MPDR 项目详解
项目概述
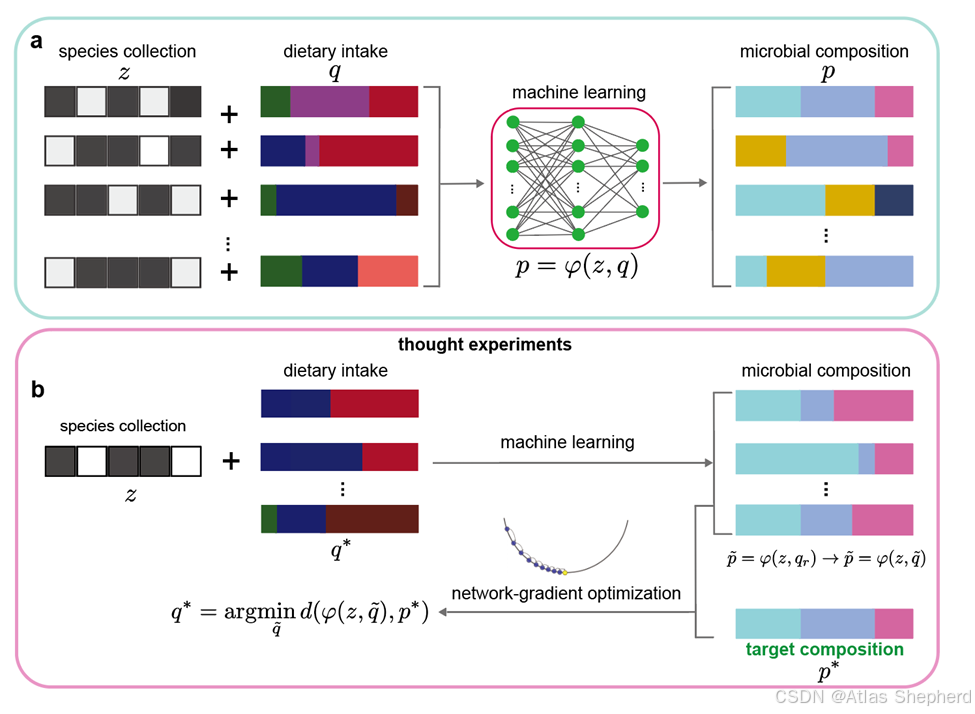
MPDR (Machine Learning-based Personalized Dietary Recommendations) 是一个基于机器学习的个性化膳食推荐框架,旨在通过饮食干预来调节肠道微生物组,以促进人体健康。
核心思想
该框架的核心思路是:
- 隐式学习饮食-微生物交互关系:通过训练机器学习模型,使用来自人群队列的配对肠道微生物组和膳食摄入数据
- 预测微生物组成:训练好的模型可以预测给定物种集合和膳食摄入的微生物组成
- 优化膳食推荐:通过解决优化问题,为个体生成定制化的膳食建议
项目结构
MPDR/
├── code/
│ ├── MPDR_simulated_community_test.py # 模拟群落测试脚本
│ ├── MPDR_train.py # 模型训练脚本
│ └── MPDR.py # 实际数据膳食推荐脚本
├── data/
│ ├── train/ # 训练数据集
│ ├── test/ # 测试数据集
│ ├── DMAS_*.csv # 真实数据集 (DMAS)
│ └── DMAS_p_disease_desired.csv
├── results/
│ ├── MPDR_train/ # 训练结果
│ └── MPDR_test/ # 测试结果
├── MPDR_model.pt # 预训练模型
├── README.md
└── LICENSE核心算法
1. 模型架构 (DietMicrobiomeMLPConcat)
python
class DietMicrobiomeMLPConcat(nn.Module):
# 输入: 饮食特征 + 当前微生物丰度 (拼接)
# 输出: Dirichlet alpha 参数
def __init__(self, diet_input_dim, microbe_output_dim, hidden=256):
in_dim = diet_input_dim + microbe_output_dim
self.mlp = nn.Sequential(
nn.Linear(in_dim, hidden),
nn.Linear(hidden, microbe_output_dim),
)- 输入: 饮食向量 + 当前微生物组成向量 (拼接后)
- 输出: Dirichlet 分布的 alpha 参数
- 激活: Softplus + 数值裁剪保证稳定性
2. 损失函数 (Masked Dirichlet Loss)
python
def masked_dirichlet_loss(pred_alpha, true_abund, mask, eps=1e-6):
# 对存在的物种计算 Dirichlet 负对数似然
dist = torch.distributions.Dirichlet(alpha)
nll = -dist.log_prob(true)
return nll.mean()- 使用 Dirichlet 分布 建模微生物组成的概率分布
- 通过 mask 只对存在的物种计算损失
3. 膳食优化 (DMAS 梯度下降)
python
def optimize_diet_for_target(model, prev_micro_start, target_micro_end, init_diet):
# 最小化预测终点与目标微生物组成的 Bray-Curtis 距离
loss = bray_curtis(pred_end, target_micro_end).mean()
loss.backward() # 反向传播梯度- 优化目标 : 最小化预测微生物组成与目标组成的 Bray-Curtis 距离
- 梯度下降: 使用 L-∞ 范数归一化的梯度步进
数据说明
训练数据 (train/)
| 文件 | 描述 |
|---|---|
train_p_healthy.csv |
健康状态的目标微生物组成 |
train_z_healthy.csv |
健康状态的基线微生物状态 |
train_q_healthy.csv |
健康状态的饮食矩阵 |
train_p_disease_desired.csv |
疾病状态的目标微生物组成 |
train_z_disease.csv |
疾病状态的基线微生物 |
train_q_disease_random.csv |
初始膳食(用于优化) |
测试数据 (test/)
模拟不同参数下的合成数据用于验证框架
使用方法
1. 模拟群落测试
bash
python MPDR_simulated_community_test.py \
--p_train ./data/test/p_healthy_0.1_0.01_0.2_0_5_1.csv \
--z_train ./data/test/z_healthy_0.1_0.01_0.2_0_5_1.csv \
--q_train ./data/test/q_healthy_0.1_0.01_0.2_0_5_1.csv \
--p_target ./data/test/p_disease_0.1_0.01_0.2_0_5_1.csv \
--z_start ./data/test/z_disease_0.1_0.01_0.2_0_5_1.csv \
--q_start ./data/test/q_disease_perm_0.1_0.01_0.2_0_5_1.csv \
--out_dir ./results/test --tag MPDR_test2. 真实数据膳食推荐
bash
python MPDR.py \
--model_path ./MPDR_model.pt \
--z_start ./data/DMAS_z_disease.csv \
--q_start ./data/DMAS_q_disease_random.csv \
--p_target ./data/DMAS_p_disease_desired.csv \
--out_dir ./results关键参数
| 参数 | 默认值 | 说明 |
|---|---|---|
--epochs |
1000 | 训练轮数 |
--lr |
1e-2 | 学习率 |
--mb |
20 | Mini-batch 大小 |
--diet_steps |
400 | 膳食优化步数 |
--step_size |
0.05 | 梯度步长 |
--early_stop |
30 | 早停耐心值 |
输出结果
diet_recommendations_*.csv: 个性化膳食推荐pred_endpoints_*.csv: 预测的微生物终点train_loss_*.csv: 训练损失曲线val_loss_*.csv: 验证损失曲线best_model_*.pt: 最佳模型检查点
技术亮点
- Dirichlet 分布建模:适合组成型数据(微生物丰度)
- Masked Loss:只对存在的物种计算损失
- 梯度优化膳食:端到端可微分
- 数值稳定性:NaN/Inf 处理、梯度裁剪
- 可替换数据集:支持用户自定义数据