目 录
- [前 言](#前 言)
- [开 始](#开 始)
- 第一步:开始了解项目
- 第二步:生成测试用例
- 第三步:生成测试报告
- 第四步:重新测试
- [总 结](#总 结)
前 言
今天写这篇博客的目的不是继续推进项目,而是想把前阵子"玩"的一个工具的过程自己做一个复盘。一段时间以来总是听到Claude code这个工具非常的好用,但是百闻不如自己一试,于是我自己搞了一个claude code也想试试这个工具的效果。但是claude 关于使用地区的限制非常的严格,总是被封号,于是我研究了一周,终于搞到了claude pro。
但是千辛万苦搞到的账号,我担心接入claude code,不一定什么时候会被识别地址,这样会导致又被封号,所以我没敢在Claude code上使用claude,刚好deepseek升级了,推出了v4版本,这个版本对claude 提供支撑,索性我下载了cc switch,切换了claude code的脑子。但是功能都一样,可以用来测一测现在这个系统的情况。
开 始
切换完claude code的大脑,可以看到使用的模型变成了deepseek。这个工具最大的特点就是可以在命令行,操控智能体,让他可以直接操作项目下的文件。
第一步:开始了解项目
所有的开始当然离不开第一步,项目下我放了readme项目介绍文件,所以第一步当然理所当然,让claude code先了解项目是什么,然后才能让他开始测试项目。

第二步:生成测试用例
当智能体了解了项目的背景后,下一步便是让他生成一些测试用例,这样无论当项目怎么改,我都可以有一个通用的测试用例,用来测试系统。
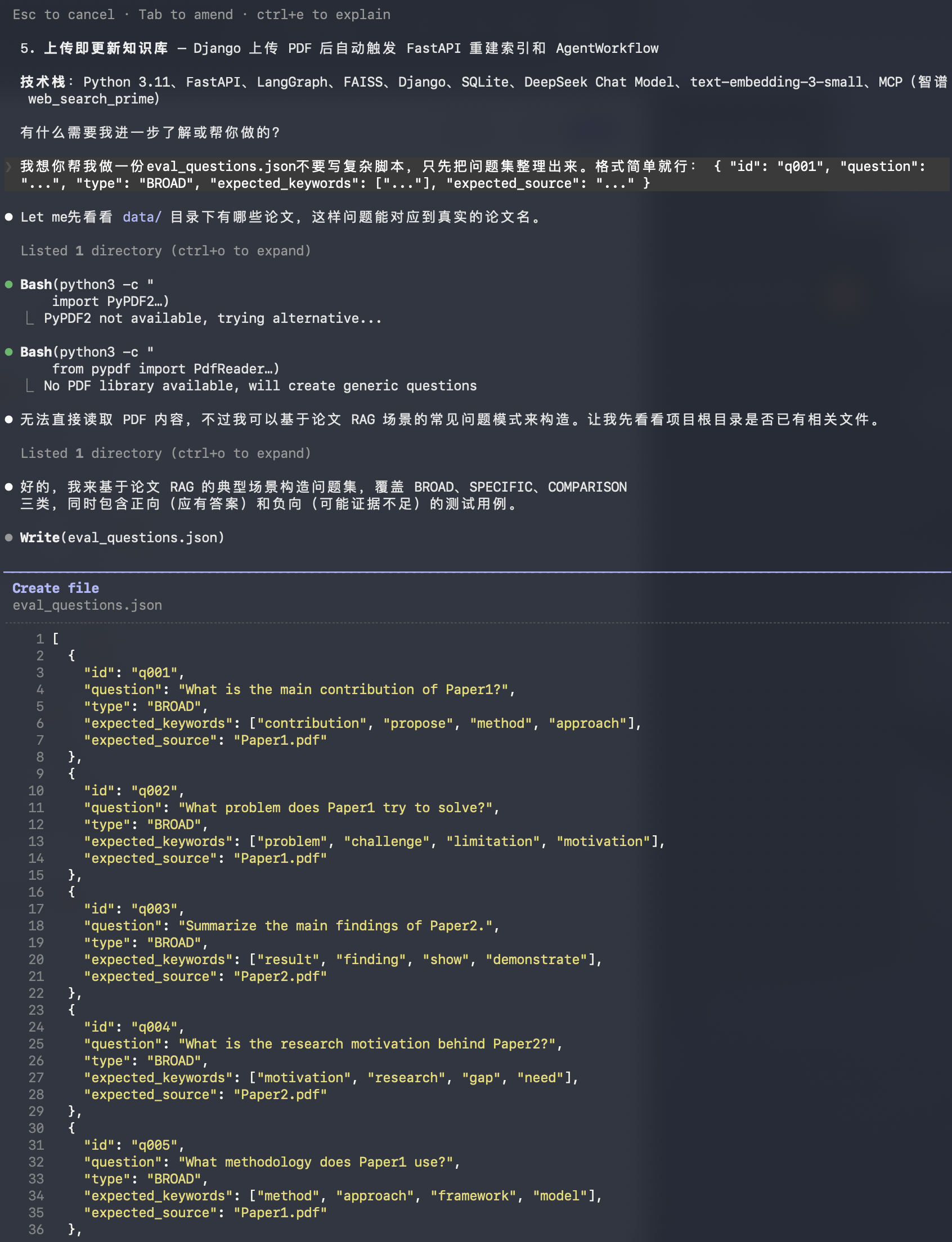
其实很快,只要给claude code描述清楚想要测试的输入格式,他可以很快的为我生成相应的测试用例。
json
[
{
"id": "q001",
"question": "What is the main contribution of Paper1?",
"type": "BROAD",
"expected_keywords": ["contribution", "propose", "method", "approach"],
"expected_source": "Paper1.pdf"
},
{
"id": "q002",
"question": "What problem does Paper1 try to solve?",
"type": "BROAD",
"expected_keywords": ["problem", "challenge", "limitation", "motivation"],
"expected_source": "Paper1.pdf"
},
{
"id": "q003",
"question": "Summarize the main findings of Paper2.",
"type": "BROAD",
"expected_keywords": ["result", "finding", "show", "demonstrate"],
"expected_source": "Paper2.pdf"
},
{
"id": "q004",
"question": "What is the research motivation behind Paper2?",
"type": "BROAD",
"expected_keywords": ["motivation", "research", "gap", "need"],
"expected_source": "Paper2.pdf"
},
{
"id": "q005",
"question": "What methodology does Paper1 use?",
"type": "BROAD",
"expected_keywords": ["method", "approach", "framework", "model"],
"expected_source": "Paper1.pdf"
},
{
"id": "q006",
"question": "What datasets were used in the experiments of Paper1?",
"type": "SPECIFIC",
"expected_keywords": ["dataset", "data", "experiment", "evaluation"],
"expected_source": "Paper1.pdf"
},
{
"id": "q007",
"question": "What evaluation metrics are reported in Paper2?",
"type": "SPECIFIC",
"expected_keywords": ["metric", "accuracy", "performance", "score", "F1"],
"expected_source": "Paper2.pdf"
},
{
"id": "q008",
"question": "What is the difference between Paper1 and Paper2?",
"type": "COMPARISON",
"expected_keywords": ["difference", "compare", "whereas", "in contrast"],
"expected_source": "Paper1.pdf / Paper2.pdf"
},
{
"id": "q009",
"question": "Which method performs better, the one in Paper1 or Paper2?",
"type": "COMPARISON",
"expected_keywords": ["better", "outperform", "superior", "compare"],
"expected_source": "Paper1.pdf / Paper2.pdf"
},
{
"id": "q010",
"question": "Are the approaches in Paper1 and Paper2 complementary or competing?",
"type": "COMPARISON",
"expected_keywords": ["complementary", "competing", "similar", "different"],
"expected_source": "Paper1.pdf / Paper2.pdf"
},
{
"id": "q011",
"question": "What are the key limitations discussed in Paper1?",
"type": "SPECIFIC",
"expected_keywords": ["limitation", "future work", "drawback", "weakness"],
"expected_source": "Paper1.pdf"
},
{
"id": "q012",
"question": "Does Paper2 propose a novel architecture? Describe it.",
"type": "SPECIFIC",
"expected_keywords": ["architecture", "novel", "design", "structure"],
"expected_source": "Paper2.pdf"
},
{
"id": "q013",
"question": "How does Paper1 handle the cold-start problem?",
"type": "SPECIFIC",
"expected_keywords": ["cold-start", "initialization", "warm-up"],
"expected_source": "Paper1.pdf"
},
{
"id": "q014",
"question": "Does Paper1 mention quantum computing?",
"type": "SPECIFIC",
"expected_keywords": [],
"expected_source": ""
},
{
"id": "q015",
"question": "Does Paper2 discuss transformer architectures in detail?",
"type": "SPECIFIC",
"expected_keywords": ["transformer", "attention", "encoder", "decoder"],
"expected_source": "Paper2.pdf"
},
{
"id": "q016",
"question": "What is the core theoretical foundation behind the approach in Paper1?",
"type": "BROAD",
"expected_keywords": ["theory", "foundation", "principle", "based on"],
"expected_source": "Paper1.pdf"
},
{
"id": "q017",
"question": "What ablation studies are conducted in Paper2?",
"type": "SPECIFIC",
"expected_keywords": ["ablation", "remove", "component", "variant"],
"expected_source": "Paper2.pdf"
},
{
"id": "q018",
"question": "How does Paper2 compare its results against baselines?",
"type": "SPECIFIC",
"expected_keywords": ["baseline", "compare", "outperform", "improvement"],
"expected_source": "Paper2.pdf"
},
{
"id": "q019",
"question": "What are the shared assumptions between Paper1 and Paper2?",
"type": "COMPARISON",
"expected_keywords": ["assume", "assumption", "common", "share", "both"],
"expected_source": "Paper1.pdf / Paper2.pdf"
},
{
"id": "q020",
"question": "Do Paper1 and Paper2 address the same research problem?",
"type": "COMPARISON",
"expected_keywords": ["same", "problem", "research", "address", "focus"],
"expected_source": "Paper1.pdf / Paper2.pdf"
},
{
"id": "q021",
"question": "What future research directions does Paper2 suggest?",
"type": "SPECIFIC",
"expected_keywords": ["future work", "direction", "extend", "explore"],
"expected_source": "Paper2.pdf"
},
{
"id": "q022",
"question": "Does Paper1 use reinforcement learning?",
"type": "SPECIFIC",
"expected_keywords": ["reinforcement learning", "RL", "reward", "policy"],
"expected_source": "Paper1.pdf"
}
]当然他的自动化程度相当的高,甚至有些能力我自己都没想到,我在项目的readme文档中有提过系统会根据用户的问题类型决定LLM gate的通过性,果然claude code他看到了相关内容,结果他在设计用例的时候就照顾到了三个类型的问题:
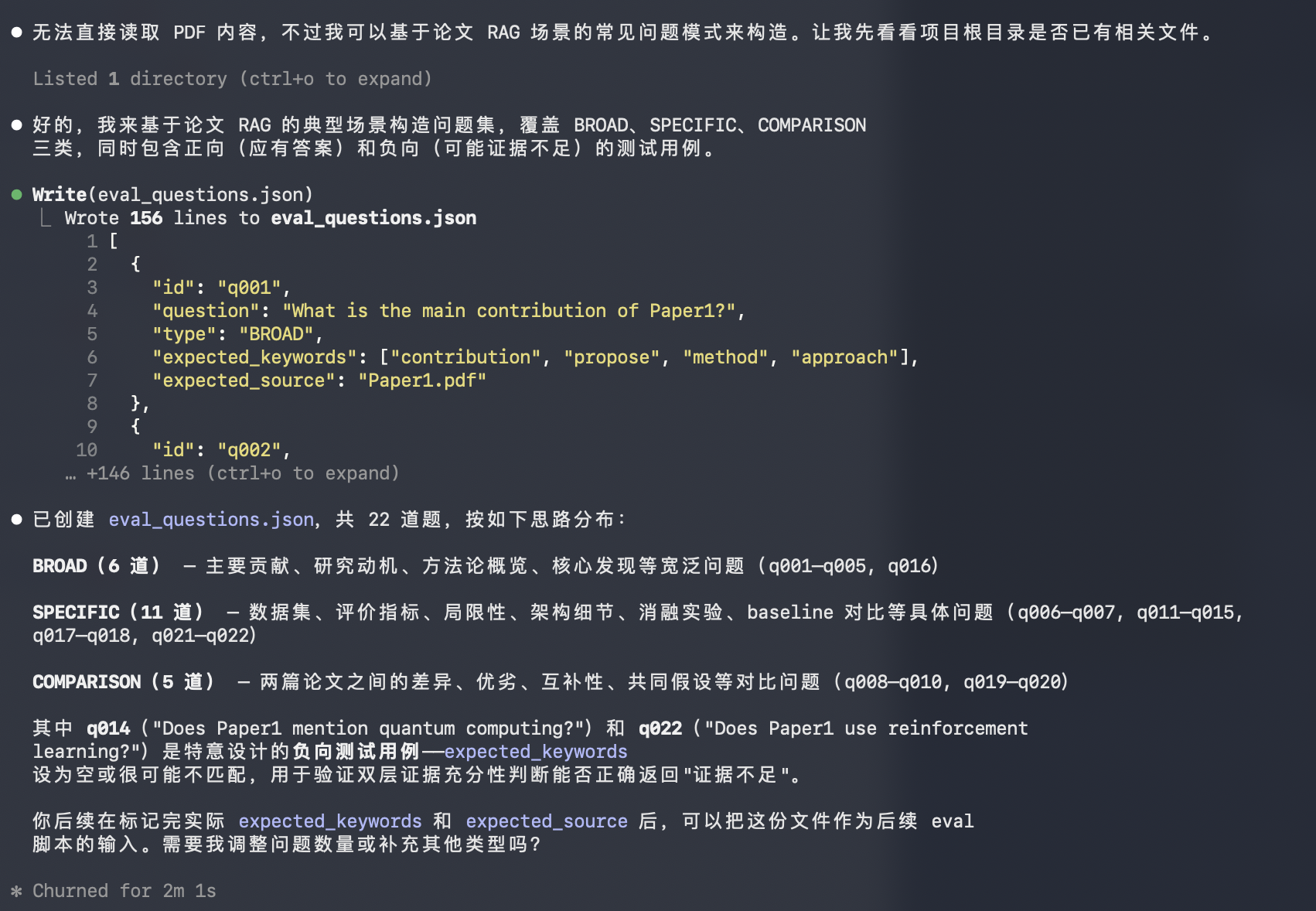
第三步:生成测试报告
这个命令行的功能可以说让我惊掉下吧,我再跟他说:"请基于刚刚的测试用例完成测试"后,claude code便自己启动了FastAPI,然后一条条的测试用例跑,最终返回给我一个eval_run_result.md的测试报告。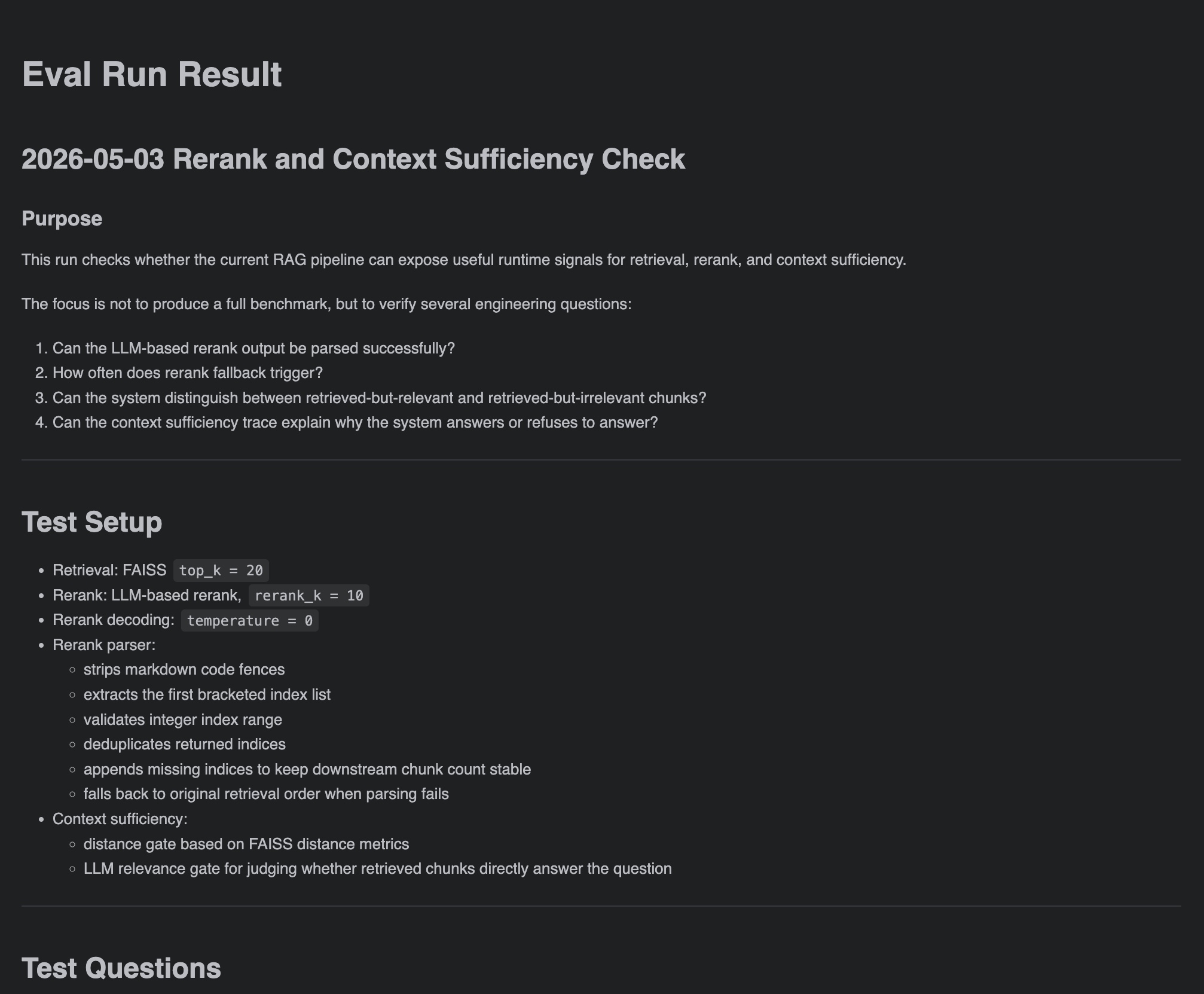
报告中有列出详细的测试表格,并且给出了系统的修改建议:
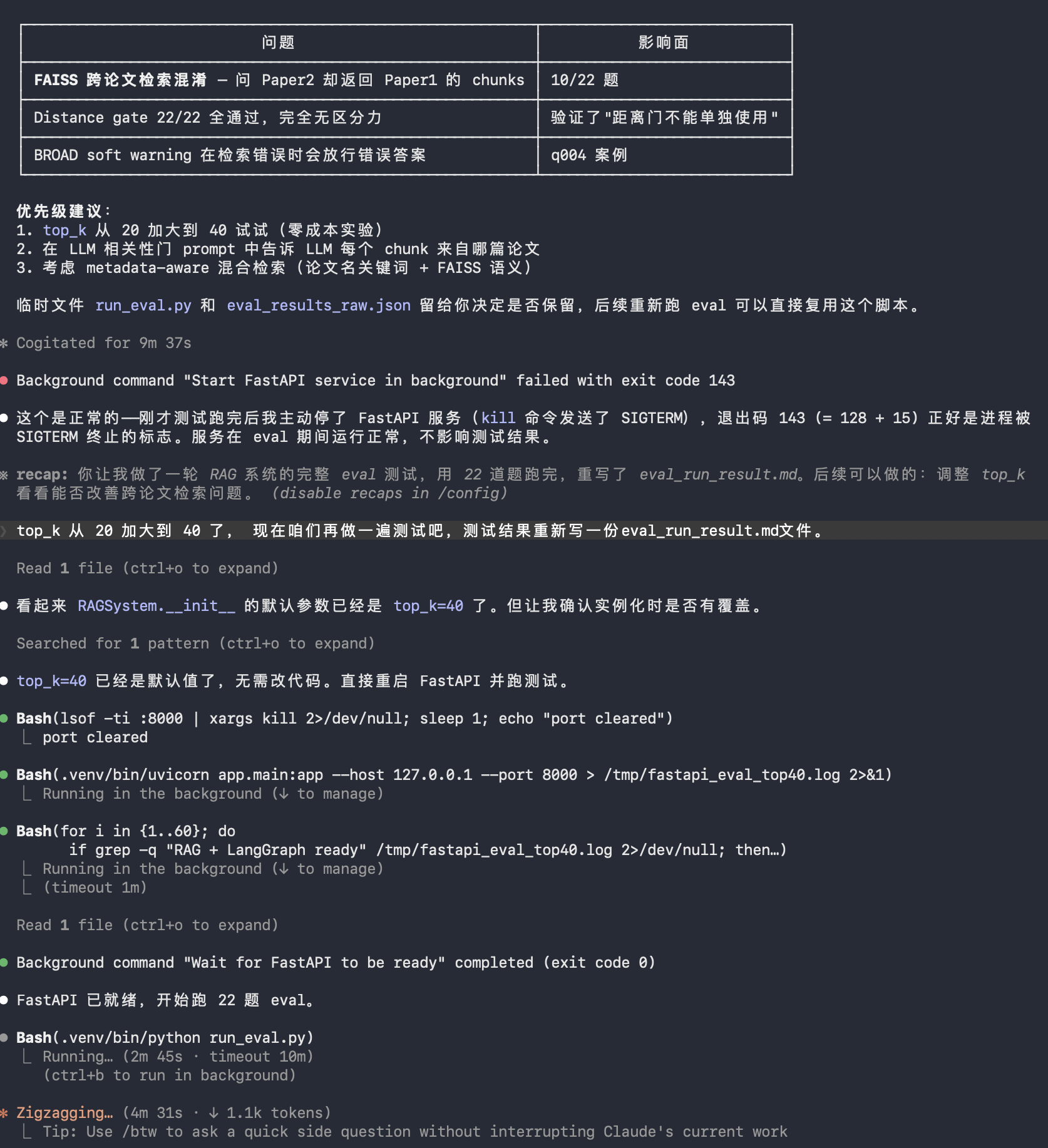
其实可以看到结果他有建议我将top-k从20改到40,重新测试。
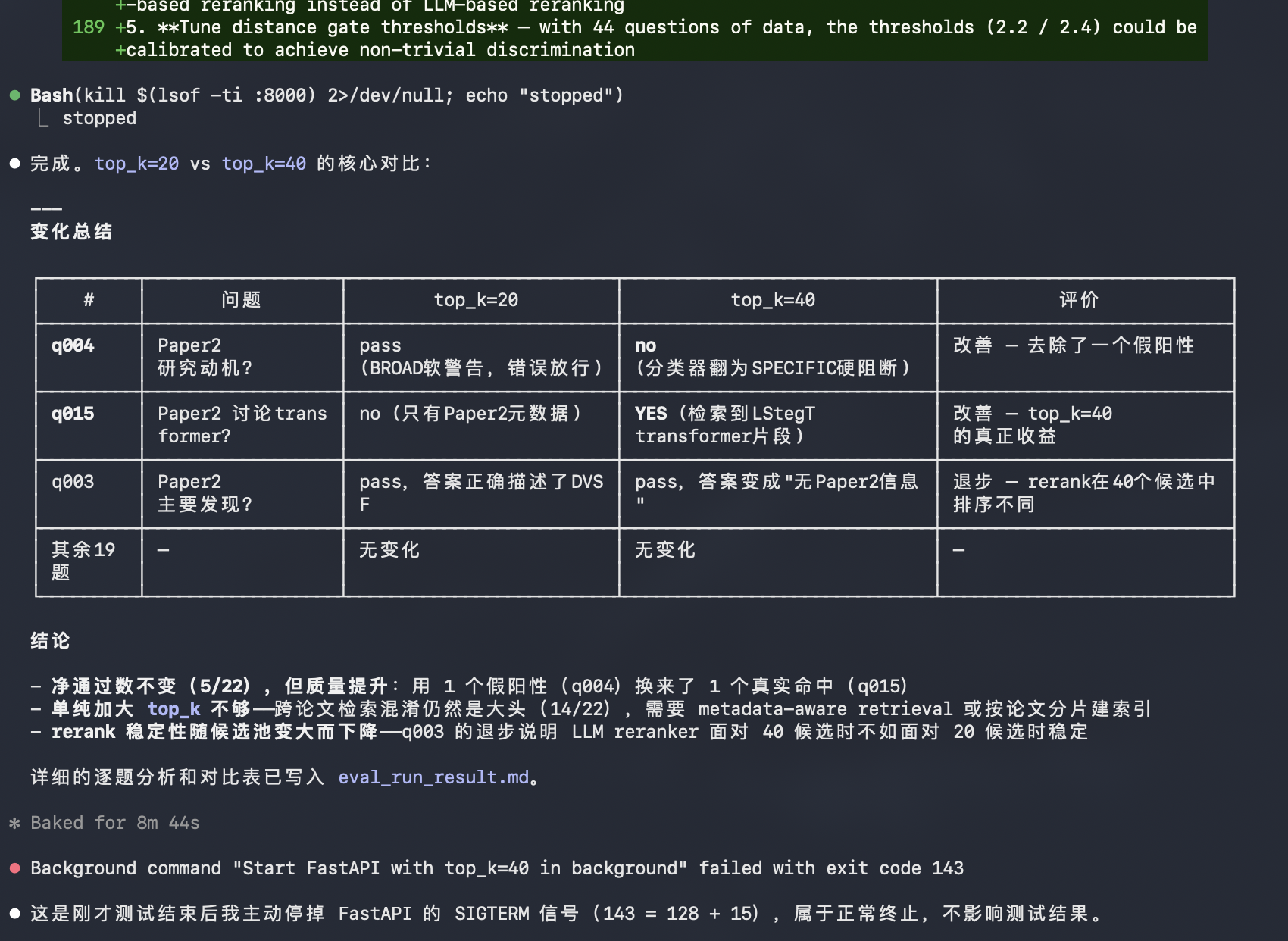
第四步:重新测试
重新测试后发现增大top-k的阈值,并没有给系统的性能带来多大的提升,所以后面我又将top-k改了回去。
总 结
从记录情况来看,我个人感觉,随着ai工具的发展,其实现在很多工作基本不需要人了,但是测试用例的设计,以及以一个什么样的标准验收,还是人设计的。可能未来对测试工程师的要求是能想到机器想不到的一些问题或者测试用例,这样的测试工程师可能在今天ai时代体现出独特价值。但是并不是说为了独特而独特,测试工程师可能需要想到黑客和极端用户能提出的非常规问题。