一、前言
在大数据开发的学习过程中,我们经常会遇到这样的场景:关系型数据库(MySQL、Oracle等)中存储着大量的业务数据,需要将这些数据迁移到Hadoop生态(HDFS、Hive、HBase)中进行离线分析;或者将Hadoop中分析后的结果数据导回关系型数据库供业务系统使用。
手动编写JDBC代码进行数据迁移?效率太低且容易出错。这时候就需要一款专业的数据迁移工具------Sqoop。
本文将结合我在大数据创新编程课程 中的学习经验,从Sqoop的安装配置讲起,深入讲解RDBMS与Hadoop之间的双向数据迁移,涵盖全部导入、查询导入、增量导入、Hive/HBase导入、数据导出以及脚本打包等完整实战案例。
二、Sqoop概述
2.1 什么是Sqoop?
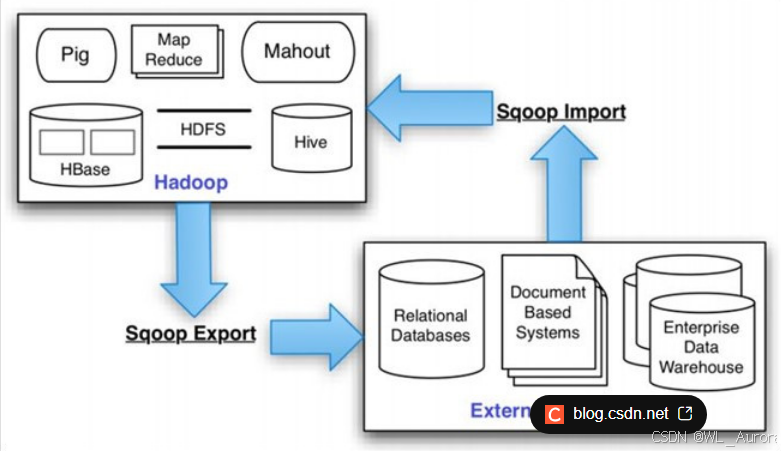
Sqoop (SQL To Hadoop )是一款开源的数据迁移工具,主要用于在Hadoop(Hive)与传统的关系型数据库(MySQL、Oracle、PostgreSQL等)之间进行数据的传递。
- ✅ 可以将关系型数据库中的数据导入到Hadoop的HDFS中
- ✅ 可以将HDFS中的数据导出到关系型数据库中
2.2 Sqoop的发展历史
Sqoop项目始于2009年 ,最早作为Hadoop的一个第三方模块存在。后来为了便于使用者快速部署和开发人员快速迭代,Sqoop独立成为Apache顶级项目。
⚠️ 重要提示 :Sqoop2的最新版本是1.99.7,但2与1不兼容且特征不完整 ,不建议用于生产环境。本文及生产环境均使用Sqoop 1.4.6版本。
2.3 Sqoop工作原理
Sqoop的核心原理非常简单:将导入或导出命令翻译成MapReduce程序来实现。
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 用户输入命令 │────▶│ Sqoop解析命令 │────▶│ 生成MapReduce │
│ (import/export)│ │ (翻译为MR程序) │ │ Job并提交执行 │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│
▼
┌─────────────────┐
│ 定制InputFormat │
│ (从MySQL读取) │
│ 定制OutputFormat│
│ (写入HDFS/MySQL)│
└─────────────────┘在翻译出的MapReduce中,主要是对InputFormat (从MySQL读取到Hive/HBase)和OutputFormat(从HDFS读取到MySQL)进行定制。
三、Sqoop安装与环境配置
3.1 安装前提
安装Sqoop前,必须确保以下环境已就绪:
| 依赖 | 版本要求 | 说明 |
|---|---|---|
| Java | JDK 1.8+ | Sqoop基于Java开发 |
| Hadoop | 2.x / 3.x | 需要Hadoop环境支持MapReduce |
| Hive | 3.x(可选) | 如需导入Hive则需要 |
| HBase | 2.x(可选) | 如需导入HBase则需要 |
💡 注意 :Sqoop类似于Flume,它不需要常驻进程(没有bin/sbin启动文件),只有在执行任务时才启动,执行完就退出。
3.2 下载并解压
bash
# 1. 下载地址(以1.4.6版本为例)
wget http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
# 2. 上传安装包到虚拟机并解压到指定目录
tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/3.3 修改配置文件
Sqoop的配置文件位于安装目录下的conf文件夹中。
步骤1:重命名配置文件
bash
cd /opt/module/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/conf/
mv sqoop-env-template.sh sqoop-env.sh步骤2:修改sqoop-env.sh
bash
vim sqoop-env.sh根据你的实际环境路径,添加以下内容:
bash
# ============================================
# Sqoop环境变量配置
# ============================================
# Hadoop Common模块路径
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
# Hadoop MapReduce模块路径(通常与HADOOP_COMMON_HOME相同)
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
# Hive安装路径(如需要导入Hive)
export HIVE_HOME=/opt/module/hive-3.1.2/
# ZooKeeper安装路径(如需要)
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.7.1/
export ZOOCFGDIR=/opt/module/zookeeper-3.7.1/
# HBase安装路径(如需要导入HBase)
export HBASE_HOME=/opt/module/hbase-2.4.15/3.4 拷贝JDBC驱动
Sqoop需要通过JDBC连接MySQL,因此需要将MySQL的JDBC驱动包拷贝到Sqoop的lib目录:
bash
cp mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/lib/3.5 验证安装
3.5.1 查看帮助命令
bash
cd /opt/module/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/
bin/sqoop help预期输出(部分):
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information3.5.2 测试数据库连接
bash
# 测试连接MySQL,列出所有数据库
bin/sqoop list-databases \
--connect jdbc:mysql://hadoop102:3306/ \
--username root \
--password 123456预期输出:
information_schema
metastore
mysql
oozie
performance_schema如果能看到数据库列表,说明Sqoop安装配置成功!🎉
四、数据导入(Import):RDBMS → Hadoop
在Sqoop中,**"导入"**指的是:从非大数据集群(RDBMS)向大数据集群(HDFS、Hive、HBase)中传输数据 ,使用import关键字。
4.1 RDBMS导入到HDFS
4.1.1 准备测试数据
首先在MySQL中创建测试数据库和表:
sql
-- 登录MySQL
mysql -uroot -p000000
-- 创建数据库
CREATE DATABASE company;
-- 创建员工表
CREATE TABLE company.staff(
id INT(4) PRIMARY KEY NOT NULL AUTO_INCREMENT,
name VARCHAR(255),
sex VARCHAR(255)
);
-- 插入测试数据
INSERT INTO company.staff(name, sex) VALUES('Thomas', 'Male');
INSERT INTO company.staff(name, sex) VALUES('Catalina', 'FeMale');
INSERT INTO company.staff(name, sex) VALUES('Mike', 'Male');4.1.2 全部导入
将MySQL表中的全部数据导入到HDFS指定目录:
bash
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"参数详解:
| 参数 | 说明 |
|---|---|
--connect |
JDBC连接URL |
--username / --password |
数据库用户名/密码 |
--table |
要导入的表名 |
--target-dir |
HDFS目标目录 |
--delete-target-dir |
如果目标目录已存在,先删除(避免报错) |
--num-mappers 1 |
启动1个MapTask(默认4个) |
--fields-terminated-by "\t" |
字段分隔符为制表符 |
💡 技巧 :命令中的反斜杠
\用于换行,防止Linux直接执行命令。
运行结果验证:
bash
hdfs dfs -ls /user/company/user/company/_SUCCESS # MapReduce执行成功标记
/user/company/part-m-00000 # 实际数据文件
bash
hdfs dfs -cat /user/company/part-m-000001 Thomas Male
2 Catalina FeMale
3 Mike Male4.1.3 查询导入(Query Import)
通过SQL查询语句导入指定条件的数据:
bash
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'SELECT name, sex FROM staff WHERE id <= 2 AND $CONDITIONS;'⚠️ 重要注意事项:
- 必须包含
$CONDITIONS:这是Sqoop用于数据分片的占位符,保证最终导入数据的顺序和原始数据一致 - 使用单引号 :如果SQL语句用双引号,则
$CONDITIONS前必须加反斜杠转义(\$CONDITIONS),防止Shell识别为变量 - 查询结果不能包含重复字段
错误示例(双引号未转义):
bash
--query "SELECT name,sex FROM staff WHERE name = 'mike' AND \$CONDITIONS;"4.1.4 导入指定列
只导入表中的部分字段:
bash
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--columns id,sex \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"💡 注意 :
--columns中多列用逗号分隔,不要添加空格!
运行结果(只有id和sex两列):
1 Male
2 FeMale
3 Male4.1.5 使用WHERE条件筛选导入
bash
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--table staff \
--where "id=1"💡
where可以与columns搭配使用,实现更灵活的数据筛选。
4.2 RDBMS导入到Hive
Sqoop可以直接将MySQL数据导入到Hive表中,无需手动创建Hive表(Sqoop会自动创建)。
bash
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table staff_hive参数详解:
| 参数 | 说明 |
|---|---|
--hive-import |
将数据导入到Hive |
--hive-overwrite |
覆盖Hive表中已存在的数据 |
--hive-table |
指定导入到Hive的表名(默认使用MySQL表名) |
执行过程解析:
Step 1: MySQL ──import──▶ HDFS临时目录 (/user/用户名/staff/)
Step 2: HDFS临时目录 ──move──▶ Hive仓库目录 (/user/hive/warehouse/staff_hive/)
Step 3: 删除HDFS临时目录验证:
sql
hive> SELECT * FROM staff_hive;4.3 RDBMS导入到HBase
Sqoop可以直接将MySQL数据导入到HBase中,通过MapReduce直接写入HBase表,不需要中间结果写入HDFS临时目录。
bash
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--columns "id,name,sex" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_staff" \
--num-mappers 1 \
--split-by id参数详解:
| 参数 | 说明 |
|---|---|
--columns |
指定要导入的列 |
--column-family |
HBase列族名 |
--hbase-create-table |
自动创建HBase表(Sqoop 1.4.6仅支持HBase 1.0.1之前版本) |
--hbase-row-key |
指定HBase行键(RowKey) |
--hbase-table |
HBase目标表名 |
--split-by |
指定分片列,提高并行导入效率 |
⚠️ 版本兼容性注意 :Sqoop 1.4.6只支持HBase 1.0.1之前版本 的自动创建表功能。如果使用更高版本HBase,需要手动创建表:
bash
hbase shell
hbase> create 'hbase_staff', 'info'
hbase> scan 'hbase_staff'如果遇到NoSuchMethodError: org.apache.hadoop.hbase.client.HBaseAdmin.<init>报错:
建议下载一个低版本的HBase,将其lib目录下的所有jar包复制到Sqoop的lib目录下,遇到重名文件不要替换。
运行结果:
ROW COLUMN+CELL
1 column=info:name, timestamp=2023-10-07T17:35:59.519, value=Thomas
1 column=info:sex, timestamp=2023-10-07T17:35:59.519, value=Male
2 column=info:name, timestamp=2023-10-07T17:35:59.519, value=Catalina
2 column=info:sex, timestamp=2023-10-07T17:35:59.519, value=FeMale
3 column=info:name, timestamp=2023-10-07T17:35:59.519, value=Mike
3 column=info:sex, timestamp=2023-10-07T17:35:59.519, value=Male
3 row(s)五、数据导出(Export):Hadoop → RDBMS
在Sqoop中,**"导出"**指的是:从大数据集群(HDFS、Hive、HBase)向非大数据集群(RDBMS)中传输数据 ,使用export关键字。
5.1 Hive/HDFS导出到RDBMS
bash
bin/sqoop export \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--num-mappers 1 \
--export-dir /user/hive/warehouse/staff_hive \
--input-fields-terminated-by "\t"参数详解:
| 参数 | 说明 |
|---|---|
--export-dir |
要导出的HDFS源目录 |
--input-fields-terminated-by |
HDFS数据文件的字段分隔符(必须与导入时一致) |
--table |
MySQL目标表名 |
⚠️ 重要 :MySQL中如果表不存在,不会自动创建!需要提前在MySQL中创建好目标表。
防止主键冲突:
sql
-- 清空MySQL表数据
mysql> TRUNCATE TABLE staff;验证导出结果:
sql
mysql> SELECT * FROM staff;+----+----------+--------+
| id | name | sex |
+----+----------+--------+
| 1 | Thomas | Male |
| 2 | Catalina | FeMale |
| 3 | Mike | Male |
+----+----------+--------+⚠️ 如果不加
--input-fields-terminated-by参数:整个数据将会被当做一个字符串存到MySQL表中的第一个字段!
六、增量导入(Incremental Import)
在实际生产环境中,数据是持续增长的。全量导入效率太低,Sqoop支持增量导入,只导入新增或修改的数据。
6.1 Append模式(基于自增ID)
适用于:表中有自增主键,只追加新数据。
bash
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff \
--num-mappers 1 \
--fields-terminated-by "\t" \
--target-dir /user/hive/warehouse/staff_hive \
--check-column id \
--incremental append \
--last-value 3参数详解:
| 参数 | 说明 |
|---|---|
--check-column |
作为增量判断的列名(通常是自增主键) |
--incremental append |
增量模式:追加 |
--last-value |
上次导入的最大值,只导入大于该值的数据 |
⚠️ 注意 :
append不能与--hive-*参数同时使用!(Append mode for hive imports is not yet supported)
6.2 LastModified模式(基于时间戳)
适用于:表中有更新时间戳字段,导入新增和修改的数据。
Step 1:创建带时间戳的表
sql
CREATE TABLE company.staff_timestamp(
id INT(4),
name VARCHAR(255),
sex VARCHAR(255),
last_modified TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
INSERT INTO company.staff_timestamp (id, name, sex) VALUES(1, 'AAA', 'female');
INSERT INTO company.staff_timestamp (id, name, sex) VALUES(2, 'BBB', 'female');Step 2:首次全量导入
bash
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff_timestamp \
--delete-target-dir \
--m 1Step 3:MySQL中新增数据
sql
INSERT INTO company.staff_timestamp (id, name, sex) VALUES(3, 'CCC', 'female');Step 4:增量导入
bash
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 000000 \
--table staff_timestamp \
--check-column last_modified \
--incremental lastmodified \
--last-value "2023-09-28 22:20:38" \
--m 1 \
--append⚠️ 注意:
- 使用
lastmodified方式需要指定增量数据是--append(追加)还是--merge-key(合并)--last-value指定的值会包含于增量导入的数据中(即包含边界值)
七、Sqoop脚本打包(Job自动化)
在实际项目中,Sqoop命令通常需要定时执行 (如每天凌晨同步数据)。将命令打包为脚本文件,可以方便地交给Oozie、Azkaban等任务调度框架执行。
7.1 创建opt脚本文件
bash
# 创建存放脚本的目录
mkdir -p /opt/module/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/opt/
# 创建脚本文件
vim /opt/module/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/opt/job_HDFS2RDBMS.opt脚本内容 (每行一个参数,不能有空格):
properties
export
--connect
jdbc:mysql://hadoop102:3306/company
--username
root
--password
000000
--table
staff
--num-mappers
1
--export-dir
/user/hive/warehouse/staff_hive
--input-fields-terminated-by
"\t"7.2 执行脚本
bash
bin/sqoop --options-file opt/job_HDFS2RDBMS.opt执行前清空MySQL表:
sql
TRUNCATE TABLE staff;验证结果:
sql
SELECT * FROM staff;💡 类似Hive的hql文件 :可以通过
hive -f命令执行hql文件中的命令,Sqoop的opt文件同理。
八、Sqoop常用命令与参数速查表
8.1 常用命令一览
| 序号 | 命令 | 类 | 说明 |
|---|---|---|---|
| 1 | import |
ImportTool | 将数据导入到集群 |
| 2 | export |
ExportTool | 将集群数据导出 |
| 3 | codegen |
CodeGenTool | 获取数据库表数据生成Java并打包Jar |
| 4 | create-hive-table |
CreateHiveTableTool | 创建Hive表 |
| 5 | eval |
EvalSqlTool | 查看SQL执行结果 |
| 6 | import-all-tables |
ImportAllTablesTool | 导入数据库下所有表到HDFS |
| 7 | job |
JobTool | 生成Sqoop任务(不立即执行) |
| 8 | list-databases |
ListDatabasesTool | 列出所有数据库名 |
| 9 | list-tables |
ListTablesTool | 列出数据库下所有表 |
| 10 | merge |
MergeTool | 合并HDFS不同目录的数据 |
| 11 | metastore |
MetastoreTool | 记录Sqoop job的元数据信息 |
| 12 | help |
HelpTool | 打印帮助信息 |
| 13 | version |
VersionTool | 打印版本信息 |
8.2 公用参数:数据库连接
| 参数 | 说明 |
|---|---|
--connect |
连接关系型数据库的URL |
--connection-manager |
指定要使用的连接管理类 |
--driver |
JDBC驱动类 |
--username |
连接数据库的用户名 |
--password |
连接数据库的密码 |
--verbose |
在控制台打印详细信息 |
8.3 Import特有参数
| 参数 | 说明 |
|---|---|
--append |
将数据追加到HDFS已存在的DataSet中 |
--as-avrodatafile |
导入到Avro数据文件 |
--as-sequencefile |
导入到Sequence文件 |
--as-textfile |
导入到普通文本文件(默认) |
--columns <col1,col2> |
指定要导入的字段 |
--m / --num-mappers <n> |
启动N个Map并行导入(默认4个) |
--query / --e <sql> |
通过SQL查询导入(必须含$CONDITIONS) |
--split-by <column> |
按指定列分片(不能与--autoreset-to-one-mapper连用) |
--table <table> |
关系数据库表名 |
--target-dir <dir> |
指定HDFS目标路径 |
--where <condition> |
导入时的WHERE条件 |
--check-column <col> |
增量导入的判断列 |
--incremental <mode> |
增量模式:append或lastmodified |
--last-value <value> |
增量导入的起始标记值 |
8.4 Export特有参数
| 参数 | 说明 |
|---|---|
--export-dir <dir> |
要导出的HDFS源目录 |
--update-key <col> |
对指定列进行更新操作 |
--update-mode <mode> |
updateonly / allowinsert(默认) |
--staging-table <table> |
创建临时表存放事务结果(防错误) |
--clear-staging-table |
导出前清空临时表 |
8.5 Hive相关参数
| 参数 | 说明 |
|---|---|
--hive-import |
将数据导入到Hive表 |
--hive-overwrite |
覆盖Hive表中已存在的数据 |
--create-hive-table |
如果目标表已存在则创建失败(默认false) |
--hive-table <table> |
指定Hive目标表名 |
--hive-partition-key |
创建分区,后跟分区名 |
--hive-partition-value <v> |
导入时指定分区值 |
九、常见问题与解决方案
9.1 缺少JDBC驱动
报错 :java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
解决:
bash
cp mysql-connector-java-*.jar /opt/module/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/lib/9.2 HBase版本不兼容
报错 :NoSuchMethodError: org.apache.hadoop.hbase.client.HBaseAdmin.<init>
解决 :下载低版本HBase的lib目录jar包,复制到Sqoop的lib目录(重名文件不要替换)。
9.3 目标目录已存在
报错 :Target directory already exists
解决 :添加--delete-target-dir参数,或手动删除HDFS目录:
bash
hdfs dfs -rm -r /user/company9.4 导出时主键冲突
报错 :Duplicate entry '1' for key 'PRIMARY'
解决:导出前清空MySQL表:
sql
TRUNCATE TABLE staff;9.5 分隔符不匹配
现象:导出后MySQL中所有数据挤在一个字段
解决 :确保--fields-terminated-by(导入)和--input-fields-terminated-by(导出)参数一致。
十、完整数据链路总结
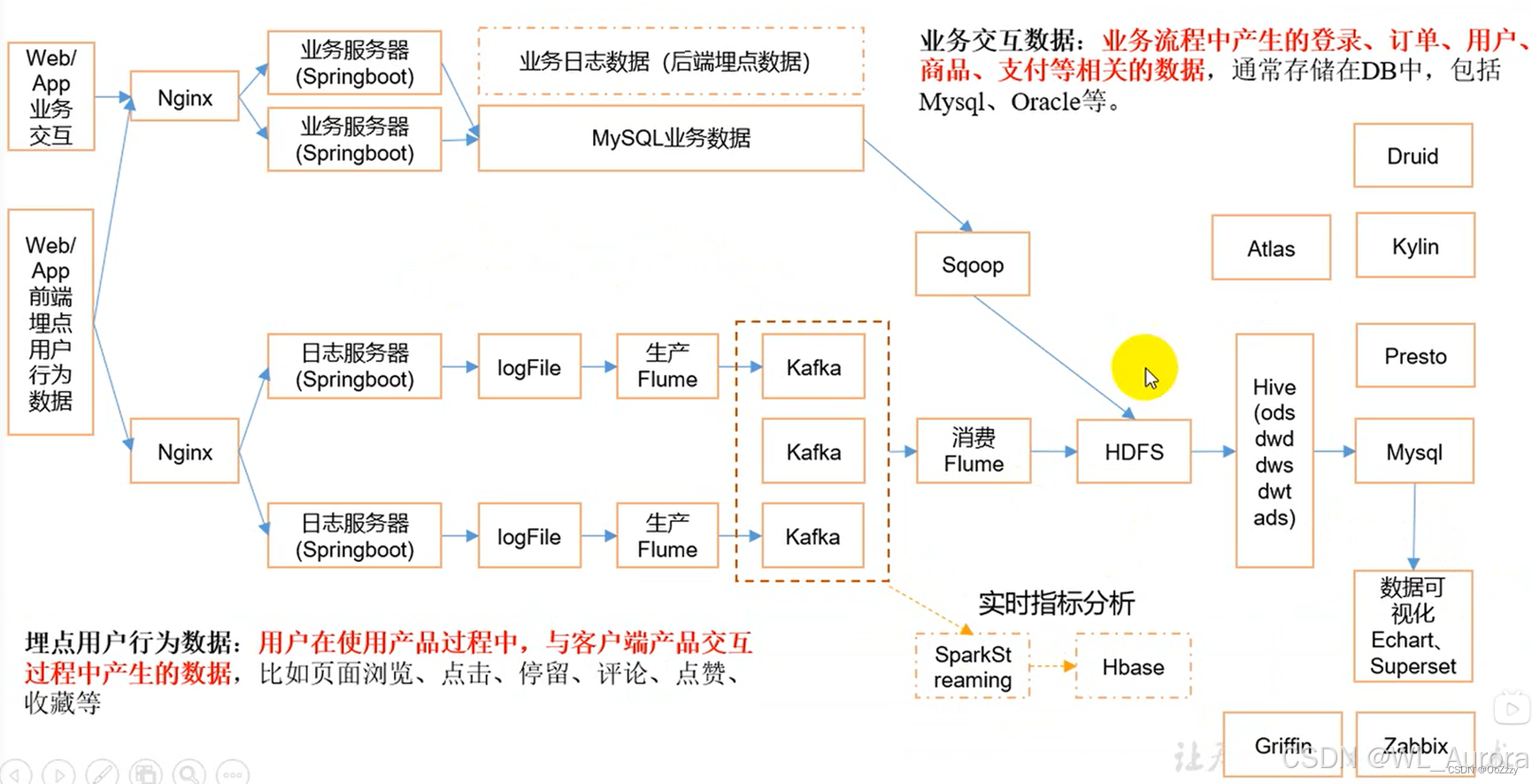
在实际的大数据项目中,Sqoop通常处于数据链路的关键位置:
十一、总结
本文从Sqoop的安装配置出发,系统讲解了RDBMS与Hadoop之间的双向数据迁移:
| 方向 | 场景 | 核心命令 |
|---|---|---|
| 导入 | MySQL → HDFS | sqoop import + --target-dir |
| 导入 | MySQL → Hive | sqoop import + --hive-import |
| 导入 | MySQL → HBase | sqoop import + --hbase-table |
| 导出 | HDFS/Hive → MySQL | sqoop export + --export-dir |
| 增量 | 追加新数据 | --incremental append |
| 增量 | 按时间更新 | --incremental lastmodified |
| 自动化 | 定时任务 | .opt脚本 + 调度框架 |
核心要点回顾:
- ✅ Sqoop将命令翻译为MapReduce程序,高效并行处理
- ✅ 导入时注意
$CONDITIONS占位符和分隔符设置 - ✅ 导出时确保MySQL表已存在且分隔符匹配
- ✅ 增量导入支持
append和lastmodified两种模式 - ✅ 使用
.opt脚本打包命令,便于任务调度