一、线性回归简介
1. 定义
线性回归(Linear Regression)是一种有监督学习算法,主要用于回归任务。它的目标是:找到一个线性函数,能够尽可能准确地描述**输入特征(X)与连续输出(y)**之间的依赖关系。
核心思想:用一条直线(或超平面)拟合数据,使得所有样本的预测误差最小。
2. 线性回归分类
根据特征的数量,可以分为一元线性回归和多元线性回归。
- 一元线性回归
- 特点:1个特征列,1个标签列
- 公式:y^=wx+b\hat{y} = wx + by^=wx+b
- 多元线性回归
- 特点:多个特征列,1个标签列
- 公式:y^=w1x1+w2x2+⋯+wnxn+b=wTx+b\hat{y} = w_1x_1 + w_2x_2 + \dots + w_nx_n + b = \mathbf{w}^T \mathbf{x} + by^=w1x1+w2x2+⋯+wnxn+b=wTx+b
参数说明: x为特征,w为权重(斜率),b为偏置(截距), y^\hat yy^为预测值
3. 应用场景
线性回归是对一个或多个自变量和因变量之间关系进行建模分析的方法,所以被广泛应用于以下场景:
- 房价预测:根据楼层、面积、卧室数量等预测价格
- 销售预测:根据时间特征、历史销量、外部特征(如优惠政策、市场营销费用)等预测销量
- 金融量化:根据市盈率 PE、动量因子、换手率预测收益率
二、线性回归问题的求解
线性回归问题的想要更好拟合所有样本点,则需要引入损失函数,通过一个优化方法,求损失函数的最小值,以便得到权重w的最优解。
1. 损失函数
用于衡量每个样本点真实值与预测值之间效果(误差)的函数,称为损失函数,也叫代价函数,成本函数。
2. 损失函数的优化方法
2.1最小二乘法
最小二乘法是直接通过数学公式计算所有样本的误差平方和,利用求导、求偏导、矩阵计算等方法,推演计算出损失函数的最小值。
- 公式:w=(XTX)−1XTy\mathbf{w} = (X^T X)^{-1} X^T \mathbf{y}w=(XTX)−1XTy
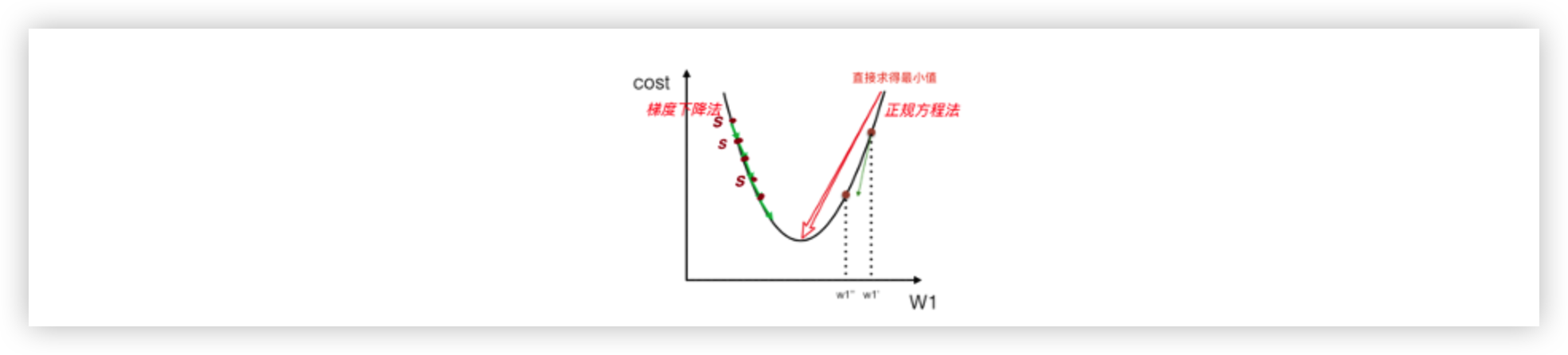
2.2. 梯度下降算法
梯度下降算法是通过不断迭代更新参数,逐步降低损失函数。顾名思义,沿着梯度下降的方向求解极小值。
- 公式:wj:=wj−α∂∂wjMSEw_j := w_j - \alpha \frac{\partial}{\partial w_j} \text{MSE}wj:=wj−α∂wj∂MSE
公式说明:下个点 = 当前点 - 学习率 * 损失函数,α为学习率\alpha 为学习率α为学习率
- 算法思想
举例:坡度最陡下山法
- 输入:初始化位置S,每步距离为a。输出:从位置S到达山底
- 步骤1:令初始化位置为山的任意位置S
- 步骤2:在当前位置环顾四周,如果四周都比S高则说明已到达最低点,返回S;否则执行步骤3
- 步骤3:在当前位置环顾四周,寻找坡度最陡的方向,令其为x方向
- 步骤4:沿着x方向往下走,长度为a,到达新的位置S'
- 步骤5:在S'位置环顾四周,如果四周都比S' 高则说明已到达最低点,返回S' ;否则执行步骤3
小结: 通过循环迭代的方法不断更新位置S(相当于不断更新权重参数w),最终找到损失函数的最优解,这个方法比最小二乘法更通用。
- 常见的分类
- 全梯度下降算法(Full Gradient Descent,FGD),每次迭代时,使用全部样本的梯度
- 随机梯度下降算法(SGD),每次迭代时,随机选择并使用一个样本的梯度值
- 小批量梯度下降算法(Min-Batch) ,每次迭代时,随机选择并使用小批量的样本的梯度值,从m个样本中,选择x个样本进行迭代(1< x < m)
- 随机平均梯度下降算法(SAG) ,每次迭代时,随机选择一个样本的梯度值和以往样本的梯度值的均值
特点
- 全梯度下降算法FGD:由于使用了全部数据集,训练速度较慢
- 随机梯度下降算法SGD:简单、高效,不稳定。遇到噪声则容易陷入局部最优解
- 小批量梯度下降算法Min-Batch :避开了FGD的运算效率低成本大和SGD收敛效果不好的缺点,表现居于FGD和SGD二者之间。
随机平均梯度下降算法SAG:训练初期表现不佳,优化速度较慢。这是因为我们常将初始梯度设置为0,而SAG每轮梯度更新都结合了上一轮梯度值
2.3. 最小二乘法与梯度下降法的对比
| 梯度下降 | 最小二乘法 |
|---|---|
| 需要选择学习率 | 不需要学习率 |
| 需要迭代求解 | 一次运算得出,一蹴而就 |
| 适合大规模数据、高维特征 | 适合小数据量、精准的数据 |
| 缺点:需要调参,可能陷入局部最优(但对线性回归MSE是凸函数,收敛到全局最优) | 缺点:计算量大,容易受到噪声、特征强相关性的影响 |
| 注意:在各种损失函数中被大量使用。在深度学习中,只能通过迭代的方式求最优解 | 注意:XTXX^T XXTX的逆矩阵不存在时,无法求解。计算XTXX^T XXTX的逆矩阵非常耗时 |
三、回归模型评估方法
我们希望衡量真实值与预测值之间的差距,会用到多种测评函数进行评价。
1. 平均绝对误差
平均绝对误差(Mean Absolute Error,MAE) = 每个样本点误差绝对值之和 / 样本总数。
- 公式:MAE=1n∑i=1n∣yi−y^i∣MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|MAE=n1∑i=1n∣yi−y^i∣
上面的公式中:n 为样本数量, y 为实际值, y^\hat{y}y^ 为预测值。MAE 越小模型预测约准确
2. 均方误差
均方误差(Mean Squared Error ,MSE) = 每个样本点误差平方和 / 样本总数。
- 公式:MSE=1n∑i=1n(yi−y^i)2MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2MSE=n1∑i=1n(yi−y^i)2
上面的公式中:n 为样本数量, y 为实际值, y^\hat{y}y^ 为预测值。MSE 越小模型预测约准确
3. 均方根误差
均方根误差(Root Mean Squared Error ,RMSE) = 每个样本点误差平方和 / 样本总数,再开平方根,即均方误差开平方根
- 公式:RMSE=1n∑i=1n(yi−y^i)2RMSE = \sqrt{ \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 }RMSE=n1∑i=1n(yi−y^i)2
上面的公式中:n 为样本数量, y 为实际值, y^\hat{y}y^ 为预测值。RMSE 越小模型预测约准确
4. 三种指标的比较
我们绘制了一条直线 y = 2x +5 用来拟合 y = 2x + 5 + e. 这些数据点,其中e为噪声
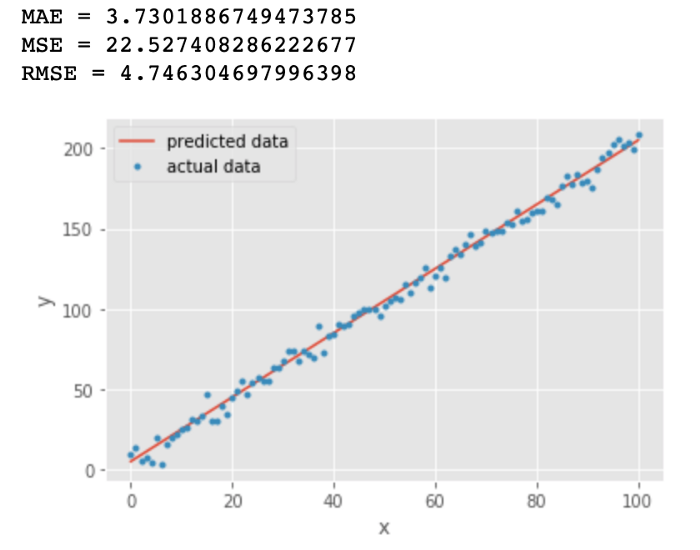
从上图中我们发现 MAE 和 RMSE 非常接近,都表明模型的误差很低(MAE 或 RMSE 越小,误差越小!)。 但是MAE 和 RMSE 有什么区别?为什么MAE较低?
-
对比MAE 和 RMSE的公式,RMSE的计算公式中有一个平方项,因此:大的误差将被平方,因此会增加 RMSE 的值
-
可以得出结论,RMSE 会放大预测误差较大的样本对结果的影响,而 MAE 只是给出了平均误差
-
由于 RMSE 对误差的 平方和求平均 再开根号,大多数情况下RMSE>MAE
举例 (1+3)/2 = 2 (12+32)/2=10/2=5=2.236\sqrt{(1^2+3^2)/2 }= \sqrt{10/2} = \sqrt{5} = 2.236(12+32)/2 =10/2 =5 =2.236
我们再看下一个例子
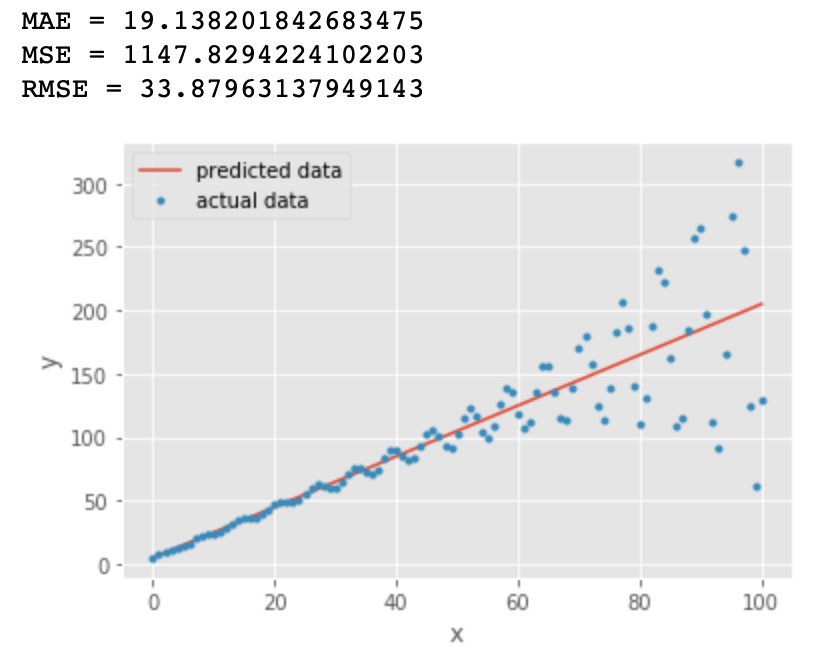
橙色线与第一张图中的直线一样:y = 2x +5
蓝色的点为: y = y + sin(x)*exp(x/20) + e 其中 exp() 表示指数函数
我们看到对比第一张图,所有的指标都变大了,RMSE 几乎是 MAE 值的两倍,因为它对预测误差较大的点比较敏感
我们是否可以得出结论: RMSE是更好的指标? 某些情况下MAE更有优势,例如:
- 假设数据中有少数异常点偏差很大,如果此时根据 RMSE 选择线性回归模型,可能会选出过拟合的模型来
- 在这种情况下,由于数据中的异常点极少,选择具有最低 MAE 的回归模型可能更合适
- 除此之外,当两个模型计算RMSE时数据量不一致,也不适合在一起比较
四、线性回归API和案例
1. 线性回归方程
python
"""
案例:
演示正规方程法 线性回归对象 完成波士顿房价预测案例.
回顾:
线性回归算法 属于 有监督学习之 有特征, 有标签, 且标签是连续的
线性回归分类:
一元线性回归: 1个特征列, 1个标签列
多元线性回归: 多个特征列, 1个标签列
线性回归大白话解释:
它是用线性公式来描述 特征 和 标签之间关系的, 方便做预测, 公式如下:
一元线性回归: y = wx + b
多元线性回归: y = w1 * x1 + w2 * x2 + w3 * x3 + ... + wn * xn + b = w的转置 * x + b
如何衡量线性回归模型的好坏?
思路:
预测值和真实值之间的误差, 误差越小, 模型越好 => 损失函数
具体方案:
1. 最小二乘 每个样本误差平方和
2. 均方误差(MSE) 每个样本误差平方和 / 样本总数
3. 均方根误差(RMSE) 每个样本误差平方和 / 样本总数 开平方根
4. 平均绝对误差(MAE) 每个样本误差绝对值和 / 样本总数
如何让损失函数最小?
思路1: 梯度下降法 => 全梯度下降(Full Gradient Descent, FGD), 随机梯度下降(SGD), 小批量梯度下降(Min-Batch), 随机平均梯度下降(SAG)
思路2: 正规方程法
机器学习开发流程:
1. 加载数据
2. 数据预处理
3. 特征工程(特征提取, 特征预处理...)
4. 模型训练
5. 模型预测
6. 模型评估
"""
from pydantic.experimental.pipeline import transform
# 导包
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error, root_mean_squared_error, mean_absolute_error
import pandas as pd
import numpy as np
# 1. 加载数据
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) # np.hstack()函数作用: 水平拼接数组
target = raw_df.values[1::2, 2]
print(f'特征: {data.shape}')
print(f'标签: {target.shape}')
print(f'特征数据: {data[:5]}')
print(f'标签数据: {target[:5]}')
# 2. 数据预处理, 切分训练集 和 测试集
# 参1: 特征数据, 参2: 标签数据, 参3: 测试集占训练集的比例, 参4: 随机种子
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=23)
# 3. 特征工程(特征提取, 特征预处理...)
# 3.1 创建标准化对象
transfer = StandardScaler()
# 3.2 对训练集进行标准化
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4. 模型训练
# 4.1 创建 线性回归 正规方程 模型对象
# 参数: 是否需要偏置
estimator = LinearRegression(fit_intercept=True)
# 4.2 模型训练
estimator.fit(x_train, y_train)
# 4.3 打印模型计算出的 w(权重, weight) 和 b(偏置, bias)
print(f'权重:{estimator.coef_}')
print(f'偏置:{estimator.intercept_}')
# 5. 模型预测
y_pred = estimator.predict(x_test)
print(f'预测结果: {y_pred}')
# 6. 模型评估
# 参1: 测试集的标签数据, 参2: 预测结果
print(f'均方误差: {mean_squared_error(y_test, y_pred)}')
print(f'均方根误差: {root_mean_squared_error(y_test, y_pred)}')
print(f'平均绝对误差: {mean_absolute_error(y_test, y_pred)}')2. 梯度下降算法
python
"""
案例:
演示正规方程法 线性回归对象 完成波士顿房价预测案例.
回顾:
线性回归算法 属于 有监督学习之 有特征, 有标签, 且标签是连续的
线性回归分类:
一元线性回归: 1个特征列, 1个标签列
多元线性回归: 多个特征列, 1个标签列
线性回归大白话解释:
它是用线性公式来描述 特征 和 标签之间关系的, 方便做预测, 公式如下:
一元线性回归: y = wx + b
多元线性回归: y = w1 * x1 + w2 * x2 + w3 * x3 + ... + wn * xn + b = w的转置 * x + b
如何衡量线性回归模型的好坏?
思路:
预测值和真实值之间的误差, 误差越小, 模型越好 => 损失函数
具体方案:
1. 最小二乘 每个样本误差平方和
2. 均方误差(MSE) 每个样本误差平方和 / 样本总数
3. 均方根误差(RMSE) 每个样本误差平方和 / 样本总数 开平方根
4. 平均绝对误差(MAE) 每个样本误差绝对值和 / 样本总数
如何让损失函数最小?
思路1: 梯度下降法 => 全梯度下降(Full Gradient Descent, FGD), 随机梯度下降(SGD), 小批量梯度下降(Min-Batch), 随机平均梯度下降(SAG)
思路2: 正规方程法
机器学习开发流程:
1. 加载数据
2. 数据预处理
3. 特征工程(特征提取, 特征预处理...)
4. 模型训练
5. 模型预测
6. 模型评估
"""
# 导包
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error, root_mean_squared_error, mean_absolute_error
import pandas as pd
import numpy as np
# 1. 加载数据
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) # np.hstack()函数作用: 水平拼接数组
target = raw_df.values[1::2, 2]
print(f'特征: {data.shape}')
print(f'标签: {target.shape}')
print(f'特征数据: {data[:5]}')
print(f'标签数据: {target[:5]}')
# 2. 数据预处理, 切分训练集 和 测试集
# 参1: 特征数据, 参2: 标签数据, 参3: 测试集占训练集的比例, 参4: 随机种子
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=23)
# 3. 特征工程(特征提取, 特征预处理...)
# 3.1 创建标准化对象
transfer = StandardScaler()
# 3.2 对训练集进行标准化
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4. 模型训练
# 4.1 创建 线性回归 随机梯度下降 模型对象
# 参1: 是否需要偏置
# 参2: 学习率模式 -> 常量, 即不会发生改变
# 参3: 学习率值
estimator = SGDRegressor(fit_intercept=True, learning_rate='constant', eta0=0.01)
# 4.2 模型训练
estimator.fit(x_train, y_train)
# 4.3 打印模型计算出的 w(权重, weight) 和 b(偏置, bias)
print(f'权重:{estimator.coef_}')
print(f'偏置:{estimator.intercept_}')
# 5. 模型预测
y_pred = estimator.predict(x_test)
print(f'预测结果: {y_pred}')
# 6. 模型评估
# 参1: 测试集的标签数据, 参2: 预测结果
print(f'均方误差: {mean_squared_error(y_test, y_pred)}')
print(f'均方根误差: {root_mean_squared_error(y_test, y_pred)}')
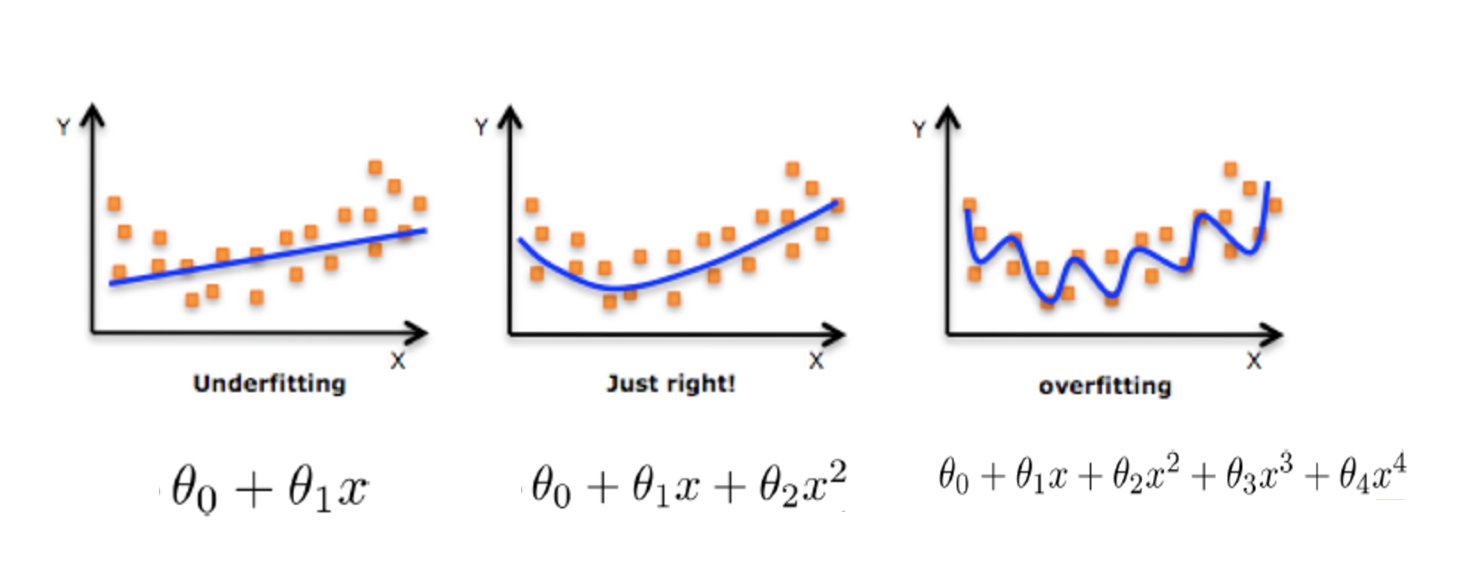
print(f'平均绝对误差: {mean_absolute_error(y_test, y_pred)}')五、欠拟合与过拟合
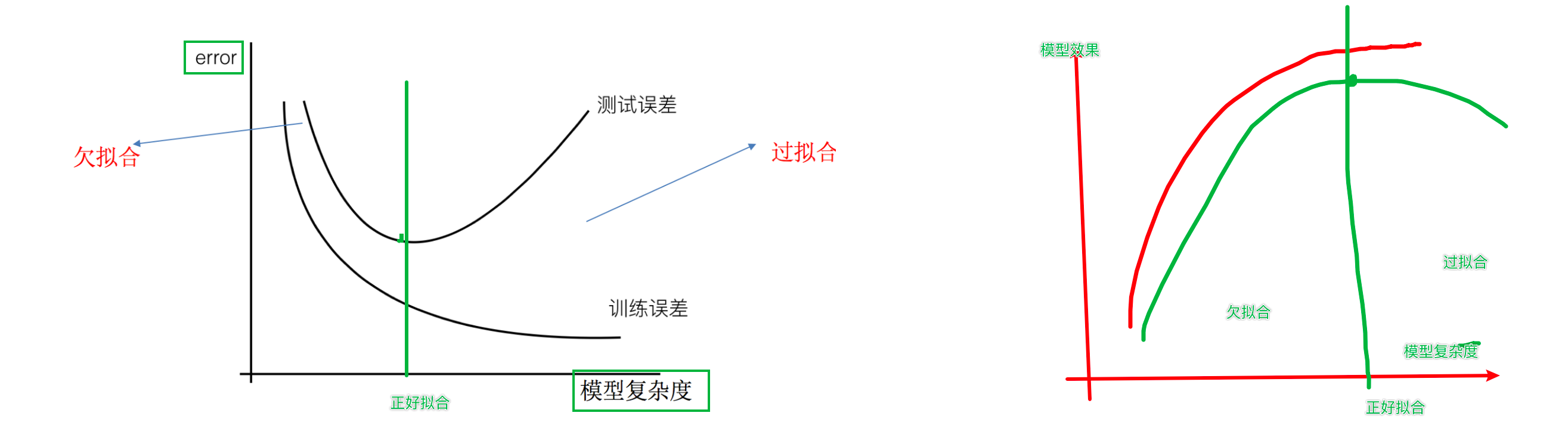
通常我们使用拟合的好坏来评估模型的效果,一般分为欠拟合、过拟合。
1. 概念
- 过拟合
一个假设 在训练数据上能够获得比其他假设更好的拟合, 但是在测试数据集上却不能很好地拟合数据 (体现在准确率下降),此时认为这个假设出现了过拟合的现象。一句话理解,模型在训练集和测试集上,表现效果都不好。 - 欠拟合
一个假设 在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据 ,此时认为这个假设出现了欠拟合的现象。
2. 原因和解决办法
- 欠拟合产生原因: 学习到数据的特征过少
解决办法:
1)添加其他特征项 ,有时出现欠拟合是因为特征项不够导致的,可以添加其他特征项来解决
2)添加多项式特征,模型过于简单时的常用套路,例如将线性模型通过添加二次项或三次项使模型泛化能力更强
- 过拟合产生原因: 原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾所有测试样本
解决办法:
1)重新清洗数据,导致过拟合的一个原因有可能是数据不纯,如果出现了过拟合就需要重新清洗数据。
2)增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
3)正则化4)减少特征维度
3. 正则化
在模型训练时,数据中有些特征影响模型复杂度、或者某个特征的异常值较多,所以要尽可能减少这个特征的影响(甚至删除某个特征的影响),这个就是正则化。
在损失函数中通过增加正则化项来消除异常点带来的w值过大或过小的影响
-
L1正则化
- 公式:J(w)=MSE(w)+α∑i=1n∣wi∣J(w) = \text{MSE}(w) + \alpha \sum_{i=1}^{n} |w_i|J(w)=MSE(w)+α∑i=1n∣wi∣
- 线性回归模型:Lasso回归
α\alphaα 叫做惩罚系数,该值越大则权重调整的幅度就越大,权重就越小
L1正则会使得权重趋向于0,甚至等于0,达到特征筛选的目的
-
L2正则化
- 公式:J(w)=MSE(w)+α∑i=1nwi2J(w) = \text{MSE}(w) + \alpha \sum_{i=1}^{n} w_i^2J(w)=MSE(w)+α∑i=1nwi2
- 线性回归模型:岭回归(Ridge)
α\alphaα 叫做惩罚系数,该值越大则权重调整的幅度就越大,权重就越小
L1正则会使得权重趋向于0,一般不等于0,不会移除特征