文章目录
- 引言
- 设计说明
- 原理方案
-
- [Spring AI 的 @Tool 机制](#Spring AI 的 @Tool 机制)
- [SuperSQL 工作流](#SuperSQL 工作流)
- 配置驱动训练
- 代码解析
- 验证结果
-
- 普通问答(走向量检索)
- [聚合查询(走 Text-to-SQL)](#聚合查询(走 Text-to-SQL))
- 复杂查询测试
- 调试日志
- 优化方向
- 小结
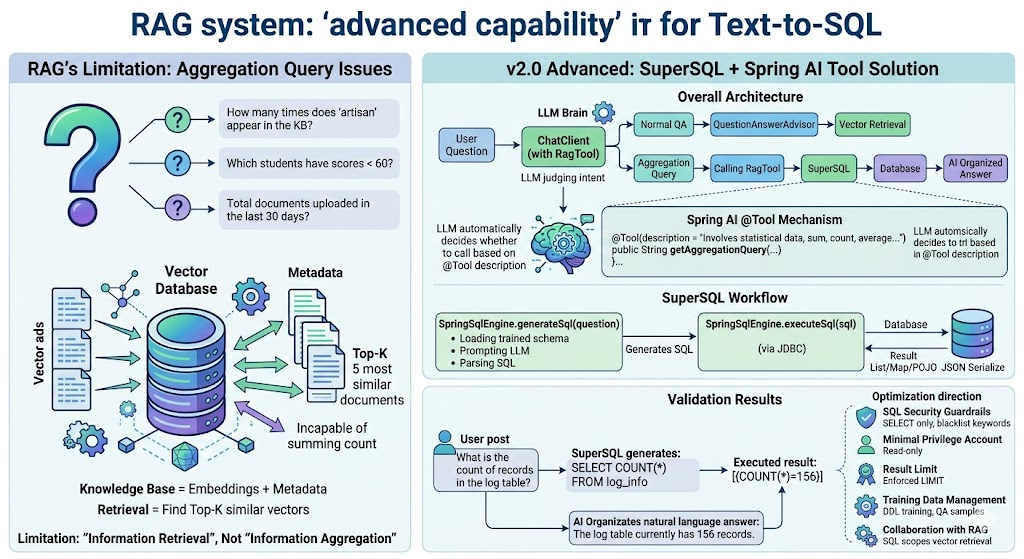
引言
向量检索擅长"语义相似度匹配",但有些问题它天生答不好。比如:
- "知识库里出现了多少次' artisan'这个词?"
- "成绩低于 60 分的学生有哪些?"
- "近 30 天上传的文档总数是多少?"
这些是统计类、计数类、范围类问题,向量库的 Top-K 机制根本无能为力------你召回 5 条最相似的文档,怎么算总数?
本篇将介绍项目 v2.0 的进阶能力:通过 SuperSQL + Spring AI Tool 实现 Text-to-SQL,让 AI 自动识别聚合查询并走 SQL 路径。
设计说明
跨向量聚合的本质
向量检索的局限:
Java
向量库 = 一堆语义向量 + 元数据
检索操作 = 找最相似的 K 个向量它本质上是"信息查找",不是"信息汇总"。要做汇总,必须在结构化数据上做。
业界主流的三种解决方案:
| 方案 | 适用场景 | 代价 |
|---|---|---|
| 知识库隔离 | 多租户、多项目 | 用户体验差,无法跨库 |
| Text-to-SQL | 结构化数据 + 数值聚合 | 需要维护两套库 |
| Map-Reduce | 全文摘要、跨片段总结 | 计算成本高,依赖 LLM 多轮 |
本项目针对"统计类查询"采用 Text-to-SQL 方案。
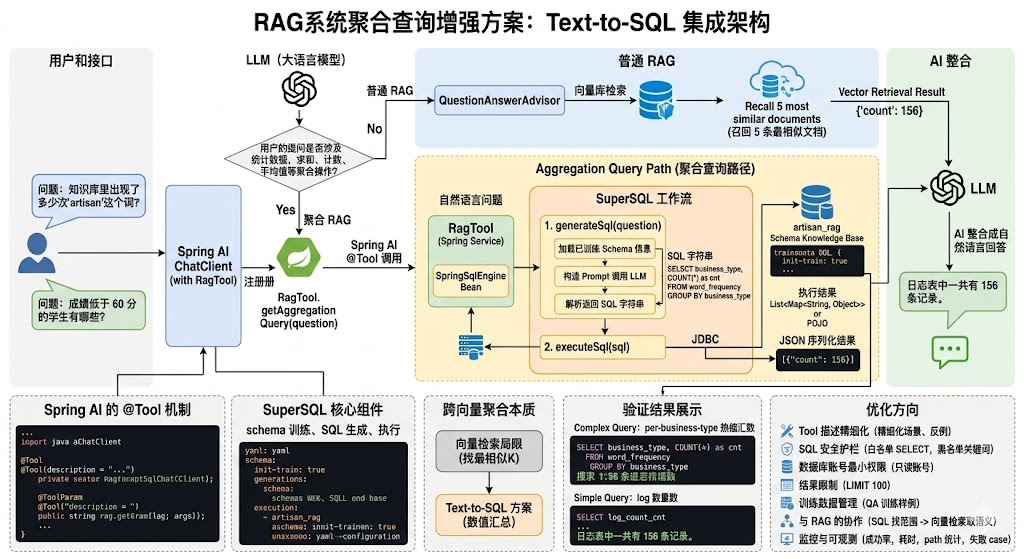
整体架构
Java
用户提问
↓
ChatClient(带 RagTool)
↓
LLM 判断意图
├─ 普通问答 → QuestionAnswerAdvisor → 向量检索
└─ 聚合查询 → 调用 RagTool → SuperSQL → 数据库 → 返回结果
↓
AI 整合成自然语言回答关键创新点:不再让 LLM 自行判断是否聚合 (这需要额外一次 LLM 调用),而是利用 Spring AI 的 @Tool 机制------LLM 在生成回复时会自动决定是否调用 Tool。
为什么用 SuperSQL?
Text-to-SQL 是个独立的工程问题:
- 需要让 LLM 了解数据库 schema
- 需要将自然语言可靠转换为合法 SQL
- 需要执行 SQL 并把结果格式化
SuperSQL 是一个开源框架,封装了上述能力:自动训练 schema、生成 SQL、执行查询。集成到 Spring AI 项目只需引入 starter。
原理方案
Spring AI 的 @Tool 机制
@Tool 是 Spring AI 对 Function Calling 的封装。在方法上加注解后,方法会被注册为 LLM 可调用的"工具":
java
@Tool(description = "涉及统计数据、求和、计数、平均值等聚合操作")
public String getAggregationQuery(@ToolParam(description = "用户的提问") String question) {
// ...
}LLM 在生成回复时,会根据 description 判断是否需要调用这个工具。如果调用,参数会被自动从对话上下文中提取(也通过 LLM 推理)。
整个流程:
Java
1. 用户:"知识库里有多少个文档?"
2. LLM 看到 prompt + 注册的工具列表
3. LLM 决定调用 getAggregationQuery(question="知识库里有多少个文档?")
4. Spring AI 拦截 function call,执行对应 Java 方法
5. 方法返回结果(如 "{"count": 12}")
6. LLM 收到结果,组织成自然语言:"您的知识库目前有 12 个文档..."SuperSQL 工作流
java签
自然语言问题
↓
SpringSqlEngine.generateSql(question)
├─ 加载已训练的 schema 信息(DDL、表关系)
├─ 构造 prompt 调用 LLM
└─ 解析返回的 SQL 字符串
↓
SpringSqlEngine.executeSql(sql)
├─ 通过 JDBC 执行
└─ 返回 List<Map<String, Object>> 或 POJO
↓
JSON 序列化结果,返回给上层配置驱动训练
yaml
super-sql:
init-train: false # 第一次设为 true(训练 schema),之后可改为 false
scope: ALONE # ALL 整库训练, ALONE 单库训练
schemas:
- schema: artisan_rag # 指定数据库init-train: true 时,SuperSQL 会扫描数据库的所有 DDL,把表结构信息训练到内部知识库中,供后续 generateSql 时参考。
代码解析
依赖引入
xml
<dependency>
<groupId>com.aispace.supersql</groupId>
<artifactId>super-sql-spring-boot-starter</artifactId>
<version>1.0.0-M1</version>
</dependency>starter 会自动装配 SpringSqlEngine Bean。
RagTool ------ 聚合查询工具
java
@Service
public class RagTool {
@Autowired
private SpringSqlEngine sqlEngine;
@Autowired
private ChatModel chatModel;
@Tool(description = "涉及统计数据、求和、计数、平均值等聚合操作")
public String getAggregationQuery(@ToolParam(description = "用户的提问") String question) {
// 1. 用 SuperSQL 的 text-to-sql 功能生成 SQL
String actualSql = sqlEngine
.setChatModel(chatModel)
.setOptions(RagOptions.builder()
.topN(10)
.rerank(false)
.limitScore(0.1)
.build())
.generateSql(question);
// 2. 执行 SQL
Object object = sqlEngine.executeSql(actualSql);
// 3. 序列化为 JSON 返回
return JSON.toJSONString(object);
}
}关键点:
@Tool(description = ...)------ description 是 LLM 判断是否调用此工具的依据,必须清晰描述适用场景@ToolParam(description = ...)------ 参数的描述也很重要,LLM 会根据它从对话中提取参数值- 链式调用 SuperSQL ------
setChatModel设置生成 SQL 用的模型,setOptions配置检索参数(topN、rerank、阈值) - 返回 JSON 字符串 ------ LLM 接收的是字符串,所以执行结果要序列化
SuperSqlIntegrationService ------ 封装服务
java
@Slf4j
@Service
public class SuperSqlIntegrationService {
@Autowired
private SpringSqlEngine sqlEngine;
/**
* 使用 SuperSQL 生成 SQL
*/
public String generateSql(String question) {
try {
String sql = sqlEngine.generateSql(question);
log.info("生成 SQL: question={}, sql={}", question, sql);
return sql;
} catch (Exception e) {
log.error("生成 SQL 失败: question={}", question, e);
return null;
}
}
/**
* 训练 DDL,让 SuperSQL 了解表结构
*/
public void trainWithDDL(String ddl) {
try {
TrainBuilder trainBuilder = TrainBuilder.builder()
.content(ddl)
.policy(TrainPolicyType.DDL)
.build();
sqlEngine.train(trainBuilder);
log.info("训练 DDL 成功: {}", ddl);
} catch (Exception e) {
log.error("训练 DDL 失败", e);
}
}
/**
* 判断是否应该创建表
*/
public boolean shouldCreateTable(String question) {
try {
String sql = generateSql(question);
return sql != null && sql.toUpperCase().contains("CREATE TABLE");
} catch (Exception e) {
return false;
}
}
}trainWithDDL 用于动态扩展 schema 知识。比如上传 Excel 后,自动建表并把表结构训练进去。
注册 Tool 到 ChatClient
java
public AiRagController(ChatModel chatModel, ChatMemory chatMemory,
VectorStore vectorStore, RagTool ragTool) {
this.chatModel = chatModel;
this.chatClient = ChatClient.builder(chatModel)
.defaultSystem(DEFAULT_SYSTEM_PROMPT)
.defaultSystem(p -> p.param("rag_message", ""))
.defaultAdvisors(
PromptChatMemoryAdvisor.builder(chatMemory).build(),
SimpleLoggerAdvisor.builder().build(),
new MetadataAwareQuestionAnswerAdvisor()
)
.defaultTools(ragTool) // 注册 Tool
.build();
this.vectorStore = vectorStore;
}.defaultTools(ragTool) 把 RagTool 中所有标注 @Tool 的方法都注册为可用工具。
路由判断的两种思路
思路一(项目采用):让 LLM 通过 Tool 自动决定
java
// 不需要显式判断,LLM 会自己根据 description 调用工具
return chatClient.prompt()
.user(message)
.stream()
.content();思路二(注释中保留):显式让 LLM 判断
java
boolean isSql = chatClient.prompt()
.system("用户的查询是否涉及统计数据、求和、计数、平均值等聚合操作?")
.user(message)
.call()
.entity(Boolean.class);
if (isSql) {
return processAggregationQuery(message);
} else {
return processNormalRagQuery(sources, message);
}思路一的优势:少一次 LLM 调用,响应快;劣势:依赖 LLM 的 Function Calling 准确性。
思路二的优势:路由可控;劣势:每次都要先做一次判断,成本翻倍。
项目代码中保留了思路二的注释,作为备选方案。
验证结果
普通问答(走向量检索)
请求:
POST /api/v1/ai/rag?message=ChatClient是什么?响应: 走 RAG 路径,从向量库检索相关文档生成回答。
聚合查询(走 Text-to-SQL)
请求:
POST /api/v1/ai/rag?message=日志表里一共有多少条记录?预期流程:
- LLM 识别到"多少条"是聚合操作
- 调用
RagTool.getAggregationQuery("日志表里一共有多少条记录?") - SuperSQL 生成 SQL:
SELECT COUNT(*) FROM log_info - 执行得到
[{"count":156}] - LLM 整合:
日志表中一共有 156 条记录。
复杂查询测试
请求:
POST /api/v1/ai/rag?message=统计每个业务类型的热词数量生成的 SQL:
sql
SELECT business_type, COUNT(*) as cnt FROM word_frequency GROUP BY business_type最终回答:
按业务类型统计的热词数量如下:
- log: 234 个
- chat: 56 个调试日志
2026-05-14 INFO RagTool - 接收到聚合查询: 日志表里一共有多少条记录?
2026-05-14 INFO SpringSqlEngine - 生成的SQL: SELECT COUNT(*) FROM log_info
2026-05-14 INFO SpringSqlEngine - 执行结果: [{COUNT(*)=156}]优化方向
Tool 描述的精细化
@Tool 的描述会直接影响 LLM 是否调用。建议:
- 列举常见关键词:"多少"、"总数"、"统计"、"平均"、"最大"、"前N"
- 给出反例:"如果是问'是什么'、'怎么用',不要使用此工具"
java
@Tool(description = """
当用户询问需要数据库聚合查询的问题时使用,例如:
- "知识库里有多少个文档"
- "统计每个分类的数量"
- "查询最近一周的日志总数"
不适用:解释概念、查找具体内容、问答类问题。
""")
public String getAggregationQuery(...) { ... }SQL 安全护栏
LLM 生成的 SQL 可能包含 DROP、DELETE 等危险操作。需要白名单校验:
java
public String getAggregationQuery(String question) {
String sql = sqlEngine.generateSql(question);
// 只允许 SELECT
if (!sql.trim().toUpperCase().startsWith("SELECT")) {
return "{\"error\": \"暂不支持非查询操作\"}";
}
// 黑名单关键词
String upperSql = sql.toUpperCase();
String[] forbidden = {"DROP", "DELETE", "UPDATE", "INSERT", "TRUNCATE", "ALTER"};
for (String keyword : forbidden) {
if (upperSql.contains(keyword)) {
return "{\"error\": \"包含不允许的操作\"}";
}
}
return JSON.toJSONString(sqlEngine.executeSql(sql));
}数据库账号最小权限
即使 SQL 校验失效,数据库层面也要兜底:
sql
-- 创建只读账号
CREATE USER 'rag_readonly'@'%' IDENTIFIED BY 'xxx';
GRANT SELECT ON artisan_rag.* TO 'rag_readonly'@'%';应用使用这个账号连接,从根本上杜绝写操作。
结果限制
防止用户问"查询所有用户"导致返回百万行:
java
@Tool(description = "...")
public String query(String question) {
String sql = sqlEngine.generateSql(question);
// 强制加 LIMIT
if (!sql.toUpperCase().contains("LIMIT")) {
sql += " LIMIT 100";
}
return JSON.toJSONString(sqlEngine.executeSql(sql));
}训练数据管理
SuperSQL 的训练效果取决于喂给它的 DDL 和样例。可以:
- 项目启动时通过
trainWithDDL训练全部表结构 - 提供"训练样例"接口,运维人员可以补充常见问题对应的 SQL
- 定期用真实查询数据回灌训练集
java
TrainBuilder.builder()
.content("查询每个用户的最后登录时间")
.sql("SELECT user_name, MAX(create_time) FROM tb_user GROUP BY user_name")
.policy(TrainPolicyType.QA)
.build();与 RAG 的协作
聚合查询的结果可以再走一次 RAG。比如:
Java
用户问:"最近上传的 PDF 都讲了什么?"
1. 调用 SQL:SELECT file_name FROM ali_oss_file WHERE file_name LIKE '%.pdf' ORDER BY create_time DESC LIMIT 5
2. 拿到 5 个文件名
3. 用这些文件名作为 sources 走 RAG
4. AI 总结每个文件的主要内容形成"SQL 找范围 → 向量检索取语义"的两段式查询。
监控与可观测
- SQL 执行成功率
- 生成 SQL 的平均耗时
- 哪些问题路由到了 SQL 路径
- SQL 执行失败的 case 收集,用于训练改进
小结
本篇展示了 RAG 系统中"聚合查询"的优雅解法:
- 利用 Spring AI 的
@Tool机制,让 LLM 自动判断是否需要 SQL 查询 - 集成 SuperSQL 框架,把自然语言可靠地转成 SQL
- "向量检索 + Text-to-SQL"双路径,覆盖语义查找和数值聚合两类场景
- 安全要点:白名单校验、最小权限账号、结果限制
下一篇将聚焦"文档更新与全链路删除"------当知识库需要迭代时,如何避免数据碎片化。
