题目:REALM: An RGB and Event Aligned Latent Manifold for Cross-Modal Perception
作者:Vincenzo Polizzi, David B. Lindell, Jonathan Kelly
当MASt3R第一次"看见"事件流:一场被遗忘的模态终于上桌
过去两年,RGB视觉社区被基础模型彻底洗牌------DINOv2、MASt3R、Depth Anything 这些在亿级图像上预训练的庞然大物,可以零样本完成从深度估计到三维重建的几乎所有任务。然而事件相机,这个号称要颠覆视觉传感的"下一代"模态,却始终被关在大门外:每一个事件相机的下游任务都要从头训练专属网络,标注数据稀缺,模型互不兼容。
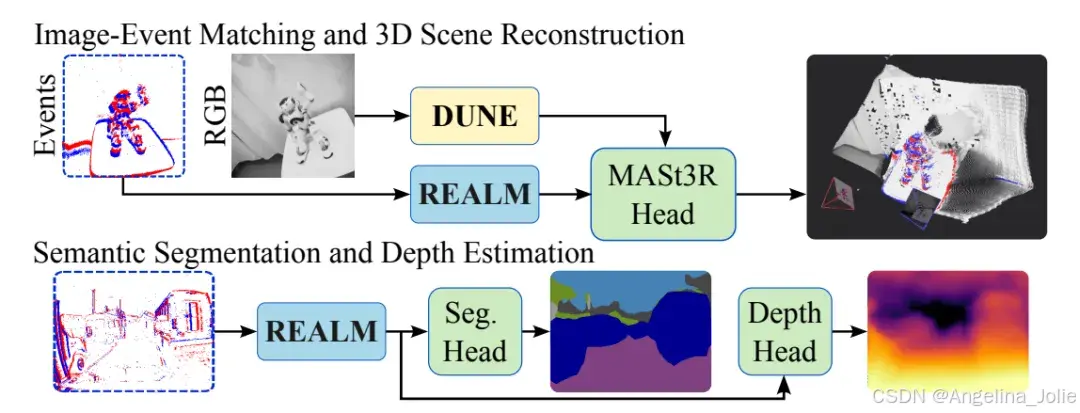
多伦多大学机器人研究所的 Polizzi 等人提出了一个让人意外的解法------与其费尽心力从头训练事件大模型,不如把事件流"翻译"成RGB基础模型听得懂的语言。他们的框架 REALM 仅训练 10% 的参数,就让冻结的 MASt3R 解码器以零样本方式直接处理稀疏事件数据,在宽基线特征匹配上的 AUC@5° 从 SOTA 的 22.7% 一举推升至 26.2%,部分场景对比 MINIMA 等跨模态方法甚至有 9 倍以上的提升。
为什么"事件大模型"这条路走不通
事件相机以微秒级延迟、超高动态范围著称,对运动模糊和极端光照天生免疫。但它的输出是异步、稀疏的事件流,与 RGB 帧的稠密网格结构格格不入。这就带来了三重困境:标准 ViT 架构无法直接吃事件数据;标注的事件数据集规模远小于 ImageNet 一类的图像库;从头训练的事件模型只能服务于单一任务,深度模型不能做语义分割,分割模型不能做特征匹配。
EvDistill 一类方法试图先把事件重建成图像再喂给视觉模型,但这一步重建本身就引入了伪影和算力开销。作者敏锐地指出:重建图像是一种浪费------事件流里已经包含了足够的几何与语义信息,关键是怎么把它"翻译"到与 RGB 共享的潜空间,而不必绕道像素空间。
核心洞察:让事件特征"伪装成"RGB token
REALM 的方法论可以用一句话概括:冻结 RGB 基础模型,只训练一个事件专用的输入嵌入器,再用 LoRA 给主干网络加几道微调通路,目标函数是把事件经过整个网络后的输出,对齐到同一时刻 RGB 图像经过 DUNE 编码器后的特征。
作者选择 DUNE 作为教师模型------它本身是从 DINOv2、MASt3R、Multi-HMR 三个异构教师蒸馏出的"通才"ViT,潜空间天然兼容多任务。学生网络的目标不是让中间嵌入对齐 (,这显然办不到,因为输入维度都不一样),而是让最终的 backbone 输出对齐:
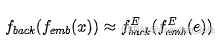
技术深度:双重掩码训练破解事件特性两大顽疾
REALM 的训练管道里有两个非常巧妙的设计,直击事件数据本身的两个痛点。
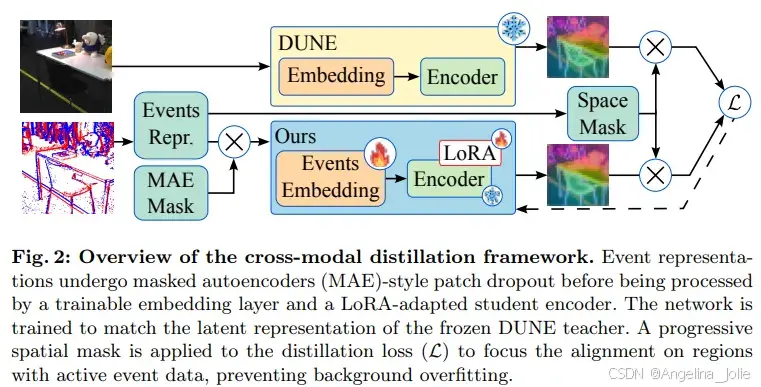
LoRA 适配代替全量微调。 主干 91M 参数全部冻结,作者只在 attention、projection、feed-forward 层各插入 rank=32 的低秩矩阵 。算上事件嵌入器(5.2M)和 LoRA 适配器(4.8M),可训练参数仅 10M,占比 10.47%。这一设计不仅省算力,更关键是避免灾难性遗忘------DUNE 在数百万 RGB 图像上学到的几何与语义先验被完整保留下来,事件流只是"借住"在这个潜空间里。
渐进式空间掩码解决静态背景幻觉问题。 事件相机只对动态变化产生事件,静态背景在 RGB 图像里清晰可见,但在事件流里完全是空白。如果硬让学生网络去预测这些"看不到"的区域,模型就会学会"硬编"------胡乱生成不存在的特征。作者的对策是:从输入事件 voxel grid 推导出一个二值占用网格,每 14×14 像素 max-pool 成一个 32×32 的 token-level mask。训练初期 (epoch 1-9) 严格只在事件活跃区域计算损失;epoch 10/15/20 时分别将 mask 形态学膨胀 2/4/6 个 patch,逐步暴露更多上下文。这个"由近及远"的课程让模型既不会过拟合到静态背景,又能利用 MAE 风格的 30% patch dropout 学会从稀疏证据外推稠密特征。
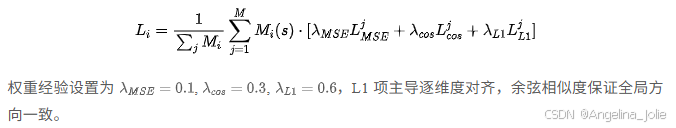
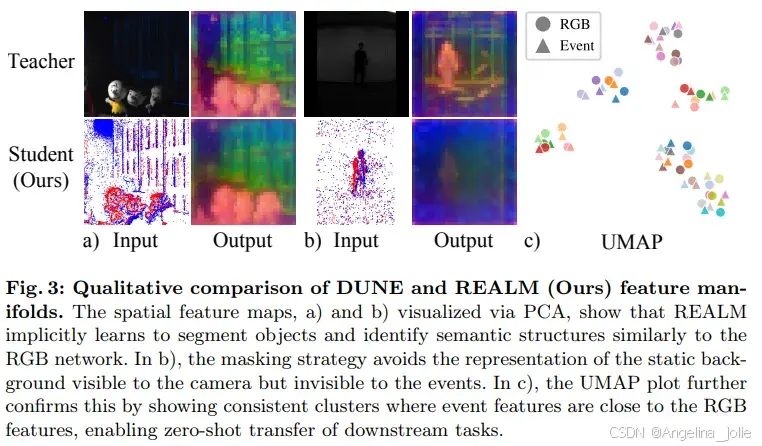
实验验证:宽基线匹配的颠覆性突破
REALM 的最强战场在宽基线特征匹配------这正是图像-训练 MASt3R 头的看家本领,作者把它直接搬到事件流上做零样本测试。在 ECD 数据集 AUC@20° 指标上,REALM 达到 **63.3%**,比上一代 SOTA SuperEvent 的 46.7% 提升超 16 个百分点;EDS 数据集上从 40.1% 跃升至 55.3%。
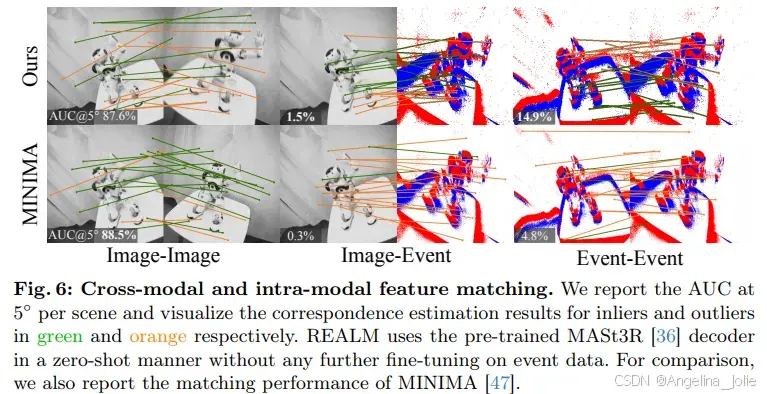
更具说服力的是 VECtor 数据集上的极端视角变化测试。在事件-事件匹配任务中,REALM 把中位旋转误差压到 2.75° ,而 SuperEvent 高达 46.33°。当视角变化超过 45° 时,几乎所有专用方法直接失效,REALM 仍能维持 8.8% 的 AUC@10°------3D 几何先验在跨模态条件下依然有效。
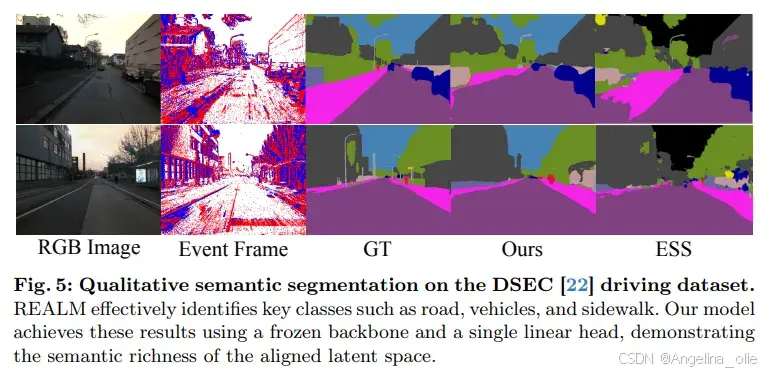
深度估计同样亮眼。MVSEC 数据集 outdoor night 1 序列上,REALM 在 20m 截止距离的平均误差为 2.51m ,超过监督方法 EMoDepth 的 2.70m 和 Zhu et al. 的 4.02m。最有趣的发现:在低光照场景下,REALM 超过了它自己的 RGB 教师 DUNE ------ 事件相机的 HDR 特性被成功保留并放大。语义分割上 mIoU 55.37%,与专用 ESEG 的 57.55% 仅差 2 个百分点,但 REALM 用的是单层线性头,无需任何边缘监督。
效率方面同样有说服力:REALM 单次特征提取耗时 50.5ms,仅为 MINIMA 的 30%;GPU 占用 2.58GB,约为 MINIMA 7.56GB 的三分之一,吞吐量 8.99 FPS 是 MINIMA 的两倍。
启示:模态不再是孤岛
REALM 最深远的意义不在某个具体指标,而在它揭示了一种普适的跨模态范式:当一个模态缺乏大规模标注数据时,与其重建数据集,不如把它"嫁接"到已经成熟的基础模型潜空间。LoRA 这种轻量适配能在不破坏原有先验的前提下打通模态壁垒。
对于事件相机社区而言,这意味着 SLAM、跨模态定位、视觉里程计等过去需要专属架构的任务,现在都可以直接借用 RGB 生态的成熟工具。当事件流学会用基础模型的语言说话,整个 RGB 视觉的工具箱瞬间就向它敞开了大门。