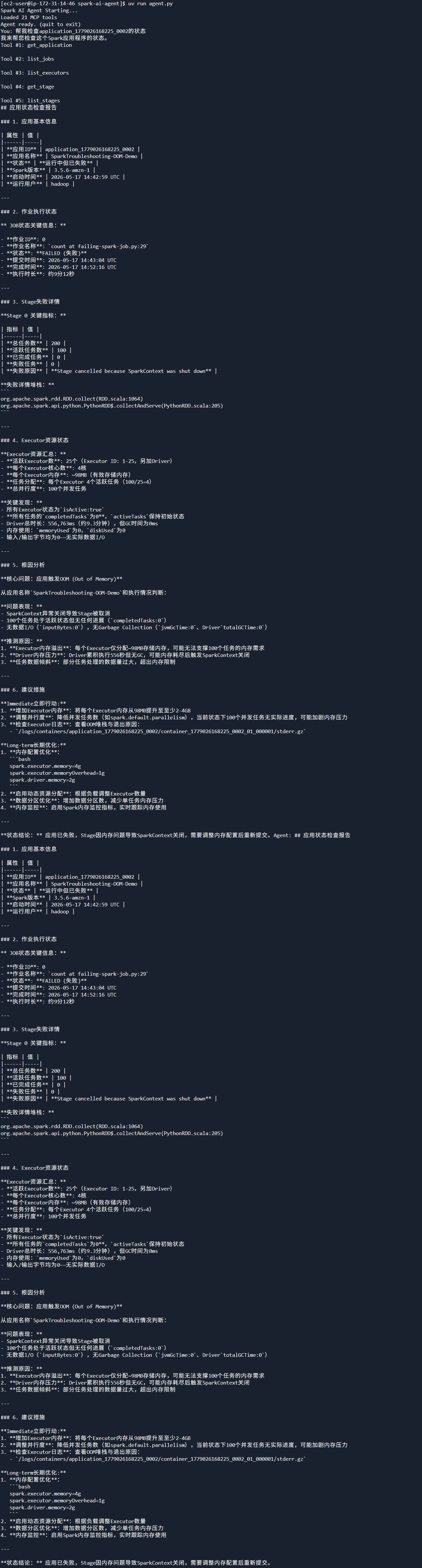
本文基于 AWS Strands SDK + MCP Server + EMR 构建 AI 驱动的 Spark 故障排查系统,总体架构如下
LLM_Layer
EMR_Cluster
Agent_Layer
Client
自然语言
MCP 工具调用
Spark REST API
读取事件日志
推理请求
分析结果
诊断报告
用户
Strands Agent
MCP Server:18888
Spark History Server:18080
S3 Event Logs
LLM API
环境搭建
创建EMR集群
配置如下
bash
aws emr create-cluster \
--name "spark-ai-agent" \
--log-uri "s3://aws-logs-ACCOUNT-REGION/elasticmapreduce" \
--release-label "emr-7.12.0" \
--applications Name=Spark \
--service-role "EMR_DefaultRole_V2" \
--ec2-attributes KeyName=cluster-key,SubnetId=subnet-xxx,InstanceProfile=EMR_EC2_DefaultRole \
--instance-groups '[{"Name":"MASTER","InstanceGroupType":"MASTER","InstanceType":"m5.xlarge","InstanceCount":1},{"Name":"CORE","InstanceGroupType":"CORE","InstanceType":"m5.xlarge","InstanceCount":2}]' \
--region cn-north-1EMR集群创建后会自动管理 Spark 事件日志,无需手动配置 spark.eventLog.dir 和spark.history.fs.logDirectory。
- Spark 事件日志自动存储在 EMR 管理的 S3 路径
- Spark History Server 自动配置为读取正确的事件日志路径
- EMR AppPusher 服务自动上传事件日志到 S3
EMR 默认日志 vs Spark 事件日志
| 类型 | 路径 | 内容 | 用途 |
|---|---|---|---|
| EMR 日志 | s3://aws-logs-ACCOUNT-REGION/elasticmapreduce/j-CLUSTER-ID/ |
driver/executor 标准输出 | 排查启动错误 |
| Spark 事件日志 | EMR 自动管理 | 结构化事件流 | SHS 分析 |
事件日志是 Spark 执行引擎产生的结构化数据,包含:
- Job 提交/完成时间
- Stage 划分和依赖关系
- Task 执行详情(耗时、内存、shuffle)
- Executor 状态变化
- SQL 执行计划
配置MCP服务
bash
uv init spark-ai-agent --python 3.12
cd spark-ai-agent
uv venv --python 3.12安装依赖
bash
UV_INDEX_URL=https://mirrors.aliyun.com/pypi/simple/ uv add \
strands-agents \
strands-agents-tools \
boto3 \
httpx \
openai \
"mcp[cli]"配置 MCP Server,从 GitHub 下载 mcp-apache-spark-history-server 到本地。
创建 config.yaml:
yaml
servers:
emr:
default: true
emr_cluster_arn: "arn:aws-cn:elasticmapreduce:cn-north-1:XXXXXXXX:cluster/j-1BGE97HH6HJZJ"
mcp:
transports:
- streamable-http
port: "18888"
debug: true
address: 0.0.0.0启动 MCP Server
bash
cd /home/ec2-user/workspace/mcp-apache-spark-history-server-main
PYTHONPATH=/home/ec2-user/workspace/mcp-apache-spark-history-server-main/src
/home/ec2-user/workspace/spark-ai-agent/.venv/bin/python -m spark_history_mcp.core.main -c config.yaml日志输出
2026-05-17 08:36:51 - INFO - Using config file: /home/ec2-user/workspace/spark-ai-agent/config.yaml
2026-05-17 08:36:51 - INFO - Found credentials from IAM Role: <admin-role>
2026-05-17 08:36:52 - INFO - AWS troubleshooting tools registered (region=cn-north-1)
INFO: Started server process [611165]
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:18888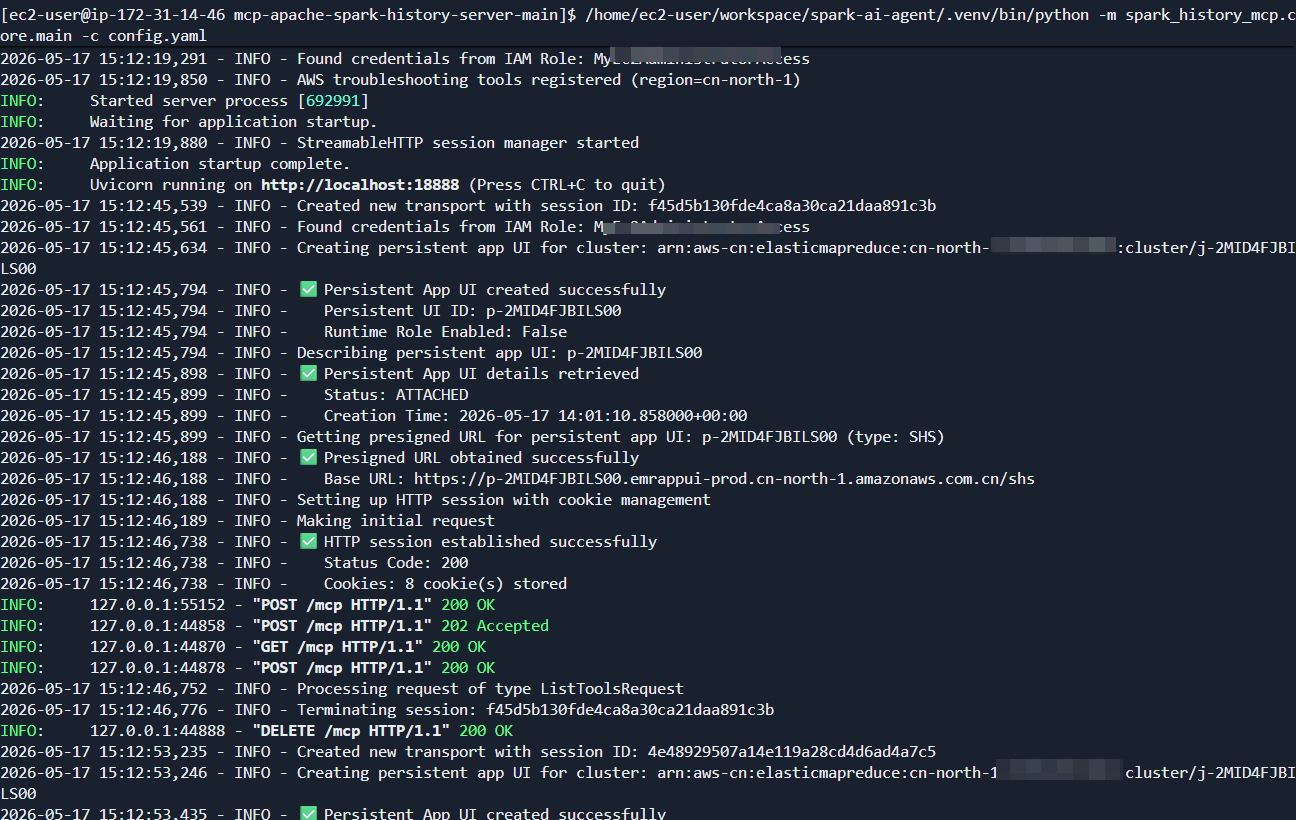
Agent 代码
示例代码
python
#!/usr/bin/env python3
import sys
import os
sys.path.insert(0, "/home/ec2-user/workspace/mcp-apache-spark-history-server-main/src")
MCP_SERVER_URL = "http://127.0.0.1:18888/mcp"
OPENAI_API_KEY = "API-KEY"
OPENAI_BASE_URL = "https://bedrock-mantle.us-east-1.api.aws/v1"
MODEL_ID = "zai.glm-5"
SYSTEM_PROMPT = """You are a professional Spark performance analysis expert with MCP tools for Spark History Server data.
INSTRUCTIONS:
- Provide direct, professional analysis without <think> tags
- Use markdown headers (### 1., ### 2.) with proper spacing
- Format as key-value pairs where appropriate
- Use bullet points only for actual lists
- Be comprehensive but well-structured
- Focus on actionable insights
Analysis approach:
1. Use MCP tools to fetch comprehensive application data
2. Identify performance metrics, bottlenecks, and resource utilization
3. Provide specific, actionable recommendations
4. Format with clear sections using markdown headers
5. Include specific metrics and measurements
Respond professionally with detailed technical analysis. /no_think"""
def main():
from mcp.client.streamable_http import streamablehttp_client
from strands import Agent
from strands.models.openai import OpenAIModel
from strands.tools.mcp.mcp_client import MCPClient
print("Spark AI Agent Starting...")
mcp_client = MCPClient(lambda: streamablehttp_client(MCP_SERVER_URL))
with mcp_client:
tools = mcp_client.list_tools_sync()
print(f"Loaded {len(tools)} MCP tools")
# Let SDK create the async client automatically
model = OpenAIModel(
client_args={
"api_key": OPENAI_API_KEY,
"base_url": OPENAI_BASE_URL,
},
model_id=MODEL_ID,
)
agent = Agent(model=model, tools=tools, system_prompt=SYSTEM_PROMPT)
print("Agent ready. (quit to exit)")
while True:
try:
query = input("You: ").strip()
if query.lower() in ("quit", "exit", "q"):
break
if not query:
continue
with mcp_client:
print(f"Agent: {agent(query)}\n")
except (KeyboardInterrupt, EOFError):
break
print("Goodbye!")
if __name__ == "__main__":
main()MCP Server 工作原理
MCP (Model Context Protocol) Server 是连接 AI Agent 和 Spark History Server 的桥梁。
数据流详解如下
S3 Event Logs Spark History Server EMRPersistentUIClient MCP Server Strands Agent S3 Event Logs Spark History Server EMRPersistentUIClient MCP Server Strands Agent 1. 启动阶段 2. 查询阶段 3. 分析阶段 初始化 create_persistent_app_ui() 返回 Presigned URL + Session list_applications() GET /api/v1/applications 扫描 eventLog.dir 事件日志列表 应用元数据 JSON 结构化数据 get_stage(app_id, stage_id) GET /api/v1/applications/{id}/stages/{stage} 阶段详情 + Task 指标 瓶颈数据
EMRPersistentUIClient
访问EMR 集群托管的 Spark History Server,需要通过 AWS API 获取临时访问凭证:
python
# 位置: api/emr_persistent_ui_client.py
class EMRPersistentUIClient:
def initialize(self):
# 1. 创建 Persistent App UI(AWS 托管的 SHS 代理)
response = self.emr_client.create_persistent_app_ui(
TargetResourceArn=self.emr_cluster_arn
)
# 2. 获取 Presigned URL(临时访问凭证)
presigned_url = self.get_presigned_url()
# 3. 建立 HTTP Session(带 AWS 认证 Cookie)
session = requests.Session()
session.get(presigned_url) # 获取认证 Cookie
return base_url, session直接 curl EMR Persistent UI URL 会失败,因为缺少认证 Cookie。正确的使用EMR Persistent UI URL访问SHS的流程如下
- 调用
create_persistent_app_ui()获取 UI ID - 调用
get_presigned_url()获取带签名临时 URL - 通过
session.get(presigned_url)获取认证 Cookie - 携带 Cookie 请求
api_endpoint访问成功
SHS API Client SHS API Client User 请求访问 create_persistent_app_ui() UI ID get_presigned_url() 预签名URL 请求预签名URL 认证 Cookie 带Cookie访问API ✅ 成功 User
具体的命令如下
bash
# 步骤 1: 获取 Presigned URL
PRESIGNED_URL=$(aws emr get-persistent-app-ui-presigned-url \
--persistent-app-ui-id p-CLUSTER-ID \
--persistent-app-ui-type SHS \
--region cn-north-1 \
--query 'PresignedURL' --output text)
# 步骤 2: 访问 Presigned URL 并保存 Cookie
curl -c cookies.txt "$PRESIGNED_URL"
# 步骤 3: 使用 Cookie 访问 API
curl -b cookies.txt \
"https://p-CLUSTER-ID.emrappui-prod.cn-north-1.amazonaws.com.cn/shs/api/v1/applications"SparkRestClient
MCP中使用 Spark History Server REST API客户端
python
# 位置: api/spark_client.py
class SparkRestClient:
def list_applications(self, status=None, limit=None):
"""GET /api/v1/applications"""
return self._make_request(f"{self.base_url}/applications")
def get_stage(self, app_id, stage_id):
"""GET /api/v1/applications/{app_id}/stages/{stage_id}"""
return self._make_request(f"{self.base_url}/applications/{app_id}/stages/{stage_id}")
def get_job_bottlenecks(self, app_id, job_id):
"""聚合多接口数据,识别瓶颈"""
stages = self.list_stages(app_id)
tasks = self.get_stage_task_summary(app_id, stage_id)
executors = self.list_executors(app_id)
# 分析逻辑...MCP Tools
将 SparkRestClient 方法封装为 MCP 协议工具:
python
# 位置: tools/tools.py
@mcp.tool()
def list_applications(server=None, status=None, limit=None):
"""列出所有 Spark 应用"""
ctx = mcp.get_context()
client = get_client_or_default(ctx, server)
return client.list_applications(status=status, limit=limit)
@mcp.tool()
def get_job_bottlenecks(app_id, job_id, server=None):
"""识别作业性能瓶颈"""
stages = list_stages(app_id, server)
slowest_stages = list_slowest_stages(app_id, limit=5, server=server)
# 分析并返回瓶颈报告MCP Server 提供 21 个工具,按功能分类如下:
应用信息
| 工具 | Spark REST API | 数据源 |
|---|---|---|
list_applications |
GET /api/v1/applications |
扫描 S3 eventLog.dir |
get_application |
GET /api/v1/applications/{id} |
事件日志元数据 |
作业分析
| 工具 | Spark REST API | 数据源 |
|---|---|---|
list_jobs |
GET /api/v1/applications/{id}/jobs |
Job 事件 |
list_slowest_jobs |
聚合 jobs + 排序 | 计算得出 |
get_job_bottlenecks |
多 API 聚合 | Stage + Task + Executor |
compare_job_performance |
聚合多应用数据 | 对比计算 |
阶段分析
| 工具 | Spark REST API | 数据源 |
|---|---|---|
list_stages |
GET /api/v1/applications/{id}/stages |
Stage 事件 |
list_slowest_stages |
聚合 stages + 排序 | 计算得出 |
get_stage |
GET /api/v1/applications/{id}/stages/{stage} |
Stage 详情 |
get_stage_task_summary |
GET /.../stages/{id}/taskSummary |
Task 指标分布 |
执行器分析
| 工具 | Spark REST API | 数据源 |
|---|---|---|
list_executors |
GET /api/v1/applications/{id}/executors |
Executor 注册事件 |
get_executor |
GET /.../executors/{id} |
Executor 详情 |
get_executor_summary |
聚合所有 executor | 汇总计算 |
get_resource_usage_timeline |
聚合 executor 时间线 | 时间序列数据 |
SQL 分析
| 工具 | Spark REST API | 数据源 |
|---|---|---|
list_slowest_sql_queries |
GET /.../sql?details=true |
SQL 执行事件 |
get_sql_execution |
GET /.../sql/{id} |
SQL 执行详情 |
compare_sql_execution_plans |
多 SQL API 聚合 | 执行计划对比 |
配置与环境
| 工具 | Spark REST API | 数据源 |
|---|---|---|
get_environment |
GET /api/v1/applications/{id}/environment |
Spark 配置 |
compare_job_environments |
聚合多应用配置 | 配置对比 |
AWS 故障排查(可选)
| 工具 | 功能 |
|---|---|
aws_analyze_spark_workload |
一键根因分析失败/慢速作业 |
aws_spark_code_recommendation |
针对识别问题的代码修复建议 |
提交测试作业
为了演示 Agent 的故障排查能力,我们需要向 EMR 集群提交两个测试作业一个成功的 Spark Pi 和一个故意失败的 OOM 作业。创建一个故意触发内存溢出的 Spark 脚本:
python
# failing-spark-job.py
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("SparkTroubleshooting-OOM-Fast") \
.config("spark.executor.memory", "256m") \
.config("spark.driver.memory", "256m") \
.config("spark.task.maxFailures", "2") \
.getOrCreate()
sc = spark.sparkContext
data = range(1, 5000000)
rdd = sc.parallelize(data, numSlices=50)
rdd = rdd.map(lambda x: list(range(x)))
result = rdd.collect()
print(f"Result size: {len(result)}")
spark.stop()上传到 S3 并提交:
bash
# 上传脚本
aws s3 cp failing-spark-job.py \
s3://aws-logs-ACCOUNT-REGION/elasticmapreduce/spark-scripts/failing-spark-job.py
# 提交作业
aws emr add-steps \
--cluster-id j-2MID4FJBILS00 \
--steps '[{
"Name": "spark-oom-fast",
"ActionOnFailure": "CONTINUE",
"Jar": "command-runner.jar",
"Args": [
"spark-submit",
"--deploy-mode", "cluster",
"--executor-memory", "256m",
"--driver-memory", "256m",
"s3://aws-logs-ACCOUNT-REGION/elasticmapreduce/spark-scripts/failing-spark-job.py"
]
}]'步骤状态
bash
aws emr describe-step --cluster-id j-2MID4FJBILS00 \
--step-id s-07643683FSY4XLDWR7AU \
--query 'Step.Status' --output json
{
"State": "FAILED",
"StateChangeReason": {},
"FailureDetails": {
"Reason": "Unknown Error.",
"LogFile": "s3://aws-logs-XXXXXXXX-cn-north-1/elasticmapreduce/j-2MID4FJBILS00/steps/s-07643683FSY4XLDWR7AU/"
},
"Timeline": {
"CreationDateTime": "2026-05-17T14:53:03.911000+00:00",
"StartDateTime": "2026-05-17T14:53:15.727000+00:00",
"EndDateTime": "2026-05-17T14:53:35.816000+00:00"
}
}两个作业都已在 SHS 中注册,Agent 可以通过 MCP 工具查询分析。
Spark History Server EMR 集群 S3 User Spark History Server EMR 集群 S3 User 作业 1: Spark Pi 作业 2: OOM 模拟 Agent 可查询两个应用 add-steps (SparkPi) 执行成功 注册 application_0001 (completed) 上传 failing-spark-job.py add-steps (OOM script) 执行失败 (OOM) 注册 application_0002 (failed) Agent 通过 MCP 查询诊断
Agent 诊断
完整的工作流如下
Output
EMR
MCP
Agent
Input
决策
决策
决策
决策
决策
REST API
解析
综合分析
用户问题: 为什么作业失败?
Strands Agent
list_applications
get_application
list_stages
get_stage_task_summary
get_job_bottlenecks
SparkRestClient
Spark History Server
S3 Event Logs
诊断报告: Stage 3 因内存不足失败
用户提问
现在有几个Spark应用?分别是什么状态?请详细分析失败的那个应用。Agent 工具调用链
Tool #1: list_applications → 发现 2 个应用
Tool #2: get_application → 获取失败应用详情
Tool #3: list_jobs → 查看失败应用的 Job 列表
Tool #4: list_executors → 检查 Executor 状态
Tool #5: get_environment → 获取内存配置信息
Tool #6: list_stages → 查看失败 Stage
Tool #7: get_job_bottlenecks → 综合瓶颈分析Agent 诊断输出
### 1. Spark应用概况
当前共有 2个Spark应用:
应用1: application_1779026168225_0001
- 名称: Spark Pi
- 状态: ✅ 已完成
- 执行时间: 11.13秒
- Spark版本: 3.5.6-amzn-1
应用2: application_1779026168225_0002
- 名称: SparkTroubleshooting-OOM-Demo
- 状态: ❌ 已失败
- 失败时间: 2026-05-17T14:52:16
- Spark版本: 3.5.6-amzn-1
### 2. 失败应用详细分析
#### 2.1 应用基本信息
应用ID: application_1779026168225_0002
应用名: SparkTroubleshooting-OOM-Demo
启动时间: 2026-05-17 14:42:59
失败时间: 2026-05-17 14:52:16
运行时长: 约9分17秒
用户: hadoop
集群: EMR-7.12.0 (j-2MID4FJBILS00)
#### 2.2 失败根因分析
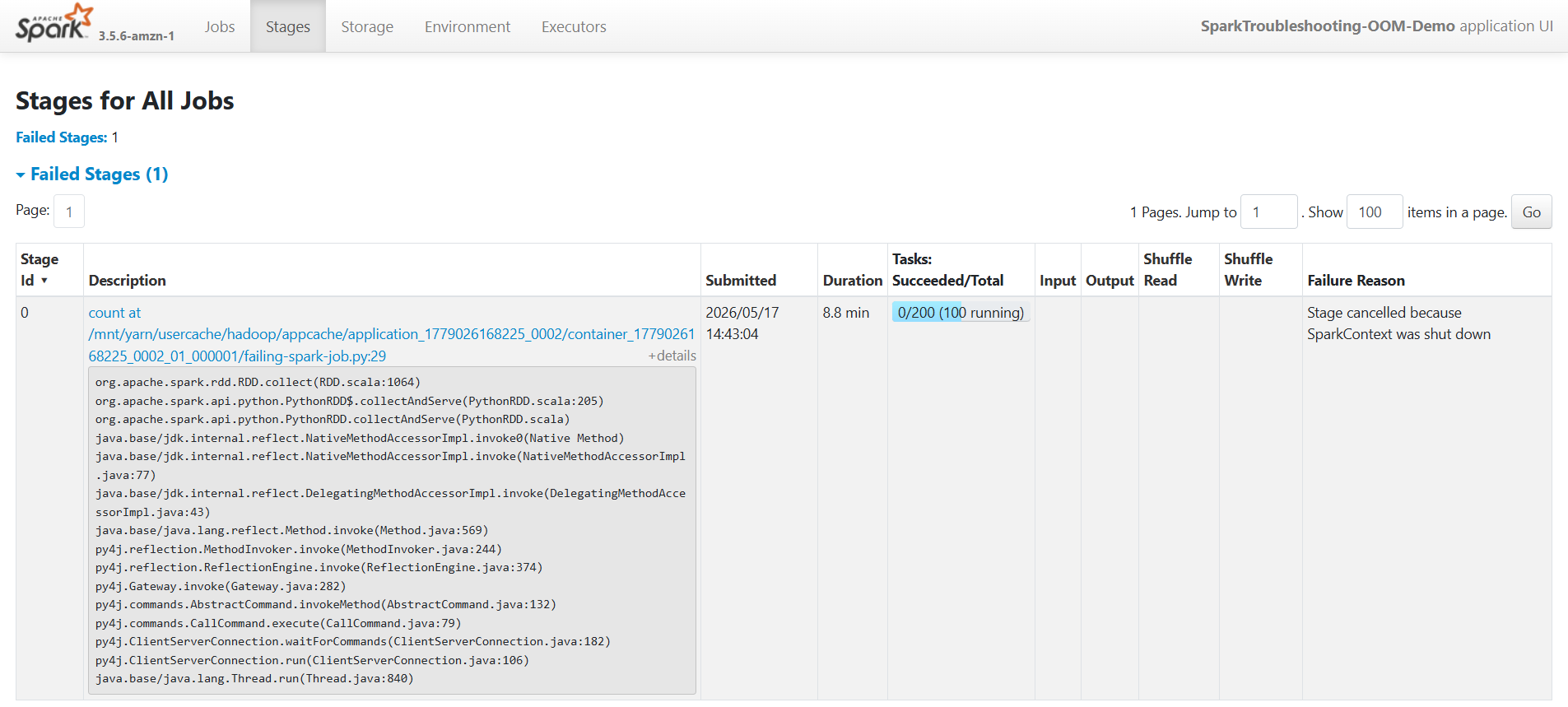
核心问题:应用因SparkContext被关闭而失败
- 失败Job: Job 0 (共1个Job)
- 失败Stage: Stage 0 (共1个Stage)
- 失败原因: Stage cancelled because SparkContext was shut down
关键证据:
- 任务配置总任务数: 200个
- 完成任务数: 0个
- 没有实际数据处理(输入/输出均为0字节)
#### 2.3 资源配置分析
内存配置严重偏低:
- Driver内存: 512MB (spark.driver.memory)
- Executor内存: 512MB (spark.executor.memory)
- 每个Executor核心数: 4
- 动态分配: 启用
执行器统计:
- Driver: 1个
- Executor: 25个活跃执行器
- 总核心数: 100个(25执行器 × 4核心)
- 每个Executor存储内存仅约 ~98MB(maxMemory)
### 3. 问题诊断
根本问题:内存配置不足导致的OOM(内存溢出)失败
失败机制:
1. 应用提交并启动作业
2. Executor尝试执行任务时,因内存不足触发OOM
3. JVM参数 -XX:OnOutOfMemoryError='kill -9 %p' 导致进程被强制终止
4. SparkContext关闭(Driver侧或executor不可用)
5. Stage被取消
### 4. 解决建议
立即修复措施:
spark.driver.memory 2g
spark.executor.memory 4g
spark.executor.cores 2
spark.executor.memoryOverhead 1g
长期优化:
1. 容量规划: 根据实际数据量合理配置资源
2. 配置优化: 调整并行度、批处理大小、shuffle分区等
3. 代码审查: 检查是否存在数据倾斜、过度对象创建等问题
4. 监控体系: 建立完整的性能监控和告警机制对于如下任务
检查具体任务状态