RSS 2021 (Robotics: Science and Systems)
摘要
- 研究问题:腿式机器人在现实世界部署时,必须能够实时适应各种未见过的场景,包括地形变化(如从平坦地面到岩石)、负载变化(如携带不同重量的物品)、以及机械磨损等。
- 提出的方法 :本文提出了快速运动适应(RMA)算法,专门用于解决四足机器人的实时在线适应问题。
- 算法组成 :RMA 由两个核心组件构成:
- 基础策略:负责生成机器人的动作指令。
- 适应模块:负责估计环境特征,使策略能够根据环境变化进行调整。
- 性能指标 :这两个组件协同工作,使机器人能够在几分之一秒内(in fractions of a second)适应全新的情况。
- 训练方式 :
- RMA 完全在仿真环境中训练。
- 训练过程中不使用任何领域知识 ,例如:
- 参考轨迹(预先定义好的理想运动路径)。
- 预定义的足部轨迹生成器(传统方法中常用的人为设计的足部运动模式)。
- 部署方式 :训练好的 RMA 直接部署在A1 机器人 上,不需要任何微调(即无需在真实机器人上额外调整参数)。
- 训练细节 :
- 使用多样化地形生成器生成各种训练地形。
- 使用基于生物能量学的奖励函数(模仿生物体能量消耗的激励机制)。
- 测试地形:岩石表面、湿滑表面、可变形表面(如泡沫、软土)、草地、长植被、混凝土、卵石、楼梯、沙子等。
- 实验结果 :RMA 在真实世界和仿真实验 中均表现出最先进的性能。
- 视频链接:https://ashish-kmr.github.io/rma-legged-robots/
I 引言
-
历史进展:过去四十年,腿式机器人技术通过物理动力学建模和控制理论工具取得了巨大进步。
-
传统方法的局限 :这些方法要求人类设计师具备大量的专业知识,门槛较高。
-
新趋势 :近年来,研究者对使用强化学习(RL) 和模仿学习技术来复现成功表现出浓厚兴趣,以期降低对人类专家知识的依赖,甚至可能提升性能。
-
标准范式:
- 在物理仿真环境中训练基于 RL 的控制器。
- 使用各种仿真到现实(sim-to-real)技术将控制器迁移到真实世界。
-
仿真到现实的挑战 : sim-to-real 差距由三个因素造成:
- (a) 物理机器人与仿真器中的模型存在显著差异。
- (b) 真实世界地形与仿真器中的地形模型差异很大。
- © 物理仿真器无法准确捕捉 真实世界的物理特性,尤其是接触力、可变形表面等------这比模拟自由空间中运动的刚体困难得多。
-
实验平台 :使用 Unitree 公司生产的相对便宜的 A1 机器人。
-
核心策略 :不仅基本的行走策略要在仿真中训练,RMA 本身也必须在仿真中训练 ,然后直接部署到真实世界。
RMA 架构概述
- 两个子系统 :
- 基础策略 (π\piπ):生成动作。
- 适应模块 (ϕ\phiϕ):辅助适应。
- 基础策略的训练 :
- 通过强化学习在仿真中训练。
- 使用特权信息 :关于环境配置 ete_tet 的信息(如摩擦系数、负载重量等)。
- 数据处理流程 :
- 环境配置向量 ete_tet 通过编码器网络 μ\muμ 编码到潜在特征空间 ztz_tzt(称为外部特征向量)。
- ztz_tzt、当前状态 xtx_txt 和上一个动作 at−1a_{t-1}at−1 一起输入到基础策略 π\piπ。
- 基础策略输出预测的期望关节位置 ata_tat。
- 联合训练 :策略 π\piπ 和环境因子编码器 μ\muμ 通过强化学习在仿真中联合训练。
适应模块的作用
- 部署问题 :在现实世界中无法获得 ete_tet。
- 解决方案 :需要在运行时估计外部特征向量 ,这就是适应模块 ϕ\phiϕ 的作用。
- 关键洞察 :命令动作与实际运动之间的差异取决于外部特征向量(例如,低摩擦地面上实际滑动会比预期更多)。
- 方法思路 :利用智能体最近的状态和动作历史 来估计 ztz_tzt,类似于卡尔曼滤波器从观测历史中进行状态估计。
- ϕ\phiϕ 的目标 :从历史中估计 ztz_tzt,不假设能够访问 ete_tet。运行时进行估计,训练时情况更简单。
训练与部署细节
- 训练阶段的便利条件 :在仿真中,状态历史和 ztz_tzt 都可以直接计算得到 ,因此可以通过监督学习 来训练 ϕ\phiϕ,学习从(状态历史、动作历史)到 ztz_tzt 的映射。
- 部署阶段的协同:两模块共同工作,实现鲁棒且自适应的运动。
- 运行频率 :
- 基础策略 π\piπ:100 Hz(较快)。
- 适应模块 ϕ\phiϕ:10 Hz(较慢)。
- 异步运行机制 :
- 两模块异步并行运行 ,没有中央时钟同步。
- 基础策略使用 ϕ\phiϕ 最新预测 的 ztz_tzt 来预测动作 ata_tat。
- 优势:即使在 ϕ\phiϕ 运行较慢的情况下,π\piπ 仍能以 100 Hz 快速响应。
与以往工作的对比
- 以往方法 :
- 在每个新环境中收集小数据集。
- 推断环境的关键参数(物理参数如摩擦 7 或潜在编码 41)。
- 存在的问题:收集数据时机器人尚未获得良好的行走策略 ,容易摔倒 和损坏。
- RMA 的方法优势 :
- 不需要收集数据集。
- 通过快速估计 ztz_tzt ,使行走策略能快速适应 ,从而避免摔倒和损坏。
创新点
- 先例:57, 41 也使用带有环境参数额外参数的 RL 训练基础策略。
- 本文的三个创新点 :
- 使用多样化地形生成器。
- 使用受生物能量学启发的自然奖励函数,无需参考示范即可学习行走策略 41。
- 在仿真中训练的适应模块(真正新颖的贡献),使 RMA 成为可能。
- 为何有效 :
- 函数近似 :神经网络可以近似从优化问题到解的映射 1, 17,这正是 ϕ\phiϕ 学习的内容。
- 不需要完美辨识 :ztz_tzt 是环境参数的低维非线性投影,能解决可辨识性问题;重要的是它能否导致正确的动作,而端到端训练正是为此优化。
- 训练覆盖广泛 :使用分形地形生成器和参数随机化(质量、摩擦等),创造涵盖现实情况的多样化物理环境。
与最可比工作的对比及实验结果
- Lee 等人 32 在真实世界实现了 RL 策略的鲁棒性能。
- Lee 等人工作的局限性 :依赖于手工编码的领域知识,如预定义轨迹生成器 25 和电机模型 23。
- RMA 的优势 :不依赖这些手工编码的先验知识。
- 实验评估:RMA 在真实世界的多种地形上进行了评估,包括湿滑表面、不平坦地面、可变形表面(泡沫、床垫)、草地、长植被、混凝土、卵石、岩石表面、沙子等,并成功行走。
II 相关工作
传统控制方法
- 传统方法 :腿式运动传统上通过基于控制的方法实现 36, 43, 16, 56, 50, 26, 28, 2, 24, 4。
- MIT Cheetah 3 5:使用正则化模型预测控制(MPC) 和简化动力学 12,实现高速运动和跳跃障碍。
- ANYmal 机器人 20:通过优化参数化控制器,并基于倒立摆模型进行规划 15。
- 传统方法的共同局限 :
- 需要对现实世界动力学进行精确建模。
- 需要对机器人有深入的先验知识。
- 需要手动调整步态和行为。
- 结合 MPC 的优化方法 :可以缓解部分问题 30, 8, 9,但仍需要大量的特定任务特征工程 11, 15, 3。
腿式运动中的学习
近期进展:
- 深度强化学习 提供了替代方案,减少对人类专业知识的依赖,在仿真中显示出良好的结果48, 33, 37, 14
主要问题:
- 仿真中训练的策略难以迁移到现实世界
解决思路:直接现实训练:
- 局限性:
- 仅限于非常简单的设置
- 扩展到复杂设置需要:
- 不安全的探索(可能损坏机器人)
- 大量的样本(时间和成本高)
仿真到现实的强化学习------域随机化
目标:
- 使用RL在现实世界中实现复杂行走行为,试图弥合仿真到现实的差距
域随机化的定义:
- 策略在广泛的环境参数 和传感器噪声 下进行训练,目的学习鲁棒的行为
域随机化的缺点:
- 用最优性换取鲁棒性 ,导致策略过于保守34,也就是说,策略虽然能在各种环境下生存,但可能无法达到最优的运动效率或速度
仿真到现实的强化学习------改进仿真精度
基本思路:
- 使仿真更加准确, 从而减少仿真到现实的差距
具体方法:
-
1)改进电机模型 ,将分段线性函数拟合到实际电机的数据
-
2)使用神经网络 来参数化执行器模型
两种方法的共同局限:
- 需要从机器人上初步收集数据以拟合电机模型
- 对于每一个新的设置 (如新的机器人、新的环境条件),都需要重新进行这个过程
系统辨识与适应
策略可以通过在线系统辨识这些物理参数。在现实世界部署期间,物理参数可以通过在仿真中训练的模块进行推断57,或者通过使用进化算法直接针对高回报进行优化58。预测精确的系统参数通常是不必要且困难的,这会导致实际中性能不佳。取而代之的是,可以使用低维潜在嵌入41, 61。在测试时,这个潜在变量可以通过使用策略梯度方法41、贝叶斯优化59或随机搜索60在真实世界的展开轨迹中进行优化。另一种方法是使用元学习来学习策略网络的初始化,以实现快速在线适应13。尽管这些方法已经在真实机器人上得到了验证49, 10,但它们仍然需要多次真实世界的展开轨迹来进行适应。
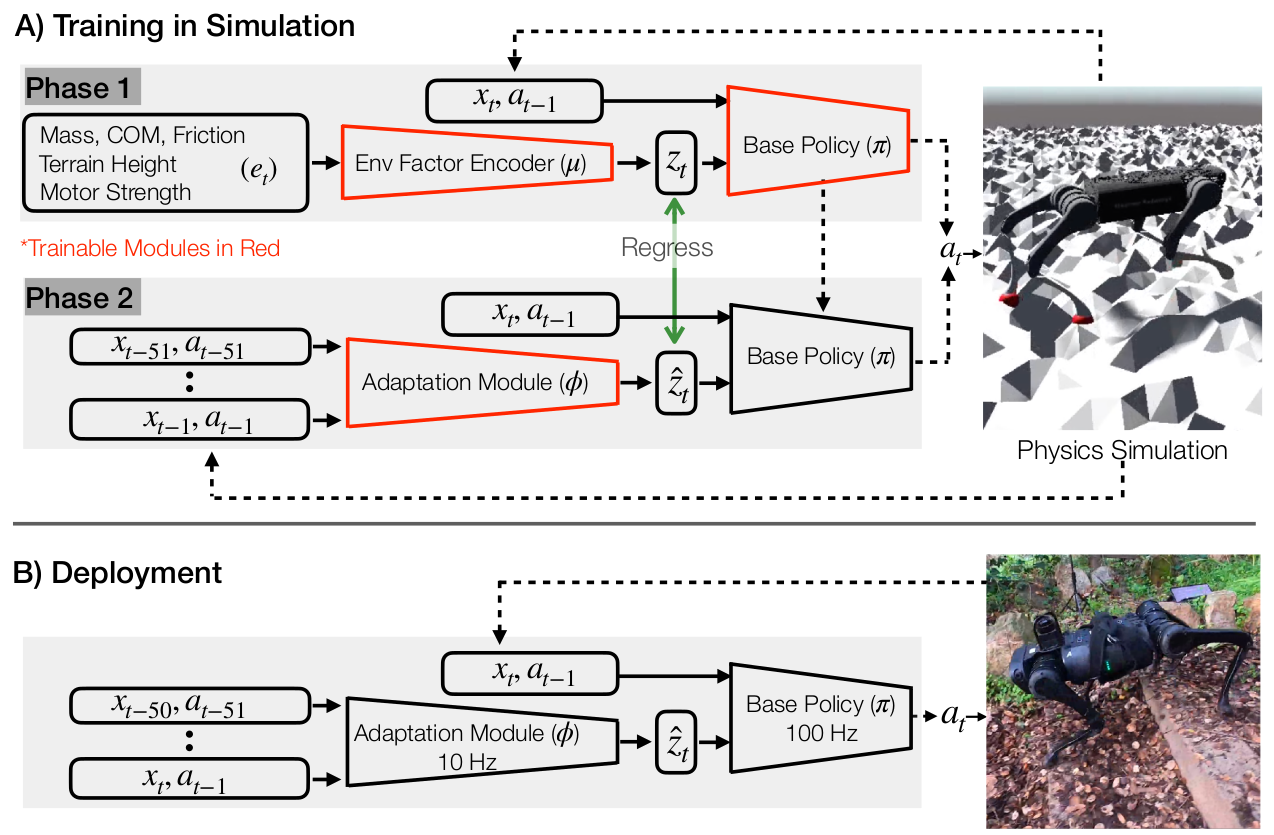
图 2: RMA 由两个子系统组成------基础策略 π\piπ 和适应模块 ϕ\phiϕ。
上半部分(训练): RMA 分两个阶段进行训练。
在第一阶段,基础策略 π\piπ 接收当前状态 xtx_txt、上一个动作 at−1a_{t-1}at−1 以及特权环境因子 ete_tet 作为输入,其中 ete_tet 通过环境因子编码器 μ\muμ 编码为潜在的外部特征向量 ztz_tzt。基础策略使用无模型强化学习在仿真中进行训练。
在第二阶段,适应模块 ϕ\phiϕ 被训练用于从状态和动作的历史中,通过监督学习结合在线策略数据,来预测外部特征 z^t\hat{z}_tz^t。
下半部分(部署): 在部署时,适应模块 ϕ\phiϕ 以 10 Hz 的频率生成外部特征 z^t\hat{z}_tz^t,基础策略以 100 Hz 的频率生成期望的关节位置,这些位置通过 A1 的 PD 控制器转换为扭矩。由于适应模块以较低的频率运行,基础策略使用适应模块预测的最新外部特征向量 z^t\hat{z}_tz^t 来预测动作 ata_tat。这种异步设计对于在计算资源有限的低成本机器人(如 A1)上实现无缝部署至关重要。
视频链接:https://ashish-kmr.github.io/rma-legged-robots/
III. 快速运动适应(RMA)
基础策略、适应模块以及在真实机器人上的部署。
A. 基础策略
我们学习一个基础策略 π\piπ,它以当前状态 xt∈R30x_t \in \mathbb{R}^{30}xt∈R30、上一个动作 at−1∈R12a_{t-1} \in \mathbb{R}^{12}at−1∈R12 和外部特征向量 zt∈R8z_t \in \mathbb{R}^8zt∈R8 作为输入,来预测下一个动作 ata_tat。预测的动作 ata_tat 是 12 个机器人关节的期望关节位置,通过 PD 控制器转换为扭矩。外部特征向量 ztz_tzt 是由编码器 μ\muμ 生成的环境向量 et∈R17e_t \in \mathbb{R}^{17}et∈R17 的低维编码。
zt=μ(et)(1) z_t = \mu(e_t) \tag{1} zt=μ(et)(1)
at=π(xt,at−1,zt)(2) a_t = \pi(x_t, a_{t-1}, z_t) \tag{2} at=π(xt,at−1,zt)(2)
我们将 μ\muμ 和 π\piπ 实现为 MLP(多层感知机),具体细节在第 IV-B 节中给出。我们使用无模型强化学习对基础策略 π\piπ 和环境因子编码器 μ\muμ 进行端到端的联合训练。在时间步 ttt,π\piπ 接收当前状态 xtx_txt、上一个动作 at−1a_{t-1}at−1 以及外部特征向量 zt=μ(et)z_t = \mu(e_t)zt=μ(et),来预测动作 ata_tat。RL 最大化策略 π\piπ 的以下期望回报:
J(π)=Eτ∼p(τ∣π)∑t=0T−1γtrt, J(\pi) = \mathbb{E}_{\tau \sim p(\tau | \pi)} \left \\sum_{t=0}\^{T-1} \\gamma\^t r_t \\right, J(π)=Eτ∼p(τ∣π)t=0∑T−1γtrt,
其中 τ={(x0,a0,r0),(x1,a1,r1),... }\tau = \{(x_0, a_0, r_0), (x_1, a_1, r_1), \dots\}τ={(x0,a0,r0),(x1,a1,r1),...} 是智能体执行策略 π\piπ 时的轨迹,p(τ∣π)p(\tau | \pi)p(τ∣π) 表示在该策略下轨迹的似然。
通过自然约束实现稳定步态: 我们没有添加人工仿真噪声,而是在以下自然约束下训练智能体。首先,奖励函数受生物能量学约束的启发,旨在最小化做功和地面冲击 42。我们发现这些奖励函数对于在仿真中学习真实的步态至关重要。其次,我们在不平坦地形(图 2)上训练策略,以此替代 23 中用于足部 clearance 和对外部推力鲁棒性的额外奖励。在这些自然约束下训练得到的行走策略,无需任何修改即可迁移到现实世界中的简单设置(如混凝土或木地板)。这与其他的仿真到现实工作形成对比,那些工作要么通过真实世界校准仿真 51, 23,要么在现实世界中微调策略 41。而适应模块则使其能够从简单设置扩展到如图 1 所示的非常具有挑战性的地形。
RL 奖励函数: 奖励函数鼓励智能体以最大 0.35 m/s 的速度向前移动,并惩罚生硬和低效的运动。记线速度为 vvv,方向角为 θ\thetaθ,角速度为 ω\omegaω,所有这些都在机器人的基座坐标系中。我们还定义关节角度为 qqq,关节速度为 q˙\dot{q}q˙,关节扭矩为 τ\tauτ,足底地面反作用力为 fff,足部速度为 vfv_fvf,以及二进制的足部接触指示向量为 ggg。时间步 ttt 的奖励定义为以下各项之和:
- 前向运动: min(vxt,0.35)\min(v_x^t, 0.35)min(vxt,0.35)
- 横向移动和旋转: −∣∣vyt∣∣2−∣∣ωyawt∣∣2-||v_y^t||^2 - ||\omega_{\text{yaw}}^t||^2−∣∣vyt∣∣2−∣∣ωyawt∣∣2
- 做功: −∣τT⋅(qt−qt−1)∣-|\tau^T \cdot (q^t - q^{t-1})|−∣τT⋅(qt−qt−1)∣
- 地面冲击: −∣∣ft−ft−1∣∣2-||f^t - f^{t-1}||^2−∣∣ft−ft−1∣∣2
- 平滑性: −∣∣τt−τt−1∣∣2-||\tau^t - \tau^{t-1}||^2−∣∣τt−τt−1∣∣2
- 动作幅度: −∣∣at∣∣2-||a^t||^2−∣∣at∣∣2
- 关节速度: −∣∣q˙t∣∣2-||\dot{q}^t||^2−∣∣q˙t∣∣2
- 方向: −∣∣θrollt,θpitcht∣∣2-||\theta_{\text{roll}}^t, \theta_{\text{pitch}}^t||^2−∣∣θrollt,θpitcht∣∣2
- Z 轴加速度: −∣∣vzt∣∣2-||v_z^t||^2−∣∣vzt∣∣2
- 足部滑动: −∣∣diag(gt)⋅vft∣∣2-||\text{diag}(g^t) \cdot v_f^t||^2−∣∣diag(gt)⋅vft∣∣2
每个奖励项的缩放因子分别为:20, 21, 0.002, 0.02, 0.001, 0.07, 0.002, 1.5, 2.0, 0.8。
训练课程: 如果我们使用上述奖励函数直接训练智能体,它会因为关节运动的惩罚项而学会待在原地不动。为了防止这种崩溃,我们遵循 23 中描述的策略。我们从非常小的惩罚系数开始训练,然后使用固定的课程逐步增加这些系数的强度。我们还随着训练的进行,线性增加其他扰动的难度,如质量、摩擦力和电机强度。我们在地形上没有设置任何课程,而是从相同的固定难度中随机采样地形轮廓开始训练。
B. 适应模块
特权环境配置 ete_tet 及其编码后的外部特征向量 ztz_tzt 在现实世界部署期间无法获取。因此,我们提出使用适应模块 ϕ\phiϕ 在线估计外部特征向量。适应模块不使用 ete_tet,而是使用机器人最近的状态历史 xt−k:t−1x_{t-k:t-1}xt−k:t−1 和动作历史 at−k:t−1a_{t-k:t-1}at−k:t−1 来生成 z^t\hat{z}_tz^t,即对真实外部特征向量 ztz_tzt 的估计。在我们的实验中,使用 k=50k = 50k=50,对应 0.5 秒的时间窗口。
z^t=ϕ(xt−k:t−1,at−k:t−1) \hat{z}t = \phi(x{t-k:t-1}, a_{t-k:t-1}) z^t=ϕ(xt−k:t−1,at−k:t−1)
需要注意的是,与典型系统辨识中预测 ete_tet 不同,我们直接估计外部特征向量 ztz_tzt,它仅编码了针对给定环境向量 ete_tet 应如何改变行为才能进行纠正。
为了训练适应模块,我们只需要状态-动作历史以及 ztz_tzt 的目标值(由环境因子编码器 μ\muμ 给出)。这两者在仿真中都可用,因此 ϕ\phiϕ 可以通过监督学习进行训练,以最小化:
MSE(z^t,zt)=∥z^t−zt∥2, MSE(\hat{z}_t, z_t) = \|\hat{z}_t - z_t\|^2, MSE(z^t,zt)=∥z^t−zt∥2,
其中 zt=μ(et)z_t = \mu(e_t)zt=μ(et)。我们将 ϕ\phiϕ 建模为 1D CNN 以捕捉时间相关性(第 IV-B 节)。
收集状态-动作历史的一种方法是使用真实的 ztz_tzt 展开训练好的基础策略 π\piπ。然而,这样的数据集将只包含机器人顺利行走的良好轨迹示例。在此数据上训练的适应模块 ϕ\phiϕ 将无法对与专家轨迹的偏差保持鲁棒性,而这种偏差在部署期间会经常发生。
我们通过使用在线策略数据(类似于 Ross 等人 45)来训练 ϕ\phiϕ 以解决这个问题。我们使用由随机初始化的策略 ϕ\phiϕ 预测的 z^t\hat{z}_tz^t 来展开基础策略 π\piπ。然后我们使用这个状态-动作历史,配对 真实的 ztz_tzt 来训练 ϕ\phiϕ。我们迭代地重复这个过程直到收敛。这种训练过程确保 RMA 在训练期间看到足够的探索轨迹,这得益于 (a) 随机初始化的 ϕ\phiϕ 和 (b) z^t\hat{z}_tz^t 的不完美预测。这增加了 RMA 在部署期间性能的鲁棒性。
C. 异步部署
我们完全在仿真中训练 RMA,然后在没有任何修改或微调的情况下将其部署到现实世界中。RMA 的两个子系统异步运行,且运行频率差异很大,因此可以轻松地使用很少的机载计算资源运行。适应策略运行较慢,因为它处理 50 个时间步的状态-动作历史,大约每 0.1 秒(10 Hz)更新一次外部特征向量 z^t\hat{z}_tz^t。基础策略以 100 Hz 运行,并使用适应模块生成的最新 z^t\hat{z}_tz^t,连同当前状态和上一个动作,来预测 ata_tat。这种异步执行在实践中不会损害性能,因为在现实世界中 z^t\hat{z}_tz^t 的变化相对不频繁。
另一种方法是训练一个直接接收状态和动作历史作为输入的基础策略,而不将它们解耦为两个模块。我们发现这种方法 (a) 导致不自然的步态和在仿真中性能较差,(b) 在机载计算上只能以 10 Hz 运行,以及 © 缺乏异步设计,而这对于在真实机器人上无缝部署 RMA、无需两个子系统的任何同步或校准是至关重要的。这种异步设计从根本上是通过将变化相对不频繁的外部特征向量与快速变化的机器人状态解耦来实现的。
IV. 实验设置
A. 环境细节
硬件细节: 我们在所有真实世界实验中使用 Unitree 的 A1 机器人。A1 是一个相对低成本的中型四足机器人狗。它有 18 个自由度,其中 12 个是驱动的(每条腿 3 个电机),重量约为 12 公斤。为了测量机器人的当前状态,我们使用电机编码器的关节位置和速度、IMU 传感器的滚转和俯仰角,以及足部传感器的二值化足部接触指示器。部署的策略使用关节位置控制。预测的期望关节位置通过一个固定增益的 PD 控制器转换为扭矩(Kp=55K_p = 55Kp=55 和 Kd=0.8K_d = 0.8Kd=0.8)。
仿真设置: 我们使用 RaiSim 仿真器 22 进行刚体和接触动力学仿真。我们导入 Unitree 的 A1 URDF 文件 53,并使用内置的分形地形生成器来生成不平坦地形(分形八度 = 2,分形 lacunarity = 2.0,分形增益 = 0.25,z 轴缩放 = 0.27)。每个 RL 回合最多持续 1000 步,如果机器人的高度低于 0.28 米、机体滚转角幅度超过 0.4 弧度或俯仰角超过 0.2 弧度,则会提前终止。策略的控制频率为 100 Hz,仿真时间步长为 0.025 秒。
状态-动作空间: 状态是 30 维的,包含关节位置(12 个值)、关节速度(12 个值)、躯干的滚转和俯仰角,以及二值化的足部接触指示器(4 个值)。对于动作,我们对 12 个机器人关节使用位置控制。RMA 预测期望的关节角度 a=q^∈R12a = \hat{q} \in \mathbb{R}^{12}a=q^∈R12,并通过 PD 控制器转换为扭矩 τ\tauτ:
τ=Kp(q^−q)+Kd(q^˙−q˙) \tau = K_p (\hat{q} - q) + K_d (\dot{\hat{q}} - \dot{q}) τ=Kp(q^−q)+Kd(q^˙−q˙)
其中 KpK_pKp 和 KdK_dKd 是手动指定的增益,目标关节速度 q^˙\dot{\hat{q}}q^˙ 设置为 0。
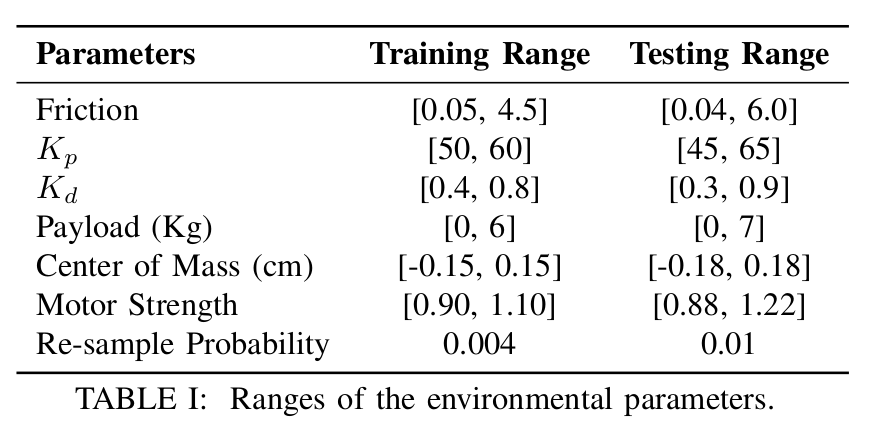
环境变化: 所有环境变化及其范围在表 I 中列出。其中,ete_tet 包括:质量和其在机器人上的位置(3 维)、电机强度(12 维)、摩擦系数(标量)和局部地形高度(标量),构成一个 17 维向量。需要注意的是,尽管地形轮廓的难度是固定的,但局部地形高度会随着智能体的移动而变化。
我们将每只脚下的地形高度离散化到小数点后第一位,然后取四足中的最大值得到一个标量。这确保了控制器不会严重依赖快速且准确的局部地形感知,并允许基础策略在部署期间以低得多的更新频率异步使用它。
B. 训练细节
基础策略和环境因子编码器架构: 基础策略是一个 3 层多层感知机(MLP),它以当前状态 xt∈R30x_t \in \mathbb{R}^{30}xt∈R30、上一个动作 at−1∈R12a_{t-1} \in \mathbb{R}^{12}at−1∈R12 和外部特征向量 zt∈R8z_t \in \mathbb{R}^8zt∈R8 作为输入,输出 12 维的目标关节角度。隐藏层的维度为 128。环境因子编码器是一个 3 层 MLP(隐藏层大小为 256 和 128),将 et∈R17e_t \in \mathbb{R}^{17}et∈R17 编码为 zt∈R8z_t \in \mathbb{R}^8zt∈R8。
适应模块架构: 适应模块首先使用一个 2 层 MLP 将最近的状态和动作嵌入到 32 维的表示中。然后,一个 3 层 1-D CNN 在时间维度上对这些表示进行卷积,以捕捉输入中的时间相关性。每层的输入通道数、输出通道数、卷积核大小和步长分别为 32,32,8,432, 32, 8, 432,32,8,4、32,32,5,132, 32, 5, 132,32,5,1、32,32,5,132, 32, 5, 132,32,5,1。展平的 CNN 输出通过线性投影来估计 z^t\hat{z}_tz^t。
学习基础策略和环境因子编码器网络: 我们使用 PPO 48 联合训练基础策略和环境编码器网络,共进行 15,000 次迭代,每次迭代使用 80,000 的批量大小,分为 4 个小批量。学习率设置为 5×10−45 \times 10^{-4}5×10−4。奖励项的系数在第 III 节中给出。在一台普通桌面计算机上训练大约需要 24 小时,使用 1 个 GPU 进行策略训练。在此期间,它仿真了 12 亿步。
学习适应模块: 我们使用监督学习结合在线策略数据来训练适应模块。我们使用 Adam 优化器 29 来最小化 MSE 损失。我们运行优化过程 1000 次迭代,学习率为 5×10−45 \times 10^{-4}5×10−4,每次迭代使用 80,000 的批量大小,分为 4 个小批量。在一台普通桌面计算机上训练这个模块需要 3 小时,使用 1 个 GPU 进行策略训练。在此期间,它仿真了 8000 万步。
V. 结果与分析
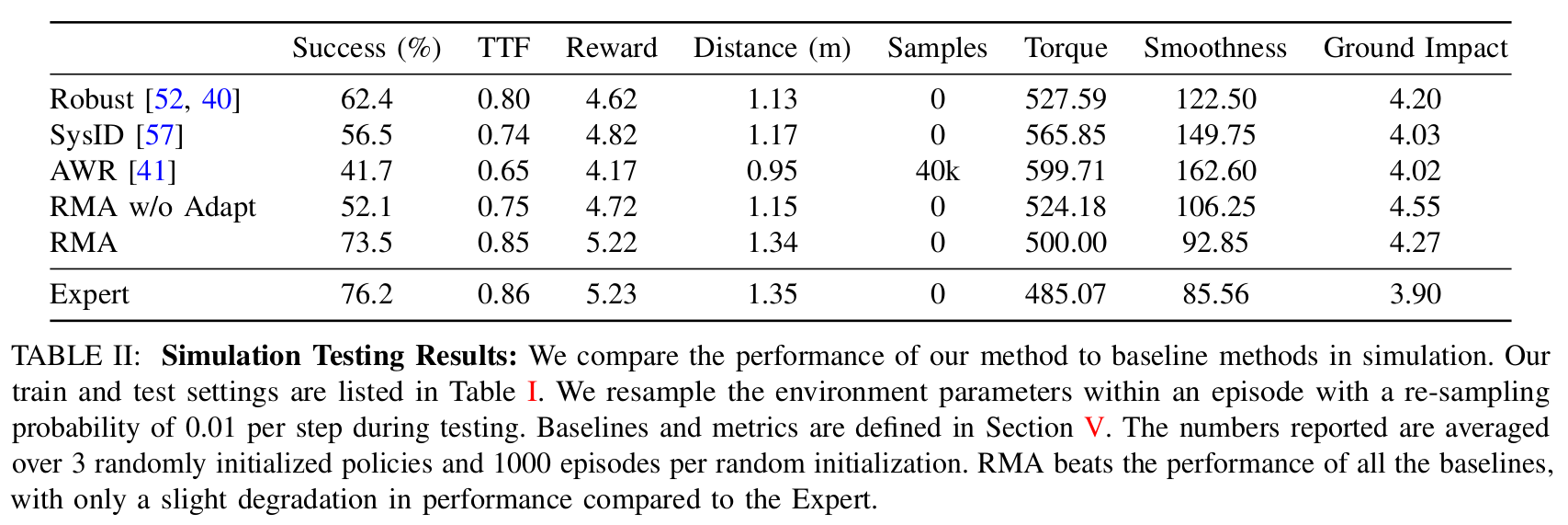
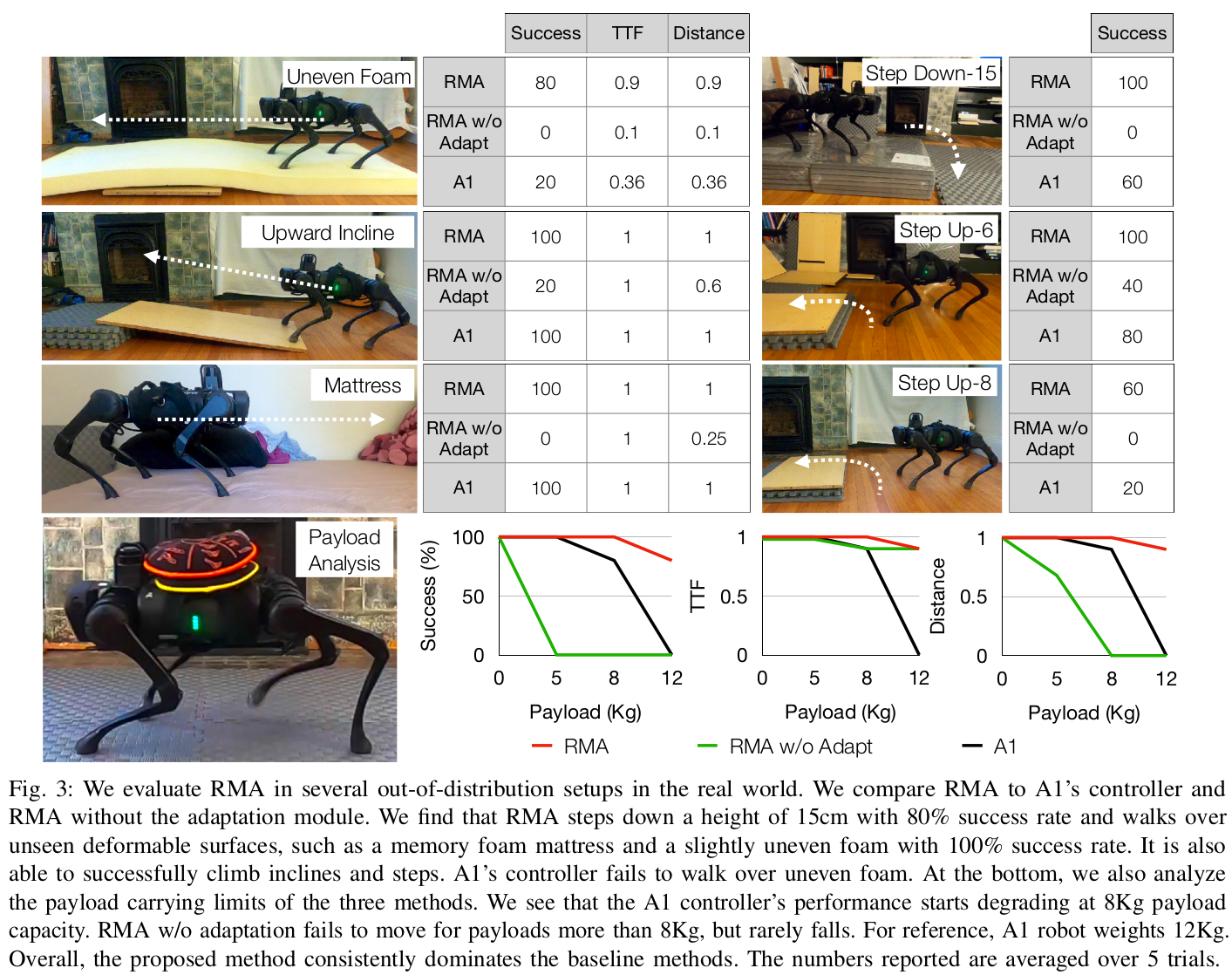
我们在仿真中将 RMA 的性能与几个基线方法进行了比较(表 II)。此外,我们还在真实世界的室内设置中与 A1 机器人自带的制造商控制器进行了比较(图 3),并在非常多样化的地形中(图 1)运行了 RMA。
基线方法: 我们与以下基线方法进行比较:
- A1 控制器: 默认的机器人制造商控制器,使用基于力的控制方案与 MPC。
- 通过域随机化的鲁棒性(Robust): 基础策略在没有 ztz_tzt 的情况下进行训练,以对训练范围内的变化具有鲁棒性 52, 40。
- 专家适应策略(Expert): 在仿真中,我们可以使用外部特征向量 ztz_tzt 的真实值。这是 RMA 性能的一个上界。
- 无适应的 RMA(RMA w/o Adaptation): 我们也可以评估没有适应模块的基础策略的性能,以消融适应模块的重要性。
- 系统辨识(SysID)57: 不预测 z^t\hat{z}_tz^t,而是直接预测系统参数 e^t\hat{e}_te^t。
- 用于领域适应的优势加权回归(AWR)41: 通过在测试环境中使用策略的真实世界展开轨迹,利用 AWR 离线优化 z^t\hat{z}_tz^t。
学习基线方法使用相同的架构、奖励函数和其他超参数进行训练。
评估指标: 我们使用以下指标比较 RMA 与基线的性能:(1) 跌倒时间除以最大回合长度,得到 0-1 之间的归一化值(TTF);(2) 平均前向奖励;(3) 成功率;(4) 覆盖距离;(5) 适应所需的探索样本数;(6) 施加的扭矩;(7) 平滑性(扭矩的导数);(8) 地面冲击(细节见补充材料)。
A. 室内实验
在真实世界中,我们将 RMA 与 A1 的控制器以及无适应模块的 RMA 进行了比较(图 3)。我们将比较限制在这两个基线上,以避免损坏机器人硬件。我们对每种方法进行了 5 次试验,并报告成功率、跌倒时间(TTF)和覆盖距离。需要注意的是,如果一种方法在某项任务中严重失败,我们只进行两次试验,然后报告失败。这样做是为了最小化对机器人硬件的损坏。我们有以下室内设置:
- n-kg 负载: 在顶部负载 n 公斤的情况下行走 300 厘米。
- StepUp-n: 上一个 n 厘米高的台阶。
- 不平坦泡沫: 在中心凸起的泡沫上行走 180 厘米。
- 床垫: 在记忆泡沫床垫上行走 60 厘米。
- StepDown-n: 下一个 n 厘米高的台阶。
- 斜坡: 在 6 度斜坡上行走。
- 油污表面: 穿过一片油污区域。
StepUp-n 和 StepDown-n 的每次试验在成功或失败后终止。因此,我们只报告这些任务的成功率,因为其他指标没有意义。
我们观察到 RMA 在所有设置中都实现了高成功率,在某些情况下大幅超越了 A1 控制器的性能。我们发现关闭适应模块会显著降低性能,这意味着适应模块对于解决这些任务至关重要。A1 控制器在不平坦泡沫以及大步下台阶和上台阶方面表现不佳。在大多数失败中,控制器因不稳定的立足点而失稳。在负载分析中,A1 控制器能够处理超过其标称负载(5 公斤)的重量,但随着负载增加开始下沉并最终摔倒。相比之下,RMA 保持了高度,并能够以高成功率承载高达 12 公斤(相当于其自身体重的 100%)。无适应的 RMA 大多不会摔倒,但也不会向前移动。我们还在一个更具挑战性的任务中评估了 RMA:用塑料袋包裹脚部穿越油污路径。机器人成功穿过了油污区域。有趣的是,无适应的 RMA 能够在没有任何微调或仿真校准的情况下在木地板上成功行走。这与现有方法形成对比,后者即使在平坦和静态环境中也需要校准仿真 51, 23 或在测试时微调其策略 41。
B. 室外实验
我们展示了 RMA 在多个具有挑战性的户外环境中的性能,如图 1 所示。机器人在所有试验中都成功地在沙子、泥地和泥土上行走,没有一次失败。这些地形由于足部下沉和粘滞而使运动变得困难,这要求机器人动态改变立足点以确保稳定性。RMA 在高大植被上行走或穿越灌木丛的成功率为 100%。这类地形会阻碍机器人的足部,使其在行走时周期性失稳。为了在这些设置中成功行走,机器人必须稳定应对足部缠绕,并积极地冲破其中一些障碍。我们还评估了机器人在徒步路径上的楼梯下行。机器人在 70% 的试验中成功,考虑到机器人在训练期间从未见过楼梯,这仍然是了不起的。最后,我们在建筑废墟上测试了机器人:在下坡穿越泥堆时成功率为 100%,在穿越水泥堆和卵石堆时成功率为 80%。水泥堆和卵石堆本身位于一个侧向陡峭倾斜的地面上,这使得机器人穿越这些堆垛极具挑战性。
C. 仿真结果
我们在仿真中将我们的方法与基线方法进行了比较(表 II)。我们根据表 I 对训练和测试参数进行采样,并在一个回合内以每步 0.004(训练)和 0.01(测试)的重采样概率重新采样它们。报告的数字是 3 个随机初始化的策略以及每个随机初始化 1000 个回合的平均值。RMA 表现最佳,与 Expert 的性能相比仅有轻微下降。不断变化的环境导致 AWR 性能不佳,因为它适应速度非常慢。由于 Robust 基线对外部特征不敏感,它学习了一个非常保守的策略,从而损失了性能。需要注意的是,SysID 的低性能意味着显式估计 ete_tet 是困难且不必要的,无法实现优越的性能。我们还与无适应的 RMA 进行了比较,结果显示没有适应模块时性能显著下降。
D. 适应分析
我们分析了在湿滑表面上适应的步态模式、扭矩分布和估计的外部特征向量 z^t\hat{z}_tz^t(图 4)。我们将油倒在地面的塑料表面上,并额外用塑料包裹机器人的足部。然后机器人尝试穿越湿滑区域,并成功适应了它。我们发现 RMA 在油污区域上的运行成功率为 90%。对于其中一次试验,我们在图 4 中绘制了膝关节的扭矩分布、步态模式以及外部特征向量 z^t\hat{z}_tz^t 经过中值滤波后的第 1 和第 5 个分量。当机器人在 2 秒左右第一次开始打滑时,打滑扰乱了机器人的正常运动,之后它进入了适应阶段。这在所绘制的对外部特征向量分量中很明显,它们响应打滑而发生变化。这种检测到的打滑使机器人能够恢复并继续在湿滑区域上行走。需要注意的是,虽然在适应之后,扭矩稳定在稍高的幅度,步态周期大致恢复,但外部特征向量没有恢复,而是继续捕捉地面湿滑这一事实。更多此类分析见补充材料。
VI. 结论
我们提出了 RMA 算法,用于腿式机器人在各种地形(terrains)上行走的实时适应。不需要任何示范(demonstrations)或预定义的运动模板。尽管只能访问本体感觉(proprioceptive )数据,机器人还可以下楼梯和在岩石上行走。然而,盲机器人有其局限性。较大的扰动,如下楼梯时的突然摔倒,或由于岩石造成的多腿障碍,有时会导致失败。为了开发真正可靠的行走机器人,我们不仅需要使用本体感觉,还需要使用带有板载视觉传感器的外部感受。视觉在引导长距离、快速运动方面的重要性已被充分研究,例如 35,这是未来工作的一个重要方向。
RMA 的补充材料:面向腿式机器人的快速运动适应
S1. 指标
我们使用多个指标(采用 SI 单位制)来评估和比较 RMA 与基线方法的性能:
- 成功率: 成功完成任务的平率,任务定义见下一节。
- 跌倒时间(TTF): 衡量跌倒前的时间。我们将其除以回合的最大持续时间,并报告一个介于 0 和 1 之间的归一化值。
- 奖励: 多个回合上的平均前向步进奖励加上横向奖励,定义见主论文第 III-A 节"RL 奖励"。
- 距离: 一个回合中覆盖的平均距离。对于真实世界实验,我们报告归一化距离,即用特定于任务的最大距离进行归一化。
- 适应样本数: 电机策略适应所需的、在测试环境中探索的控制步数。
- 扭矩: 每个关节上扭矩的平方 L2 范数 ∥τt∥2\|\tau^t\|^2∥τt∥2。
- 加加速度: 扭矩差值的平方 L2 范数 ∥τt−τt−1∥2\|\tau^t - \tau^{t-1}\|^2∥τt−τt−1∥2。
- 地面冲击: 每只脚上地面反作用力差值的平方 L2 范数 ∥ft−ft−1∥2\|\mathbf{f}^t - \mathbf{f}^{t-1}\|^2∥ft−ft−1∥2。
S1. 额外的训练与部署细节
训练流程如算法 1 所示,部署流程如算法 2 所示。
我们使用 PPO 48 来训练基础策略和环境因子编码器。我们总共训练 15,000 次迭代。在每次迭代中,我们收集一批 80,000 个状态-动作转移,这些转移被均匀分成 4 个小批量。每个小批量依次输入到基础策略和环境因子编码器中,进行 4 轮计算损失和误差反向传播。损失是代理策略损失加上 0.5 倍价值损失之和。我们将动作对数概率比裁剪在 0.8 到 1.2 之间,并将目标值裁剪在相应旧值的 0.80.80.8 到 1.21.21.2 倍范围内。我们不使用基础策略的熵正则化,但将参数化高斯动作空间的标准差约束为大于 0.2 以确保探索。在广义优势估计 47 中,λ\lambdaλ 和 γ\gammaγ 分别设置为 0.95 和 0.998。我们使用 Adam 优化器 29,设置学习率为 5×10−45 \times 10^{-4}5×10−4,β\betaβ 为 (0.9,0.999)(0.9, 0.999)(0.9,0.999),ϵ\epsilonϵ 为 1×10−81 \times 10^{-8}1×10−8。参考实现可在 RaisimGymTorch 库 21 中找到。
如果我们使用聚合所有项的奖励函数直接训练智能体,它会因为惩罚项而学会摔倒。为了防止这种崩溃,我们遵循 23 中描述的策略。除了所有奖励项的缩放因子外,我们还对主论文第 III-A 节中定义的惩罚项 3-10 应用一个小乘数 ktk_tkt。我们从非常小的 k0=0.03k_0 = 0.03k0=0.03 开始训练,然后使用固定的课程指数级增加这些系数:
kt+1=kt0.997 k_{t+1} = k_t^{0.997} kt+1=kt0.997
其中 ttt 是迭代次数。学习过程如图 S2 所示。

S1. 额外的真实世界适应分析
除了主论文图 4 中的油污行走实验外,我们还分析了质量适应情况下的步态模式和扭矩分布,如图 S3 所示。我们在机器人运行途中向其背部抛掷一个 5 公斤的负载,并绘制了膝关节的扭矩分布、步态模式以及外部特征向量 z^t\hat{z}_tz^t 的第 2 和第 7 个分量,如图 S3 所示。我们观察到额外的负载扰乱了机器人的正常运动,之后机器人进入适应阶段并最终从扰动中恢复。当负载落在机器人上时,可以注意到所绘制的外部特征向量分量响应于滑移(或冲击)而发生变化。适应之后,我们看到扭矩稳定在比之前更高的幅度以应对负载,并且步态周期大致恢复。

S2. 额外的仿真测试
在图 S4 中,我们进一步在极端的仿真环境中测试 RMA,并展示了其在三种环境变化类型中的性能:A1 机器人基座上添加的负载、地形高度变化(分形地形生成器中使用的 z 轴缩放,详情见主论文第 IV 节"仿真设置"),以及机器人足部与地形之间的摩擦系数。我们在所有情况下展示了 RMA 在成功率、TTF 和奖励(定义见第 S1 节)方面的优越性。