文章目录
[奖励模型Reward model](#奖励模型Reward model)
概要
对于大模型,除了监督微调,还需要将其与人类反馈对齐,使得大模型不仅能够回答问题,还能引导模型的回答更符合人们认知、更具价值,这类方法就是强化学习(简称RL),本系列文章以近端策略优化算法(Proximal Policy Optimization 简称PPO)作为深度强化学习的入门,让我们开始把!
强化学习概念
强化学习的目标是让智能体按策略与环境经过多次交互后获取到的反馈Return尽可能得大。
举例来说,通过大厨的反馈,训练一个学徒在当前状态State 采取放调料还是放菜还是出锅的决策能力,其中智能体agent (即学徒)能够根据当前状态做出动作action ,即策略policy ,环境environment (即大厨)对学徒采取的每个动作给予奖励 或惩罚Reward。
轨迹Trajectory 为学徒从开始做菜到做菜完成中经历的全部状态、动作
,数学表达为
,其中,当前的状态
由上次的状态
、动作
决定。
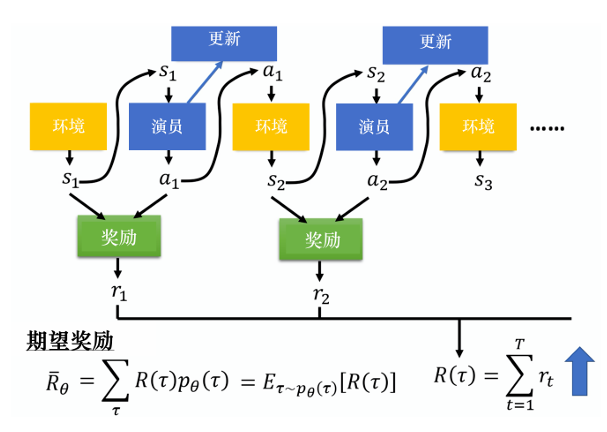
图片参考大规模语言模型 :从理论到实践
理解了以上概念后,我们发现,大语言模型即是智能体,当前的prompt就是某个状态,大模型对于当前prompt推理出的logits(在词表上的概率分布)为策略。
强化学习的目标就是使得智能体基于轨迹的期望反馈最大:
其中
策略梯度
由于目标是期望反馈最大,需要计算期望反馈的梯度,来做梯度上升保证期望反馈最大:
由于
因此,
根据上节的第三个公式,可以得出
因此,期望反馈的梯度为,我们可以通过对大模型进行采样多个轨迹来估计期望反馈的梯度,即
(1)
式中是按照回答token的策略概率来计算的,以"北京在哪里?北京在中国"举例来讲:
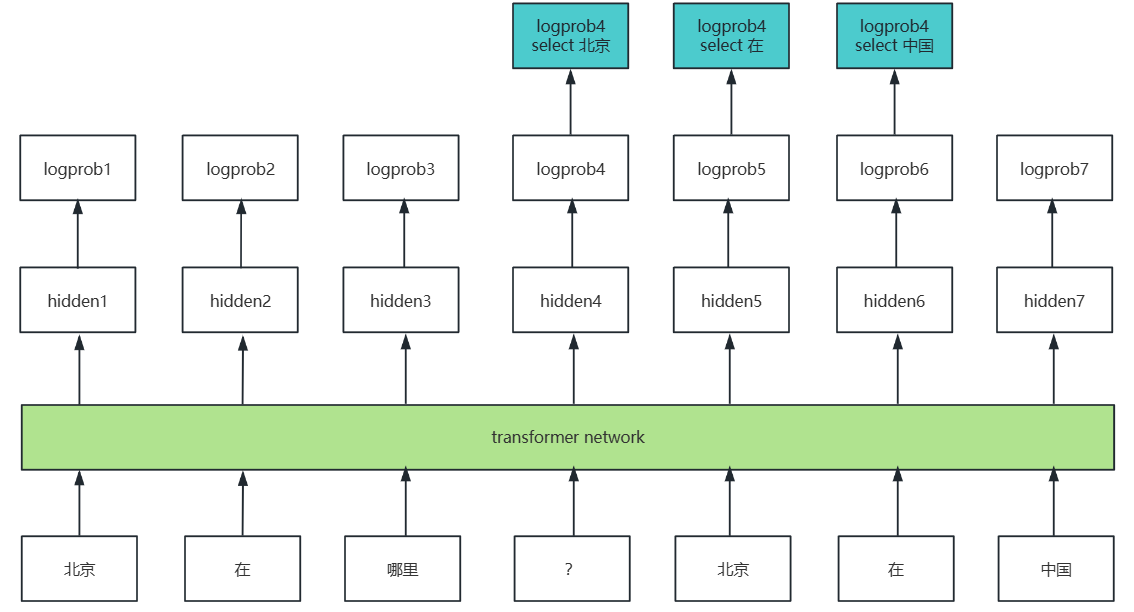
将"北京在哪里?北京在中国"这个prompt+answer这个轨迹中采用answer的各token(即动作action)的概率的对数,其中涉及三个(状态,动作)对:
状态state 动作action
北京在哪里? -> 北京
北京在哪里?北京 -> 在
北京在哪里?北京在 -> 中国
概率的对数指的是:把llm当作能够基于状态做出行动action的策略模型,其network的linear层会输出hidden,经过softmax会得出在整个词表上的各个概率prob,最后选取轨迹中采用的action的prob即为,后续pytorch的反向梯度计算可以得到
奖励模型Reward model
策略梯度中的为轨迹
的奖励,强化学习中需要奖励模型来评价 相对于问题来说**回答的好坏,**直觉上来讲,应该采用问答对、人工给出的reward打分的数据集的方式来训练reward model,然而相对于问题,我们往往无法直接给出回答的理想打分,但是我们可以明确地知道哪个是较好的回答,哪个是较差的回答,即用于训练reward model的数据集如下:
|----------|---------|---------|-------|
| question | answer1 | answer2 | 更好的回答 |
| 北京在哪里? | 北京在中国 | 不知道 | 1 |
| 1+1等于几? | 这是一个数学题 | 等于2 | 2 |
| ... | ... | ... | |
定义一个能够输出轨迹的数值打分的reward model,其结构如下:
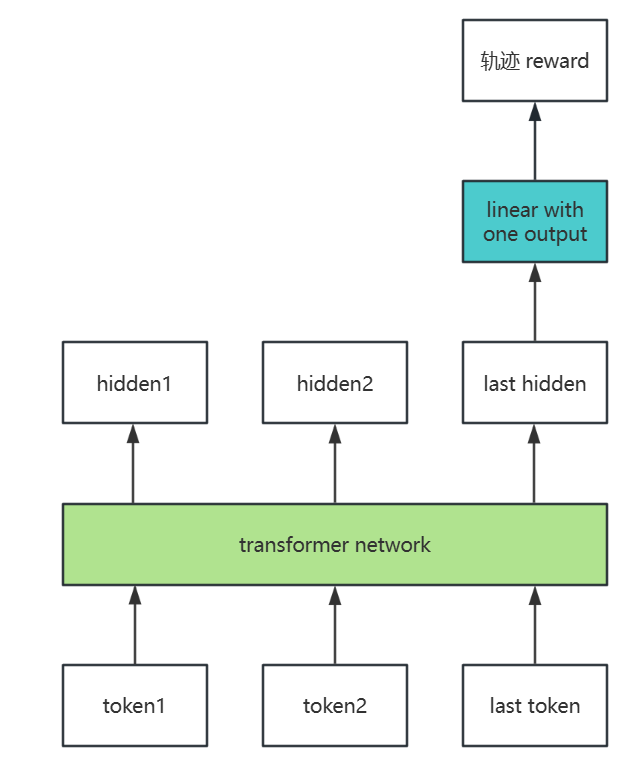
与常规训练不同的是,reward model的损失函数是对相同问题的俩个回答之间的比较定义的:
可以观察到,当reward model网络对于较好的答案的打分低于较差答案的打分时候,,此时,较好
,则
,并且
相比于
的打分越低时,
也就是
越接近无穷大,反之
,因此将loss朝着较小的方向优化,可以实现reward model对于较好的回答给出更高的打分。
策略梯度的一些问题
观察公式(1)可以发现,一条轨迹的各个步骤都是乘以整个轨迹的reward ,但是实际上,当前(状态,动作)对的reward与过去的动作步骤无关(因为过去的动作已经发生,无法影响接下来的动作的奖励),所以将公式(1)的优化为
,则公式(1)优化为
(2)
除此以外,状态即刻的奖励reward权重较高,越迟获得的奖励reward权重较低,因此将按折扣因子优化:
此外,观察公式(1)可以发现,当某条轨迹的,要保证
上升,
需要增加,即
需要增加,反之,当某条轨迹的
,要保证
上升,
需要减少,即
需要降低。所以为了加快策略模型的收敛,
需要减去基准线baseline,保证与
相乘的因子有正有负,所以公式(2)优化为:
(3)
为基于状态
采用动作
的收益 ,定义它为动作价值
,
baseline为 ,由于该值与动作无关,这个期望被定义为状态价值
,则策略概率对数的梯度
的权重为
,在给定状态
下,
与具体的动作有关,
与动作无关,
衡量的是采取特定动作
的优势, 将其定义为优势函数
,
越大,代表动作
相比于别的动作更有优势。
由于的期望很难计算,在PPO算法中采用带有linear头的神经网络来估计
,损失函数为均方误差损失:
(4)
(注意是用状态价值神经网络的拟合目标是不同时间步的,而不是
的期望,原因是均方误差mse的优化结果是模型拟合出随机变量的条件期望,而
,因此不断降低神经网络与随机变量
之间的mse loss来训练状态神经网络)。
广义优势估计GAE
PPO算法采用以下网络训练价值函数:
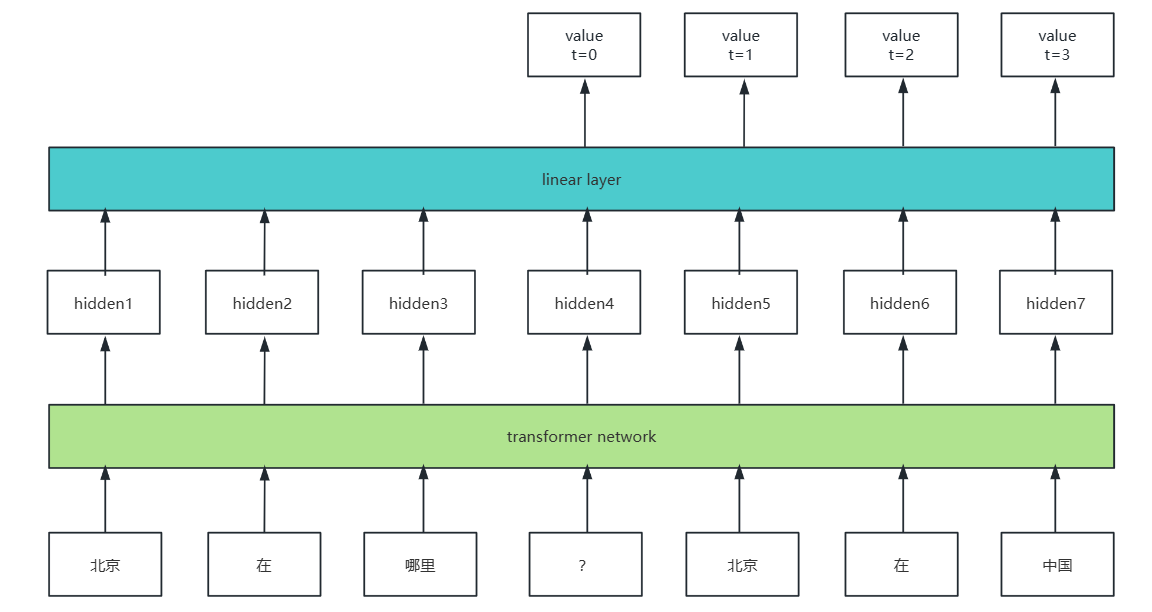
在transformer network输出logits后加上输出维度为1的linear layer作为状态价值模型在不同时间步的预测值,其真实值为
,注意轨迹最后一个value值为reward model给出的轨迹评分。
分别可用蒙特卡洛 、时序差分 的方法估计优势函数,其中蒙特卡洛法的思想是从环境中采样得到全部时间步的奖励后计算出来,然而这种方法需要多次采样,方差较大,不同的是,时序差分 方法是只是采样一步,其余采用状态价值估计,推广到
步时,即
(5)
为了平衡方差和偏差,定义了广义优势函数GAE :
为了方便计算,定义TD误差 ,huggingface的源码实现按照以下递归方式计算优势函数
(5)
计算出各个时间步的优势后,加上
即可表达出状态价值函数 拟合的目标值
小结
本文介绍了大模型RLHF的基础概念、策略梯度以及广义优势估计GAE,下篇文章正式介绍近端策略优化算法PPO的损失函数和优化过程。如果这篇文章对你有帮助,动下小手点赞、关注、收藏把,博主会带来更多算法、工程方面的技术文章分享!