目录
文件名不会作为属性,保存在文件的inode中!---保存在哪里?
1.
不管什么文件,都要有同样类型的属性。但属性的内容可以不一样。
文件的属性大小是一样的
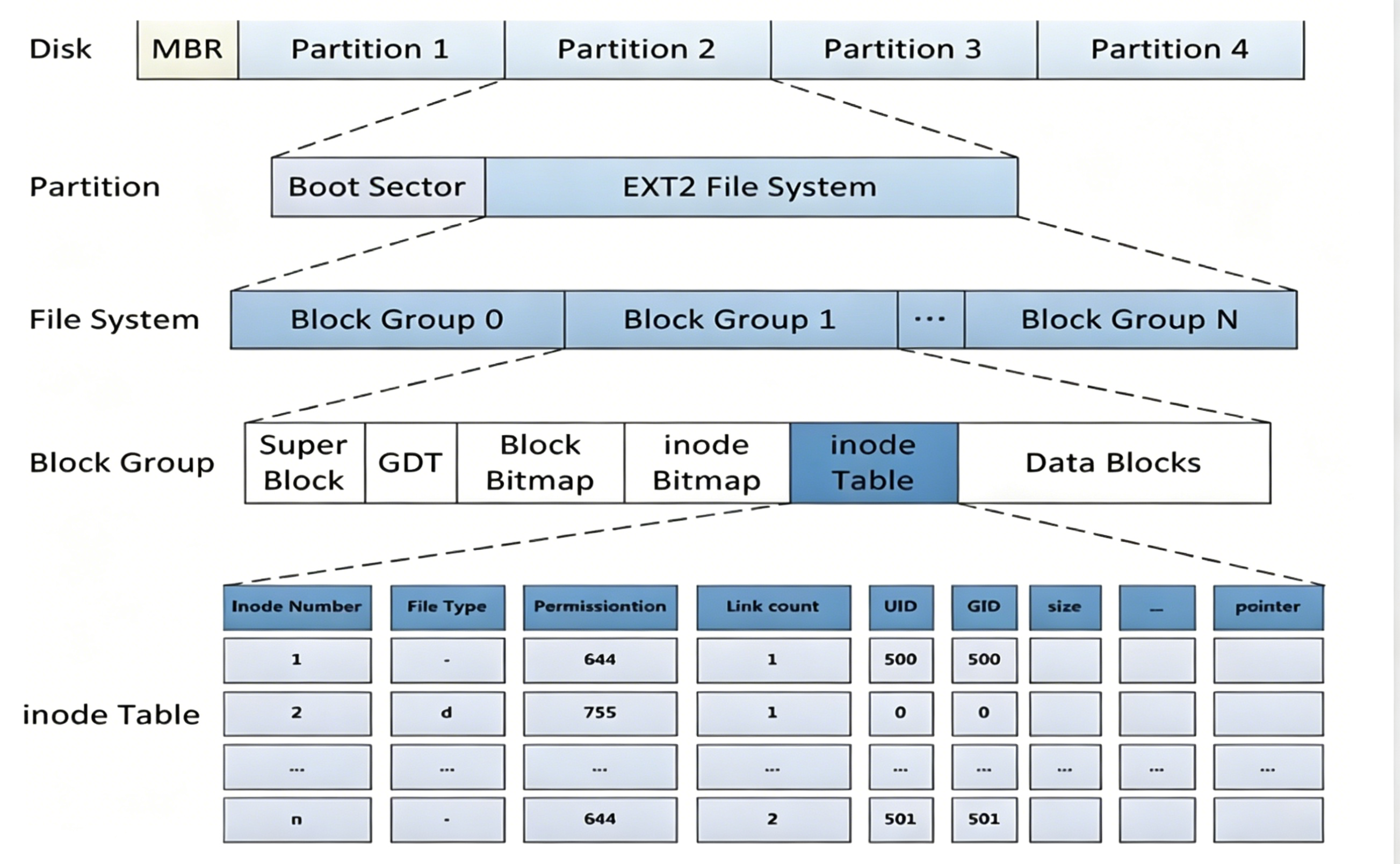
文件系统的整体是分区!
文件名不会作为属性,保存在文件的inode中!
一个数据块,会保存32个inode
filesystem和IO交互的时候,4KB
使用数据(属性)。ls -l 的时候看到的除了看到文件名,还能看到文件元
inode编号(在inode table中)
struct inode
{
type
size
pri
...
int inode_number
}
ls -li可以看到文件inode编号
[user1@iZ5waahoxw3q2bZ my_stdio]$ ls -li
total 36
1180362 -rwxrwxr-x 1 user1 user1 13352 May 16 13:36 code
1180194 -rw-rw-r-- 1 user1 user1 150 May 16 13:36 log.txt
1180197 -rw-rw-r-- 1 user1 user1 72 May 16 13:07 Makefile
1180355 -rw-rw-r-- 1 user1 user1 1604 May 16 13:17 mystdio.c
1180195 -rw-rw-r-- 1 user1 user1 404 May 16 13:15 mystdio.h
1180356 -rw-rw-r-- 1 user1 user1 473 May 16 13:36 usercode.c每⾏包含7列:
• 模式
• 硬链接数
• ⽂件所有者
• 组
• 大小
• 最后修改时间
• ⽂件名
》块位图(BlockBitmap)
与data blocks对应
• BlockBitmap中记录着DataBlock中哪个数据块已经被占⽤,哪个数据块没有被占⽤
哪一个数据块被占用了,就把对应的比特位置为1;
哪一个数据库没有被占用,就把对应的比特位清零,为0;
申请一个数据块来保存我们的数据,本质对数据块的比特位置1
释放一个数据块,对对应的数据块清零
》inode位图(InodeBitmap)
与inode table对应
• 每个bit表示⼀个inode是否空闲可用。
为什么拷贝的时候时间长,清除的时候时间短?
因为拷贝的时候是真的需要向data block里面写入数据
而删的时候只要对blockbitmap位图做清空就可以
》GDT(GroupDescriptorTable)
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储⼀个块组的描述信息,如在这个块组中从哪里开始是inodeTable,从哪⾥开始是Data
Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有⼀份拷贝。
》超级块(SuperBlock)
存放⽂件系统本⾝的结构信息,描述整个分区的⽂件系统信息。记录的信息主要有:bolck和inode的总量,未使⽤的block和inode的数量,⼀个block和inode的大小,最近⼀次挂载的时间,最近⼀次写⼊数据的时间,最近⼀次检验磁盘的时间等其他⽂件系统的相关信息。SuperBlock的信息被破坏,可以说整个文件系统结构就被破坏了
每个组里面有多少块,每个组里面有多少个inode,就决定了所有信息
格式化
两张bitmap清零
格式化的本质,就是写入文件系统的管理信息!
不是所有的分组都包含super block,但是有super block的组里面super block内容是完全一样的
super block一旦坏掉,整个文件系统会出问题,所以要在不同的组里面进行备份。
从而一个super block坏掉了,可以用其他的进行恢复覆盖
inode和数据块,跨组编号的。 举例,如果我们Block1中有一个编号inode100,其他组里面不能出现100
inode和数据块,不能跨分区!
所以,在同一分区内部,inode编号,和块号都是唯一的!
当操作系统开机管理磁盘时,操作系统需要把磁盘上面的管理信息加载到内存里
以上操作全部在内存中进行
我们往后拿着一个文件的inode,就可以找到文件的所有内容!
拿到inode后先去查找inode Bitmap如果为1证明是一个合法的,就在我们对应inode Table上把对应的inode属性填好了。
怎么通过inode进一步找到它的数据块呢?
struct inode
{
type
size
pri
...
int inode_number;
int datablocksN;其实一个文件的inode节点里面会包含一个固定大小的数组。该数组里保存的是该文件对应的数据块的编号
}
所以这样一个文件的属性和内容都有了
inode只在分区里面有效,
怎么知道在哪一个分组里?
怎么知道在分组位图的哪一个位置?
每一个组大小固定,/运算%运算
目录
Linux下如何看待目录?
目录也是按照刚才的方式保存的!
目录也有inode和数据内容!
文件名和inode的映射关系---也是数据!
文件名不会作为属性,保存在文件的inode中!---保存在哪里?
默认显示的是:路径+文件名---先打开我所在的路径,读取对应目录里面的数据内容,得到文件名和inode映射关系,根据文件名->inode->inode进行文件的查找!
保存在当前文件,所属的目录的数据内容当中!在磁盘的文件保存没有目录的概念,保存的无非是inode和数据
磁盘上的文件系统,只认inode
我们没用过inode找文件!我们用的都是文件名啊?
路径+文件名
我们访问,任何文件,都必须得有路径!
user1@iZ5waahoxw3q2bZ my_stdio$ ls /home/user1/linux-learning/linux/my_stdio ---路径,谁提供的?---进程提供文件路径!
code.c dir
所以,找到任何Linux文件,都必须从根目录开始,进行路径解析,直到找到对应的文件!
我的路径,谁提供的?---进程提供文件路径!
路径缓存
我们访问任何文件,都要从根目录进行路径解析吗?
不就是一直在做键盘IO吗?---这样做是不是效率太低了!
操作系统,在进行路径解析的时候,会把我们历史访问的所有的目录(路径)形成一颗多叉树,进行保存!--Linux系统的树状目录结构!
问题1:Linux磁盘中,存在真正的目录吗? 答案:不存在,只有文件。只保存文件属性+文件内容 问题2:访问任何文件,都要从/目录开始进行路径解析? 答案:原则上是,但是这样太慢,所以Linux会缓存历史路径结构
问题3:Linux目录的概念,怎么产生的? 答案:打开的文件是目录的话,由OS自己在内存中进行路径维护
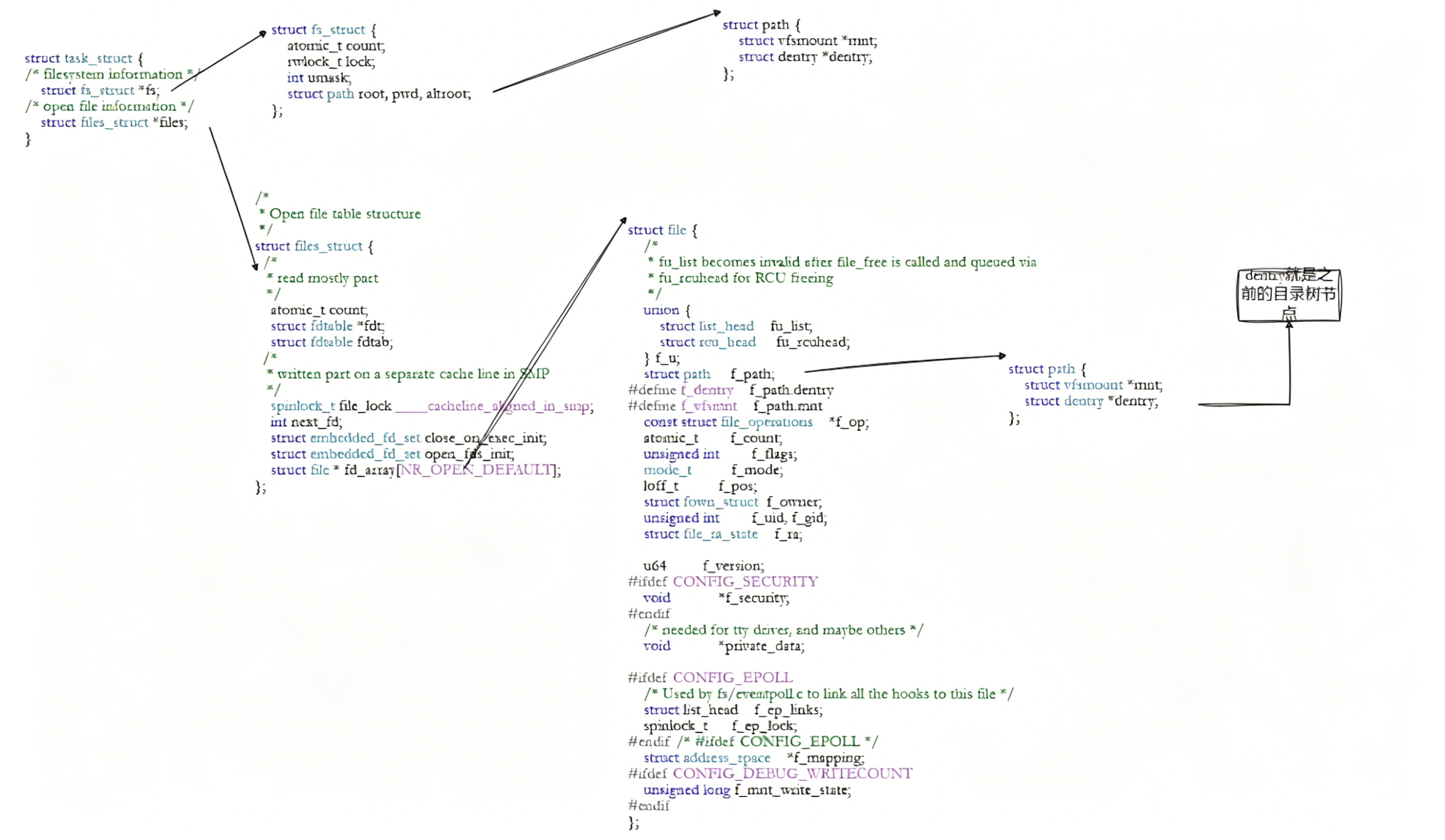
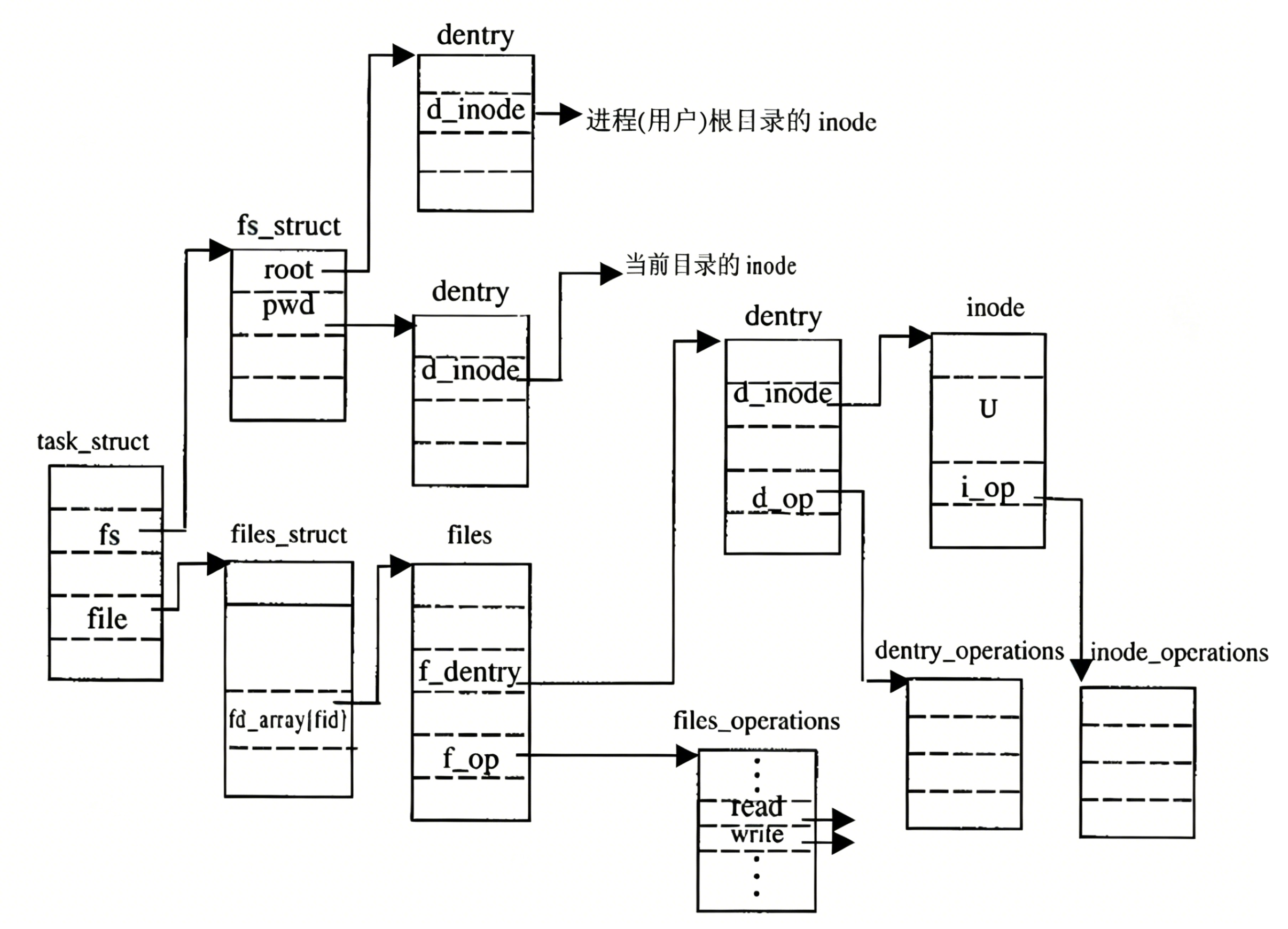
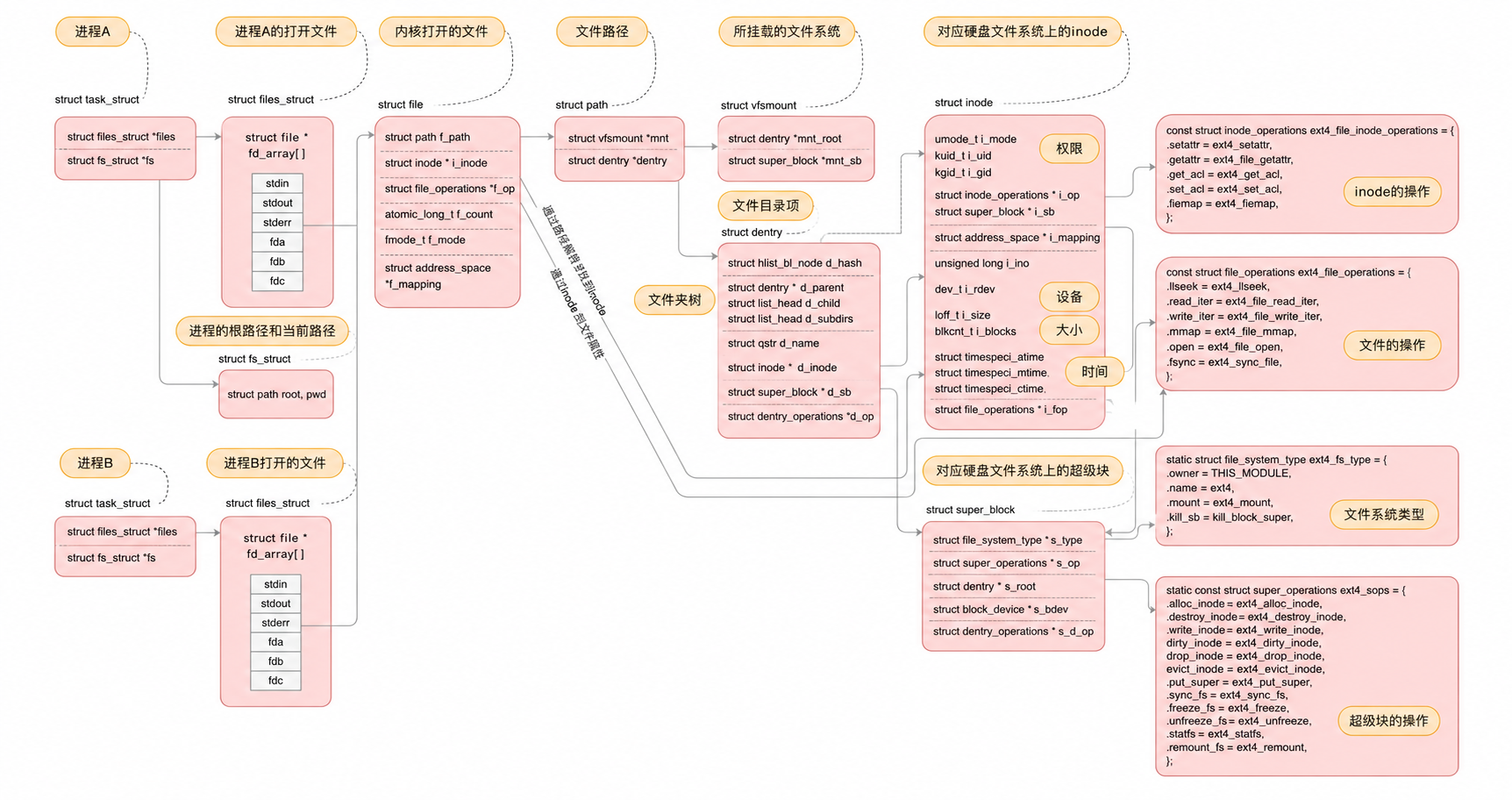
Linux中,在内核中维护树状路径结构的内核结构体 叫做:struct dentry
每个⽂件其实都要有对应的dentry结构,包括普通⽂件。这样所有被打开 的⽂件,就可以在内存中形成整个树形结构•整个树形节点也同时会⾪属于LRU(LeastRecentlyUsed,最近最少使⽤结构中,进⾏节点淘汰
•整个树形节点也同时会⾪属于Hash,方便快速查找
•更重要的是,这个树形结构,整体构成了Linux的路径缓存结构,打开访问任何⽂件,都在先在这棵树下根据路径进⾏查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry结构,缓存新路径
挂载分区
我们已经能够根据inode号在指定分区找⽂件了,也已经能根据⽬录⽂件内容,找指定的inode了,在指定的分区内,我们可以为所欲为了。可是:
问题:
inode不是不能跨分区吗?Linux不是可以有多个分区吗?我怎么知道我在哪⼀个分区???
磁盘->分区->格式化->我们依旧不能直接使用这个分区!
我们的磁盘
[user1@iZ5waahoxw3q2bZ my_stdio]$ ls /dev/vda* -l
brw-rw---- 1 root disk 253, 0 Apr 11 20:10 /dev/vda
brw-rw---- 1 root disk 253, 1 Apr 11 20:10 /dev/vda1/dev/vda 是整个磁盘,/dev/vda1 是其上的第一个分区
我们的分区,一定要和特定的一个目录进行关联->通过进入这个目录,就相当于进入这个分区->挂载!
通过该文件路径前缀,知道在哪一个分区下
实验
我们可以在以下链接知道指令(之前的docker中文章)
dd if=/dev/zero of=./disk.img bs=1M count=5 #制作一个大的磁盘块,就当做一个分区
mkfs.ext4 disk.img # 格式化写入文件系统
mkdir /mnt/mydisk # 建立空目录
df -h # 查看可以使用的分区
sudo mount -t ext4 ./disk.img /mnt/mydisk/ # 将分区挂载到指定的目录
df -h # 查看可以使用的分区
sudo umount /mnt/mydisk # 卸载分区
/dev/loop0 在Linux系统中代表第一个循环设备(loop device)。循环设备,也被称为 回环设备或者loopback设备,是一种伪设备(pseudo-device),它允许将文件作为块设备 (block device)来使用。这种机制使得可以将文件(比如ISO镜像文件)挂载(mount)为 文件系统,就像它们是物理硬盘分区或者外部存储设备一样
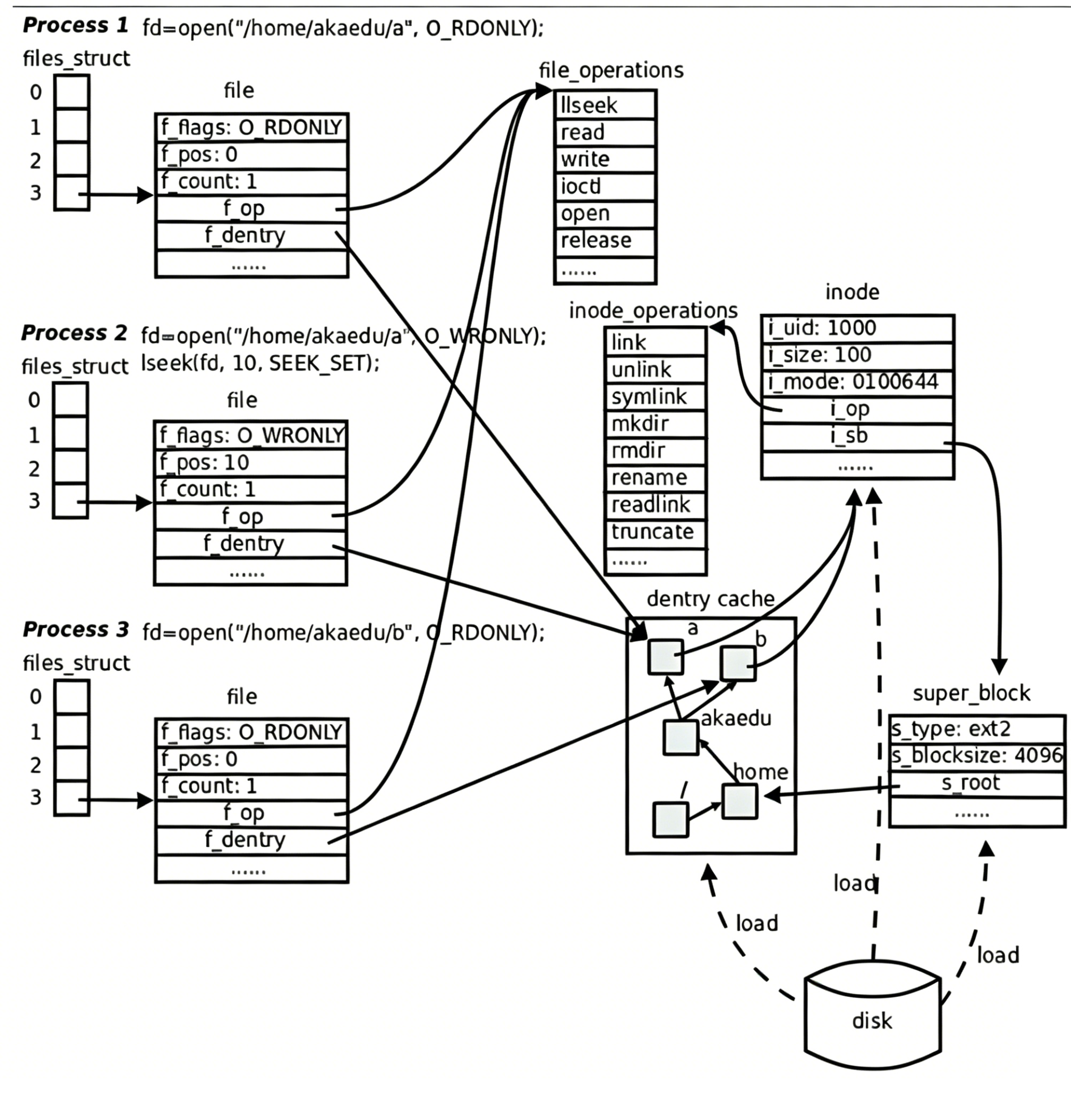
我们在fopen的时候,我们没有指定路径的话,操作系统会给我们添加它的cwd操作系统在内核中根据路径找到文件,如果需要就要查找struct dentry树进行路径搜索,把所有的文件所对应的路径的节点全部打开找到对应的文件名和inode映射关系。根据路径依次搜索,找到文件的inode。根据文件的inode找到文件对应的属性和内容,在内核中创建struct_file、struct_inode,创建文件的缓冲区,创建文件对应的之前将的两个表(文件描述符表和),然后把inode属性进行填充,磁盘属性加载到内存,文件内容+部分或全部加载到文件缓冲区里。然后把struct_file对应的地址在文件描述符中分配给用户返回文件描述符。
之后根据文件描述符可以找到内核中它的struct_file对象,该文件对应的inode和缓冲区
fopen("data.txt", "r") // 相对路径
│
▼
libc: 根据 cwd 补全为绝对路径(例如 /home/user/data.txt)
│
▼
系统调用 open()
│
▼
内核: path_lookup() 逐级查找 dentry(利用 dcache/磁盘)
│
▼
找到 dentry → inode(读入内存,填充 struct inode)
│
▼
分配 struct file,关联 inode 和 f_op
│
▼
在当前进程 fd 表中分配空闲 fd,fd_arrayfd = file
│
▼
返回 fd 给 libc
│
▼
libc: 分配 FILE*,内含 fd 和用户态缓冲区,返回 FILE*
挂载(Mount) 是指将某个存储设备(或分区、文件)附加到 Linux 目录树中某个目录(称为挂载点)的过程。只有挂载后,该设备上的文件系统才能被用户访问。
inode和datablock映射(弱化)
- inode内部存在__le32 i_blockEXT2_N_BLOCKS;/* Pointers to blocks*/ ,EXT2_N_BLOCKS =15,就是⽤来进行inode和block映射的
- 这样文件=内容+属性,就都能找到了。
文件内容是可以跨组保存的
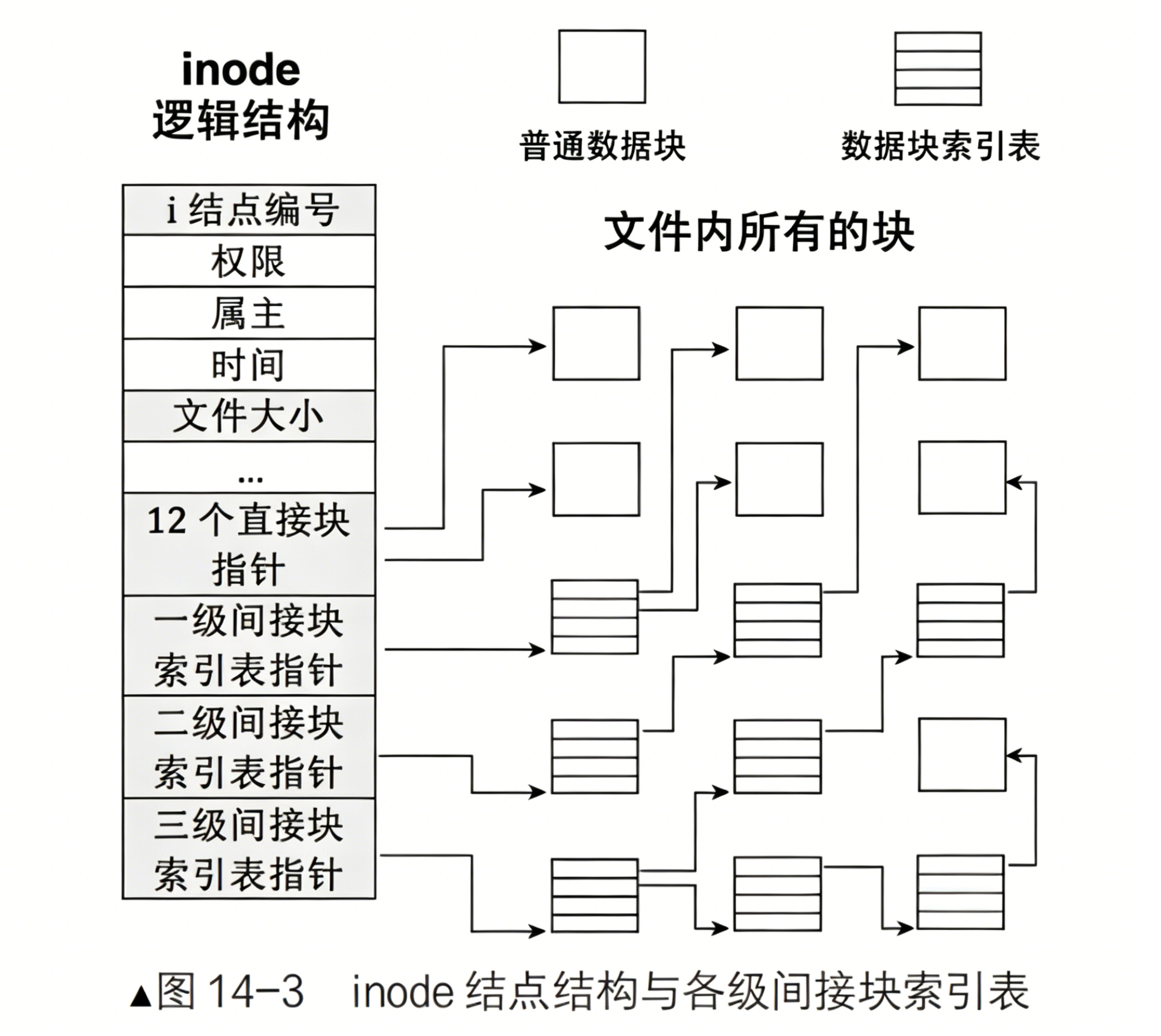
ext 系列 是 Linux 原生支持最广泛、使用时间最长的日志型文件系统 家族,包括 ext2 、ext3 、ext4 。它们的作用是管理磁盘或分区上的数据如何存储、索引、访问,提供文件的创建、读写、权限控制等基本功能。
如果对应的文件特别大,假设分组10GB data blocks里面都是4KB,如果文件是20GB呢?
data blocks不就存不下了吗?
之前讲过inode跟data blocks编号是全局的。所以对应的inode是确定在哪个分组里,但是它的数据块不一定只能在自己的分组里还可以跨组保存。也就是说文件的内容是可以跨组保存的。
只要分区能装的下,如果都超过分区的范围那就不适合单机保存了,就适合在分布式的多重机下拆分了分别保存。
2.软硬链接
软链接
[user1@iZ5waahoxw3q2bZ 26-5-17]$ ln -s code.c code-soft意味着我要用后者链接前者,名字随便取
[user1@iZ5waahoxw3q2bZ 26-5-17]$ touch code.c
[user1@iZ5waahoxw3q2bZ 26-5-17]$ ln -s code.c code-soft
[user1@iZ5waahoxw3q2bZ 26-5-17]$ ll
total 0
-rw-rw-r-- 1 user1 user1 0 May 16 18:19 code.c
lrwxrwxrwx 1 user1 user1 6 May 16 18:19 code-soft -> code.c
[user1@iZ5waahoxw3q2bZ 26-5-17]$ echo "hello code.c" >> code.c
[user1@iZ5waahoxw3q2bZ 26-5-17]$ ll
total 4
-rw-rw-r-- 1 user1 user1 13 May 16 18:19 code.c
lrwxrwxrwx 1 user1 user1 6 May 16 18:19 code-soft -> code.c
[user1@iZ5waahoxw3q2bZ 26-5-17]$ cat code-soft
hello code.c
[user1@iZ5waahoxw3q2bZ 26-5-17]$ ls -li
total 4
1180372 -rw-rw-r-- 1 user1 user1 13 May 16 18:19 code.c
1180373 lrwxrwxrwx 1 user1 user1 6 May 16 18:19 code-soft -> code.c可以看出软链接是一个独立的文件,因为他有独立的node number
文件内容+文件属性 软链接能干什么?
保存目标文件的路径
如果之后可执行程序不在当前目录下
可以由后者自定义的指向前者需要的
相当于windows下快捷方式
硬链接
[user1@iZ5waahoxw3q2bZ 26-5-17]$ ln code.c code-hard
[user1@iZ5waahoxw3q2bZ 26-5-17]$ ln code.c code-hard
[user1@iZ5waahoxw3q2bZ 26-5-17]$ ll
total 8
-rw-rw-r-- 2 user1 user1 13 May 16 18:19 code.c
-rw-rw-r-- 2 user1 user1 13 May 16 18:19 code-hard
lrwxrwxrwx 1 user1 user1 6 May 16 18:19 code-soft -> code.c
[user1@iZ5waahoxw3q2bZ 26-5-17]$ ls -li
total 8
1180372 -rw-rw-r-- 2 user1 user1 13 May 16 18:19 code.c
1180372 -rw-rw-r-- 2 user1 user1 13 May 16 18:19 code-hard
1180373 lrwxrwxrwx 1 user1 user1 6 May 16 18:19 code-soft -> code.c发现code.c跟code-hard前面编号一样
硬链接,本质不是一个独立的文件!因为它没有独立的inode!
是什么?
本质是一组新的文件名和目标inode number的映射关系
1变2,多一个新的文件名指向目标文件!2表示硬链接数
有什么用?
对文件进行备份
.和..就是硬链接
硬链接只能给普通文件进行建立,Linux系统,不支持给目录建立硬链接!
软链接都可以
.和..本质就是对目录的硬链接?---os自己建,用户不行
如果让用户自己建,容易形成路径环问题!---不允许用户自己给目录建立硬链接了
.和..:名字特殊,做特殊处理---方便命令行操作
引用计数
1.inode对所有数据的操作都必须要在内存当中
2.虽然在磁盘中保存,但是如果要修改,那么就要从磁盘搬到内存里
inode在内存/内核中就是一个结构体变量,结构体变量包含一个整数int,对引用计数做++ --就是更改引用计数,在内存中改完写回磁盘,进而进行引用计数的更改
计数类型 变量名 作用域 存储位置 主要用途
内存引用计数 i_count 内存 内存inode结构体 管理inode在内存中的生命周期
硬链接计数 i_nlink 持久化 磁盘inode 管理文件的硬链接数量
感谢你的观看,期待我们下次再见!