
架构设计
复制集架构
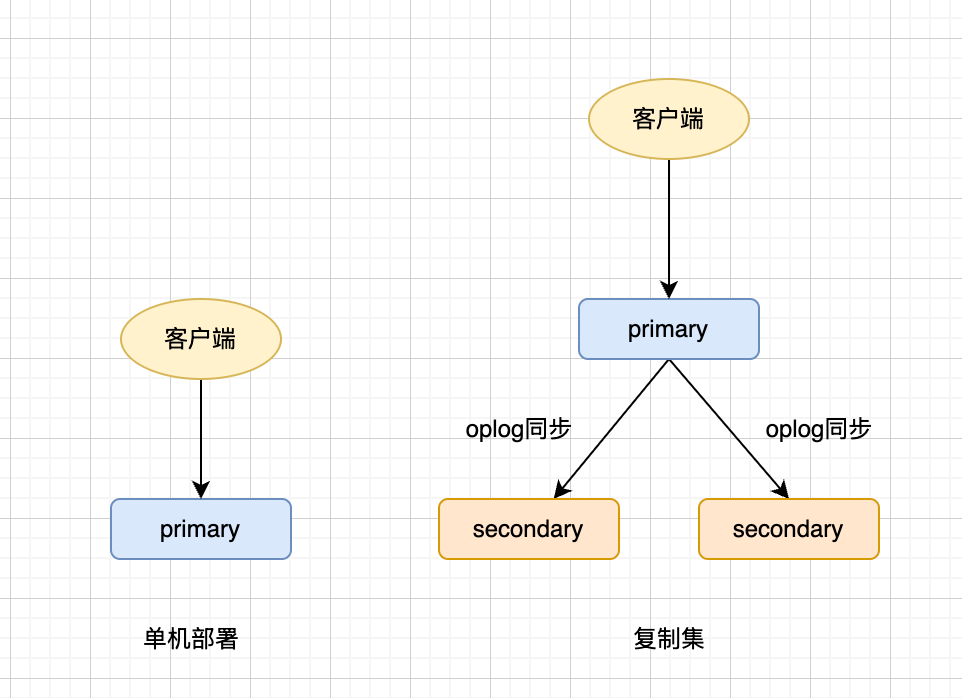
在谈具体的读写前,必须先理解复制集(Replica Set)。它是 MongoDB 保证数据安全和自动容灾的基础。
Primary(主节点):接收所有的写操作,并将变更记录到 oplog(操作日志)中。
Secondary(从节点):定期从主节点异步复制 oplog 并应用到自身,保持数据同步。默认情况下,从节点不处理读写,但可以配置为只读。
Arbiter(仲裁节点,可选):不存储数据,不参与读写,纯粹为了凑足选举票数。
心跳机制:节点间每 2 秒发送一次心跳。如果 Primary 挂掉,Secondary 节点们会在毫秒级内自动发起选举,选出新的 Primary,实现自动故障转移。
分片集群架构
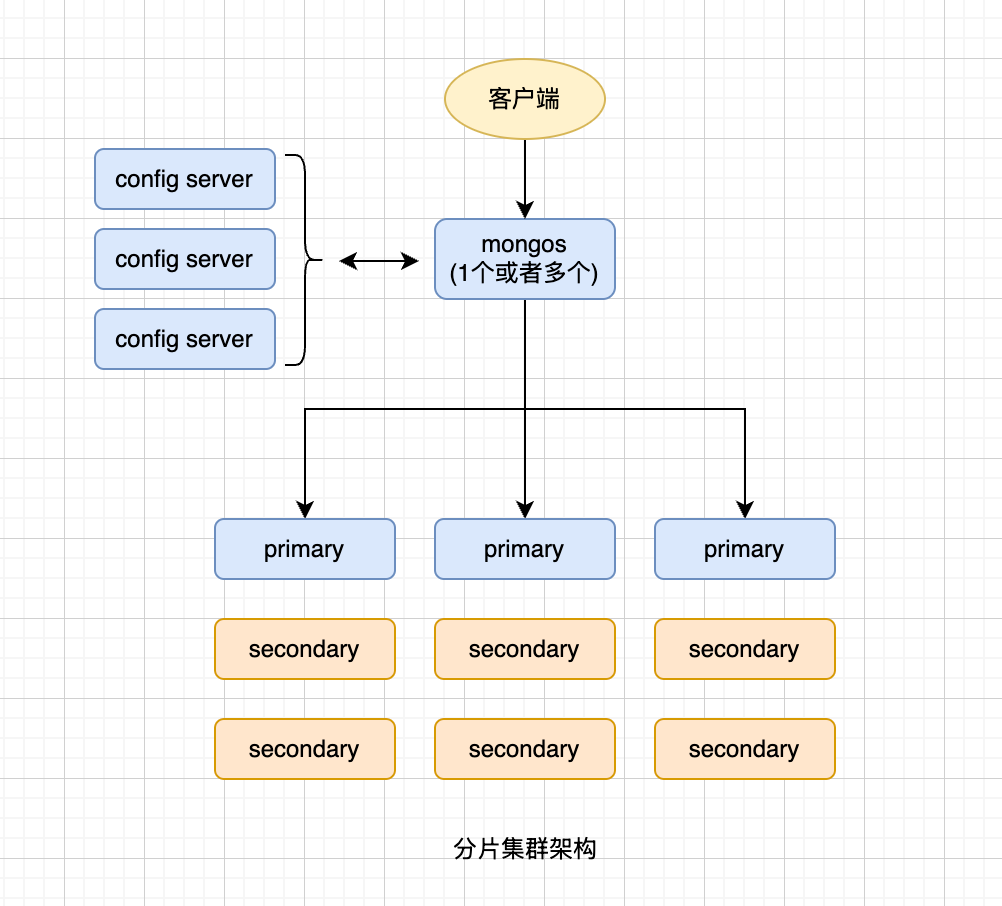
MongoDB 最核心的优势在于支持分片集群(Sharded Cluster),实现海量数据的水平扩展。一个完整的 MongoDB 集群架构通常由以下三个核心组件构成:
Mongos(路由服务器):客户端的统一入口。
功能:它是个无状态的代理,不存储数据。当收到客户端的读写请求时,它会去 Config Server 查询数据路由表,然后将请求精准转发到对应的分片(Shard)上
Config Server(配置服务器):集群的"大脑"与元数据存储。
功能:存储整个集群的元数据和路由信息(比如哪个范围的数据在哪个分片上)。为了保证高可用,生产环境中 Config Server 必须部署为一个复制集(Replica Set)
Shard(分片/数据节点):真正存储数据的容器。
功能:每个分片负责存储总数据的一部分。为了防止单点故障,每个 Shard 在生产环境中都是一个独立的复制集(Replica Set)
写流程
MongoDB 的写操作(Insert/Update/Delete)默认必须在 Primary 节点上执行。现代 MongoDB 默认使用 WiredTiger 存储引擎。
节点的内部写步骤(以 Primary 为例)
当一个写请求到达 Primary 节点时,WiredTiger 引擎在内存和磁盘中的交互流程如下:
-
内存更新:数据首先写入 WiredTiger 的内存缓冲区(Cache),并在内存中修改 B 树(B-Tree)索引。
-
写 Journal 日志(预写日志):
-
内存修改完成后,WiredTiger 会将这次修改的具体操作(类似于变动记录)写入到内存中的 Journal Buffer(日志缓冲区)
-
根据设置(默认每 100ms,或者满足 128KB 触发),Journal Buffer 中的数据会被执行系统的 fsync 刷入磁盘的 journal 文件中(类似于 MySQL 的 Redo Log)
-
写 Oplog:同时,该操作会被记录到 local.oplog.rs 集合中,用于后续的节点间复制。
-
返回客户端:根据客户端配置的 Write Concern(写安全级别),决定何时向客户端返回成功信号。
-
Data Checkpoint(异步刷盘):
- 内存中的脏数据并不会立刻写入真正的数据文件。
- WiredTiger 默认每 60 秒(或脏数据达到一定比例)做一次 Checkpoint,将内存中的修改真正同步到磁盘的数据文件中。
这种"先内存 + 顺序写日志"的设计,将随机的磁盘 IO 变成了顺序的日志 IO,是 MongoDB 写入性能极高的核心原因。
什么是 Write Concern(写关注)?
写流程返回成功的时机由 w 参数决定:
- w: 1(默认):Primary 节点将数据写入内存和 Journal 成功后,立刻返回成功。
- w: "majority":数据必须被写入大多数(超过半数)可见节点后,才向客户端返回成功。这是防止数据在极端异常下被回滚的最安全做法。
WAL(预写日志)的真实含义:"预写"指的是日志(Journal)落盘的时机,要早于数据(Data)落盘的时机。
只要 Step 3(日志落盘) 完成了,Step 5(数据落盘) 即使没做也无所谓。宕机后,MongoDB 会读取磁盘上的 Journal 日志,把没来得及刷盘的数据在内存中"重做"一遍,这就保证了持久性(Durability)
读流程
读策略(Read Preference)
客户端可以通过设置 Read Preference 来决定将读请求发送给谁:
primary(默认):只从主节点读。保证强一致性(能读到最新的写)。
primaryPreferred:优先从主节点读,挂了再读从节点。
secondary:只从从节点读(读写分离,适合报表等非实时高并发查询)。
secondaryPreferred:优先从从节点读。
nearest:根据网络延时,优先选择最近的节点读。
单节点内部的读步骤
假设读请求落到了某个节点上:
-
检查 Cache:WiredTiger 引擎首先看请求的数据页(Page)是否在内存 Cache 中。
-
磁盘加载:如果命中,直接从内存返回;如果未命中,产生 Page Fault(缺页中断),从磁盘数据文件中将数据页加载到 Cache 中。
-
索引加速:如果有索引,会通过 B-Tree 索引快速定位数据页;如果是全表扫描(COLLSCAN),则需要加载大量数据页。
读数据效率高的原因
在 MongoDB 中,当你创建任何一个集合时,系统都会自动为 _id 字段创建一个唯一的主键索引
B+树 的"高度"(从根节点到叶子节点的层数)增长非常缓慢。对于上亿条数据,B+树 的高度通常只有 3到5层。这意味着即使在磁盘上找,也只需极少量的磁盘 I/O
用 _id 查询速度极快,根本原因在于 _id 索引几乎必然会完整地常驻内存,理由非常充分:
战略优先级:WiredTiger 官方明确指出,在内存压力下,引擎会 "优先确保索引缓存" 。这意味着索引比普通文档数据更难被"踢出"内存
物理尺寸小:_id 索引是 MongoDB 中"最瘦"的索引。一个 12 字节的 ObjectId 比动辄几百字节的普通文档小得多,即使在上亿数据量下,其整体大小也更容易被内存容纳
天生的"热数据":作为主键,_id 是最频繁的查询入口。根据"最近最少使用"算法,被高频访问的 _id 索引页会一直处于"活跃"状态,永远不会被系统视为"冷数据"而淘汰