基础概念
FTS(全文检索)
FTS(Full-Text Search,全文检索)是针对文本内容的高效模糊 / 关键词搜索,比普通 LIKE 快百倍,支持分词、权重、短语匹配、多字段搜索等核心能力。
示意图:FTS 如何把自然语言查询映射到可检索结果

倒排索引索引的建立流程
示意图:倒排索引构建链路
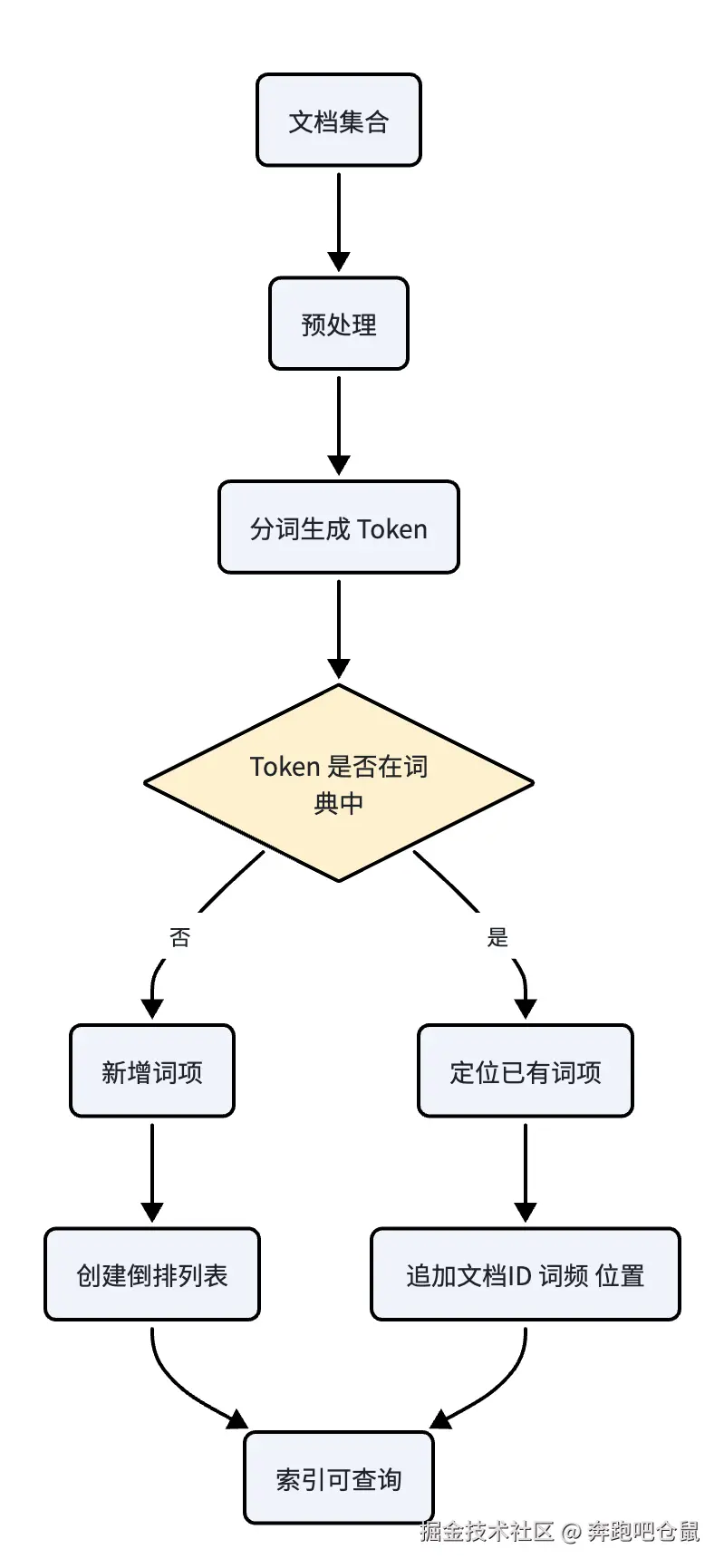
- 文档预处理:对原始文档/记忆进行清洗,包括去除 HTML/XML 标签、去除停用词(如 "的""是""我" 等无意义词汇)、词干提取等操作。
- 分词 :将预处理后的文本拆分为独立的语义单元(Token)。中文场景需使用专用分词器,英文场景则可按空格或标点拆分。例如,"我在中国工作" 会被拆分为
["我", "在", "中国","工作"]。 - 索引构建:遍历所有文档的分词结果,对每个 Token 动态更新词典与倒排列表:
- 若 Token 不在词典中,则将其加入词典,并创建对应的倒排列表;
- 若 Token 已在词典中,则将当前文档 ID、词频、位置信息追加到对应的倒排列表中。
倒排索引的检索流程
示意图:倒排索引检索链路
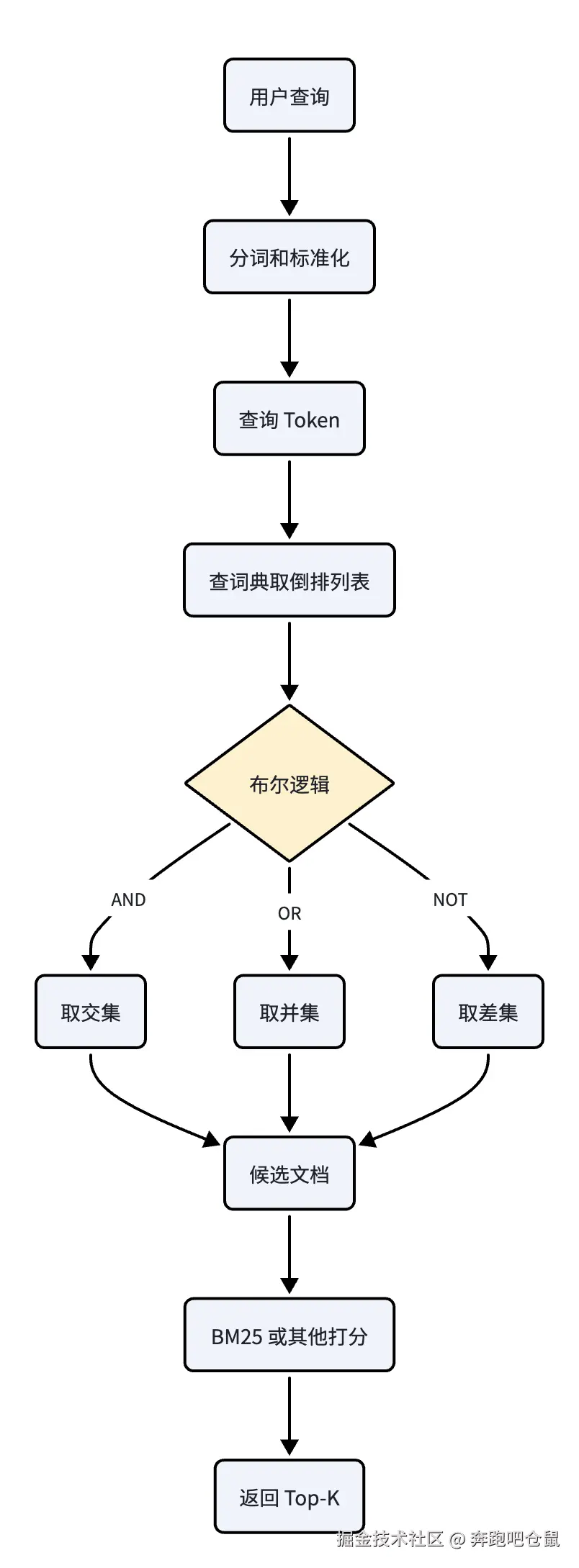
当用户发起查询时,FTS 系统会执行以下步骤快速定位相关文档:
-
查询解析 :对用户查询进行与文档预处理相同的操作(分词、停用词过滤、词干提取等),生成标准化的查询 Token 列表。例如,用户查询 "如何去中国工作" 会被解析为
["中国", "工作"]。 -
词典查找:在倒排索引的词典中查找每个查询 Token 对应的倒排列表。若 Token 不存在于词典中,则直接返回空结果。
-
布尔运算 :根据查询的布尔逻辑(AND/OR/NOT)对多个倒排列表进行集合运算。例如,"
中国AND工作" 需要对两个 Token 的倒排列表执行交集 操作,返回同时包含这两个 Token 的文档 ID;"中国OR工作" 则执行并集操作,返回包含任意一个 Token 的文档 ID。 -
文档打分:对匹配的文档进行相关性打分(如 BM25),按得分从高到低排序,最终返回 Top-K 结果。
- 自建搜索引擎
排序算法
示意图:TF-IDF 到 BM25 的排序直觉
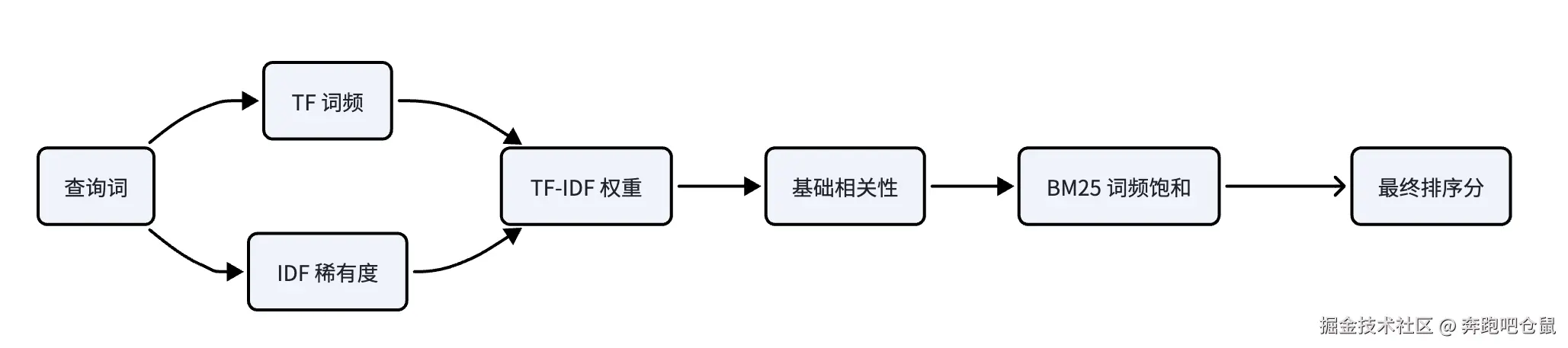
TF-IDF
TF-IDF(词频 - 逆文档频率)是经典的统计加权算法,其核心思想是:关键词在文档中出现的频率越高(TF 越高),且在整个语料库中出现的文档比例越低(IDF 越高),则该关键词对文档的重要性越高。例如,"中国" 在某篇文章中出现 10 次(高 TF),但在整个语料库中仅在 1% 的文档中出现(高 IDF),则该关键词的权重会很高。
实际情况中,过多的重复可能是冗余信息,此时高TF的文章并不一定是希望召回的。
BM25
score(D,Q)=∑i=1nIDF(qi)⋅f(qi,D)+k1⋅(1−b+b⋅avgdl∣D∣)f(qi,D)⋅(k1+1)
例如,当 k1=1.、 b=0.7时,若某查询词在文档中出现 3 次,其对得分的贡献会比出现 1 次高约 2 倍;但当出现次数从 10 次增加到 20 次时,贡献仅会增加约 1.2 倍,有效避免了关键词堆砌的影响。
| 短文本场景(如新闻标题、商品标题) | 长文本场景(如技术文档) | 关键词密集型场景(如代码搜索) |
|---|---|---|
| 降低文档长度惩罚,同时提升词频的影响权重 | 平衡词频与文档长度的影响 | 更关注关键词的精确匹配,而非语义关联,因此需要进一步提升词频的影响权重 |
词典
压缩字典树如何减少公共前缀存储
压缩字典树
ANN 近似最近邻
示意图:从文本到向量检索
向量空间模型
将文本映射为高维向量,通过向量之间的相似度来衡量文本的语义关联。
精确最近邻(kNN)
精确最近邻(k-Nearest Neighbor, kNN)是向量检索的基础算法,其逻辑是遍历向量库中的所有向量,计算查询向量与每个库向量的距离,然后返回距离最近的 Top-K 个向量。kNN 的优势是精度 100% ,但时间复杂度为 O(n×d( 为向量数量,为向量维度)------ 这意味着,当向量数量达到百万级以上时,kNN 的检索延迟会急剧上升至无法接受的程度。
相似度计算
余弦相似度 :衡量两个向量的方向一致性,取值范围为 -1, 1,越接近 1 表示方向越一致(语义越相似)
IVF-PQ
示意图:IVF-PQ 的召回与压缩思路
 倒排文件 + 乘积量化(Inverted File + Product Quantization, IVF-PQ) :结合了聚类分区 与乘积量化 的优势:首先通过 k-means 将所有向量聚类为 nlis个簇,每个簇对应一个倒排列表;然后对每个簇内的向量单独进行 PQ 量化。检索时,先找到与查询向量距离最近的 nprob个簇(而非所有簇),再在这些簇内进行 PQ 检索。
倒排文件 + 乘积量化(Inverted File + Product Quantization, IVF-PQ) :结合了聚类分区 与乘积量化 的优势:首先通过 k-means 将所有向量聚类为 nlis个簇,每个簇对应一个倒排列表;然后对每个簇内的向量单独进行 PQ 量化。检索时,先找到与查询向量距离最近的 nprob个簇(而非所有簇),再在这些簇内进行 PQ 检索。
-
乘积量化(Product Quantization, PQ) :将高维向量均匀划分为 个低维子向量,对每个子向量分别进行聚类(训练码本),然后用聚类中心的索引(码字)来表示每个子向量。最终,整个高维向量可表示为个码字的组合,存储开销显著降低 ------ 例如,将 768 维向量划分为 8 个子向量,每个子向量用 8 位码字表示(对应 256 个聚类中心),则总存储开销为 8×8=6位,仅为原始 FP32 向量(768×32=24576 位)的 0.26%。PQ 的检索过程是:先计算查询向量与每个子向量码本的距离,再通过查表得到近似距离,无需存储原始向量。
-
聚类分区, 首先会从所有向量中随机选一批样本作为初始质心,然后计算每个向量到各质心的距离,把向量分到最近的质心所在簇;接着重新计算每个簇的平均向量作为新质心,重复上述过程,直到质心变化小于阈值或达到最大迭代次数,最终形成稳定的簇结构。分簇时的簇数量(nlist 参数),OpenClaw 默认会根据向量总量动态调整,也支持手动配置。
-
传统无监督聚类(如 K-means 做用户分群)追求 "簇内相似度高、簇间差异大",以发现数据天然结构为目标;而 IVF 里的分簇是工程化手段,核心是为了加速检索,簇数量(nlist)通常远小于传统聚类的 K 值,且允许一定的簇重叠或边界模糊,只要能把 "大概率相似的向量" 圈到少数几个簇里即可。另外,IVF 分簇会和后续的 "精排" 结合,而传统聚类输出的簇标签往往就是最终结果。
对比维度 传统无监督聚类(K-means等) IVF分簇 核心目标 发现数据的天然结构,实现数据的自然分类与业务知识挖掘 工程化的向量检索加速手段,核心是提升大规模向量检索效率、降低检索时延 核心设计原则 严格遵循「簇内相似度高、簇间差异大」,追求聚类结果的可解释性与分类准确性 只要能把「大概率相似的向量」圈到少数几个簇里即可,不追求完美分类效果,优先保证检索效率 簇数量要求 K值通常根据数据分布、业务需求确定,数值相对较大,需覆盖数据全部分类维度 nlist通常远小于传统聚类的K值,仅需划分出能覆盖向量空间的粗粒度分区,无需精细分类 簇边界要求 严格要求簇边界清晰,尽量避免簇重叠,每个样本有唯一明确的簇归属 允许一定的簇重叠、边界模糊,甚至支持向量归属到多个簇,不要求严格的边界划分 结果定位 聚类输出的簇标签就是最终业务结果,可直接用于业务分析、用户分层等场景 分簇结果只是中间过程的索引结构,不是最终业务结果,仅用于检索过程的粗筛环节 后续流程 无额外的精排/二次筛选环节,聚类结果可直接落地应用 必须和后续的「精排」环节结合,粗筛出的候选向量需再做精准相似度计算与排序,输出最终结果 典型应用场景 用户分群、客户分层、画像标签构建、异常检测、数据分类与归档 大规模向量数据库检索、推荐系统召回、图像/文本语义检索、ANN近似最近邻检索场景 对数据结构的要求 需要数据有明确的可聚类特征,对特征区分度要求高,需保证数据结构能支撑天然分类的挖掘 对向量的整体分布有基础要求即可,无需特征有极强的区分度,核心是能通过分簇实现检索范围的快速收敛 -
ANN 近似最近邻 牺牲可接受的少量精度,来换取数量级的检索速度提升
| 场景类型 | FTS 全文检索 | ANN 向量检索 |
|---|---|---|
| 搜索引擎 | 核心召回层,处理 80% 以上的明确意图查询;适用于新闻、电商、代码等精确查询场景 | 辅助召回层,处理模糊语义查询;适用于图像检索、推荐系统、语义搜索等场景 |
| Agent 记忆检索 | 负责精确事实提取(如预算、订单号);适用于短期记忆、程序记忆的检索 | 负责语义上下文关联(如历史偏好、上下文依赖);适用于长期记忆、情景记忆的检索 |
| 其他场景 | 日志分析、代码搜索、文档检索、结构化数据查询 | 图像检索、视频检索、推荐系统、生物信息学、多模态检索 |
Agent 记忆
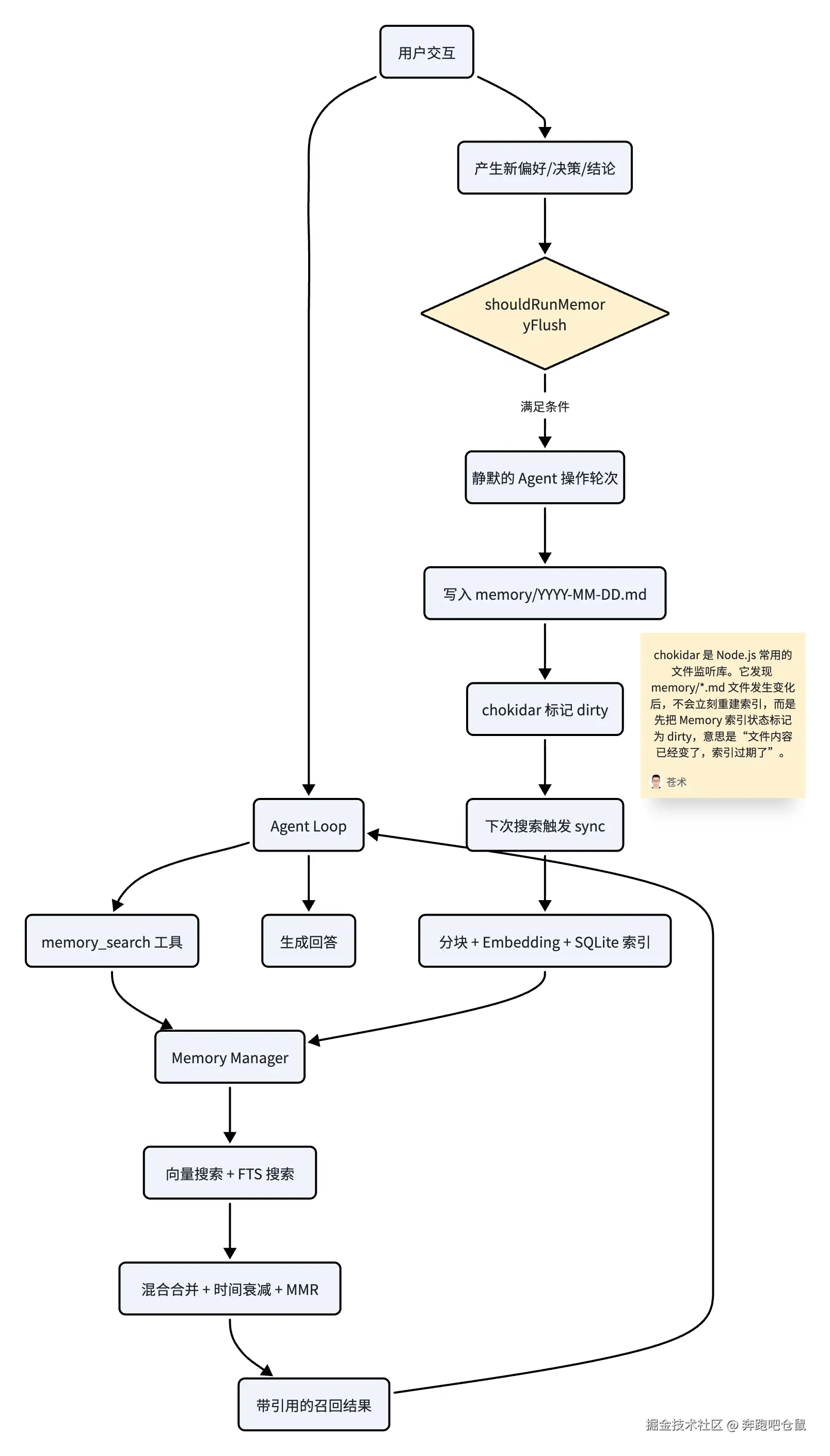
示意图:Agent 记忆分层
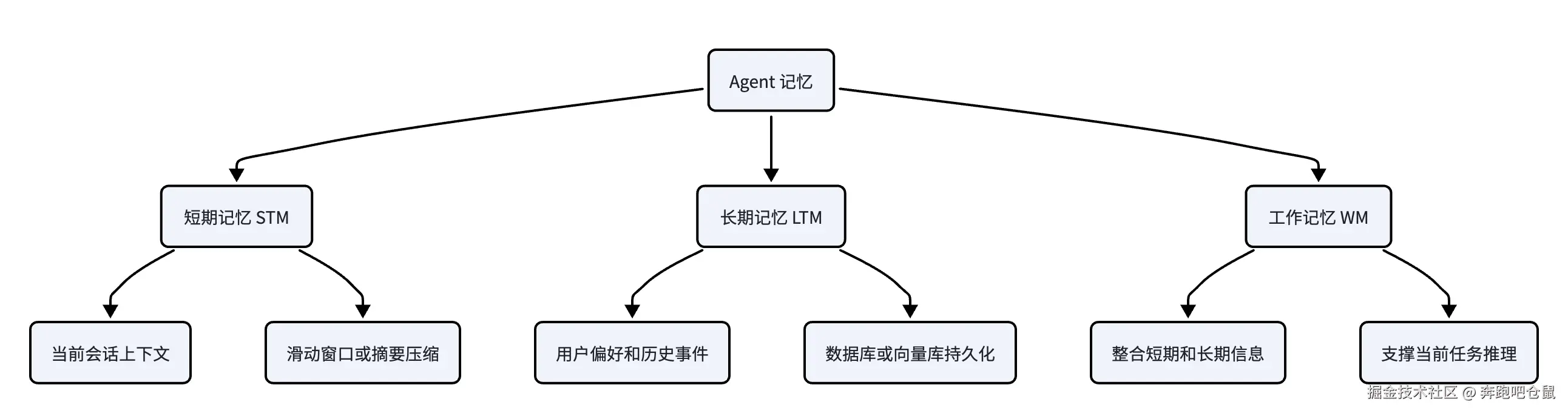
Agent 的记忆通常分为三类,每类记忆的存储与检索需求不同,需要选择不同的技术方案:
- 短期记忆(STM) :记录当前会话的实时上下文,如 "帮我创建活动工作流"、当前任务的步骤(如 "查询到活动包括:活动头像,活动banner,待用户选择")。短期记忆的生命周期通常为一次任务或会话,任务结束即清空。短期记忆的存储通常采用滑动窗口 或摘要压缩策略,以控制 Token 开销 ------ 例如,当会话长度超过 1000 Token 时,Agent 会自动压缩早期的对话内容,保留核心信息。
| 方案 | 信息保留度 | 成本 | 延迟 | 实现复杂度 | 适用场景 | 实现方式 |
|---|---|---|---|---|---|---|
| 滑动窗口 | 低 | 零 | 零 | 最低 | 短对话、闲聊 | 只保留最近 N 轮对话,超出的直接丢弃。 |
| LLM 摘要 | 中高 | 高 | 高 | 低 | 中等长度任务型对话 | 超过 token 阈值时,调用 LLM 把历史对话总结成一段摘要文本。 |
| 摘要+窗口混合 | 高 | 中 | 中 | 中 | Agent 场景推荐 | 早期消息用 LLM 摘要压缩,最近 N 轮保持原文。 |
| 向量检索 RAG | 中 | 低 | 低 | 高 | 知识库问答、跨会话记忆 | 把所有历史消息向量化存入向量数据库,每次请求时根据当前问题检索最相关的 K 条历史。 |
| 结构化记忆 | 中 | 低 | 低 | 最高 | 长期用户画像、多会话 | 从对话中提取实体、关系、事实,存成结构化知识(知识图谱或 key-value),而不是存原始消息。 |
| Token 压缩 | 中高 | 低 | 低 | 中 | 高吞吐、低延迟场景 | 在 token 级别用小模型判断每个 token 的信息量,去掉冗余 token。 |
| 长上下文模型 | 最高 | 最高 | 高 | 零 | 预算充足、对话不超长 |
- 长期记忆(LTM) :跨会话持久化的信息,如用户的偏好、习惯使用的图片生成模型、长期任务的上下文。长期记忆的生命周期是持久化的,需要外部存储支持(如数据库、向量数据库)。长期记忆又可细分为情景记忆(记录具体事件)、语义记忆(记录结构化知识,如 "礼物设计常用的生图模型")和程序记忆(记录技能 / 工作流,如 "用户已经创建好的活动头图翻译工作流")。
- 工作记忆(WM) :动态整合短期与长期记忆的临时存储,用于 Agent 的决策推理过程。工作记忆的核心作用是将短期记忆与长期记忆的信息整合为 Agent 可利用的格式,支撑 Agent 的响应生成。
不同类型的记忆需要不同的存储设计:
-
短期记忆 :通常存储在内存中,采用滑动窗口 或摘要压缩策略,以控制 Token 开销 ------ 例如,eino 框架的短期记忆模块,默认采用滑动窗口策略,保留最近的 n 轮对话内容;
-
长期记忆 :通常存储在外部数据库中,采用分层存储策略 ------ 例如,将情景记忆存储为文本,将语义记忆存储为向量,将程序记忆存储为结构化数据;
-
工作记忆 :通常存储在内存中,采用临时缓存策略,在 Agent 完成当前任务后自动清空。
这个记忆检索流程 为什么先混排(id合并)再排序,而不是像搜索引擎一样先粗排/精排排序再混排。
搜索引擎 排序与 Agent 记忆混排的差异
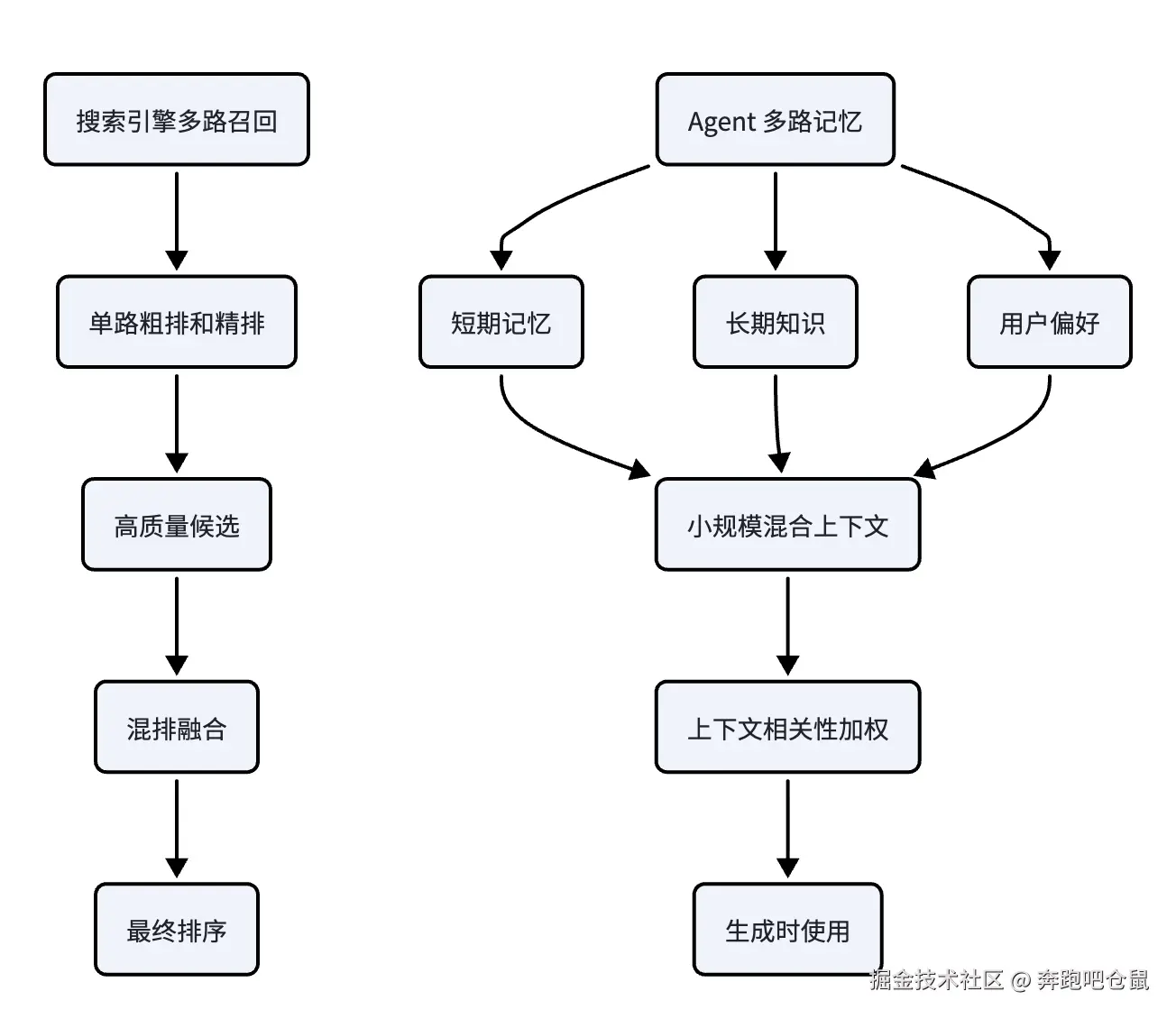
存储和检索时候向量化方式不同怎么办
不同模型的训练数据、网络结构、目标任务都可能不同,对文本语义的编码逻辑就有差异。生成的向量,维度可能不同,向量空间分布也不一样。
OpenClaw 默认要求向量化和检索使用同一模型,通过配置强制绑定。若手动混用不同模型,会因向量空间不一致导致检索失效,此时系统可能静默降级为关键词匹配。解决需统一模型,或通过claw.adapt_tensor()生成张量适配器对齐格式,但官方更推荐前者。
-
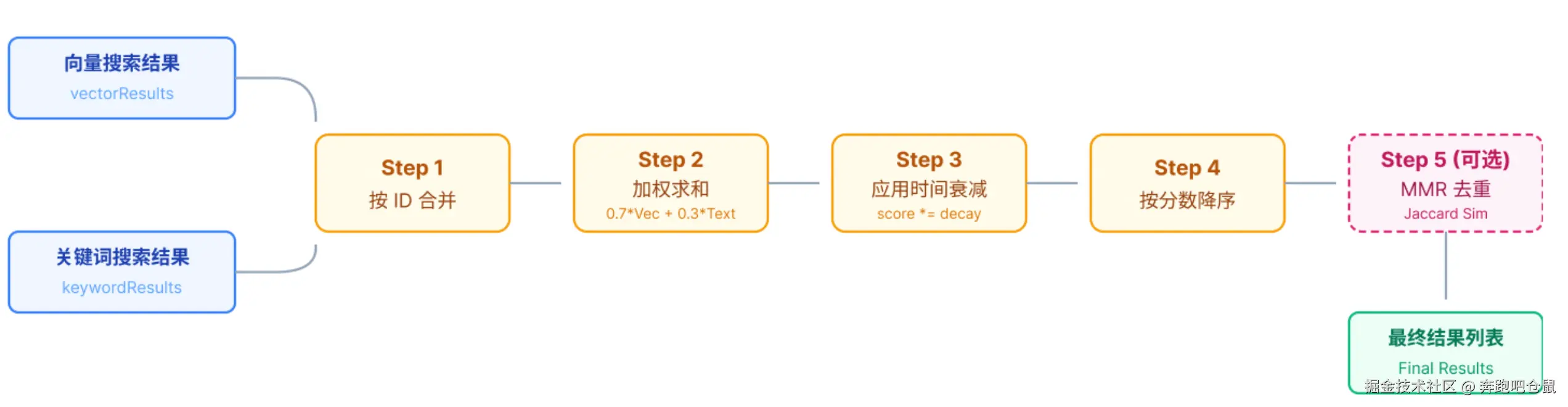
混合搜索 :70% 向量 + 30% 关键词的双引擎设计,
buildFtsQuery实现 Unicode 感知分词 -
BM25 转换 :
bm25RankToScore将负数 rank 映射到 (0, 1),公式为relevance / (1 + relevance) -
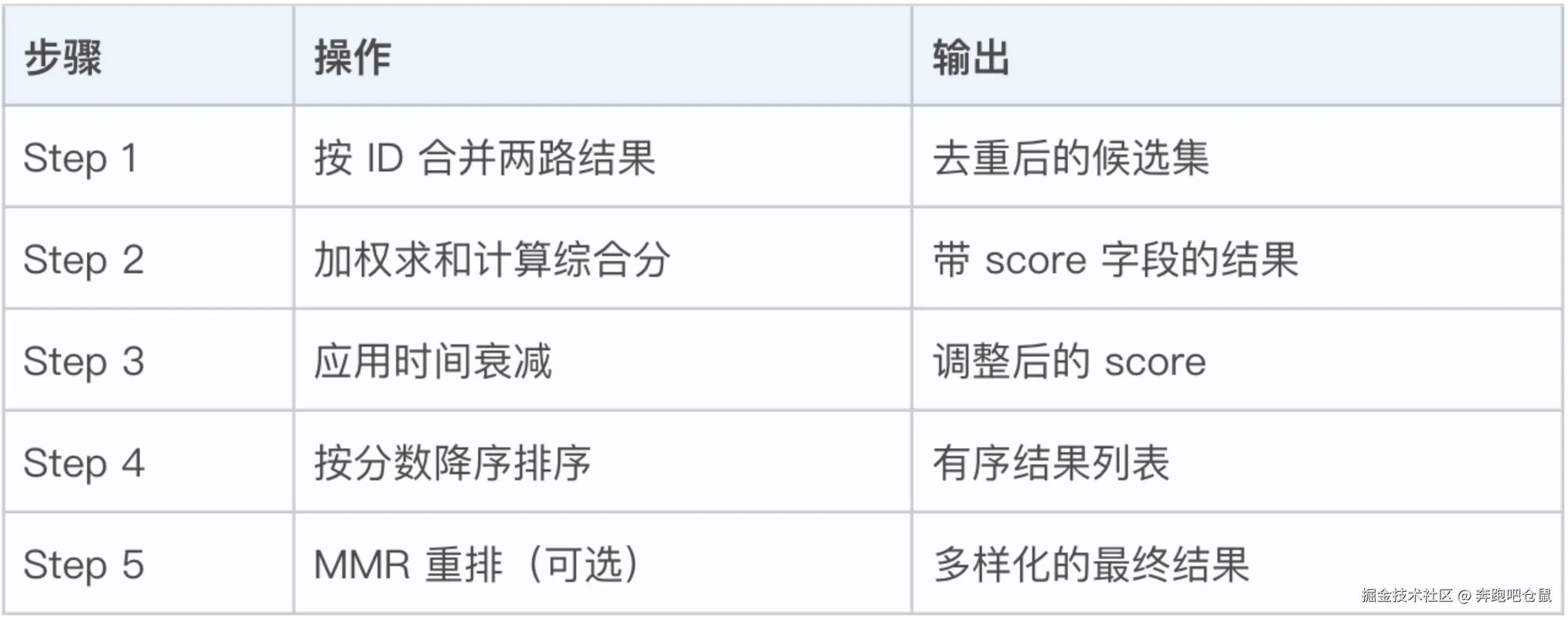
五步合并:按 ID 去重 → 加权求和 → 时间衰减 → 排序 → MMR 重排
-
MMR 算法 :基于 Jaccard 相似度的贪心迭代,
λ=0.7平衡相关性与多样性 -
时间衰减 :指数衰减模型,30 天半衰期,常青记忆(MEMORY.md)永不衰减
-
工程思维:选择 Jaccard 而非余弦相似度,是"够用即可"的务实决策
记忆权重机制
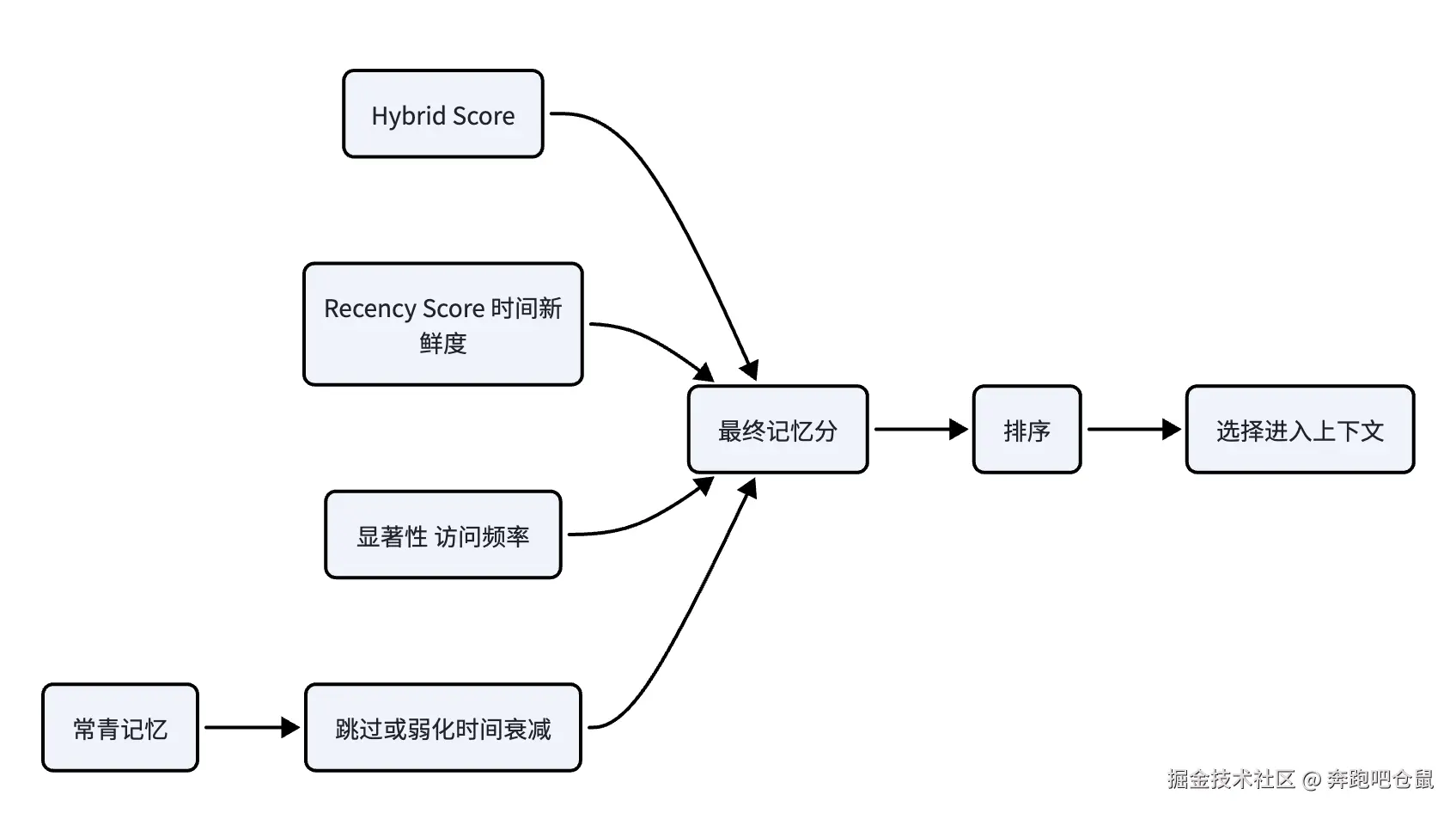
-
时间权重(时间衰减) :可选后评分修饰器,默认关闭。
- 公式:
finalScore = (1 - weight) * hybridScore + weight * recencyScore - 半衰期默认 168 小时,衰减率
decayRate = ln(2) / halfLifeHours,越新记忆权重越高。
- 公式:
-
显著性权重:频繁调用的记忆即使相似,也可能被优先保留,结合动态访问频率调整优先级。
记忆存储
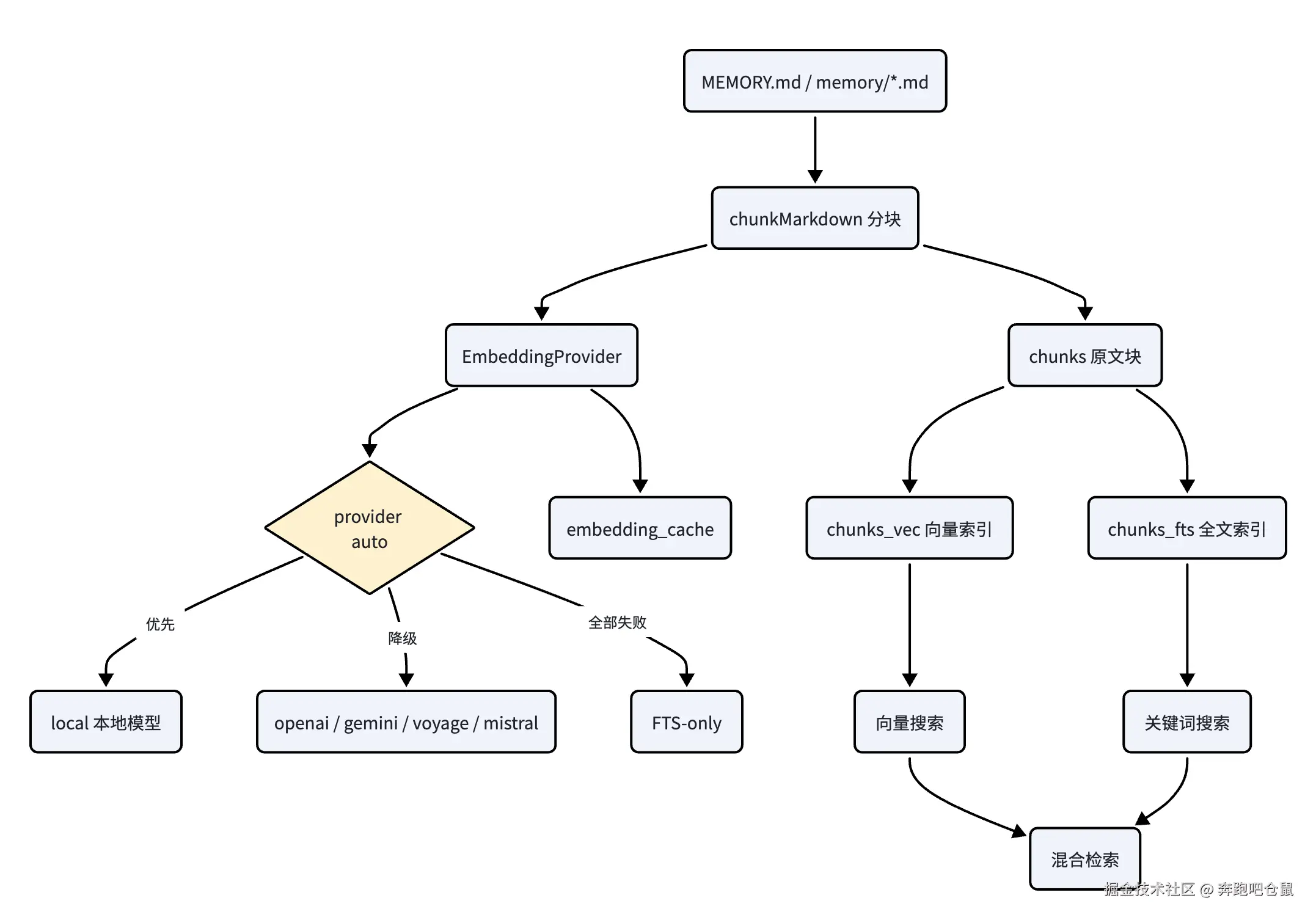
EmbeddingProvider:统一嵌入模型接口
OpenClaw 用 EmbeddingProvider 抹平不同嵌入引擎的差异。无论底层是本地 node-llama-cpp、OpenAI、Gemini、Voyage 还是 Mistral,上层只依赖统一接口。
embedQuery:搜索时对单条用户查询生成向量,优先追求低延迟。embedBatch:索引时批量生成文档块向量,优先减少网络请求和整体成本。model:参与缓存键和 Chunk ID 生成,用于隔离不同模型产生的向量。
Auto 选择与降级:Local-First,失败后退化为 FTS
当配置为 embedding.provider = auto 时,系统按 local → openai → gemini → voyage → mistral 的顺序尝试可用提供者。Local 排第一体现了本地优先策略:减少外部依赖、降低成本,并保护隐私。
如果所有嵌入提供者都不可用,系统不会直接失败,而是退化为 FTS-only 模式,只使用 BM25 关键词检索。这样语义召回质量会下降,但基础搜索能力仍然可用。
Local 提供者:懒初始化与重入保护
本地嵌入模型加载通常耗时且占内存,因此系统采用懒初始化:只有第一次真正需要向量时才加载模型。同时通过单例实例和初始化 Promise 防止并发请求重复加载模型。
- 已有实例时直接复用,避免重复占用内存。
- 正在初始化时复用同一个 Promise,避免并发重入。
- 向量会做归一化,使余弦相似度可等价为点积,也方便统一相似度阈值。
SQLite 六张表:同时支撑增量同步、向量搜索和全文搜索
| 表 | 职责 |
|---|---|
meta |
记录索引状态和元信息。 |
files |
记录文件路径、hash、mtime、size,是增量同步的基础。 |
chunks |
保存分块后的原始文本、行号、内容 hash 和 JSON 向量。 |
embedding_cache |
用 content_hash + model 缓存向量,减少重复 API 调用。 |
chunks_vec |
sqlite-vec 向量虚拟表,用于相似度检索。 |
chunks_fts |
FTS5 全文索引表,用于关键词和 BM25 检索。 |
Chunk ID 与分块策略
Chunk ID 由 source:path:startLine:endLine:contentHash:model 组合后做 SHA-256 生成。这样相同内容和相同模型会得到稳定 ID,切换模型后也不会误用旧向量。
chunkMarkdown 采用基于行的滑动窗口,默认目标大小约 400 tokens,并保留约 80 tokens 重叠。重叠窗口可以避免语义被硬切断,例如"项目方案"和"实施细节"分到不同块时,仍能保留一部分上下文连续性。
安全重建索引与查询扩展
全量重建索引时,runSafeReindex 不会直接清空旧库,而是创建临时数据库、迁移嵌入缓存、在临时库完成索引构建,最后通过文件重命名做原子交换。这样重建失败时可以回滚,重建期间旧索引仍可用。
查询侧通过 extractKeywords 做多语言关键词提取:英文和中文停用词会被过滤;中文采用轻量级 Unigram + Bigram 策略,例如"讨论方案"会拆成单字和双字组合,再交给 FTS5/BM25 排序自然降权无意义组合。
Memory Tool:把记忆搜索包装成 Agent 工具
createMemorySearchTool把 MemorySearchManager.search() 封装成 Agent 可调用的 memory_search 工具,使 LLM 能通过 Tool Call 访问长期记忆,而不是直接调用 TypeScript 函数。
- 工具参数主要是自然语言查询
query,便于 LLM 按当前任务意图主动检索。 - 工具描述中使用
Mandatory recall step,通过提示工程强化"回答前先回忆"的行为。 - 执行链路会走完整的混合搜索、MMR 去重、时间衰减和结果裁剪逻辑。
引用标注:让记忆召回可溯源
decorateCitations 会为每条搜索结果附加引用 ID、文件路径和行号范围,例如 [1] memory/2026-02-23.md:L15-L28。这样 Agent 在基于记忆回答时,可以明确说明信息来源,降低"凭空生成"的风险。
| 机制 | 作用 |
|---|---|
| 引用 ID | 把多条召回结果编号,便于回答中引用。 |
| 文件路径 | 定位信息来自 MEMORY.md 还是某个 memory/*.md 文件。 |
| 行号范围 | 支持用户追问来源,也方便调试记忆内容质量。 |
Memory Flush:静默沉淀长期记忆
shouldRunMemoryFlush 用来判断是否触发记忆持久化。触发条件主要包含三类:会话存在且 Token 用量有效、Token 用量接近上下文窗口阈值、当前 compaction 周期尚未执行过 flush。
触发后,系统会发起一次对用户透明的 Silent Agentic Turn :内部提示词要求 LLM 审查当前对话,只提取值得长期保存的信息,并写入当天的 memory/YYYY-MM-DD.md。如果没有值得保存的信息,则返回 [SILENT]。