11. 大模型的 DPO 和 PPO 的区别是什么?
DPO 和 PPO 都是大模型对齐训练里的方法,都是在 SFT 之后让模型的输出更符合人类期望。
PPO 是强化学习里的一个算法,在大模型里的用法是:先额外训练一个「奖励模型」来给模型的回答打分,然后用 PPO 这个 RL 算法不断调整大模型的参数,让它生成的内容往高分方向走。这套流程需要同时维护好几个模型,工程复杂度高,训练也容易不稳定,所以成本比较大。
DPO 是后来提出的简化方案,它不需要单独训练奖励模型。它直接拿「人类偏好对」数据,就是同一个问题的「好回答」和「差回答」,让模型直接学「应该更像哪个」。更准确地说,DPO 是从带 KL 约束的 RLHF 目标推导出来的一个闭式偏好优化目标,不是说它和任意 PPO 训练过程都完全等价。工程上可以把它理解成把复杂 RL 流程简化成监督学习问题,只需要两个模型,更稳定、更好实现。
简单总结:PPO 是「先训练裁判、再训练选手」,DPO 是「直接拿比赛录像告诉选手哪个动作对哪个动作错」,两者目标一致,但 DPO 省去了裁判这个中间层。
SFT 之后,还差什么?
要理解 PPO 和 DPO,得先搞清楚它们出现的背景:为什么 SFT 训完之后还需要对齐?
预训练让模型掌握了语言能力和世界知识;SFT(监督微调)让模型学会了用对话格式回答问题。但 SFT 本质上是「模仿」,模型在模仿标注人员写的标准答案的格式和风格。这里有一个根本问题:SFT 告诉模型「怎么写」,但没有告诉模型「哪个更好」。
举个例子,同一个问题「怎么学好 Python」,可以有很多种合格的回答:有的很简洁,有的很详细,有的带代码,有的全文字。SFT 只学了某一种写法,但用户对质量的偏好是有排序的,比如带代码示例的回答会更受欢迎,或者承认「我不知道」比自信地胡说更安全。
这种「知道合格,但不知道哪个更好」的局限,就是对齐阶段要解决的问题。不经过对齐的模型可能会生成有毒内容、一本正经地胡说八道,或者输出让用户不满意的答案。PPO 和 DPO 都是解决这个问题的方案,只是路径不同。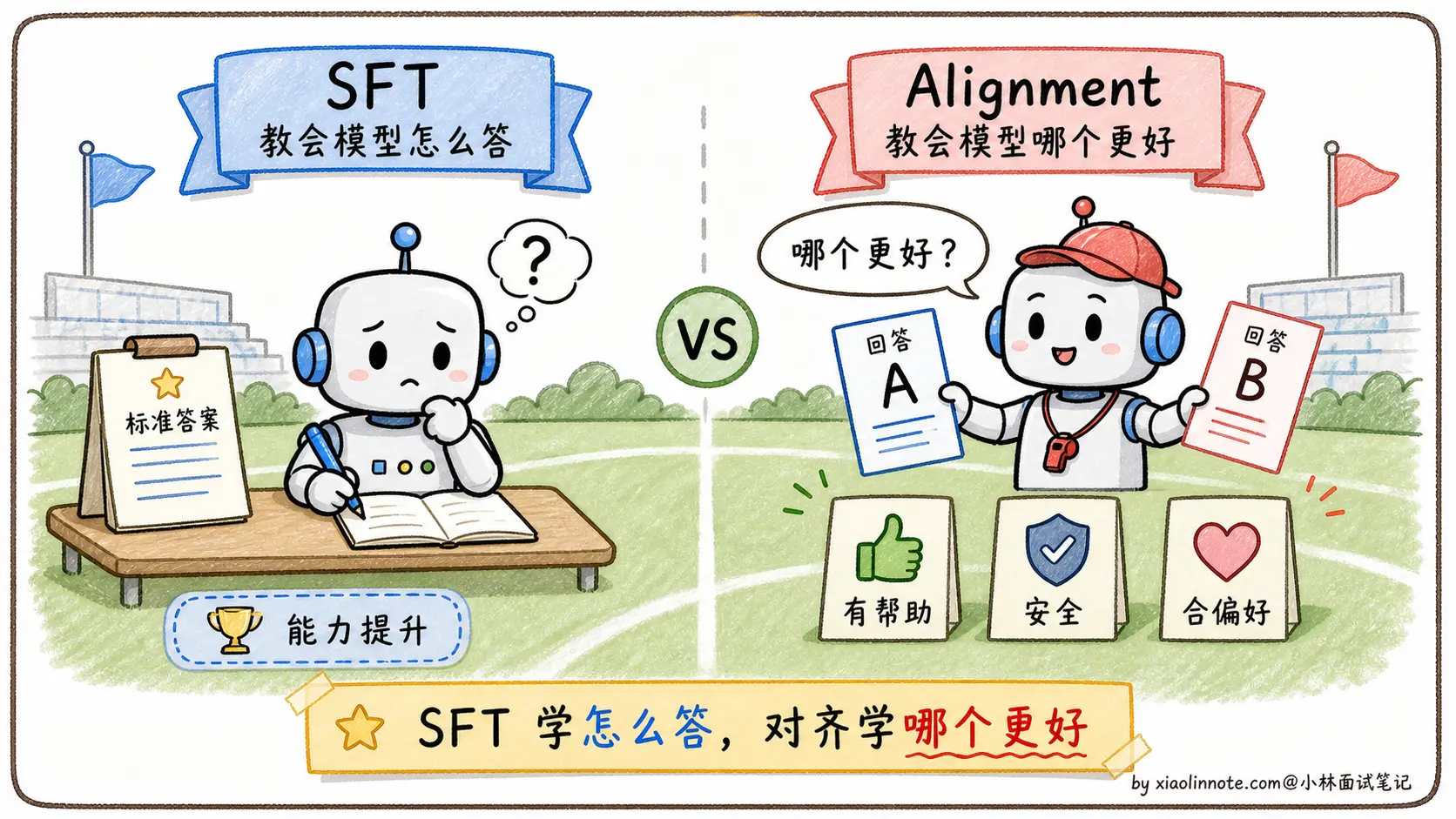
PPO:先培养「裁判」,再训练「选手」
PPO(Proximal Policy Optimization,近端策略优化)是强化学习里的一个经典算法,最早不是为大模型设计的,但 OpenAI 在 InstructGPT 里把它用到了 RLHF(基于人类反馈的强化学习)流程里。
第一步:训练奖励模型(Reward Model)
这个阶段,人类标注员会拿到很多「同一问题的多个回答」,然后按质量排名。比如问题「解释什么是递归」,回答 A 比回答 B 好,回答 B 比回答 C 好。用这些排名数据,训练一个专门的奖励模型,让它学会「给一个回答打质量分」。这个奖励模型就是裁判,它代替人类完成后续的自动评分。
第二步:用 PPO 优化主模型
有了裁判,就可以用强化学习来训练主模型了。流程是:主模型生成一段回答 -> 奖励模型打分 -> PPO 根据得分调整主模型的参数,让它以后生成更高分的回答。
但这里有一个危险:如果只追求高分,模型可能学会「钻空子」,生成一些奖励模型打高分但实际上没用的内容(这叫做 reward hacking)。为了防止这个,PPO 流程里会同时维护一个「参考模型」(Reference Model),也就是 SFT 之后的原始模型的冻结副本,并用 KL 散度(一种衡量两个概率分布差距的指标)约束主模型,让它不要偏离参考模型太远。KL 散度就像一根绳子,主模型可以向高分方向移动,但不能走太远。
4 个模型同时加载到显存里,每个都和主模型差不多大,光是显存占用就是 SFT 训练的好几倍。加上 RL 训练本身的不稳定性(超参数敏感、容易 reward hacking、训练曲线震荡),PPO 的工程难度和资源成本都极高,能驾驭 PPO 的团队在业界凤毛麟角。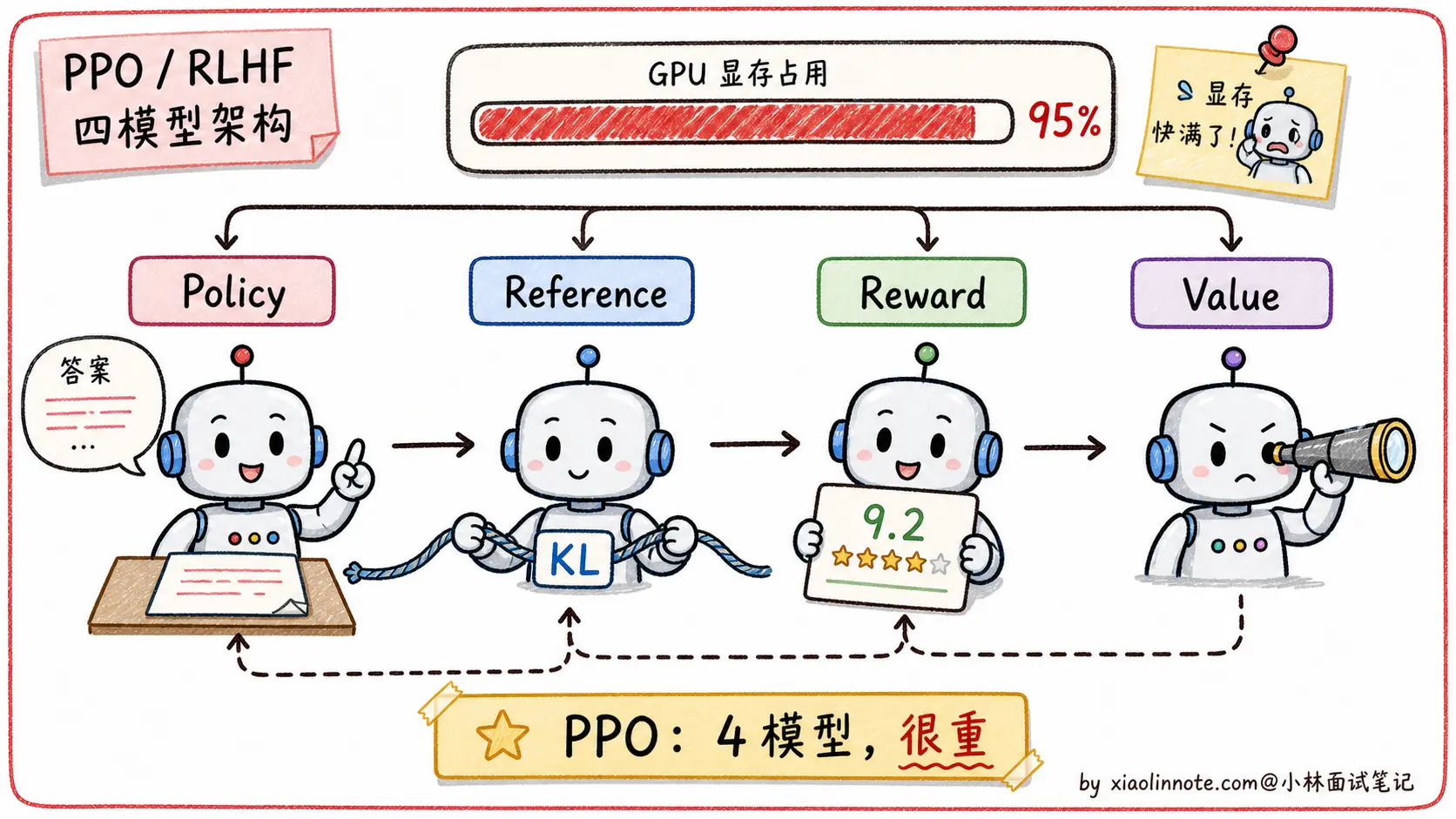
DPO:绕过裁判,直接看回放
DPO(Direct Preference Optimization,直接偏好优化)是 2023 年斯坦福提出的方法,核心思路是一个数学上的等价转化。
研究者们发现:RLHF(PPO 方案)的优化目标,可以通过推导改写成一个纯监督学习的目标函数,不需要显式训练和调用奖励模型。直觉上,「奖励模型」的功能可以被「主模型相对于参考模型的概率比值」完全替代,如果主模型在某个回答上比参考模型提升了更多概率,那这个回答就被认为更受偏好。简单说就是两件事同时发生:模型对「好回答」的概率,相对于参考模型升高;模型对「差回答」的概率,相对于参考模型降低
DPO 把对齐训练变成了一个普通的监督学习问题,用现成的深度学习框架就能实现,训练稳定,超参数也容易调。这就是为什么开源社区大量采用 DPO 的原因,不需要复杂的 RL 基础设施。
各自适合什么场景?
理解了两者的权衡,选择就很清晰了。
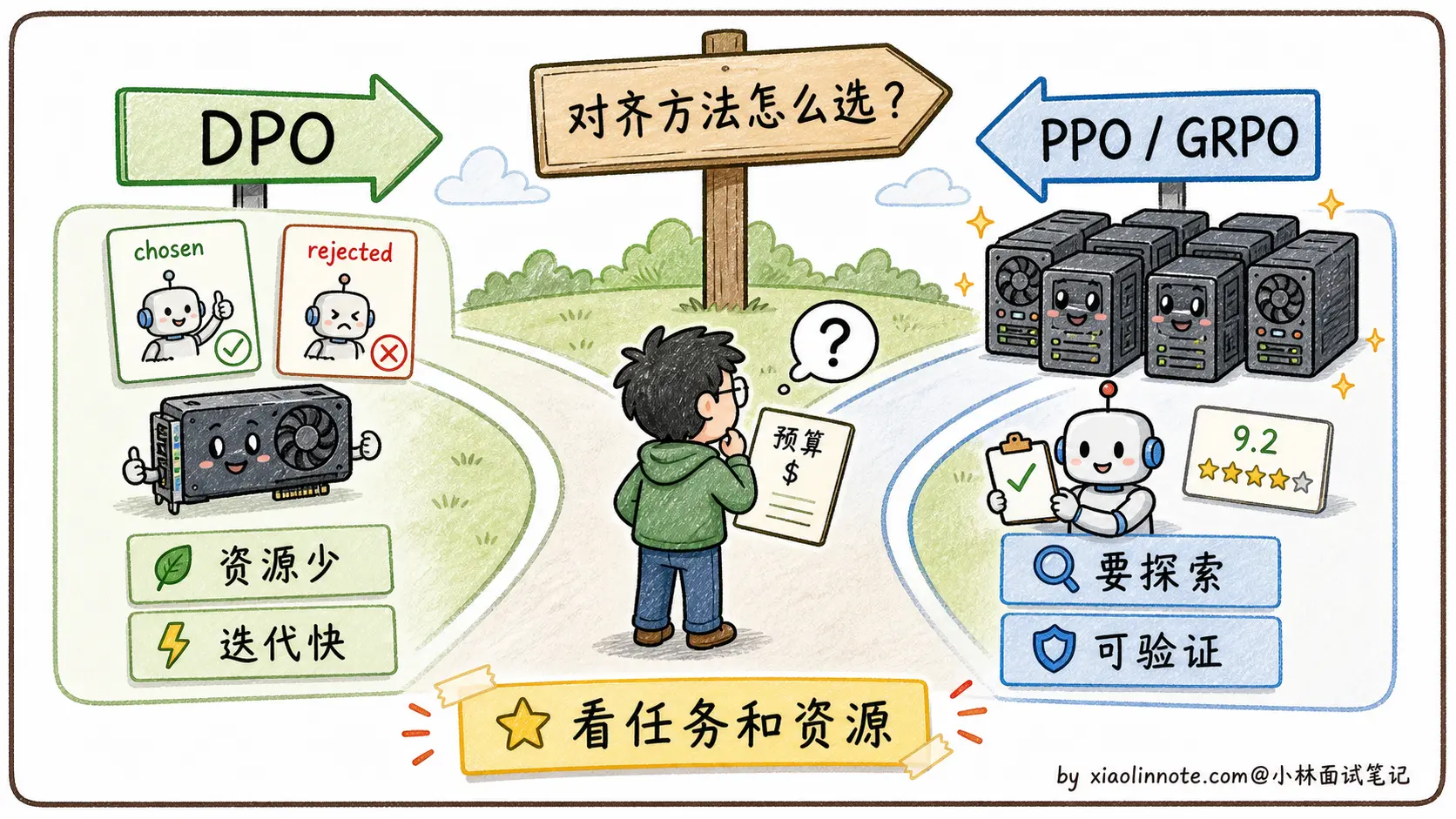
PPO 适合对对齐效果要求极高、资源充足、有 RL 工程能力的团队。它能探索训练数据里没有的高质量回答方式,理论上表达能力更强,ChatGPT 早期的强大效果很大程度上就来自精心调优的 PPO 流程。但门槛极高,能驾驭它的团队凤毛麟角。
DPO 适合快速迭代、GPU 资源有限、开源社区场景。不需要 RL 工程能力,偏好数据收集相对容易(众包打排名就可以),训练一次成功率高。大多数开源模型在资源有限的情况下都选 DPO,效果虽然可能略逊于精心调优的 PPO,但工程代价小得多。
一个简单的判断原则是:如果你想在已有偏好数据的分布上把模型质量提升一步,DPO 够用且高效;如果你需要模型探索超出现有数据的能力边界、或者对齐效果要求接近 OpenAI 的水平,才值得投入 PPO 的工程成本。
回到开头那段对话,问到 DPO 和 PPO 的区别,最重要的是先讲清楚两者都在解决「SFT 之后的对齐问题」。SFT 让模型学会按指令回答,但回答风格不一定符合人类偏好,所以需要进一步训练让模型学会「哪种回答更受人类欢迎」。这一句铺垫先讲到,面试官就知道你抓到了对齐这件事的本质。
接下来讲 PPO 的流程:先收集人类偏好排序数据 → 训一个奖励模型代替人类打分 → 用 PPO 算法调整主模型参数让它生成的回答尽量得高分。整个流程要同时维护 4 个模型(policy / reference / reward / value),训练复杂、不稳定、调参难。能把「4 个模型分别做什么」讲清楚,面试官就知道你真的研究过 RLHF 流程。
DPO 的核心创新是「把带 KL 约束的 RLHF 目标改写成偏好对上的监督学习损失」。不需要显式奖励模型,不需要跑 PPO,直接拿 (prompt, chosen, rejected) 三元组训练,让模型学会「好回答的概率比差回答提升得多」。流程从 4 模型砍到 2 模型,训练稳定、容易实现。能用「PPO 是先训裁判再训选手,DPO 是直接拿比赛录像告诉选手哪个动作对」这种类比讲出来,会比纯讲算法生动很多。
最关键的一句话是:两者目标一致,但 DPO 省掉了「奖励模型」这个中间层,让对齐训练变成监督学习。这是 DPO 在开源社区大爆发的核心原因。
如果还想再加分,可以提一句 GRPO(DeepSeek 2024 年提出的 PPO 改进版,砍掉 Value Model 用组内归一化代替),让面试官知道你跟得上 2026 年的最新对齐方法。能讲到这一层,已经是面试里很难追问的水平了。
12. 大模型生成文本时的解码策略有哪些?贪心、Beam Search、采样分别什么时候用?
我理解大模型的解码策略本质上是回答一个问题:模型在每一步输出了一个 vocabulary 大小的概率分布,我们怎么从中选下一个 token?
主流方案分两大类。
第一类是确定性策略,输入相同输出永远相同。
- 贪心解码(Greedy Decoding):每一步选概率最高的 token。简单、可复现,但容易重复啰嗦、缺乏多样性
- Beam Search:每一步保留 Top-B 条候选路径(B=4、8 等),最后选总概率最高的整条序列。比贪心更接近全局最优,但对生成式任务有「天然缺陷」
第二类是随机性策略,引入随机性让输出有多样性。
- Temperature 采样:通过缩放概率分布的「锐度」,控制随机性强度。Temperature 越低越确定,越高越发散
- Top-K 采样:每步只从概率最高的 K 个 token 里采样,截断长尾
- Top-P(Nucleus)采样:每步累加概率到 P 为止,从这个「核」里采样,自适应截断
这两大类的核心区别是,确定性策略保证质量但牺牲多样性;随机性策略保证多样性但每次输出不同。
LLM 工程实践里有个反直觉的现象:Beam Search 在大模型时代基本被弃用了。原因是 Beam Search 优化的是「整体序列概率最高」,但生成式任务(聊天、写作、推理)没有「单一最优答案」,Beam Search 给出的「最高概率序列」往往是「最 boring 的回答」,多样性差还容易陷入复读循环。
所以现在的 LLM API 通常都会提供 Temperature + Top-P 这类采样参数,但默认值各家不完全一样,有的默认更稳定,有的默认更开放。更稳的工程表达是:精确任务(代码、数学、信息抽取)用 Temperature=0 或低温来提高可复现性;对话/创意任务用较高 Temperature 配合 Top-P 平衡多样性和质量。
回到开头那段对话,问到解码策略,最重要的是先把本质讲清楚。每生成一个 token 都对应一个 vocabulary 大小的概率分布,解码策略就是「怎么从这个分布里挑下一个 token」。不同策略对应「生成任务到底有没有最优答案」的不同假设,这是整道题的地基。
讲完本质,自然过渡到贪心和 Beam Search 这两种确定性策略。贪心每步选最高,简单可复现但容易陷入复读循环;Beam Search 是贪心的并行版,保留 B 条候选最后选总分最高的整条序列。Beam Search 在翻译时代是王者,因为翻译有「单一最优译文」,所以「找概率最高序列」这个目标和任务本质契合。
最关键的是讲清为什么 LLM 时代 Beam Search 失宠了 ,这是面试官最爱追问的点。生成式任务(对话、写作、推理)根本没有「单一最优答案」,Beam Search 优化的「整体概率最高」反而等价于「最 boring 的回答」,多样性差还容易陷入复读。再加上和 KV Cache、Flash Attention 等现代推理优化不兼容,工业界几乎弃用。能说出「任务本质和 Beam Search 算法目标不匹配」这一句,比单纯说「Beam Search 慢」深刻一个层次。
最后讲采样族(Temperature/Top-K/Top-P)的整体定位。它们用随机性换多样性,配合长尾截断保证质量。实际选型上,精确任务(代码、SQL、JSON)用贪心或低温;对话/写作可以从官方默认值开始微调;创意任务再提高 Temperature,但要用测试集观察跑偏率。
如果还想再加分,可以提一句推测解码(小模型起草 + 大模型验证,推理速度 2-3 倍)和 Self-Consistency(多次采样投票,推理任务准确率涨 5-15%)。能讲到这一层,面试官基本就没什么追问的余地了。
13. 大模型的参数:温度值、Top-P、Top-K 分别是什么?各个场景下的最佳设置是什么?
我调这几个参数的经验是,Temperature 是最关键的,另外两个基本不用动。
Temperature 控制输出的随机性,越低越稳定可复现,越高越发散有创意;Top-P 是从累积概率达到 P 的候选词里采样,比 Top-K 更灵活自适应;Top-K 是固定从概率最高的 K 个词里选。
实践下来,代码生成或者精确问答我会把 Temperature 调到 0~0.2,创意写作调到 0.8~1.2,日常对话 0.5~0.7 就够了。Top-P 和 Top-K 保持默认就好,同时调多个参数反而互相干扰。
先理解大模型是怎么「选下一个词」的
要理解这三个参数,得先搞清楚大模型生成文字的底层机制。
大模型生成的本质是一个「不断选词」的过程。每生成一个 token,模型实际上在做一件事:计算词汇表里所有词(典型 5 万到 15 万个)的概率分布 。比如对于「今天天气真」这句话,模型会算出下一个词的可能性分布:「好」70%、「不错」15%、「热」8%、「冷」5%、「猫」0.001%......以此类推。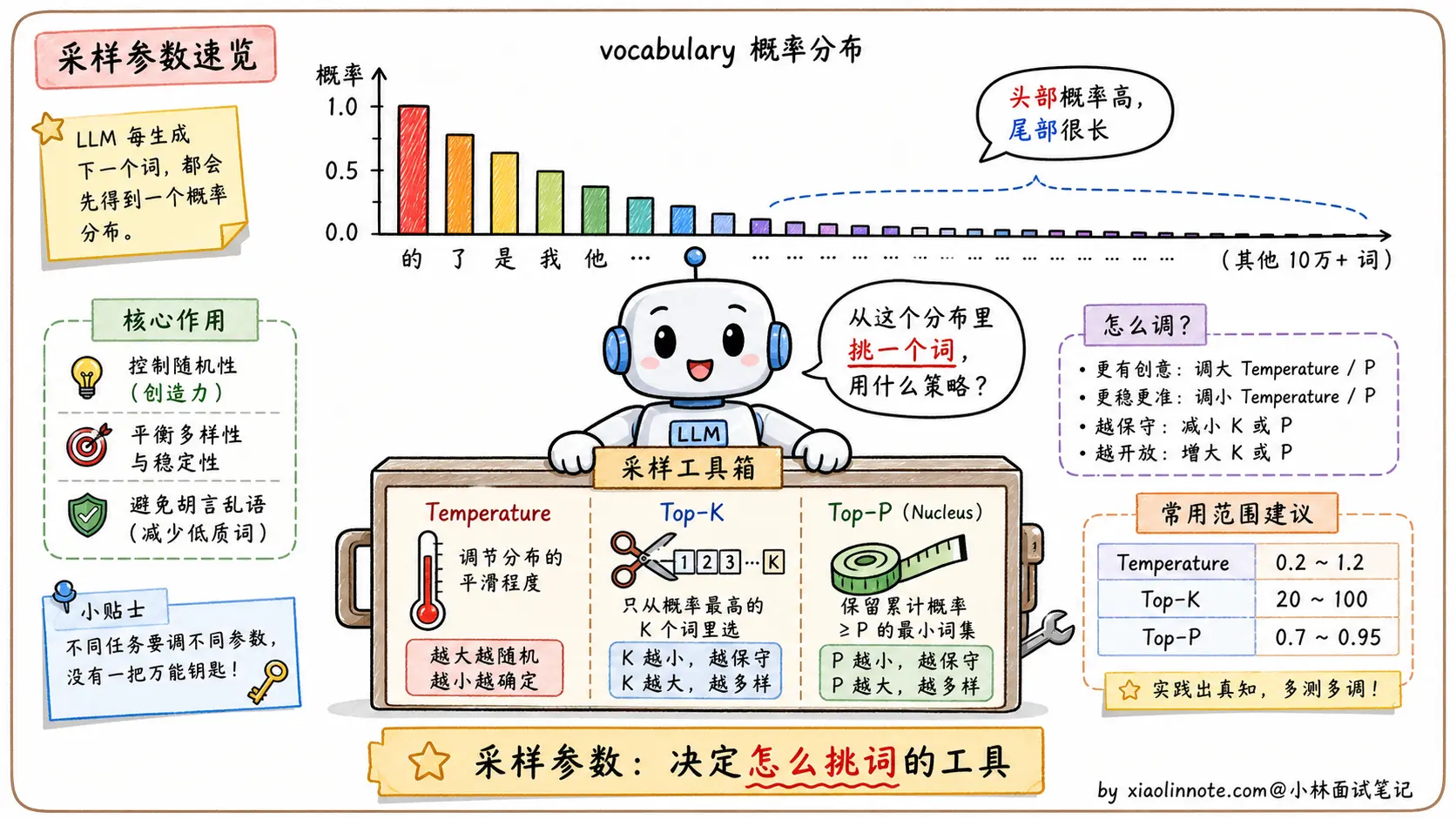
接下来怎么选词?最简单的策略叫贪心解码(greedy decoding),每次直接选概率最高的那个。这种方式输出完全确定,但往往过于保守,文本缺乏多样性,长一点还会陷入重复循环(前面已经讲过的「复读机问题」)。
为了避免贪心的死板,业界发展出三个采样调节参数:Temperature、Top-K、Top-P。它们各自从不同维度调控「怎么从概率分布里采样」,让生成既有合理性又有多样性。下面分别看。
Temperature:热水和冷水的类比
Temperature(温度)这个名字不是随便取的,背后真的有「热」「冷」的物理意义。
数学上,Temperature 的作用是在采样前对概率分布做「缩放」:每个词的 logit(未归一化的分数)会除以温度值 T,然后再做 softmax 得到最终概率。
温度低(比如 T=0.1)的效果类似「冷水 」。冷水会让分子运动变慢、状态趋于稳定,这里也是一样:概率分布变得更尖锐,高概率的词概率变得更高,低概率的词概率接近于零。模型几乎只会选最有把握的词,输出非常稳定,但也非常单调。
温度高(比如 T=1.5)的效果类似「热水 」。热水让分子运动加快、状态趋于混沌,这里也是一样:概率分布变得更均匀,原本概率很低的词也有了被选中的机会。输出更有创意、更多样,但也更可能出错或偏离主题。
T=1 是个临界点,概率分布完全不变,就是模型「原始」的采样。T=0 是另一个临界点,相当于退化成贪心解码(永远选概率最高的那个),输出完全确定,相同的输入永远得到相同的输出。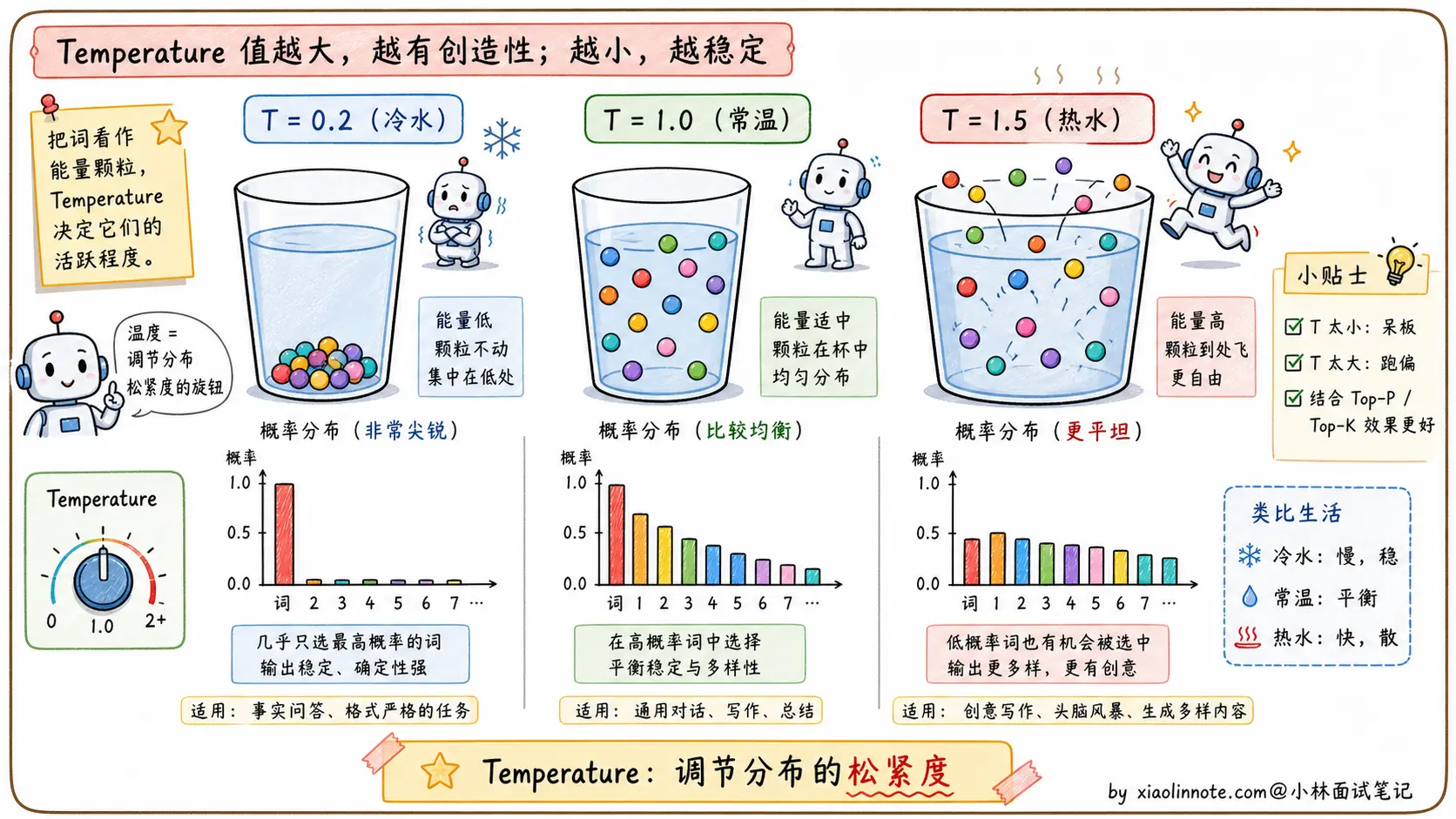
Temperature 解决的是「分布的松紧」,但还有另一个维度可以控制采样:候选词的数量。这就是 Top-K 和 Top-P 要解决的问题。
Top-K:限制候选词的数量
Top-K 的思路特别直觉:每次采样前,把概率分布截断到只保留概率最高的 K 个词,其余全部置零,然后在这 K 个词里按比例采样。
比如 Top-K=50 意味着每一步只从概率最高的 50 个词里选。K 越小,输出越保守;K 越大,可选范围越广。这个机制能有效避免「采到长尾噪声词」(vocabulary 里那 10 万多个词大部分都是无用的,长尾里偶尔抽到一个会让句子毁掉)。
但 Top-K 有一个明显的问题,K 是固定的,对不同情境不够自适应。
举个例子。如果你问模型「中国的首都是____」,模型对「北京」的概率可能高达 99%,剩下所有词加起来才 1%。这时候 Top-K=50 让你从前 50 个词里选,意味着候选池里有 49 个概率极低的离谱词,硬要从 50 个里选并不合理。
反过来,如果你让模型「写一首关于秋天的诗」,前 50 个词的概率可能都很分散,每个词都有合理的可能性,这时候 Top-K=50 又显得不够,因为可能第 51 个词比第 50 个词更有诗意,硬截断在 50 反而错过了好选项。
固定 K 的本质问题是:它不知道当前上下文的概率分布有多尖锐或多平坦。要解决这个问题,就需要更智能的截断方式,这就是 Top-P。
Top-P(Nucleus Sampling):自适应的截断
Top-P 也叫 Nucleus Sampling(核采样),它解决了 Top-K「不自适应」的问题。
它的逻辑是:按概率从高到低排列所有词,累加概率,当累加值超过阈值 P 时停止,只保留这个「核」(Nucleus)里的词,然后在其中采样。
举两个对比例子就能看出 Top-P 的妙处。
「中国的首都是____」这种问题,模型对「北京」的概率是 99%,Top-P=0.9 意味着「北京」一个词就累加超过了 0.9,候选池里就只有「北京」一个词,结果非常确定。这正是这种确定性问题应该有的行为。
「写一首关于秋天的诗」这种开放问题,前几个词的概率分散,比如前 30 个词累加才达到 0.9,那候选池就有 30 个词,保留了足够的多样性。这也正是这种开放任务应该有的行为。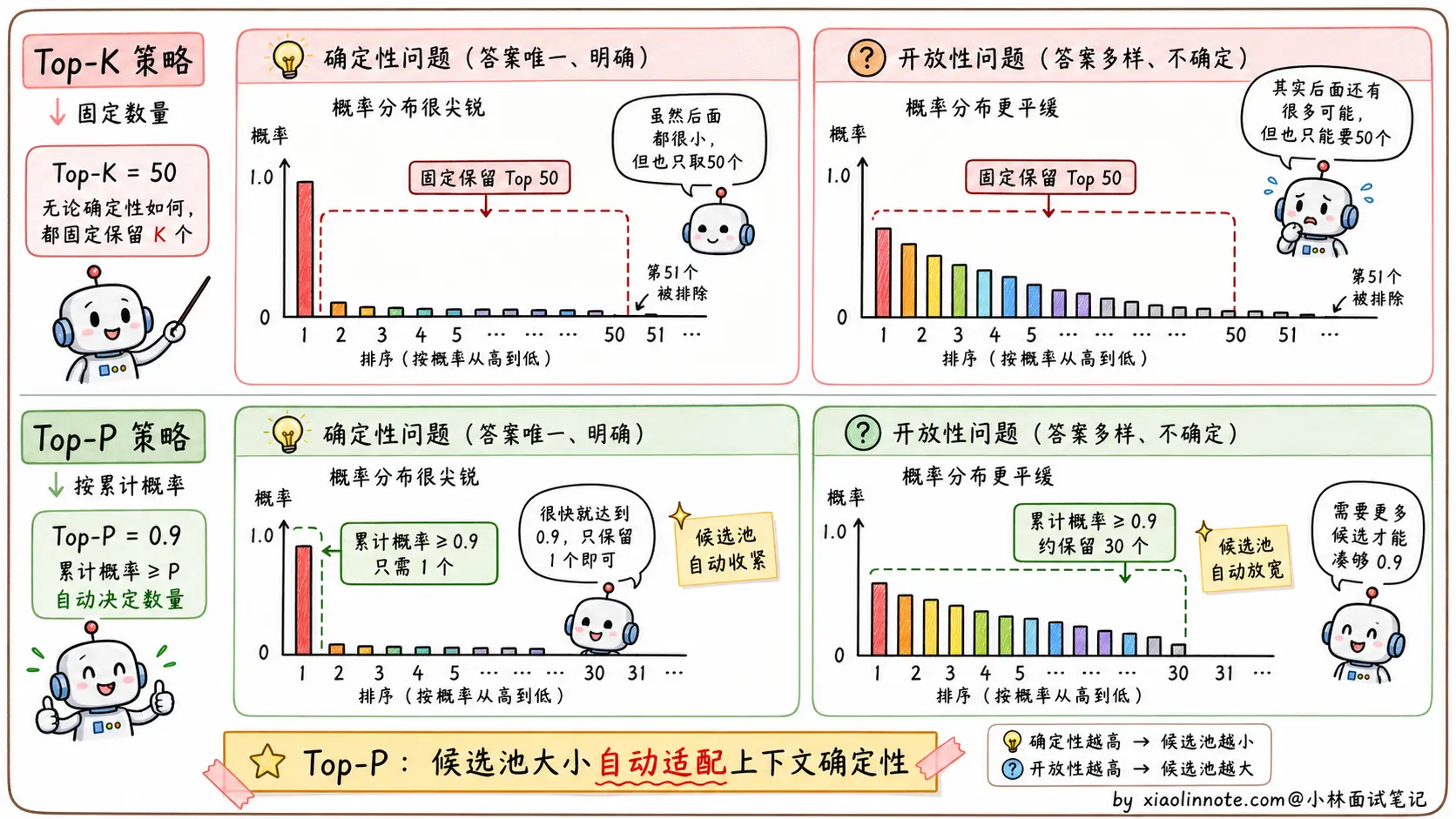
Top-P 的核心优势就是自适应。候选池的大小会根据当前上下文的「确定性」自动调整:确定性高时候选池小、确定性低时候选池大,这比固定 K 要合理得多。
讲清三个参数的原理之后,最关键的问题是:实际工程里这三个参数怎么配?
实际工程怎么配三个参数
讲了这么多原理,落到实战是这样:绝大多数情况下,只调 Temperature 一个参数就够了,Top-P 和 Top-K 保持默认值。
为什么?因为这三个参数的作用其实有重叠。它们都在控制「采样的随机性」,只是从不同维度切入。同时调多个参数会互相干扰,让你搞不清楚到底是哪个参数在起作用。OpenAI、Anthropic 等官方文档都建议通常只调 temperature 或 top_p 其中一个;Qwen、DeepSeek 这类开源模型也要以对应推理框架和模型卡建议为准。总之,不要一上来三个参数一起拧。
具体到不同任务的配置,根据多年踩坑总结,分三档场景。
精确任务(代码生成、SQL 生成、JSON 抽取、信息抽取、数学计算)。这些任务有「标准答案」或者格式严格,最忌讳模型乱发挥。Temperature 调到 0~0.2,Top-P 保持 1.0(不做限制)就行。Temperature=0 等价于贪心,相同输入永远得到相同输出,特别适合需要可复现的场景。
日常对话 / 总结摘要 / 翻译。这些任务希望模型自然流畅但不能太离谱。Temperature 可以从 0.5~0.7 试起,Top-P 保持 0.9 或官方默认值。这是很多 ChatBot、客服 AI 会尝试的配置区间,平衡了多样性和可控性。不要把某个产品某个版本的默认值当成行业固定标准,模型更新后默认策略也会变。
创意任务 (写作、头脑风暴、角色扮演、营销文案)。这些任务希望模型有「惊喜感」,重复或保守的回答反而不好。Temperature 调到 0.8~1.2,Top-P 保持 0.95。这种配置下模型会偶尔冒出意想不到的好句子,也偶尔会跑偏,可以接受。
最后讲两个常见的踩坑。
第一个是「同时调 temperature 高 + top_p 低」。比如 temperature=1.2 + top_p=0.5,意思是「让分布变平坦再截掉一半」,两个参数互相打架,结果完全不可预测。
第二个是「同时设置 top_k 和 top_p」。这两者都在做截断,先截 top_k 再截 top_p(或者反过来)会让候选池变得很奇怪。建议的最佳实践是「top_k 不设置或用默认,只用 top_p」,因为 top_p 更智能。
记住一句口诀:先只调 temperature,top_p 保持默认或 0.9~1.0,top_k 不设置。如果你决定调 top_p,就先固定 temperature,不要两个一起大幅改。这条经验能帮你避开大多数参数坑。
讲作用维度时可以这样组织:Temperature 控制「分布的松紧 」(缩放概率分布的尖锐度),Top-K 是「固定截断 」(只保留前 K 个词),Top-P 是「自适应截断」(按累积概率截断到 P)。三者从不同维度控制采样的随机性。
讲完原理后,把 Top-P 比 Top-K 更好的原因点出来:Top-P 能根据当前上下文的概率分布形状自动调整候选池大小,确定性问题候选池小,开放性问题候选池大,比固定 K 智能。这一句能讲出来就比死记硬背深刻一层。
最关键的实战经验是:一次主要调一个参数。最常见做法是先调 Temperature,Top-P 保持默认或 0.9~1.0,Top-K 不设置;如果要调 Top-P,就固定 Temperature。不要同时大幅调 temperature 和 top_p,两者会互相干扰。这个经验直接说出来,面试官就知道你真的调过参数,不是只看过文档。
如果还想再加分,可以提一句不同任务的具体配置:精确任务(代码、SQL)用 T=0~0.2、日常对话 T=0.5~0.7、创意任务 T=0.8~1.2。能讲出这种「按任务选 T 值」的工程视角,这道题就答得很完整了。