摘要__:本文从企业私有架构视角出发,深度解析构建 AI-IDE / AI-Studio 所需的五大核心技术方向。涵盖从 NLP 到图形化 UML 设计辅助、理解推理引擎与模板评分选择、沙箱技术、基础技术底座,以及工程能力分层与数据飞轮。每个方向均提供核心概念解释、架构设计思路、关键技术挑战与解决方案,以及企业落地实践建议。
关键词__:AI-IDE、NLP 驱动开发、Harness Engineering、编译沙箱、Agent 协议、数据飞轮
方向一:从 NLP 到图形化 UML 设计辅助
1.1 核心概念解释
在 AI-IDE 的语境下,"从 NLP 到图形化 UML 设计辅助"指的是一套完整的智能设计管线:用户通过自然语言描述业务需求,系统经过意图识别、领域建模、结构生成,最终输出可视化的 UML 设计图或可执行的 UI 组件配置。这一方向的核心价值在于消除需求文档与实现代码之间的语义鸿沟------让自然语言成为软件开发的第一公民。
传统的软件开发流程中,需求从自然语言到代码需要经过"需求文档 → 人工分析 → 架构设计 → 编码实现"多个环节,每个环节都存在信息损耗。AI-IDE 的目标是通过 NLP 技术压缩这一链条,实现"意图即实现"。
1.2 架构设计思路
1.2.1 自然语言意图识别与领域建模
意图识别是 NLP 管线的入口,其质量直接决定后续所有环节的正确性。企业级 AI-IDE 应采用双引擎策略:规则引擎处理高频、确定性意图,LLM 引擎处理复杂、模糊意图。
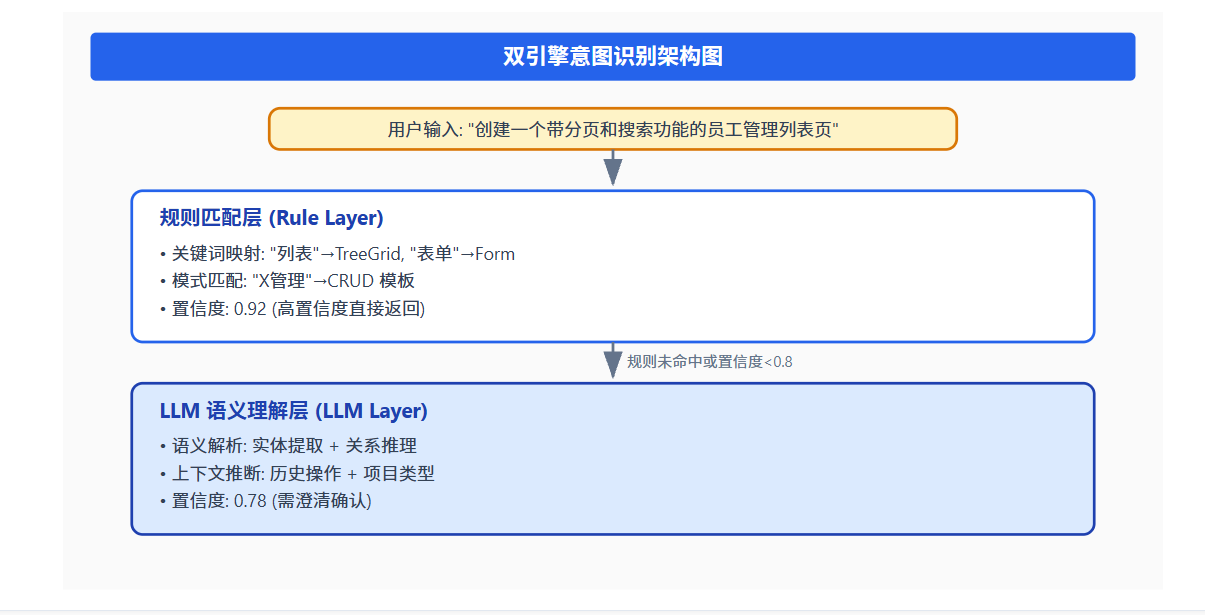
领域建模层将识别出的意图转化为结构化的领域对象。关键设计是**实体提取器(Entity Extractor)**的构建:
javascript
public class DomainModelExtractor {
public DomainModel extract(String userInput, Intent intent) {
DomainModel model = new DomainModel();
// 1. 模块识别
model.setModuleName(extractModuleName(userInput));
// 2. 字段提取
model.setFields(extractFields(userInput));
// 3. 操作推断
model.setOperations(inferOperations(userInput, intent));
// 4. 关系识别
model.setRelations(extractRelations(userInput));
return model;
}
}1.2.2 四分离架构(数据/行为/事件/样式)
四分离架构是 AI-IDE 中组件模型的核心设计原则,将 UI 组件解耦为四个正交维度:
| 维度 | 职责 | 典型属性 | 解耦收益 |
|---|---|---|---|
| Properties(数据) | 业务属性与数据绑定 | dataUrl, columns, fields | 切换后端只需改 URL |
| Styles(样式) | 视觉表现与主题 | cssClass, theme, layout | 设计系统无缝切换 |
| Events(事件) | 用户交互响应 | onClick, onChange, onLoad | 交互逻辑模块化 |
| Behaviors(行为) | 业务动作链 | actions, apiCallers, callbacks | 复杂交互可配置化 |
四分离的深层价值在于为 LLM 提供了结构化的生成约束。当 LLM 生成一个组件时,不再是自由发挥,而是在四个维度上分别填充------这大大降低了生成结果的方差。
javascript
{
"componentType": "TreeGrid",
"properties": {
"dataUrl": "/api/employees",
"columns": [
{ "field": "id", "caption": "ID", "width": 80 },
{ "field": "name", "caption": "姓名", "width": 120 },
{ "field": "department", "caption": "部门", "width": 150 }
]
},
"styles": {
"cssClass": "employee-grid-theme",
"striped": true,
"hoverEffect": "highlight"
},
"events": {
"onRowClick": "handleRowSelect",
"onRowDoubleClick": "handleEdit"
},
"behaviors": {
"apiCallers": [
{ "alias": "SEARCH", "url": "/api/employees/search" },
{ "alias": "SAVE", "url": "/api/employees/save" }
],
"actions": [
{ "type": "CustomGridAction.RELOAD", "trigger": "afterSave" }
]
}
}1.2.3 LLM 驱动的代码生成管线(Pipeline)
代码生成管线是 NLP 到实现的桥梁。一个成熟的管线应包含 6-8 个阶段,每个阶段都有明确的输入输出契约:

每个阶段都应实现 StageContract 接口,确保输入验证、输出验证和失败回退:
javascript
public interface PipelineStage<I, O> {
ValidationResult validateInput(I input);
StageResult<O> process(I input);
ValidationResult validateOutput(O output);
StageResult<O> fallback(I input, Throwable error);
}1.2.4 从文本到可视化设计器的自动桥接
文本描述到可视化设计器的桥接是 AI-IDE 的关键用户体验环节。核心挑战在于:LLM 生成的是结构化文本(JSON/XML),而设计器需要的是可视化节点和连线。
桥接层的设计要点:
- 元数据驱动渲染:设计器不直接解析 LLM 输出,而是通过元数据层(Meta Layer)进行转换
- 双向同步:设计器的修改能实时同步回文本表示,文本的变更也能实时反映到设计器
- 增量更新:支持局部更新而非全量刷新,保持用户操作状态
javascript
public class DesignBridge {
// 文本 → 可视化节点
public VisualNode toVisualNode(ComponentModel model) {
VisualNode node = new VisualNode();
node.setType(model.getComponentType());
node.setPosition(calculateLayout(model));
node.setProperties(model.getProperties());
// 递归处理子组件
for (ComponentModel child : model.getChildren()) {
node.addChild(toVisualNode(child));
}
return node;
}
// 可视化节点 → 文本
public ComponentModel toComponentModel(VisualNode node) {
// 逆向转换逻辑
}
}1.2.5 实时反馈与迭代优化机制
AI-IDE 必须支持"生成 → 预览 → 反馈 → 修正"的闭环迭代。关键设计包括:
- 渐进式披露(Progressive Disclosure):根据置信度决定展示完整度
- 澄清请求(Clarification Request):当置信度不足时,主动向用户询问
- 增量修正(Incremental Correction):支持局部修改而非全量重生成
| 置信度区间 | 披露级别 | 用户看到的内容 | 交互策略 |
|---|---|---|---|
| 0.00 - 0.30 | SKELETON | 只有组件框架,无细节 | 强制澄清 |
| 0.30 - 0.60 | ESSENTIAL | 核心组件 + 基本配置 | 建议澄清 |
| 0.60 - 0.85 | COMPLETE | 完整实现(含事件、样式) | 允许直接修改 |
| 0.85 - 1.00 | POLISHED | 生产级优化代码 | 自动执行 |
1.3 关键技术挑战与解决方案
挑战 1:LLM 输出的不确定性
问题:同样的输入,LLM 可能生成不同的组件类型或配置。
解决方案:
- 约束生成(Constrained Generation):通过 JSON Schema 或特定 DSL 限制 LLM 的输出空间
- 多引擎协作:规则引擎 + LLM 引擎并行执行,加权融合结果
- 后处理校验:生成后通过 JSON Schema 校验,不通过则触发重试或降级
javascript
public class ConstrainedGenerator {
public JSONObject generateWithSchema(String prompt, JsonSchema schema) {
// 1. 将 Schema 注入 Prompt
String constrainedPrompt = prompt + "\n输出必须符合以下 Schema:\n" + schema.toString();
// 2. 调用 LLM
String rawOutput = llmService.generate(constrainedPrompt);
// 3. Schema 校验
ValidationResult validation = schema.validate(rawOutput);
if (!validation.isValid()) {
// 4. 自动修复或降级
return autoFixOrFallback(rawOutput, validation.getErrors());
}
return JSONObject.parse(rawOutput);
}
}挑战 2:领域知识的注入
问题:通用 LLM 不了解企业内部的组件库、命名规范、业务规则。
解决方案:
- RAG(检索增强生成):在生成前检索相关领域知识注入上下文
- 知识分层:私有知识(项目级)→ 场景组知识(业务线级)→ 通用知识(平台级)
- 知识缓存:高频知识预加载,减少检索延迟
挑战 3:长上下文下的信息丢失
问题:复杂需求需要大量上下文,超出 LLM 的上下文窗口。
解决方案:
- 上下文压缩:通过摘要和索引减少冗余信息
- 分阶段生成:将大需求拆分为子模块,逐一生成后组装
- 滑动窗口:维护一个动态上下文窗口,保留最关键的信息
1.4 企业落地实践建议
- 从高频场景切入:先覆盖企业内部最高频的 CRUD 页面生成,建立信心
- 建立组件知识库:将现有组件库文档化,形成 LLM 可消费的格式
- 渐进式引入:先作为"设计辅助"(Copilot),再逐步过渡到"设计主导"(Agent)
- 人工复核机制:关键业务模块的生成结果必须经过人工确认
- 度量驱动优化:建立生成准确率、用户采纳率等核心指标,持续迭代
方向二:理解推理引擎与模板评分选择
2.1 核心概念解释
理解推理引擎是 AI-IDE 的"大脑",负责将解析后的用户意图转化为具体的技术实现方案。与简单的模板填充不同,现代推理引擎需要具备上下文感知、多模态理解、动态决策的能力------它不仅要"知道"有哪些模板,更要"理解"在当前场景下哪个模板最合适、如何调整参数以匹配需求。
模板评分选择是推理引擎的核心输出环节。面对一个"员工管理"需求,系统可能拥有列表模板、表单模板、仪表盘模板等多个候选,评分算法需要综合考虑需求匹配度、历史使用频率、用户偏好、技术约束等多维因素。
2.2 架构设计思路
2.2.1 推理引擎的核心架构(RAG + CoT + 工具调用)
现代 AI-IDE 的推理引擎应采用三层推理架构:

**RAG(检索增强生成)**在推理引擎中的作用:
javascript
public class RAGReasoningEngine {
public ReasoningResult reason(UserQuery query) {
// 1. 查询理解
QueryVector vector = embeddingModel.encode(query.getText());
// 2. 知识检索
List<KnowledgeChunk> chunks = vectorStore.similaritySearch(vector, TOP_K);
// 3. 上下文构建
String context = buildContext(query, chunks);
// 4. 推理生成
String reasoning = llmService.generateWithContext(query.getText(), context);
// 5. 结果结构化
return parseReasoningResult(reasoning);
}
}CoT(思维链)推理的关键在于让 LLM "展示思考过程":
javascript
用户输入: "创建一个支持审批流程的请假表单"
CoT 推理过程:
1. 识别核心意图: CREATE_FORM (置信度: 0.95)
2. 识别附加需求: WORKFLOW_APPROVAL (置信度: 0.88)
3. 推断字段: [申请人, 请假类型, 开始日期, 结束日期, 请假原因, 审批人]
4. 推断操作: [提交申请, 审批通过, 审批拒绝, 查看进度]
5. 选择模板: FormWithWorkflowTemplate (匹配度: 0.91)
6. 参数注入: workflowType=SEQUENTIAL, approvalLevels=22.2.2 特定技术栈模板库的设计
企业级 AI-IDE 必须支持多技术栈模板库。模板库的设计应遵循以下原则:
- 分层组织:框架级模板 → 项目级模板 → 团队级模板
- 元数据驱动:每个模板附带完整的元数据(适用场景、依赖项、版本兼容性)
- 可组合性:支持模板嵌套和组合,而非简单的复制粘贴
javascript
# 模板元数据示例
template:
id: "spring-boot-crud-v2"
name: "Spring Boot CRUD 模板"
version: "2.1.0"
techStack: ["Spring Boot 3.x", "MyBatis-Plus", "MySQL 8.0"]
applicability:
minConfidence: 0.75
requiredIntents: ["CREATE_CRUD", "MANAGE_ENTITY"]
forbiddenIntents: ["REALTIME", "STREAMING"]
parameters:
- name: "entityName"
type: "string"
required: true
description: "实体类名"
- name: "hasPagination"
type: "boolean"
default: true
description: "是否开启分页"
scoring:
baseScore: 0.80
intentMatchWeight: 0.40
techStackMatchWeight: 0.30
historyUsageWeight: 0.20
userPreferenceWeight: 0.102.2.3 基于上下文感知的模板评分算法
模板评分不是简单的关键词匹配,而是多因素加权融合的决策过程:
javascript
public class TemplateScoringEngine {
public ScoredTemplate score(Template template, UserContext context, Intent intent) {
double score = template.getBaseScore();
// 1. 意图匹配度 (40%)
double intentMatch = calculateIntentMatch(template, intent);
score += intentMatch * 0.40;
// 2. 技术栈匹配度 (30%)
double techMatch = calculateTechStackMatch(template, context.getTechStack());
score += techMatch * 0.30;
// 3. 历史使用频率 (20%)
double usageScore = calculateUsageScore(template, context.getUserId());
score += usageScore * 0.20;
// 4. 用户偏好 (10%)
double preference = calculateUserPreference(template, context.getUserId());
score += preference * 0.10;
// 5. 惩罚因子
if (template.isDeprecated()) score -= 0.30;
if (template.getVersion().isOutdated()) score -= 0.20;
return new ScoredTemplate(template, Math.min(1.0, Math.max(0.0, score)));
}
}2.2.4 多模态推理(代码+图形+配置)
企业级 AI-IDE 需要支持多种输入模态的统一推理:
| 模态 | 输入形式 | 处理方式 | 应用场景 |
|---|---|---|---|
| 文本 | 自然语言描述 | NLP 解析 + 意图识别 | 需求描述 |
| 代码 | 现有代码片段 | AST 分析 + 语义理解 | 代码补全/重构 |
| 图形 | UML 图/流程图 | 图形解析 + 节点识别 | 架构设计 |
| 配置 | YAML/JSON/Properties | 结构化解析 + 校验 | 环境配置 |
多模态融合的关键是统一表示层:将所有模态转换为统一的中间表示(Intermediate Representation),再进行推理:
javascript
文本描述 ──→ NLP Parser ──→ ┐
代码片段 ──→ AST Parser ──→ ┼→ 统一表示层 ──→ 推理引擎 ──→ 决策
UML 图形 ──→ Graph Parser ─→ ┘
配置文件 ──→ Config Parser ─→ ┘2.2.5 模板匹配与动态参数注入
模板匹配后,需要将用户意图中的具体参数注入到模板中。这一过程涉及参数提取 和参数映射两个环节:
javascript
public class ParameterInjector {
public InjectedTemplate inject(Template template, DomainModel model) {
Map<String, Object> parameters = new HashMap<>();
// 1. 直接映射
parameters.put("entityName", model.getModuleName());
parameters.put("fields", model.getFields());
// 2. 推断映射
parameters.put("hasPagination", model.getFields().size() > 10);
parameters.put("primaryKey", inferPrimaryKey(model.getFields()));
// 3. 默认值填充
for (TemplateParam param : template.getParameters()) {
if (!parameters.containsKey(param.getName()) && param.hasDefault()) {
parameters.put(param.getName(), param.getDefaultValue());
}
}
// 4. 必填校验
validateRequiredParameters(template, parameters);
return new InjectedTemplate(template, parameters);
}
}2.3 关键技术挑战与解决方案
挑战 1:模板膨胀与选择困难
问题:随着业务发展,模板库可能膨胀到数百甚至数千个,导致选择困难。
解决方案:
- 模板分层:按业务域、技术栈、复杂度分层,缩小搜索空间
- 动态推荐:基于用户历史行为和当前上下文,预过滤候选模板
- 模板聚类:相似模板合并为"模板族",减少重复
挑战 2:跨技术栈的模板复用
问题:同一业务场景在不同技术栈下需要维护多份模板。
解决方案:
- 平台无关模板(PIT):定义技术无关的抽象模板,再通过适配器转换为具体技术栈
- 代码转换引擎:基于 AST 的跨语言代码转换
挑战 3:模板版本管理与兼容性
问题:模板升级后,历史项目可能不兼容。
解决方案:
- 语义化版本:模板采用 SemVer 规范
- 兼容性矩阵:记录模板与框架版本的兼容关系
- 迁移工具:自动生成从旧模板到新模板的迁移脚本
2.4 企业落地实践建议
- 建立模板治理委员会:负责模板的审核、发布、下线
- 模板质量门禁:新模板必须通过功能测试、性能测试、安全扫描
- 用户反馈闭环:收集用户对模板的使用反馈,持续优化评分算法
- A/B 测试:新模板上线前进行小流量 A/B 测试,验证效果
- 文档化:每个模板必须有完整的文档和使用示例
方向三:沙箱技术
3.1 核心概念解释
在 AI-IDE 的语境下,沙箱技术是指为 AI 生成的代码提供一个隔离、安全、可控的执行环境,用于验证生成代码的正确性、安全性和性能。沙箱是 AI 代码生成闭环中的关键环节------没有沙箱验证,AI 生成的代码直接部署到生产环境将带来巨大的风险。
沙箱技术的核心目标:
- 隔离性:生成的代码不能影响宿主机或其他进程
- 安全性:防止恶意代码执行(即使 AI 无意生成)
- 可观测性:完整记录执行过程、资源消耗、异常信息
- 可回滚:验证失败时能够完全清理副作用
3.2 架构设计思路
3.2.1 编译沙箱(动态编译与热加载)
编译沙箱负责将 AI 生成的源代码动态编译为可执行代码,并在隔离环境中运行。

r 层级• 编译时字节码校验• 资源配额限制 (CPU/内存/时间)热加载执行层• 动态类加载• 方法级单元测试执行• 执行结果捕获
Java 生态中的隔离编译实现:
javascript
public class IsolatedCompiler {
private final URLClassLoader isolatedClassLoader;
private final JavaCompiler compiler;
public CompilationResult compile(String sourceCode, List<String> dependencies) {
// 1. 创建隔离的类加载器
URL[] urls = dependencies.stream()
.map(this::toUrl)
.toArray(URL[]::new);
try (URLClassLoader classLoader = new URLClassLoader(urls, getParentLoader())) {
// 2. 准备编译任务
StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null);
JavaFileObject sourceFile = new InMemoryJavaFile("GeneratedClass", sourceCode);
// 3. 设置编译选项
List<String> options = Arrays.asList(
"-classpath", buildClassPath(dependencies),
"-d", tempOutputDir.getAbsolutePath()
);
// 4. 执行编译
CompilationTask task = compiler.getTask(
null, fileManager, diagnosticCollector, options, null, List.of(sourceFile)
);
boolean success = task.call();
// 5. 返回结果
return new CompilationResult(success, diagnosticCollector.getDiagnostics());
} catch (Exception e) {
return new CompilationResult(false, List.of(), e);
}
}
}3.2.2 运行时隔离与安全策略
运行时隔离是沙箱技术的核心。不同语言生态有不同的隔离方案:
| 隔离级别 | 技术方案 | 适用场景 | 开销 |
|---|---|---|---|
| 进程级 | 独立 JVM/Node 进程 | 高安全要求 | 高 |
| 容器级 | Docker/Kubernetes Pod | 完全隔离 | 中 |
| 虚拟机级 | Firecracker/gVisor | 云原生环境 | 中 |
| 语言级 | SecurityManager/Policy | Java 生态 | 低 |
| 沙箱库 | vm2/isolated-vm | JS 生态 | 低 |
Java 进程级隔离的安全策略配置:
javascript
public class SecureSandbox {
public SandboxResult executeInSandbox(CompiledClass clazz, SandboxConfig config) {
// 1. 创建安全管理器
SecurityManager securityManager = new RestrictiveSecurityManager(config);
System.setSecurityManager(securityManager);
// 2. 设置资源限制
Thread executionThread = new Thread(() -> {
try {
// 3. 在隔离上下文中执行
Object instance = clazz.newInstance();
Method method = clazz.getMethod(config.getEntryMethod());
Object result = method.invoke(instance, config.getParameters());
// 4. 捕获结果
context.setResult(result);
} catch (Exception e) {
context.setError(e);
}
});
// 5. 设置超时
executionThread.start();
executionThread.join(config.getTimeoutMillis());
if (executionThread.isAlive()) {
executionThread.interrupt();
return SandboxResult.timeout(config.getTimeoutMillis());
}
return context.toResult();
}
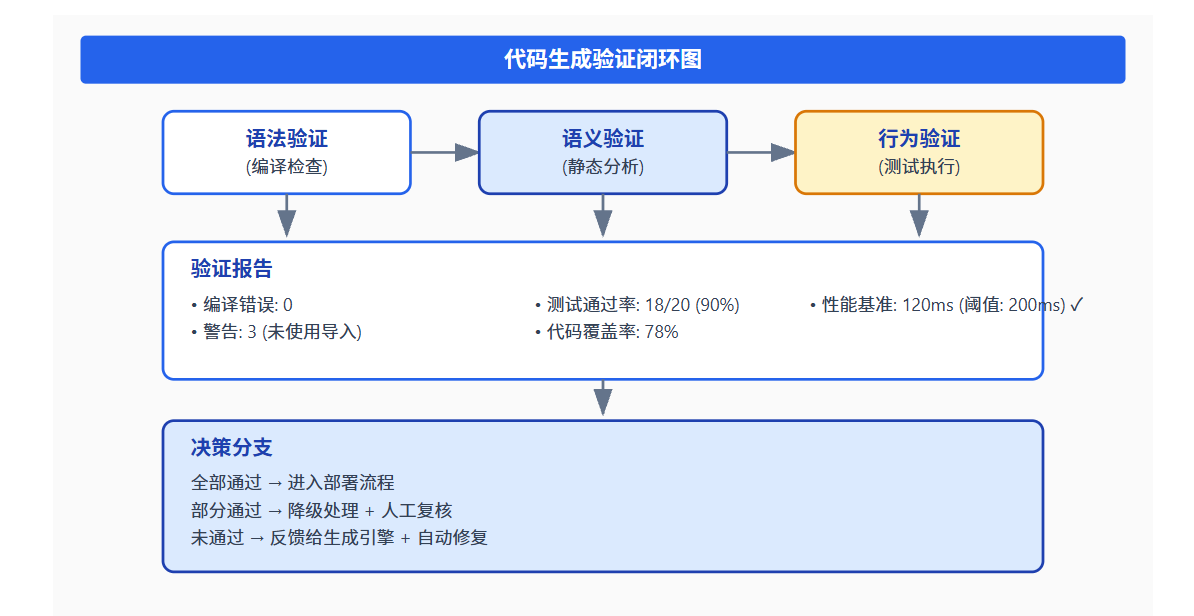
}3.2.3 代码生成验证闭环
验证闭环是沙箱技术的最终目标------确保生成的代码在语法、语义、行为三个层面都正确。
3.2.4 增量编译与依赖管理
AI 生成代码的特点是高频、小批量、快速迭代。全量编译在这种场景下效率极低,必须支持增量编译:
javascript
public class IncrementalCompiler {
private final Map<String, Long> compiledChecksums = new ConcurrentHashMap<>();
public CompilationResult compileIncrementally(List<SourceFile> files) {
List<SourceFile> changedFiles = files.stream()
.filter(f -> isChanged(f))
.collect(Collectors.toList());
if (changedFiles.isEmpty()) {
return CompilationResult.cached();
}
// 1. 分析变更影响范围
Set<String> affectedClasses = analyzeImpact(changedFiles);
// 2. 仅编译受影响文件
CompilationResult result = compile(affectedClasses);
// 3. 更新校验和
changedFiles.forEach(f -> compiledChecksums.put(f.getPath(), f.getChecksum()));
return result;
}
private boolean isChanged(SourceFile file) {
Long lastChecksum = compiledChecksums.get(file.getPath());
return lastChecksum == null || lastChecksum != file.getChecksum();
}
}3.2.5 错误回滚与降级策略
沙箱验证失败时,系统需要有明确的回滚和降级策略:
| 失败类型 | 回滚策略 | 降级方案 |
|---|---|---|
| 编译错误 | 清理临时文件,释放资源 | 返回骨架代码 + 错误说明 |
| 测试失败 | 回滚数据库事务 | 返回基础实现 + 失败测试列表 |
| 超时 | 强制终止进程 | 标记为"需优化",返回简化版 |
| 安全违规 | 立即终止,记录审计日志 | 返回安全审查报告 |
| 资源耗尽 | 回收资源,清理临时数据 | 建议优化资源使用 |
3.3 关键技术挑战与解决方案
挑战 1:编译性能瓶颈
问题:AI 高频生成代码导致编译队列堆积。
解决方案:
- 编译缓存:基于内容寻址的编译缓存,相同输入直接返回缓存结果
- 编译集群:水平扩展编译节点,支持并行编译
- 预编译依赖:将常用依赖预编译为共享库,减少重复编译
挑战 2:依赖冲突与版本地狱
问题:AI 生成的代码可能引入与现有项目冲突的依赖。
解决方案:
- 依赖冲突检测:在编译前扫描依赖树,检测版本冲突
- 依赖隔离:每个沙箱实例拥有独立的依赖空间
- 版本推荐:基于项目现有依赖,推荐兼容版本
挑战 3:安全边界划定
问题:过度限制会影响正常功能验证,限制不足则存在安全风险。
解决方案:
- 分级安全策略:根据代码来源(内部模板/AI生成/外部导入)设置不同安全级别
- 行为白名单:只允许执行明确授权的操作
- 审计日志:完整记录所有沙箱内的操作,支持事后追溯
3.4 企业落地实践建议
- 分层沙箱策略:开发环境使用轻量级沙箱,生产环境使用重量级隔离
- 资源配额管理:为每个团队/项目分配沙箱资源配额,防止滥用
- 与 CI/CD 集成:将沙箱验证作为 CI 流水线的一环,自动化执行
- 性能基线建立:为常见场景建立编译和测试性能基线,超基线时告警
- 故障演练:定期进行沙箱逃逸演练,验证隔离有效性
方向四:基础技术底座
4.1 核心概念解释
基础技术底座是支撑 AI-IDE 运行的底层协议、通信机制和扩展框架。如果说前三个方向是 AI-IDE 的"智能层",那么基础技术底座就是"连接层"------它定义了不同 Agent 之间如何通信、人与 Agent 之间如何交互、Agent 的能力如何被组织和调度。
企业级 AI-IDE 不是单一 Agent 的独角戏,而是多 Agent 协作的交响乐团。基础技术底座就是这个乐团的"指挥系统"和"乐谱规范"。
4.2 架构设计思路
4.2.1 A2A(Agent-to-Agent)通信协议设计
A2A 协议定义了 AI-IDE 内部不同 Agent 之间的通信规范。一个完整的 A2A 协议应包含:

SkillCard 协议示例:
javascript
{
"protocolVersion": "1.0",
"skillId": "skill-crud-generator-001",
"name": "CRUD 代码生成器",
"description": "根据实体定义生成完整的增删改查代码",
"version": "2.3.1",
"provider": {
"agentId": "agent-codegen-01",
"endpoint": "http://codegen.internal:8080",
"capabilities": ["java", "spring-boot", "mybatis"]
},
"inputSchema": {
"type": "object",
"required": ["entityName", "fields"],
"properties": {
"entityName": { "type": "string" },
"fields": { "type": "array", "items": { "$ref": "#/definitions/Field" } }
}
},
"outputSchema": {
"type": "object",
"properties": {
"entityCode": { "type": "string" },
"serviceCode": { "type": "string" },
"controllerCode": { "type": "string" }
}
},
"qos": {
"timeoutMs": 30000,
"retryPolicy": "EXPONENTIAL_BACKOFF",
"maxRetries": 3
}
}4.2.2 P2A(Person-to-Agent)交互协议
P2A 协议定义了人类用户与 AI Agent 的交互规范。关键设计要点:
- 多模态输入支持:文本、语音、图形、手势
- 渐进式披露:根据置信度决定展示信息的完整度
- 澄清机制:当意图不明确时,主动发起澄清请求
- 上下文保持:跨会话保持用户偏好和历史状态
javascript
public interface P2AProtocol {
// 用户发起交互
InteractionResult interact(UserInput input, SessionContext context);
// 系统主动澄清
ClarificationRequest requestClararation(Ambiguity ambiguity);
// 渐进式披露
DisclosureLevel determineDisclosureLevel(double confidence, UserPreference preference);
// 上下文同步
void syncContext(SessionContext context);
}4.2.3 P2P(Peer-to-Peer)协作协议
P2P 协议支持 AI-IDE 节点之间的去中心化协作,特别适用于分布式团队和多环境部署场景。
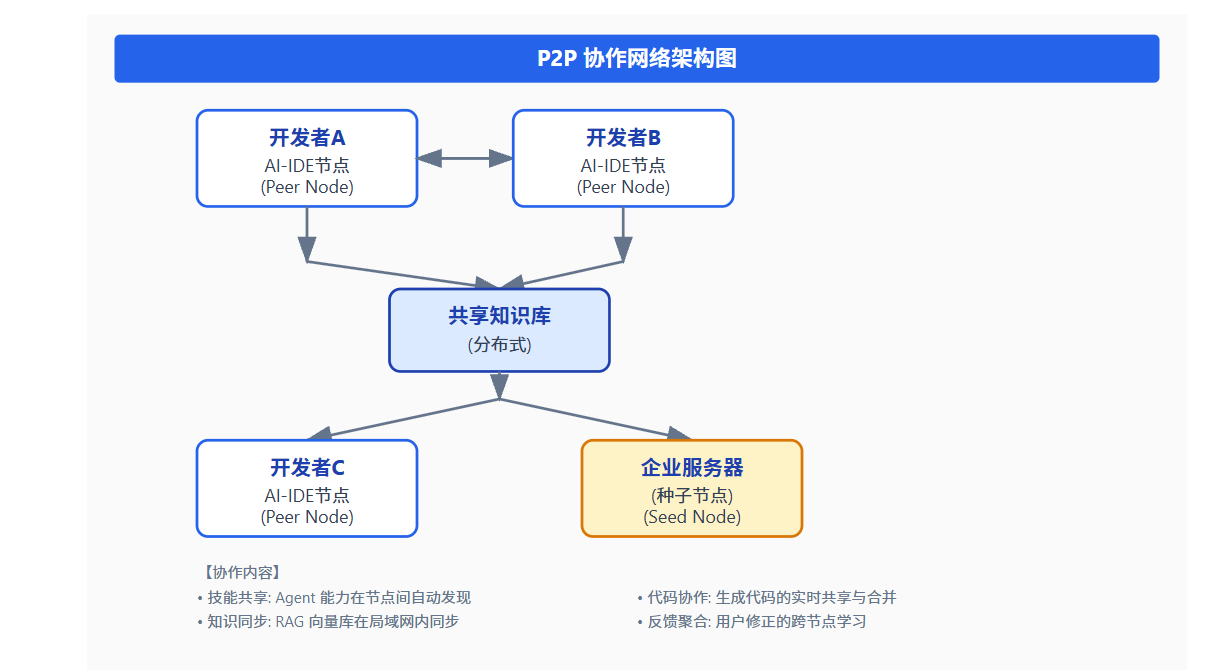
P2P 协作的关键机制:
javascript
public class P2PCollaborationManager {
// 节点发现
public List<PeerNode> discoverPeers() {
// mDNS 广播 + 注册中心查询
return peerDiscoveryService.findPeers();
}
// 技能共享
public void shareSkill(SkillCard skill, PeerNode target) {
SkillShareMessage message = new SkillShareMessage(skill);
message.sign(privateKey); // 数字签名防篡改
transport.send(target, message);
}
// 知识同步
public void syncKnowledge(KnowledgeBase local, PeerNode peer) {
KnowledgeDelta delta = local.diff(peer.getKnowledgeVersion());
if (!delta.isEmpty()) {
transport.send(peer, new KnowledgeSyncMessage(delta));
}
}
// 共识机制(用于共享反馈学习)
public boolean reachConsensus(FeedbackEvent event, List<PeerNode> peers) {
// 简单多数共识
int approvals = peers.stream()
.mapToInt(p -> p.validateFeedback(event) ? 1 : 0)
.sum();
return approvals > peers.size() / 2;
}
}4.2.4 Agent 能力编排与调度
Agent 能力编排是将多个独立 Agent 组合成复杂工作流的能力。核心组件包括:
- Agent Registry:Agent 注册与发现
- Workflow Engine:工作流定义与执行
- Orchestrator:动态编排与调度
- Circuit Breaker:故障隔离与熔断
javascript
public class AgentOrchestrator {
public WorkflowResult executeWorkflow(WorkflowDefinition workflow, Context context) {
WorkflowResult result = new WorkflowResult();
for (WorkflowStep step : workflow.getSteps()) {
// 1. 发现可用 Agent
List<Agent> candidates = agentRegistry.findAgents(step.getRequiredCapabilities());
// 2. 选择最优 Agent
Agent selected = agentSelector.select(candidates, step, context);
// 3. 执行(带熔断保护)
try {
CircuitBreaker cb = circuitBreakerManager.getBreaker(selected.getId());
StepOutput output = cb.execute(() -> selected.execute(step.getInput(), context));
result.addStepOutput(step.getId(), output);
} catch (CircuitBreakerOpenException e) {
// 熔断开启,尝试备用 Agent
Agent fallback = agentSelector.selectFallback(candidates, selected);
StepOutput output = fallback.execute(step.getInput(), context);
result.addStepOutput(step.getId(), output);
}
// 4. 上下文传递
context.mergeOutput(step.getId(), output);
}
return result;
}
}4.2.5 Skill 能力底座(插件化、可扩展)
Skill 是 Agent 能力的原子单元。Skill 底座的设计目标是让扩展像安装 App 一样简单。

Skill 接口定义:
javascript
public interface Skill {
// 元数据
SkillMetadata getMetadata();
// 能力声明
List<Capability> getCapabilities();
// 执行入口
SkillResult execute(SkillContext context, Map<String, Object> parameters);
// 生命周期回调
default void onInstall() {}
default void onActivate() {}
default void onDeactivate() {}
default void onUninstall() {}
}
public class SkillMetadata {
private String skillId;
private String name;
private String version;
private String author;
private List<String> dependencies; // 依赖的其他 Skill
private List<String> permissions; // 所需权限
}4.2.6 可视化工具集合(架构图、流程图、数据流)
AI-IDE 需要提供丰富的可视化工具,帮助用户理解系统架构、数据流和业务流程。
| 可视化类型 | 用途 | 技术方案 | 数据源 |
|---|---|---|---|
| 架构图 | 展示系统组件关系 | C4 Model / ArchiMate | 代码注解 + 依赖分析 |
| 流程图 | 展示业务流程 | BPMN 2.0 | 工作流定义 |
| 数据流图 | 展示数据流转 | DFD (Data Flow Diagram) | 数据库 Schema + API 定义 |
| 时序图 | 展示交互时序 | UML Sequence | 调用链追踪 |
| 思维导图 | 展示知识关联 | Custom Graph | 知识图谱 |
可视化工具的生成管线:
javascript
源代码/配置 ──→ 解析器 ──→ 中间表示 (IR) ──→ 布局引擎 ──→ 渲染器 ──→ SVG/Canvas4.3 关键技术挑战与解决方案
挑战 1:协议兼容性
问题:不同厂商的 AI-IDE 使用不同的通信协议,难以互操作。
解决方案:
- 协议适配器:为常见协议(MCP、A2A、OpenAI Function Calling)提供适配层
- 标准推进:参与行业标准制定,推动协议统一
- 网关模式:通过协议网关实现异构系统的互联互通
挑战 2:Agent 发现与信任
问题:在开放网络中,如何发现可信的 Agent?
解决方案:
- 数字证书:Agent 身份通过 X.509 证书认证
- 信誉系统:基于历史交互建立 Agent 信誉评分
- 白名单机制:企业内网仅允许白名单内的 Agent 注册
挑战3:Skill 依赖地狱
问题:Skill A 依赖 Skill B v1.0,Skill C 依赖 Skill B v2.0,产生冲突。
解决方案:
- 语义化版本:Skill 采用 SemVer,明确兼容性范围
- 依赖隔离:每个 Skill 拥有独立的依赖空间
- 依赖解析算法:类似 npm/yarn 的依赖解析机制
4.4 企业落地实践建议
- 统一协议网关:企业内部所有 Agent 通信必须经过协议网关,便于管控
- Skill 审核机制:第三方 Skill 必须经过安全审核才能进入企业市场
- 分级网络策略:核心系统 Agent 部署在隔离网络,通过网关与外部通信
- 监控与告警:建立 Agent 通信监控,异常流量实时告警
- 文档化协议:所有内部协议必须有完整的文档和示例
方向五:工程能力分层与数据飞轮
5.1 核心概念解释
工程能力分层是指将 AI-IDE 的质量保障体系按照测试范围和复杂度划分为多个层次,从单元测试到集成测试再到端到端测试,形成完整的验证金字塔。数据飞轮则是指通过收集用户反馈、系统运行数据,持续优化 AI 模型的闭环机制------用得越多,系统越聪明。
这两个概念的结合是 AI-IDE 从"可用"走向"好用"的关键:工程能力分层确保生成质量的可控性,数据飞轮确保系统能力的持续进化。
5.2 架构设计思路
5.2.1 Harness 技术验证框架(分层测试策略)
Harness 技术验证框架是 AI-IDE 质量保障的核心。与传统测试框架不同,Harness 框架需要处理概率性输出------AI 生成的代码每次可能不同,传统"通过/失败"的二元判断不再适用。
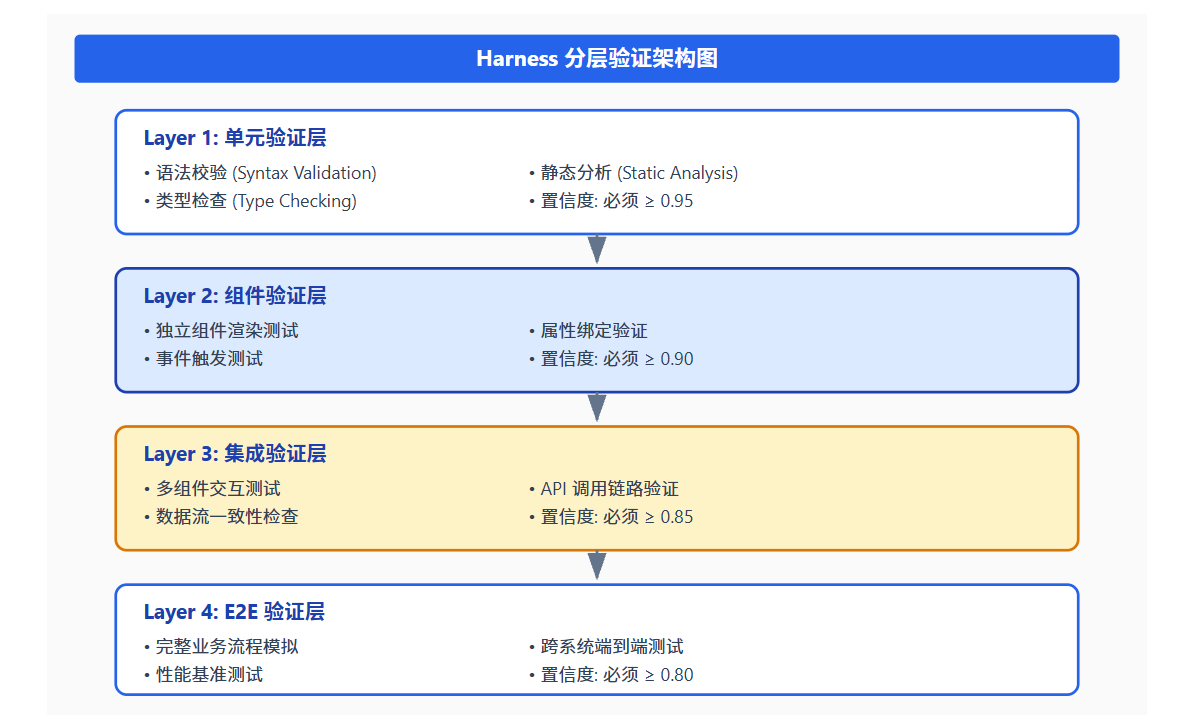
Harness 框架的核心数据结构:
javascript
public class HarnessResult<T> {
private final T data; // 实际数据
private final double confidence; // 置信度 0.0-1.0
private final String source; // 来源: SKILL / LLM / RULE / HYBRID
private final List<String> harnessLog; // 驾驭日志
private final boolean requiresReview; // 是否需要人工复核
private final List<String> suggestions; // 改进建议
private final DisclosureLevel disclosureLevel; // 披露级别
public boolean isReliable() {
return confidence >= 0.85;
}
public boolean needsClarification() {
return confidence < 0.60;
}
}5.2.2 单元测试/集成测试/E2E 测试的自动化
AI-IDE 的测试自动化与传统软件有显著差异------测试用例本身也是 AI 生成的。
javascript
public class AITestGenerator {
// 根据生成的代码自动推导测试用例
public List<TestCase> generateTestCases(GeneratedCode code, TestLevel level) {
List<TestCase> cases = new ArrayList<>();
switch (level) {
case UNIT:
// 为每个 public 方法生成边界值测试
for (Method method : code.getPublicMethods()) {
cases.addAll(generateBoundaryTests(method));
cases.addAll(generateNullTests(method));
}
break;
case INTEGRATION:
// 为组件交互生成集成测试
for (ComponentInteraction interaction : code.getInteractions()) {
cases.add(generateIntegrationTest(interaction));
}
break;
case E2E:
// 基于用户意图生成端到端测试
cases.add(generateE2ETest(code.getOriginalIntent()));
break;
}
return cases;
}
}测试自动化的关键指标:
| 指标 | 定义 | 目标值 |
|---|---|---|
| 测试生成覆盖率 | AI 自动生成测试覆盖的代码比例 | ≥ 80% |
| 测试通过率 | 生成测试的执行通过率 | ≥ 95% |
| 误报率 | 通过的测试中发现实际缺陷的比例 | ≤ 5% |
| 测试生成时间 | 从代码生成到测试生成完成的耗时 | ≤ 30s |
5.2.3 数据飞轮:用户反馈 → 模型微调 → 质量提升
数据飞轮是 AI-IDE 持续进化的核心机制。其运转逻辑如下:
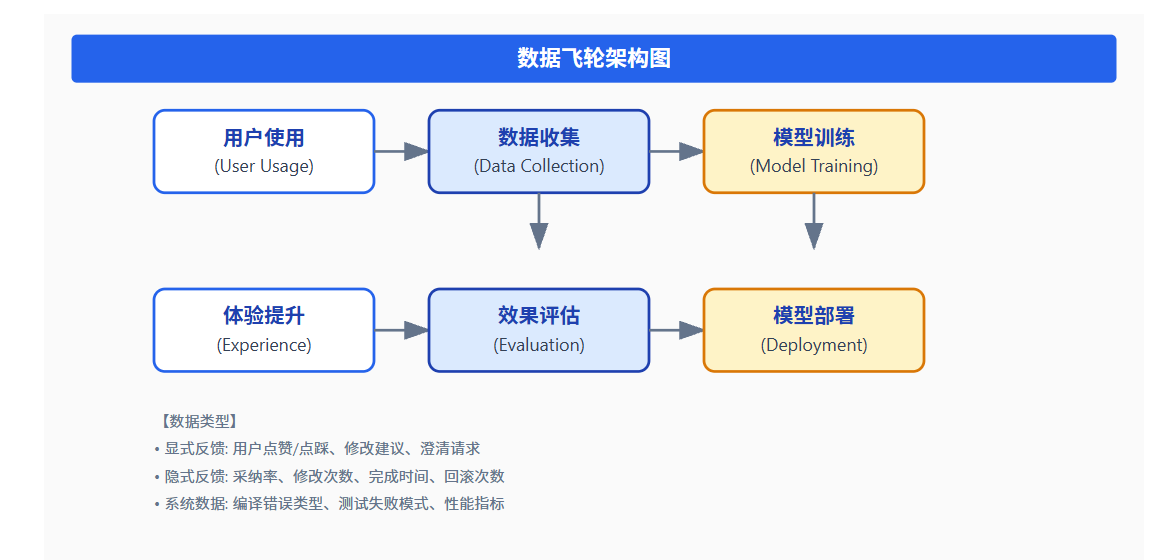
数据飞轮的关键组件:
javascript
public class DataFlywheel {
private final FeedbackCollector collector;
private final TrainingDataBuilder builder;
private final ModelFineTuner fineTuner;
private final EffectivenessEvaluator evaluator;
public void processFeedback(FeedbackEvent event) {
// 1. 收集反馈
collector.collect(event);
// 2. 构建训练数据
TrainingSample sample = builder.build(event);
// 3. 触发训练(当积累足够数据时)
if (shouldTriggerTraining()) {
FineTuningJob job = fineTuner.submit(getRecentSamples(BATCH_SIZE));
// 4. 评估效果
EvaluationResult result = evaluator.evaluate(job.getModelId());
// 5. 决策:部署或回滚
if (result.getImprovement() > DEPLOYMENT_THRESHOLD) {
deployModel(job.getModelId());
} else {
log.info("模型改进不足,跳过部署: {}" , result.getImprovement());
}
}
}
private boolean shouldTriggerTraining() {
return collector.getPendingCount() >= MIN_BATCH_SIZE
&& timeSinceLastTraining() >= MIN_INTERVAL_HOURS;
}
}5.2.4 A/B 测试与效果度量
A/B 测试是验证模型改进效果的金标准。在 AI-IDE 中,A/B 测试需要关注:
- 模型版本对比:新模型 vs 旧模型的生成质量
- 功能特性对比:新功能是否真正提升用户体验
- 参数调优对比:不同参数配置的效果差异
javascript
public class ABTestFramework {
public void runExperiment(ExperimentDefinition exp) {
// 1. 流量分配
TrafficSplitter splitter = new TrafficSplitter(exp.getTrafficPercentage());
// 2. 对照组与实验组
for (UserRequest request : incomingRequests) {
Variant variant = splitter.assign(request.getUserId());
AIModel model = variant.isControl()
? modelRegistry.getBaseline()
: modelRegistry.getExperiment(exp.getModelId());
// 3. 执行并记录
GenerationResult result = model.generate(request);
metrics.record(variant, result, request);
}
// 4. 统计分析
ExperimentReport report = analyzeResults(exp);
if (report.isStatisticallySignificant() && report.isPositive()) {
promoteToBaseline(exp.getModelId());
}
}
}核心度量指标:
| 维度 | 指标 | 说明 |
|---|---|---|
| 生成质量 | 语法正确率 | 生成代码无编译错误的比例 |
| 生成质量 | 语义正确率 | 生成代码符合用户意图的比例 |
| 生成质量 | 测试通过率 | 生成代码通过自动测试的比例 |
| 用户体验 | 采纳率 | 用户直接使用生成结果的比例 |
| 用户体验 | 修改次数 | 用户平均修改次数 |
| 用户体验 | 完成时间 | 从输入到完成的时间 |
| 系统效率 | 生成延迟 | 从请求到输出的延迟 |
| 系统效率 | Token 消耗 | 平均每次生成的 Token 数 |
| 系统效率 | 缓存命中率 | 缓存避免重复生成的比例 |
5.2.5 持续交付与灰度发布
AI-IDE 的持续交付需要特别考虑模型版本的管理:

5.3 关键技术挑战与解决方案
挑战 1:反馈数据稀疏
问题:用户不会每次都提供明确反馈,导致训练数据不足。
解决方案:
- 隐式反馈挖掘:从用户行为(采纳、修改、删除)推断满意度
- 主动采样:对置信度边缘的生成结果,主动请求用户反馈
- 合成数据:通过数据增强技术生成合成训练样本
挑战 2:模型退化(Model Drift)
问题:随着时间推移,模型性能逐渐下降。
解决方案:
- 持续监控:建立模型性能监控Dashboard,关键指标实时告警
- 自动回滚:当性能下降超过阈值时,自动回滚到上一个稳定版本
- 定期重训练:设定固定周期(如每周)进行模型重训练
挑战 3:A/B 测试的统计显著性
问题:AI-IDE 的用户量可能不足以在合理时间内达到统计显著性。
解决方案:
- 分层实验:按用户属性(部门、项目类型)分层,提高实验灵敏度
- 代理指标:用短期可观测的代理指标(如采纳率)替代长期指标(如满意度)
- 贝叶斯方法:采用贝叶斯 A/B 测试,减少所需样本量
5.4 企业落地实践建议
- 建立数据治理规范:明确哪些数据可以收集、存储多久、谁可以访问
- 反馈激励机制:通过积分、排名等方式激励用户提供反馈
- 效果度量委员会:定期评审核心指标,决策模型上线/下线
- 故障演练:定期进行模型故障演练,验证回滚机制有效性
- 合规审查:确保数据收集和模型训练符合企业合规要求
总结与展望
五大技术方向的协同关系
AI-IDE 的五大技术方向并非孤立存在,而是相互支撑、协同演进的有机整体:
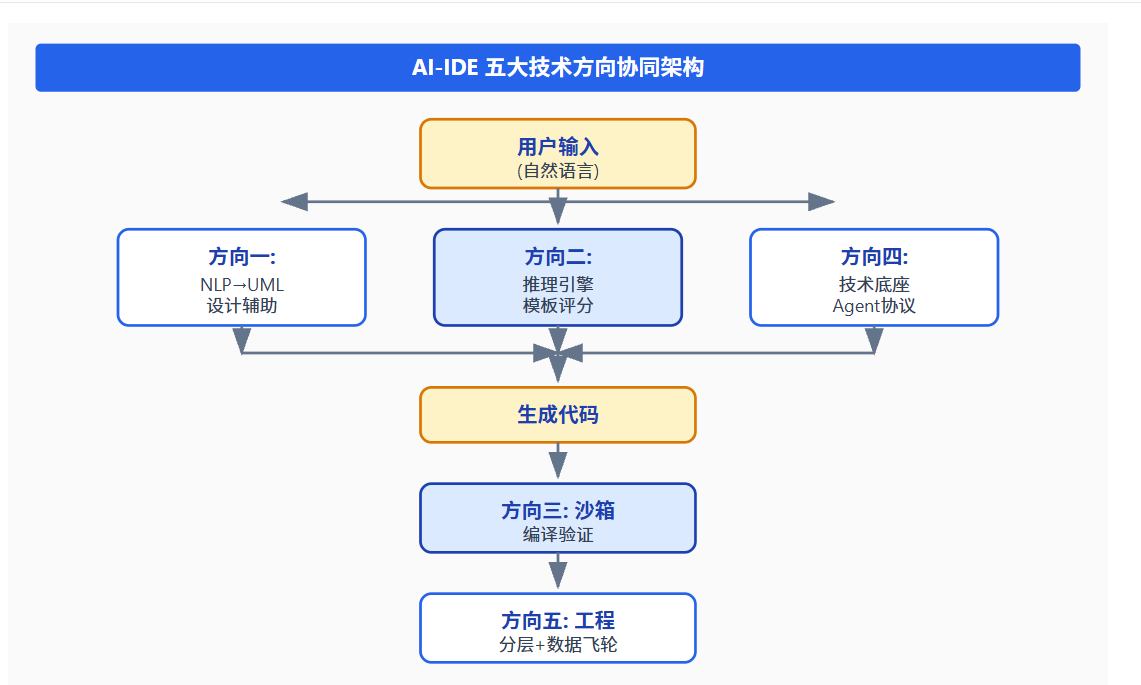
- **方向一(NLP→UML)**提供用户交互入口,将自然语言转化为结构化设计
- **方向二(推理引擎)**提供智能决策能力,选择最优实现方案
- **方向三(沙箱)**提供质量保障,确保生成代码的安全性和正确性
- **方向四(技术底座)**提供连接能力,支持多 Agent 协作和扩展
- **方向五(工程分层+数据飞轮)**提供持续进化能力,让系统越用越好
未来演进趋势
- 多模态融合:从纯文本输入扩展到语音、草图、手势等多模态输入
- 自主 Agent 网络:AI-IDE 不再是被动的工具,而是主动的"数字员工",能够自主规划、执行、汇报
- 联邦学习:跨企业、跨组织的模型协作训练,在保护隐私的前提下共享知识
- 形式化验证:用数学方法证明生成代码的正确性,从根本上消除 Bug
- 具身智能:AI-IDE 与物理世界的交互,支持物联网、机器人等场景的代码生成
最后的话
构建企业级 AI-IDE 不是简单的技术堆砌,而是一场软件工程范式的根本性变革。它要求我们从"确定性工程"的思维定式中解放出来,学会与概率性系统共处------不是消除不确定性,而是驾驭不确定性。
Harness Engineering 方法论告诉我们:好的 AI 系统不是不出错的系统,而是出错时知道如何优雅处理的系统。渐进式披露、置信度量化、反馈闭环------这些概念将成为新一代软件工程师的核心素养。
在 AI 原生开发的时代,企业的竞争力将不再取决于"能写多少代码",而取决于"能多快、多准地将业务意图转化为可运行的软件"。AI-IDE 正是这一转化过程的加速器。
技术栈参考:
- 后端:Java 17/21 + Spring Boot 3.x
- 前端:自主 UI 框架 (ood.UI)
- AI 层:多模型路由 (OpenAI / DeepSeek / 私有化部署)
- 协议:A2A / P2A / P2P 四层协议栈
- 沙箱:隔离 JVM + Docker 容器
- 数据:SQLite (开发) / PostgreSQL + Milvus (生产)
本文基于企业级 AI-IDE 架构实践撰写,所有设计思路均来自真实项目经验。技术演进永无止境,愿与各位架构师、开发者共同探索 AI 原生开发的无限可能。