Redis 跳表实现详解
Redis 的有序集合 zset 需要同时支持两类能力,一类是按 member 快速定位,一类是按 score 有序遍历,比如 zrange、zrevrange、zrank 这类操作
如果只用数组,二分查找可以很快,但插入和删除需要移动大量元素,如果只用普通链表,插入删除很方便,但查找只能从头遍历,如果使用 B+ 树或平衡树,时间复杂度也很好,但实现上会涉及节点分裂、旋转、维护平衡等细节,工程实现成本更高
跳表的思路是给链表增加多级索引,底层仍然是一条完整有序链表,上层节点只保留一部分元素作为快速通道,查找时从最高层开始向右走,走不动就向下一层,最终落到底层定位目标节点,它本质上是用概率换平衡,用多层指针换查询效率
一、为什么 Redis zset 会选择跳表
1. zset 需要有序遍历
zset 不是简单的 key-value 结构,它需要按照 score 排序,例如排行榜、延迟队列、范围查询等场景都依赖有序性
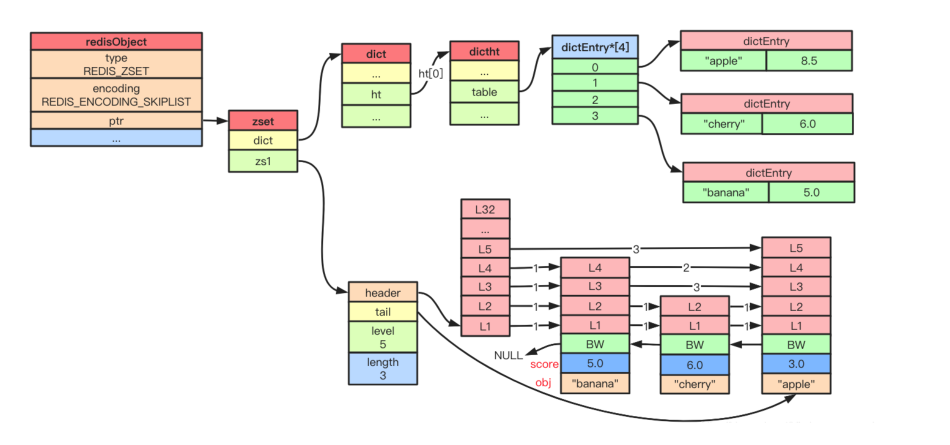
普通哈希表可以做到按 member 快速查询,但它没有顺序,无法高效支持 zrange 这类范围遍历,所以 Redis zset 在 skiplist 编码下会同时维护 dict 和 zskiplist
dict 负责从 member 快速找到 score,zskiplist 负责按照 score 组织节点并支持范围查询、排名查询和顺序遍历
2. 跳表适合动态增删
理想情况下,跳表像给有序链表建立了多级目录,越高层节点越少,越低层节点越多,查找时可以跳过大量无关节点
但如果严格要求每隔一个节点生成一个上层节点,那么每次插入和删除都可能破坏原有结构,重建索引成本很高,所以跳表使用随机层数来近似理想结构
一个节点能不能出现在更高层,不靠全局重构,而靠概率决定,节点数量足够多时,整体结构会趋近于均衡状态,单个节点的删除不会导致整个跳表重建
3. Redis 对跳表做了工程化取舍
Redis 中跳表最大层数是 32,概率因子 ZSKIPLIST_P 是 0.25,也就是每向上一层,节点继续晋升的概率是四分之一
这样做会让结构比二分式索引更扁平一些,牺牲一点查询路径长度,换来更少的高层节点和更低的内存开销
Redis 的跳表节点还维护 backward 指针和 span 字段,backward 用于反向遍历,span 用于计算排名,比如 zrank
二、跳表节点到底长什么样
1. Redis 的 zskiplistNode
Redis 的跳表节点大致包含 member、score、后退指针和多层 level,每一层 level 里有一个 forward 指针和一个 span
c
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;这里最关键的是 level[],它是一个柔性数组,节点创建时会根据随机出来的层数申请不同大小的空间
普通节点可能只有 1 层,少数节点有 2 层,更少数节点有 3 层,这样上层链表天然更稀疏,查找时就可以从高层快速跨越
2. 我的 kvstore_skiplist 节点设计
我的 kvstore_skiplist 是一个更简化的跳表实现,它没有 Redis 的 score、span、backward,也没有额外的 dict 辅助索引,节点只保存 key、value 和多层 next 指针
skiplist_node 中的 level 是一个 vector,每个元素代表一层,每一层只有一个 next 指针,含义就是当前节点在这一层的后继节点
cpp
class skiplist_node {
public:
string key;
string value;
class skiplist_level {
public:
skiplist_level(): next(nullptr) {}
skiplist_node *next;
};
vector<skiplist_level> level;
};这个设计保留了跳表最核心的部分,也就是多层有序链表结构,适合用来理解跳表的查找、插入和删除流程
3. 头节点和当前层数
kvstore_skiplist 里有一个虚拟头节点 m_header,它不存真实数据,只负责作为每一层链表的起点
构造函数中创建了一个拥有 MAXLEVEL 层的头节点,初始真实数据为空,所以 m_count=0,当前跳表层数 m_level=1
cpp
kvstore_skiplist::kvstore_skiplist()
: m_count(0),
m_level(1)
{
m_header = new skiplist_node(MAXLEVEL, "\0", "\0");
}头节点必须拥有最大层数,因为以后新节点可能随机到更高层,此时高层链表也需要从头节点开始挂接
三、随机层数是跳表的核心
1. 为什么不能固定分层
如果固定每两个节点抽一个上层节点,每四个节点抽一个更高层节点,查找结构确实很漂亮,但只要中间插入或删除节点,就可能破坏这种严格比例
如果每次都为了保持理想结构而重建索引,那么跳表就失去了动态增删的优势
所以跳表不追求每一层绝对均匀,而是让每个节点通过随机概率决定自己有多少层,只要数据规模足够大,整体分布就会接近理想状态
2. kvstore_skiplist 的 random_level
我的实现中 MAXLEVEL=32,SKIPLIST_P=0.5,也就是每次有一半概率继续向上增加一层
cpp
int kvstore_skiplist::random_level() {
int level = 1;
while((rand() & 0xFFFF) < (SKIPLIST_P * 0xFFFF)) {
level += 1;
}
return ((level<MAXLEVEL) ? level : MAXLEVEL);
}这段代码可以理解为连续抛硬币,第一次成功就让节点拥有第 2 层,第二次成功就拥有第 3 层,直到失败为止
因此大部分节点只有 1 层,少部分节点有 2 层,更少部分节点有 3 层,高层节点数量会越来越少
3. Redis 和我的实现有什么区别
Redis 的概率是 0.25,我的实现是 0.5
P=0.5 会让节点更容易晋升到高层,上层索引更密,查询时可能少走一些节点,但指针数量更多,内存占用更高
P=0.25 会让结构更扁平,高层节点更少,内存更省,这也是 Redis 针对工程场景做出的选择
四、插入操作 zset 如何实现
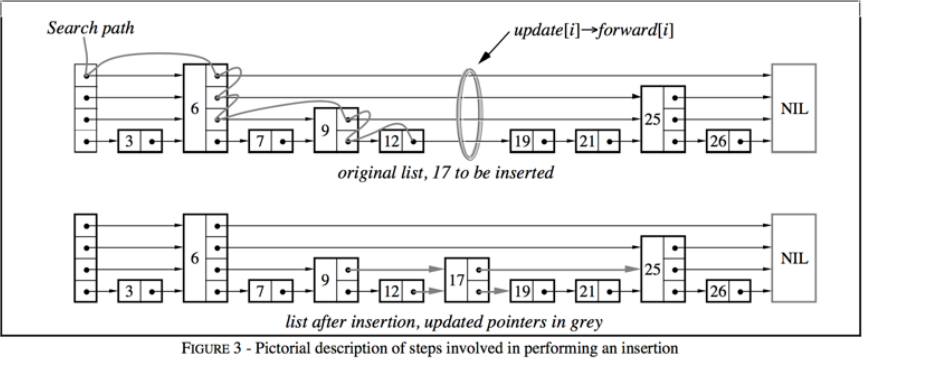
1. update 数组记录每一层前驱
跳表插入最关键的是找到新节点在每一层应该插到谁后面
我的 zset 中使用 update 数组记录每一层的前置节点,比如 update[i] 表示新节点如果出现在第 i 层,那么它应该插在 update[i] 后面
查找过程从当前最高层开始,能向右就向右,不能向右就下降一层
cpp
for(int i=m_level-1; i>=0; --i) {
while(node->level[i].next && key.compare(node->level[i].next->key)>0) {
node = node->level[i].next;
}
update[i] = node;
}这就是跳表查找路径的核心逻辑,横向移动用于跳过更小的 key,纵向下降用于进入更细粒度的链表
2. 随机层数并更新最高层
找到每一层前驱之后,调用 random_level 得到新节点层数
如果新节点层数大于当前跳表最高层,那么新增的那些高层还没有任何真实节点,它们的前驱都应该是 m_header
cpp
int level = random_level();
if(level > m_level) {
for(int i=m_level; i<level; ++i) {
update[i] = m_header;
}
m_level = level;
}这里建议使用 i<level,因为层数为 level 的节点,下标范围是 0 到 level-1
3. 修改指针完成插入
真正插入时,只需要在新节点拥有的每一层做链表插入
node->level[i].next = update[i]->level[i].next 表示新节点先指向原来的后继,update[i]->level[i].next = node 表示前驱再指向新节点
cpp
node = new skiplist_node(level, key, value);
for(int i=0; i<level; ++i) {
node->level[i].next = update[i]->level[i].next;
update[i]->level[i].next = node;
}这和普通单链表插入本质相同,只是跳表需要在多个层级重复做同样的指针调整
五、查找操作 zget 如何实现
1. 从最高层开始查找
查找 key 时同样从最高层开始,当前层的下一个节点比目标 key 小,就一直向右走
如果下一个节点不存在,或者下一个节点已经大于等于目标 key,就下降一层继续找
cpp
skiplist_node* kvstore_skiplist::get_node(const string &key) {
skiplist_node *node = m_header;
for(int i=m_level-1; i>=0; --i) {
while(node->level[i].next && key.compare(node->level[i].next->key)>0) {
node = node->level[i].next;
}
}
node = node->level[0].next;
if(!node || key.compare(node->key)!=0) return nullptr;
return node;
}循环结束后,node 停在目标位置的前一个节点,所以还要走一步到 level[0].next,再判断是不是目标 key
2. 为什么最终一定要回到底层
高层链表只包含部分节点,不一定包含目标节点
底层链表才包含所有节点,所以无论上层跳得多快,最终都要落到底层完成精确判断
这也是跳表名字里"跳"的含义,高层用于快速跳跃,底层用于完整存储
3. zget 和 zmod 的关系
zget 和 zmod 都复用了 get_node
zget 找到节点后返回 value,没找到返回空 string,zmod 找到节点后直接修改 value,没找到返回 1
这种写法把查找逻辑集中在一个函数里,避免插入、查询、修改重复写同一段跳表搜索代码
六、删除操作 zdel 如何实现
1. 删除也需要 update 数组
删除节点时也要先找到每一层的前驱节点,因为只有前驱节点才能把 next 指针绕过待删除节点
zdel 的前半部分和 zset 很像,都是从最高层向下查找,并记录每一层的前驱
cpp
for(int i=m_level-1; i>=0; --i) {
while(node->level[i].next && key.compare(node->level[i].next->key)>0) {
node = node->level[i].next;
}
update[i] = node;
}定位完成后,底层后继才可能是真正要删除的节点
2. del_node 修改多层指针
删除时遍历所有层,如果某一层的前驱确实指向待删除节点,就把前驱的 next 改成待删除节点的 next
cpp
void kvstore_skiplist::del_node(skiplist_node *node, const vector<skiplist_node *> &update) {
for(int i=0; i<m_level; ++i) {
if(update[i]->level[i].next == node) {
update[i]->level[i].next = node->level[i].next;
}
}
while(m_level>1 && m_header->level[m_level-1].next==nullptr) {
m_level--;
}
m_count--;
}删除完成后,如果最高层已经没有任何节点,就把 m_level 往下降,避免后续查找从空层开始浪费时间
3. 析构函数为什么只遍历第 0 层
所有真实节点一定都在第 0 层出现,高层只是这些节点的索引
所以释放整个跳表时,只需要沿着第 0 层从头到尾释放每个节点,不需要每一层都遍历,否则同一个节点会被重复释放
cpp
skiplist_node *node = m_header->level[0].next;
while(node != nullptr) {
skiplist_node *next = node->level[0].next;
delete node;
node = next;
}
delete m_header;这也是理解跳表结构时容易忽略的一点,高层不是新节点集合,而是同一批节点上的额外指针
七、这个实现和 Redis 跳表的差异
1. 排序依据不同
Redis zset 的排序依据是 score,当 score 相同时还会比较 member,保证顺序稳定
我的 kvstore_skiplist 是按 key.compare 排序,更像是一个有序 key-value 容器,不是完整的 Redis zset
2. Redis 多维护了 dict
Redis zset 同时有 dict 和 zskiplist
如果按 member 查 score,dict 可以直接定位,如果按 score 范围遍历,skiplist 可以顺序扫描
我的实现只有 skiplist,所以查询也走跳表路径,不具备哈希表 O(1) 定位 member 的能力
3. Redis 多维护了 span 和 backward
Redis 的 span 用于排名计算,比如 zrank 不需要从头数到目标节点
Redis 的 backward 用于反向遍历,比如 zrevrange 可以从尾部往前走
我的实现没有这两个字段,所以更适合讲清楚跳表的基本增删改查,而不是完整复刻 Redis zset
八、实现细节中需要注意的点
1. 插入重复 key 的处理
当前 zset 直接插入新节点,没有判断 key 是否已经存在
如果业务语义是 key-value 存储,那么相同 key 再次 zset 时更合理的行为是更新 value,而不是插入重复 key
可以在插入前复用 get_node 判断,如果存在就修改 value 并返回
2. 层数下标边界
当新节点层数大于当前 m_level 时,更新新层前驱的循环建议写成 for(int i=m_level; i<level; ++i)
因为 level 表示层数,不是最大下标,节点有 level 层时,合法下标是 0 ~ level-1
3. zkeys 空表问题
zkeys 最后调用了 ret.back(),如果跳表为空,ret 也是空字符串,此时访问 back() 有风险
更稳妥的写法是先判断 !ret.empty(),再决定是否删除最后一个换行符
九、总结
跳表可以理解为"带多级索引的有序链表",底层保存全部数据,上层保存稀疏索引,查找时从高层快速跳跃,最终落到底层精确定位
Redis zset 选择跳表,是因为它既要支持有序范围查询,又要支持频繁插入删除,跳表用随机层数避免了复杂的树旋转和节点分裂,在工程实现上更直接
我的 kvstore_skiplist 保留了跳表最核心的机制,random_level 负责生成层数,update 数组负责记录每一层前驱,插入和删除本质上都是多层链表指针修改
真正理解跳表,不是背它的时间复杂度,而是理解三件事,第一是上层链表为什么能加速查找,第二是随机层数为什么能替代理想分层,第三是插入删除为什么只需要改局部指针而不需要重建全局结构