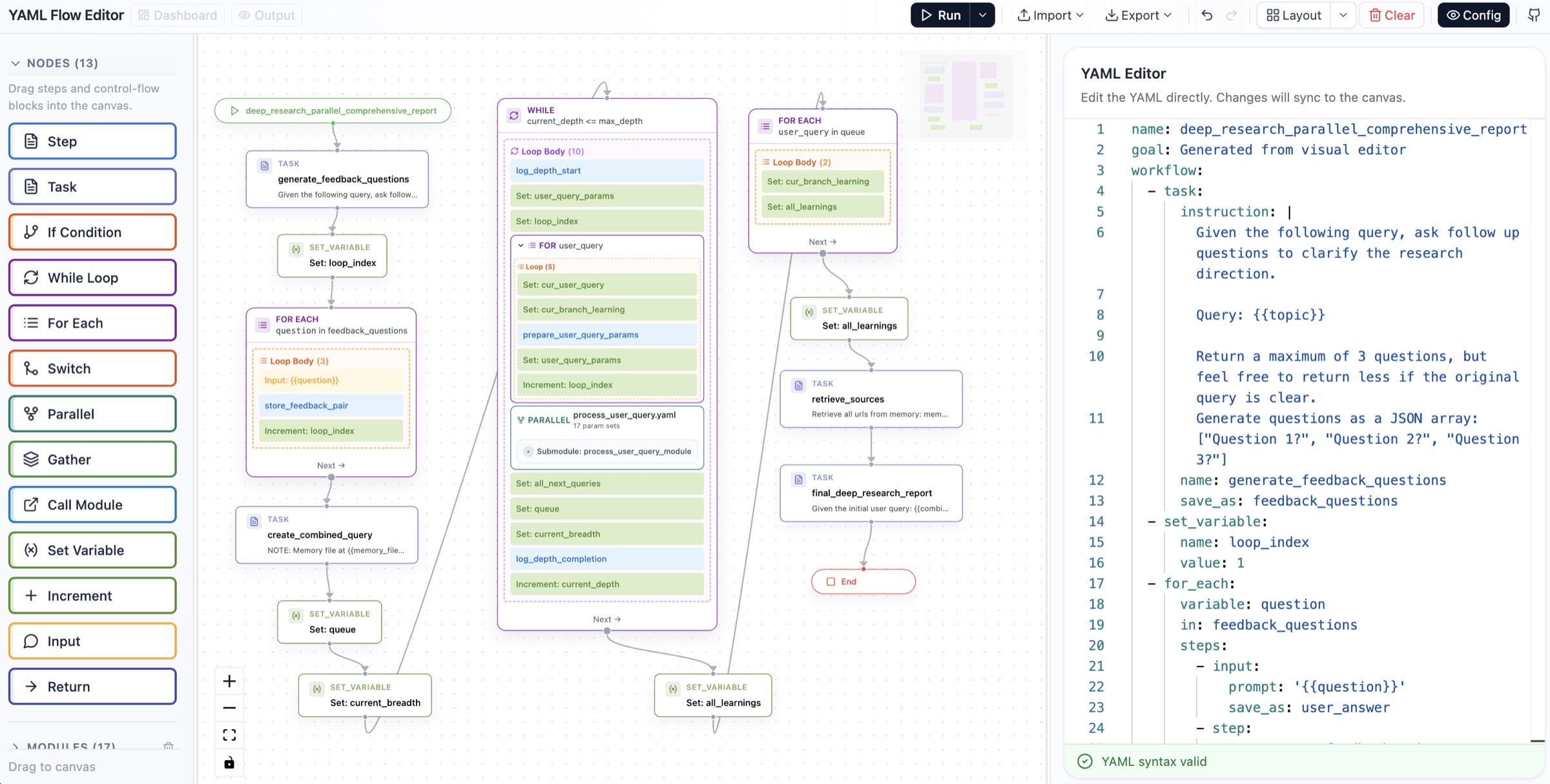
图2:左边节点面板可以拖拽(13 种节点类型 + 17 个可复用模块),中间是工作流的图形化展示------你能看到 WHILE 循环、FOR EACH 嵌套、PARALLEL 并行块,每个节点是一个 task/step,颜色区分类型。右边的 YAML 编辑器跟图视图是实时双向同步的:在图上加一个节点,YAML 立刻更新;在 YAML 改一个字段,图视图立刻刷新。底部还能看到 "YAML syntax valid" 的实时校验。
这个双向同步的设计是论文里我觉得最有诚意的部分。很多 low-code 工具的图形化编辑器是单向的------拖拽生成代码后,代码就跟图脱节了。AgentSPEX 把图和 YAML 当成同一份数据的两个视图,避免了"改代码后图不更新"或"改图后代码乱了"的常见坑。
工程上想得明白的人都知道,AST 双向同步比看起来难。要保证你修改 YAML 时图不会爆炸,又要保证图上拖拽产生的 YAML 是 well-formed 且语义正确的------这背后需要一套挺扎实的 schema validation 和 round-trip 编辑实现。
Agent Harness:执行引擎是真正的硬骨头
写 YAML 容易,让 YAML 真的稳定跑起来才是难的。论文用了整整一章讲 Harness,我把核心几个点拎出来。
Interpreter + Executor 双层结构
Interpreter 是入口:解析 YAML、校验结构、展开模板变量、按操作类型分发到对应的 handler。它管嵌套结构(循环、条件、子模块)的递归和变量作用域。每个操作会被分配一个层级化的 step ID(比如 3.2.1 表示第 3 个操作的第 2 次迭代里的第 1 个子操作),这套 ID 后面给 checkpoint 和日志用。
Executor 是 LLM 交互循环:对每个 step 或 task,跑一个多轮的 tool-calling loop------发 message history 给模型、解析 tool calls、通过 MCP client 执行、把结果 append 回 message history、继续。终止条件是模型返回不带 tool call 的 response 或达到 token/tool 上限。
我特别想夸的是层级 step ID 这个设计 。我之前自己写 Agent 框架时一直纠结日志里 step ID 怎么标,扁平化的话嵌套循环里就乱了。3.2.1 这种树状 ID 直接对应 YAML 里的逻辑结构,看日志立刻知道在哪一层。这个细节体现了论文作者真的在自己用这套框架。
Docker 沙箱 + 50+ 工具
每个 workflow 跑在一个隔离的 Docker 沙箱里,提供:
- 浏览器(Chromium + CDP)
- X11/VNC(1680x1050)做 GUI 自动化
- 文件系统隔离
- MCP server 暴露的 50+ 工具(文件操作、web 搜索、代码执行、浏览器自动化等)
这套东西的好处是显而易见的------Agent 真要写代码、跑代码、连环境,必须在沙箱里。坏处也很明显------每个 workflow 起一个 Docker 实例的启动开销不小,对快速迭代不友好。
Durability:长程任务的命门
这部分我觉得是整个 Harness 里设计最扎实的:
Checkpointing:每个 step 跑完后存一个快照,包括完成的 step ID、当前 context(所有变量和上游输出)、step 级 metrics、沙箱状态。任何时候都能从某个 checkpoint 恢复------重新加载 context、跳过已完成 step、重新挂回原沙箱 session。
Selective Trace Replay:这个特性是真的香。开发工作流时最大的痛点之一就是------改一个中间 step 的 prompt,要重跑整个 workflow 包括所有未变的上游 step,又慢又烧钱。AgentSPEX 的做法是:从某条历史轨迹里加载前 N 个 step 的结果,从第 N+1 个 step 开始 live 执行。这样你能在保持上游 context 不变的前提下隔离测试某一步的改动。
我之前调一个 8 步的研究 Agent,每次改第 6 步的 prompt 都要重跑前 5 步(每次 50 多刀的 API 费用),心都在滴血。这种 "selective replay" 真要做出来能省下大量钱和时间。
Formal Verification(实验性) :因为 YAML 把控制流、变量依赖、step 边界全显式化了,可以用 Lean 或 Isabelle 这类形式化语言给每一步定义 pre/post-condition,然后做静态或运行时验证。论文在附录里给了一个完整例子------验证一个 extract_single_citation_module,能输出每个变量满足哪些谓词(isValidFilePath、isValidBibtex、isNonEmptyString 等),最后输出 "ALL NODES VERIFIED"。
说实话这个方向我自己也还在摸索。让 Agent 行为可形式化验证这个目标听起来很美,但真要落地非常难------LLM 的输出是概率性的,所谓的 isValidBibtex 这种谓词最后还是得靠 tool 校验或正则匹配。论文也没声称已经能 production-ready,只是说"AgentSPEX 的声明式结构使这件事变得可能"。我觉得这个表态挺克制,没硬吹。
Observability Dashboard
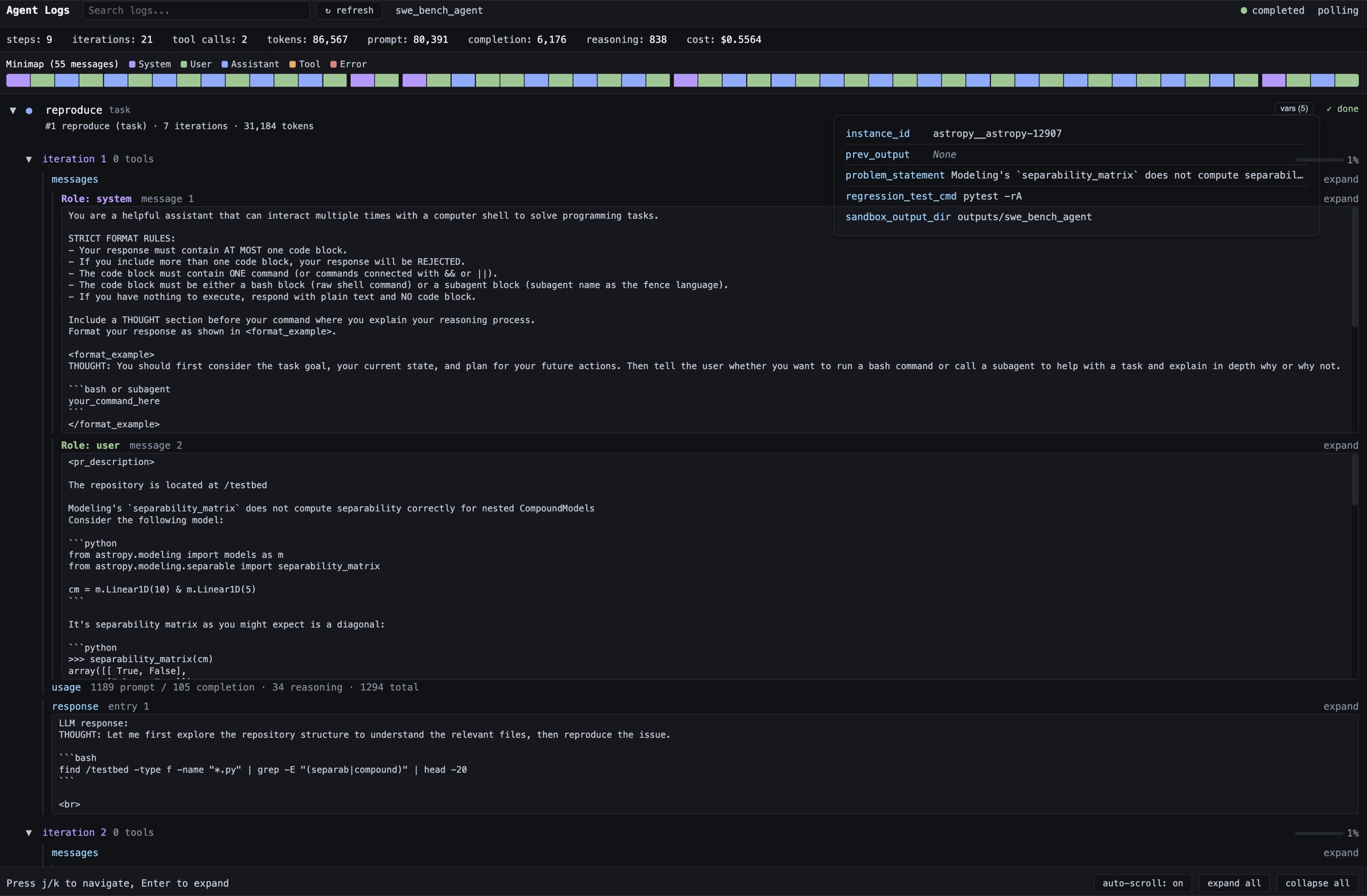
图3:左上角的统计条直接把 steps、iterations、tool calls、tokens(区分 prompt/completion/reasoning)和 cost 摆出来;中间是一个时间轴 minimap 用颜色区分 system/user/assistant/tool message;下面是逐条 message 的展开视图,每条 message 能看到 role、内容、tools 调用情况、token 消耗。这种粒度的可观测性对调试长程 Agent 是必须的------光看最终答案根本不知道哪一步走偏了。
实验结果:榜单数字 vs 真正有意思的发现
7 个 benchmark 全胜------但要分开看
论文在 7 个 benchmark 上做了对比,都是 CoT、ReAct、AgentSPEX 三方对比。具体数据:
| 数据集 | 领域 | 模型 | CoT | ReAct | AgentSPEX | 提升 |
|---|---|---|---|---|---|---|
| SciBench | 科学推理 | GPT-5 | 85.92% | 87.79% | 90.61% | +2.82 |
| StemEZ (MMLU-Pro 物化子集) | 科学推理 | GPT-5 | 82.87% | 84.72% | 86.57% | +1.85 |
| ChemBench | 化学知识 | GPT-5* | 78.90% | 77.80% | 83.30% | +4.40 |
| AIME 2025 | 数学竞赛 | GPT-5 | 94.60%(无工具)/ 99.60%(带 Python) | --- | 100.0% | +0.40 |
| ELAIPBench | 论文理解 | GPT-5* | 37.22% | 33.80% | 43.70% | +6.48 |
| WritingBench | 生成写作 | Claude-Sonnet-4.5-Thinking | 79.90% | 80.30% | 81.00% | +0.70 |
| SWE-Bench Verified | 软件工程 | Claude-Opus-4.5/4.6* | mini-SWE-agent: 76.20% / Live-SWE-agent: 74.60% | --- | 77.10% | +0.90 |
(*表示用了 high-reasoning effort)
我的第一反应是怀疑
看到这个表我先泼冷水。CoT 和 ReAct 本来就不是合适的对手------CoT 是单 prompt 推理,ReAct 是 prompt 里塞了工作流但不强制执行。这个比较等于让一个有"工作流执行引擎"的 Agent 跟一个"只看到工作流但靠自己理解执行"的 Agent 比,赢是必然的。
真正要对手的是 LangGraph、DSPy、CrewAI 这些用 Python 写工作流的同类框架------它们也能写出同样的逻辑结构,只是 DX 不一样。但论文没在主表里跟这些框架直接打。
不过论文在 Discussion 里有个观察我觉得挺有意思------ReAct 在 ELAIPBench 和 ChemBench 上反而比 CoT 还差(ELAIPBench:33.8% vs 37.2%;ChemBench:77.8% vs 78.9%)。作者的解释是:把工作流塞 prompt 里但不强制执行,反而给模型增加了认知负担------它要同时理解工作流结构和推理任务本身。
这个发现其实蛮反直觉的,但想明白后又很合理。让 LLM 自己解释长 prompt 里的工作流然后忠实执行是不靠谱的------它会偷懒、会跳步、会被推理任务带偏。把控制流抠出来交给确定性的 interpreter 反而能减负。这个证据其实比"我的榜分更高"重要得多。
真正值钱的发现:模型版本鲁棒性
我前面提到的那张表才是这篇论文最有 insight 的实验数据:
| Agent | Claude-Opus-4.5 | Claude-Opus-4.6 | Δ |
|---|---|---|---|
| mini-SWE-agent | 76.8% | 75.6% | −1.2 |
| Live-SWE-agent | 78.0% | 71.2% | −6.8 |
| AgentSPEX (Ours) | 77.2% | 77.0% | −0.2 |
Live-SWE-agent 在升级模型后掉了 6.8 个点------这个数字很恐怖。它意味着当前主流的 Agent 框架是高度耦合于具体模型行为的。你以为升级到更强的模型应该更好,结果反而崩了。
而 AgentSPEX 几乎没变(−0.2,基本是噪声水平)。
为什么会这样?我的理解是:当 prompt、控制流、工具调度全部分离时,每一层的稳定性就独立了。模型升级只影响 LLM 那一层的具体输出格式或推理偏好,不会牵动整个工作流的执行逻辑。而把这些东西混在 Python 代码里写的框架,模型一升级,里面藏的各种"模型特定的 prompt hack"就全要重新调。
这个发现其实回应了 Chen 等人 2023 那篇广为流传的"ChatGPT 输出随时间变化"研究------LLM 行为漂移是常态,Agent 框架的抗漂移能力应该被作为一个核心评估维度。AgentSPEX 在这个维度上比 mini-SWE-agent 和 Live-SWE-agent 都强一截,这才是它真正的竞争力,不是榜单分数高那 1-2 个点。
User Study:23 人问卷的取舍
论文还做了个用户研究:23 位有编程背景的参与者,对比 AgentSPEX 和 LangGraph 写的同一个 Agent。
定性结论:
- AgentSPEX 占优:可读性、清晰度、新建 workflow 的易用性
- LangGraph 占优:构建"复杂多步"工作流时
- 描述:AgentSPEX 是 "accessible to non-coders"、"easier to understand";LangGraph 是 "customizable"、"more rigorous"
23 人样本量太小,不能下太重的结论。但定性反馈里有个信号挺关键:用户对 AgentSPEX 处理超复杂场景的能力没信心。论文用 deep research / AI scientist / AI advisor 三个 demo 来反驳这个怀疑,但说服力有限------你给我看 demo 跑通了,跟我相信它能在生产环境处理我自己的复杂工作流,是两回事。
跟同期工作的对比:到底是底层突破还是工程整合
我最反感"首个 XX"这种话术,所以特别留意了 Related Work。论文的对比表很坦诚:
| 框架 | 自然语言指令 | 显式 Context 控制 | 可视化编辑器 |
|---|---|---|---|
| AutoGen | ❌ | ❌ | ❌ |
| DSPy | ❌ | ❌ | ❌ |
| CrewAI | 部分 | ❌ | ❌ |
| LangGraph + LangFlow | ❌ | ❌ | ✅ |
| n8n | ❌ | ❌ | ✅ |
| ADL | ✅ | ❌ | ❌ |
| PDL | ✅ | 部分 | ❌ |
| AgentSPEX | ✅ | ✅ | ✅ |
老实说,这三列里每一列单独看都不是新东西:
- 自然语言指令工作流:ADL、PDL 早就在做
- 显式 Context 管理:MemGPT、ACON 这些专门做内存管理的框架已经把这个问题挖得很深
- 可视化编辑器:LangFlow、n8n 早就有了
AgentSPEX 的真正贡献是把这三件事整合在一个统一的设计里,并且做了几个值得肯定的细化:
stepvstask的二分把 context 流向显式化(这个是 ADL/PDL 没有的精度)- 双向同步的 visual editor + YAML(LangFlow 没做到双向)
- Selective trace replay(这个我没看到其他框架做到这个程度)
- 形式化验证的接口(实验性但方向对)
所以这篇论文的定位应该是"扎实的工程整合 + 几个有创意的细化设计",不是底层范式突破。但工程整合做得好本身就有价值------尤其是当整合的方向对,且数据能证明(比如 SWE-Bench 的模型鲁棒性)。
我的判断:什么场景该用,什么场景别用
适合的场景
- 业务逻辑稳定、需要长期维护的 Agent 产品------领域专家能直接看 YAML 改 prompt,PR diff 一眼能看出工作流变了什么
- 需要频繁切换底层模型的场景------SWE-Bench 那个鲁棒性数据已经证明了,模型一直在升级,框架越解耦越能扛
- 多人协作开发的复杂 Agent 系统------Python 代码 review 里很难看出工作流意图,YAML 自带文档属性
- 需要可观测、可审计、可断点恢复的生产 Agent------Durability System 是真东西,长程任务跑一半挂了能续上能省命
不太适合的场景
- 强 Python 生态依赖的场景------比如要在工作流里嵌入复杂的 numpy 数据处理、调用一堆 ML 模型推理。这些用 LangGraph 写更直接,YAML 反而绕
- 超复杂的动态分支逻辑------23 人用户研究里也提到了,复杂多步场景大家更倾向 LangGraph。YAML 能表达 if/while/for_each 但更复杂的策略型分支会变得难看
- 需要细粒度并发控制的场景 ------
parallel/gather是有,但跟 Python 的 asyncio 比起来表达力差一截 - 快速 prototype 期------写 YAML、跑 Docker 沙箱、配 MCP 工具的 setup 成本不低,做 demo 阶段直接 ReAct 更快
我会重点借鉴的几个设计
就算你不打算用 AgentSPEX,下面这几个设计也值得抄到自己的 Agent 框架里:
stepvstask的显式二分------把"这一步要不要继承上下文"这件事从代码逻辑变成关键字- 层级化 step ID(
3.2.1这种)------用一套 ID 同时给日志、checkpoint、追踪用 - Selective trace replay------加载前 N 步历史,从 N+1 步开始 live 跑,省钱省时间
- workflow 即一切------skill、subagent、tool 全部用同一个抽象表达,避免重复造轮子
还没解决的问题
最后吐槽几个我觉得论文没说清楚的地方:
- YAML 的认知开销:当 workflow 嵌套深了(5+ 层),YAML 缩进会成为新的可读性灾难。论文没正面回应这个问题
- 没跟 LangGraph/CrewAI 直接对比性能:榜单都是打 CoT/ReAct,没有跟同类工作流框架在同样任务上的对比
- 形式化验证只是 toy demo:真要落到生产场景,谓词怎么定义、tool-based 校验怎么自动化,全是开放问题
- Visual editor 对超大 workflow 的扩展性:截图里的 deep_research workflow 已经看着挺挤了,再大几倍能不能用?
收尾:YAML 化 Agent 是不是趋势
整体看完这篇论文,我的态度是谨慎的乐观。
谨慎在于------它本身没有底层突破,更像是把现有方向(声明式工作流、显式 context、可视化编辑、可观测沙箱)做了一次扎实的整合实现。在评估上也有一些不太严谨的地方(CoT/ReAct 不是合适对手、用户研究样本量太小)。
乐观在于------Agent 框架"去 Python 化"这个方向我觉得是对的。GitHub Actions 当年也是从"shell 脚本 + 自定义 runner"演化到"YAML workflow + 标准化 action",最终成为 DevOps 的标配。Agent 领域大概率会走同样的路:从今天的"Python 代码 + ad-hoc Agent"演化到"YAML workflow + 标准化 harness"。
LangGraph、CrewAI 这些今天的主流框架,要么会自己把声明式层做出来,要么会被新一代框架替代。AgentSPEX 至少给出了一个看起来挺合理的设计参考,特别是 step/task 二分、selective replay、模型版本鲁棒性这几个点,值得认真琢磨。
如果你正在维护一个 LangGraph/CrewAI 写的 Agent 项目,被工作流逻辑跟代码缠绕的问题困扰过,强烈建议把这篇论文和它的开源代码拿来过一遍------就算不直接迁移,里面的几个抽象设计也能直接借鉴到你自己的项目里。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我