1.前言:为什么需要 Skills ?
我们最初是通过编写提示词来驱动大模型工作的,但这一过程中会存在大量重复的提示词。于是,我们尝试将这些重复内容抽离到项目规则或用户规则中。然而,这种做法又导致提示词整体过大,使大模型的注意力分散,甚至部分提示词因压缩而丢失。
为了解决这一问题,Anthropic 公司提出了 Skills 的概念。其核心思路是:将重复的提示词封装到独立的 SKILL.md 文件中。从编程视角来看,这类似于把重复的功能代码封装成公共函数或类,并实现按需加载,同时有效节省 tokens。
2. Skills 系统的实现原理
一个 SKILL.md 文件的结构如下:
yaml
---
name: Skill 名称
description: 描述
---
正文其中以 YAML 格式定义的部分称为元数据 ,它始终会被加载,包含 name(名称)和 description(描述)两个字段。而正文部分则在 Skill 被触发时才加载。
name 和 description 是 Skill 声明文件中的必填字段。从工具(Tool)的定义角度来看,name 相当于工具名称,description 相当于工具描述。
所以无论是 MCP 还是 Skills,都可以转换成大模型调用工具的方式进行执行:通过 description 让大模型判断应该调用哪个 Skill,然后加载对应的 SKILL.md 文件内容提供给大模型,如同执行一个工具函数并获取结果返回给大模型。
需要注意的是 Skills 并不一定要注册为 tools,更常见的做法是:在系统提示词中直接拼接各个 Skills 的 name 和 description 来告知大模型当前可用的 Skills。这样大模型就可以根据 description 决定使用哪个 Skill,然后再根据 name 或者路径加载具体的 Skill 文件内容。一个典型的包含 Skills 的系统提示词片段如下:
xml
# 技能
以下技能可扩展你的能力。如果要使用某项技能,请使用 read_file 工具读取其 SKILL.md 文件。
<skills>
<skill>
<name>Skill名称</name>
<description>描述</description>
<location>路径</location>
</skill>
<skill>
<name>Skill名称</name>
<description>描述</description>
<location>路径</location>
</skill>
</skills>一般通过系统提示词说明都有哪些 Skills,以及怎么加载完整的 Skill 文件。
基于上述机制,有人将 Skills 的本质总结为 "Skills 只是一段 prompt" 。我个人也认同这一观点。那么 Skills 中附带的可执行脚本(如 Python、Shell 等脚本)又如何理解呢?实际上,这些脚本最终也会被处理成适当的 prompt 形式嵌入 SKILL.md 文件中,再由大模型决定如何执行,通常是通过 bash 去执行。这样一来,Skills 就能捆绑大量信息,而不会额外增加上下文,因为这些脚本并不会加载到上下文中。
当然,不同 AI Agent 的具体 Skills 系统实现各有差异,就像不同浏览器对 W3C 标准的支持也并不完全一致一样。理解这一特性后,你就可以使用任何编程语言来开发自己的 AI Agent 的 Skills 系统了。
接下来我们就实现一个 Agent Skills 系统,进一步了解具体的实现。
3. Skills 加载机制
Skills 加载机制负责在 Agent 启动或运行时,从指定工作区中发现可用技能、解析其元数据,并生成可供上层使用的技能摘要。本节将通过实现一个 SkillsLoader 类来详细说明其核心流程。
python
import re
from pathlib import Path
class SkillsLoader:
"""
技能加载器,负责从工作区中发现、加载和解析技能文件(SKILL.md)。
技能目录约定:
workspace/skills/<技能名称>/SKILL.md
"""
def __init__(self, workspace: Path):
"""
初始化技能加载器。
Args:
workspace: 工作区根目录路径,技能将位于 workspace/skills/ 下
"""
self.workspace = workspace
# 拼接出技能根目录的路径
self.workspace_skills = workspace / "skills"初步实现一个 SkillsLoader 类,并约定技能目录路径为 workspace/skills/<技能名称>/SKILL.md。
3.1 技能发现
技能发现的目标是定位工作区中所有符合规范的技能目录,并返回技能的基本信息。我们通过 list_skills 方法实现了这一功能:
python
import re
from pathlib import Path
class SkillsLoader:
# 省略...
def list_skills(self) -> list[dict[str, str]]:
"""
发现工作区中所有可用的技能。
遍历技能根目录下的每个子文件夹,检查是否存在 SKILL.md 文件。
Returns:
技能信息列表,每个元素为字典,包含:
- name: 技能名称(文件夹名)
- path: SKILL.md 文件的绝对路径
- source: 技能来源(固定为 "workspace")
"""
skills = []
# 仅当技能根目录存在时才进行遍历
if self.workspace_skills.exists():
for skill_dir in self.workspace_skills.iterdir():
# 只处理文件夹,忽略文件
if skill_dir.is_dir():
skill_file = skill_dir / "SKILL.md"
# 只收集存在 SKILL.md 的文件夹
if skill_file.exists():
skills.append({
"name": skill_dir.name,
"path": str(skill_file),
"source": "workspace"
})
return skills设计要点:
- 约定优于配置 :每个技能必须位于
workspace/skills/目录下,且技能文件夹内必须包含SKILL.md文件。这种约定降低了配置成本,使技能可被自动发现。 - 路径与来源标记 :返回的字典包含技能名称(即文件夹名)、完整文件路径以及来源标识(
workspace),为后续加载和摘要构建提供必要信息。未来可扩展支持多个来源(如内置技能、远程仓库等)。
3.2 元数据解析
每个技能的 SKILL.md 文件必须通过 YAML 格式声明技能的元数据(如名称、描述)。我们通过 get_skill_metadata 方法负责提取这些信息:
python
class SkillsLoader:
# 省略...
def load_skill(self, name: str) -> str | None:
"""
加载指定技能的原始内容(SKILL.md 全文)。
Args:
name: 技能名称(即技能文件夹名)
Returns:
技能文件的文本内容(UTF-8 编码),若文件不存在则返回 None
"""
workspace_skill = self.workspace_skills / name / "SKILL.md"
if workspace_skill.exists():
return workspace_skill.read_text(encoding="utf-8")
return None
def get_skill_metadata(self, name: str) -> dict | None:
"""
从技能的 SKILL.md 中提取 YAML Front Matter 元数据。
约定 Front Matter 格式:
---
key1: value1
key2: "value2"
---
Args:
name: 技能名称
Returns:
元数据字典,例如 {"description": "某个技能", "version": "1.0"};
若文件不存在或没有有效 Front Matter 则返回 None。
"""
content = self.load_skill(name)
if not content:
return None
# 检查文件是否以 "---\n" 开头,表示存在 Front Matter
if content.startswith("---"):
# 使用正则匹配最外层的一对 --- ... ---
# re.DOTALL 使 . 也能匹配换行符,从而捕获多行元数据块
match = re.match(r"^---\n(.*?)\n---", content, re.DOTALL)
if match:
# 提取元数据块中的每一行,进行简易的键值对解析
metadata = {}
for line in match.group(1).split("\n"):
# 只处理包含冒号的行(忽略空行或注释行)
if ":" in line:
key, value = line.split(":", 1) # 仅按第一个冒号分割
# 去除键和值两端的空白字符,并去掉值两端的引号(单/双引号)
metadata[key.strip()] = value.strip().strip('"\'')
return metadata
return None实现原理很简单就加载指定技能的原始内容(SKILL.md 全文),然后解析元数据,返回元数据字典,例如 {"name": "技能名称","description": "某个技能"}。
3.3 技能摘要构建
为了让 Agent 或用户快速了解当前可用的技能集合,我们通过 build_skills_summary 方法将所有技能的元数据聚合为一个结构化的 XML 字符串:
python
class SkillsLoader:
# 省略...
def build_skills_summary(self) -> str:
"""
构建所有技能的摘要信息,以 XML 格式返回。
摘要包含每个技能的名称、描述和文件位置,便于 LLM 或外部系统解析。
Returns:
XML 格式的技能摘要字符串,若无任何技能则返回空字符串。
"""
all_skills = self.list_skills()
if not all_skills:
return ""
lines = ["<skills>"]
for s in all_skills:
name = s["name"]
path = s["path"]
# 获取该技能的元数据(描述等)
meta = self.get_skill_metadata(name)
# 假设元数据必然存在且包含 description 字段
desc = meta["description"]
lines.append(f" <skill>")
lines.append(f" <name>{name}</name>")
lines.append(f" <description>{desc}</description>")
lines.append(f" <location>{path}</location>")
lines.append(f" </skill>")
lines.append("</skills>")
return "\n".join(lines)这样我们就可以通过 build_skills_summary() 方法生成如下的 XML 结构:
xml
<skills>
<skill>
<name>technical-article-writer</name>
<description>当用户请求撰写技术文章时使用...</description>
<location>/path/to/skills/technical-article-writer/SKILL.md</location>
</skill>
<skill>
<name>frontend-code-review</name>
<description>系统性的前端代码审查规范...</description>
<location>/path/to/skills/frontend-code-review/SKILL.md</location>
</skill>
</skills>为什么用 XML 而不是 JSON 或纯文本?
因为 XML 的标签语义对 LLM 极其友好------<name>、<description>、<location> 的语义无需解释,LLM 能直接理解每个字段的含义和用途。这是一种面向 LLM 优化的数据格式。
至此我们就实现了 Skills 的加载机制,接下来我们接入我们前面实现 AI Agent 系统,进一步验证我们 Skills 的加载器。
4. 集成 AI Agent 系统
4.1 AI Agent 系统回顾
通过前面文章的学习,我们对 AI Agent 系统的集成应该是驾轻就熟了,首先一个简单 AI Agent 系统如下:
python
import os
import json
from pathlib import Path
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量(如 DEEPSEEK_API_KEY)
load_dotenv()
# ---------- 工具定义 ----------
tools = [
{
"type": "function",
"function": {
"name": "read_file",
"description": "读取文本文件内容。",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "要读取的文件路径"},
"encoding": {"type": "string", "enum": ["utf-8", "gbk"], "description": "文件编码格式"}
},
"required": ["path"]
}
}
}
]
# ---------- 工具实现 ----------
class ReadFileTool:
def execute(self, path: str, encoding: str = "utf-8") -> str:
try:
file_path = Path(path).expanduser()
if not file_path.exists():
return f"❌ 文件不存在: {path}"
return file_path.read_text(encoding=encoding)
except Exception as e:
return f"❌ 读取失败: {str(e)}"
file_tool = ReadFileTool()
# ---------- 初始化客户端 ----------
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
SYSTEM = "你是一个AI助手,必要时可以调用 read_file 工具帮助用户读取文件内容。"
MODEL = "deepseek-chat"
def agent_loop(messages: list):
while True:
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tools,
tool_choice="auto"
)
msg = response.choices[0].message
# 添加助手的回复
messages.append(msg)
# 如果模型没有调用工具,说明已完成任务
if not msg.tool_calls:
return msg.content
# 否则,执行每个工具调用并收集结果
for tool_call in msg.tool_calls:
if tool_call.function.name == "read_file":
args = json.loads(tool_call.function.arguments)
print(f"\033[33m🔧 调用工具: {tool_call.function.name}, 参数: {args}\033[0m")
result = file_tool.execute(**args)
print(f"✅ 工具执行结果:\n{result[:200]}\n")
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call.function.name,
"content": result
})
if __name__ == "__main__":
history = [
{"role": "system", "content": SYSTEM}
]
while True:
try:
query = input("\033[36m用户 >> \033[0m")
except (EOFError, KeyboardInterrupt):
break
if query.strip().lower() in ("q", "exit", ""):
break
history.append({"role": "user", "content": query})
final_answer = agent_loop(history)
if final_answer:
print(f"\033[32m助手: {final_answer}\033[0m\n")上述 AI Agent 系统也是我们所有的文章所用到的基础代码,后续我们所讲的内容也都将在此基础上进行拓展。
跟前面实现 MCP 系统相比, Skill 系统与 Agent 集成非常的简单,只需要在启动对话前,系统将 Skills 目录注入到系统提示中即可。
4.2 系统提示注入 Skills 目录
在启动对话前,将 Skills 目录注入到系统提示中:
python
workspace = Path.cwd()
skills = SkillsLoader(workspace)
skills_summary = skills.build_skills_summary()
SYSTEM = f"""你是一个AI助手,必要时可以调用工具帮助用户读取文件内容以及使用以下Skills能力。
Skills:
以下技能可扩展你的能力。要使用某项技能,请使用 read_file 工具阅读其 SKILL.md 文件。
{skills_summary}
"""通过上述操作就完成了技能"目录"的注入。此时大模型就可以知道:
- 有哪些技能可用(名称 + 描述)
- 每个技能文档在哪里(路径)
- 如何获取技能详情(使用
read_file工具)
但大模型还不知道每个技能的具体内容------这就是懒加载设计的核心。其中关键指令是 "要使用某项技能,请使用 read_file 工具阅读其 SKILL.md 文件" ,这让大模型明白不需要特殊的"加载技能"工具,只需复用已有的 read_file 能力进行一次常规的文件读取操作即可。
read_file 工具同时承担"通用文件读取"和"技能加载器"两个角色,这种设计大幅降低了系统复杂度:无需为每个技能单独定义工具,所有技能共享同一个加载通道。
至此,我们就可以更加清晰地知道所谓 Agent Skills 系统的实现原理了。大模型通过调用 read_file 读取某个 SKILL.md 并把技能内容追加为 tool 角色的消息,这样模型在下一次生成时会看到完整的技能正文,从而按照其中的指示执行后续的操作。
4.3 与普通 Function Calling 的关系
Function Calling 让 LLM 能够调用外部 API/函数,本质是动作执行 。Agent Skills 则是一种元模式:将"技能本身"也视为通过函数调用加载的外部资源。
更妙的是,两者可以混合使用:
- 技能
SKILL.md的内容中,可以描述"如果遇到 X 情况,请调用write_file工具"。 - 于是,Agent 先通过
read_file加载技能,再根据技能指令调用其他工具。
这种嵌套使得单个技能可以编排复杂的多步操作,而无需在 Agent 核心代码中硬编码任何流程。
5. 最佳实践
一个好的 SKILL.md 应包含:
markdown
---
name: skill-name
description: [触发条件] + [能做什么] + [触发关键词]
---
# 技能名称
## 概述
简要说明技能的用途和适用范围
## 触发条件
明确列出何时使用此技能
## 工作流程
1. 步骤一
2. 步骤二
## 规范和约束
- 必须遵守的规则
- 禁止的行为
## 示例
具体的输入/输出示例基于上述 Skill 的最佳实践,我们编写一个 Skill 来测试我们上面所实现的 Agent Skills 系统。示例如下:
yaml
---
name: agent-skills-test
description: 当用户说"测试 Agent Skills 系统"时使用此技能,通过 read_file 工具读取系统文件,验证系统完整性。
---
# Agent Skills 完整性测试
## 概述
使用 `read_file` 读取系统关键文件,验证 Agent Skills 系统是否正常工作。
## 触发条件
用户说"测试 Agent Skills 系统"。
## 工作流程
1. 用 `read_file` 读取 `skills/skills.py`,确认 `SkillsLoader` 类存在
2. 用 `read_file` 读取 `skills/agent-loop.py`,确认 `agent_loop` 函数存在
3. 输出验证报告
## 规范和约束
- 只允许使用 `read_file` 工具
## 示例
**输入:** "测试 Agent Skills 系统"
**输出:**
`
✅ skills.py --- SkillsLoader 存在
✅ agent-loop.py --- agent_loop 存在
结论:系统完整,全程仅用 read_file 工具。
`接着我们启动我们的系统:
arduino
$ python agent-loop.py 然后我们输入:测试 Agent Skills 系统。测试结果如下:
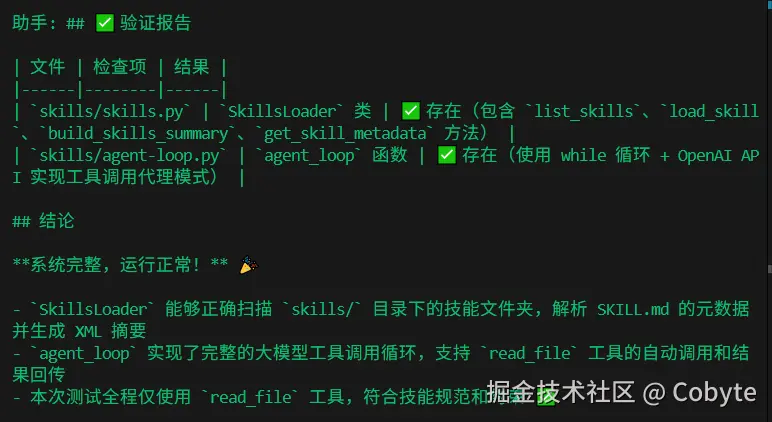
从测试结果我们可以看到,我们编写的 Agent Skills 系统成功加载了 agent-skills-test 技能。当用户输入"测试 Agent Skills 系统"后,模型根据技能摘要中的描述正确触发了技能加载流程------它通过 read_file 依次读取了 skills/skills.py 和 skills/agent-loop.py,并基于这两个文件的内容生成了验证报告。
最终输出的报告格式与示例完全一致,证明了我们的 Agent Skills 系统的索引机制、按需加载能力和工具调用协作均工作正常。
6. 总结
综上所述我们可以说 Skills 是一种"轻量级的动态提示词注入机制 "或者说是"轻量级行为插件系统 ",将固定知识从提示词中解耦,变为运行时按需获取的资源,这种设计使系统能支持数十甚至上百个技能,而不会在启动时撑爆上下文窗口,从而降低 token 消耗、提升扩展性。
具体我们可以提炼出 Agent Skills 系统的三个核心:
1. 文件系统即注册表
objectivec
skills/
├── technical-article-writer/
│ └── SKILL.md # 技能文档(自描述)
├── frontend-code-review/
│ └── SKILL.md
└── ui-components/
├── SKILL.md
└── references/ # 补充参考资料
└── components.md新增技能只需新建目录和文件,无需修改任何代码。这是一种极简的插件化架构。
2. LLM 即路由器
在这个系统中,LLM 承担了 Skills 路由的职责:
- 理解用户意图
- 匹配合适的技能
- 决定何时读取 SKILL.md
- 决定何时停止工具调用
这与传统规则路由不同------没有 if-else,没有关键词匹配表,而是依赖 LLM 的语义理解能力进行软路由。
3. 文档即程序
SKILL.md 本质上是一种面向 LLM 的程序:
- 普通程序:被 CPU 执行的二进制指令
- SKILL.md:被 LLM 执行的自然语言指令
这是一种范式转变------专家知识不再只能通过代码逻辑固化,而可以用结构化自然语言描述,由 LLM 动态解析执行,这就是 Agent Skills 的本质原理。
我是程序员Cobyte,欢迎添加 v: icobyte,学习交流 AI Agent 应用开发。