逻辑回归的核心原理可以概括为以下几点:
-
理论基础:逻辑回归基于最大似然估计(MLE),通过最大化观测数据发生的概率来确定模型参数,而非使用最小二乘法。
-
损失函数:推导得出对数损失(LogLoss/交叉熵),其特点是:
- 对"盲目自信的错误预测"施加严厉惩罚
- 形成凸函数,保证优化过程能找到全局最优解
-
优化方法:由于无法直接求解,必须采用梯度下降等迭代算法:
- 将概率乘积转换为对数求和,避免数值计算问题
- 通过求导获得简洁的梯度表达式
-
概率解释:模型输出通过Sigmoid函数转换为概率,完美适配二分类问题的伯努利分布特性。
这种理论框架确保了逻辑回归在分类问题中的统计合理性,而梯度下降则提供了可行的参数优化路径。
逻辑回归 (Logistic Regression)
这里是重点:逻辑回归不使用"最小二乘法"。
-
为什么不用最小二乘法?
- 如果你强行把最小二乘法(平方损失)套在逻辑回归头上,因为那个 S 形的 Sigmoid 函数存在,你的损失函数图像会变成**"非凸的" (Non-convex)**。
- 人话解释: 图像会变得像波浪线一样,有很多个坑。梯度下降走进去,很容易掉进一个小坑(局部最优)就以为到底了,找不到真正的深渊(全局最优)。而且,你也推导不出一个像线性回归那样的直接求解公式。
-
那它基于什么?
- 理论基础: 最大似然估计 (Maximum Likelihood Estimation, MLE)。
- 损失函数: 推导出来的是对数损失 (Log Loss / Cross Entropy)。这个函数的图像是个完美的碗形(凸函数),只有一个底。
- 解题方法: 必须使用 梯度下降(或者更高级的牛顿法、L-BFGS等迭代算法)。逻辑回归没有"一步到位"的数学公式解。
结论: 逻辑回归的理论基础是最大似然估计 ,解法主要靠梯度下降。
| 算法模型 | 核心思想 (理论基础) | 损失函数 (评判标准) | 求解方法 (怎么算出权重) |
|---|---|---|---|
| 逻辑回归 | 最大似然估计 (MLE) | 对数损失 (Log Loss) | 只能用 梯度下降 (及其变种) |
最大似然和对数损失函数(讲人话)
这两个概念是逻辑回归(以及所有概率模型)的灵魂。我们抛开枯燥的公式,用**"侦探破案"和"严厉的老师"**这两个比喻来解释。
1. 最大似然估计 (Maximum Likelihood Estimation, MLE)
人话代号:逆向推理的侦探
想象这样一个场景:
你面前有一个黑盒子(模型),上面有两个旋钮(参数)。你不确定这两个旋钮应该拧到刻度几,才能最完美地解释你看到的现象。
侦探游戏:抛硬币
假设你捡到一枚硬币,你怀疑它做过手脚(灌了铅)。
- 实验: 你抛了 10 次,竟然 10 次都是正面朝上。
- 推测 A: 这是一枚普通硬币 (正面概率 50%)。
- 发生"10次全正"的概率是:0.5×0.5×...≈0.00090.5×0.5×...≈0.0009(万分之九)。
- 推测 B: 这是一枚作弊硬币 (正面概率 99%)。
- 发生"10次全正"的概率是:0.99×0.99×...≈0.900.99×0.99×...≈0.90(百分之九十)。
侦探(MLE)的逻辑:
"既然'10次全正'这件事已经实实在在发生了 ,那么推测 B 让这件事发生的概率最大(90% vs 0.09%)。所以,我有理由相信,这枚硬币就是作弊硬币!"
总结:
最大似然估计 就是一种**"事后诸葛亮"**的思维。
既然事情已经发生了,我们就反推:到底什么样的参数(旋钮),能让这件事情发生的概率最大? 那个参数就是我们要找的"最优解"。
2. 对数损失函数 (Log Loss)
人话代号:惩罚吹牛的严厉老师
在最大似然估计中,我们要算一连串概率的乘积 (例如 0.9×0.8×...0.9×0.8×...)。
这有两个大麻烦:
- 数值太小: 几十个零点几乘起来,结果接近于 0,计算机算不准(下溢出)。
- 不好算: 乘法求导很麻烦,加法求导很容易。
于是,数学家引入了 对数(Log) ,把乘法变成了加法。同时,为了配合梯度下降(它喜欢找最低点,不喜欢找最高点),我们加了个负号 。这就变成了对数损失。
它的评分标准非常特别:它不仅看你对不对,还看你"信不信"。
假设我们要预测一张图是不是猫(1是猫,0不是猫)。真实答案是:这是一只猫(1)。
- 学生小明(谦虚且对):
- 预测:是猫的概率 0.6。
- Log Loss 评价:虽然对了,但你不太自信。罚酒 1 杯(损失值小)。
- 学生小红(自信且对):
- 预测:是猫的概率 0.99。
- Log Loss 评价:非常自信且正确!不罚,甚至发小红花(损失值接近 0)。
- 学生小刚(犹豫且错):
- 预测:是猫的概率 0.4(意味着他觉得可能是狗)。
- Log Loss 评价:错是错了,好在你话没说死。罚酒 3 杯(损失值中等)。
- 学生小强(自信但大错特错------最惨):
- 预测:是猫的概率 0.01(他拍着胸脯说:这绝对不是猫!)。
- Log Loss 评价:直接拖出去枪毙!
- 原理: log(0.01)log(0.01) 是一个巨大的负数,取反后就是巨大的惩罚。
总结:
对数损失函数最痛恨**"盲目自信的错误"**。
- 如果你预测对了,且越自信(概率越接近1),损失越小。
- 如果你预测错了,且越自信(概率越接近0或1的极端),损失会呈指数级爆炸。
3. 两者的关系(一句话点破)
最大似然 是我们的**"指导思想"(我们要让模型最符合现实)。
对数损失是这个思想落地的"执行工具"**。
数学上:
最大化 似然函数(让好事发生的概率最大) ≈≈ 最小化 对数损失函数(让犯错的惩罚最小)。
它们是一枚硬币的两面,只是为了方便计算机算梯度,我们平时都只用"对数损失"。
最大似然和对数损失函数(数学推导)
简单来说,对数损失函数(Log Loss)并不是数学家拍脑袋想出来的,而是通过最大似然估计(MLE)严格推导出来的。
我们分四步来完成这个推导。
第一步:定义单个样本的概率公式
在二分类(Binary Classification)中,我们假设:
- y=1y=1 的概率是 hθ(x)hθ(x)。
- y=0y=0 的概率是 1−hθ(x)1−hθ(x)。
为了方便数学运算,我们需要把这两个式子合并成一个通项公式 。
利用 yy 只能取 0 或 1 的特性,我们可以写出**伯努利分布(Bernoulli Distribution)**公式:
P(y∣x;θ)=(hθ(x))y⋅(1−hθ(x))1−yP(y∣x;θ)=(hθ(x))y⋅(1−hθ(x))1−y
我们来验证一下是否正确:
- 当 y=1y=1 时:
P=(h)1⋅(1−h)0=h⋅1=hP=(h)1⋅(1−h)0=h⋅1=h
(对应 y=1y=1 的概率,正确) - 当 y=0y=0 时:
P=(h)0⋅(1−h)1=1⋅(1−h)=1−hP=(h)0⋅(1−h)1=1⋅(1−h)=1−h
(对应 y=0y=0 的概率,正确)
第二步:构建似然函数 (Likelihood Function)
现在的目标是:找到一组参数 θθ,使得所有样本(假设有 mm 个)同时发生的概率最大。
因为样本之间是独立 的,所以"所有样本同时发生"的总概率,就是每一个样本概率的乘积。
定义似然函数 L(θ)L(θ):
L(θ)=∏i=1mP(y(i)∣x(i);θ)L(θ)=∏i=1mP(y(i)∣x(i);θ)
L(θ)=∏i=1m(hθ(x(i)))y(i)⋅(1−hθ(x(i)))1−y(i)L(θ)=∏i=1m(hθ(x(i)))y(i)⋅(1−hθ(x(i)))1−y(i)
最大似然的核心思想: 我们要调节 θθ,让 L(θ)L(θ) 的值最大。
第三步:取对数 (Log-Likelihood)
上一步得到的 L(θ)L(θ) 是连乘积。连乘有两个坏处:
- 难算: 对连乘求导非常痛苦。
- 下溢出: 很多个 0.9、0.8 乘在一起,结果会迅速趋近于 0,计算机无法处理。
所以,我们两边同时取自然对数 (lnln 或 loglog) 。
利用对数性质:log(a⋅b)=loga+logblog(a⋅b)=loga+logb 和 log(ab)=blogalog(ab)=bloga。
得到对数似然函数 l(θ)l(θ):
l(θ)=logL(θ)l(θ)=logL(θ)
l(θ)=∑i=1mlog(hθ(x(i)))y(i)⋅(1−hθ(x(i)))1−y(i)l(θ)=∑i=1mlog(hθ(x(i)))y(i)⋅(1−hθ(x(i)))1−y(i)
利用加法和指数下沉的性质拆开:
l(θ)=∑i=1my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))l(θ)=∑i=1my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))
此时的目标依然是:最大化 (Maximize) l(θ)l(θ)。
第四步:转化为损失函数 (Loss Function)
在机器学习中,我们习惯做最小化 (Minimize) 任务(比如梯度下降是往山谷走,不是往山顶走)。
为了把"最大化似然"变成"最小化损失",我们需要做两个操作:
- 取负号: 最大化 AA 等价于最小化 −A−A。
- 取平均: 除以样本数 mm(为了让损失值不随样本数量增加而变大,标准化)。
于是,我们得到了最终的对数损失函数 (Log Loss / Cross Entropy):
J(θ)=−1ml(θ)J(θ)=−m1l(θ)
代入刚才的式子:
J(θ)=−1m∑i=1my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))J(θ)=−m1∑i=1my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))
总结推导逻辑链
- 概率模型: P=hy(1−h)1−yP=hy(1−h)1−y (巧妙利用0和1的特性)
- 似然函数: L=∏PiL=∏Pi (所有样本全对的概率,连乘)
- 对数似然: logL=∑logPilogL=∑logPi (为了好算,变乘为加)
- 损失函数: Loss=−1mlogLLoss=−m1logL (为了做梯度下降,变大为小)
这就是为什么逻辑回归的损失函数长成这个样子。它本质上就是带着负号的最大似然估计。
最大似然和对数损失函数(代码实现)
这段代码将通过可视化的方式,直观地展示对数损失函数(Log Loss)是如何工作的,以及 最大似然估计(MLE)与最小化损失之间的"镜像关系"。
代码包含两个核心可视化部分:
- 单样本视角:展示为什么预测错了要"重罚"(损失函数的形状)。
- 全局优化视角 :展示最大化似然 (找最高点)和最小化损失(找最低点)是如何殊途同归的。
Python 代码实现
python
import numpy as np
import matplotlib.pyplot as plt
# ==========================================
# 0. 基础函数定义
# ==========================================
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def calculate_log_loss(y_true, y_pred_prob):
# 加一个极小值 eps 防止 log(0) 报错
eps = 1e-15
y_pred_prob = np.clip(y_pred_prob, eps, 1 - eps)
# 公式: - [y * log(h) + (1-y) * log(1-h)]
return - (y_true * np.log(y_pred_prob) + (1 - y_true) * np.log(1 - y_pred_prob))
def calculate_log_likelihood(y_true, y_pred_prob):
eps = 1e-15
y_pred_prob = np.clip(y_pred_prob, eps, 1 - eps)
# 似然是概率乘积,对数似然是概率对数之和
# 公式: Σ [y * log(h) + (1-y) * log(1-h)]
return np.sum(y_true * np.log(y_pred_prob) + (1 - y_true) * np.log(1 - y_pred_prob))
# ==========================================
# 可视化 1: 单个样本的损失函数形状
# ==========================================
plt.figure(figsize=(12, 5))
# 模拟预测概率从 0.01 到 0.99
h = np.linspace(0.001, 0.999, 100)
# 情况 A: 真实标签 y=1 (是一只猫)
# 损失 = -log(h)
cost_y1 = -np.log(h)
# 情况 B: 真实标签 y=0 (不是猫)
# 损失 = -log(1-h)
cost_y0 = -np.log(1 - h)
plt.subplot(1, 2, 1)
plt.plot(h, cost_y1, 'b-', linewidth=3, label='y=1 (True is 1)')
plt.plot(h, cost_y0, 'r--', linewidth=3, label='y=0 (True is 0)')
plt.title("Log Loss Function (Single Sample)", fontsize=14)
plt.xlabel("Predicted Probability (h)", fontsize=12)
plt.ylabel("Loss / Cost", fontsize=12)
plt.legend(fontsize=12)
plt.grid(True, alpha=0.3)
# 添加文字说明
plt.text(0.1, 3, "Predict wrong\n(High Cost)", fontsize=10, color='red')
plt.text(0.7, 0.5, "Predict right\n(Low Cost)", fontsize=10, color='blue')
# ==========================================
# 可视化 2: 最大似然 vs 最小损失 (全局视角)
# ==========================================
# 1. 生成模拟数据
np.random.seed(42)
X = np.random.randn(50) # 50个样本
true_w = 2.0 # 真实的权重是 2.0
# 根据真实权重生成 y (概率采样)
probs = sigmoid(X * true_w)
y = np.random.binomial(1, probs)
# 2. 暴力搜索:假设我们不知道 w 是 2.0,我们试探从 -2 到 6 的各种 w
w_candidates = np.linspace(-2, 6, 100)
log_likelihoods = []
losses = []
for w in w_candidates:
# 预测概率
y_pred = sigmoid(X * w)
# 计算总对数似然 (Log Likelihood) -> 我们希望它最大
ll = calculate_log_likelihood(y, y_pred)
log_likelihoods.append(ll)
# 计算平均损失 (Log Loss / Cost) -> 我们希望它最小
# Loss = -1/m * LogLikelihood
loss = np.mean(calculate_log_loss(y, y_pred))
losses.append(loss)
# 3. 绘图对比
plt.subplot(1, 2, 2)
# 双Y轴绘制
ax1 = plt.gca()
ax2 = ax1.twinx()
# 画对数似然 (红色,找最高点)
line1, = ax1.plot(w_candidates, log_likelihoods, 'r-', linewidth=2, label='Log Likelihood (Maximize)')
ax1.set_xlabel('Parameter w (Weight)', fontsize=12)
ax1.set_ylabel('Log Likelihood (Sum)', color='r', fontsize=12)
ax1.tick_params(axis='y', labelcolor='r')
# 画损失函数 (蓝色,找最低点)
line2, = ax2.plot(w_candidates, losses, 'b--', linewidth=2, label='Log Loss (Minimize)')
ax2.set_ylabel('Log Loss / Cost (Mean)', color='b', fontsize=12)
ax2.tick_params(axis='y', labelcolor='b')
# 标出最优解
best_w_idx = np.argmax(log_likelihoods)
best_w = w_candidates[best_w_idx]
plt.axvline(x=best_w, color='green', linestyle=':', label='Optimal w')
plt.title(f"MLE vs Log Loss\nOptimal w ≈ {best_w:.2f} (True=2.0)", fontsize=14)
# 合并图例
lines = [line1, line2]
labels = [l.get_label() for l in lines]
ax1.legend(lines, labels, loc='center right')
plt.tight_layout()
plt.show()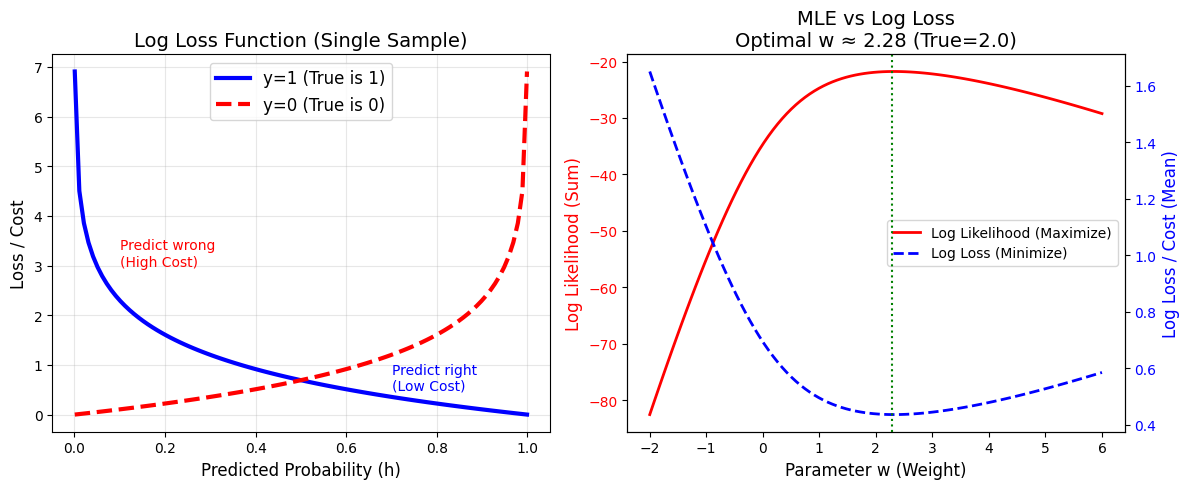
可视化图解
图一(左侧):单样本的赏罚机制
这张图展示了对数损失函数的核心逻辑:不要盲目自信。
- 蓝线 (当真实是 y=1 时):
- 如果你预测概率是 1.0(非常自信是对的),损失是 0。
- 如果你预测概率是 0.0(非常自信是错的),损失直接飙升到无穷大(图左侧蓝线陡峭上升)。
- 红线 (当真实是 y=0 时):
- 如果你预测概率是 0.0,损失是 0。
- 如果你预测概率是 1.0,损失飙升到无穷大。
结论: 对数损失函数是一个"严厉的老师",它对**Confidence(置信度)**非常敏感。
图二(右侧):最大似然 vs 最小损失
这张图展示了硬币的两面。X 轴是我们猜测的参数 ww(权重)。
- 红线 (Log Likelihood): 这是一个倒扣的碗。也就是最大似然估计。我们要爬到山顶(Maximize),山顶对应的 ww 大约是 2.0。
- 蓝线 (Log Loss): 这是一个正放的碗。也就是损失函数。我们要走到谷底(Minimize)。
- 绿线 (最优解): 你会发现,红线的最高点 ,垂直对下来的位置,正好也是蓝线的最低点。
结论:
数学推导中的 J(θ)=−1ml(θ)J(θ)=−m1l(θ) 在图上得到了完美验证。
最大化似然(让模型最像真的) 等价于 最小化对数损失(让犯错惩罚最小)。它们算出的是同一个最优参数。
最大似然和对数损失函数(逻辑回归中的应用)
在逻辑回归中,**最大似然估计(MLE)和对数损失函数(Log Loss)**并不是两个独立的东西,而是一套组合拳。
它们的应用流程可以概括为:MLE 制定战略,Log Loss 执行战术,梯度下降负责跑腿。
以下是它们在逻辑回归中应用的完整四步闭环:
第一步:确立目标(MLE 制定战略)
应用场景: 模型刚建立,甚至还没开始训练时。
逻辑回归的输出是一个概率值 y^y^(比如 0.8)。
面对一堆训练数据(有的 y=1y=1,有的 y=0y=0),我们到底想要什么样的参数 θθ(权重 ww 和偏置 bb)?
最大似然估计(MLE)站出来定调子:
"我们的终极目标是:找到一组参数 w,bw,b,使得模型预测出来的概率分布,最像真实发生的历史数据。"
- 如果某条数据真实是 1,模型预测的概率 y^y^ 就要越接近 1 越好。
- 如果某条数据真实是 0,模型预测的概率 y^y^ 就要越接近 0 越好。
- 应用体现: 这一步确定了我们的数学方向------我们要最大化所有样本预测正确概率的乘积(即似然函数 LL)。
第二步:转化难题(Log Loss 执行战术)
应用场景: 准备构建损失函数时。
MLE 虽然定好了目标(最大化乘积),但在计算机工程落地时遇到了两个大坑:
- 算不动: 几万个样本的概率(0.x)乘在一起,结果几乎等于 0(下溢出)。
- 不好求导: 乘法的导数极其复杂,没法做梯度下降。
对数损失函数(Log Loss)站出来解决问题:
它对 MLE 的公式做了"整容手术":
- 取对数: 把"连乘"变成了"求和"。
- 取负号: 把"最大化似然"变成了"最小化损失"(符合人类直觉:误差越小越好)。
应用体现:
逻辑回归最终使用的损失函数公式 ,就是这样诞生的:
J(θ)=−1m∑ylog(y\^)+(1−y)log(1−y\^)J(θ)=−m1∑ylog(y\^)+(1−y)log(1−y\^)
这步的意义: 如果没有 MLE 的理论支撑,我们就不知道为什么要用这个奇怪的 Log Loss 公式(为什么不用平方差 MSE?)。正是 MLE 告诉我们:对于 0/1 分类问题,Log Loss 才是统计学上的最优解。
第三步:指导方向(计算梯度)
应用场景: 训练过程中的每一次迭代。
现在有了 Log Loss 函数 J(θ)J(θ),它的图像是一个碗底形(凸函数)。
我们需要告诉计算机:参数 ww 和 bb 应该往大调,还是往小调?
应用体现:
我们对 Log Loss 函数进行求导(计算梯度) 。
因为 Log Loss 的特殊结构(包含对数),它和 Sigmoid 函数(包含指数)在一起求导时,会发生奇妙的化学反应------复杂的对数和指数互相抵消了!
最终算出的梯度非常简洁:
梯度=预测值−真实值=(y^−y)⋅x梯度=预测值−真实值=(y^−y)⋅x
- 如果 Log Loss 很大(预测严重错误),梯度就很大,参数调整幅度就大。
- 如果 Log Loss 很小(预测基本正确),梯度就很小,参数微调即可。
第四步:修正模型(参数更新)
应用场景: 梯度下降的最后一步。
根据上一步 Log Loss 提供的"梯度(方向和力度)",我们更新参数:
wnew=wold−学习率×梯度wnew=wold−学习率×梯度
总结:一句话理清关系
在逻辑回归中:
- 最大似然 (MLE) 是**"立法者":它从概率论的角度证明了,为了让模型最准,我们必须**优化"预测概率的对数"这一指标。
- 对数损失 (Log Loss) 是**"执法者":它把 MLE 的理论思想,固化成了一个具体的、计算机可运行的数学公式**。
- 此后,所有的训练过程(梯度下降),都是围绕着**"如何让 Log Loss 这个数字变小"**来进行的。