目录
[ps axj](#ps axj)
进程的基本概念
课本概念:程序的⼀个执行实例,正在执行的程序等
内核观点:担当分配系统资源(CPU时间,内存)的实体。
简单的概念是如此,但是深入了解的话却不只是那么简单
根据冯诺依曼体系,我们编译好的可执行程序(二进制文件)会存在于磁盘,运行起来就需要加载到内存当中

打开任务管理器,就会出现如图的正在运行的软件,就相当于一个个存在于磁盘中的可执行程序运行后加载到内存中运行,如下图
在每次电脑重新启动的时候,比这些软件先启动的是操作系统
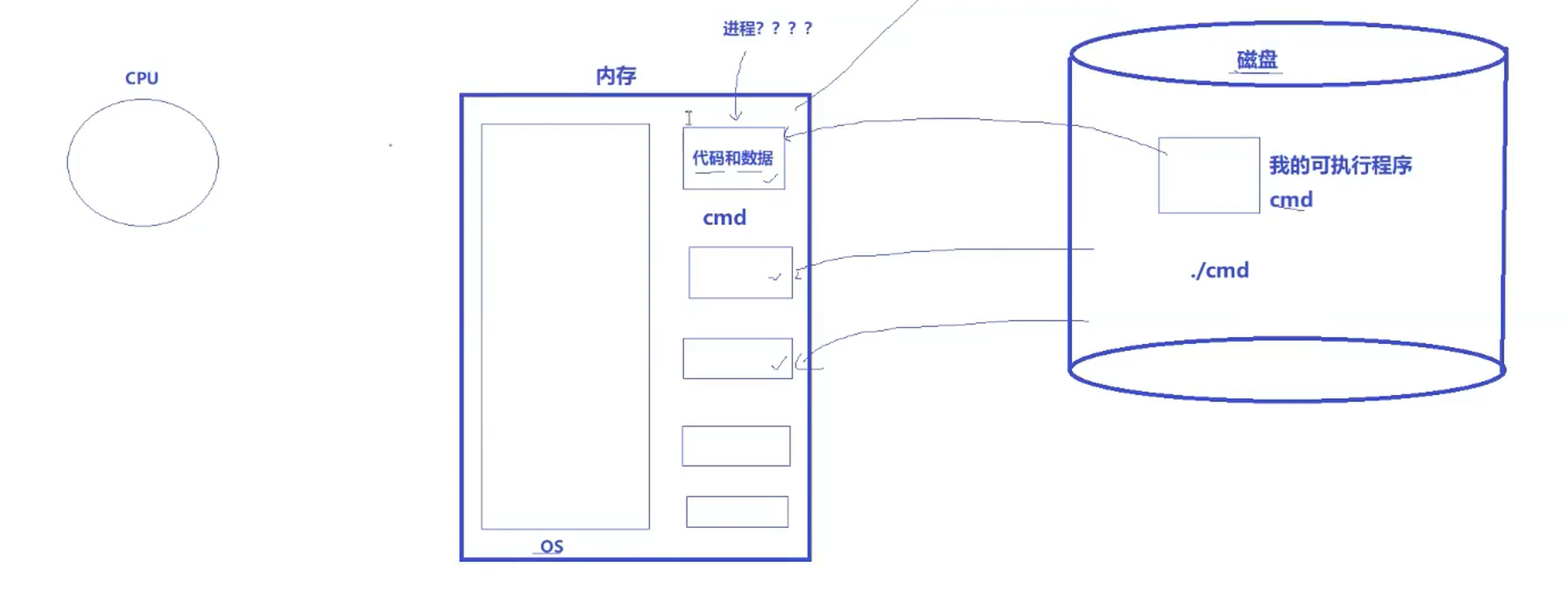
在操作系统的眼中,他是不知道哪个代码和数据是哪个进程的,所以,这么多可执行程序被加载进了内存中,操作系统必然要对多个被加载到内存中的数据进行管理,也就需要"先描述,在组织"
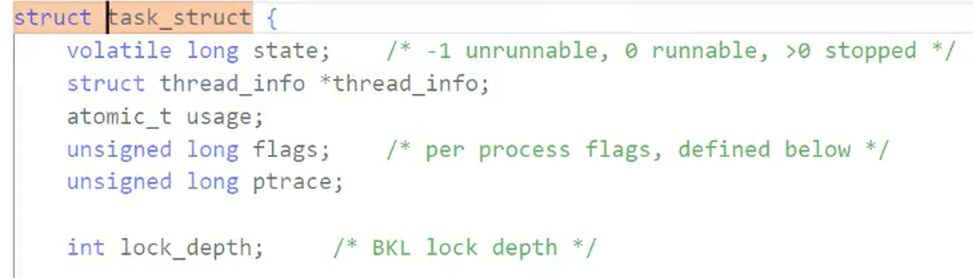
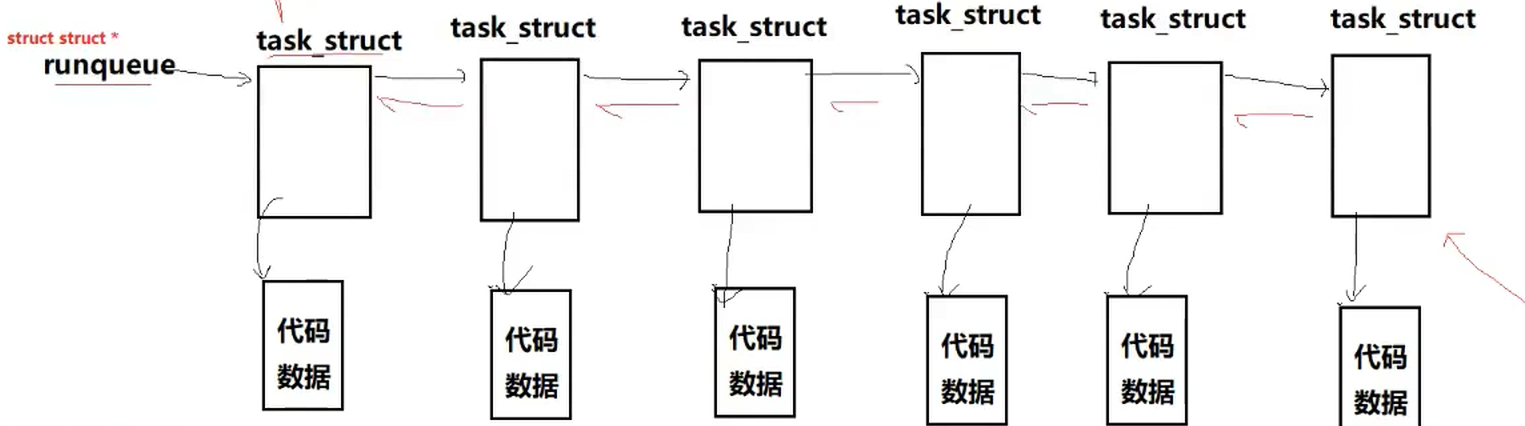
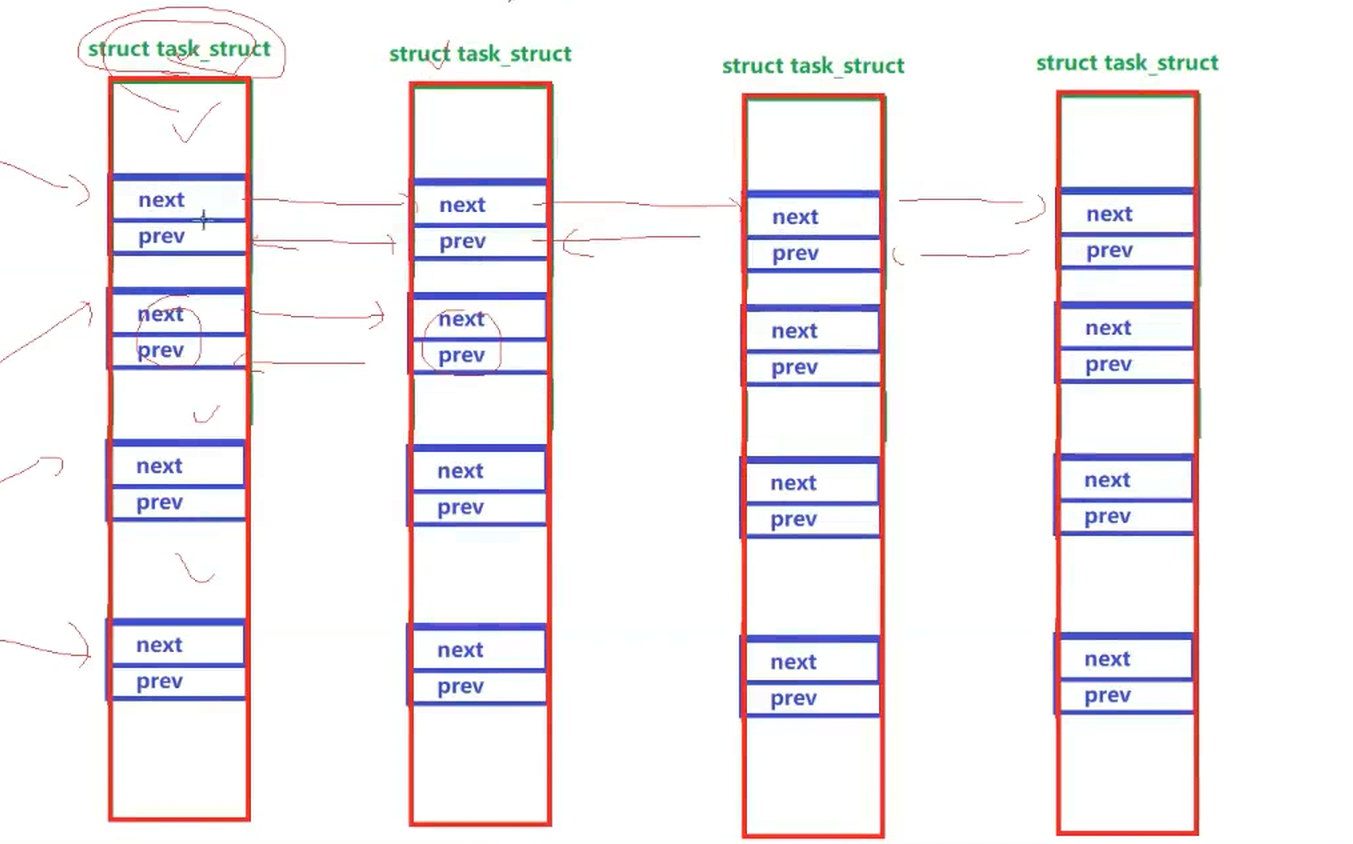
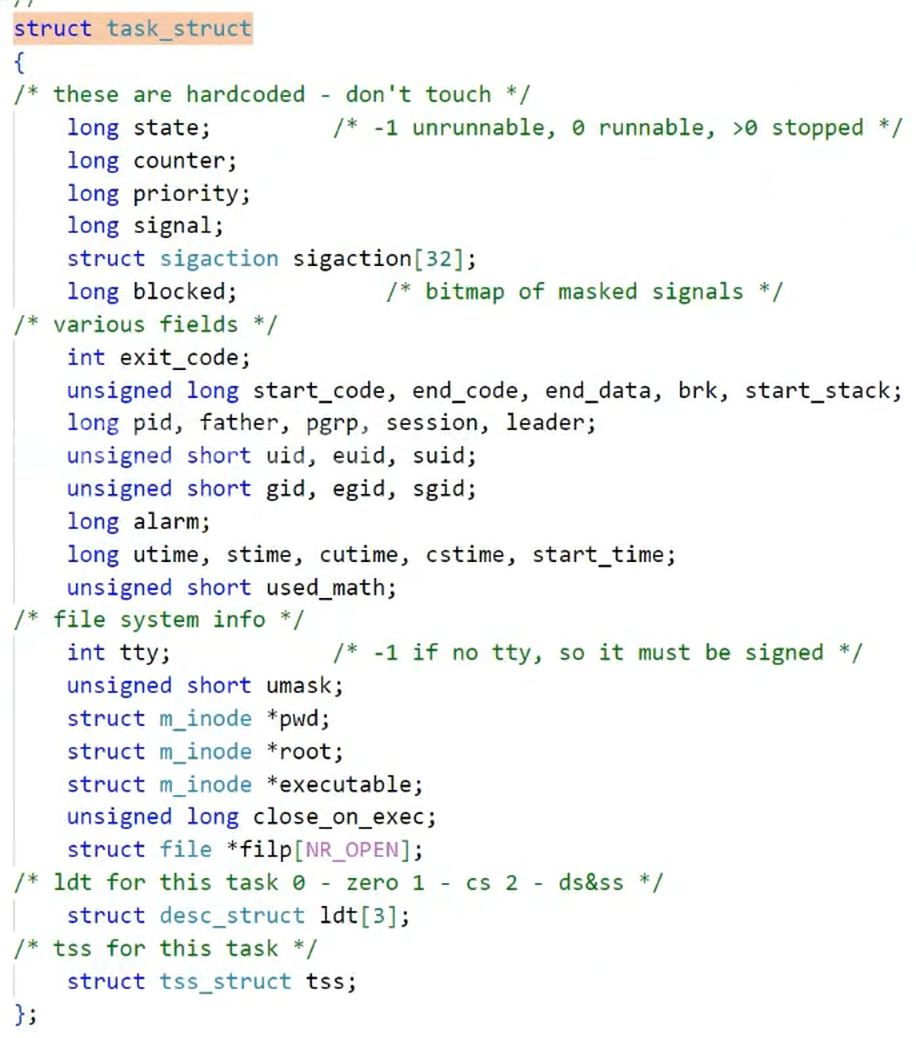
操作系统为了管理每一份代码和数据,就会在操作系统内部对应地构建一个struct结构体,也就是PCB(进程控制块)
Linux是一个具体的操作系统,在内核中是一种数据结构类型,所以PCB具体为(task_struct)是由双链表连接的
进程的所有属性,都可以直接或者间接通过task_struct找到

源码中的task_struct

每从磁盘中加载一个可执行程序到内存中,操作系统就为这个程序按照该结构体类型new一个对象,按照结构体中的属性相对应填好,就多出一个节点(每个节点都有指向自己代码和数据以及下一个节点的指针,包含所有属性),这一个个节点在操作系统内形成了加载内存的进程列表
对进程的管理,就变成了对链表的增删查改
之后CPU要进行调度,可以将该列表想象成一个队列(先进先出),就需要在进程列表中进行查找PCB,然后再根据PCB相对应的代码和数据进行调度
有一个进程代码运行结束了,就先将代码和数据释放掉,再在列表中将该节点释放掉,完成了操作系统对进程的删除
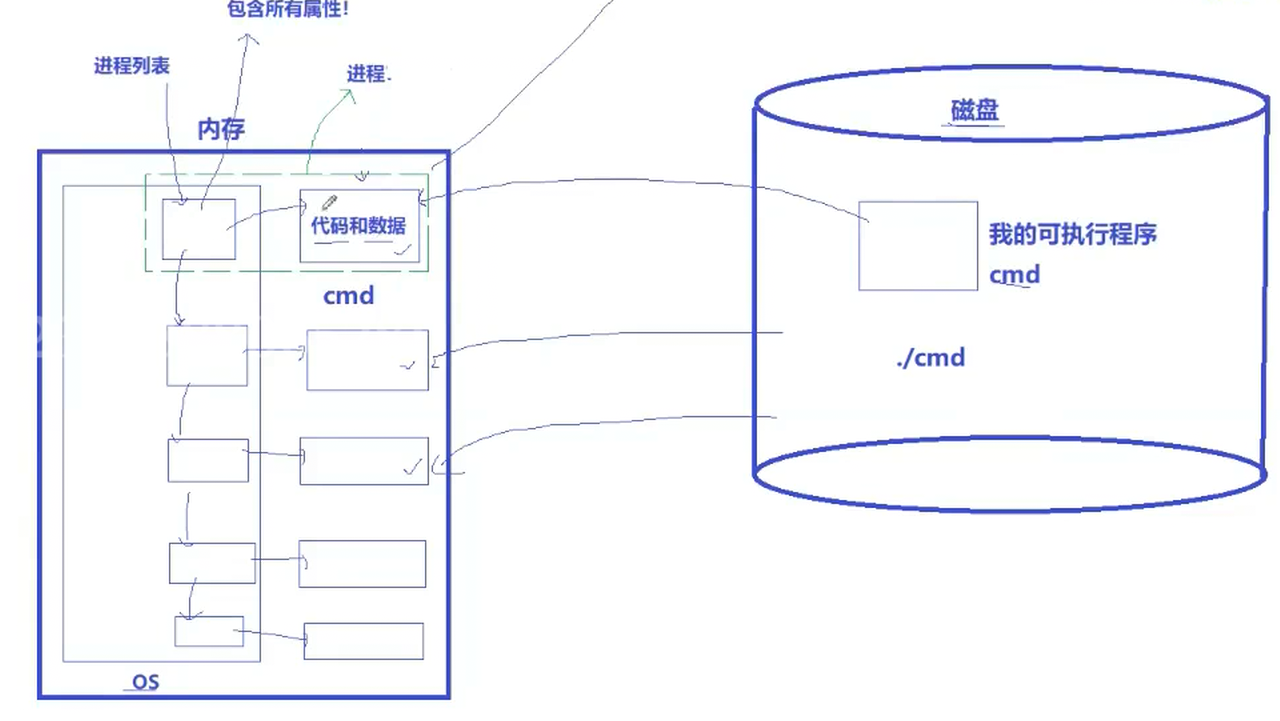
结论:
进程 = 内核数据结构对象【PCB(task_struct)】 + 自己的代码和数据
这整个过程可以想象成你投简历(相对于PCB,里面包含了你的所有信息),面试官(相对于CPU)通过一份份简历来筛选人(即进程 = 自己 + 简历)
例子


我们历史上执行的所有指令,工具,自己的程序,运行起来,全部都是进程
getpid()
系统调用
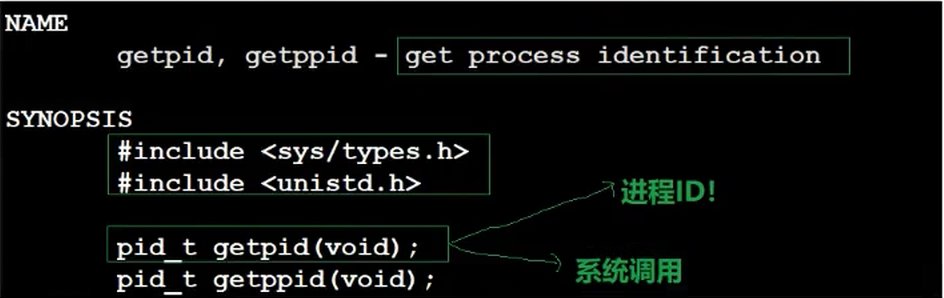

getppid()
获取父进程id
Linux系统所有的进程都是被父进程创建的,一个父进程可以创建多个子进程
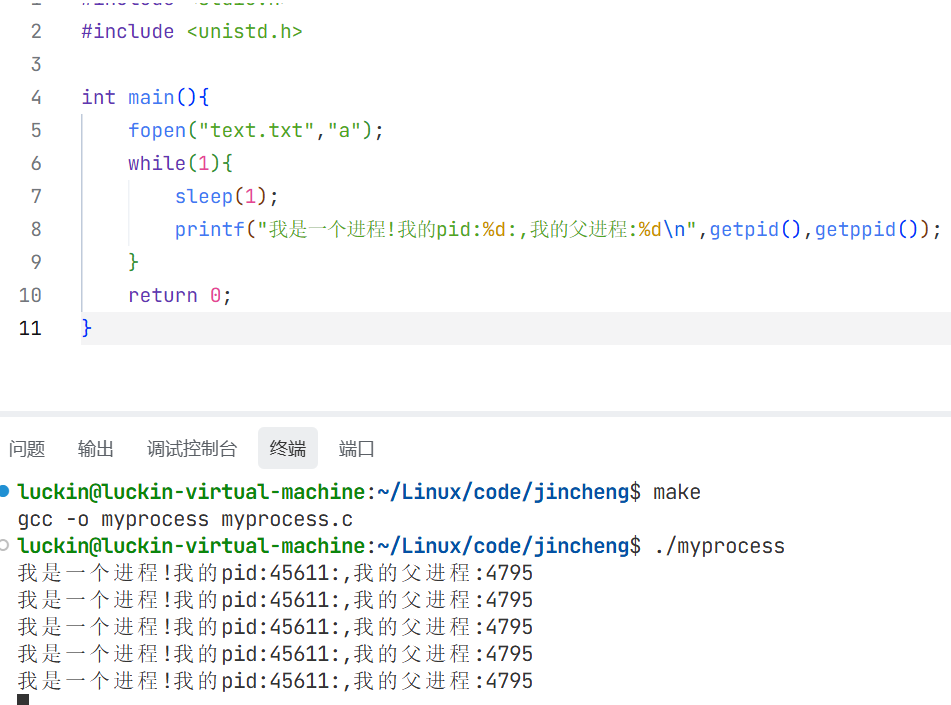
每次启动进程的时候,都会往系统里面加载,所有pid会不同,但父进程id却不变呢?
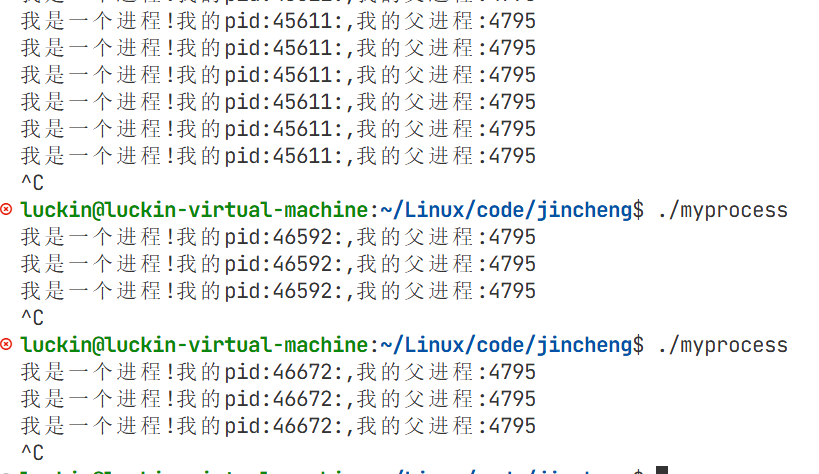
查找该ppid的进程

这里存在一个bash
bash是命令行解释器:本质是一个进程

操作系统会给每一个登陆用户,分配一个bash(命令行输入的所有命令都是喂给了bash,以字符串交给了bash)
ps axj
进程一旦启动,我们可以用ps来进行查询
top
也可以使用top查询
如果你只想看到你刚刚启动的进程

但是你不知道这每一列都是什么意思,可输入命令(ps axj | head -1)

如果你想两个命令一起使用,就可以这样输入


对于这里第二行红色框处进行解释:执行完前面命令后,因为grep自己也是个进程,后面带上了文件关键字,所以每次查询都带上了grep
如果不想看到grep的话,可以进行反向匹配,包含grep的就过滤掉

对于杀死进程,我们比较常用的是ctrl + c,这里我们也可以使用kill -9 + pid值
对于同一个程序,存在不同的pid值是很正常的,Linux系统中对于分配pid的值是通过一个线性递增的整型值在不断递增的
proc
这也是一种查看进程的方法(通过文件的方式查看进程),记录的是当前系统所有进程的详细信息,每一个数字目录代表的就是进程的pid



进程对应的可执行文件(PCB会记录当前可执行文件的绝对路径,这是库的行为)
cwd(current work dir)记录当前可执行文件位置


chdir()
chdir可以修改现有文件的路径


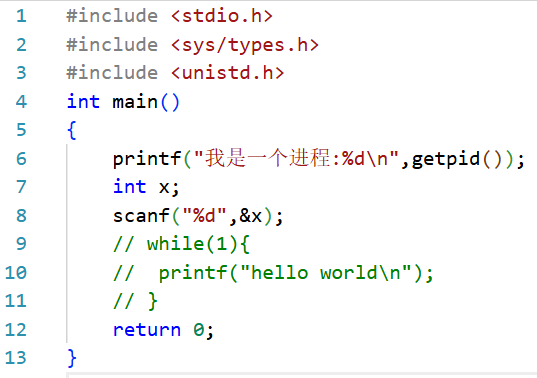
代码创建子进程方式
fork()
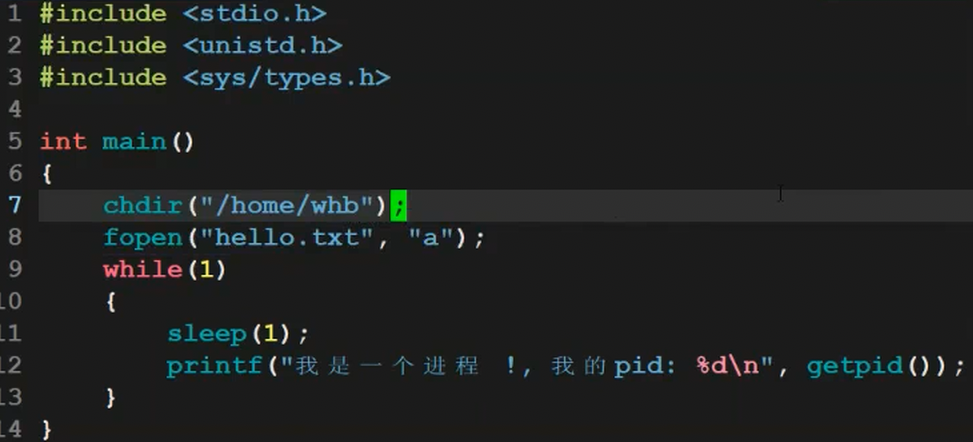
测试代码


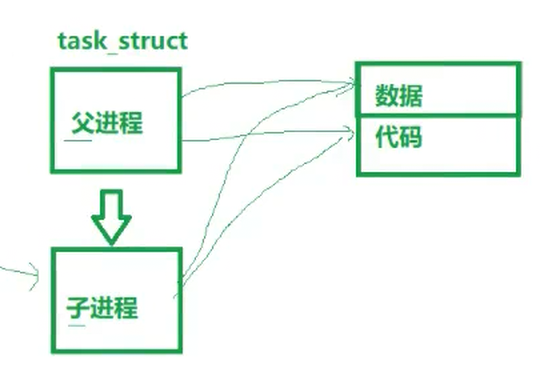
子进程拷贝父进程的PCB,属性基本相似,相同的,父进程PCB指向的数据和代码,子进程也同样指向
调度子进程的时候,子进程就会执行父进程之后的代码
子进程没有自己的代码和数据,因为目前没有程序新加载(暂时)
fork()的返回值

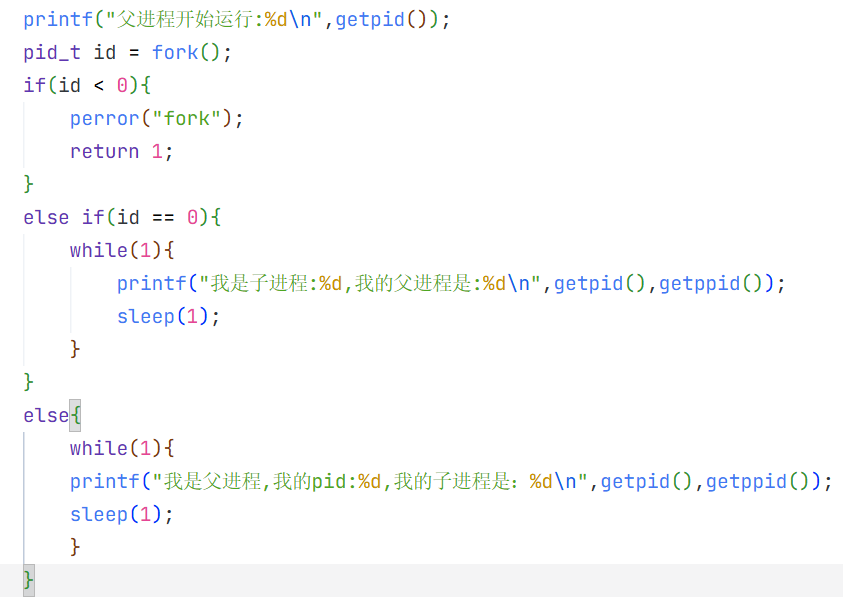


第一个问题即条件成立的话,为什么给子进程返回0,给父进程返回子进程的pid呢?
因为父进程 : 子进程 = 1 :n,所有父进程需要记录每一个子进程的pid以方便管理,而每个子进程只需要记录唯一的父进程,表明自己是否建立即可
第二个问题
一个函数到达return后,核心部分已经执行完了
在fork函数内部父子进程都会执行一次return
返回的本质:在写入变量

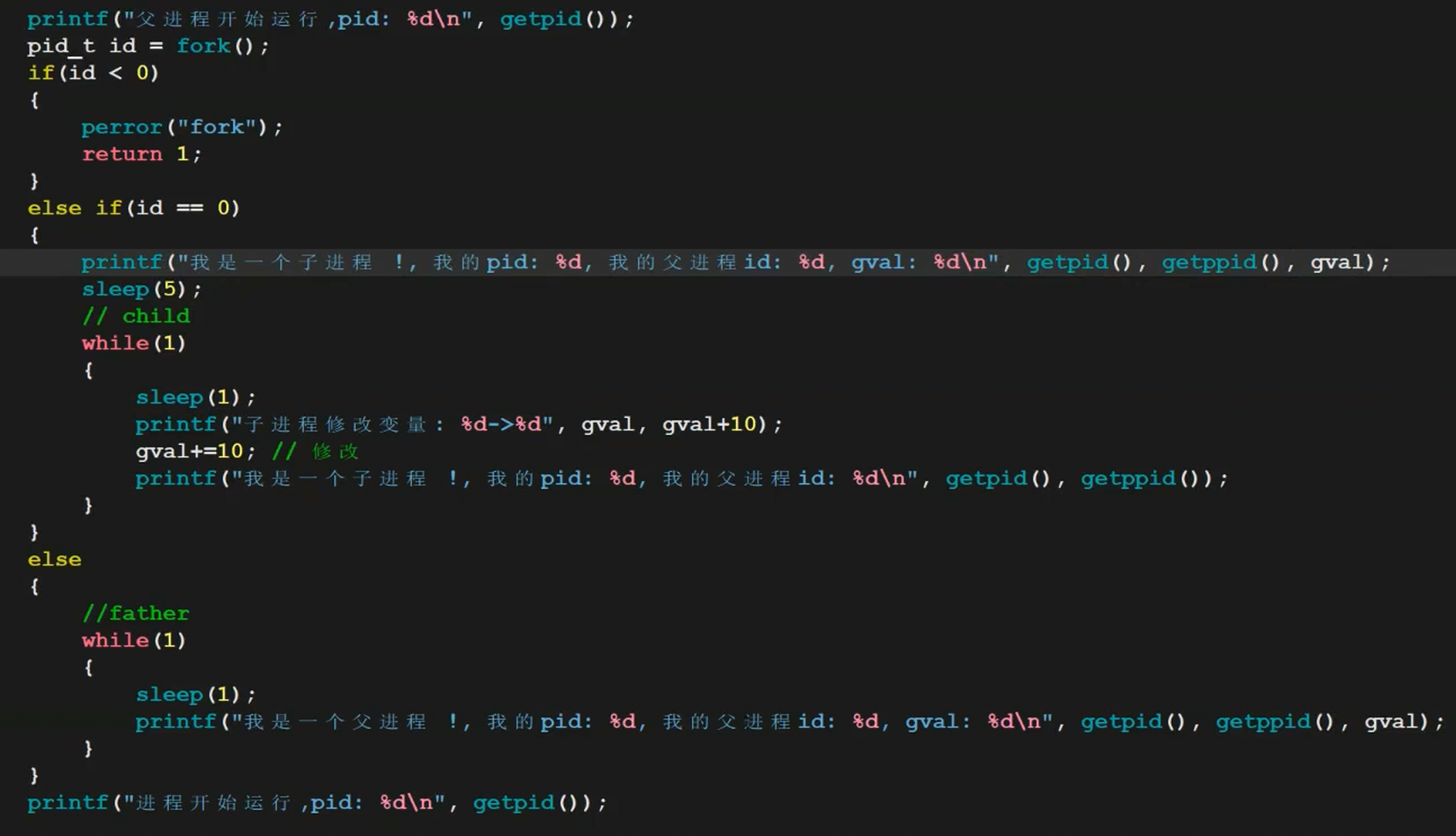
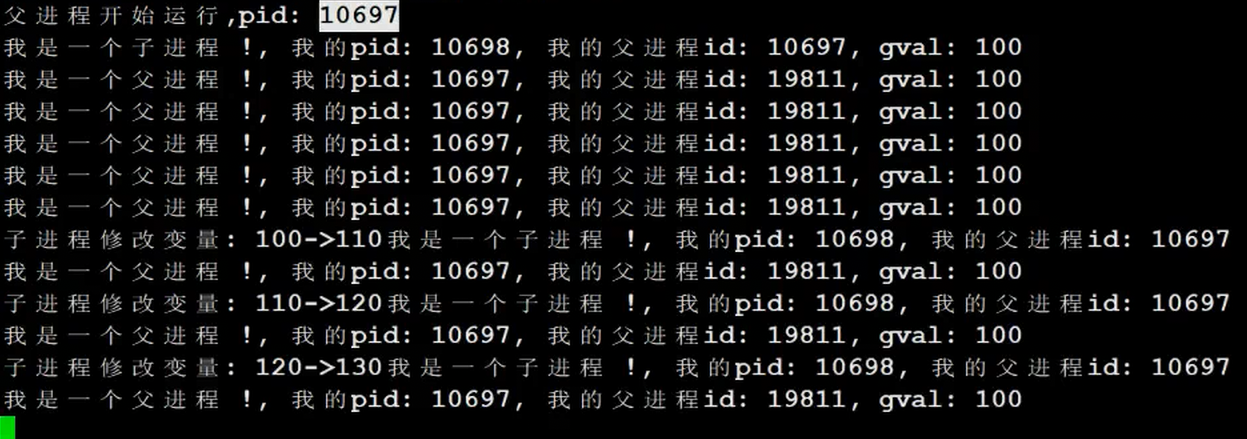
结论:进程具有独立性(一个进程挂了不会影响其他进程)
父子进程任何一方进行修改数据,操作系统把修改的数据在底层拷贝一份,让目标进程修改这个拷贝(这样就会出现两份拷贝,例如父进程使用老的数据,子进程使用新的数据)-------------写时拷贝
进程状态
进程状态属于进程的一个属性
本质是task_struct结构体中的一个整型变量
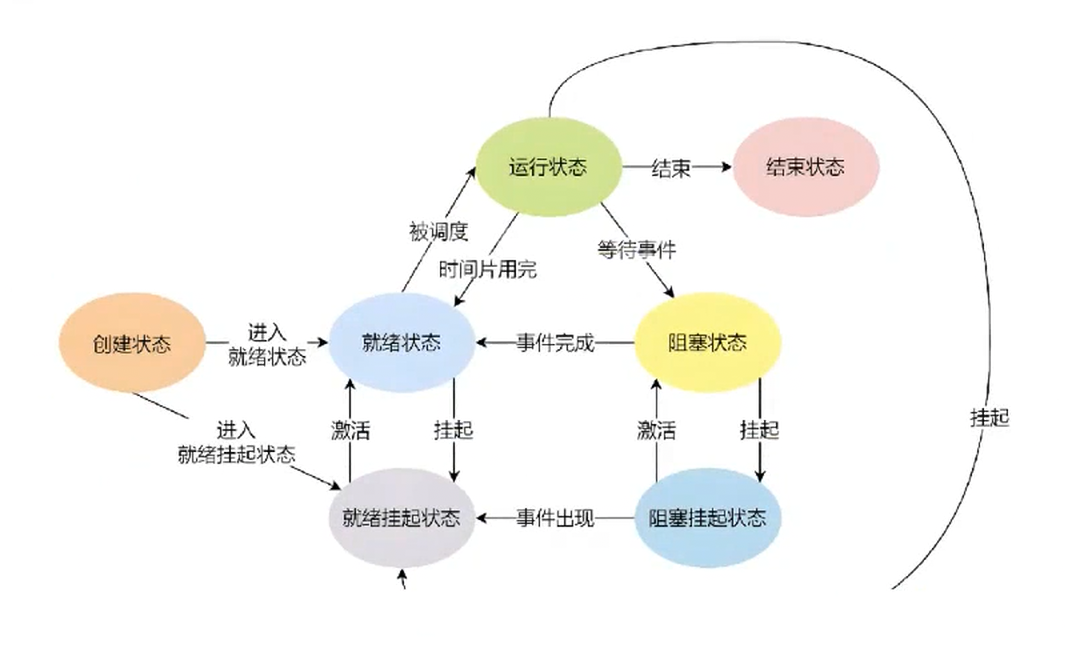
运行&&阻塞&&挂起
一个CPU,一个调度队列
运行:进程只要在调度队列中,状态都是运行的(要么是已经在运行的,要么是准备好随时被调度的)
阻塞:等待某种设备或者资源就绪
操作系统要管理系统中的各种硬件资源-------先描述,在组织
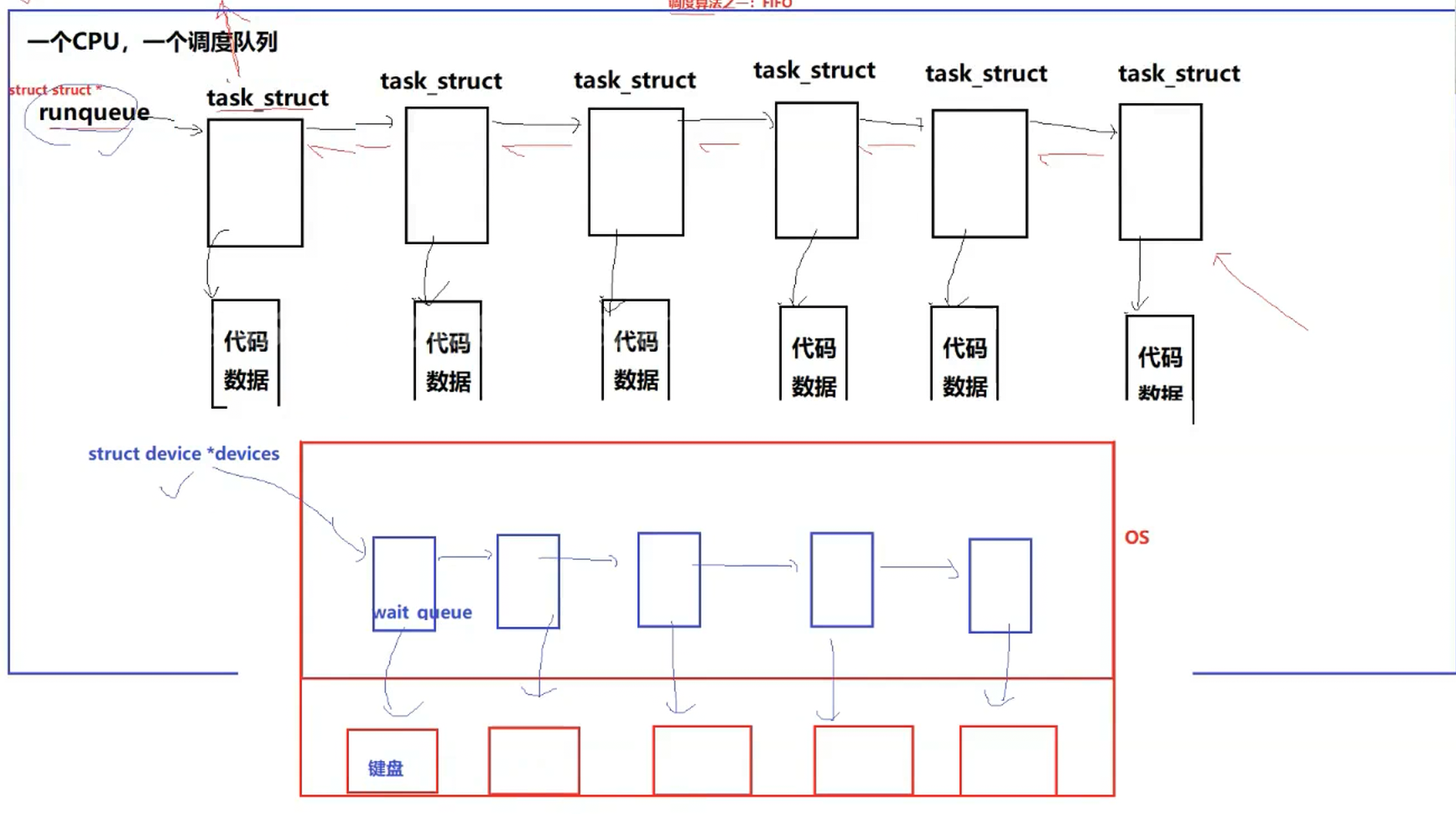
例子:
CPU正好运行一个进程(执行的进程代码发现进程要进行scanf读取),操作系统发现你要读键盘,操作系统就会帮我们去检查键盘的status状态,发现键盘并没有任何按下status的动作(即设备没有活跃),操作系统就发现这个进程无法进行读取键盘的数据,进程就无法执行了,将该进程从CPU上拿下来,从运行队列中移走,将PCB列入到特定设备的等待队列中,一旦将该进程列入到其他队列里,他就不在运行队列中了,也就永远不会被调度,该进程就处于阻塞状态(只有在运行队列中才会被CPU调度)
运行---->阻塞:本质是将进程PCB列入到不同的队列中
当前进程就开始等待这个设备,一旦键盘被按下(进程是不知道的),该行为属于硬件就绪了,操作系统第一时间知道硬件的状态发生了变化,就直接查看对应就绪设备的对应节点,将设备状态设置为活跃的,并检查等待队列,发现队列里指针不为空,就将该等待队列中的头部进程的状态设置为运行状态,任何将该进程重新列回运行队列中,任何后面CPU调度该进程(继续运行scanf),然后将数据从设备上读到进程上下文中,被我们拿到
阻塞----->运行:本质是就是找到PCB,然后将PCB列入到运行队列中
进程状态的变化,表现之一,就是要在不同的队列中进行流动,本质都是数据结构的增删查改
键盘上面可以同时存在很多进程来找他,所以键盘上可以同时存在很多个进程来进行等待,就需要进行排队,如果遇到内存资源紧张的状态下,这批在等待设备响应且处于阻塞状态的进程,其对应的代码和数据就会被从内存唤入到磁盘的swap交换分区中,此时这些进程的阻塞状态为阻塞挂起
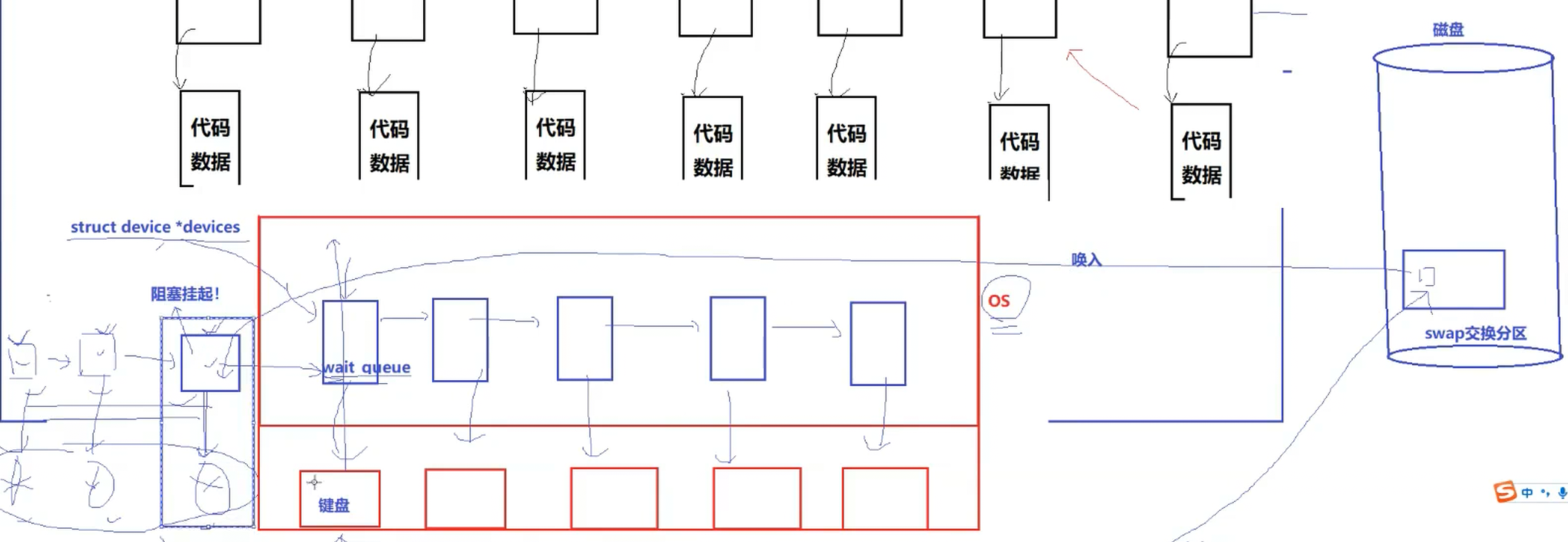
阻塞挂起(将进程的代码数据挂到外设上)------>运行
设备这时候能够响应了,操作系统知道了,操作系统就会将当初被唤出进磁盘中的进程的代码数据重新加载内存,重新构建指针映射,然后将加载到磁盘中的这些代码数据唤入内存形成完成进程,然后再将这些进程放入到运行队列中
再极端的情况下,这些阻塞状态的进程被挂起后依然内存吃紧,操作系统就只能打运行内存中进程的注意了,当前CPU是单CPU,即使是多CPU也不可能同时运行几十个进程,操作系统可能就将处于运行队列末端的进程,按比例将这些进程的代码数据从内存唤出磁盘中的swap交换分区中,为运行挂起
理解内核链表的话题
Linux内核链表

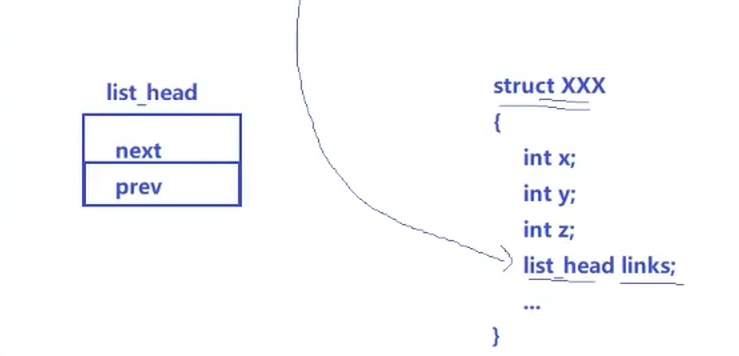
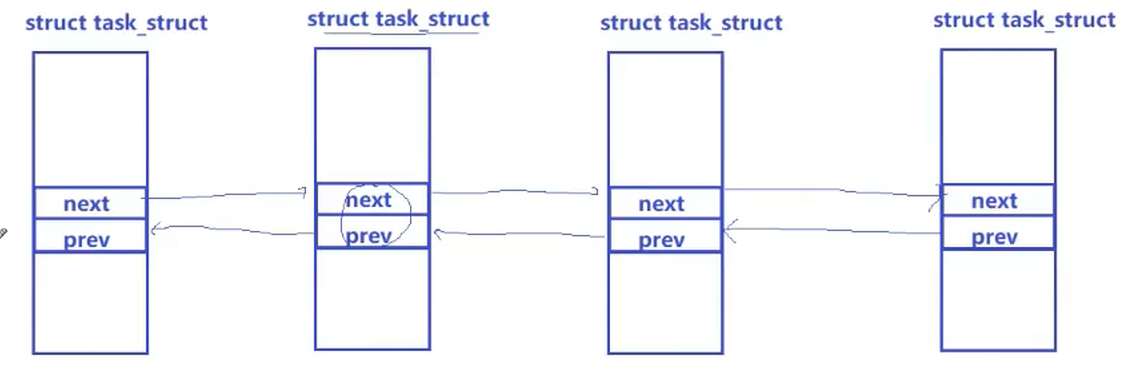
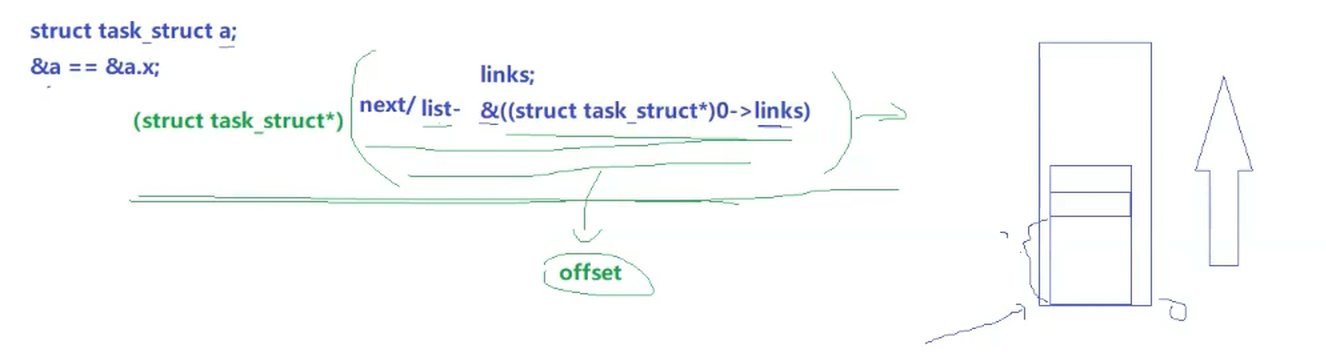
与双链表的next会指向整个node不同,Linux内核中的next只会指向目标结构体内部的某一个成员对象(如links),这样只能访问到next和prev所在区域,其他区域怎么访问呢?

C语言中,结构体变量本身的地址和结构体变量的第一个常量地址在数字上是相同的

结构体中有很多的成员变量,地址排布从上往下以此增大
通过强转类型的方式,计算next/list出的地址与0位置的地址的偏移量来进行访问其他区域
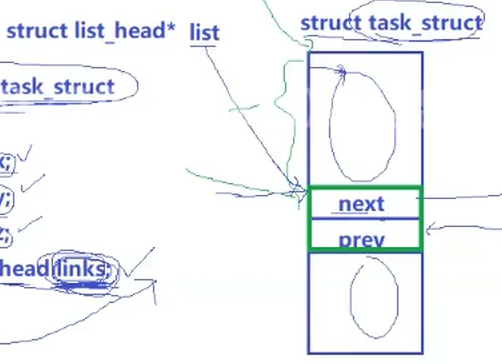
一个进程PCB可以隶属于多种数据结构
Linux的进程状态
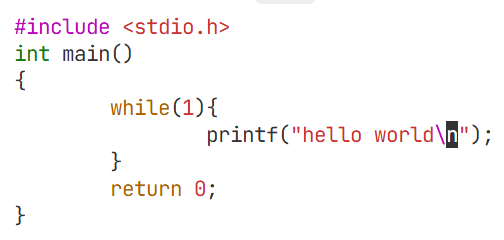

此处状态为S+,是因为printf,进程在执行printf的时候只有很短的时间(例如1ns),可能进程在1s以内只有1ns在执行代码,剩下的时间可能都在监测进程的进程等待IO
代码可能执行的时间很短,大部分时间都在等待,基本都在S状态
如果想要看到R状态,就需要把printf注释掉,少掉IO,就不会等待设备了

将该进程放到后台运行


只有R前面就不存在+号了,表示该进程在后台运行
停止该进程

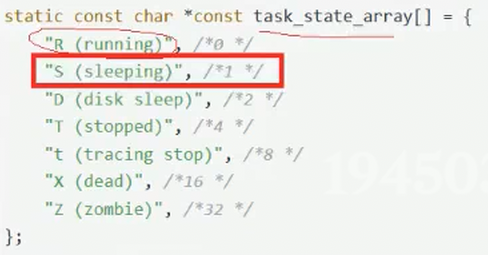
Linux系统中,阻塞状态成为S

暂停状态为T,t
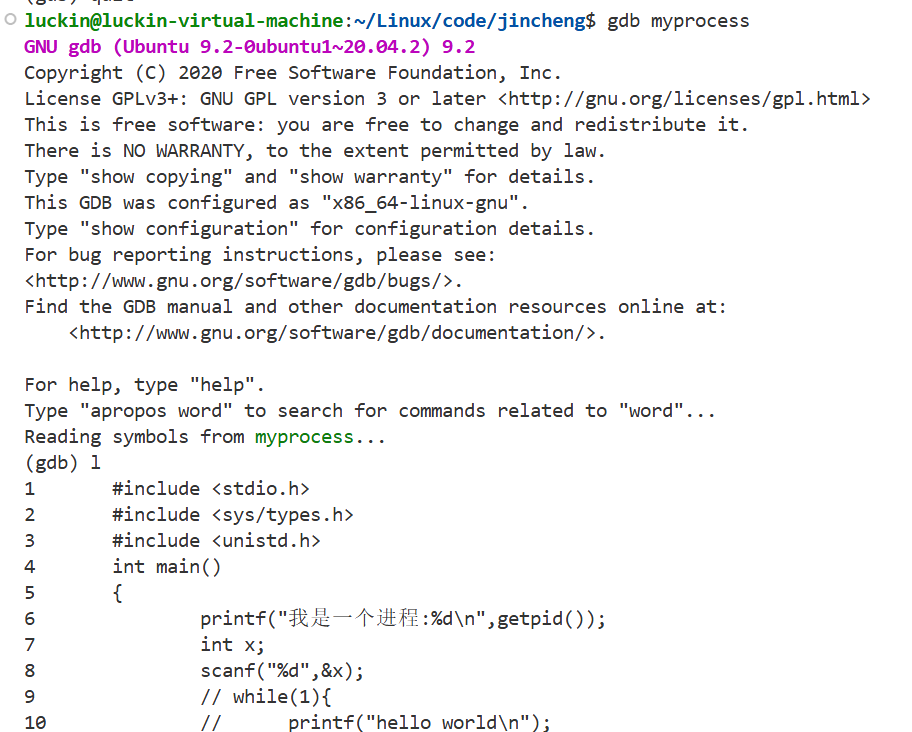

在第7行处打个断点,并且运行,就可以看到进程状态为t(为追踪状态)
因为该进程被debug了,断点使得进程被暂停了

CTRL+Z让进程暂停,呈现T状态

S状态被称为可中断休眠,浅睡眠(Linux下),操作系统称为阻塞
D状态被称为不可中断休眠,深度睡眠,和磁盘有关系,也是阻塞的一种状态
处于D状态中的进程不能被操作系统直接"杀死",防止涉及到向磁盘这种关键数据存储的,进程处于高IO状态的时候,状态设为D而不是S,主要防止该进程丢失进而导致数据丢失的问题

kill -19 是让进程停下来

kill -18是让进程继续跑

僵尸进程

Z状态:在子进程退出之后,父进程获取子进程退出信息之前的状态,这些信息主要存在于子进程的task_struct中
如果父进程一致不管,不回收,不获取子进程的退出信息,那么Z状态就会一直存在,PCB一直被维护,内存一直被占用,就会产生内存泄漏问题
僵尸进程就是内存泄漏
进程退出了,内存泄漏问题还在
常驻内存的进程(软件如操作系统)具有内存泄漏问题是比较麻烦的
关于内核结构申请:
在系统中维护一张存储废弃的task_struct结构体的列表,回收从Z状态变为X状态的task_struct表,当有操作系统来创建进程的时候,就不需要冲new或mallco,从该列表中拿出一个task_struct,将其中的字段的初始化,填入新进程的,就可以支持复用了,实现了一种类似于数据结构对象的缓存
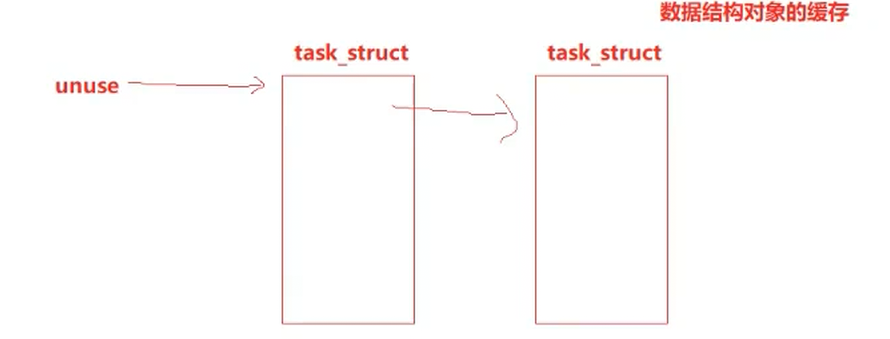
这种技术在Linux内核中被叫做slab
孤儿进程
前面的僵尸进程是因为子进程先挂了,但是父进程还在,子进程的退出信息父进程没有及时去获取,那如果父进程比子进程先挂了呢
以下代码来进行验证


父子进程关系中,如果父进程先退出,子进程要被1号进程领养,这个被领养的进程(子进程),叫做孤儿进程
如果在系统中存在了一百组父子关系,父进程都退出了,1号进程就需要领养这100组子进程
可以理解为就是操作系统,bash就是由其创建的
存在0号进程,但是开机后就被1号进程替换掉了

为什么要领养?
如果子进程不被领养,就会一直处于僵尸状态,在操作系统中,能够处理子进程的就只有操作系统和父进程,进行领养的话,作为父进程就可以将子进程进行回收,不会一直占用内存,导致内存泄漏
孤儿进程被系统领养后,直接就变成了后台进程了

CTRL+c杀不掉后台进程,需使用kill杀死进程
进程优先级
是进程得到CPU资源的先后顺序
对于优先级,是因为目标资源的稀缺,导致要通过优先级确认谁先谁后的问题
优先级:能得到资源,但是存在先后的问题
权限:是否能得到某种资源
优先级可以理解为也是一种数字(int),既然属于进程的一种属性,当然也就会存在于PCB(task_struct)中,值越低,优先级就越高,反之,优先级越低
现在我们所用的大部分操作系统,都被称为基于时间片的分时操作系统(就是对每个进程分配的时间都差不多,如1ns),考虑公平性,优先级可能变化,但是变化幅度不能太大
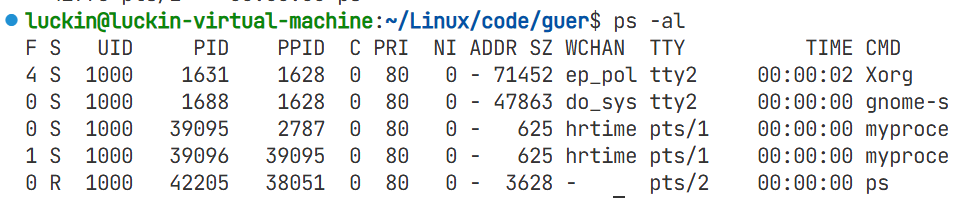
如果要查看特定进程所对应的优先级,带优先级的进程信息所有的为ps -a,详细的为ps -al
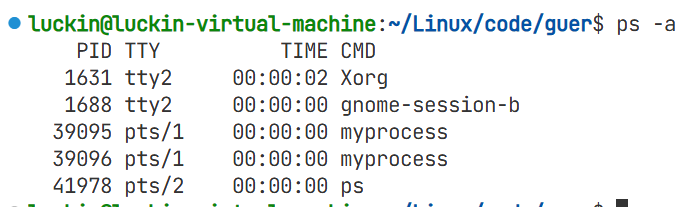

这里的UID:user id
在Linux系统里面,识别我们这个人不是通过名字识别,而是每个名字都有一个用户id,下面是查用户id
进程在进行启动的时候,进程也会将对应的UID保存起来,以辨别这个进程是谁启动的

系统怎么知道我访问的时候,是拥有者,所属组,还是other?
Linux系统中,访问任何资源,都是进程访问,进程就代表用户,所以识别权限,不是识别用户的,是识别进程和文件之前的权限
PRI:进程的优先级,默认为80
NI:进程优先级的修正数据,nice值
进程的真实优先级 = PRI(默认) + NI
输入r,就会进入重新调节优先级
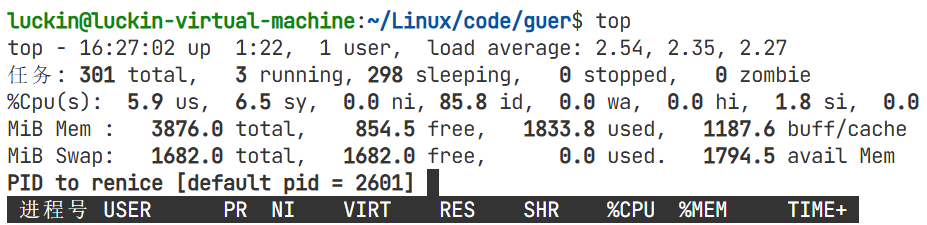


重新进入调节优先级,改成-10

也就是说Linux进程每次做调整的时候,都是从80开始调整的,不需要管历史你调整的值

优先级的极值问题
改多了普通用户权限不足,需要切到root用户进行修改



可得到nice的范围为【-20,19】
Linux进程的优先级范围为【60,99】
优先级设立不合理,会导致优先级低的进程,长时间得不到CPU资源,进而导致进程饥饿
竞争、独立、并行、并发
在系统当中会存在多进程

此处为两个CPU
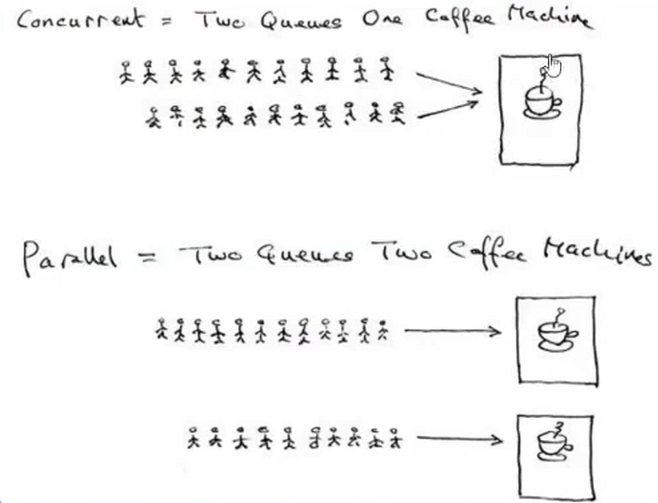
上面的图就是并发,下面是并行
并行就是任何时刻都有多个进程在同时跑(如果有两个CPU的话,就有可能有两个进程在同时在两个CPU上跑)
并发就是在一段时间之内,让多个进程都得以推进,单核CPU像任务管理器中有多个进程在跑,其实是一种错觉,任何时刻,只有一个进程在运行,但是在多个进程在一个CPU下采用进程切换的方式(比如今天有两个进程,让一个进程上来10ms,然后不让他运行,再切另外一个进程上来10ms,来回切换,只要切换的速度足够快,用户就感觉不到)
进程切换
a.一旦一个进程占有CPU,会把自己的代码跑完吗?(比如while循环,系统会卡但是不会卡死) 不会,除非你的代码只有一两行,在一个时间片就能够跑完,我们的每一个进程,系统都会给他分配一个时间片的东西
根据时间片来进行运行,就不会产生一个进程死占CPU的情况
b.死循环进程,不会打死系统,不会一直占有CPU
CPU中会存在很多寄存器,起着临时保存数据的任务,保存当前进程的临时数据
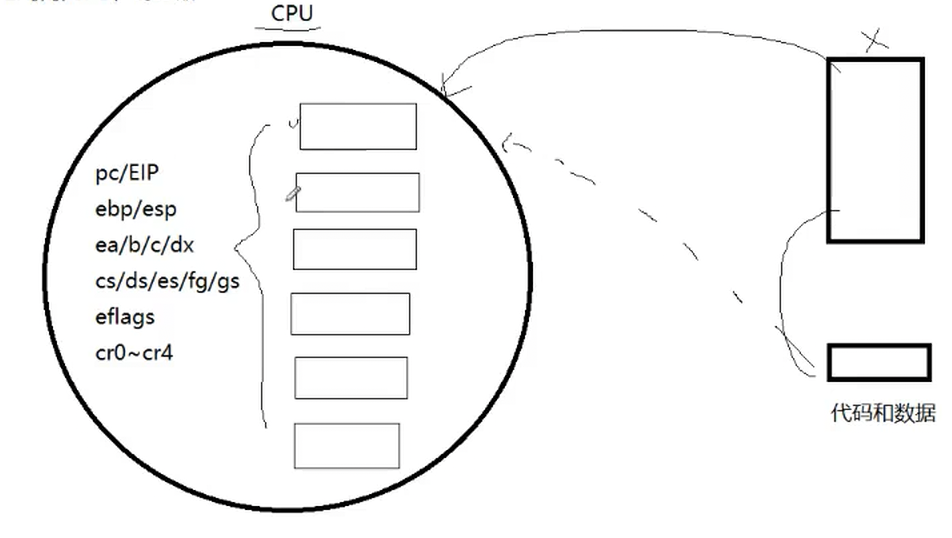
在我们CPU内部存在一个pc指针,他里面会保存当前指令下一条指令的地址,比如我当前正在执行0x1,将这个指令读取进来,执行完,pc指针自动更新到下一条,这是CPU自动帮我们去获取的
结论:
1.寄存器就是CPU内部的临时空间(比如要执行1+1=2,就需要1,1,add,2)
2.寄存器(空间) != 寄存器里面的数据(内容)
空间永远只有一份,内容是变化的、多份的
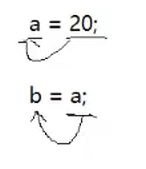
这两个是不一样,第一个是将20放入到a的空间里,第二个是把a的内容放给b
所以上面的a为左值,下面的a为右值
举个例子来进行理解进程切换(当兵):
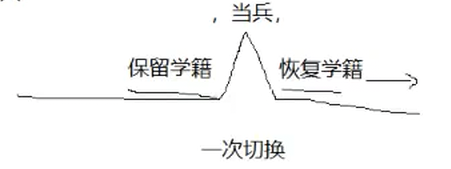
去当兵之前我们需要在学校找到辅导员保留学籍,然后学校就会让辅导员拿给我们一个档案袋来保留我们的学籍,当完兵回来以后需要找到辅导员恢复学籍,对应于进程切换这个过程
学校----CPU
辅导员-----调度器
你-----进程
学籍------进程运行的临时数据,CPU内寄存器里面的内容(当前进程的上下文数据)
保留学籍-----保存进程上下文数据,CPU内寄存器里面的内容,保存起来
恢复学籍-----恢复进程上下文数据,保存起来,恢复到CPU内寄存器里
去当兵------进程被从CPU剥离下来
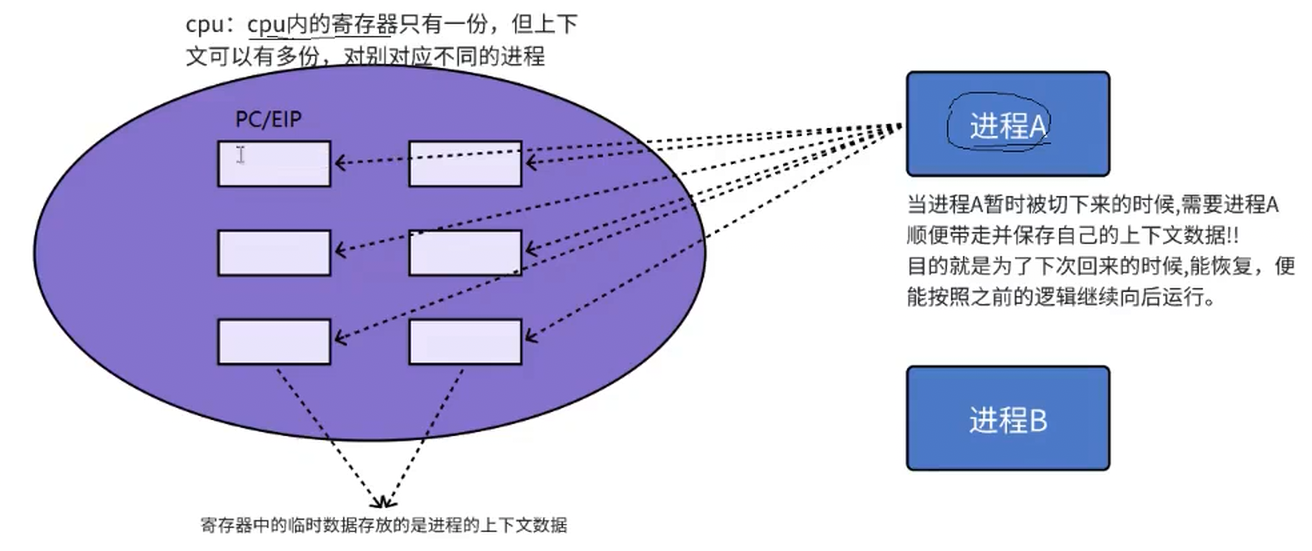

由于时间片的原因,进程A在被切走的时候,需要将寄存器内的值进行拷贝保存起来,再把当前进程A切走,放到运行队列重新进行排队,换上进程B后,对寄存器中之前进程A的数据进行覆盖,当时间片到了,进程B被切走的时候,进行与进程A相同的步骤,再把进程A拿回来,不能直接跑(我们也做不到),我们需要将之前保存的进程历史上下文数据对应地重新恢复寄存器内,这样就可以在历史的位置继续运行了
进程切换最核心的,就是保存和恢复当前进程的硬件上下文的数据,即CPU内寄存器的内容
1.当前进程要把自己的进程硬件上下文数据保存起来,保存到哪里了呢?
保存到了进程的task_struct里面了
可以通过task_struct找到TSS(任务状态段)
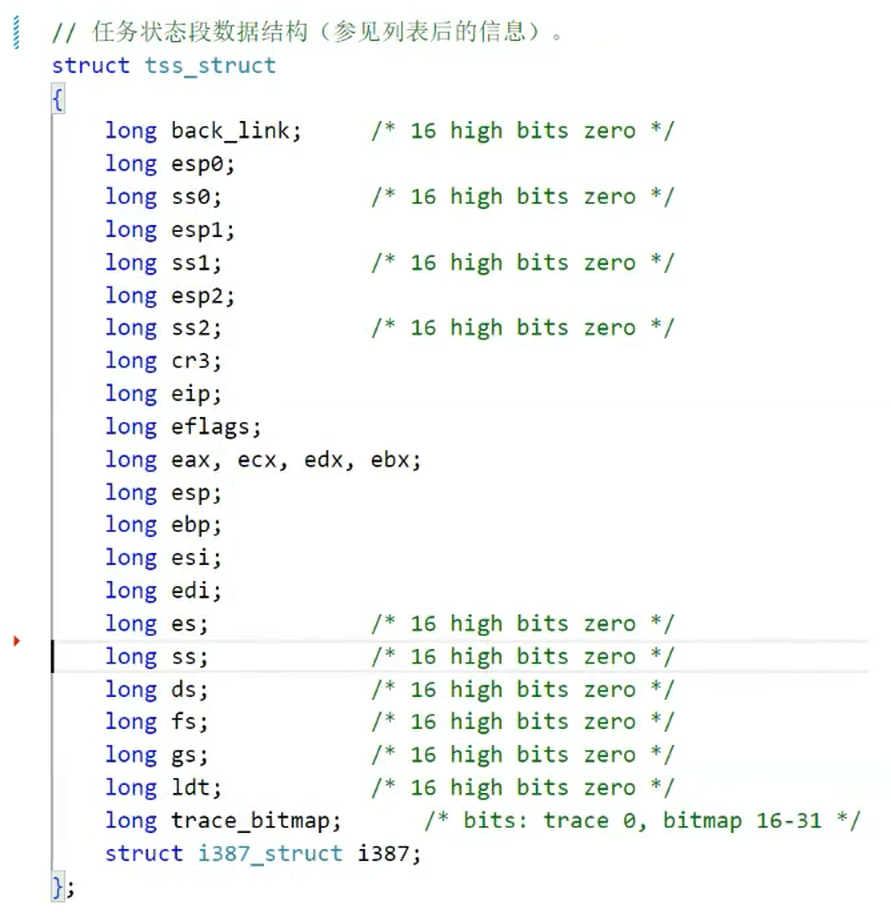
任务状态段就是进程的硬件上下文
2.全新的进程 vs 已经调度过的进程
可以在task_struct里新增一个标记位int isrunning,布尔类型,当你这个进程刚开始准备第一次运行时,就为0,开始第一次调度后就置为1,从此以后都为1,所以CPU调度器很容易区分出来
tips:操作系统中存在一个全局的指针struct task_struct * current,他永远会指向当前进程,当进程在调度的时候,选择好进程了,他就把当前的进程的task_struct地址填到这个指针里面,往后在调度进程的时候,直接挑这个指针所指向的进程就可以了,比如一些架构arm,可能会把这个指针直接放到寄存器内部,为了加速他找对应的进程

Linux真实调度算法
O(1)调度算法
一个CPU一个"运行队列"
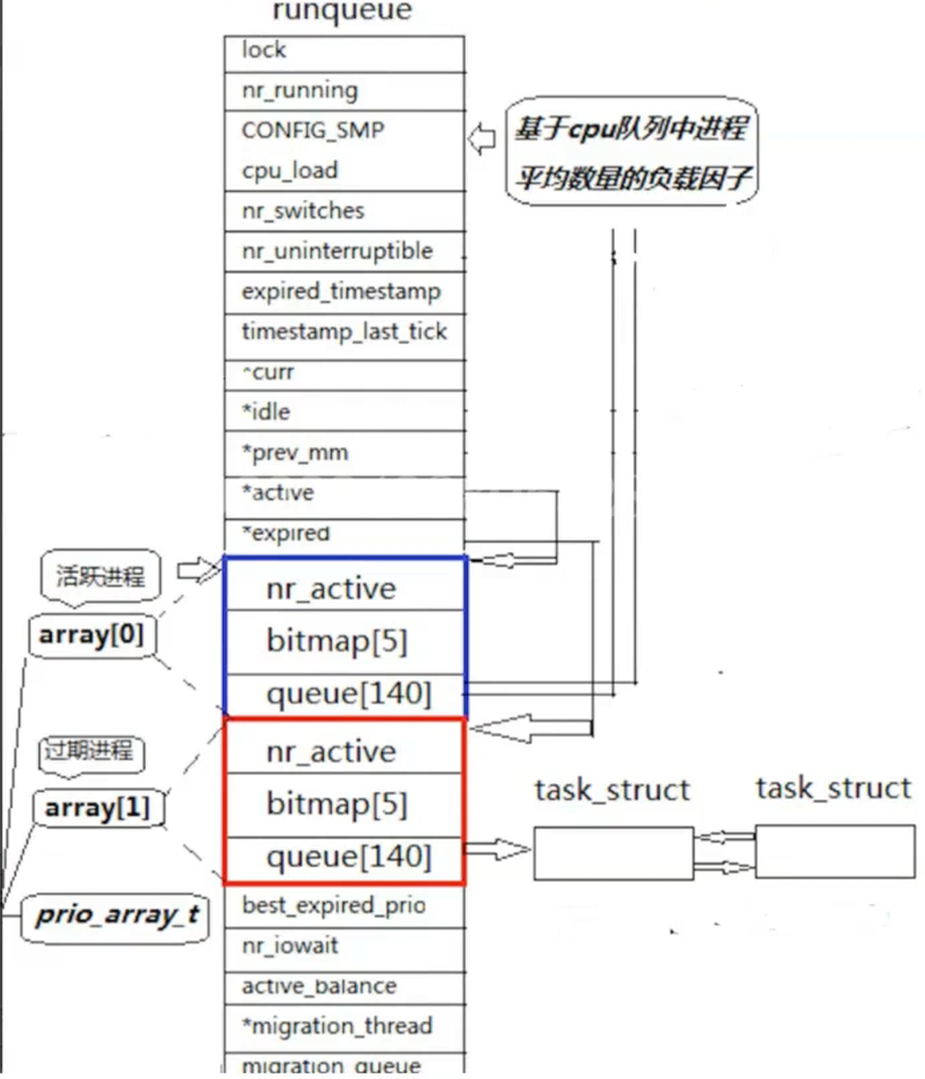
Linux的优先级140个
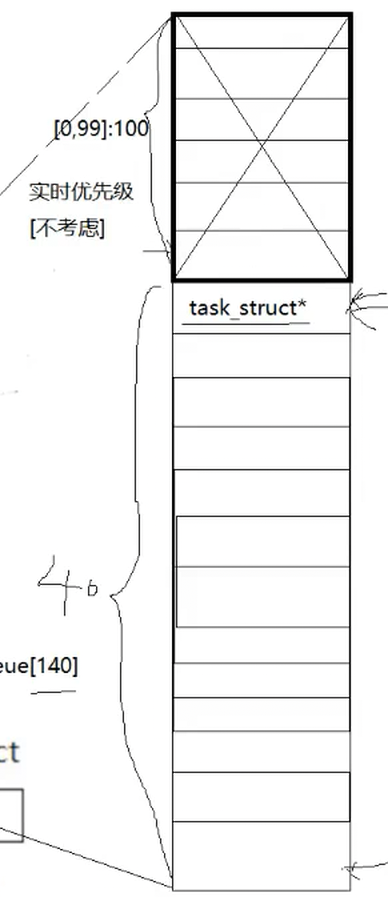
40个队列中保留的都task_struct*,优先级相等的进程,即可以列入同一个优先级下标下,宏观上先看优先级,优先级相同的先进先出
这个表的本质就是哈希表

调度器如何快速地挑选一个进程呢?
1.挑队列(直接查看位图) 2.挑进程
时间复杂度O(1)
队列中存在一个位图

比特位地内容:1/0,是否为空
160>140,多出来的20队列不需要用到

为整个队列中由多少个进程
如果优先级为60处中的一个进程运行完,下次还要被调度,就需要回到原先队列的末尾处进行排队等待,如果单纯是这样的话,那CPU在调度时,永远都是需要前面的进程调度完才能到下一个队列,如果前面的进程进入死循环,后面的99队列就别想运行了,造成饥饿问题,为了解决这个问题,就需要再分出一个与之前runqueue一模一样地队列

这样就会有如下情况

在局部保证了后来进程的权益,被调度过的进程被调到expired queue中
当active queue中的进程全都被调度完了,直接与expired queue进行swap,重复调度

这样就完成了O(1)调度算法
来一个新进程,放入active queue中

查负载,放入负载最低的队列中
实时操作系统:一旦来了一个进程,那么这个进程就必须立马响应,就必须要处理完,才能处理下一个进程,比分时操作系统的调度算法简单(新能源汽车刹车)
分时操作系统-----内核优先级抢占(时间片)
多一个nice值修改进程优先级的原因:如果只有一个PRI,随便修改的话,如果该进程再active queue,就需要对整个队列进行修改,如果多了NI进行修改进程的优先级的话,就可以等到进程调度完后到empired queue中再修改优先级等下次调度