本质是一块内存预留空间,用来缓存输入输出数据。
先来例子入手
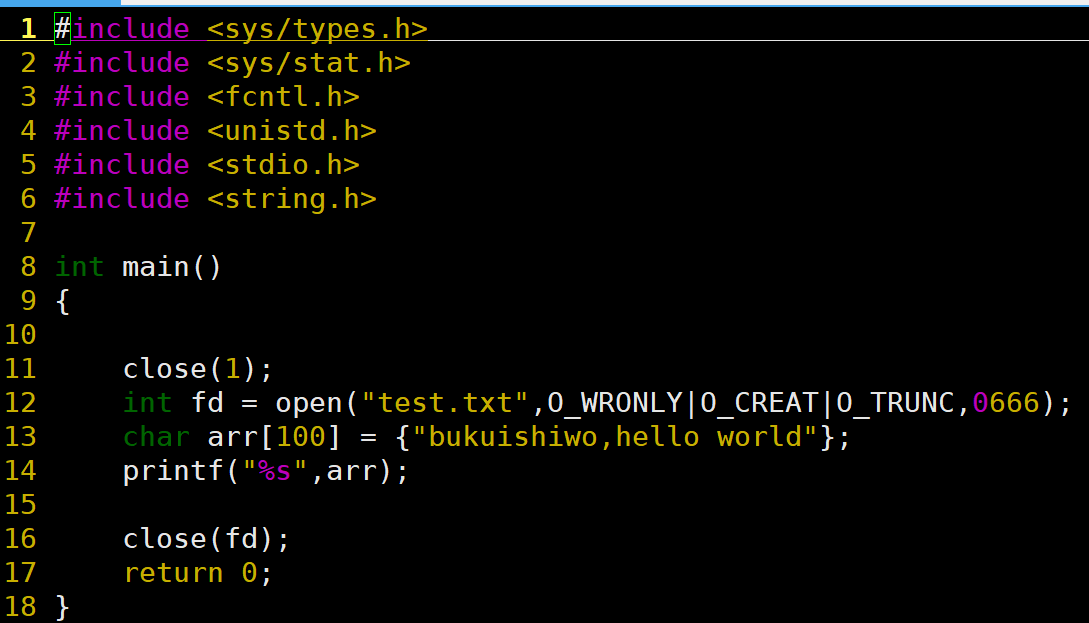
可以看到的是这个运行完之后,硬盘中test.txt文件中并没有写入内容。
为什么?
首先我们要知道对于操作系统存在一块缓存区,在语言层面上同样存在一块缓存区。所以实际上,存在两块缓存区!只有当语言上的缓存区(后面称为缓存区1)刷新到操作系统中的缓存区(后面称为缓存区2),在接着刷新到硬盘上,才是完整的写入操作。
刷新的方式总共存在三种:
全缓冲:
当缓存区满了就刷新
行缓冲:
遇到 '\n' 就刷新
无缓冲:
只要写入缓存区,就会进行刷新
调用flush/flush进行强制刷新,系统结束时自动刷新。
这些刷新方式即适用于语言层面上的,同时适用于系统的。
对于输入流:方向和输出流的方向是相反的,这部分的刷新机制是全缓冲
标准输出流:行刷新
标准错误流:全缓冲
普通输出流:全缓冲
所以在这个基础上我们来研究一下上面代码
我是用系统调用将这个普通输出流成为语言级printf的输出流,此时printf会输出到test.txt 的缓存区中,我接着关闭这个文件流,会触发刷新test.txt的系统缓存区,但是问题是我这个还没有刷新到内存缓存区中,等文件结束后,缓存区1才会刷新到对应的缓存区2,但是此时,由于这个流已经被删除了,这个刷新无效。最终导致了内容没有被写入
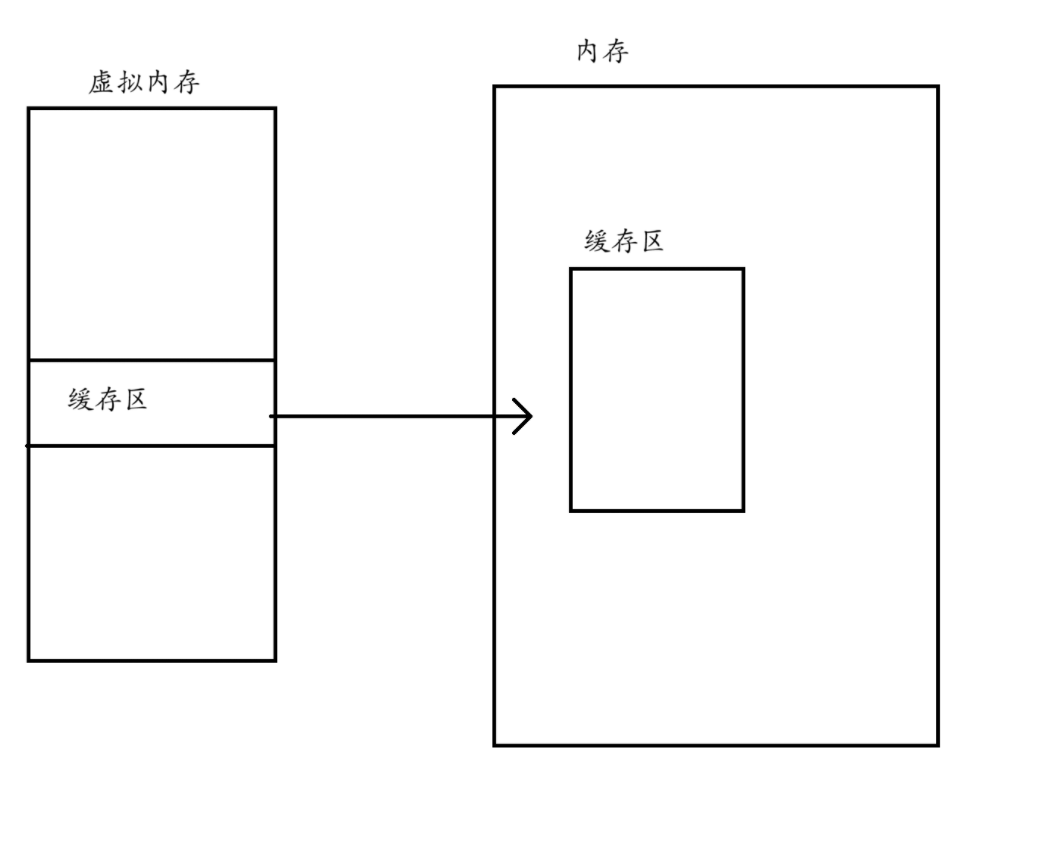
语言层面的缓存区是如何写入到系统层面的缓存区的?
通过系统调用write进行写入!可以看出来的是这个说白了就是暂存在虚拟地址而已!
至于系统层面如何刷新到硬盘之后再将。
缓冲有什么必要?
假设一个场景,现在你要清理垃圾,你是准备看到垃圾就下楼去扔一次,还是等到差不多清理完了或者说是快满了,再扔一次?
本质原因:刷新需要消耗资源,所以尽量减少刷新次数,就能增加效率和节省资源
为什么要设计两个垃圾桶?
因为从缓冲区1刷新到缓冲区2是需要调用wrie系统调用的,和上面一个意思,尽量减少调用的次数,就能降本增效。