
💎【行业认证·权威头衔】
✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家
✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主
✔ 技术生态共建先锋:横跨鸿蒙、云计算、AI等前沿领域的技术布道者
🏆【荣誉殿堂】
🎖 连续三年蝉联"华为云十佳博主"(2022-2024)
🎖 双冠加冕CSDN"年度博客之星TOP2"(2022&2023)
🎖 十余个技术社区年度杰出贡献奖得主
📚【知识宝库】
覆盖全栈技术矩阵:
◾ 编程语言:.NET/Java/Python/Go/Node...
◾ 移动生态:HarmonyOS/iOS/Android/小程序
◾ 前沿领域:物联网/网络安全/大数据/AI/元宇宙
◾ 游戏开发:Unity3D引擎深度解析
文章目录
- 🚀前言
- 🚀一、AI漫剧视频生成工具
-
- 🔎1.漫剧AI视频生成工具推荐
-
- [🦋1. Vidu AI:漫剧角色的"御用演员"](#🦋1. Vidu AI:漫剧角色的“御用演员”)
- [🦋2. 即梦AI:漫剧画面的"还原大师"](#🦋2. 即梦AI:漫剧画面的“还原大师”)
- [🦋3. 可灵AI:漫剧世界的"特技演员"](#🦋3. 可灵AI:漫剧世界的“特技演员”)
- [🔎2.Vidu AI界面功能及使用要点](#🔎2.Vidu AI界面功能及使用要点)
-
- [🦋1. Vidu AI界面介绍](#🦋1. Vidu AI界面介绍)
- [🦋2. 图片选取要点](#🦋2. 图片选取要点)
- [🦋3. 其他参数设置要点](#🦋3. 其他参数设置要点)
- [🦋4. 提示词设计要点](#🦋4. 提示词设计要点)
- 🚀附:AI提示词模板与完整回答示例
-
- [🔎模板:Vidu AI视频生成提示词(图生视频)](#🔎模板:Vidu AI视频生成提示词(图生视频))
- 🔎完整回答示例(用户需求:二次元漫剧战斗分镜)
🚀前言
在前面的章节中,我们已经完成了AI 漫剧从构思、分镜、画风设定到图像 生成与精修的完整流程。至此,我们已经积累了足以支撑成片的高质量画面素 材。但漫剧之所以被称为"剧",核心就在于它打破了漫画的静态表达。
在短视频平台上,观众的注意力窗口通常只有前3秒。仅凭精美的静态图轮 播,很难在信息流里实现有效留存。只有当画面有了呼吸感、镜头有了推拉摇移 的节奏、角色有了细腻的微表情,故事的情绪张力才会真正爆发。
本章的核心任务,就是跨越"动效"这道门槛。我们将重心从图像转向视频, 重点解决以下问题:如何让画面自然动起来,如何让镜头运动更稳定、如何把握 节奏更精准,以及如何选择最适配的工具链,把我们积累的视觉素材最终制作成 一部具备完整观感的成熟漫剧。
🚀一、AI漫剧视频生成工具
目前,AI视频生成领域正处于爆发期,AI视频工具层出不穷。根据国内外市场表现,目前主流的视频生成工具如表6-1所示。
| 工具名称 | 开发公司 | 核心优势 | 适配场景 |
|---|---|---|---|
| Vidu AI | 生数科技 | 动态感强,保留原画张力;Q1/Q2模型可控制面部和服装一致性;支持微表情 | 二次元漫剧、连载剧 |
| 即梦AI | 字节跳动 | 语义理解精准,可执行复杂动作;S3.0模型可保留原画风格 | 绘本风、水墨风、强风格化漫剧 |
| 可灵AI | 快手 | 模型推理能力强;物理逻辑稳定;自动生成环境音效 | 长镜头、特效场景 |
| Runway | Runway Research | 支持文本驱动动画、实时编辑;与第三方软件兼容 | 多风格动画/视频 |
| Sora | OpenAI | 生成高保真、长时长、场景连贯的视频;理解复杂物理规律与真实世界动态 | 全场景、高真实感视频、剧情短片 |
🔎1.漫剧AI视频生成工具推荐
从全球视野来看,以Sora、Runway为代表的国际梯队,在通用场景动态生成、技术迭代速度上有一定优势;而国产AI视频工具如Vidu AI、即梦AI、可灵AI,则在中文语境理解、角色一致性控制以及动漫风适配上表现得更为惊艳,更贴合国内创作者需求,可作为我们制作漫剧时的三大核心工具。
🦋1. Vidu AI:漫剧角色的"御用演员"
如果制作的是二次元风格 或CG风格的漫剧,Vidu AI是首选工具。
在早期测试中我们发现,多数AI视频工具在处理动漫形象时极易出现 "写实化"偏差 ,会让原本帅气的纸片人动起来后带有诡异的真人质感,在漫剧呈现中十分出戏。而Vidu AI的核心优势正是极强的二次元动态适配能力,能完好保留原画的视觉张力与线条质感,不会强行篡改原有画风。
更关键的是,它在角色一致性 上的表现十分稳定。漫剧创作最忌讳角色一动就"变脸",Vidu AI的Q1/Q2模型对角色面部与服饰的把控力极强,能保障在十几集乃至几十集的长篇连载中,主角始终保持观众熟悉的形象。
Q2模型亮点:支持精细化微表情处理,可实现细腻的眼神流转、嘴角微动等效果。这是当下漫剧摆脱角色"面瘫"问题的核心要点。在实战创作中,当剧情推进至情感爆发节点,哪怕只是眼眶微红或是轻蔑一笑,传递出的叙事张力都远胜一段复杂的打斗戏份。
🦋2. 即梦AI:漫剧画面的"还原大师"
如果说Vidu AI擅长"演",那即梦AI更擅长"不乱改",即梦因此又称为 "还原大师"。
即梦AI对指令的理解非常精准 ,对于"一边跑一边回头"这类复合动作,完成度往往比较高。更难得的是,在图生视频过程中,它对原画风格的干预很克制。在漫剧制作中,我们经常会遇到一些构图非常复杂的静态原画,如多人物重叠、特定的透视角度或是极端的冷暖对比光影。很多视频工具在让这类图片动起来的同时,会破坏原有的艺术氛围,但即梦能较好地保持原画的构图和神韵。
它仅在静态画面基础上增加动态效果,不会随意修改原画的光影层次、笔触质感。这也是为什么在绘本风、水墨风、古风这类强风格漫剧中,即梦AI往往是更稳妥的选择。
🦋3. 可灵AI:漫剧世界的"特技演员"
可灵AI出自快手团队,它在发布之初就凭借生成画面中包含大幅度动作惊艳了整个行业。
在漫剧制作中,通常把可灵AI作为 "特技演员" 来使用。如果剧本里有大量的肢体互动(如两个角色握手、拥抱)、复杂的物理碰撞,或者是需要那种电影级长焦推拉运镜,可灵的表现会非常稳健。可灵的01模型对物理逻辑的处理能力较强,在魔法破碎、能量扩散、流体效果等特效场景中,往往更符合直觉。
在大场景、空镜头或长镜头中,它的稳定性优势会更加明显。画面主体结构不容易出现失真,空间关系也相对合理。
综合建议 :这三款工具并不存在简单的替代关系,而是各自承担着不同角色。如果从稳定性、成本和适配度等方面综合考量,Vidu AI依然是最通用的选择。因此,接下来将以Vidu AI为核心,详细讲解如何将分镜一步步转换为视频。
🔎2.Vidu AI界面功能及使用要点
工欲善其事,必先利其器。在正式开始实际操作之前,需要首先熟悉Vidu AI的界面。只有清楚了解界面上的主要功能,才能灵活地使用Vidu AI工具,避免因功能遗漏或操作失误影响生成效果。
🦋1. Vidu AI界面介绍
整体来看,Vidu AI的操作界面结构清晰,功能分区明确,新手也可以快速上手。登录Vidu AI后,其主界面大致可以分为4个区域 (如图所示):
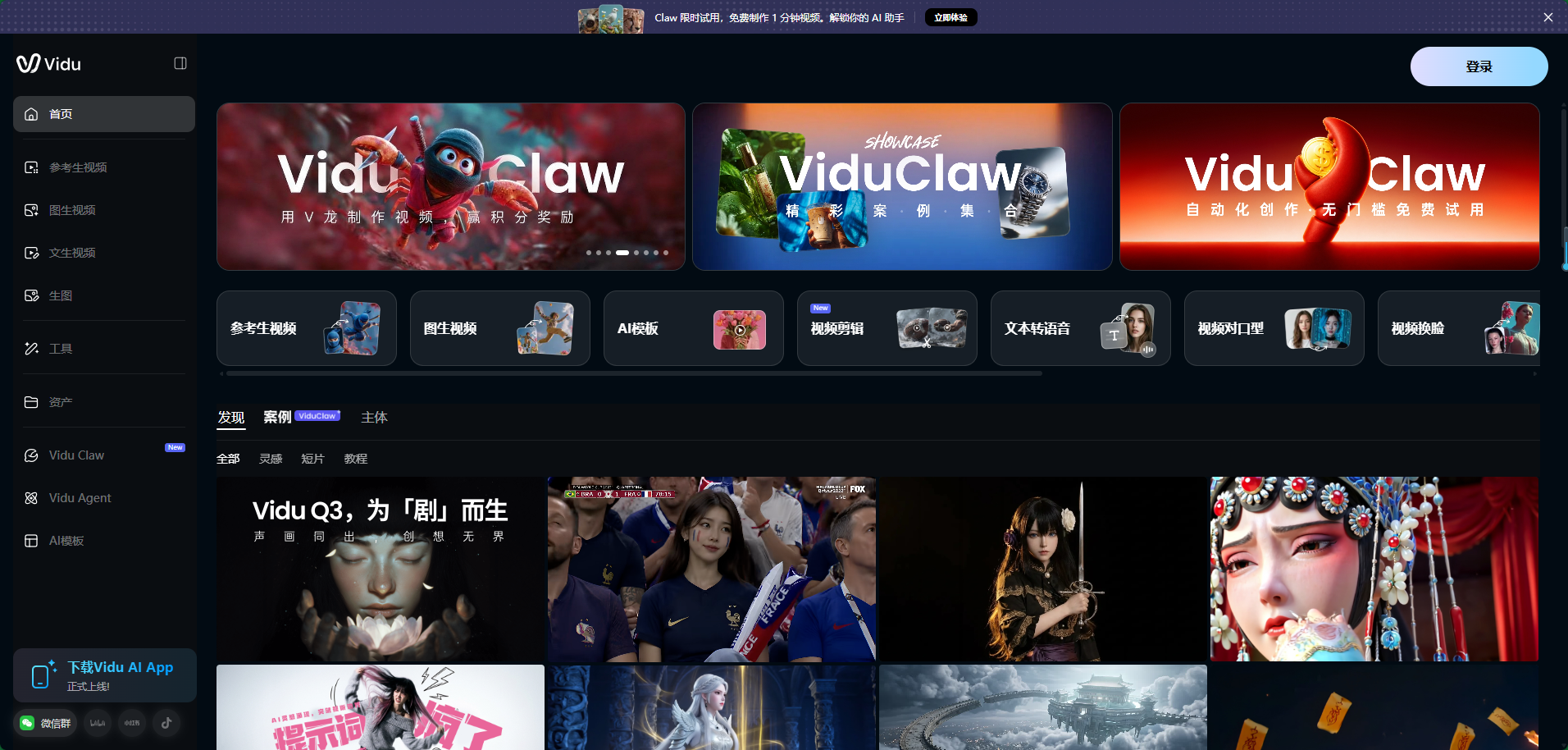
| 区域 | 位置 | 功能说明 | 漫剧创作相关操作 |
|---|---|---|---|
| 功能导航栏 | 左侧 | 选择生成方式和查看历史任务 | 常用"参考生视频""图生视频";"主体库"上传角色三视图,创建主体角色(图) |
| 核心功能区 | 顶端 | AI视频生成的主要创作入口 | "图生视频"上传静态分镜图转视频;"参考生视频"通过参考视频引导运动节奏 |
| AI模板区 | 中部/右侧 | 集成现成视频模板 | 可套用节日、趣味等模板快速出片 |
| 学习与灵感区 | 底部/侧边 | 热门作品、教程、直播 | 获取创作灵感,提升创作能力 |
实操建议:先花一点时间熟悉这4个区域的分工,再进入具体生成流程,大大降低试错成本。
🦋2. 图片选取要点
在Vidu AI的图生视频流程中,输入图片的质量,几乎决定了视频效果的上限 。为了确保生成的视频符合预期,在选取图片时需要注意以下4点:
| 要点 | 要求 | 原因 |
|---|---|---|
| 图片尺寸 | 宽高保持在1024~2048像素 | 平衡画质与效率;过小则粗糙,过大触发压缩丢细节 |
| 图片比例一致性 | 图片比例与目标视频比例一致(如16:9) | 避免AI裁切或拉伸破坏构图 |
| 图片清晰度 | 必须清晰,无模糊 | AI基于原图像素"运动推演",模糊底图导致视频质量差 |
| 主题内容明确 | 构图合理、主体突出,避免杂乱 | 帮助AI准确理解"谁该动、往哪动" |
总结 :适合用于视频生成的分镜图,应该尺寸合适、比例一致、画面清晰、主体明确。把控好这一关,后续生成过程会顺畅很多。
🦋3. 其他参数设置要点
掌握了底图选取的要点,接下来的关键就是通过参数调节来给AI"定规矩"。
模型选择 :Vidu AI提供多个版本模型,推荐使用最新的Q1、Q2模型(如图所示)。
- Q1模型:更偏基础稳定,适合普通动作或远景镜头
- Q2模型:表情和细节更细腻,适合特写镜头或情绪表达较强的画面
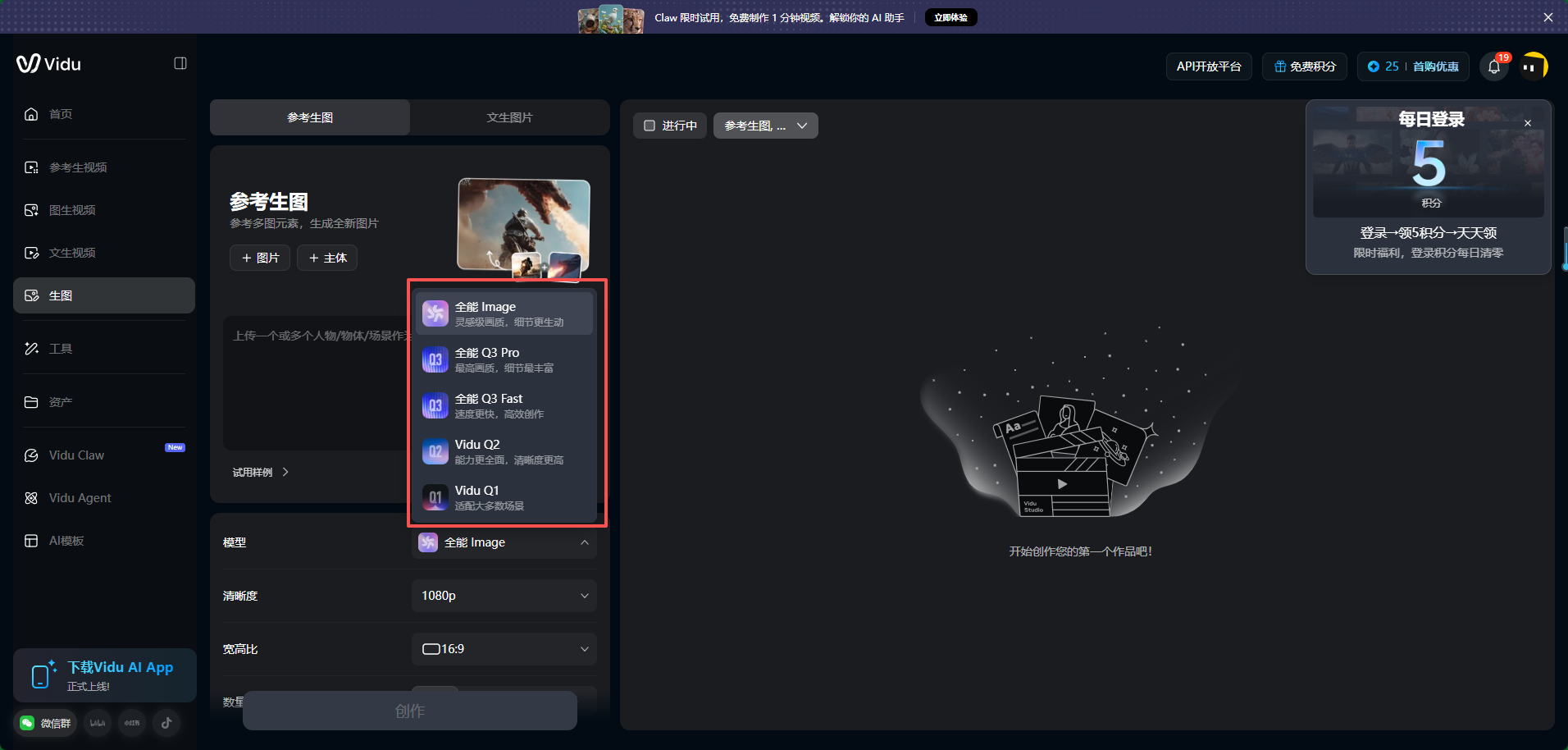
可根据分镜的重要程度进行区分,而不是全程只用一个模型。
时长取舍:Vidu AI支持生成2~8秒的视频(如图所示)。
- 4秒视频:性价比最高,生成速度快且最易受控
- 8秒视频:提供更长叙事空间,但稳定性下降,出错概率增加
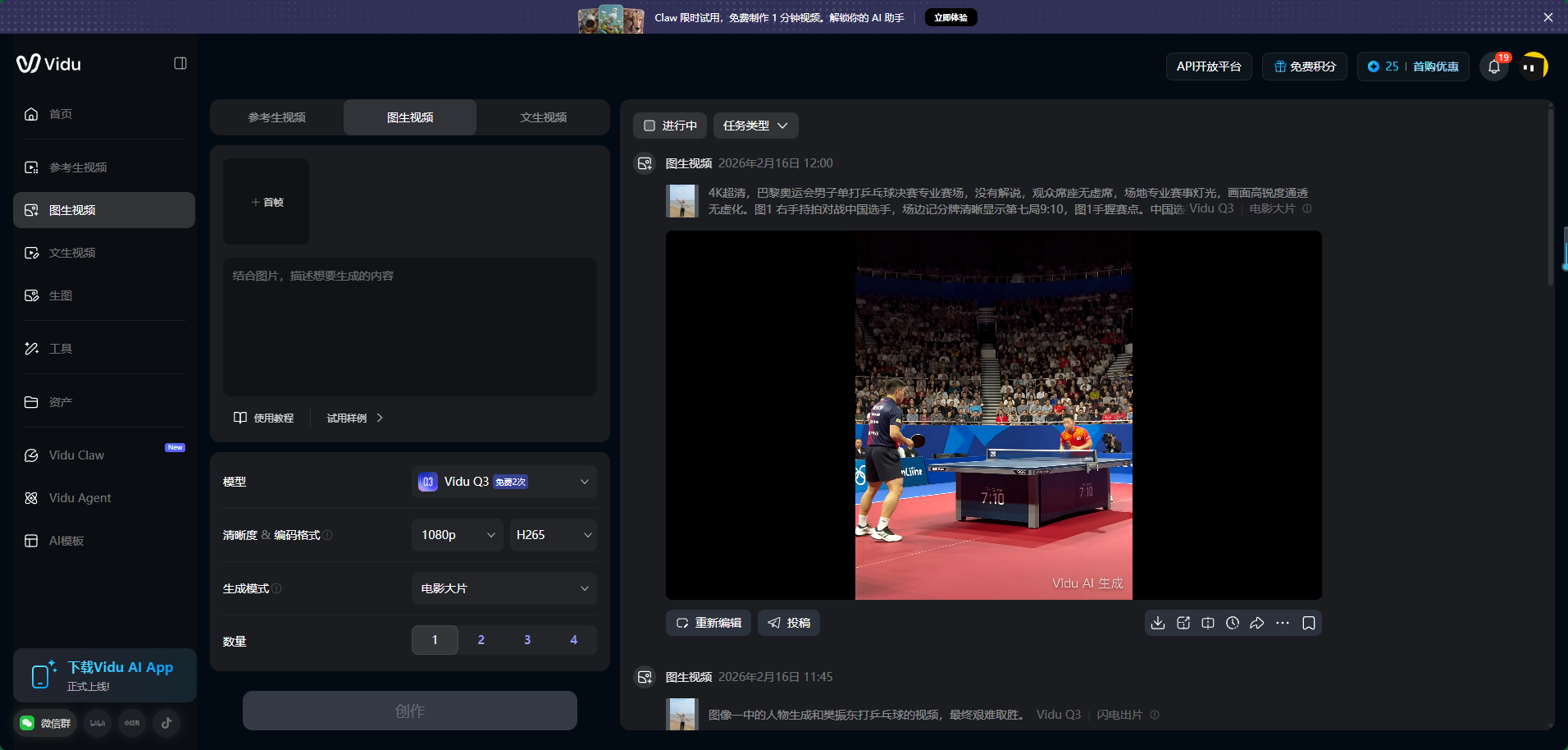
建议:初学者先从4秒练手,提示词掌控力提升后再挑战8秒长镜头。
运动幅度调校:此参数直接控制画面中动作的剧烈程度。
- 大运动幅度:适用于快速奔跑、激烈打斗等爆发力场面
- 小运动幅度:适用于静静思考、微弱呼吸、嘴角含笑等细腻"文戏"
动态调整:没有"标准答案"。先使用默认值生成样片,动作太僵硬就调大,角色变形就调小。
🦋4. 提示词设计要点
提示词设计是创作者与AI沟通的专属语言。一个结构清晰、描述具体的提示词,能极大地提高AI的理解与执行效率。Vidu AI作为国产大模型的代表之一,对中文提示词的理解往往更具神韵,尤其在处理古风或中式意境时,中文表达比英文更精准。
| 要点 | 说明 | 示例 |
|---|---|---|
| 字数控制 | 建议50~200字,给AI留出想象空间 | 不冗长也不过于简略 |
| 结构逻辑 | "主体 + 动作 + 运镜 + 环境" | "一个白发剑客,缓缓睁开眼,镜头缓慢推向面部特写,背景是飘落的樱花" |
| 描述具体 | 避免抽象词,用可视觉化的细节 | ❌"一个好看的女孩" → ✅"一个穿着白色连衣裙的长发女孩,面带微笑" |
核心原则:提示词越具体、动作指向越明确,生成效果越符合预期。
🚀附:AI提示词模板与完整回答示例
以下提供一个Vidu AI视频生成提示词模板,涵盖图生视频的完整参数设置,并附上基于实际需求的完整回答示例。
🔎模板:Vidu AI视频生成提示词(图生视频)
【任务】使用Vidu AI将静态分镜图转换为动态视频。
【输入】
- 分镜图:[上传图片,要求尺寸1024-2048,比例与输出一致,清晰,主体明确]
- 模型选择:[Q1 / Q2]
- 视频时长:[2-8秒,推荐4秒]
- 运动幅度:[大/中/小]
【提示词结构】(50-200字,遵循"主体+动作+运镜+环境"逻辑)
[主体描述] + [具体动作] + [镜头运动] + [环境/氛围]
【输出要求】输出一段完整的提示词(中文),并附上参数设置建议。🔎完整回答示例(用户需求:二次元漫剧战斗分镜)
用户输入:
分镜图:一名银发少年剑客,身穿黑色战斗服,手持发光蓝色长剑,站在破败的赛博朋克天台上,背后是霓虹灯光。需要生成4秒视频,动作:缓缓举起剑,目光凝视前方。运镜:镜头从脚下缓缓上摇到面部。环境:雨夜,有雨滴和雾气。
AI回答(完整提示词 + 参数设置):
🦋提示词正文(可直接复制)
银发少年剑客,黑色战斗服,右手缓缓举起发光的蓝色长剑,剑尖指向天空,目光坚定凝视前方。镜头从脚下开始缓慢上摇,经过身体最终定格在面部特写。背景是赛博朋克天台,霓虹灯光在雨夜中闪烁,雨滴飘落,地面有积水反射光芒,雾气弥漫。氛围紧张而肃杀。🦋参数设置建议
| 参数 | 推荐值 |
|---|---|
| 模型 | Q2(需要微表情和细节,适合特写感镜头) |
| 视频时长 | 4秒 |
| 运动幅度 | 中(举剑动作属于中幅运动) |
| 比例 | 与分镜图一致(如9:16或16:9) |
🦋生成后优化建议
- 如果动作速度不理想,可在下次生成时调整提示词加入"缓慢""加速"等修饰。
- 检查雨滴和环境光是否与角色阴影匹配,若不匹配合成后期微调。
- 如需更长的持剑凝视镜头,可尝试5-6秒,但注意稳定性。