一、逻辑回归
1.概念
逻辑回归是一种分类模型,把线性回归的结果,作为逻辑回归的输入。逻辑回归的输出是0~1之间的值。
通常,逻辑回归用来解决二分类问题,比如预测某个人是否患病,某段话语气是否正向。
2.基础数学知识储备
- sigmoid函数
逻辑回归通过sigmoid函数,将线性回归的输出映射到(0, 1)区间的概率值,然后根据概率值进行分类预测。
sigmoid函数的公式如下,我们看一下他的图长啥样
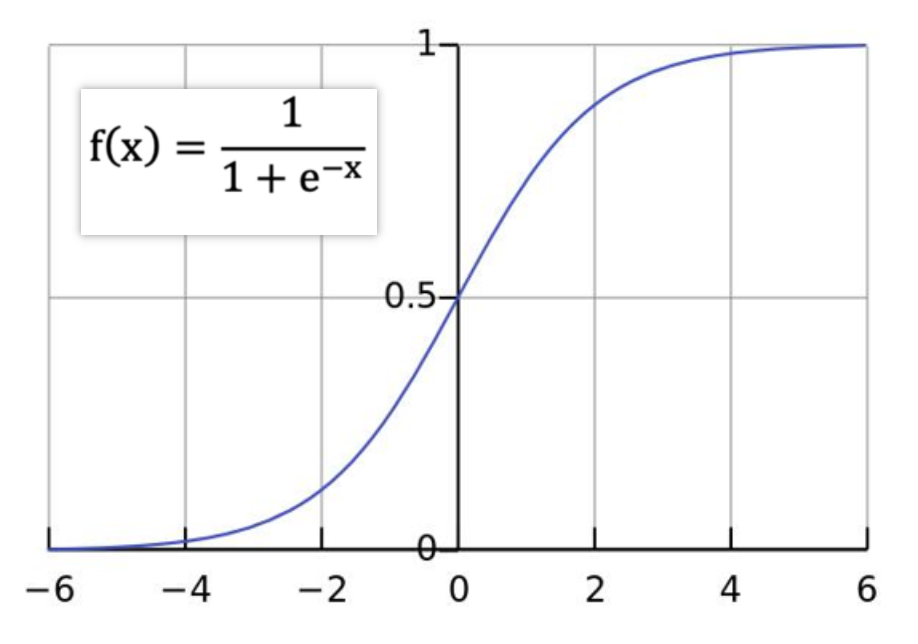
可以看到,该函数的结果永远在0~1之间。
并且,该函数有一个特点,当x的值特别小或特别大时,sigmoid函数的导数会接近于0。
- 概率
这里只对一些写法做个扫盲,避免后续看到不知道是什么意思
1)边际概率------单一事件发生的可能性,事件A发生的可能性写作:
2)联合概率------多个,独立事件同时发生的概率,事件A与事件B同时发生的概率写作:或
独立事件间,该等式成立:
3)条件概率------在事件A已发生的条件下,事件B发生的概率写作:
3.原理
- 基本思想
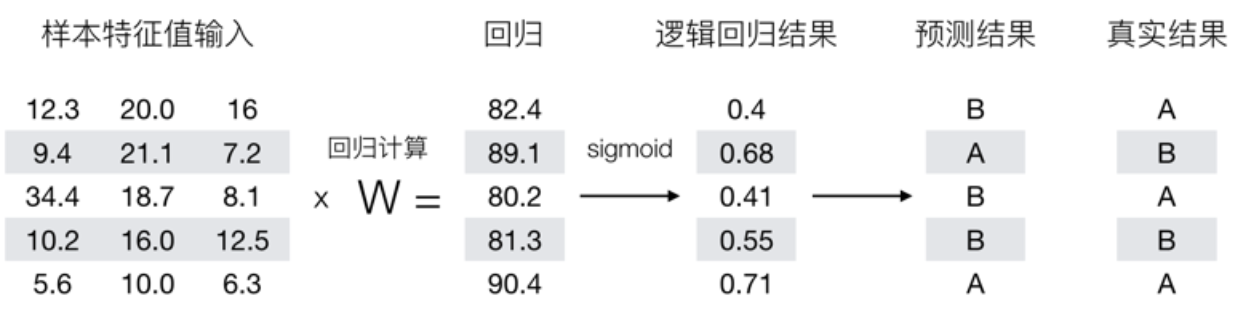
1)利用线性模型根据特征的重要性计算出一个值
2)利用sigmoid函数将f(x)的输出值映射为概率值
3)设置阈值,比如说阈值为0.6,则输出概率值大于0.6,则分类为1类,否则分类为0类。
- 损失函数
这部分不讲函数的具体推导过程,只讲逻辑关系,感兴趣的可以自行AI一下
跟线性回归类似,逻辑回归也需要有一个损失函数来收敛最终的结果。
在逻辑回归中,我们一般通过二分类交叉熵损失函数来评估模型预测值与真实值之间的差距。而二分类交叉熵损失函数又是从似然函数变换得来的。因此,我们先讲一下似然函数。
1)似然函数
假设一个场景,我们需要预测一个二分类问题,目标值分别为1和0。
当我们有60%的概率确认预测值的标签为1的时候,相对应的,我们就有40%的概率(1-0.6=0.4)确认预测值的标签为0。
把标签用k来表示,把概率用p来表示,我们可以抽象出一个函数:
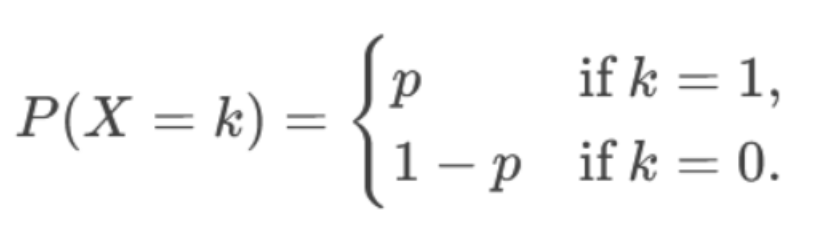
进一步,我们可以把该函数简写为以下形式
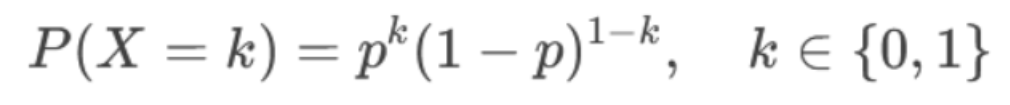
在上面的数学扫盲中,我们提到了,那么针对多个样本,他们同时被预测正确的概率,我们就可以用以下公式表示:
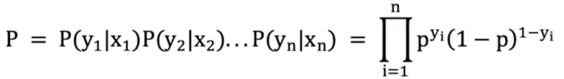
那么我们就可以把问题转化为,当联合事件概率最大时,估计w、b的权重参数,这个就是极大似然估计。
他的核心思想是,在已知观测数据的情况下,选择使得这些数据出现概率最大的参数值。
2)二分类交叉熵损失函数
二分类交叉熵损失函数就是负对数似然损失
为什么不直接使用极大似然,而是要取对数再取负呢?
因为极大似然是连乘,而连乘会导致数值下溢。
因为连乘求导麻烦。
因为大部分优化框架,如梯度下降,默认都是做最小化,而极大似然是求最大值。
为什么不跟线性回归一样都用MSE做损失函数?
假如我们使用MSE做损失函数,当我们对参数w求导,根据链式法则:
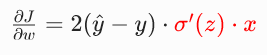
问题来了,我们上面提到过,sigmoid的导数,当z过小或过大时,他的值趋近于0.
那这就会导致,我们计算出来的梯度也跟着趋近于0,而梯度下降又是根据梯度来迭代的,我们模型的迭代就会停滞在这里,这个现象叫做梯度消失。
然而,如果使用交叉熵损失函数,就不会有这个问题,当我们对参数w求导:
综上,我们使用二分类交叉熵损失函数,他的公式如下:
sigmoid的导数被处理掉了,因此不会有上述问题
综上,二分类交叉熵损失函数就是逻辑回归的损失函数,具体公式如下:
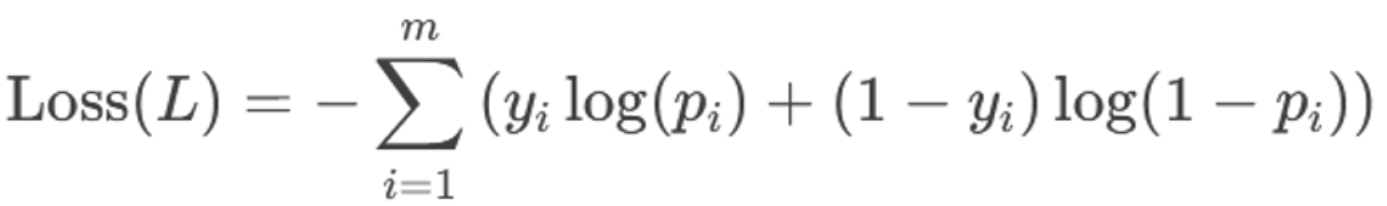
二、混淆矩阵
以下这个图就叫混淆矩阵,他表示了模型的预测值和标签的真实值的分布情况,通过这四个指标的结合,我们可以得到评估模型表现的几个指标

举个例子,已知样本一共10个,其中有6个是恶性肿瘤样本,4个是良性肿瘤样本。
模型A预测对了3个恶性肿瘤样本,4个良性肿瘤样本。
模型B预测对了6个恶性肿瘤样本,1个良性肿瘤样本。
1.准确率
准确率=预测正确的样本数量/总样本数量
在以上例子中,模型A的准确率=(3+4)/10=70%;模型B的准确率=(6+1)/10=70%
2.精确率
一个模型如果专注于精确率,则代表训练人员希望"别误杀",降低FP的占比
打个比方,比如说我们训练了一个模型识别是谁偷吃了蛋糕,并枪毙掉偷吃蛋糕的人。此时,我们自然是希望降低被模型错误的识别为偷吃蛋糕的人数的。

在以上例子中,模型A的精确率=3/(3+0)=100%;模型B的精确率=6/(6+3)=67%
3.召回率
一个模型如果专注于召回率,则代表训练人员希望"别放过",降低FN的占比
在我们这个识别肿瘤案例中,如果出现恶性肿瘤患者被误诊为良性肿瘤患者,会产生严重的问题。因此,对于解决这类问题的模型,我们自然是更希望降低真案例被识别为假案例的比例。
在该例子中,模型A的召回率=3/(3+3)=50%;模型B的召回率=6/(6+0)=100%
4.F1-score
某些场景下,我们对模型的精确率、召回率都有要求,通过F1-score分数,我们可以计算出模型在这两个方向的综合预测能力,公式为P=2*精确率*召回率/(精确率+召回率)
三、实操案例
示例数据集是一个如下样式的CSV文件,这是一个预测癌症是良性还是恶性的案例,当target为4,癌症是恶性的;当target为2,癌症是良性的。
可以去kaggle找其他数据集来练手。
|---------|----|----|----|----|----|----|----|----|----|--------|
| ID | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | TARGET |
| 1000025 | 5 | 1 | 1 | 1 | 2 | 1 | 3 | 1 | 1 | 2 |
| 1002945 | 5 | 4 | 4 | 5 | 7 | 10 | 3 | 2 | 1 | 2 |
| 1017122 | 8 | 10 | 10 | 8 | 7 | 10 | 9 | 7 | 1 | 4 |
python
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
import pandas as pd
# 1 获取数据
dataset = pd.read_csv("dataset.csv")
# 2 数据预处理
# 缺失值处理
dataset.replace("?", np.nan, inplace=True)
dataset.dropna(inplace=True)
# 提取特征与标签
x_data = dataset.iloc[:, 1:-1]
y_data = dataset.iloc[:, -1]
y_data[y_data == 4] = 1
y_data[y_data == 2] = 0
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size = 0.2, random_state = 5)
# 3 特征工程
# 标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4 模型选择
estimator_lr = LogisticRegression()
# 5 模型训练
estimator_lr.fit(x_train, y_train)
# 6 模型评估
# 6-1 一步评估准确率
print("准确率", estimator_lr.score(x_test, y_test))
# 6-2 手动评估准确率
y_predict = estimator_lr.predict(x_test)
print("准确率", accuracy_score(y_test, y_predict))
# 6-3 手动评估精确率
print("精确率", precision_score(y_test, y_predict))
# 6-4手动评估召回率
print("召回率", recall_score(y_test, y_predict))
# 6-5 手动评估f1-score
print("f1-score", f1_score(y_test, y_predict))
# 6-6 混淆矩阵
print(confusion_matrix(y_test, y_predict, labels=[1, 0]))
# 6-7 分类评估报告
print(classification_report(y_test, y_predict))