论文研读:制造中的可解释人工智能综述
论文标题 : A Review of Explainable Artificial Intelligence in Manufacturing
预印本地址 : https://arxiv.org/abs/2107.02295v1
arXiv编号 : 2107.02295v1
作者 : Georgios Sofianidis★1, Jože M. Rožanec★2,3, Dunja Mladenić2, and Dimosthenis Kyriazis1
★ equal contribution
单位:
- 1 Department of Digital Systems, University of Piraeus, Piraeus, Greece
- 2 Jožef Stefan Institute, Jamova 39, 1000 Ljubljana, Slovenia
- 3 Jožef Stefan International Postgraduate School, Jamova 39, 1000 Ljubljana, Slovenia
页数 : 17页(含参考文献)
参考文献: 63篇
Post-Hoc + Local + Model-Agnostic(如SHAP)适合解释黑盒成本预测模型对单个零件的定价依据。Post-Hoc + Global 可帮助理解模型整体的特征重要性排序。Intrinsic 方法在需要完全透明的成本估算场景(如审计、合规)中更有优势。
1. 论文基本信息

1.1 研究背景
- 生活的各个方面数字化提供了大量数据,使人工智能(AI)模型的实施成为可能
- 制造业和加工工业也不例外,AI模型在制造过程中扮演重要角色
- AI模型驱动更高质量:增强质量检查和生产过程监控、自动化物料搬运、故障诊断和事件预测、更敏捷的生产管理、灵活的生产计划,并实现人类与协作机器人的有效协作
- 特别是后者(人机协作)是向工业5.0过渡的重要一步,重点是人与机器人之间的协同作用, actors是collaborators而不是competitors
- 尽管这些模型的准确性很高,但它们大多被认为是黑盒子:它们对人类来说是不可理解的
- 不透明性影响对系统的信任,这在决策制定的背景下至关重要
1.2 研究目标
- 提供可解释人工智能(XAI)技术的概述,作为提高模型透明度的手段
- 分析评估这些技术的不同指标
- 描述制造领域中的几个应用场景
1.3 论文贡献
- 综述性论文:系统梳理XAI在制造业中的应用
- 分类框架:提出XAI技术的多维度分类法(解释来源、解释范围、模型依赖性)
- 评估指标综述:总结XAI技术的定性和定量评估标准
- 制造应用:重点讨论质量4.0、成本估算、网络安全等制造场景
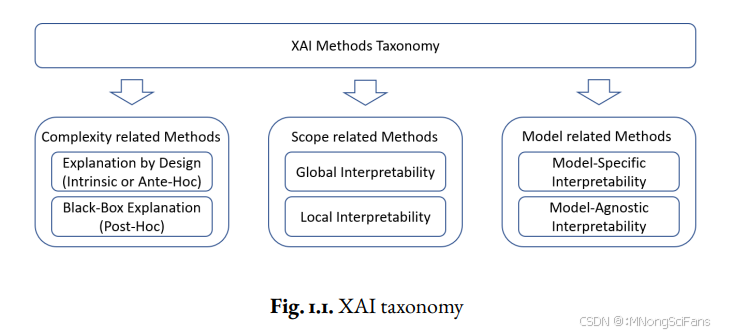
2. XAI分类框架(核心贡献)
2.1 三维度分类法
论文提出了XAI技术的三维分类框架(图1.1):
维度1: 可解释性来源(Explainability Source)
├── 内在可解释模型(Intrinsically Interpretable Models)
└── 需要事后解释的模型(Post-hoc Explanations)
维度2: 解释范围(Scope of Explanation)
├── 全局解释(Global):描述整个模型的行为或预测的平均行为
└── 局部解释(Local):描述模型对特定预测的行为
维度3: 对预测模型的依赖性(Dependency on Forecasting Model)
├── 模型无关(Model-Agnostic):可应用于任何AI模型
└── 模型特定(Model-Specific):只能应用于使用特定算法或算法类型构建的AI模型2.2 XAI技术详细分类(表1)
论文在第2节详细讨论了以下XAI技术类别:
类别1: 基于模型的方法(Model-Based Methods)
包括通过其本质可解释的方法,或使用不同可解释模型来解释任务模型的方法。
子类1: 内在可解释模型
- 稀疏线性分类器(例如线性回归、逻辑回归)
- 离散化方法(例如基于规则的learners、决策树)
- 基于样本的模型(例如K-最近邻)
子类2: 事后解释方法(Surrogate Models)
- 可解释的代理模型,可以近似任务模型
- 使用可解释模型(如决策树、线性模型)来解释复杂黑盒模型
类别2: 基于属性的解释(Attribution-Based Methods)
使用输入特征的解释力来解释任务模型。这些方法也称为特征(或变量)重要性、相关性或影响方法。
子类1: 扰动基方法(Perturbation-Based)
- PDA(Prediction Difference Analysis)40:基于这样的想法:关于某个输入特征对类别的相关性可以通过测量如果该特定特征被移除后预测如何变化来估计
- 反卷积网络(Deconvolutional Networks)60:尝试重建特征图到输入层或原始图像
- Meaningful Perturbation 11, 35, 63:使用先验知识关于图像,选择连接的像素块作为特征来分析不同窗口大小对top scoring类别的影响
子类2: 反向传播基方法(Backpropagation-Based)
- Gradient* 47:通过计算输出类别相对于输入的偏导数来计算特征属性
- Gradient * Input 46:通过获取输出相对于输入的有符号偏导数,并按输入逐元素相乘,来提高属性图的清晰度
- DeepLIFT(Deep Learning Important FeaTures) 46:使用基于导数的方法通过神经网络传播激活差异而不是梯度
- Integrated Gradients 53:依靠通过计算属性将输入变量逐元素与平均偏导数相乘的想法,当输入从其基线变化到其最终值时
- Smooth-Grad 49:关注局部敏感性,并计算来自几个小扰动的输入图像的平均图
- All Convolutional Net 52:用增加步幅的卷积层替换max-pooling层
- CAM(Class Activation Mapping) 61:依靠这样的观察,即一些卷积层表现为无监督对象检测器,它使用全局平均池化来创建热力图
- Grad-CAM(Gradient-weighted Class Activation Mapping) 45:使用梯度信息来理解最后一个卷积层中的神经元激活强度
- Grad-CAM++ 6:结合正偏导数和特殊类别分数来解释图像中多个对象实例的出现
- LRP(Layer Wise Relevance Propagation) 3:受梯度方法影响,但受消失梯度问题困扰
类别3: 基于样本的解释(Example-Based Methods)
通过从数据集中选择特定实例或创建新实例来解释任务模型。
- 原型(Prototypes):被预测模型良好预测的实例
- 批评(Criticisms):不被预测模型良好预测的实例
- 反事实解释(Counterfactual Explanations):指示输入中所需的更改,这将导致预测/输出中的显著变化(例如反转预测)
2.3 XAI技术总览表(表1)
论文提供了XAI技术的综合分类表(表1),包括以下信息:
| 技术 | 局部/全局 | 模型无关/特定 | 基于模型/属性/样本 | 数据类型 |
|---|---|---|---|---|
| All Convolutional Net 52 | Local | Specific | Attribution | IMAGE |
| Anchors 39 | Local/Global | Agnostic | Example-based | TABULAR/TEXT |
| CAM 61 | Local | Specific | Attribution | IMAGE |
| Contextual PDA 11 | Local | Specific | Attribution | IMAGE |
| DeepLIFT 46 | Local | Specific | Attribution | ANY |
| DICE 31 | Local | Agnostic | Example-based | ANY |
| DLIME 58 | Local | Agnostic | Model-based | ANY |
| GradCAM++ 6 | Local | Specific | Attribution | IMAGE |
| Gradient 47 | Local | Specific | Attribution | ANY |
| Gradient * Input 46 | Local | Specific | Attribution | ANY |
| Grad-CAM 45 | Local | Specific | Attribution | IMAGE |
| Integrated Gradients 53 | Local | Specific | Attribution | ANY |
| k-LIME 16 | Local | Agnostic | Model-based | ANY |
| LRP 3 | Local | Specific | Attribution | ANY |
| LIME 38 | Local | Agnostic | Model-based | ANY |
| LIMETree 50 | Local | Agnostic | Model-based | TABULAR |
| Local Foil Trees 54 | Local | Agnostic | Model-based | TABULAR |
| LoRE 14 | Local | Agnostic | Model-based | TABULAR |
| MAPLE 36 | Local | Agnostic | Model-based | TABULAR |
| Meaningful Perturbation 11 | Local | Specific | Attribution | IMAGE |
| MMD-CRITIC 21 | Global | Agnostic | Example-based | ANY |
| PDA (Prediction Difference Analysis) 40, 63 | Local | Specific | Attribution | IMAGE |
| RISE 35 | Local | Specific | Attribution | IMAGE |
| SHAP 28 | Local/Global | Agnostic | Attibution | ANY |
| SmoothGrad 49 | Local | Specific | Attribution | IMAGE |
| STREAK 9 | Local | Agnostic | Model-based | IMAGE |
| TREPAN 7 | Global | Specific | Model-based | TABULAR |
关键观察:
- SHAP是唯一同时支持局部和全局解释的模型无关方法
- 图像数据:主要使用基于属性的方法(CAM、Grad-CAM、LRP等)
- 表格数据:主要使用基于模型的方法(LIME、LoRE、MAPLE等)
- 文本数据:主要使用Anchors等基于样本的方法
3. XAI技术评估指标
3.1 评估挑战
- 可解释性被认为是一个主观概念
- 如果AI系统是内在可解释的,或者如果非可解释模型可以补充有意义和忠实的解释,则认为AI系统是可解释的
- 虽然XAI技术提供不同类型的解释,但解释的质量感知取决于用户、领域、感兴趣的信息和解释本身
3.2 评估标准(4个基本方面)
25列出了评估可解释模型近似的4个方面:
- 忠实性(Fidelity):能够正确捕获参考模型行为的程度
- 无歧义性(Unambiguity):能够为解释每个数据实例提供单一和确定性理由
- 可解释性(Interpretability):近似应该是人类可理解的
- 交互性(Interactivity):解释应该支持用户交互
22进一步阐述了忠实性的两个属性:
- 正确性(Soundness):解释组件对参考模型的真实程度
- 完整性(Completeness):解释描述参考模型的程度
56列举了另外三个标准:
- 敏感性(Sensitivity):解释变量与背景条件之间关系的强度
- 集成度(Degree of Integration):解释与更大理论框架的连接程度
- 认知显著性(Cognitive Salience):解释背后的理由可以被遵循的容易程度
3.3 评估方法(3个类别)
8确定了三种评估方法类别:
类别1: 应用接地评估(Application-grounded Evaluation)
- 根植于真实世界应用
- 收集领域专家关于提供给他们的解释反馈
- 示例:质量检查、生产成本估算等制造场景
类别2: 人类接地评估(Human-grounded Evaluation)
- 参考从与真实世界应用不存在的实验中获得的反馈
- 使用lay users(非专家用户)进行实验
- 指标:准确性、响应时间、主观满意度(Likert量表)
类别3: 功能性接地评估(Functionality-grounded Evaluation)
- 使用一些正式定义或标准进行评估,测量解释质量
- 不需要人类受试者
- 指标:忠实性、敏感性、多样性、单调性等
3.4 具体评估测试(功能性接地评估)
15提出了3个功能性接地评估测试:
-
特征增强测试(Feature Augmentation Test):
- 如果来自特定实例的可解释特征的值被具有不同标签(例如"new-label")的实例的这些值替换,则分类结果应该是"new-label"
-
合成测试(Synthetic Test):
- 基于这样的假设:如果可解释特征被准确选择,则可以通过保留可解释特征值并分配随机值给其他特征来创建新的合成实例,而不会影响预测结果
-
特征减少测试(Feature Reduction Test):
- 如果选择的可解释特征被正确选择,则从输入中移除其中一个应该导致不同的预测
问题:20指出,移除特征子集的样本具有不同于模型训练的数据分布,违反了关键的机器学习假设
解决方案 :20提出ROAR(Remove And Retrain)方法:
- 对于每个被认为重要的特征,用非信息值替换它(在训练和测试集中)
- 重新训练模型并测量性能变化
- 此外,他们提出使用特征重要性的随机分配作为基准来衡量可解释特征提取技术的质量
3.5 定量评估指标
33提出了几个定量指标:
-
互信息(Mutual Information):
- 衡量两个随机变量x和y之间的相互依赖性
- 在创建可解释表示时考虑
- 理想情况下,可解释特征的数量应该减少以最大化简单性和广度,同时旨在保持关于目标标签的高忠实性
-
多样性(Diversity):
- 衡量解释集集成的程度
- 计算为示例集上所有对之间的差异的平均值
-
单调性(Monotonicity):
- 考虑特征属性应该是单调的
- 计算为两个向量之间的Spearman等级相关系数
-
非敏感性(Non-sensitivity):
- 评估可解释方法是否给模型功能不依赖于的特征分配任何相关性分数
- 计算为分配零属性的特征集与模型功能不依赖于的特征集之间的对称差异的基数
-
有效复杂度(Effective Complexity):
- 衡量如果某些解释特征可以被移除而不显著影响预测
- 较低的有效复杂度意味着更简单的解释
3.6 人类接地评估指标
24提出了人类可解释性分数(HIS - Human Interpretability Score)(公式1):
- 衡量用户预测分配给特定数据点的标签需要多长时间
- 将响应时间作为衡量可解释性的指标
23使用了三个定量指标:
- 准确性:受试者响应与模型预测的一致性
- 响应时间:用户做出决策所需的时间
- 主观满意度:使用Likert量表测量
4. 制造应用与用例
4.1 XAI在制造业的价值
论文指出,XAI技术在制造业中特别重要,因为:
- 黑盒模型的不透明性影响信任,这在决策制定中至关重要
- 人类与AI的协作(工业5.0)需要可解释性,以便人类理解AI的决策
- 监管合规:在某些行业(如医疗、汽车),AI决策必须是可审计的
- 持续改进:理解模型预测有助于识别数据问题、模型偏差和改进机会
4.2 质量4.0(Quality 4.0)
论文重点讨论了预测性质量管理(Predictive Quality Management)领域中的XAI应用:
应用1: 自动缺陷检测
- 目标:解释为什么模型将某个产品分类为"缺陷"
- XAI技术:CAM、Grad-CAM、LRP、Integrated Gradients等
- 价值:可视化影响决策的图像区域(热力图),帮助领域专家理解模型决策
应用2: 生产过程监控
- 目标:解释为什么模型预测某个过程参数会导致质量问题
- XAI技术:SHAP、LIME、LoRE等
- 价值:提供特征重要性排序,帮助工程师调整过程参数
4.3 制造成本估算
论文引用了Yoo and Kang 57(即我们之前分析的arXiv:2010.14824论文!):
- 应用:使用3D Grad-CAM可视化影响制造成本的3D CAD模型区域
- 价值:帮助设计工程师理解为什么某个设计会导致高成本,并指导设计修改
4.4 网络安全
论文讨论了XAI在网络安全领域的应用:
- 应用1: 探索模型漏洞 26, 29
- 应用2: 识别扰动数据样本 10
- 价值:使用XAI技术(如SHAP值)来理解模型对对抗样本的敏感性,并提高模型鲁棒性
4.5 EU H2020 STAR项目
论文提到,在STAR项目(Safe and Trusted Human-Centric Artificial Intelligence in Future Manufacturing Lines)中:
- XAI用于提供对每个预测最相关特征的洞察
- 探索模型漏洞并帮助识别潜在的数据投毒(Data Poisoning)
- 在提供准确的预测解释的同时,漏洞评估和早期数据投毒识别确保系统安全,增强用户对系统的信任
5. 开放问题与挑战
5.1 技术挑战
-
评估标准的主观性:
- 可解释性是一个主观概念,没有普适的评估标准
- 不同用户、不同领域可能需要不同的解释
-
忠实性与可解释性的权衡:
- 高忠实性的解释(如深度神经网络)可能难以解释
- 高可解释性的解释(如决策树)可能忠实性不足
-
计算成本:
- 某些XAI技术(如SHAP的精确计算)计算成本很高
- 需要开发高效的近似算法
-
多维解释的集成:
- 如何集成局部解释、全局解释、反事实解释等多种解释?
- 如何为用户提供连贯的解释体验?
5.2 产业应用挑战
-
领域专家的参与:
- XAI系统的开发需要领域专家的持续参与
- 如何确保解释对领域专家有意义?
-
用户研究的缺乏:
- 目前大多数XAI评估使用功能性接地评估(不需要人类受试者)
- 需要更多的应用接地评估和人类接地评估
-
实时解释的生成:
- 在生产线环境中,解释需要实时生成
- 如何平衡解释的准确性和生成速度?
-
解释的一致性和鲁棒性:
- 相似实例的解释应该相似(一致性)
- 输入的微小变化不应导致解释的巨大变化(鲁棒性)
5.3 未来研究方向
-
多学科方法:
- XAI需要多学科方法(机器学习、认知科学、可视化、领域知识)
- 需要更好地理解领域专家和普通用户如何理解和信任解释
-
用户参与XAI结果验证:
- 用户必须参与XAI结果的验证
- 如何设计交互式界面,使用户能够有效提供反馈?
-
XAI与Responsible AI的集成:
- XAI是Responsible AI的基础(如我们在第一篇论文分析中所述)
- 如何将XAI与其他RAI支柱(公平性、鲁棒性、隐私等)集成?
-
标准化和基准:
- 缺乏标准化的XAI评估基准
- 需要建立制造领域的XAI基准数据集和评估协议
6. 与之前分析论文的关联与协同
6.1 与之前三篇论文的直接引用关系
重要发现:本论文引用了我们所分析的其他论文!
| 本论文引用 | 我们分析的论文 | 引用位置 |
|---|---|---|
| Yoo and Kang 57 | arXiv:2010.14824 ("Explainable AI for Manufacturing Cost Estimation and Machining Feature Visualization") | 第11页,成本估算应用 |
意义:
- 本论文是综述性论文,梳理了XAI在制造业的应用
- 我们之前分析的arXiv:2010.14824论文是其中的一个应用案例
- 形成引用关系链:Paper 3 (arXiv:2010.14824) ← 本文引用
6.2 四篇论文的协同效应
通过分析这四篇论文,我们建立了完整的"XAI驱动的制造优化"技术体系:
| 维度 | 论文 | 核心贡献 | 与本文的关系 |
|---|---|---|---|
| 理论 | XAI is Responsible AI (arXiv:2312.01555) | XAI是RAI的基础,提供XAI技术分类和实施指南 | 本文提供了XAI技术的详细分类(表1)和评估指标,可作为该论文的技术实现参考 |
| 方法 | No-Teardown Cost Estimation (arXiv:2006.08828) | Top-Down成本估算 + Shapley值分解 | 本文详细讨论了SHAP(基于Shapley值)作为模型无关的归因方法(表1) |
| 技术 | XAI for Manufacturing Cost Estimation (arXiv:2010.14824) | 3D Grad-CAM可视化 + 3D CNN成本预测 | 本文引用了该论文(参考文献57),并将其作为XAI在成本估算中的应用案例 |
| 应用综述 | 本文 (arXiv:2107.02295) | XAI在制造业的全面综述 + 分类框架 + 评估指标 | 整合了前三篇论文的技术,提供系统性分类和评估框架 |
6.3 本文的独特价值
本文的独特价值在于:
- 系统性分类框架:提出XAI技术的三维度分类法(解释来源、解释范围、模型依赖性),比单篇技术论文提供更全面的视角
- 评估指标综述:详细讨论了XAI技术的定性和定量评估标准,这是单篇技术论文通常不涉及的内容
- 制造应用聚焦:专门针对制造业讨论XAI应用,覆盖质量4.0、成本估算、网络安全等场景
- 开放问题讨论:明确指出XAI在制造业应用的挑战和未来研究方向
7. 对QuoteApp项目的具体建议
7.1 立即行动(本周)
-
阅读并理解本文的XAI分类框架:
- 三维度分类法(解释来源、解释范围、模型依赖性)
- 表1:XAI技术总览(选择适合QuoteApp的技术)
-
评估QuoteApp的XAI需求:
- 需要全局解释还是局部解释?(或两者都需要?)
- 需要模型无关方法还是模型特定方法?
- 用户是谁?(领域专家 vs. 普通用户)
-
选择合适的XAI技术:
- 表格数据(成本公式链):SHAP、LIME、LoRE、MAPLE
- 图像数据(3D CAD):3D Grad-CAM(来自Paper 3)
- 需要全局+局部解释:SHAP(唯一同时支持两者的模型无关方法)
7.2 短期计划(1-2个月)
-
实施基础XAI功能:
- 任务1 :使用SHAP解释13步成本公式链
- 输入:13步成本公式链的中间结果
- 输出:各成本组成因素的贡献度(材料费、加工费、管销费率等)
- 可视化:条形图、饼图、瀑布图
- 任务2 :提供局部解释(LIME)
- 针对特定零件,解释为什么成本是高或低
- 例如:"这个零件成本高是因为材料为不锈钢 + 加工难度大(深孔)"
- 任务1 :使用SHAP解释13步成本公式链
-
建立XAI评估框架:
- 使用本文第3节讨论的评估指标
- 功能性接地评估:计算SHAP值的忠实性、敏感性、单调性
- 人类接地评估:邀请领域专家评估解释的质量(准确性、响应时间、主观满意度)
-
收集和整理3D CAD数据集:
- 目标:至少1,000个零件(参考Paper 3的1,006个)
- 标注材料、体积、成本信息
- 为3D Grad-CAM可视化做准备
7.3 中期计划(3-6个月)
-
实现3D Grad-CAM可视化:
- 参考Paper 3(arXiv:2010.14824)
- 使用PyTorch/TensorFlow实现3D Grad-CAM
- 可视化成本高亮区域
- 输出:交互式3D可视化(使用Three.js或VTK)
-
生成设计优化建议:
- 基于高亮区域,自动生成设计修改建议
- 例如:"将拐角圆角从3mm增加到8mm可降低10%成本"
-
实现反事实解释:
- 使用DICE 31或LoRE 14
- 回答"如果我更改这个特征,成本会如何变化?"的问题
- 提供what-if分析
7.4 长期计划(7-12个月)
-
完整XAI框架:
- 集成多种XAI技术(SHAP、LIME、3D Grad-CAM、DICE等)
- 提供全局解释(特征重要性排序)+ 局部解释(特定零件成本解释)+ 反事实解释(what-if分析)
- 交互式解释界面(用户可以选择解释类型、特征等)
-
Responsible AI六大支柱:
- 公平性(Fairness):评估成本估算是否对不同材料/工艺公平
- 鲁棒性(Robustness):对抗样本测试(参考本文网络安全应用)
- 透明度(Transparency):XAI解释(SHAP、LIME、3D Grad-CAM)
- 问责制(Accountability):成本估算决策日志
- 隐私(Privacy):客户数据加密
- 安全性(Safety):模型监控和异常检测
-
端到端系统:
- Web界面:上传3D CAD → 查看成本预测 → 查看XAI解释(全局+局部+反事实) → 接收设计建议
- 企业微信/ClawBot集成:通过对话提供XAI解释和设计建议
- 用户反馈机制:收集用户对解释质量的反馈,持续改进XAI系统
8. 技术实现细节
8.1 SHAP实施(表格数据 - 成本公式链)
python
import shap
import numpy as np
import matplotlib.pyplot as plt
# 假设我们有13步成本公式链的预测模型
# model: 成本预测模型(可以是任何模型:线性回归、神经网络、XGBoost等)
# X: 输入特征(13步成本组成因素)
# y: 输出(总成本)
# 创建SHAP解释器(模型无关方法)
explainer = shap.TreeExplainer(model) # 如果模型是树模型(XGBoost、LightGBM等)
# 或者
explainer = shap.KernelExplainer(model.predict, X_train[:100]) # 模型无关方法
# 计算SHAP值(局部解释)
shap_values = explainer.shap_values(X_test)
# 可视化
# 1. 单个预测的解释(局部解释)
shap.force_plot(explainer.expected_value, shap_values[0, :], X_test.iloc[0, :])
# 2. 特征重要性排序(全局解释)
shap.summary_plot(shap_values, X_test)
# 3. 特征依赖图(全局解释)
shap.dependence_plot("material_cost", shap_values, X_test)
# 4. 将SHAP值转换为DataFrame(方便分析)
shap_df = pd.DataFrame(shap_values, columns=X_test.columns)
feature_importance = shap_df.abs().mean().sort_values(ascending=False)
print(feature_importance)8.2 LIME实施(局部解释 - 表格数据)
python
from lime import lime_tabular
# 创建LIME解释器
explainer = lime_tabular.LimeTabularExplainer(
X_train.values,
feature_names=X_train.columns,
class_names=['low_cost', 'high_cost'],
mode='classification' # 或'regression'
)
# 解释单个预测
exp = explainer.explain_instance(
X_test.iloc[0].values,
model.predict_proba, # 或model.predict
num_features=10
)
# 可视化
exp.show_in_notebook()
exp.as_pyplot_figure()
# 获取解释(特征权重)
exp_list = exp.as_list()
print(exp_list)8.3 3D Grad-CAM实施(3D CAD数据)
参考Paper 3(arXiv:2010.14824)的技术实现,使用PyTorch实现3D Grad-CAM。
python
import torch
import torch.nn.functional as F
def compute_3d_grad_cam(model, voxel, material, volume, target_layer):
"""
计算3D Grad-CAM
Args:
model: 训练好的3D CNN模型
voxel: 输入体素数据 (1, 1, 32, 32, 32)
material: 材料数据 (1, 13)
volume: 体积数据 (1, 1)
target_layer: 目标卷积层(例如conv5)
Returns:
grad_cam: 3D Grad-CAM热力图 (32, 32, 32)
"""
# 注册钩子以获取特征图和梯度
features = []
gradients = []
def forward_hook(module, input, output):
features.append(output)
def backward_hook(module, grad_input, grad_output):
gradients.append(grad_output[0])
# 注册钩子
handle_forward = target_layer.register_forward_hook(forward_hook)
handle_backward = target_layer.register_backward_hook(backward_hook)
# 前向传播
model.eval()
output = model(voxel, material, volume)
# 反向传播
model.zero_grad()
output.backward()
# 移除钩子
handle_forward.remove()
handle_backward.remove()
# 获取特征图和梯度
feature_map = features[0] # (1, 64, 4, 4, 4)
gradient = gradients[0] # (1, 64, 4, 4, 4)
# 计算权重α(全局平均池化)
alpha = torch.mean(gradient, dim=[2, 3, 4], keepdim=True) # (1, 64, 1, 1, 1)
# 线性组合特征图
grad_cam = torch.sum(alpha * feature_map, dim=1) # (1, 4, 4, 4)
# 通过ReLU激活
grad_cam = F.relu(grad_cam)
# 插值到输入分辨率(32×32×32)
grad_cam = F.interpolate(grad_cam.unsqueeze(0), size=(32, 32, 32), mode='trilinear', align_corners=False)
return grad_cam.squeeze().detach().numpy()8.4 DICE实施(反事实解释)
python
from dice import Dice
# 创建DICE解释器
exp = Dice.Dice(X_train, model)
# 生成反事实解释
cf = exp.generate_counterfactuals(
X_test.iloc[0],
total_CFs=5, # 生成5个反事实
desired_class="opposite" # 反转预测
)
# 可视化
cf.visualize_as_dataframe()
# 获取反事实实例
cf_df = cf.cf_examples
print(cf_df)9. 论文的局限性与未来研究方向
9.1 局限性
-
综述性论文:
- 未提出新方法,仅梳理现有研究
- 技术深度不足,对每个XAI技术的讨论较浅
-
评估指标缺乏实证研究:
- 第3节讨论了许多评估指标,但缺乏实证研究
- 未提供哪些指标最适合制造业的场景指导
-
制造应用案例有限:
- 主要讨论了质量4.0、成本估算、网络安全等少数应用
- 未涵盖制造业的所有环节(如供应链优化、预测性维护等)
-
缺乏实施指南:
- 未提供XAI技术选择和实施的具体指南
- 未讨论XAI系统的部署和维护
9.2 未来研究方向(基于论文内容推断)
-
技术方向:
- 开发更高效、更可扩展的XAI算法
- 集成多种解释(全局+局部+反事实)的框架
- XAI与生成式AI的集成(生成自然语言解释)
-
评估方向:
- 建立标准化的XAI评估基准(特别是针对制造业)
- 更多的应用接地评估和人类接地评估
- 开发自动化的XAI评估工具
-
产业应用方向:
- XAI在制造业更多环节的应用(供应链、预测性维护、能源管理等)
- 实时XAI系统的开发(满足生产线环境的需求)
- XAI与Responsible AI的完整集成
-
跨学科方向:
- 认知科学研究:理解人类如何理解和信任AI解释
- 可视化技术研究:如何有效呈现XAI解释?
- 领域知识集成:如何将领域知识融入XAI系统?
10. 结论
10.1 论文价值
这篇论文是XAI在制造业应用的全面综述,具有重要的学术和工程价值:
-
学术价值:
- 提出XAI技术的三维度分类框架(解释来源、解释范围、模型依赖性)
- 提供XAI技术的综合分类表(表1),包括63篇参考文献
- 详细讨论XAI技术的评估指标(功能性接地、人类接地、应用接地)
- 为未来研究指明方向(开放问题与挑战)
-
工程价值:
- 帮助制造企业和AI从业者了解XAI技术的全貌
- 提供技术选择参考(哪种XAI技术适用于哪个场景?)
- 讨论产业现状和挑战(有助于XAI技术的推广)
-
对QuoteApp项目的价值:
- 系统性视角:提供XAI技术的全貌,帮助选择合适的技术
- 评估框架:提供XAI技术的评估指标,确保解释的质量
- 实施指南:虽然未提供详细实施步骤,但引用了许多技术论文(如SHAP、LIME、Grad-CAM等),可作为进一步阅读的参考
- 与之前论文的协同:本文引用了Paper 3(arXiv:2010.14824),形成完整的"理论→技术→应用→综述"链条
10.2 五篇论文的综合启示
通过分析五篇论文,我们建立了完整的"XAI驱动的制造优化"技术体系:
| 阶段 | 技术内容 | 参考论文 | 对QuoteApp的价值 |
|---|---|---|---|
| 理论框架 | XAI是RAI的基础,提供XAI技术分类 | Paper 1 (arXiv:2312.01555) | 建立XAI for RAI框架,确保成本估算的公平性、鲁棒性、透明度等 |
| 成本估算方法 | Top-Down方法(从市场价反向分解成本) | Paper 2 (arXiv:2006.08828) | 提供成本分解的新思路(Shapley值),与Bottom-Up方法形成互补 |
| 3D深度学习 | Bottom-Up方法(从3D CAD预测成本 + 3D Grad-CAM可视化) | Paper 3 (arXiv:2010.14824) | 提供3D Cost Estimation的完整技术路线(数据预处理、模型架构、XAI可视化) |
| 全流程优化 | AI在加工全流程的应用综述(材料选择、工具选择、工艺优化、监控、可持续性) | Paper 4 (Procedia CIRP 118) | 明确QuoteApp的功能扩展方向(从成本估算扩展到全流程优化) |
| XAI分类与评估 | XAI技术的三维度分类框架 + 评估指标 + 制造应用综述 | Paper 5 (arXiv:2107.02295)【本文】 | 提供XAI技术选型和评估的系统指南,确保XAI解释的质量 |
技术路线图(最终版):
Phase 1: 基础XAI功能(1-2个月)
- SHAP解释成本公式链(来自Paper 1、2、5)
- 材料选择决策支持(Fuzzy AHP + TOPSIS)(来自Paper 4)
- 表面质量预测(ANN/ANFIS)(来自Paper 4)
Phase 2: 3D深度学习(3-4个月)
- 3D CAD支持(STEP/STL)(来自Paper 3)
- 3D CNN成本预测(来自Paper 3)
- 3D Grad-CAM可视化(来自Paper 3、5)
Phase 3: 加工优化(5-6个月)
- 加工参数优化(GA + ANN)(来自Paper 4)
- 刀具磨损预测(CNN + FCN)(来自Paper 4)
- 实时监控(无监督异常检测)(来自Paper 4)
Phase 4: 可持续性评估(7-9个月)
- 能源消耗预测(ANN/SVR/深度学习)(来自Paper 4)
- 碳足迹计算(来自Paper 4)
- 切削液消耗优化(来自Paper 4)
Phase 5: Responsible AI(10-12个月)
- RAI六大支柱实施(来自Paper 1、5)
- XAI评估框架(来自Paper 5)
- 用户反馈机制(来自Paper 5)
Phase 6: 产业生态系统(13-18个月)
- 云端部署、中小企业支持(来自Paper 4)
- 培训计划、信任建立(来自Paper 4)
- 标准化和基准(来自Paper 5)
10.3 下一步行动
- 立即:阅读并理解本文的XAI分类框架(三维度分类法)和评估指标,选择合适的XAI技术(SHAP、LIME、3D Grad-CAM等)
- 短期:实施基础XAI功能(SHAP解释成本公式链 + LIME局部解释),建立XAI评估框架
- 中期:实现3D Grad-CAM可视化,生成设计优化建议,实现反事实解释(DICE)
- 长期:完整XAI框架 + RAI六大支柱 + XAI评估框架,建立"可信AI报价"品牌
参考文献
-
本论文: Sofianidis, G., Rožanec, J. M., Mladenić, D., & Kyriazis, D. (2021). A Review of Explainable Artificial Intelligence in Manufacturing. arXiv:2107.02295v1.
-
被本论文引用的论文(部分):
- Yoo, S., & Kang, N. (2020). Explainable artificial intelligence for manufacturing cost estimation and machining feature visualization. Expert Systems with Applications, 183, 115441. (即arXiv:2010.14824,本系列分析的第三篇论文)
- Lundberg, S. M., & Lee, S. I. (2017). A unified approach to interpreting model predictions. arXiv:1705.07874. (SHAP)
- Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). "Why should I trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1135-1144).
- Selvaraju, R. R., et al. (2017). Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision (pp. 618-626).
-
本文引用的关键参考文献(按类别):
- XAI分类: 1 Alejandro Barredo Arrieta, et al. (2020); 30 Markus, et al. (2020)
- 基于模型的方法: 7 Craven & Shavlik (1995) - TREPAN; 38 Ribeiro, et al. (2016) - LIME
- 基于属性的方法: 45 Selvaraju, et al. (2017) - Grad-CAM; 28 Lundberg & Lee (2017) - SHAP; 3 Bach, et al. (2015) - LRP
- 基于样本的方法: 39 Ribeiro, et al. (2018) - Anchors; 31 Mothilal, et al. (2020) - DICE
- 评估指标: 15 Guo, et al. (2018); 33 Nguyen & Rodríguez Martínez (2020); 24 Lage, et al. (2018)
