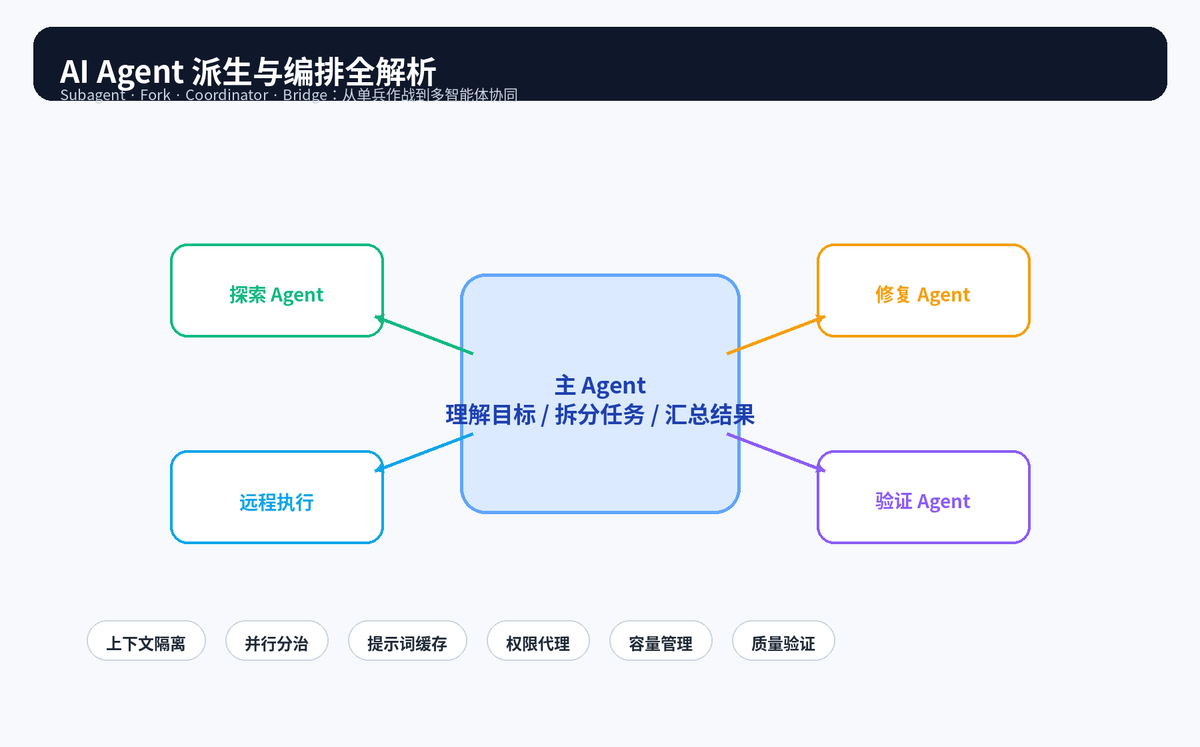
一、真正的转折点:AI Agent 不再只是"会聊天",而是要会分身、会协同、会治理
很多人理解 AI 编程助手,还停留在"让模型帮我改一段代码"的阶段。但真正复杂的工程任务,往往不是一句话就能解决:先要调查代码库,再定位根因,再做方案,再修改,再测试,再复盘。
如果所有步骤都压在一个 Agent 身上,就会出现三个问题:第一,上下文越来越胀;第二,调查和修改必须串行等待;第三,验证和实现由同一个智能体完成时,容易产生"自己证明自己正确"的幻觉。
所以,多 Agent 编排的价值不是炫技,而是把复杂工程任务拆成多个相对独立的工作单元:有人探索,有人实现,有人验证,有人远程执行,有人只负责协调。一个优秀的 AI Agent 系统,本质上正在从"聊天窗口"进化成"软件工程操作系统"。

二、一句话讲透:多 Agent 编排解决的是"上下文、并行、安全、质量"的四重矛盾
2.1 上下文矛盾:信息越多,主线越乱
单个 Agent 的上下文窗口再大,也不是垃圾桶。搜索结果、日志、文件片段、测试输出全部塞进去,短期看似信息充足,长期会让主线判断变混乱。子 Agent 的意义,是把大量临时探索放进独立上下文,只把最终结论和关键证据带回主线。
2.2 并行矛盾:软件工程天然适合分治
查调用链、看测试、分析性能、审查安全,本来就可以并行做。多 Agent 编排把"一个人排队做所有事"变成"多个角色同时推进",让复杂任务的时间被压缩。
2.3 安全矛盾:越自动,越需要边界
Agent 能改文件、跑命令、调用外部工具,能力越强,风险越高。多 Agent 不是简单放权,而是要让不同 Worker 拥有不同工具池、权限模式、隔离目录和审批链路。
2.4 质量矛盾:实现者不能完全替代验证者
实现 Agent 很容易被"代码看起来合理""测试表面通过"迷惑。验证 Agent 的存在,就是把质量把关从主线拆出来,用只读约束、对抗性探测和清晰判定,逼系统面对真实结果。
三、AgentTool:一个入口管住所有派生能力
整个派生体系最关键的设计,是统一入口。也就是说,模型不是随便打开一个新进程,而是通过一个明确的 Agent 工具入口来创建不同类型的 Worker。这样做有三个好处。
第一,能力面板可以动态变化。当前环境支持什么,模型就只看到什么;不支持的能力不展示,模型自然不会乱用。第二,所有派生行为都能被统一记录、追踪和管控。第三,后续要增加新模式时,不需要打乱主循环,只要接入统一入口即可。
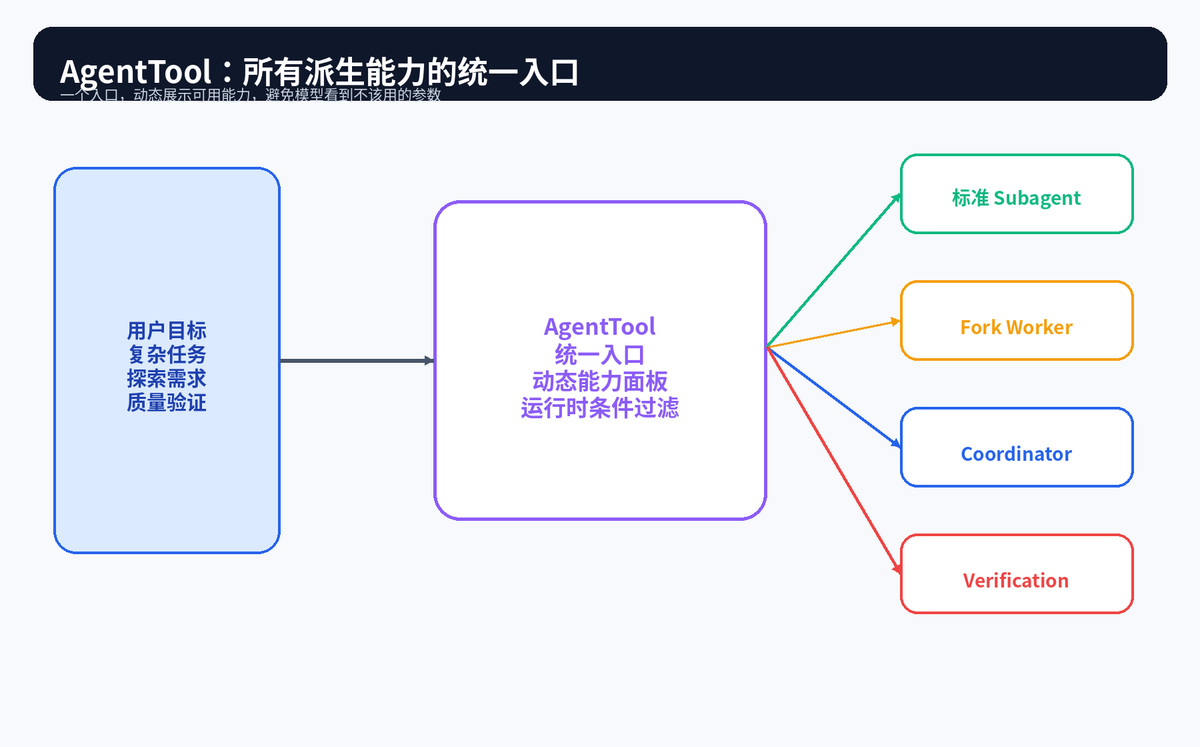
这里最值得普通开发者学习的不是某个字段,而是"能力暴露要精确"。AI 系统不要把所有开关都丢给模型,让它自己猜;应该根据 Feature Flag、运行环境、交互模式、安全策略,动态裁剪模型能看到的能力。
四、并发 Agent 的第一道底座:身份上下文隔离
当多个 Agent 同时运行时,一个很容易被忽视的问题是:事件到底属于谁?如果 Agent A 还在跑,Agent B 又被放到后台执行,日志、权限请求、追踪 ID、会话来源如果都写到一个共享状态里,就可能发生串线。
因此,系统需要一种"每条异步执行链都有自己的身份上下文"的机制。每个 Agent 在自己的异步链路里携带 agentId、名称、来源请求等信息。这样即使多个 Worker 在同一个进程内并发执行,也不会互相覆盖身份。
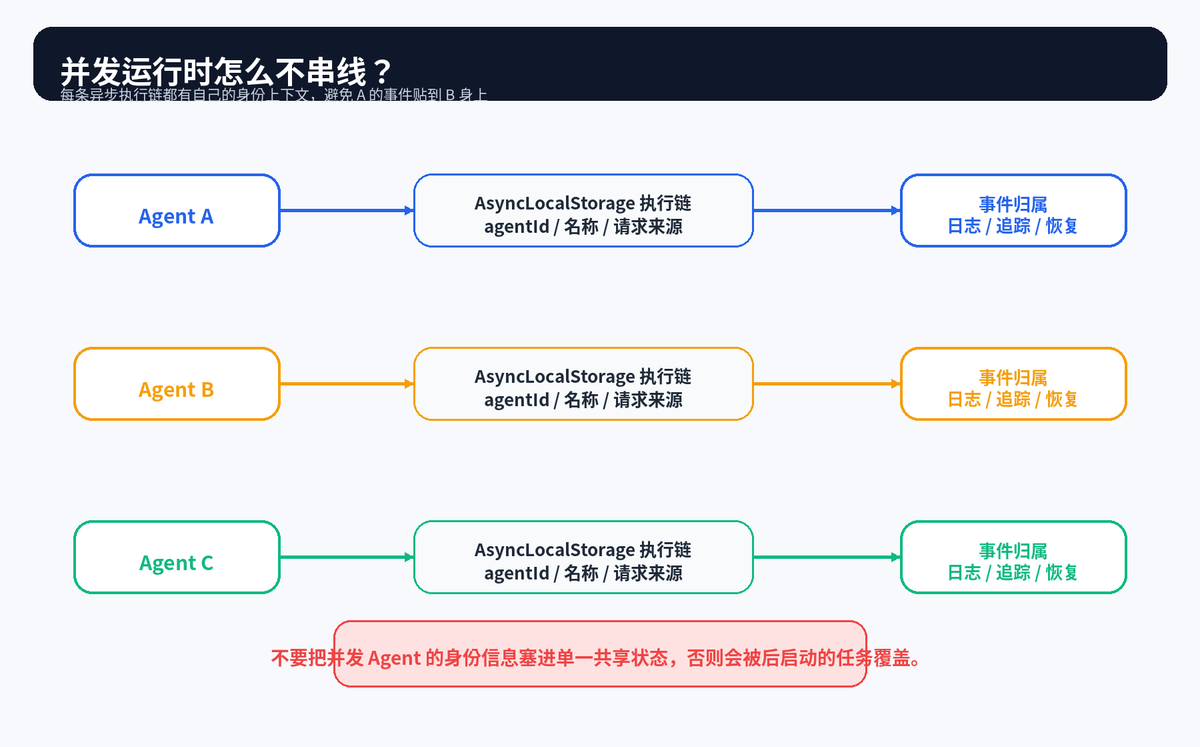
这给企业级 AI 应用一个很重要的提醒:只要你允许并发任务,就不要只依赖全局变量保存"当前用户、当前任务、当前 Agent"。并发一多,当前状态就会变成不可靠状态。
五、三种核心模式:Subagent、Fork、Coordinator
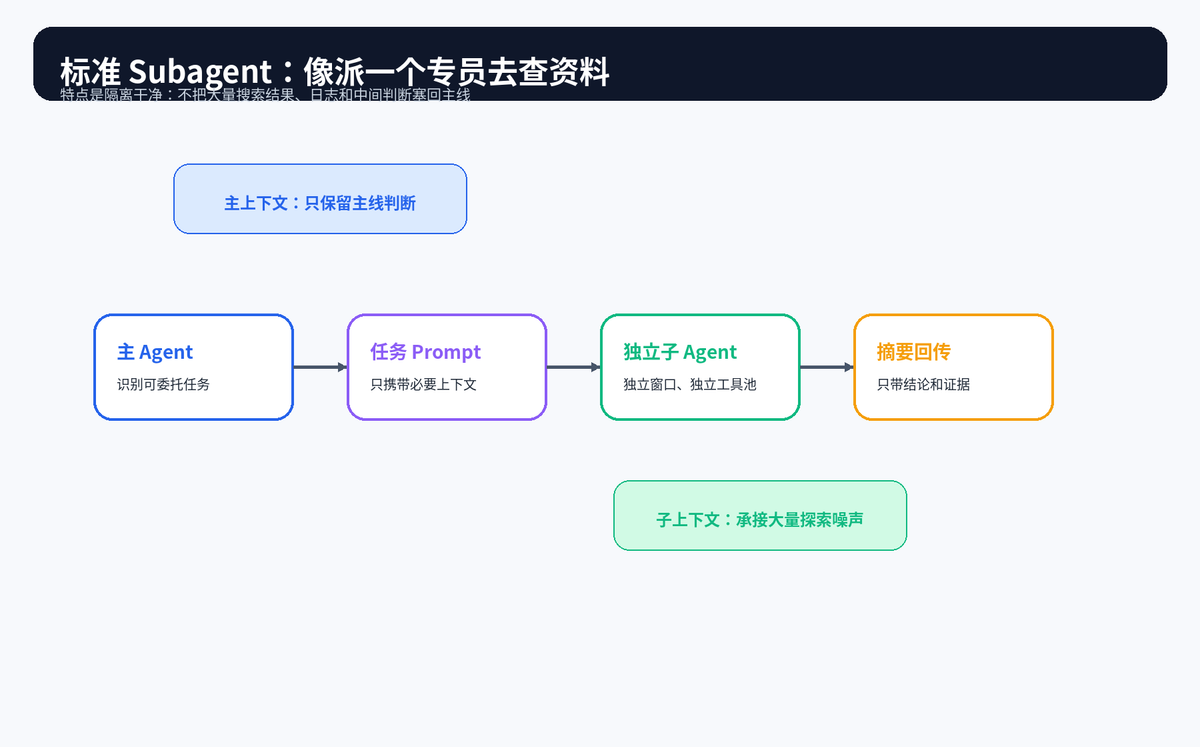
5.1 标准 Subagent:把独立任务外包给专员
标准 Subagent 的特点是上下文隔离。它通常不会继承主会话的完整历史,而是只接收父 Agent 传入的任务说明,然后在自己的上下文窗口里完成探索、分析或处理,最后返回摘要。
这类模式适合处理"查找所有调用方""阅读某个模块""分析一批日志""总结测试失败原因"等任务。它最大的价值是保护主上下文,不让大量临时信息污染主线。
5.2 Fork 模式:继承完整现场,适合并行探索
Fork 模式与标准 Subagent 最大的区别在于:它继承父级完整上下文。你可以把它理解成"把当前工作现场复制几份,让多个 Worker 从同一个现场出发,各自研究不同方向"。
它的关键价值是缓存共享。多个 Fork Worker 前面的工具定义、系统指令、历史对话尽量保持一致,只在最后追加不同子任务。这样稳定前缀更容易复用,长上下文任务的成本和延迟都有机会下降。
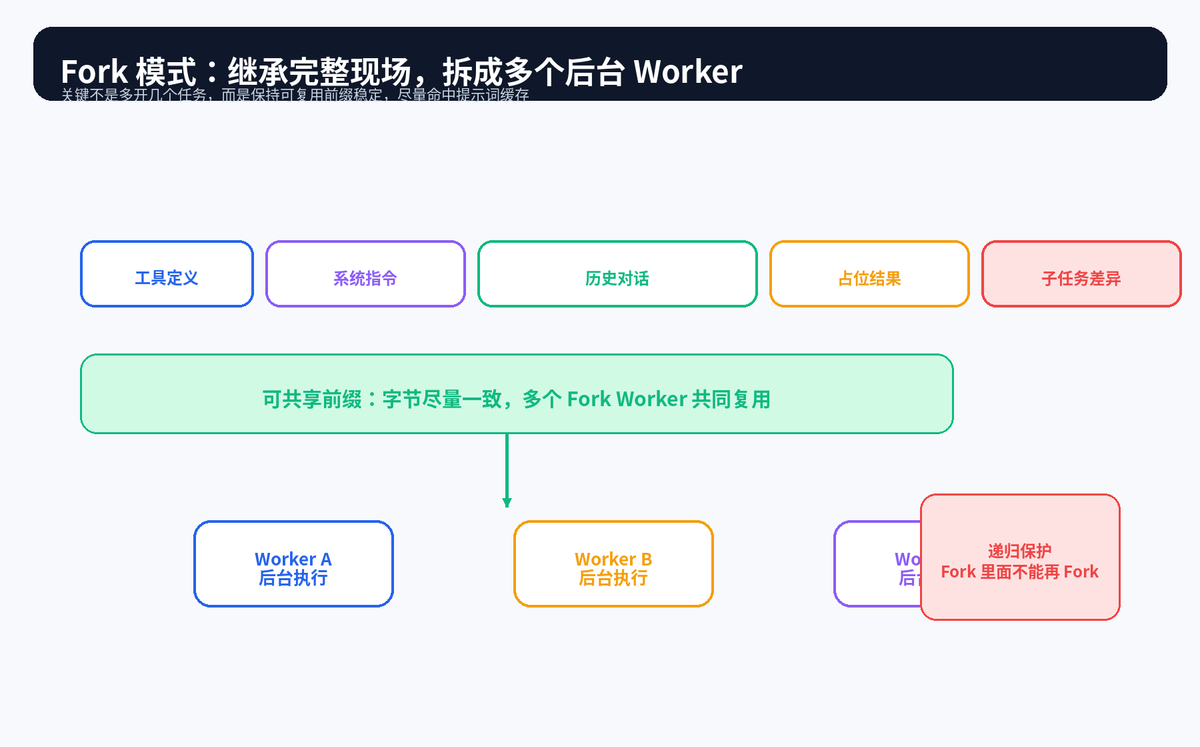
但 Fork 也有天然限制:为了防止派生树无限膨胀,它通常会禁止在 Fork Worker 内继续 Fork。否则一个任务可能迅速变成不可控的递归派生,带来成本、权限和状态管理灾难。
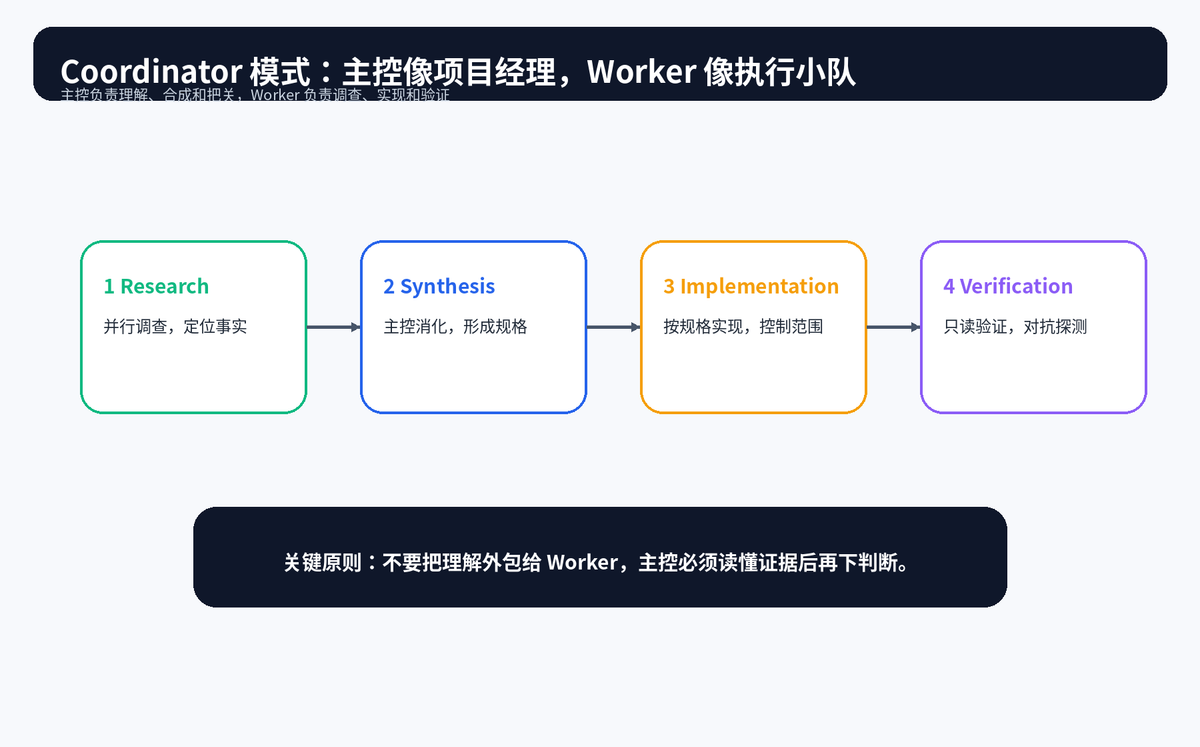
5.3 Coordinator 模式:主控不直接干活,而是负责理解与调度
Coordinator 模式更像项目经理。主控 Agent 不直接写代码,而是把任务拆给 Research Worker、Implementation Worker、Verification Worker 等角色。它的职责不是"少干活",而是把理解、合成、分派和验收集中起来。
这种设计最强调一个原则:不要把理解外包。Worker 可以调查事实,但主控必须自己读懂事实、形成规格、再交给实现者执行。否则主控只是在转发别人的判断,系统就会失去真正的中枢。
5.4 三种模式对比
|--------|-----------------|--------------|--------------------|
| 维度 | 标准 Subagent | Fork 模式 | Coordinator 模式 |
| 上下文 | 全新或高度裁剪 | 完整继承父级 | Worker 独立,主控保留全局视图 |
| 执行方式 | 可前台或后台 | 通常强制后台 | 多 Worker 后台协同 |
| 缓存价值 | 较低 | 较高,前缀可复用 | 取决于任务拆分方式 |
| 递归风险 | 可控 | 需要显式禁止 | Worker 通常不继续派生 |
| 适用场景 | 独立探索、小任务 | 需要当前上下文的并行分析 | 复杂项目、跨模块变更、强质量要求 |

六、侧问能力:上下文、工具、回合数可以独立裁剪
很多系统把派生理解成"要么新开一个全能 Agent,要么不派生"。这其实太粗糙。真正成熟的设计,会把能力拆成三个维度:是否继承上下文、是否允许使用工具、是否允许多轮执行。
例如有一种侧问信道,它继承当前上下文,但不允许工具调用,也只做单轮回答。这样用户可以在主任务执行中顺手问一个无副作用的问题,不会打断主线,也不会产生额外工具风险。
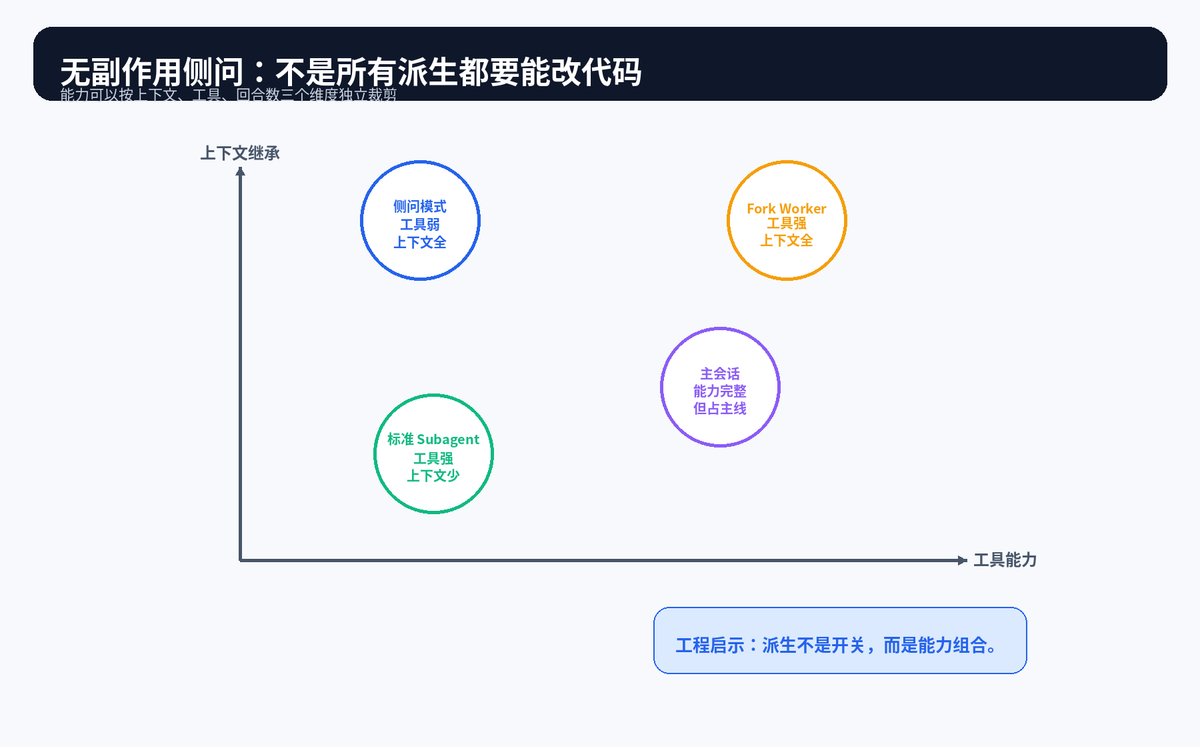
这个思路非常适合迁移到其他 AI 产品:不要把所有辅助问题都塞进主对话,也不要每次都启动全能力 Worker。轻量侧问、只读探索、后台执行、远程会话,本来就应该是不同档位。
七、验证 Agent:专门对抗"看起来已经好了"的错觉
在 AI 编程场景里,最危险的不是完全失败,而是"看起来成功"。界面能打开、测试过了一部分、控制台没有明显报错,模型就容易倾向于给出通过结论。
验证 Agent 的设计重点,就是主动对抗这种倾向。它不是复述实现过程,而是要找到能证明系统真的工作的证据。更关键的是,它要能识别自己的偷懒借口:只读代码不算验证,只描述测试步骤不算验证,只看到快乐路径不算验证。
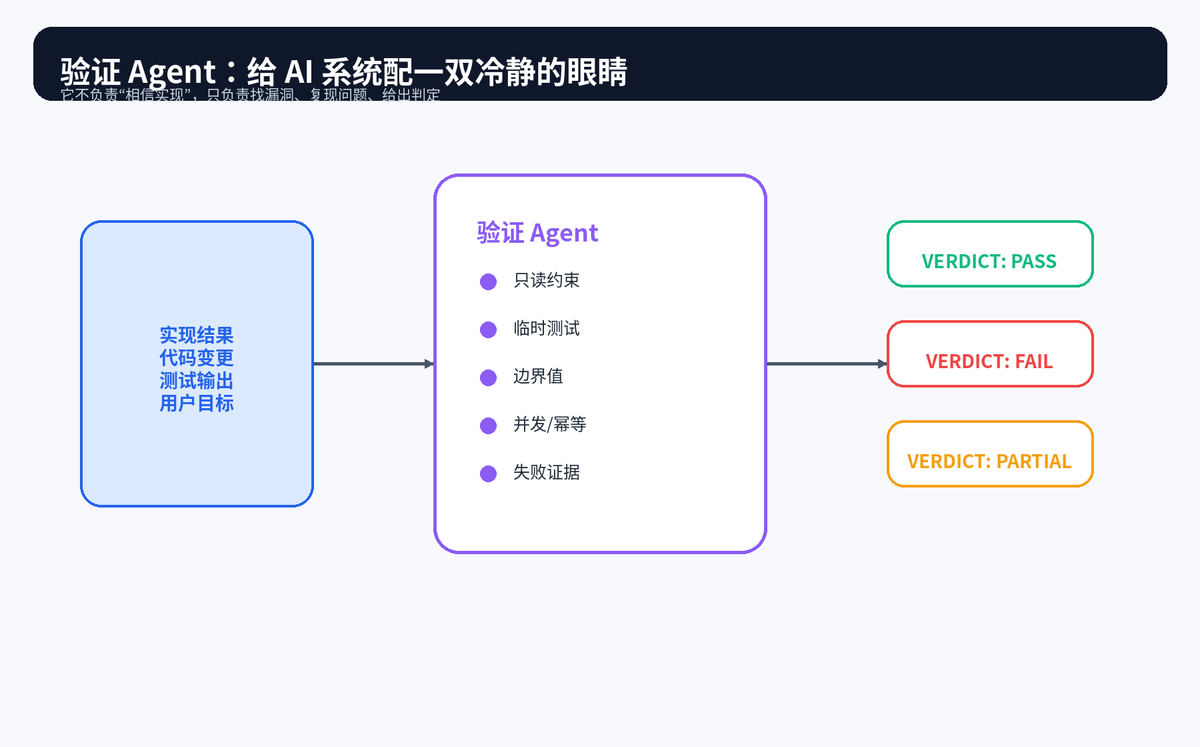
7.1 只读约束:验证者不能顺手改代码
验证者如果一边验证一边修改,就会模糊责任边界。只读约束能保证它的核心职责是发现问题、复现问题、给出证据,而不是把问题悄悄修掉。
7.2 三类判定:通过、失败、受限
一个可靠验证者应该给出明确结论:验证通过;发现失败并提供证据;或者因为环境缺失而只能部分验证。注意,受限不等于不确定。受限必须对应明确环境原因,例如依赖不存在、服务无法启动、测试框架不可用。
7.3 对抗性探测:不要只跑快乐路径
对抗性探测包括边界值、并发请求、幂等性、重复操作、异常输入等。很多缺陷不是在"正常点击一次"时暴露,而是在重复、并发、取消、回滚、极端数据下才出现。
八、工具池独立组装:每个 Worker 的能力边界都要重新计算
多 Agent 系统最容易犯的错误,是让所有 Worker 继承同一套工具。看似方便,实际上风险很大。研究型 Worker 可能只需要读文件和搜索;实现型 Worker 才需要写文件;验证型 Worker 应该尽量只读;远程执行 Worker 还要走权限回路。
因此,每个 Worker 启动时都要根据角色定义、权限上下文、MCP 服务器状态、隔离模式重新组装工具池。这样能让"该做什么的人拿到什么工具",而不是全员拥有最高权限。
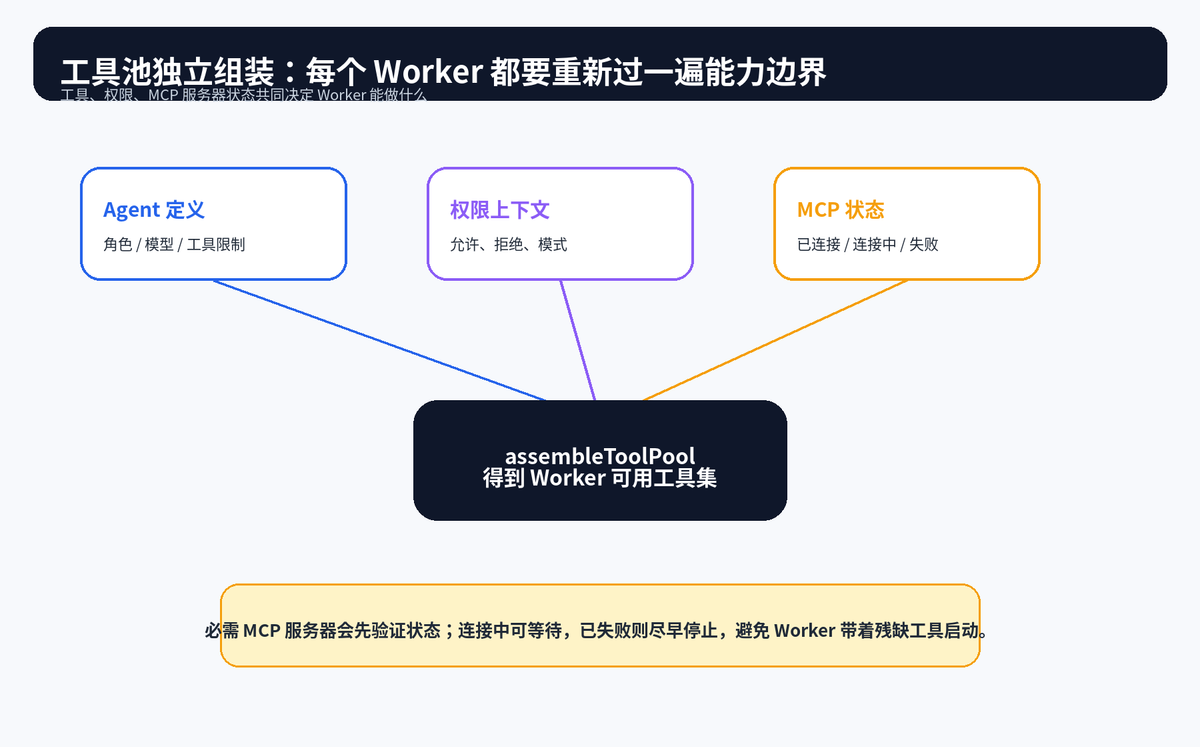
这里还有一个实用细节:如果某个 Agent 声明必须依赖某个 MCP 服务器,就应该在启动前检查连接状态。连接中可以等待一小段时间,已失败则尽早停止。不要让 Worker 在缺少关键工具的情况下开始执行,否则后面会产出大量无效推理。
九、Worktree 隔离:并行修改不能互相踩文件
当多个 Worker 都可能修改文件时,只做上下文隔离还不够,还需要文件系统层面的隔离。Git worktree 的价值就在这里:每个会话或子 Agent 可以在独立工作目录和独立分支里操作,避免同一份文件被多个 Worker 同时改坏。
一个合理策略是:探索任务不需要 worktree;实现任务尽量使用 worktree;高风险实验必须使用 worktree;无变更时自动清理,有变更时保留分支供人工检查。这样既能支持并行,也能降低主分支被污染的风险。
把这套思路迁移到企业内部 AI 平台,可以设计为"任务沙箱":每个自动执行任务都有独立目录、独立临时凭证、独立日志、独立回滚点。
十、Bridge 远程执行:把本地 Agent 能力投射到网络边界之外
前面讨论的 Subagent、Fork、Coordinator,主要是在本地进程或本地子进程里完成派生。而 Bridge 架构解决的是另一类问题:用户从远端创建任务,本地机器实际执行,服务端负责分发、状态汇总和权限回传。
这可以理解成"远程投射":Agent Loop 内核仍然在本地跑,但会话创建、权限确认、心跳状态、输出展示都跨过网络边界。好处是用户可以从更方便的入口触发任务,同时保留本地代码、工具和环境能力。
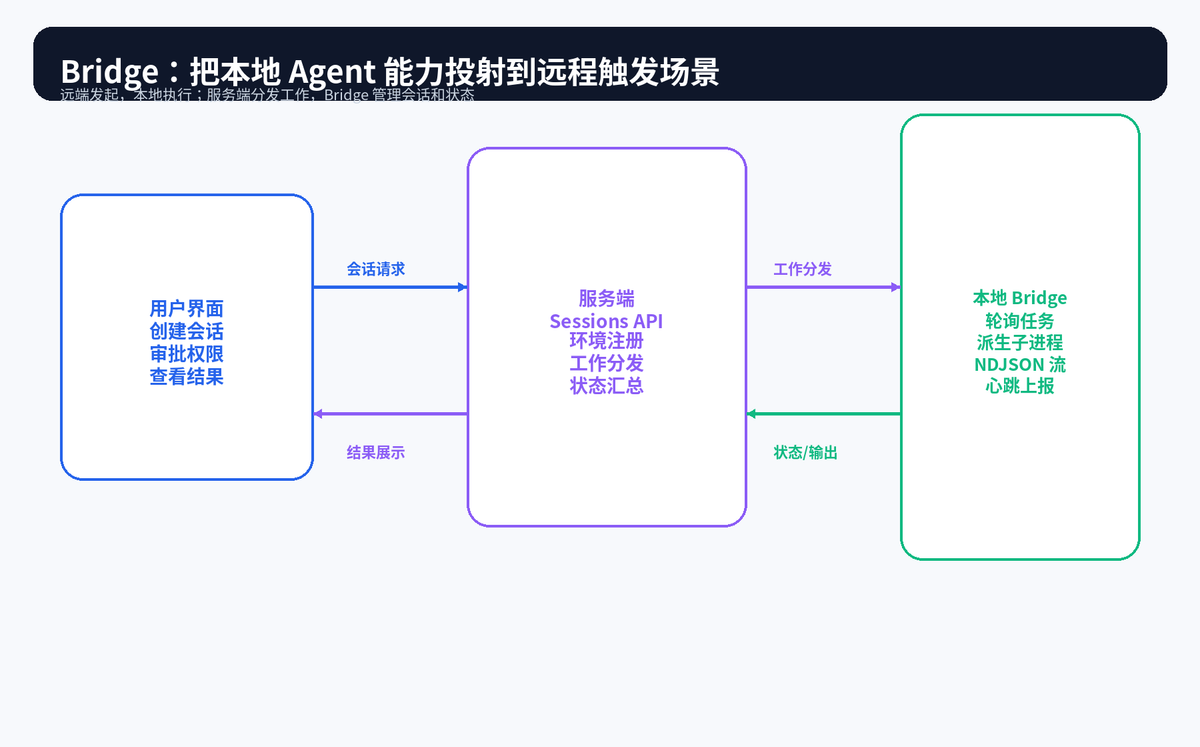
10.1 三组件协作:用户入口、服务端、本地 Bridge
用户入口负责发起会话和做权限决策;服务端负责保存会话状态、注册环境、分发工作;本地 Bridge 通过轮询拿到任务,并派生本地子进程执行。子进程输出以结构化流形式回到 Bridge,再回传服务端。
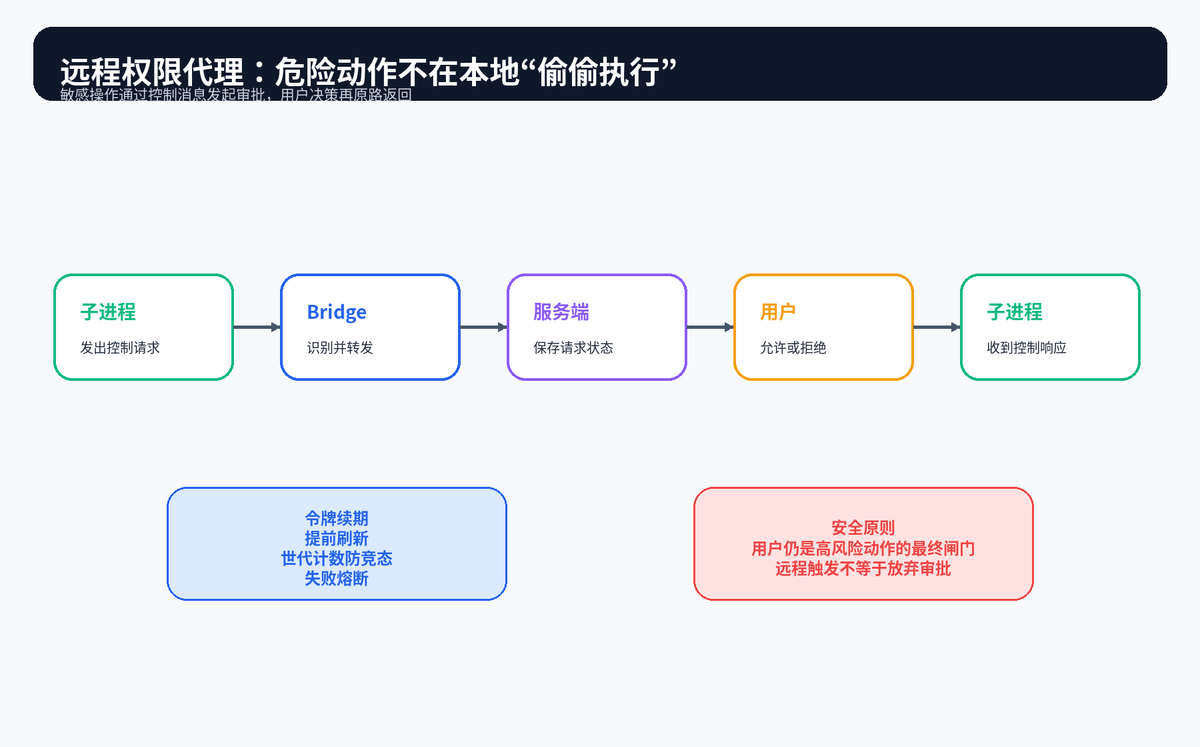
10.2 JWT 续期:认证不是一次性动作
远程会话可能持续很久,所以令牌不能只在启动时检查一次。更稳的方式是提前刷新、失败重试、连续失败熔断,并用世代计数避免旧刷新任务覆盖新状态。
10.3 权限代理:远程触发不等于无限授权
Bridge 最关键的安全设计,是敏感操作仍然需要权限回路。子进程发出控制请求,Bridge 转发给服务端,用户在远端做允许或拒绝的决策,响应再原路返回子进程。
10.4 容量管理:多会话不是无限开
远程执行系统必须管理并发会话数量、工作目录模式、会话超时、心跳上报和异常清理。否则一个用户连续触发多个任务,或者某个任务卡死,就可能拖垮本地机器。
常见模式包括单会话模式、每会话独立 worktree 模式、共享目录模式。共享目录最轻,但冲突风险最高;worktree 成本更高,但更适合并行执行。
十一、从本地派生到远程投射:完整能力光谱
把所有模式放在一起看,会发现它们不是互相替代,而是覆盖不同场景。Subagent 解决局部探索,Fork 解决带完整上下文的并行分析,Coordinator 解决复杂项目调度,Bridge 解决远程触发和跨网络执行。
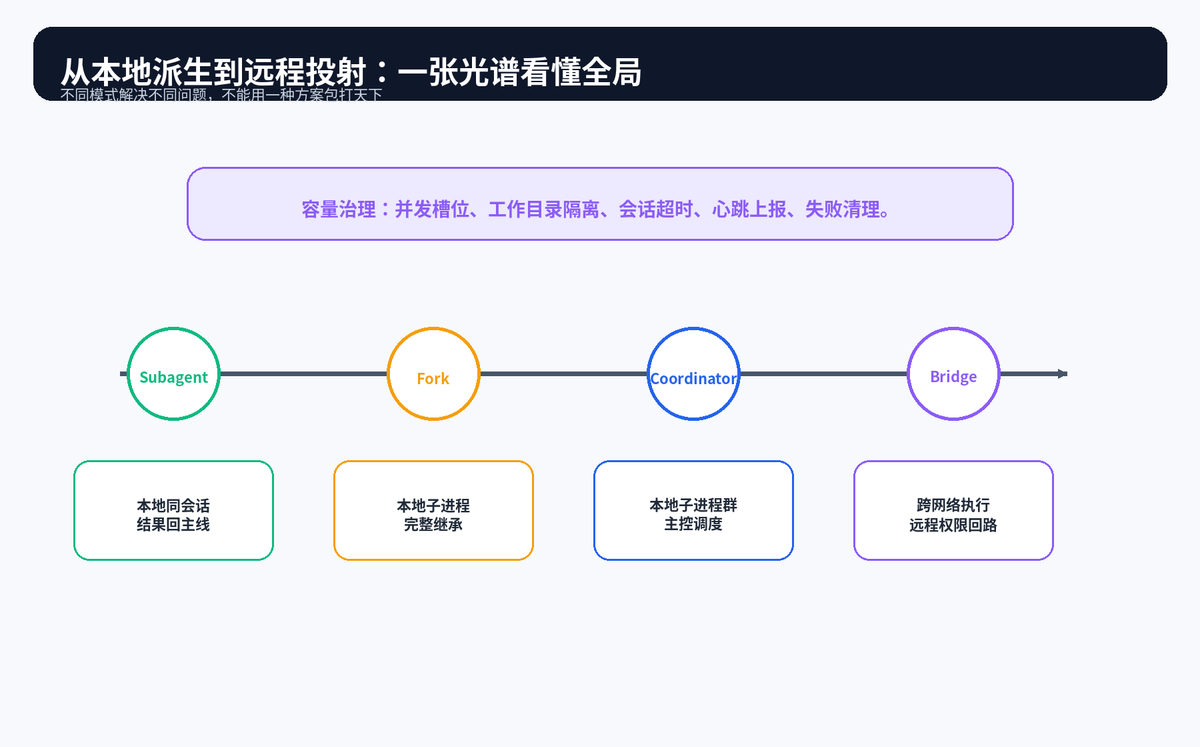
从本地派生到远程投射的能力光谱。
|--------------|---------------|--------------------|---------------------|
| 模式 | 最适合解决什么问题 | 最容易踩什么坑 | 治理重点 |
| Subagent | 主上下文被探索信息污染 | 任务描述太模糊,返回摘要不可用 | 给足必要上下文,限制工具能力 |
| Fork | 多个方向都需要当前完整现场 | 递归派生、缓存前缀被破坏 | 禁止递归,保持稳定前缀 |
| Coordinator | 跨模块、跨角色、强质量任务 | 主控只转述 Worker,不真正理解 | 主控必须消化证据并形成规格 |
| Verification | 实现后的质量兜底 | 只跑快乐路径,给出虚假通过 | 只读约束、对抗性探测、明确判定 |
| Bridge | 远端触发本地能力 | 权限、令牌、容量不可控 | 权限代理、续期调度、并发上限、超时清理 |
十二、企业落地:别急着堆 Agent,先把控制面做出来
很多团队做多 Agent,会先想着"我要开 10 个 Worker"。但真正难的不是数量,而是控制面。没有控制面,多 Agent 只会变成更贵、更乱、更难排查的单 Agent。
12.1 任务拆分要有边界
适合并行的任务,应该满足三个条件:输入边界清楚、输出可汇总、失败可隔离。如果任务之间强依赖、需要频繁互相等待,就不适合硬拆。
12.2 上下文要能回收
子 Agent 的探索结果不应该原封不动倒回主线,而应该沉淀成结论、证据、风险、下一步建议。主线需要的是高密度信息,不是原始噪声。
12.3 权限要按角色下发
探索者只读,实现者可写,验证者只读加临时测试,远程 Worker 走审批。把工具权限和角色绑定,是多 Agent 安全治理的核心。
12.4 缓存要从一开始设计
长上下文系统如果不设计缓存前缀,很快就会被成本和延迟拖垮。稳定内容放前面,变化内容放后面,缓存断点要尽量落在长期不变的边界上。
12.5 质量要用独立角色兜底
实现和验证不要完全混在一起。特别是生产级任务,应该有单独验证角色输出明确结论,并提供可复现证据。

十三、通俗总结:AI Agent 的未来,是"会分工的智能体系统"
单个 Agent 像一个能力很强的工程师,但复杂项目不是靠一个人闭门完成的。真正可落地的 AI 编程系统,需要探索者、实现者、验证者、协调者、远程执行器共同工作。
Subagent 解决上下文污染,Fork 解决完整现场下的并行探索,Coordinator 解决复杂任务调度,Verification 解决质量兜底,Bridge 解决远程触发与本地执行。它们组合起来,才构成一个可扩展、可审计、可恢复的 AI Agent 工程体系。
未来的竞争,不只是模型谁更强,而是谁能把 Agent 的上下文、工具、权限、缓存、验证、远程执行治理得更稳。换句话说,AI Agent 的上限看模型,下限看工程。
参考资料:https://pan.baidu.com/s/1Fm6rZSZkY3q2NcrmTfTMeQ?pwd=6fkr