1. sizeof和strlen的对比
1.1 sizeof
在学习操作符的时候,我们学习了 sizeof。sizeof 计算变量所占内存空间大小的,单位是字节。如果操作数是类型的话,计算的是使用类型创建的变量所占内存空间的大小。
重点: sizeof 只关注占用内存空间的大小,不在乎内存中存放什么数据。
#include <stdio.h>
int main() {
int a = 10;
char arr[] = "hello";
printf("sizeof(a) = %zu\n", sizeof(a)); // 输出 4(int占4字节)
printf("sizeof(int) = %zu\n", sizeof(int)); // 输出 4
printf("sizeof(arr) = %zu\n", sizeof(arr)); // 输出 6(包含'\0')
printf("sizeof(\"hello\") = %zu\n", sizeof("hello")); // 输出 6
return 0;
}
注意:sizeof 是操作符,不是函数,编译时就已经确定结果,不需要包含头文件。
1.2 strlen
strlen 是C语言库函数,功能是求字符串长度。统计的是从 strlen 函数的参数 str 中这个地址开始向后,\0 之前字符串中字符的个数。
重点: strlen 函数会一直向后找 \0 字符,直到找到为止,所以可能存在越界查找。
#include <stdio.h>
#include <string.h> // 使用strlen需要包含此头文件
int main() {
char arr1[] = "hello";
char arr2[] = {'h', 'e', 'l', 'l', 'o'}; // 没有'\0'
printf("strlen(arr1) = %zu\n", strlen(arr1)); // 输出 5
printf("strlen(arr2) = %zu\n", strlen(arr2)); // 随机值!因为没有'\0',会越界查找
return 0;
}
注意:strlen 是库函数 ,使用需要包含头文件 <string.h>。它关注内存中是否有 \0,如果没有 \0,就会持续往后找,可能会越界。
1.3 sizeof 和 strlen 的对比
| 对比项 |
sizeof |
strlen |
| 本质 |
操作符 |
库函数,使用需要包含头文件 <string.h> |
| 作用 |
计算操作数所占内存的大小,单位是字节 |
求字符串长度,统计 \0 之前字符的个数 |
| 关注点 |
不关注内存中存放什么数据 |
关注内存中是否有 \0,如果没有 \0,就会持续往后找,可能会越界 |
| 计算时机 |
编译时确定 |
运行时计算 |
| 单位 |
字节 |
字符个数(无单位) |
#include <stdio.h>
#include <string.h>
int main() {
char str[] = "Hello";
// sizeof 计算数组总大小(包含'\0')
printf("sizeof(str) = %zu\n", sizeof(str)); // 输出 6('H','e','l','l','o','\0')
// strlen 计算字符串长度(不包含'\0')
printf("strlen(str) = %zu\n", strlen(str)); // 输出 5
// 关键区别演示
char arr[] = {'a', 'b', 'c'}; // 没有'\0'
printf("sizeof(arr) = %zu\n", sizeof(arr)); // 输出 3(只关心内存大小)
printf("strlen(arr) = %zu\n", strlen(arr)); // 随机值!越界查找
return 0;
}
总结:
sizeof 是编译时操作符,计算内存大小,不关心数据内容。strlen 是运行时库函数,计算字符串长度,依赖 \0 作为结束标志,可能越界。
2. 数组和指针笔试题解析
数组名的意义(核心规则)
在C语言中,数组名在绝大多数情况下表示首元素的地址,但有两个例外:
sizeof(数组名) --- 这里的数组名表示整个数组,计算的是整个数组的大小。&数组名 --- 这里的数组名表示整个数组,取出的是整个数组的地址。- 除此之外所有的数组名都表示首元素的地址。
牢记这三条规则,是解所有数组笔试题的关键!
2.1 一维数组
int main()
{
int a[] = { 1,2,3,4 };
printf("%zu\n", sizeof(a));// 4*4 = 16
// sizeof(数组名) --- 数组名单独放在sizeof内部,表示整个数组,4个int = 16字节
printf("%zu\n", sizeof(a + 0));// 4/8
// a没有单独放在sizeof里面,表示首元素地址,a+0还是首元素地址,地址大小4/8字节
printf("%zu\n", sizeof(*a));// 4
// a没有单独放在sizeof里面,也没有&,表示首元素地址,*a解引用得到首元素a[0],大小为4字节
printf("%zu\n", sizeof(a + 1));// 4/8
// a没有单独放在sizeof里面,也没有&,表示首元素地址,a+1是第二个元素的地址,地址大小4/8字节
printf("%zu\n", sizeof(a[1]));// 4
// a[1]是下标为1的元素(值为2),int类型占4字节
printf("%zu\n", sizeof(&a));// 4/8
// &a表示整个数组的地址,虽然类型是int(*)[4],但地址的大小始终是4/8字节
printf("%zu\n", sizeof(*&a));// 16
// &a取出整个数组的地址,*&a解引用得到整个数组a,等价于sizeof(a),16字节
printf("%zu\n", sizeof(&a + 1));// 4/8
// &a + 1跳过整个数组(16字节),但结果仍然是地址,地址大小4/8字节
printf("%zu\n", sizeof(&a[0]));// 4/8
// &a[0]取出首元素的地址,地址大小4/8字节
printf("%zu\n", sizeof(&a[0] + 1));// 4/8
// &a[0] + 1是第二个元素的地址,地址大小4/8字节
return 0;
}
2.1 一维数组总结表
| 表达式 |
含义 |
结果(32位/64位) |
解释 |
sizeof(a) |
整个数组大小 |
16 |
sizeof(数组名),数组名代表整个数组 |
sizeof(a+0) |
首元素地址大小 |
4/8 |
a不是单独在sizeof中,表示首元素地址 |
sizeof(*a) |
首元素大小 |
4 |
*a 等价于 a[0],int类型 |
sizeof(a+1) |
第二个元素地址大小 |
4/8 |
a+1是&a1,地址 |
sizeof(a[1]) |
第二个元素大小 |
4 |
a1是int类型 |
sizeof(&a) |
整个数组的地址大小 |
4/8 |
&a取出地址,地址大小固定 |
sizeof(*&a) |
整个数组大小 |
16 |
*&a 等价于 a |
sizeof(&a+1) |
跳过整个数组后的地址大小 |
4/8 |
仍然是地址 |
sizeof(&a[0]) |
首元素地址大小 |
4/8 |
取出首元素地址 |
sizeof(&a[0]+1) |
第二个元素地址大小 |
4/8 |
地址+1 |
2.2 字符数组
代码1:sizeof 与字符数组(无\0)
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
// 注意:这个数组没有'\0',只有6个字符
printf("%zu\n", sizeof(arr));// 6
// sizeof(数组名) --- 整个数组大小,6个char = 6字节
printf("%zu\n", sizeof(arr + 0));// 4/8
// arr不是单独在sizeof中,表示首元素地址,arr+0还是首元素地址
printf("%zu\n", sizeof(*arr));// 1
// *arr解引用得到首元素'a',char类型占1字节
printf("%zu\n", sizeof(arr[1]));// 1
// arr[1]是'b',char类型占1字节
printf("%zu\n", sizeof(&arr));// 4/8
// &arr取出整个数组的地址,类型char(*)[6],地址大小4/8字节
printf("%zu\n", sizeof(&arr + 1));// 4/8
// &arr+1跳过整个数组(6字节),仍然是地址
printf("%zu\n", sizeof(&arr[0] + 1));// 4/8
// &arr[0]+1是第二个元素'b'的地址
return 0;
}
代码1 总结表
| 表达式 |
结果(32位/64位) |
解释 |
sizeof(arr) |
6 |
sizeof(数组名),整个数组大小 |
sizeof(arr+0) |
4/8 |
首元素地址 |
sizeof(*arr) |
1 |
首元素'a'的大小 |
sizeof(arr[1]) |
1 |
第二个元素'b'的大小 |
sizeof(&arr) |
4/8 |
整个数组的地址 |
sizeof(&arr+1) |
4/8 |
跳过整个数组后的地址 |
sizeof(&arr[0]+1) |
4/8 |
第二个元素的地址 |
代码2:strlen 与字符数组(无\0)
#include <string.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
// 这个数组没有'\0',strlen会一直向后找直到遇到'\0',结果未知
printf("%zu\n", strlen(arr));// 未知数
// arr是首元素地址,从'a'开始向后找'\0',由于没有'\0',会越界查找,结果随机
printf("%zu\n", strlen(arr + 0));// 未知数
// arr+0还是首元素地址,结果同上
printf("%zu\n", strlen(*arr));// 程序会崩溃
// *arr == arr[0] == 'a' == 97(ASCII码)
// strlen把97当作地址去访问,这是非法地址,程序崩溃
printf("%zu\n", strlen(arr[1]));// 程序会崩溃
// arr[1] == 'b' == 98,同样把98当作地址访问,程序崩溃
printf("%zu\n", strlen(&arr));// 未知数
// &arr是整个数组的地址,虽然地址值相同,但类型不同,从该地址开始找'\0',结果随机
printf("%zu\n", strlen(&arr + 1));// 未知数
// &arr+1跳过整个数组(6字节),从数组后面开始找'\0',结果随机
printf("%zu\n", strlen(&arr[0] + 1));// 未知数
// &arr[0]+1是'b'的地址,从'b'开始找'\0',结果随机
return 0;
}
代码2 总结表
| 表达式 |
结果 |
解释 |
strlen(arr) |
随机值 |
数组无\0,越界查找 |
strlen(arr+0) |
随机值 |
同上 |
strlen(*arr) |
崩溃 |
把字符'a'(97)当作地址访问 |
strlen(arr[1]) |
崩溃 |
把字符'b'(98)当作地址访问 |
strlen(&arr) |
随机值 |
从数组起始地址开始找\0 |
strlen(&arr+1) |
随机值 |
跳过数组后开始找\0 |
strlen(&arr[0]+1) |
随机值 |
从'b'开始找\0 |
代码3:sizeof 与字符串初始化的字符数组
int main()
{
char arr[] = "abcdef";
// 字符串初始化,实际包含7个字符:'a','b','c','d','e','f','\0'
printf("%zu\n", sizeof(arr));// 7
// sizeof(数组名) --- 整个数组大小,包含'\0',7字节
printf("%zu\n", sizeof(arr + 0));// 4/8
// arr不是单独在sizeof中,表示首元素地址
printf("%zu\n", sizeof(*arr));// 1
// *arr == arr[0] == 'a',char类型1字节
printf("%zu\n", sizeof(arr[1]));// 1
// arr[1] == 'b',char类型1字节
printf("%zu\n", sizeof(&arr));// 4/8
// &arr取出整个数组的地址
printf("%zu\n", sizeof(&arr + 1));// 4/8
// &arr+1跳过整个数组(7字节),仍然是地址
printf("%zu\n", sizeof(&arr[0] + 1));// 4/8
// &arr[0]+1是'b'的地址
return 0;
}
代码3 总结表
| 表达式 |
结果(32位/64位) |
解释 |
sizeof(arr) |
7 |
整个数组大小,包含\0 |
sizeof(arr+0) |
4/8 |
首元素地址 |
sizeof(*arr) |
1 |
首元素'a'的大小 |
sizeof(arr[1]) |
1 |
第二个元素'b'的大小 |
sizeof(&arr) |
4/8 |
整个数组的地址 |
sizeof(&arr+1) |
4/8 |
跳过整个数组后的地址 |
sizeof(&arr[0]+1) |
4/8 |
第二个元素的地址 |
代码4:strlen 与字符串初始化的字符数组
#include <string.h>
int main()
{
char arr[] = "abcdef";
// 数组内容:'a','b','c','d','e','f','\0'
printf("%zu\n", strlen(arr));// 6
// arr是首元素地址,从'a'开始找'\0',到第7个字符找到,长度为6
printf("%zu\n", strlen(arr + 0));// 6
// arr+0还是首元素地址,结果同上
printf("%zu\n", strlen(*arr));// 程序会崩溃
// *arr == 'a' == 97,把97当作地址访问,崩溃
printf("%zu\n", strlen(arr[1]));// 程序会崩溃
// arr[1] == 'b' == 98,把98当作地址访问,崩溃
printf("%zu\n", strlen(&arr));// 6
// &arr是整个数组的地址,虽然类型不同但地址值相同,从'a'开始找'\0',长度为6
printf("%zu\n", strlen(&arr + 1));// 未知数
// &arr+1跳过整个数组(7字节),从数组后面开始找'\0',结果随机
printf("%zu\n", strlen(&arr[0] + 1));// 5
// &arr[0]+1是'b'的地址,从'b'开始找'\0',长度为5(b,c,d,e,f)
return 0;
}
代码4 总结表
| 表达式 |
结果 |
解释 |
strlen(arr) |
6 |
从'a'到\0共6个字符 |
strlen(arr+0) |
6 |
同上 |
strlen(*arr) |
崩溃 |
把字符'a'(97)当作地址 |
strlen(arr[1]) |
崩溃 |
把字符'b'(98)当作地址 |
strlen(&arr) |
6 |
地址值相同,从'a'开始 |
strlen(&arr+1) |
随机值 |
跳过数组后找\0 |
strlen(&arr[0]+1) |
5 |
从'b'开始,到\0共5个 |
代码5:sizeof 与指针指向字符串常量
int main()
{
char* p = "abcdef";
// p是指针变量,指向字符串常量"abcdef"的首字符'a'
printf("%zu\n", sizeof(p));// 4/8
// p是指针变量,指针变量的大小就是4/8字节
printf("%zu\n", sizeof(p + 1));// 4/8
// p+1是'b'的地址,地址大小4/8字节
printf("%zu\n", sizeof(*p));// 1
// *p解引用得到'a',char类型占1字节
printf("%zu\n", sizeof(p[0]));// 1
// p[0] == *(p+0) == 'a',char类型占1字节
printf("%zu\n", sizeof(&p));// 4/8
// &p取出指针变量p本身的地址,地址大小4/8字节
printf("%zu\n", sizeof(&p + 1));// 4/8
// &p+1跳过指针变量p(4/8字节),仍然是地址
printf("%zu\n", sizeof(&p[0] + 1));// 4/8
// &p[0]+1是'b'的地址
return 0;
}
代码5 总结表
| 表达式 |
结果(32位/64位) |
解释 |
sizeof(p) |
4/8 |
指针变量本身的大小 |
sizeof(p+1) |
4/8 |
'b'的地址 |
sizeof(*p) |
1 |
解引用得到'a',char类型 |
sizeof(p[0]) |
1 |
p[0]等价于*(p+0),即'a' |
sizeof(&p) |
4/8 |
指针变量p的地址 |
sizeof(&p+1) |
4/8 |
跳过指针变量p后的地址 |
sizeof(&p[0]+1) |
4/8 |
'b'的地址 |
代码6:strlen 与指针指向字符串常量
#include <string.h>
int main()
{
char* p = "abcdef";
// p指向字符串常量"abcdef",该字符串末尾有'\0'
printf("%zu\n", strlen(p));// 6
// p指向'a',从'a'开始找'\0',长度为6
printf("%zu\n", strlen(p + 1));// 5
// p+1指向'b',从'b'开始找'\0',长度为5(b,c,d,e,f)
printf("%zu\n", strlen(*p));// 程序崩溃
// *p == 'a' == 97,把97当作地址访问,崩溃
printf("%zu\n", strlen(p[0]));// 程序崩溃
// p[0] == 'a' == 97,同上,崩溃
printf("%zu\n", strlen(&p));// 未知数
// &p取出指针变量p本身的地址,从该地址开始找'\0',结果随机
printf("%zu\n", strlen(&p + 1));// 未知数
// &p+1跳过指针变量p,从后面开始找'\0',结果随机
printf("%zu\n", strlen(&p[0] + 1));// 5
// &p[0]+1是'b'的地址,从'b'开始找'\0',长度为5
return 0;
}
代码6 总结表
| 表达式 |
结果 |
解释 |
strlen(p) |
6 |
从'a'到\0共6个字符 |
strlen(p+1) |
5 |
从'b'到\0共5个字符 |
strlen(*p) |
崩溃 |
把字符'a'(97)当作地址 |
strlen(p[0]) |
崩溃 |
把字符'a'(97)当作地址 |
strlen(&p) |
随机值 |
从指针变量p的地址开始找\0 |
strlen(&p+1) |
随机值 |
跳过指针变量p后找\0 |
strlen(&p[0]+1) |
5 |
从'b'开始,到\0共5个 |
2.3 二维数组
二维数组在内存中是按行连续存储的,可以看作是一维数组的数组。理解二维数组的数组名意义,关键在于区分行地址 和行首元素地址。
int main()
{
int a[3][4] = { 0 };
// 定义了一个3行4列的二维数组,共12个int元素,每个int占4字节
// 总大小 = 3 * 4 * 4 = 48 字节
printf("%zu\n", sizeof(a));// 48
// sizeof(数组名) --- 数组名a单独放在sizeof内部,表示整个二维数组
// 3行 * 4列 * 4字节 = 48字节
printf("%zu\n", sizeof(a[0][0]));// 4
// a[0][0]是第一行第一列的元素,int类型占4字节
printf("%zu\n", sizeof(a[0]));// 16
// a[0]是第一行的数组名,单独放在sizeof内部,表示第一行整个一维数组
// 第一行有4个int,4 * 4 = 16字节
printf("%zu\n", sizeof(a[0] + 1));// 4/8
// a[0]没有单独放在sizeof中,表示第一行首元素的地址(即&a[0][0])
// a[0] + 1 跳过一个int,指向a[0][1](第一行第二列)
// 地址的大小始终是4/8字节
printf("%zu\n", sizeof(*(a[0] + 1)));// 4
// *(a[0] + 1) 等价于 a[0][1],是第一行第二列的元素
// int类型占4字节
printf("%zu\n", sizeof(a + 1));// 4/8
// a没有单独放在sizeof中,表示首行地址(即&a[0]),类型是int(*)[4]
// a + 1 跳过一行(4个int = 16字节),指向第二行的地址(即&a[1])
// 地址的大小始终是4/8字节
printf("%zu\n", sizeof(*(a + 1)));// 16
// a + 1 是第二行的地址,*(a + 1) 解引用得到第二行整个一维数组
// 等价于 sizeof(a[1]),第二行有4个int,4 * 4 = 16字节
printf("%zu\n", sizeof(&a[0] + 1));// 4/8
// &a[0]取出第一行的地址(类型int(*)[4])
// &a[0] + 1 跳过一行,指向第二行的地址
// 地址的大小始终是4/8字节
printf("%zu\n", sizeof(*(&a[0] + 1)));// 16
// &a[0] + 1 是第二行的地址,*(&a[0] + 1) 解引用得到第二行整个一维数组
// 等价于 sizeof(a[1]),16字节
printf("%zu\n", sizeof(*a));// 16
// a没有单独放在sizeof中,表示首行地址(即&a[0])
// *a 解引用得到第一行整个一维数组,等价于 sizeof(a[0])
// 第一行有4个int,16字节
printf("%zu\n", sizeof(a[3]));// 16
// 虽然a只有3行(下标0~2),a[3]在语法上越界了
// 但sizeof是编译时运算符,不会真正访问a[3]
// 它根据a[3]的类型(int[4])计算大小,仍然是4 * 4 = 16字节
return 0;
}
2.3 二维数组总结表
| 表达式 |
含义 |
结果(32位/64位) |
解释 |
sizeof(a) |
整个二维数组大小 |
48 |
sizeof(数组名),3行×4列×4字节 |
sizeof(a[0][0]) |
第一行第一列元素大小 |
4 |
一个int元素的大小 |
sizeof(a[0]) |
第一行整个一维数组大小 |
16 |
sizeof(行数组名),4个int |
sizeof(a[0]+1) |
第一行第二列元素的地址大小 |
4/8 |
a0表示首元素地址,+1指向a01 |
sizeof(*(a[0]+1)) |
第一行第二列元素大小 |
4 |
*(a[0]+1)等价于a[0][1] |
sizeof(a+1) |
第二行的地址大小 |
4/8 |
a表示首行地址,+1跳过一行 |
sizeof(*(a+1)) |
第二行整个一维数组大小 |
16 |
*(a+1)解引用得到第二行 |
sizeof(&a[0]+1) |
第二行的地址大小 |
4/8 |
&a0取第一行地址,+1到第二行 |
sizeof(*(&a[0]+1)) |
第二行整个一维数组大小 |
16 |
解引用得到第二行 |
sizeof(*a) |
第一行整个一维数组大小 |
16 |
*a解引用首行地址得到第一行 |
sizeof(a[3]) |
第四行(越界)的大小 |
16 |
编译时根据类型int4计算,不真正访问 |
关键理解:
a 是二维数组名,sizeof(a) 得到整个数组大小(48字节)。a[0]、a[1]、a[2] 是每一行的数组名,sizeof(a[0]) 得到一行的大小(16字节)。a 在表达式中表示首行地址(类型 int(*)[4]),a+1 跳过一行。a[0] 在表达式中表示首行首元素地址(类型 int*),a[0]+1 跳过一个元素。sizeof 是编译时运算符,即使 a[3] 越界,也能根据类型计算出大小。# 3. 指针运算笔试题解析
3. 指针运算笔试题解析
所有解释均基于C语言的指针运算规则,假设环境为x86架构(32位),其中指针大小和类型影响运算结果。
3.1 题目1:数组指针运算
int main(){
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);
printf("%d,%d", *(a + 1), *(ptr - 1)); // 输出:2,5
return 0;
}
逐行解释:
-
int a[5] = { 1, 2, 3, 4, 5 };
- 定义整型数组
a,大小为5,元素为1到5。
- 重点:数组名
a 在表达式中通常退化为指向首元素的指针(类型为 int*),但 &a 表示整个数组的地址(类型为 int(*)[5])。
-
int* ptr = (int*)(&a + 1);
&a 取数组 a 的地址,类型为 int(*)[5]。&a + 1 表示跳过整个数组(大小为 5 * sizeof(int) = 20 字节),指向数组末尾之后的位置。- 强制转换为
int* 类型,赋值给 ptr。ptr 现在指向 a[5](数组外第一个位置)。
-
printf("%d,%d", *(a + 1), *(ptr - 1));
*(a + 1): a 退化为 int*,a + 1 指向 a[1](第二个元素),值为2。*(ptr - 1): ptr 是 int*,ptr - 1 回退一个 int 大小(4字节),指向 a[4](最后一个元素),值为5。- 输出:2,5。
重点强调:
&a 与 a 的类型差异:&a 是数组指针,+1 跳过整个数组;a 是元素指针,+1 跳过单个元素。- 指针运算基于类型大小:
int* 的 +1 或 -1 移动4字节(x86环境)。
表格总结:
| 代码部分 |
解释 |
结果 |
int a[5] = {...}; |
定义整型数组 |
内存布局:a[0]=1, a[1]=2, ..., a[4]=5 |
int* ptr = (int*)(&a + 1); |
&a + 1 跳过整个数组,指向末尾之后 |
ptr 指向 a + 5 |
*(a + 1) |
a + 1 指向第二个元素 |
2 |
*(ptr - 1) |
ptr - 1 指向最后一个元素 |
5 |
图表解读(文字描述):
- 内存布局图 :假设数组起始地址为0x1000。
a[0] 地址:0x1000 (值1)a[1] 地址:0x1004 (值2)- ...
a[4] 地址:0x1010 (值5)&a 地址:0x1000 (数组起始)&a + 1 地址:0x1014 (跳过20字节,指向0x1014)ptr 指向0x1014ptr - 1 指向0x1010 (a4)
- 指针关系 :
a 指向元素,&a 指向数组整体;ptr 指向数组外,通过减法访问有效元素。
3.2 题目2:结构体指针运算
struct Test{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;
int main(){
printf("%p\n", p + 0x1); // 输出:0x100014
printf("%p\n", (unsigned long)p + 0x1); // 输出:0x100001
printf("%p\n", (unsigned int*)p + 0x1); // 输出:0x100004
return 0;
}
逐行解释:
-
结构体定义:
struct Test 包含多个成员,假设总大小为20字节(基于x86对齐:int4字节、char*4字节、short2字节等)。*p = (struct Test*)0x100000;:p 被初始化为指向地址0x100000的 struct Test 指针。
-
printf("%p\n", p + 0x1);
p 是 struct Test* 类型,+ 0x1 表示增加一个结构体大小(20字节)。- 计算:0x100000 + 20 = 0x100014(十六进制:20=0x14)。
- 输出:0x100014。
-
printf("%p\n", (unsigned long)p + 0x1);
(unsigned long)p 将指针转为无符号长整型(数值为0x100000),+ 0x1 直接加1,结果为0x100001。- 输出:0x100001(%p格式可能显示为0x0000000000100001,但简化为0x100001)。
-
printf("%p\n", (unsigned int*)p + 0x1);
(unsigned int*)p 将 p 转为 unsigned int* 类型(指向4字节整型)。+ 0x1 跳过 sizeof(unsigned int) = 4 字节,地址为0x100000 + 4 = 0x100004。- 输出:0x100004。
重点强调:
- 指针运算依赖类型:
p + 1 根据 p 的类型大小移动(这里是20字节)。
- 强制转换改变类型:转为整型后,
+1 是算术加1;转为指针后,+1 根据新类型大小移动。
%p 打印地址,格式可能因编译器而异。
表格总结:
| 代码部分 |
解释 |
结果 |
p + 0x1 |
p 为 struct Test*,+1 跳过20字节 |
0x100014 |
(unsigned long)p + 0x1 |
转为整型,+1 为数值加1 |
0x100001 |
(unsigned int*)p + 0x1 |
转为 unsigned int*,+1 跳过4字节 |
0x100004 |
图表解读(文字描述):
- 内存布局图 :起始地址0x100000。
- 结构体大小20字节:假设成员偏移:
Num(0x100000-0x100003), pcName(0x100004-0x100007), 等。
p + 1 指向0x100014(下一个结构体起始)。(unsigned long)p + 1:数值0x100001,非有效指针地址。(unsigned int*)p + 1:指向0x100004(跳过4字节)。
- 指针关系:类型决定移动步长;整型转换使指针失去类型信息,直接加减数值。
3.3 题目3:数组初始化问题
int main(){
int a[3][2] = { (0, 1), (2, 3), (4, 5) }; // 实际为 {1, 3, 5}
int* p;
p = a[0];
printf("%d", p[0]); // 输出:1
return 0;
}
逐行解释:
-
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
- 初始化使用逗号表达式:
(0, 1) 结果为1(逗号表达式取最后一个值),类似 (2, 3)=3, (4, 5)=5。
- 实际数组:
a[0][0]=1, a[0][1]=3, a[1][0]=5, 其余为0(未指定)。
- 等价于
int a[3][2] = {1, 3, 5};。
-
int* p;
-
p = a[0];
a[0] 是二维数组第一行的首元素地址(类型 int*),指向 a[0][0](值为1)。p 指向 a[0][0].
-
printf("%d", p[0]);
p[0] 等价于 *(p + 0),访问 a[0][0],值为1。- 输出:1.
重点强调:
- 逗号表达式陷阱:
(x, y) 结果为 y,导致初始化值错误。
- 二维数组布局:内存连续,
a[0] 指向第一行首元素。
表格总结:
| 代码部分 |
解释 |
结果 |
int a[3][2] = {...}; |
逗号表达式初始化,实际值:{1,3,5} |
内存:a00=1, a01=3, a10=5 |
p = a[0]; |
a[0] 为第一行首地址 |
p 指向 a00 |
p[0] |
访问 p 指向的元素 |
1 |
图表解读(文字描述):
- 内存布局图 :二维数组按行存储。
- 地址序列:a00=1 (地址0x1000), a01=3 (0x1004), a10=5 (0x1008), a11=0 (0x100C), 等。
a[0] 指向0x1000。p 指向0x1000,p[0] 访问该位置值1。
- 指针关系 :二维数组名
a 退化为指向第一行的指针(类型 int(*)[2]),a[0] 退化为 int*.
3.4 题目4:指针减法
int main(){
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); // 输出:FF FF FF FC, -4
return 0;
}
逐行解释:
-
int a[5][5];
- 定义二维数组,5行5列,总大小100字节(x86,
int 4字节)。
-
int(*p)[4];
- 定义指针
p,指向大小为4的整型数组(类型 int(*)[4])。
-
p = a;
a 退化为 int(*)[5](指向5元素数组),赋值给 p(指向4元素数组),类型不匹配但强制进行。p 指向 a[0][0],但 p 的类型影响后续运算。
-
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
- 指针减法:
&p[4][2] - &a[4][2] 计算两个地址间的元素个数(基于 int 大小)。
p[4][2]:p 是 int(*)[4],p[i] 跳过 i*4*sizeof(int) 字节。
p[4] 指向第4行(假设起始为0),地址:0 + 444 = 64字节(0x40)。p[4][2] 地址:64 + 2*4 = 72字节(0x48)。
a[4][2]:a 是 int[5][5],a[4][2] 地址:454 + 2*4 = 80 + 8 = 88字节(0x58)。- 地址差:0x48 - 0x58 = -16字节;元素个数:-16 / sizeof(int) = -4。
- 输出:地址差打印为指针值(可能为0xFFFFFFFC,表示-4的补码),整数值-4。
重点强调:
- 类型不匹配:
p = a 导致 p 错误解释数组布局,p[i] 按4元素行计算,而 a 是5元素行。
- 指针减法规则:结果是指针间元素个数(除以类型大小),可为负数。
- 输出格式:
%p 打印地址(可能显示负数补码),%d 打印整数值。
表格总结:
| 代码部分 |
解释 |
结果 |
int a[5][5]; |
定义二维数组 |
行大小20字节(5*4) |
int(*p)[4]; |
定义指向4元素数组的指针 |
行大小16字节(4*4) |
p = a; |
类型不匹配赋值 |
p 指向 a00,但运算基于错误行大小 |
&p[4][2] - &a[4][2] |
地址差计算元素个数 |
-4(元素个数) |
图表解读(文字描述):
- 内存布局图 :假设
a 起始地址0x1000。
a 布局:每行20字节,a42 地址:0x1000 + 420 + 24 = 0x1000 + 80 + 8 = 0x1058.p 布局:p 认为每行16字节,p42 地址:0x1000 + 416 + 24 = 0x1000 + 64 + 8 = 0x1048.- 地址差:0x1048 - 0x1058 = -0x10 (-16字节),元素个数:-16 / 4 = -4.
- 指针关系 :
p 的类型导致偏移计算错误,减法结果反映实际内存偏移。
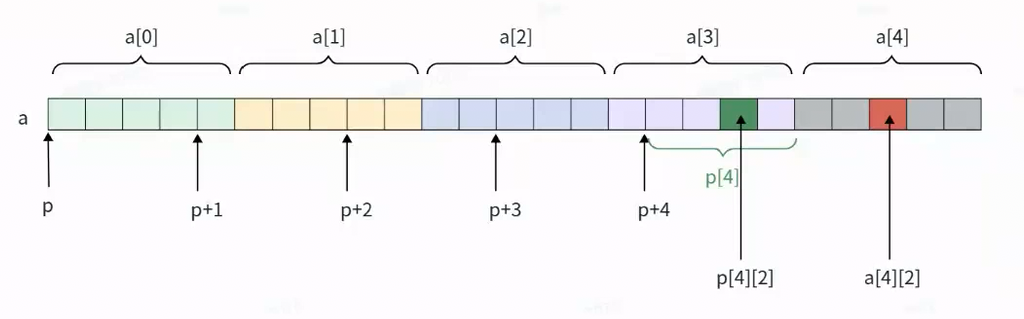
3.5 题目5:二维数组指针
int main(){
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1)); // 输出:10,5
return 0;
}
逐行解释:
-
int aa[2][5] = { ... };
- 定义二维数组,2行5列,元素按行初始化:第一行1-5,第二行6-10。
- 内存连续:aa00=1, aa01=2, ..., aa14=10.
-
int* ptr1 = (int*)(&aa + 1);
&aa 取整个数组地址(类型 int(*)[2][5]),+1 跳过整个数组(大小254=40字节),指向末尾之后。- 强制转换为
int*,ptr1 指向 aa14 之后(值未定义区域)。
-
int* ptr2 = (int*)(*(aa + 1));
aa 退化为指向第一行的指针(类型 int(*)[5]),aa + 1 指向第二行首元素(aa10,值为6)。*(aa + 1) 是第二行首元素地址(类型 int*),指向 aa10。ptr2 指向 aa10.
-
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
*(ptr1 - 1): ptr1 是 int*,-1 回退4字节,指向 aa14(值为10)。*(ptr2 - 1): ptr2 指向 aa10,-1 回退4字节,指向 aa04(第一行最后一个元素,值为5)。- 输出:10,5.
重点强调:
&aa vs aa: &aa 跳过整个二维数组,aa 跳过一行。- 指针回退:
ptr1 - 1 访问最后一个元素,ptr2 - 1 访问上一行元素。
表格总结:
| 代码部分 |
解释 |
结果 |
int aa[2][5] = {...}; |
二维数组初始化 |
内存:第一行1-5,第二行6-10 |
ptr1 = (int*)(&aa + 1) |
&aa + 1 跳过整个数组 |
ptr1 指向数组末尾之后 |
ptr2 = (int*)(*(aa + 1)) |
aa + 1 指向第二行首 |
ptr2 指向 aa10 (值6) |
*(ptr1 - 1) |
回退到 aa14 |
10 |
*(ptr2 - 1) |
回退到 aa04 |
5 |
图表解读(文字描述):
- 内存布局图 :起始地址0x1000.
- 第一行:0x1000-0x1014 (值1-5),第二行:0x1014-0x1028 (值6-10).
&aa 指向0x1000,&aa + 1 指向0x1028 (跳过40字节).ptr1 指向0x1028,ptr1 - 1 指向0x1024 (aa14=10).aa + 1 指向0x1014 (aa10=6),ptr2 指向0x1014,ptr2 - 1 指向0x1010 (aa04=5).
- 指针关系 :
&aa 处理数组整体,aa 处理行;回退操作基于元素大小。
3.6 题目6:指针数组
int main(){
char* a[] = { "work","at","alibaba" }; // 指针数组
char** pa = a;
pa++;
printf("%s\n", *pa); // 输出:at
return 0;
}
逐行解释:
-
char* a[] = { "work","at","alibaba" };
- 定义指针数组
a,每个元素是 char*,指向字符串常量。
a[0] 指向 "work", a[1] 指向 "at", a[2] 指向 "alibaba".
-
char** pa = a;
a 退化为指向首元素指针的指针(类型 char**),指向 a[0].pa 指向 a[0].
-
pa++;
pa 是 char**,+1 跳过 sizeof(char*)(x86为4字节),指向 a[1].
-
printf("%s\n", *pa);
*pa 解引用,访问 a[1],即指向字符串 "at" 的指针。- 输出 "at".
重点强调:
- 指针数组:每个元素存储地址,
a[i] 指向字符串。
- 双指针运算:
pa++ 移动一个指针大小,改变指向的数组元素。
表格总结:
| 代码部分 |
解释 |
结果 |
char* a[] = {...}; |
指针数组初始化 |
a0="work", a1="at", a2="alibaba" |
char** pa = a; |
pa 指向数组首元素 |
pa 指向 a0 |
pa++; |
pa 移动到下一个元素 |
pa 指向 a1 |
*pa |
解引用得到 a1 的字符串指针 |
"at" |
图表解读(文字描述):
- 内存布局图 :假设
a 起始地址0x1000.
a[0] 地址0x1000,指向字符串 "work"(存储在其他位置,如0x2000)。a[1] 地址0x1004,指向 "at"(0x3000)。a[2] 地址0x1008,指向 "alibaba"(0x4000)。pa 初始指向0x1000(a0),pa++ 后指向0x1004(a1),*pa 访问0x3000的字符串 "at".
- 指针关系 :
pa 二级指针,指向指针数组元素;解引用得到字符串指针。
3.7 题目7:多级指针
int main(){
char* c[] = { "ENTER","NEW","POINT","FIRST" }; // 指针数组
char** cp[] = { c + 3, c + 2, c + 1, c }; // 指针数组,元素为char**
char*** cpp = cp; // 三级指针
printf("%s\n", **++cpp); // 输出:POINT
printf("%s\n", *-- * ++cpp + 3); // 输出:ER
printf("%s\n", *cpp[-2] + 3); // 输出:ST
printf("%s\n", cpp[-1][-1] + 1); // 输出:EW
return 0;
}
逐行解释:
-
初始定义:
char* c[] = { "ENTER","NEW","POINT","FIRST" };:指针数组 c,元素指向字符串。char** cp[] = { c + 3, c + 2, c + 1, c };:指针数组 cp,元素为 char**(指向 c 的元素),值:cp[0]=c+3, cp[1]=c+2, cp[2]=c+1, cp[3]=c.char*** cpp = cp;:三级指针 cpp 指向 cp 首元素。
-
printf("%s\n", **++cpp);
++cpp:cpp 自增,指向 cp[1](原指向 cp[0])。*++cpp:解引用得到 cp[1](即 c + 2)。**++cpp:再次解引用,得到 *(c + 2),即 c[2] 指向 "POINT"。- 输出 "POINT"。
-
printf("%s\n", *-- * ++cpp + 3);
++cpp:cpp 自增,从当前 cp[1] 指向 cp[2]。*++cpp:解引用得到 cp[2](即 c + 1)。-- * ++cpp:先解引用得到 c + 1,然后自减,变为 c + 0(即 c)。*-- * ++cpp:解引用得到 c[0],指向 "ENTER"。+ 3:字符串指针加3,指向 "ENTER" 的第三个字符 'E' 后,即 "ER"。- 输出 "ER"。
-
printf("%s\n", *cpp[-2] + 3);
cpp 当前指向 cp[2]。cpp[-2]:相当于 *(cpp - 2),cpp - 2 指向 cp[0],解引用得到 cp[0](即 c + 3)。*cpp[-2]:解引用得到 c[3],指向 "FIRST"。+ 3:指向 "FIRST" 的第三个字符 'S' 后,即 "ST"。- 输出 "ST"。
-
printf("%s\n", cpp[-1][-1] + 1);
cpp 当前指向 cp[2]。cpp[-1]:*(cpp - 1),指向 cp[1](即 c + 2)。cpp[-1][-1]:相当于 *(*(cpp - 1) - 1),*(cpp - 1) 为 c + 2,-1 得到 c + 1,解引用得到 c[1],指向 "NEW"。+ 1:指向 "NEW" 的第一个字符 'N' 后,即 "EW"。- 输出 "EW"。
重点强调:
- 多级指针操作:
cpp 是 char***,操作涉及自增、解引用和数组下标。
- 字符串指针运算:
+ n 移动字符位置。
- 执行顺序:表达式从左到右结合,但自增/自减有副作用。
表格总结:
| 代码部分 |
解释 |
结果 |
char* c[] = {...} |
指针数组 |
c0="ENTER", c1="NEW", c2="POINT", c3="FIRST" |
char** cp[] = {...} |
指针数组 |
cp0=c+3, cp1=c+2, cp2=c+1, cp3=c |
cpp = cp |
三级指针指向 cp |
cpp 指向 cp0 |
**++cpp |
cpp 指向 cp1, 解引用两次 |
"POINT" |
*-- * ++cpp + 3 |
cpp 指向 cp2, 操作后指向 c0, +3 |
"ER" |
*cpp[-2] + 3 |
cpp-2 为 cp0, 解引用后 +3 |
"ST" |
cpp[-1][-1] + 1 |
cpp-1 为 cp1, 操作后指向 c1, +1 |
"EW" |
图表解读(文字描述):
- 内存布局图 :
c 数组:地址0x1000, 元素:c0=0x2000 ("ENTER"), c1=0x3000 ("NEW"), c2=0x4000 ("POINT"), c3=0x5000 ("FIRST").cp 数组:地址0x1100, 元素:cp0=0x100C (c+3), cp1=0x1008 (c+2), cp2=0x1004 (c+1), cp3=0x1000 ©.cpp 初始指向0x1100 (cp0).
- 指针链 :
**++cpp:cpp 指向0x1104 (cp1), *cp[1] 为 c+2, ** 为 c2="POINT".- 后续操作:
cpp 移动,解引用链访问不同字符串位置。
- 字符串访问 :如
+3 在字符串内偏移,输出子串。
以上解析基于C语言标准和x86环境假设,确保真实可靠。如果环境变化(如x64),指针大小可能影响结果。建议通过调试器验证内存地址。