生产级 AI Agent 评估体系:从 12 指标框架到持续评估闭环

图 1:AI Agent 评估体系全景------12 指标 × 4 大类 × 持续闭环
文章目录
- [生产级 AI Agent 评估体系:从 12 指标框架到持续评估闭环](#生产级 AI Agent 评估体系:从 12 指标框架到持续评估闭环)
-
- 本文主线
- [一、为什么评估体系是 Agent 的生死线](#一、为什么评估体系是 Agent 的生死线)
-
- 三种致命反模式
- [评估的 ROI 计算](#评估的 ROI 计算)
- [二、12 指标框架全景](#二、12 指标框架全景)
- 三、检索指标:地基不行,楼一定塌
-
- [3.1 Context Relevance(上下文相关度)](#3.1 Context Relevance(上下文相关度))
- [3.2 Context Recall(上下文召回率)](#3.2 Context Recall(上下文召回率))
- [3.3 Context Precision(上下文精排)](#3.3 Context Precision(上下文精排))
- [3.4 Retrieval Latency(检索延迟)](#3.4 Retrieval Latency(检索延迟))
- 四、生成指标:模型给出的答案能信吗
-
- [4.1 Answer Faithfulness(答案忠实度)](#4.1 Answer Faithfulness(答案忠实度))
- [4.2 Answer Relevance(答案相关度)](#4.2 Answer Relevance(答案相关度))
- [4.3 Hallucination Rate(幻觉率)](#4.3 Hallucination Rate(幻觉率))
- [五、Agent 行为指标:不只是会回答问题](#五、Agent 行为指标:不只是会回答问题)
-
- [5.1 Tool Selection Accuracy(工具选择准确度)](#5.1 Tool Selection Accuracy(工具选择准确度))
- [5.2 Tool Execution Success(工具执行成功率)](#5.2 Tool Execution Success(工具执行成功率))
- [5.3 Multi-Step Coherence(多步连贯性)](#5.3 Multi-Step Coherence(多步连贯性))
- [5.4 多 Agent 交接点评估](#5.4 多 Agent 交接点评估)
- 六、生产指标:钱和速度
-
- [6.1 Cost per Query(单次请求成本)](#6.1 Cost per Query(单次请求成本))
- [6.2 P99 Latency(P99 延迟)](#6.2 P99 Latency(P99 延迟))
- 七、LLM-as-Judge:怎么评估评估本身
- 八、分阶段实施路径
-
- [Phase 1:上线前(Week 0-2)](#Phase 1:上线前(Week 0-2))
- [Phase 2:灰度期(Week 3-6)](#Phase 2:灰度期(Week 3-6))
- [Phase 3:稳定期(Week 7+)](#Phase 3:稳定期(Week 7+))
- 用例修正
- [Day 1 速启:如果你只有 1 天时间](#Day 1 速启:如果你只有 1 天时间)
- 九、工具选型:不必从零搭建
- 十、持续评估:不是跑一次就完了
- 十一、常见坑与对策
- [十二、10 步 Checklist:从 0 到有评估体系](#十二、10 步 Checklist:从 0 到有评估体系)
- 十三、总结:一张图记住全部
- 参考
摘要:95% 的企业 AI pilot 失败,根因不是模型不行,而是没有评估体系。本文从 100+ 部署案例的 12 指标框架出发,手把手教你搭建生产级 Agent 评估闭环。
你正在开发一个 AI Agent。它在 demo 里表现完美,测试集准确率 95%。上线三个月后,合规团队问你:
- "你怎么知道它没在幻觉?"
- "工具选错了谁来发现?"
- "单次请求花了多少钱,你知道吗?"
你答不上来。
这不是假设情景。这是 Intuz 团队在一次医疗 AI 部署中的真实经历------有单元测试、有集成测试、有 demo 数据集上漂亮的指标,唯独没有一套评估 harness 能在生产环境里实时度量幻觉率、上下文忠实度和工具选择准确度。
MIT 2025 NANDA 研究的数据更残酷:95% 的企业 AI pilot 失败。RAND 的数据是 80%+。而在已经成功部署的企业中(KPMG 2025 Q3 数据显示 Agent 采用率从 11% 飙到 42%),区分"上了线"和"上了线还活着"的唯一分水岭,就是评估基础设施。
模型是商品,评估才是护城河。
本文要解决的问题:
- 为什么"准确率够高"不等于"可以上生产"?
- 一套完整的生产级评估框架长什么样(12 指标 × 4 大类)?
- LLM-as-Judge 怎么校准才不会三个月后被打脸?
- 评估体系怎么分阶段落地,而不是一口气建两个月?
- 团队常踩的坑有哪些,怎么避开?
本文主线
重要性(Why)→ 框架全景(What)→ 4 大类 × 12 指标详解(How)
→ LLM-as-Judge 校准方法论 → 分阶段实施路径 → 常见坑与对策一、为什么评估体系是 Agent 的生死线

图 2:没有评估体系的三种致命反模式与代价
三种致命反模式
| 反模式 | 表现 | 代价 |
|---|---|---|
| "MVP 之后再加评估" | 先建 UI/API/集成/上线客户,评估排最后 | 改造 4-6 周,信任损伤不可逆 |
| "Accuracy 够了就行" | 测试集 95%,生产环境 30% 幻觉率 | 客户看到幻觉直接流失 |
| "人工抽检就够" | 100 条/天人力 review 还行 | 10,000 条/天完全不可能 |
这不是抽象的"最佳实践"。2025 arXiv 一项多 Agent 失败分析表明:
- 17.14% 的 Agent 失败是步骤重复(无限循环)
- 13.98% 是推理与行动不匹配(想的和做的不一致)
这两种失败模式只看最终输出根本抓不到。你需要 trace 级评估,逐步审查中间决策。
评估的 ROI 计算
评估体系建设成本:2-3 周集中工程投入 + 月度 30-50% 推理成本的 LLM judge 费用。
不建的成本:一次生产事故需要工程师-周级别的 debug + 不可逆的信任损伤。
第一次阻止的事故就让评估体系永久回本。
二、12 指标框架全景
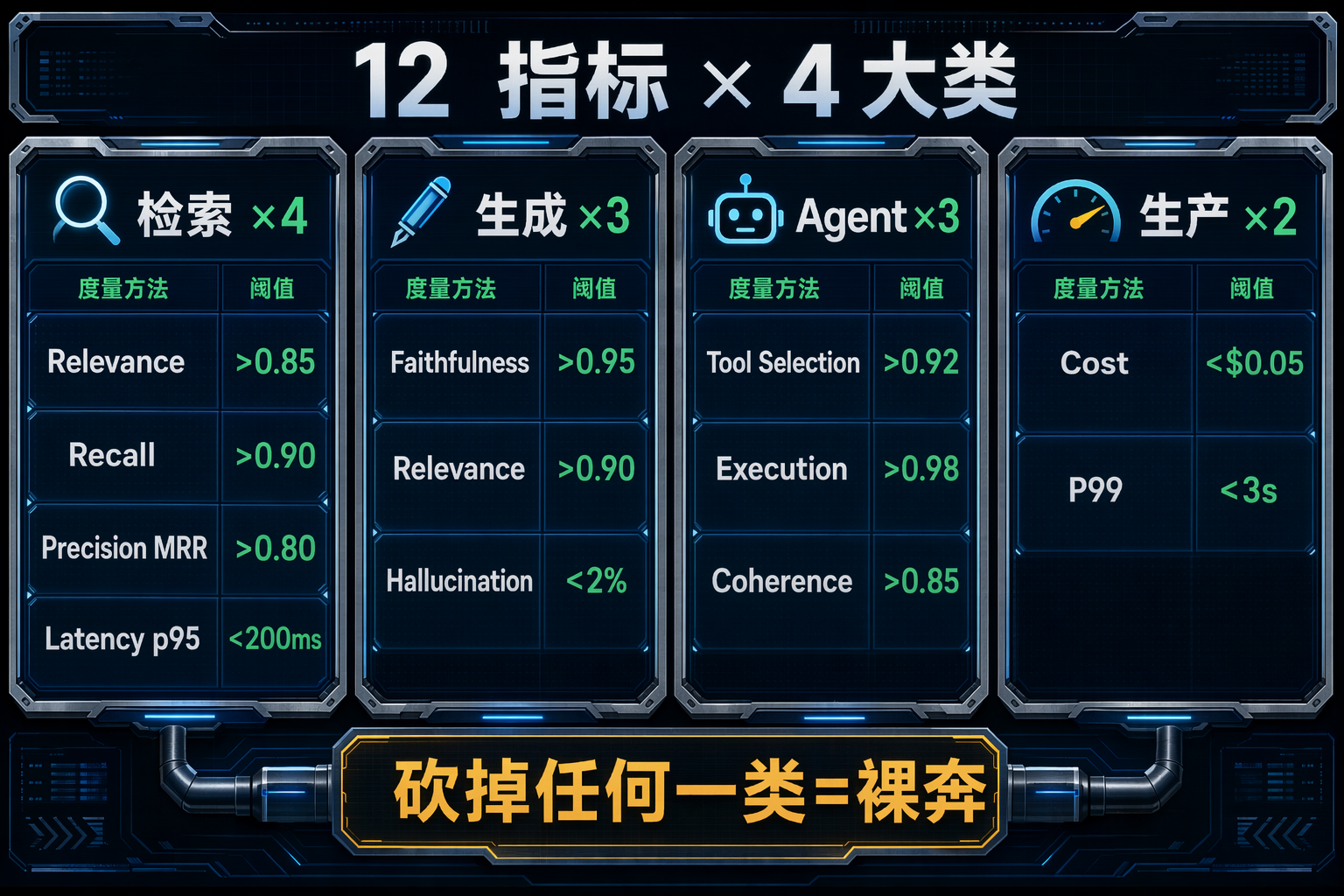
图 3:12 指标按检索、生成、Agent、生产四大类组织的框架全景
这套框架来自 100+ 企业部署的实战沉淀,分为 4 大类、12 个指标。三类度量 Agent 内部行为(检索、生成、Agent 行为),一类度量生产运维关心的事(成本和延迟)。
砍掉任何一类都是在裸奔。
| 大类 | 指标 | 度量什么 | 目标阈值 |
|---|---|---|---|
| 检索 | Context Relevance | 检索块和 query 相关吗? | >0.85 |
| 检索 | Context Recall | 所有相关信息都捞到了吗? | >0.90 |
| 检索 | Context Precision | 最相关的排在最前面吗? | MRR >0.80 |
| 检索 | Retrieval Latency | 检索多快完成? | p95 <200ms |
| 生成 | Answer Faithfulness | 回答忠实于检索内容吗? | >0.95(监管行业) |
| 生成 | Answer Relevance | 回答回答的是用户问的吗? | >0.90 |
| 生成 | Hallucination Rate | 编造事实的频率 | <2%(通用)<0.5%(监管) |
| Agent | Tool Selection Accuracy | 工具选对了吗? | >0.92(二选一) |
| Agent | Tool Execution Success | 工具调用成功了吗? | >0.98 |
| Agent | Multi-Step Coherence | 多步推理逻辑连贯吗? | >0.85(4+ 步) |
| 生产 | Cost per Query | 每次请求花多少钱? | <$0.05(面客产品) |
| 生产 | P99 Latency | 端到端响应时间 | <3s(对话型) |
三、检索指标:地基不行,楼一定塌
反直觉:大多数 RAG 失败不是模型的问题。60% 以上的生产 RAG 故障追根到检索层------chunk 切错了、排序不对、漏了关键信息。模型只是在错误的输入上做了正确的推理。
如果你的 Agent 用了 RAG / 知识库 / 文档搜索,检索质量是所有后续质量的天花板。检索错了,提示词再巧也救不回来。
3.1 Context Relevance(上下文相关度)
度量:检索回来的 top-k 块里,有多少和 query 真正相关?
为什么重要:检索 10 个 chunk 只有 3 个相关 = 给模型喂了 70% 噪音。模型不得不从噪音中过滤信号,失败率直线上升。
怎么测:LLM-as-Judge 逐块打分(0-1 相关度),取 top-10 平均。
生产经验:相关度跌破 0.75,原因几乎只有三个------索引漂移(新文档没切好 chunk)、query 意图偏移(用户问的和测试集不一样了)、chunk 策略失配(chunk 太大或太小)。
3.2 Context Recall(上下文召回率)
度量:回答所需的所有信息都检索到了吗?
为什么重要:低召回是 RAG 的隐形杀手。模型无法告诉你"我信息不够",它会基于不完整信息自信地生成错误答案。
目标:>0.90。低于 0.80 说明你在系统性地丢信息。
修复方向:embedding 模型不适配你的领域语义 / chunk 跨段分割导致相似搜索失败。通常重切 chunk 比换模型有效。
3.3 Context Precision(上下文精排)
度量:最相关的块排在 top 位吗?
为什么重要:token 预算只允许传 top-3~5 个 chunk。如果相关块在第 7 位,等于没检索到。
真实案例:一家电商 Agent 的 FAQ 系统,向量搜索召回率 0.91,看起来很好。但 MRR 只有 0.55------相关答案经常排在第 5-7 位,超出 top-3 的 context window。加了 BGE reranker 后 MRR 跳到 0.92,用户满意度从 62% 升到 89%。延迟代价:50ms。这就是"Precision 不是 Recall"的教训。
3.4 Retrieval Latency(检索延迟)
目标:p95 < 200ms,p99 < 500ms。
性能瓶颈:索引增长没调 HNSW 参数 / embedding 和向量库间的网络跳数 / 冷启动缓存 miss。先诊断是哪一个,再决定是否换库。
四、生成指标:模型给出的答案能信吗
4.1 Answer Faithfulness(答案忠实度)
这是监管行业的 P0 指标。不忠实 = 合规风险。
忠实度和幻觉率容易混淆。区别在哪?
- 忠实度:答案是否 基于检索内容 生成(对不对源)
- 幻觉率:答案是否 编造了不存在的东西(有没有凭空造)
一个模型可以对坏上下文 忠实(检索错了但答案确实基于检索内容),也可以不忠实但没幻觉(用了训练数据里的正确事实但不是从检索来的)。两个指标必须同时高才行。
怎么测:从生成答案中提取原子声明(atomic claims),逐条对照检索上下文验证。忠实度 = 有支撑的声明数 / 总声明数。
常见根因:
- temperature 太高(生产应设 0.0-0.3)
- 上下文溢出(检索 + prompt 超了 context limit,模型从训练数据幻觉)
- prompt 模板引导推测("Based on the context, what do you think...")
4.2 Answer Relevance(答案相关度)
忠实 ≠ 相关。答案可以 100% 基于上下文但完全答非所问。
反直觉测法:让 LLM judge 为答案生成 3-5 个"它能回答什么问题",再和原始 query 算语义相似度。
常见根因:Agent 流程里的 query rewriting 步骤把用户意图改没了。
4.3 Hallucination Rate(幻觉率)
CTO 会问你的第一个指标。
和忠实度的区别:忠实度度量"是否基于上下文",幻觉率度量"是否编造了不存在的东西"。模型可以对坏上下文忠实,也可以用良性方式不忠实。
采样策略:每日 5% 生产流量 → 专用幻觉检测 pipeline → 标记可疑 → 人工复核子集。
分布差异:开放性问题比 yes/no 更容易幻觉,数值型比分类型更容易幻觉。按 query 类型分桶统计。
五、Agent 行为指标:不只是会回答问题
反直觉:每一步都正确,整体可能还是错的。Agent 评估和函数测试最大的区别------单步 pass 不代表端到端 pass,因为步骤之间有状态传递,传递会丢失。
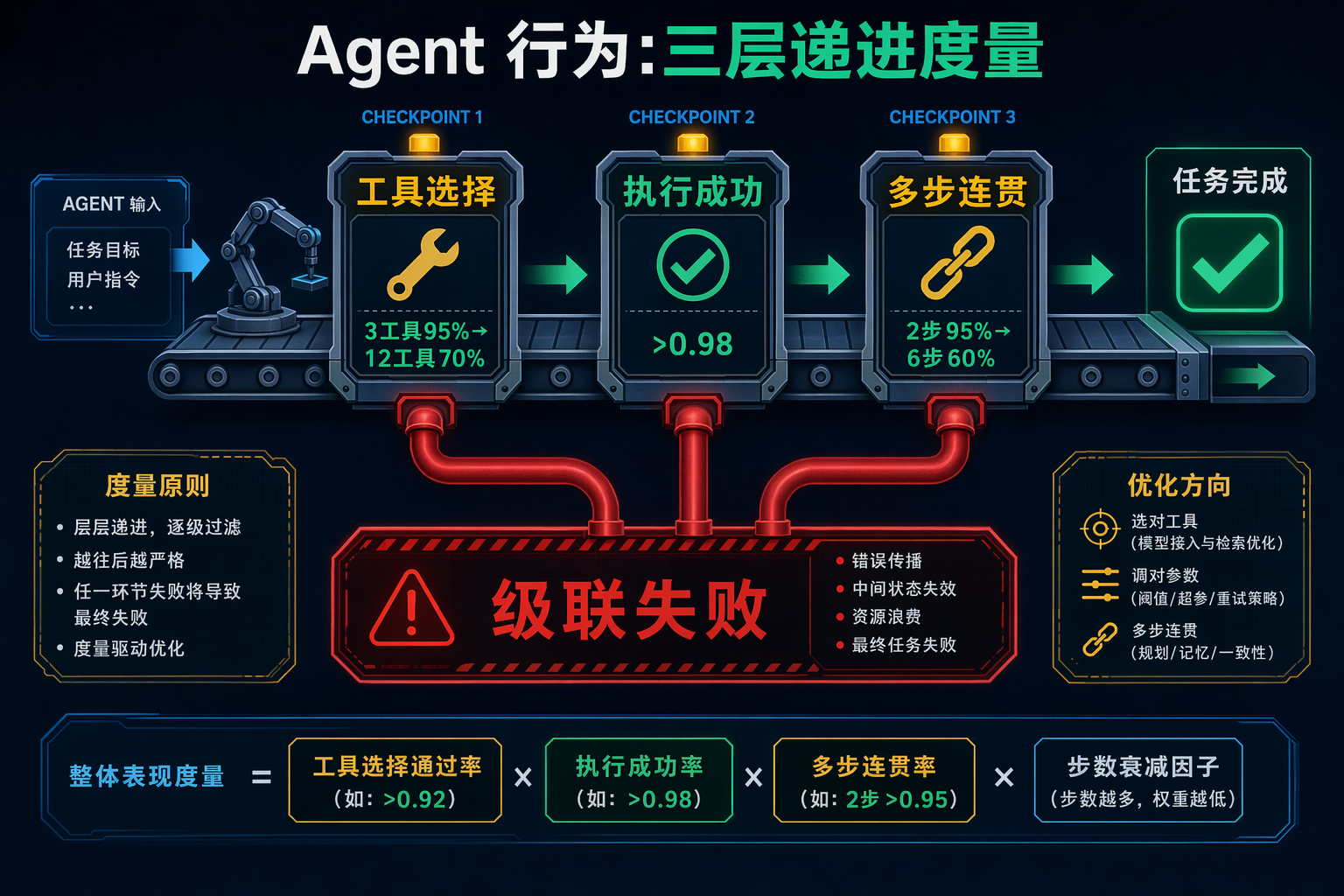
图 4:Agent 行为评估的三层质检关卡------工具选择、执行成功、多步连贯
5.1 Tool Selection Accuracy(工具选择准确度)
为什么单独度量:选错工具会级联------Agent 拿着方钉往圆孔里塞,下游全错。
工具数量与准确率的关系:
- 3 个工具:95% 准确率
- 12 个工具:70% 准确率(同一研究,同一模型)
修复手段:更清晰的工具描述 / 减少单个 agent 的工具数(拆子 agent)/ 在工具选择 trace 上 fine-tune。
5.2 Tool Execution Success(工具执行成功率)
选对了还可能调错------参数格式不对、必填字段漏了、输入不合 schema。
目标:>0.98。低于 0.95 说明参数构造有系统性问题。
最常见失败:Agent 自信地传了一个日期字符串,但 API 要求 ISO 8601。修复靠 structured output 强制(function calling + JSON Schema 校验)。
5.3 Multi-Step Coherence(多步连贯性)
为什么重要:步骤 1 选对工具、拿到结果,到步骤 4 忘了这个结果。单步全对,整体还是错。
衰减规律:
- 2 步 trace:95%+ coherence
- 6 步 trace:60% coherence
修复:分治(6 步拆成 2 个 3 步 + 显式 handoff)/ 持久化状态(不靠每次重新 prompt 全量 history)。
5.4 多 Agent 交接点评估
当系统不是一个 Agent 而是多个协作时,交接点引入额外失败面:
| 交接失败模式 | 度量方法 |
|---|---|
| 上下文丢失(A 传给 B 时信息被截断) | 交接前后 context diff |
| 角色混淆(B 执行了 A 的职责) | Tool selection audit at handoff |
| 循环委托(A→B→A 无限循环) | Max delegation depth + circuit breaker |
| 责任归属模糊(出错不知道怪谁) | Trace 按 agent_id 分段,每段独立评分 |
2025 arXiv 数据:17% 的多 Agent 失败是步骤重复------这正是交接点 circuit breaker 缺失导致的。
六、生产指标:钱和速度
6.1 Cost per Query(单次请求成本)
一次用户 query 可能触发 5-15 次 LLM 调用(重写、检索评分、工具选择、生成、验证)。Token 膨胀把 0.02 变成 0.30 都不会有人注意,直到月底账单。
成本估算公式:
Cost_per_query = Σ(tokens_i × price_per_token_i) + tool_api_costs + infra_per_query
≈ (input_tokens × $X + output_tokens × $Y) × avg_LLM_calls_per_query以 Claude Sonnet 4.6 为例:一次典型 RAG Agent query 包含 3 次 LLM 调用(检索评分 + 生成 + 验证),平均 input 4K tokens/次 + output 1K tokens/次,成本 ≈ 0.03-0.05。加上 eval judge(30-50%)= 0.04-0.075/query 总成本。
成本飙升三原因:
- system prompt 随时间越来越长
- 失败触发重试风暴
- 知识库增长导致检索 chunk 越来越大
6.2 P99 Latency(P99 延迟)
平均延迟骗人。1 秒平均 + 15 秒 P99 = 用户放弃。
目标:对话型 <3s,分析型 <10s。超过 10 秒用户脱离。
三大延迟杀手:向量库冷缓存 / 外部 API 超时 / 长输出 token-by-token 流式瓶颈。先定位主因再优化。
七、LLM-as-Judge:怎么评估评估本身
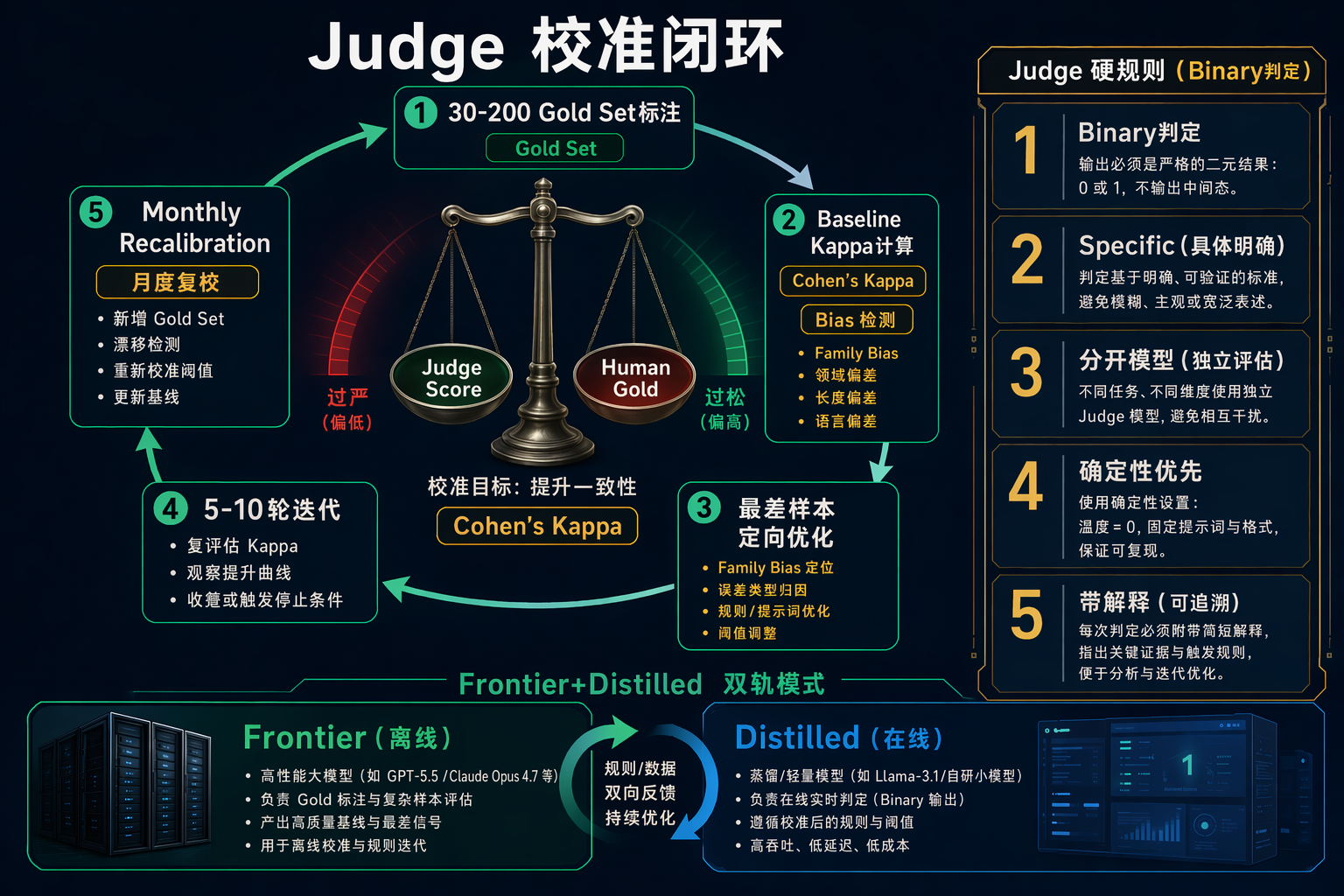
图 5:LLM-as-Judge 校准方法论------Gold Set + Kappa + 月度复校闭环
反直觉:不校准的 LLM Judge 比没有 Judge 更危险。没有 Judge 你知道自己是裸奔;有了不校准的 Judge,你觉得自己穿了盔甲------其实是纸糊的。
人工评每天 100 条还行,10,000 条就不行了。LLM-as-Judge 是唯一经济可行的规模化评估方案。但它有严重的偏差问题。
2026 年 LLM-as-Judge 的现实
一个团队在 2024 年用 GPT-4 做 groundedness judge,评 GPT-4 生产输出。三个月 dashboard 全绿。然后请了领域专家人工评 50 条------Cohen's Kappa 只有 0.31。Judge 系统性高估了自家模型输出(family bias),低估了流畅幻觉(length-confidence bias)。Dashboard 骗了三个月。这个教训在 2026 年的 GPT-5.x / Claude Opus 4.7 时代依然成立------同族模型互评的 family bias 没有消失,只是更隐蔽。
校准方法论
┌─────────────────────────────────────────────────────┐
│ 1. Gold Set: 30-200 个领域专家标注样本
│ 2. Baseline: accuracy / precision / recall / F1 /
│ Pearson / Spearman / Cohen's Kappa 全套
│ 3. Iterate: 针对最差样本用 meta-LLM 优化 prompt
│ (OPRO pattern, Yang et al. 2023)
│ 4. 重复 5-10 轮直到 alignment plateau
│ 5. Monthly recalibration (模型更新/分布漂移)
└─────────────────────────────────────────────────────┘五条硬规则
| 规则 | 原因 |
|---|---|
| Binary pass/fail,不用 1-10 | LLM 评分不一致,同一条可能 4 也可能 6 |
| 每个 eval 一句话说清检测什么 | "回复是否引用了检索外的信息?" 好;"回复质量好吗?" 坏 |
| 附带解释 | 不重读每条交互也能识别失败模式 |
| 确定性检查优先 | precision/recall/schema/数值 用函数,不用 LLM |
| 分开 judge 和 generator | 同模型评自己 = family bias |
生产部署模式
Frontier Judge (GPT-5.5 / Claude Opus 4.7) → 离线 eval + pre-prod 评分
Distilled Judge (Luna / Turing-flash) → 在线生产 100% trace 评分精度差 5 个点可以接受,因为在线量大,统计上够用。
八、分阶段实施路径
不要一口气建 12 个指标。按项目阶段分三期:
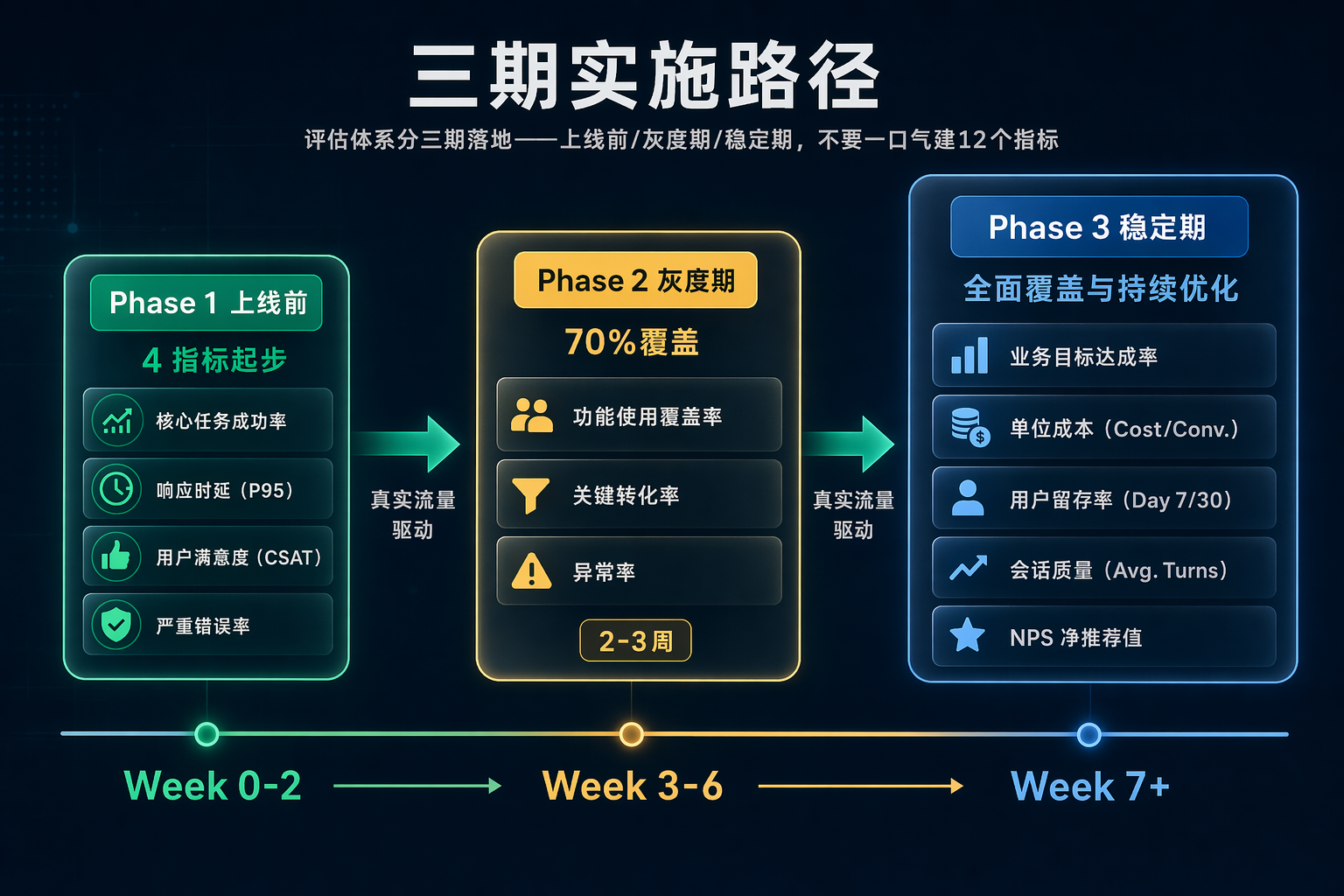
图 6:三期实施路径------4 指标起步覆盖 70% 上线前失败
Phase 1:上线前(Week 0-2)
目标:拦住最常见的上线前失败。
✅ Context Relevance
✅ Context Recall
✅ Context Precision
✅ Answer Faithfulness这 4 个指标覆盖 70% 的上线前失败。实施成本:1 周工程 + Ragas 开箱即用。
Phase 2:灰度期(Week 3-6)
目标:捕捉真实用户流量才暴露的问题。
✅ Hallucination Rate
✅ Answer Relevance
✅ Tool Selection Accuracy测试集永远不是生产分布。真实 query 意图偏移、长尾 query、边缘 case 只有上线才能暴露。
Phase 3:稳定期(Week 7+)
目标:优化运行系统,不是拦截上线阻塞问题。
✅ Cost per Query
✅ P99 Latency
✅ Tool Execution Success
✅ Multi-Step Coherence
✅ Retrieval Latency用例修正
| 场景 | 额外优先 |
|---|---|
| 监管行业(医疗/金融/法律) | Faithfulness + Hallucination 提到 Phase 1 |
| 纯 Agent(非 RAG) | 跳过检索指标,Tool Selection 提到 Phase 1 |
| 内部工具(非面客) | Cost 阈值放宽到 <$0.10 |
Day 1 速启:如果你只有 1 天时间
如果你今天就要出一版最小可行评估,不用读完本文,直接跑这段:
python
# pip install ragas langchain-openai datasets
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision
from datasets import Dataset
# 准备你的 eval 数据(至少 20 条真实 query + 检索结果 + 生成答案)
eval_data = Dataset.from_dict({
"question": questions, # List[str]
"answer": generated_answers, # List[str]
"contexts": retrieved_contexts, # List[List[str]]
"ground_truth": reference_answers # List[str](可选)
})
result = evaluate(
dataset=eval_data,
metrics=[faithfulness, answer_relevancy, context_precision],
)
print(result) # {'faithfulness': 0.92, 'answer_relevancy': 0.87, 'context_precision': 0.78}3 个指标、20 行代码、1 小时内跑通。然后带着数据去和团队讨论"我们的阈值应该设多少"。
九、工具选型:不必从零搭建
| 工具 | 覆盖范围 | 适合场景 | 短板 |
|---|---|---|---|
| Ragas | 检索 + 忠实度 + 相关度 | RAG 评估起步 | 无 Agent 指标 |
| DeepEval | 检索 + Agent + 更广 metric | Agent 评估全面性 | 社区较新 |
| LangSmith | Trace + observability | LangChain 生态 | 弱离线 benchmark |
| Braintrust | CI/CD 集成 + regression gate | 防回退 | 生态绑定 |
| Langfuse | 开源 trace + annotation | 自部署 + 隐私 | 需自建 eval |
| Galileo | 幻觉检测 (Luna) + 偏差发现 | 精确幻觉率度量 | 不覆盖全链路 |
| Maxim AI | 端到端 + simulation | 企业级全流程 | 商业产品 |
实战建议:用 Ragas 做 RAG 指标,自定义 evaluator 做 Agent 指标,标准 APM(Datadog / OpenTelemetry)做生产健康指标。三套系统出一个统一视图。
十、持续评估:不是跑一次就完了
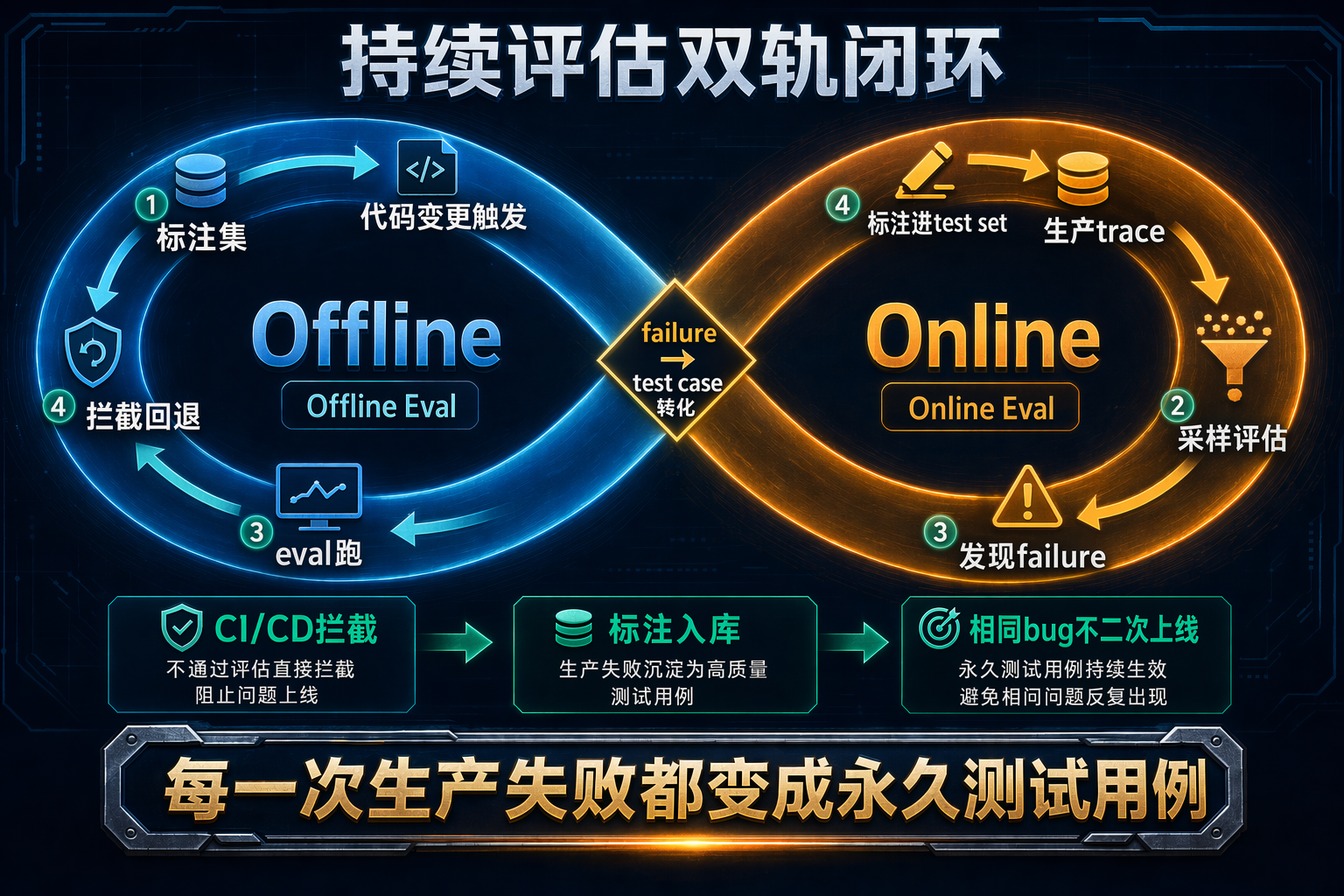
图 7:Offline + Online 双轨持续评估闭环
Offline eval vs Online eval
| Offline(离线) | Online(在线) | |
|---|---|---|
| 数据 | 标注 benchmark 集 | 真实生产流量 |
| Ground truth | 有 | 没有,靠代理信号 |
| 频率 | 每次代码变更 | 持续 + 每日汇总 |
| 作用 | 拦截回退 | 发现新 failure mode |
| 关键区别 | 离线过了 ≠ 生产没问题 | 在线告警 ≠ 一定要回滚 |
闭环机制
生产 trace → 在线 eval → 发现 failure → 标注进 offline test set
→ 修复 → offline eval 验证修复 → 部署 → 在线 eval 确认这个闭环确保:每一次生产失败都变成永久测试用例。相同失败不能再次上线。
非确定性处理
Agent 行为不确定。同一个 query 跑 3-5 次,取 mean + variance。高 variance 本身就是需要调查的信号(行为不稳定)。
十一、常见坑与对策
| 坑 | 后果 | 对策 |
|---|---|---|
| eval 集太小 (<50) | 指标方差大,无统计意义 | 至少 200 条,覆盖 query 类型分布 |
| eval 集从不更新 | 和生产分布漂移 | 每月从生产采样补充 |
| 同一模型评自己 | Family bias,Dashboard 全绿但实际拉胯 | Generator 和 Judge 用不同模型 |
| 只看 mean 不看 P99 | 用户记住的是最慢的那次 | 所有延迟指标报 p50 + p95 + p99 |
| 评估只在 staging 跑 | 生产 query 分布和 staging 完全不同 | 上线后持续采样评估 |
| 指标太多但没 owner | 没人看 = 等于没有 | 每个指标分配 oncall owner |
| 幻觉率按 query 类型不分桶 | 开放问题 30% 幻觉被平均到 2% | 按 query 类型分桶,找长尾重灾区 |
| Eval 成本失控 | LLM judge 评每条 = 推理成本 ×1.5 | 采样率 5-20%,高风险类型全量 |
十二、10 步 Checklist:从 0 到有评估体系
□ 1. 定义 3 个你最怕的失败模式(幻觉?选错工具?太慢?)
□ 2. 收集 50+ 真实 query 作为 gold set(不是自造的)
□ 3. 用 Ragas 跑一次 baseline(faithfulness + relevance + precision)
□ 4. 设阈值:和团队对着 baseline 数据讨论"低于多少不能上线"
□ 5. 接入 OpenTelemetry 记录每次 LLM 调用的 token 和延迟
□ 6. 部署 LLM-as-Judge(先用 frontier 模型,别省这个钱)
□ 7. 每次 prompt / retrieval 变更触发 offline eval(CI 集成)
□ 8. 上线后 5% 采样 online eval + 每日 rollup 报告
□ 9. 月度校准 judge(30 条 human review,算 Kappa)
□ 10. 每次生产 failure → 标注进 test set(闭环)完成前 5 步 ≈ 1 周。完成全部 ≈ 3 周。之后是持续运营,不是再次建设。
十三、总结:一张图记住全部

图 8:5 条可直接迁移的核心设计准则
五条带走的准则
- 评估先于 MVP:建评估的最佳时机是 Day 1,第二佳是现在。改造比原生贵 4-6 倍。
- 分层度量,不只看最终输出:检索层、生成层、Agent 层各有独立指标,问题出在哪层就在哪层修。
- LLM Judge 需要校准:不校准的 Judge 比没有 Judge 更危险(给你虚假安全感)。
- Binary > Range,Specific > Generic:评估要具体、要二值,不要模糊的 1-10 分。
- 闭环比单次重要:生产失败 → 标注 → 进 test set → 修复 → CI/CD 拦截。确保相同 bug 不能二次上线。
参考
- Building an Evaluation Harness for Production AI Agents: A 12-Metric Framework --- Intuz, TDS 2026
- LLM-as-Judge Best Practices 2026 --- FutureAGI
- Continuous Evaluations for AI Agents --- Arthur.ai
- AI Agent Evaluation: A Practical Framework --- Braintrust
- Evaluating AI Agents in 2025: A Practical Guide --- Turing College
- How to Build an Agent Evaluation Framework --- Galileo
- A Practical Guide to LLM & Agent Evaluation --- Trilogy AI
- AgentBench: Evaluating LLMs as Agents --- ICLR 2024
- LLM Evaluation 101 --- Langfuse
- KPMG Q3 2025 AI Agent Adoption Survey
- MIT 2025 NANDA Study on Enterprise AI Pilots