前提介绍
MySQL 集群架构与主从复制原理
1. 架构背景与核心组件
高可用性需求:在典型的"前端-Nginx-后端Java-存储MySQL"架构中,单台数据库存在单点故障风险,一旦宕机将导致数据丢失,因此必须引入集群方案。
核心日志类型:重点介绍了二进制日志(Binary Log),用于记录主库上所有的增删改SQL语句;以及中继日志(Relay Log),用于从库同步主库的二进制日志内容。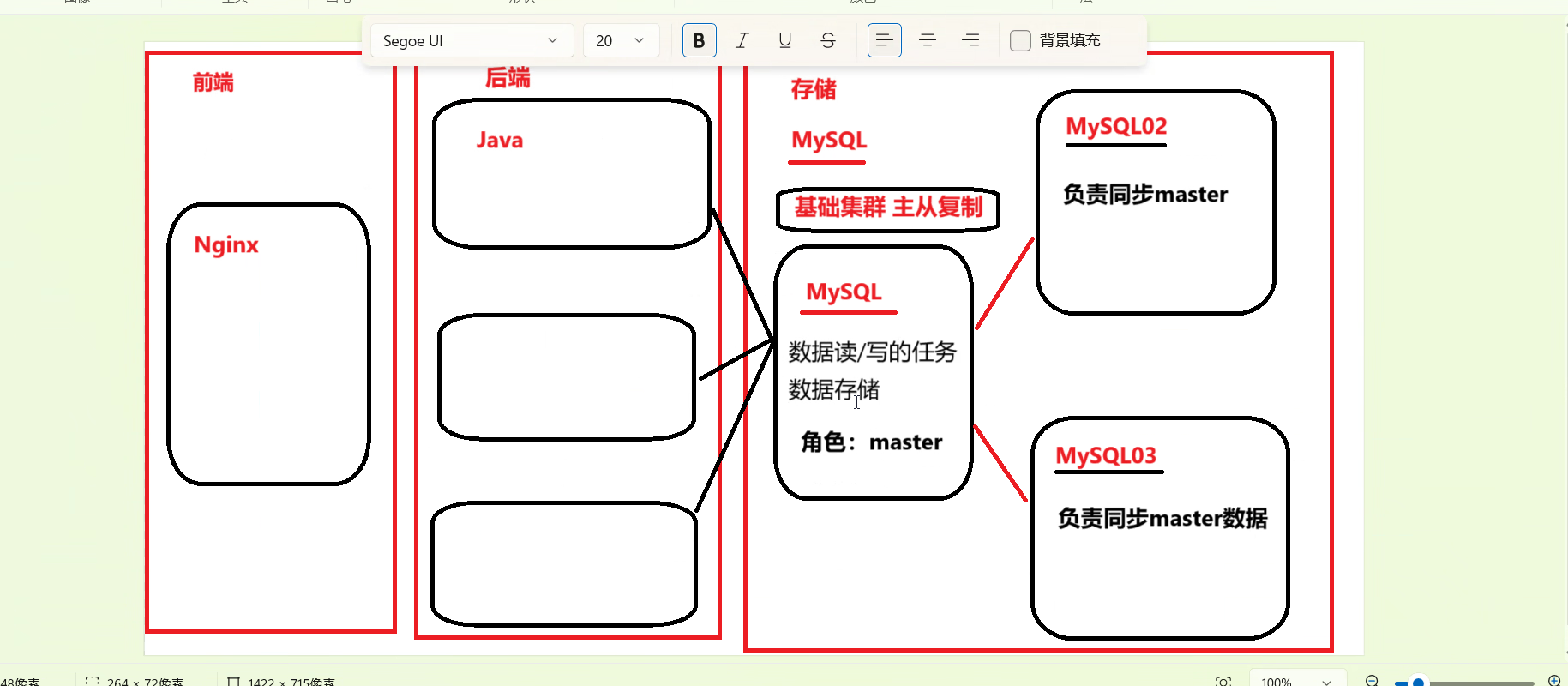
慢查询日志作用:简要提及慢查询日志用于记录执行时间过长的SQL语句,作为数据库性能优化的关键参考依据。
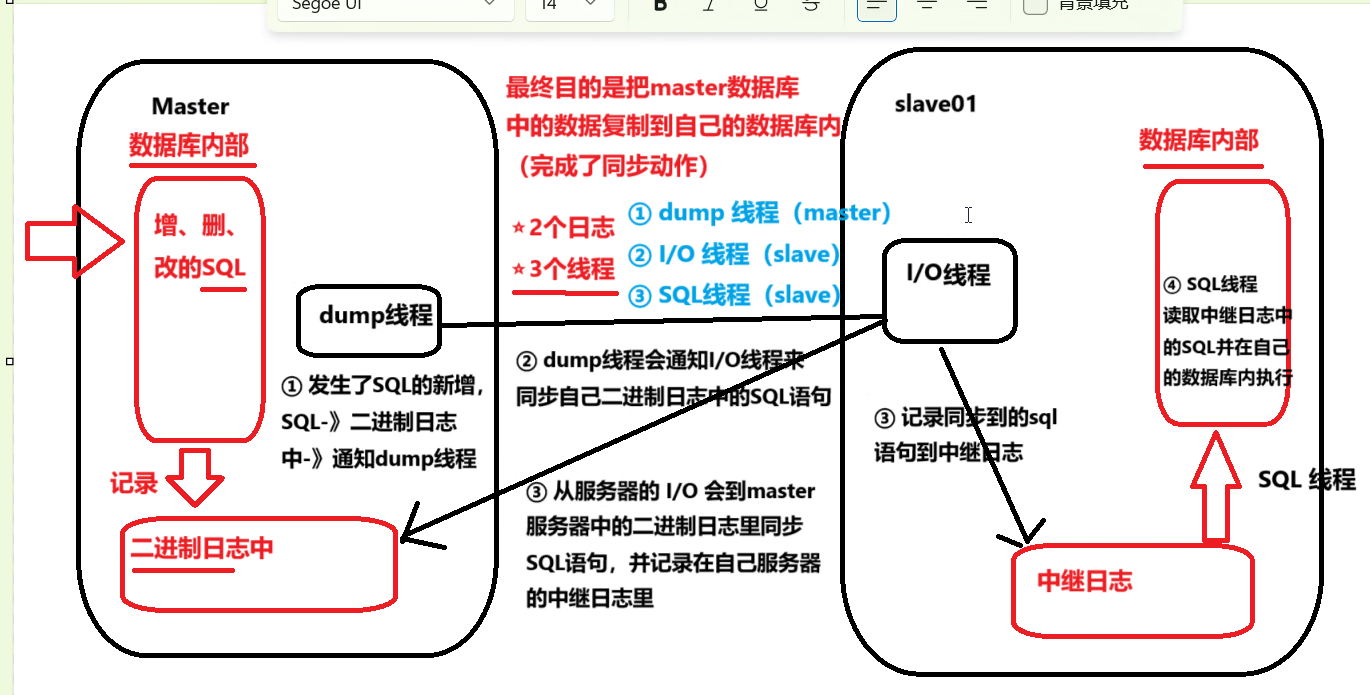
2. "两日志三线程"同步机制
线程角色分工:主从复制涉及三个核心线程。主库的 `Dump Thread` 负责读取二进制日志并发送给从库;从库的 `I/O Thread` 负责接收日志并写入中继日志;从库的 `SQL Thread` 负责读取中继日志并执行其中的SQL语句。
数据同步流程:数据写入主库 -> 记录至二进制日志 -> Dump Thread 通知 -> I/O Thread 拉取日志 -> 写入从库中继日志 -> SQL Thread 执行SQL -> 数据同步完成。
一、主从复制
1.1 什么是主从复制
MySQL主从复制是一种数据库复制技术,用于将数据从一个MySQL数据库服务器(称为主服务器或主库)复制到一个或多个MySQL数据库服务器(称为从服务器或从库)。这种技术主要用于数据备份、读写分离、负载均衡等场景,以提高数据库系统的可用性和性能。
1.2 主从复制的应用场景
数据备份 :通过主从复制,可以将主服务器的数据实时同步到从服务器,从而实现数据备份和灾难恢复。 读写分离 :在主服务器上处理写操作(如INSERT、UPDATE等),在从服务器上处理读操作(如SELECT等),以减轻主服务器的负载并提高系统的吞吐量。 负载均衡:通过配置多个从服务器,可以将读操作分散到不同的从服务器上,从而实现负载均衡。
补充:
高可用 = 保证服务永远不挂、不停机、不宕机
1. 干什么的?
简单说:一台服务器坏了、宕机、死机、重启了,业务还能正常用,用户毫无感知,这就是高可用。
2. 解决什么问题
-
单台机器挂了,系统直接瘫痪
-
半夜服务器崩了,用户用不了
-
生产环境不能随便停机维护
高可用就是:做集群、做备份,一台倒了另一台立刻顶上。
3. 常见场景
-
MySQL 高可用:主库崩了,从库自动变主库,业务不用改配置
-
Nginx 高可用:一台 Nginx 挂了,Keepalived 自动切另一台
-
项目服务高可用:多台后端服务,一台挂了请求自动分给别的机器
4. 核心原理就俩词
冗余 + 自动切换
-
冗余:不止一台,有多台备用
-
自动切换:故障自动切,不用人工干预
高可用就是通过集群部署、冗余备份、故障自动转移,避免单点故障,保证系统 7×24 小时持续可用,不宕机。
1.3 MySQL主从复制原理
MySQL主从复制的原理主要涉及两个日志(bin log和relay log) 和三个线程(IO线程、SQL线程、DUMP线程):
1.3.1 两个日志:
bin log(二进制日志):主库上的数据更新操作(如INSERT、UPDATE、DELETE等)会被记录到二进制日志中。
relay log(中继日志):从库上的IO线程会从主库上拉取二进制日志事件,并将其保存到中继日志中。随后,从库上的SQL线程会读取中继日志中的事件,并在本地进行重放(即将事件解析为SQL语句并逐一执行)
1.3.2 三个线程:
**DUMP线程:**主库上为每个从库的IO线程请求开启的线程,负责发送二进制日志事件给从库。
**IO线程:**从库上用于与主库通信的线程,负责从主库上拉取二进制日志事件并保存到中继日志中。
**SQL线程:**从库上用于读取中继日志中的事件并在本地进行重放的线程。
1.4 MySQL 主从复制核心机制
针对 MySQL 主从复制的实现原理,讲师从日志记录模式与核心组件两个维度进行了深度拆解:
1.4.1 二进制日志(Binlog)记录模式
Statement 模式:仅记录用户执行的原始 SQL 语句,日志量小但存在不确定性风险。
Row 模式:不记录 SQL 语句本身,而是记录数据表中每一行的变更结果,数据一致性高但日志量较大。
Mixed 模式:混合模式,MySQL 会根据具体操作自动选择使用 Statement 或 Row 模式,是实际生产环境中推荐使用的模式。
1.4.2 核心组件与职责
二日志三线程:主从复制依赖二进制日志(Binlog)和中继日志(Relay Log),以及主库的 Dump 线程、从库的 I/O 线程和 SQL 线程。
数据流转逻辑:Master 将数据变更写入 Binlog,Slave 的 I/O 线程拉取 Binlog 并写入 Relay Log,最后由 SQL 线程解析 Relay Log 并在 Slave 端执行。
二、主从服务器配置实操
2.1 基础环境与主库配置
环境初始化:强调了防火墙关闭、时间同步(ntpdate)及 MySQL 服务安装的必要性。
主库参数配置:配置了 `server-id`(唯一标识)、`log-bin`(开启二进制日志)、`binlog_format`(日志格式)及 `expire_logs_days`(日志过期时间)。
主库授权操作:在主库执行 `GRANT REPLICATION SLAVE` 命令,创建用于复制的专用账号并刷新权限。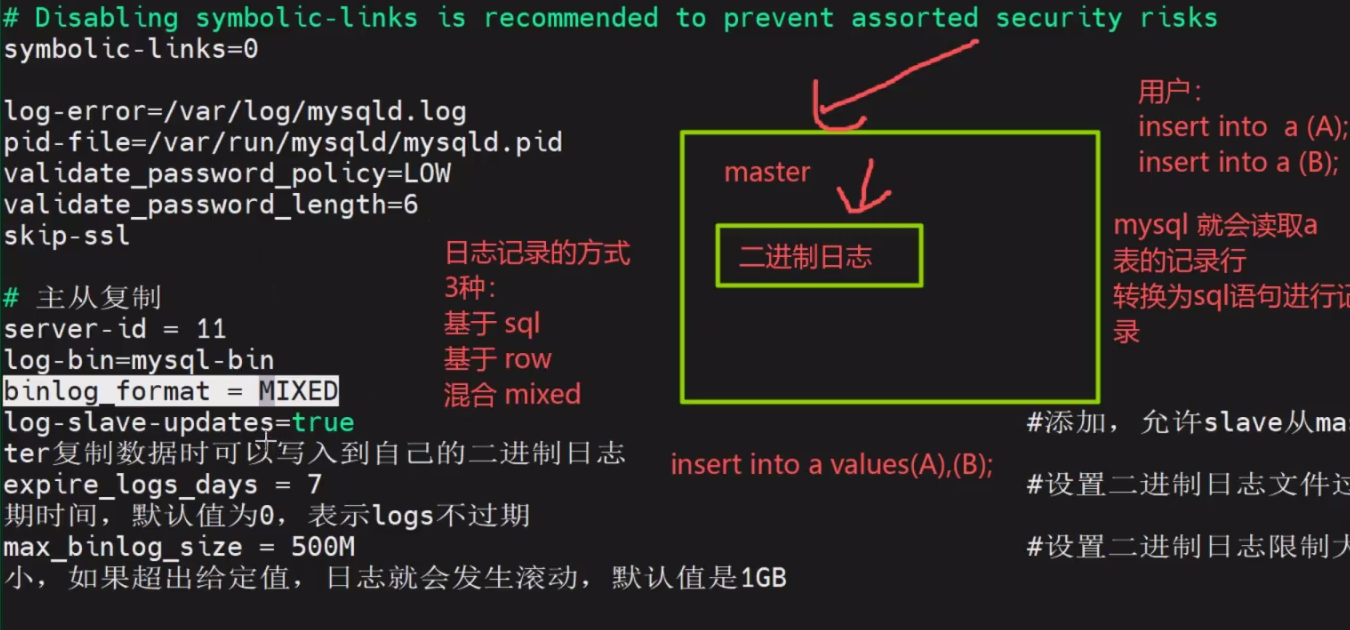
2.2 从库配置与链路建立
从库参数配置:配置了 `server-id`(区别于主库)、`relay-log`(中继日志)及 `relay-log-index`(索引文件)。
链路指向命令:在从库执行 `CHANGE MASTER TO` 命令,指定主库 IP、端口、账号密码、Binlog 文件名及起始位置(Position)。
2.3 常见报错与排查
I/O 线程异常(No):通常由 Binlog 文件名或 Position 位置指定错误导致,需检查 `show master status` 的输出是否与从库配置一致。
连接状态异常(Connecting):若长时间处于 Connecting 状态,需排查网络连通性、防火墙策略或账号权限问题。
2.4 修复与验证流程
配置修正流程:发现 Binlog 文件名错误后,执行 `stop slave` 停止同步,重新执行 `CHANGE MASTER TO` 修正配置,再执行 `start slave` 恢复。
数据同步验证:在主库创建数据库和表并插入数据,在从库查询验证数据是否成功同步。
三、读写分离架构设计与实现
3.1什么是读写分离
读写分离是为了优化数据库性能,通过将写操作(INSERT、UPDATE、DELETE)和读操作(SELECT)分别分配到不同的数据库实例上,以达到降低单一数据库负载、提高整体响应速度的目的。这通常通过数据库的主从复制技术来实现,主数据库负责处理写操作,从数据库负责处理读操作,并保持与主数据库的数据同步。
3.2 读写分离的适用场景
读写分离通常适用于以下场景:
-
读多写少:如果系统的查询操作远多于更新操作,那么读写分离可以显著提高性能。
-
高并发:在高并发场景下,读写分离可以有效分散数据库请求,提高系统的处理能力。
-
数据一致性要求不高的读操作**:对于某些读操作,即使数据略有延迟也是可以接受的,这样可以使用读写分离来提高性能。
3.3 主从复制与读写分离
必要性:在生产环境中,单一数据库服务器无法满足高并发、高可用性和安全性需求。
实现方式:通过主从复制同步数据,再通过读写分离提升数据库的并发处理能力。类似于rsync,但rsync是对磁盘文件备份,而MySQL主从复制是对数据和语句的备份。
3.4 MySQL 读写分离原理
核心思想:只在主服务器上执行写操作,在从服务器上执行读操作。
实现方式:主数据库处理事务性操作,从数据库处理SELECT查询。通过数据库复制技术,将主数据库上的变更同步到从数据库。
3.5 MySQL读写分离的实现方式
- 基于程序代码内部实现:
-
优点:性能较好,不需要额外的硬件设备。
-
缺点:需要开发人员实现,运维人员难以介入;对于大型复杂应用,代码改动可能较大。
- 基于中间代理层实现:
-
优点:易于运维和管理,可以实现更复杂的路由规则和负载均衡策略。
-
缺点:可能增加系统的复杂性和延迟;需要额外的硬件设备或软件资源。
常见的中间代理层实现方式包括MySQL-Proxy、Atlas、Amoeba和Mycat等。这些工具各有优缺点,选择时应根据具体的应用场景和需求进行权衡。
3.6 架构设计逻辑
职责分离原则:Master 节点仅负责写操作(Insert/Update/Delete),Slave 节点仅负责读操作(Select/Show)。
数据一致性基础:读写分离必须建立在主从复制架构之上,通过主从同步机制保证读库与写库的数据最终一致。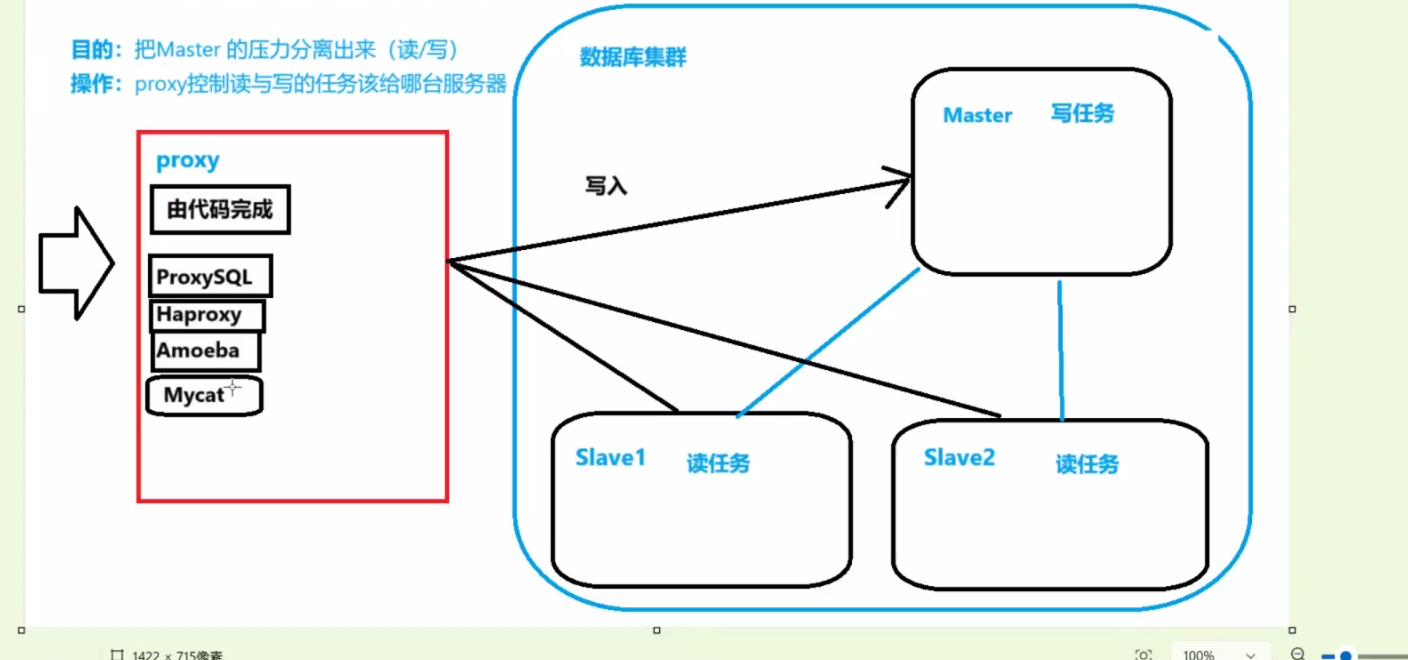
3.7 实现方案选型
中间件代理模式: 推荐使用 ProxySQL、HAProxy 或 Amoeba 等中间件作为代理层,根据 SQL 类型(读/写)自动转发请求至对应的数据库节点。
代码层实现方案:在开发层面,通过代码逻辑判断 SQL 类型,将读请求路由至从库,写请求路由至主库。
四、MySQL读写分离实验
4.1 代表性程序
4.1.1 MyCat 高级功能
分库分表能力:MyCat 不仅能实现读写分离,还支持将大表(如 300 万行数据)进行水平拆分(分表)或垂直拆分(分库),解决单表数据臃肿问题。
4.1.2 Amoeba 配置流程
双用户认证机制:配置 Amoeba 时需建立两层用户体系,即连接代理的用户和代理连接后端数据库的用户,以实现安全隔离。
四步配置法:流程包括安装主从复制、安装 Amoeba 服务、配置访问用户、配置读写任务分配规则。
4.2 Amoeba 服务器配置
4.2.1 架构原理与环境初始化
针对单节点数据库压力过大及单点故障风险,明确了读写分离的架构逻辑与基础环境准备:
- 架构设计逻辑
职责分离机制:确立 Master 节点负责写操作,Slave 节点负责读操作的架构,通过 Proxy 代理实现请求分发,以降低单点压力。
代理配置流程:明确了配置顺序,需先完成主从复制状态校验,再部署代理服务,最后配置用户访问权限与后端数据库集群指向。
- 基础环境准备
主从状态校验:在部署前必须通过 `show slave status` 命令确认主从复制状态正常,确保数据同步基础。
网络与防火墙:调整了代理服务器 IP 地址以避免冲突,并关闭防火墙以确保网络连通性。
4.2.2 Ameba 代理服务部署
Ameba 代理服务的安装、环境变量配置及资源优化过程:
- Java 环境与软件安装
JDK 环境配置:上传并解压 JDK 包,通过修改 `/etc/profile` 文件配置 JAVA_HOME 环境变量,确保系统识别指定版本的 Java。
服务包解压:将 Ameba 软件包解压至 `/usr/local` 目录,并创建专属目录以管理服务文件。
- 系统资源监控与优化
资源占用排查:使用 `htop` 命令发现 `jlong` 进程占用内存过高,通过强制终止进程释放资源。
内存扩容:考虑到 Ameba 服务基于 Java 开发,为避免实验过程中因内存不足导致故障,现场对虚拟机内存进行了扩容。
4.2.3核心配置文件解析与修改
`amoba.xml` 和 `dbServer.xml` 两个核心配置文件的修改逻辑:
- 主配置文件 (amoba.xml)
用户认证配置:修改第 30-32 行,设置客户端连接 Ameba 的用户名(amoba)和密码(123456),并建议生产环境使用不同密码以提升安全性。
读写池定义:修改第 115-117 行,取消注释并定义默认连接池(master)以及读写分离策略(写指向 master,读指向 slaves)。
- 数据库连接配置文件 (dbServer.xml)
连接参数修正:注释掉第 23 行 `schema` 配置以避免版本兼容性报错,修改第 26 行数据库连接用户为 `test`,并设置密码。
后端地址池配置:修改第 45-57 行,定义 master 和 slave 节点的 IP 地址,并确保 slave 节点命名与主配置中的 `slaves` 池对应。
负载均衡策略:修改第 65-71 行,设置读请求的负载均衡规则为 `round robin`(轮询),并关联后端 slave 地址池。
4.2.4 服务启动与故障排查
完成了配置后,服务启动流程及遇到连接失败时的排查方法:
- 数据库授权与服务启动
权限授予:在 MySQL 主从节点上为 `test` 用户授予远程连接权限,确保 Ameba 能正常连接后端数据库。
后台启动:使用 `&` 符号将 Ameba 服务置于后台运行,并通过 `jps` 命令确认 Java 进程已启动。
- 连接故障排查
日志分析:在客户端连接失败时,通过查看 `logs` 目录下的网络日志,定位到密码配置错误导致连接被拒绝。
配置修正:检查发现 `dbServer.xml` 中密码行的注释未取消,修正后重启服务,连接恢复正常。
4.2.5 读写分离与负载均衡验证
通过模拟真实业务场景,验证读写分离及轮询负载均衡的效果:
- 读写分离验证
写操作验证:在客户端执行 `insert` 操作,数据仅写入 Master 节点,验证了写请求的正确路由。
读操作验证:执行 `select` 查询,请求被正确分发至 Slave 节点,未在 Master 上产生读负载。
- 轮询负载均衡测试
数据差异化插入:分别在两个 Slave 节点手动插入差异化数据(Slave1 插入张三,Slave2 插入李四)。
轮询效果验证:在客户端多次执行查询,观察到结果在"张三"和"李四"之间交替出现,证实了读请求被轮询分发至不同的 Slave 节点。
**补充:**中文字符集不支持的问题:
1、创建单个表的时候,添加中文字符集的支持,需要修改配置文件
2、添加数据库的时候支持中文
sql
CREATE DATABASE `ry-Vue` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;总结
sql
主从复制:原理 分担压力
⭐⭐核心是日志文件
日志文件有很多不同的类型,常见:
系统日志(/var/log/messages)
应用程序日志(/var/log/nginx/access.log error.log)
访问日志/错误日志:access.log/error.log
用户日志:用户登陆系统后记录的操作流程
####数据库日志类型(mysql):
服务日志:
错误日志:
⭐二进制日志:简单来说,就是在数据库内执行的所有增删改的SQL,都会被记录在此日志中
⭐中继日志(slave从服务器的"二进制日志"):同步master的二进制日志,记录SQL
⭐慢查询/慢日志:记录的是执行时间过长的SQL语句,目的是提供给管理人员,作为优化的参考依据
读写分离
高可用集群
备份与恢复时间、索引、优化
服务器 3台
192.168.110.129 master mysqld (开启二进制日志)
192.168.110.130 slave1 mysqld (开启中继日志)
192.168.110.131 slave2 mysqld (开启中继日志)
grant all privileges on *.* root@'%' indentified by '123456';
master 二进制日志数据的位置
mysql-bin.000001 604
change master to master_host='192.168.110.129',master_port=3306 ,master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_pos=604;
主从复制原理⭐⭐
2日志 3线程
2日志干嘛的
3线程做什么事情
实验操作:
1、时间同步 ntpdate ntp1.aliyun.com
2、安装mysql数据库(3台)
3、修改主、从服务器的配置文件
4、进入master 数据库--》grant 授权,show master status 查看二进制日志名字和位置(记录)
5、进入slave 数据库--》change master to 指向master 服务器位置,show slave status\G
--》查看2个线程是否为yes
6、最后验证
读写分离: 把master压力分离出来(读/写)
amoeba 怎么做:
1、先把主从做好
2、安装amoeba 服务程序
3、配置访问用户 amoeba 123456 连接后端数据库的用户 test 123.com
配置读与写的任务,该分配给哪些后端的数据库服务器
4、验证回顾补充
sql
一、SQL 多表连接查询实战
针对部门与员工信息的多表查询需求,讲师详细拆解了三种连接方式的应用场景与语法规范:
1. 内连接(INNER JOIN)应用
核心语法规范:演示了标准的内连接写法,即 `SELECT * FROM 表A a INNER JOIN 表B b ON a.id = b.id`,强调通过 `ON` 关键字指定连接条件。
数据匹配逻辑:内连接用于查询两张表中共同存在且满足条件的记录,即输出两表 ID 相等的所有信息,适用于需要完整组合数据的场景。
2. 外连接(LEFT/RIGHT JOIN)应用
左外连接逻辑:当需要查询某张表(如员工表)的所有数据,并关联另一张表(如部门表)的匹配数据时,即使另一张表无匹配项,主表数据仍需显示,此时使用 `LEFT JOIN`。
右外连接逻辑:与左连接逻辑相反,以右表为主表进行数据关联,确保右表数据全部显示。
3. 多表连接进阶
三表关联策略:如在处理部门、员工、绩效三张表关联时,采取"两两连接"的策略。先通过 `INNER JOIN` 将员工表与部门表连接生成中间表,再将中间表与绩效表进行二次连接。
连接条件设定:强调连接条件必须基于表间的共同字段(如 ID),通过 `ON` 子句确保数据关联的准确性。
二、子查询与聚合函数应用
1. 子查询构建逻辑
子查询定义:子查询是在一张表上进行多次 `SELECT` 操作,常用于在 `WHERE` 条件中进行数据筛选或计算。
复杂条件处理: `WHERE` 子句中使用子查询来计算平均薪资,并以此作为筛选条件(如 `WHERE salary > (SELECT AVG(salary) FROM employees)`)。
2. 聚合函数使用
AVG 函数应用:使用 `AVG(salary)` 计算平均薪资,并配合 `WHERE` 子句筛选高于平均值的记录。
多条件组合:在查询绩效为 A 且薪资高于部门平均薪资的员工时,需结合子查询与聚合函数,构建复杂的筛选逻辑。
三、复杂 SQL 语句解析方法论
1. "由内向外"解析法
括号优先原则:面对包含多层括号的复杂 SQL,建议从最内层的括号开始解读,先理解子查询或子表达式的含义,再逐步向外层扩展。
别名识别:在多层连接中,表别名(Alias)的使用至关重要,需准确识别别名对应的表实体,避免混淆。
2. 逻辑拆解与重构
需求分解:面对复杂需求(如三表关联加多条件筛选),建议先将需求拆解为独立的 `WHERE` 条件,再构建表连接逻辑。
中间表思维:将多表连接视为生成"中间表"的过程,即每次连接操作都会生成一个新的虚拟表,后续操作基于此虚拟表进行。一、SQL 多表连接查询实战
针对部门与员工信息的多表查询需求,讲师详细拆解了三种连接方式的应用场景与语法规范:
1. 内连接(INNER JOIN)应用
核心语法规范:演示了标准的内连接写法,即 `SELECT * FROM 表A a INNER JOIN 表B b ON a.id = b.id`,强调通过 `ON` 关键字指定连接条件。
数据匹配逻辑:内连接用于查询两张表中共同存在且满足条件的记录,即输出两表 ID 相等的所有信息,适用于需要完整组合数据的场景。
2. 外连接(LEFT/RIGHT JOIN)应用
左外连接逻辑:当需要查询某张表(如员工表)的所有数据,并关联另一张表(如部门表)的匹配数据时,即使另一张表无匹配项,主表数据仍需显示,此时使用 `LEFT JOIN`。
右外连接逻辑:与左连接逻辑相反,以右表为主表进行数据关联,确保右表数据全部显示。
3. 多表连接进阶
三表关联策略:如在处理部门、员工、绩效三张表关联时,采取"两两连接"的策略。先通过 `INNER JOIN` 将员工表与部门表连接生成中间表,再将中间表与绩效表进行二次连接。
连接条件设定:强调连接条件必须基于表间的共同字段(如 ID),通过 `ON` 子句确保数据关联的准确性。
二、子查询与聚合函数应用
1. 子查询构建逻辑
子查询定义:子查询是在一张表上进行多次 `SELECT` 操作,常用于在 `WHERE` 条件中进行数据筛选或计算。
复杂条件处理: `WHERE` 子句中使用子查询来计算平均薪资,并以此作为筛选条件(如 `WHERE salary > (SELECT AVG(salary) FROM employees)`)。
2. 聚合函数使用
AVG 函数应用:使用 `AVG(salary)` 计算平均薪资,并配合 `WHERE` 子句筛选高于平均值的记录。
多条件组合:在查询绩效为 A 且薪资高于部门平均薪资的员工时,需结合子查询与聚合函数,构建复杂的筛选逻辑。
三、复杂 SQL 语句解析方法论
1. "由内向外"解析法
括号优先原则:面对包含多层括号的复杂 SQL,建议从最内层的括号开始解读,先理解子查询或子表达式的含义,再逐步向外层扩展。
别名识别:在多层连接中,表别名(Alias)的使用至关重要,需准确识别别名对应的表实体,避免混淆。
2. 逻辑拆解与重构
需求分解:面对复杂需求(如三表关联加多条件筛选),建议先将需求拆解为独立的 `WHERE` 条件,再构建表连接逻辑。
中间表思维:将多表连接视为生成"中间表"的过程,即每次连接操作都会生成一个新的虚拟表,后续操作基于此虚拟表进行。