1. 命令行级别的宏定义
vim code.c命令打开一个.c文件进行编辑:
bash
1 #include<stdio.h>
2 #define M
3 int main()
4 {
5 #ifndef M
6 printf("社区版/免费版 version 1\n");
7 #else
8 printf("专业版/收费版 version 2\n");
9 #endif
10 }编译的这段代码代表的含义是:如果没有对M进行宏定义,就输出:社区版/免费版 version 1;
如果对M进行了宏定义就输出:专业版/收费版 version 2。
保存退出后对文件进行编译并运行得出输出结果:
bash
[cyq@VM-0-5-centos ~]$ gcc code.c
[cyq@VM-0-5-centos ~]$ ll
total 20
-rwxrwxr-x 1 cyq cyq 8360 May 16 13:53 a.out
-rw-rw-r-- 1 cyq cyq 162 May 16 13:51 code.c
-rw-rw-r-- 1 cyq cyq 827 May 14 22:11 install.sh
-rw-rw-r-- 1 cyq cyq 0 May 14 22:15 test.c
[cyq@VM-0-5-centos ~]$ ./a.out
专业版/收费版 version 2随后将宏定义注释掉:
bash
1 #include<stdio.h>
2 //#define M
3 int main()
4 {
5 #ifndef M
6 printf("社区版/免费版 version 1\n");
7 #else
8 printf("专业版/收费版 version 2\n");
9 #endif
10 }再次编译运行:
bash
[cyq@VM-0-5-centos ~]$ gcc code.c
[cyq@VM-0-5-centos ~]$ ll
total 20
-rwxrwxr-x 1 cyq cyq 8360 May 16 13:53 a.out
-rw-rw-r-- 1 cyq cyq 162 May 16 13:51 code.c
-rw-rw-r-- 1 cyq cyq 827 May 14 22:11 install.sh
-rw-rw-r-- 1 cyq cyq 0 May 14 22:15 test.c
[cyq@VM-0-5-centos ~]$ ./a.out
社区版/免费版 version 1当然编译过程可以使用对应命令将code.c文件形成一个指定名称的可执行程序并运行:
bash
[cyq@VM-0-5-centos ~]$ gcc code.c -o code
[cyq@VM-0-5-centos ~]$ ll
total 32
-rwxrwxr-x 1 cyq cyq 8360 May 16 13:53 a.out
-rwxrwxr-x 1 cyq cyq 8360 May 16 13:58 code
-rw-rw-r-- 1 cyq cyq 162 May 16 13:51 code.c
-rw-rw-r-- 1 cyq cyq 827 May 14 22:11 install.sh
-rw-rw-r-- 1 cyq cyq 0 May 14 22:15 test.c
[cyq@VM-0-5-centos ~]$ rm ./a.out
[cyq@VM-0-5-centos ~]$ ./code
社区版/免费版 version 1这是我们是没有对M进行宏定义的,想要再次宏定义就得再次打开code.c文件进行编辑,这样就很麻烦,所以这里介绍一条命令,可以进行命令行级别的宏定义:
bash
gcc code.c -o code -DM使用这条命令之后直接在命令行运行便可以看到输出结果中M进行了宏定义:
bash
[cyq@VM-0-5-centos ~]$ gcc code.c -o code -DM
[cyq@VM-0-5-centos ~]$ ll
total 20
-rwxrwxr-x 1 cyq cyq 8360 May 16 14:01 code
-rw-rw-r-- 1 cyq cyq 162 May 16 13:51 code.c
-rw-rw-r-- 1 cyq cyq 827 May 14 22:11 install.sh
-rw-rw-r-- 1 cyq cyq 0 May 14 22:15 test.c
[cyq@VM-0-5-centos ~]$ ./code
专业版/收费版 version 2当然,在上面进行的命令行宏定义中,并没有给定M的值,所以会给默认值:1,如果想要自己设置M的初始值,使用下面的命令即可:
bash
gcc code.c -o code -DM=n演示命令:
bash
[cyq@VM-0-5-centos ~]$ gcc code.c -o code -DM
[cyq@VM-0-5-centos ~]$ ./code
专业版/收费版 version 2 M:1
[cyq@VM-0-5-centos ~]$ gcc code.c -o code -DM=100
[cyq@VM-0-5-centos ~]$ ./code
专业版/收费版 version 2 M:100编译器在编译过程的第一步是预处理。预处理阶段主要包括头文件展开、删除注释、宏替换以及条件编译等操作。从这个角度看,预处理的本质是在正式编译之前对源代码文本进行一系列修改和调整。
在命令行级别进行宏定义时,比如通过**-DM=100** 的编译选项,编译器会将其解释为等同于在源代码中插入一条**#define M 100**的宏定义语句,之后才进入常规的预处理流程。这种做法是合理的,因为它既保持了源码的简洁性,又允许在编译时灵活地控制宏的取值,从而影响后续条件编译和代码生成的逻辑。
2. 条件编译的用途
条件编译在实际开发中具有重要的作用。以上面提到的 code.c中的代码为例,它在编译过程中就运用了条件编译机制。那么,条件编译具体有哪些用途呢?
目前许多编译器和开发工具会分为免费版(社区版)与收费版(专业版)。如果一家公司需要同时维护这两个版本,通常需要分别编写和更新两套独立的代码,这无疑会增加开发和维护成本。通过引入条件编译,可以将专属于专业版功能的代码封装在特定条件模块中,而将免费版与专业版均可运行的代码放在公共模块中。这样,只需维护一份包含条件分支的代码,即可实现在不同版本间的灵活切换,大幅提高维护效率。
因此,条件编译在软件功能分级、版本收费策略区分等场景中尤为重要,它实现了代码的动态裁剪,使同一套代码可适应不同的发布形态。
除了商业软件版本管理,条件编译在系统级开发中同样广泛应用。例如,操作系统内核源码通常借助条件编译,让用户能够根据实际需求,选择启用或禁用特定功能模块,从而生成符合自身场景的内核镜像。这种机制使得内核既保持功能完整性,又兼顾了定制化与精简化的可能。
此外,许多开发工具和应用软件也常借助条件编译来实现跨平台兼容。同一份源代码可在编译时根据目标系统(如 Linux 或 Windows)进行差异化处理,从而生成适应不同操作系统的可执行文件。这不仅提升了代码的复用性,也让用户能够根据自身使用的平台,方便地完成安装和部署。
总的来说,条件编译通过编译时的分支判断,在保持代码逻辑统一的前提下,实现了功能、平台和版本等多维度上的灵活适配。
3. 为什么编译器编译时要变成汇编语言
编程的本质是控制计算机完成特定任务。早期的计算机通过物理开关实现0和1的输入,后来出现了打孔编程,这本质上仍然属于二进制编程,但效率低下且操作不便。随着技术的发展,汇编语言应运而生。汇编语言虽然比二进制直观,但其本质仍是文本形式,因此需要通过编译器翻译成机器可执行的二进制指令。
此后,编程语言继续演进。在汇编语言的基础上,衍生出了许多更高级的语言分支,其中最具代表性的便是C语言。那么随之而来的问题是:应该将C语言直接编译为二进制可执行程序,还是先翻译成汇编语言,再转为二进制?
实际采用的是第二种路径,原因主要有两点:第一,将C语言转化为汇编语言属于文本到文本的转换,技术实现难度相对较低;第二,在C语言诞生之前,汇编语言及相关工具链已经发展了多年,其编译与转换机制相对成熟。因此,采用"C语言→汇编语言→二进制"的转换路径,可以直接借助已有的汇编工具链,相当于站在了前人的技术积累之上。
最终,将C语言编译为对应的汇编代码,再通过汇编器转换为二进制目标文件,之后便可进入链接阶段,生成最终的可执行程序。

打孔编程的打孔纸带
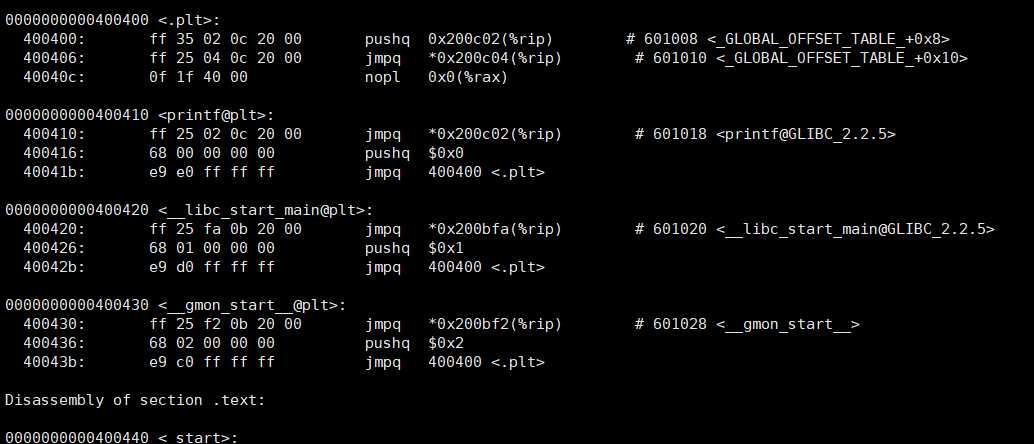
汇编语言示例
接下来就是讨论一个先有鸡还是先有蛋的问题,到底是先有汇编语言还是先用汇编语言编译器呢,答案是先有汇编语言,既然是先有汇编语言,那我如何编译汇编语言呢?答案是先写一个二进制版的编译器用来编译汇编语言,然后再用汇编语言来写一个汇编编译器来替换最早的二进制版编译器,这样就可以使用汇编编译器来写汇编语言了,这个过程称为编译器的**自举过程。**同样的,C语言编译器也是通过自举过程产生的。
4. 动态库与静态库
所谓库,就是一套方法或者数据集,为我们开发提供最基本的保证(基本接口,功能)来加速我们的二次开发。
在Linux系统中,想要查看系统下默认所带的各种库,可以使用下面的指令:
bash
ls /usr/lib64输出结果:
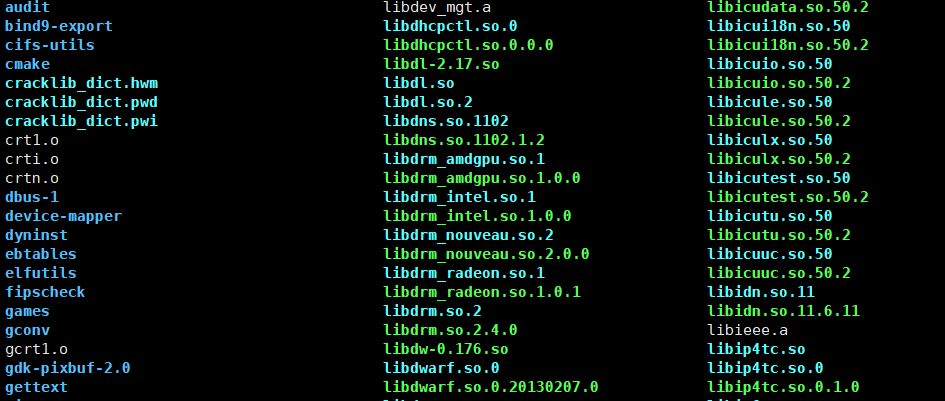
可以看到,以.so结尾的就是动态库文件;以.a结尾的就是静态库文件。
想要知道一个静态库或者一个动态库的名字,只需要除去文件的前缀和后缀,剩下的字符就是库的名字,例如库文件:lisxyz.so,除去前缀"lib"和后缀".so",剩下的"xyz"就是对应的库的名字。
4.1 动态库
在编写程序的过程中,我们经常会调用动态库中已实现的方法。编译时,程序会与动态库中的相关方法进行链接,从而在库中定位所需功能,最终生成可执行文件。动态库的一个主要特点是,当程序需要执行涉及库中的目标方法时,会先跳转到该库中运行对应代码,执行完成后再返回到原程序中继续执行。
在动态链接的过程中,程序里调用动态库的方法会被替换为对应方法在库中的地址。程序执行到相应位置时,便会跳转到库中该地址处运行目标代码,执行结束后再返回主程序的后续流程。
4.2 静态库
静态库的链接过程属于静态链接。当程序调用静态库中的某个方法时,在链接阶段会把该方法的实现代码直接拷贝到最终生成的可执行程序中。这样,程序在运行时就不再需要跳转到外部库文件,而是直接在自身的代码段中执行相关功能。这也是静态库与动态库最显著的区别之一。需要注意的是:静态库只有在链接的时候有用,一旦形成可执行程序,静态库可以不再需要。
4.3 动态库与静态库区别
-
动态库形成的可执行程序体积一定很小;
-
可执行程序对静态库的依赖度小,但是动态库不能缺失;
-
程序运行,需要加载到内存,静态链接的,会在内存中出现大量的重复代码;
-
动态链接比较节省内存和磁盘资源。
补充:
动态库(又称"共享库")与静态库的一个关键区别在于内存管理方式。动态库在编译过程中并不直接将库代码复制到可执行文件中,而是在程序加载时,将所需的库函数映射到内存的共享区域。这意味着,当多个程序使用同一个动态库时,内存中只会保存一份库代码,各个程序通过地址跳转共享该副本。这不仅有效节约内存空间,也便于库的更新和维护。
相反,静态库的代码会在链接阶段被完整拷贝到每一个调用它的可执行程序中。因此,如果多个程序都使用了相同的静态库功能,内存中就会存在多份相同的库代码,造成存储和运行时内存的重复占用。从这个角度看,动态库的核心优势在于实现了代码在内存中的真正共享,提高了资源利用率;而静态库则因代码重复冗余,在内存使用效率上存在明显劣势。
4.4 演示
首先使用vim编辑器写一个简单的程序:
bash
#include<stdio.h>
int main()
{
printf("Hello\n");
return 0;
}然后继续编译并执行:
bash
[cyq@VM-0-5-centos ~]$ vim demo.c
[cyq@VM-0-5-centos ~]$ gcc demo.c -o demo
[cyq@VM-0-5-centos ~]$ ll
total 20
-rwxrwxr-x 1 cyq cyq 8360 May 16 16:30 demo
-rw-rw-r-- 1 cyq cyq 69 May 16 16:30 demo.c
-rw-rw-r-- 1 cyq cyq 827 May 14 22:11 install.sh
-rw-rw-r-- 1 cyq cyq 0 May 14 22:15 test.c
[cyq@VM-0-5-centos ~]$ ./demo
Hello可以看到程序正常运行,那么如果想要查看这个查询调用的是静态库还是动态库,可以使用下面的指令:
bash
ldd [可执行程序名称]输出结果演示:
bash
[cyq@VM-0-5-centos ~]$ ldd demo
linux-vdso.so.1 => (0x00007fffad79f000)
libc.so.6 => /lib64/libc.so.6 (0x00007ff1e9fb4000)
/lib64/ld-linux-x86-64.so.2 (0x00007ff1ea382000)可以观察到调用的库文件libc.so.6后缀为.so,代表是动态库(这里是C标准库),说明默认是动态链接的。
想要查看可执行程序的信息,可以使用下面的指令:
bash
file [可执行程序名称]演示:
bash
[cyq@VM-0-5-centos ~]$ file demo
demo: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=893bb285626aca9b10a4bfb028674b2551785688, not stripped可以观察到,当前可执行程序是64位,executable可执行的,调用的是dynamically linked (uses shared libs)动态库。
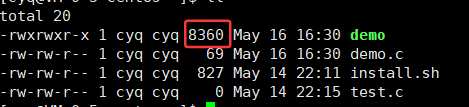
同时通过指令ll输出的结果可以观察到当前可执行程序的体积是8360。
从上面的学习中我们可以发现,对所写程序进行编译时,默认使用的是动态链接(前提是具备相应的动态库文件),想要查看使用的到底是哪个动态库文件,可以使用下面的指令:
bash
指令:
[cyq@VM-0-5-centos ~]$ ldd demo
输出:
linux-vdso.so.1 => (0x00007fffad79f000)
libc.so.6 => /lib64/libc.so.6 (0x00007ff1e9fb4000)#得知使用的是c标准库libc.so
/lib64/ld-linux-x86-64.so.2 (0x00007ff1ea382000)
指令:
[cyq@VM-0-5-centos ~]$ ls /usr/lib64/libc.so*
输出:
/usr/lib64/libc.so /usr/lib64/libc.so.6
指令:
[cyq@VM-0-5-centos ~]$ ls /usr/lib64/libc.so* -l
输出:
-rw-r--r-- 1 root root 253 Jun 4 2024 /usr/lib64/libc.so
lrwxrwxrwx 1 root root 12 Jul 8 2024 /usr/lib64/libc.so.6 -> libc-2.17.so从上面的输出结果可以观察到,printf函数使用的具体动态库文件为:libc-2.17.so,这是被包含在Linux系统中的,所以可以成功的进行动态链接。
如果想要让系统使用静态链接,可以使用如下指令来强制编译器静态链接:
bash
gcc demo.c -o demo -static输出结果:
bash
[cyq@VM-0-5-centos ~]$ gcc demo.c -o demo -static
/usr/bin/ld: cannot find -lc
collect2: error: ld returned 1 exit status可以观察到运行发生了报错:cannot find -lc,代表系统缺少libc.a的静态库文件。如果想要程序能够正常的静态链接,就要对缺失的静态库进行安装,指令如下:
bash
sudo yum install -y glibc-static安装之后想要查看是否安装成功,可以查看路径/usr/lib64/libc*的文件,命令如下:
bash
ls /usr/lib64/libc*
ls /usr/lib64/libc* -l如果输出结果显示了libc.a的文件,就说明安装成功了。
安装成功后再对程序进行静态链接便可以成功运行了:

但从图中的输出结果可以看到,单纯一个printf库函数的调用,使用静态链接的程序体积就达到了861288,这是非常夸张的,所以系统默认动态链接是有原因的。并且使用静态链接的可执行程序查询不到相关的静态库信息:

同时查询可执行程序信息可以得到如下结果,很明显的可以观察到输出结果显示使用的是statically linked静态库:

5. 解决普通用户sudo权限
首先执行下列命令:
bash
ls /etc/sudoers -l输出结果为;
bash
[cyq@VM-0-5-centos ~]$ ls /etc/sudoers -l
-r--r----- 1 root root 4363 Apr 26 15:55 /etc/sudoers可以发现:该文件的拥有者和所属者都是root。
再执行下面命令:
bash
vim /etc/sudoers输出结果为:

可以发现打开编辑器后什么内容也没有,左下角显示:noporm,代表该用户没有权限查看,这是因为当前用户为普通用户,所以想要解决普通用户的sudo权限,要先切换为root超级用户。然后再打开这个编辑器:
bash
[cyq@VM-0-5-centos root]$ su -
Password:
Last login: Sat May 16 20:39:40 CST 2026 on pts/0
[root@VM-0-5-centos ~]# vim /etc/sudoers以root用户的身份打开对应文件之后,可以看到再第100行有如下内容:
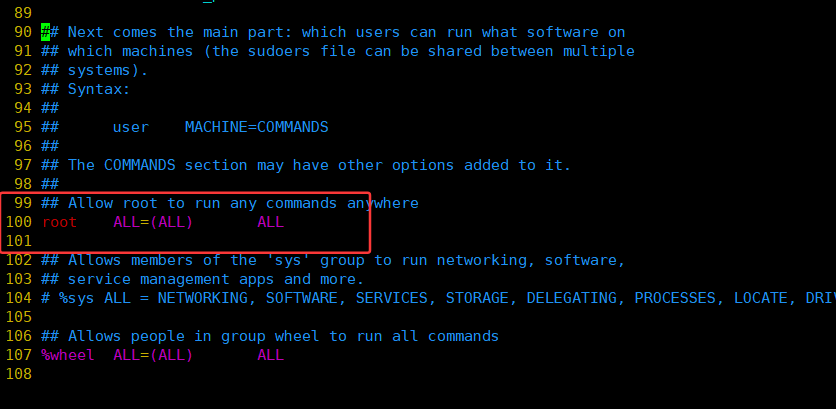
在这一行内容下面加上想要赋予sudo权限的普通用户名称,即可解除普通用户的sudo权限:
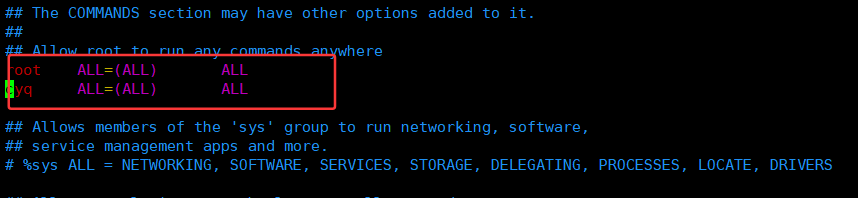
随后按下ctrl+d,便可切回普通用户,再来验证一下普通用户已经可以使用sudo权限了:
bash
[cyq@VM-0-5-centos root]$ sudo ls
hello.txt lesson1 log.txt world.txt顺便提一点:库就是.o文件的集合,链接的本质就是将自己写的程序的,o文件与库中所用.o文件进行合并