5. 基础IO

本节重点:
-
复习C⽂件IO相关操作
-
认识⽂件相关系统调⽤接⼝
-
认识⽂件描述符,理解重定向
-
对⽐
fd和FILE,理解系统调⽤和库函数的关系 -
理解⽂件和内核⽂件缓冲区
-
⾃定义shell新增重定向功能
-
理解Glibc的IO库
1. 理解"⽂件"
1-1 狭义理解
-
⽂件在磁盘⾥
-
磁盘是永久性存储介质,因此⽂件在磁盘上的存储是永久性的
-
磁盘是外设(即是输出设备也是输⼊设备)
-
磁盘上的⽂件本质是对⽂件的所有操作,都是对外设的输⼊和输出简称IO
1-2 ⼴义理解
- Linux下⼀切皆⽂件(键盘、显⽰器、⽹卡、磁盘......这些都是抽象化的过程)(后⾯会讲如何去 理解)
1-3 ⽂件操作的归类认知
-
对于0KB的空⽂件是占⽤磁盘空间的 (尽管它的内容为空,但是创建该文件的时间,大小,权限描述等等,都需要消耗内存)
-
⽂件是⽂件属性(元数据)和⽂件内容的集合(⽂件=属性(元数据)+内容)
-
所有的⽂件操作本质是⽂件内容操作和⽂件属性操作
1-4 系统⻆度
- 对⽂件的操作本质是进程对⽂件的操作
- 磁盘的管理者是操作系统
- ⽂件的读写本质不是通过C语⾔/C++的库函数来操作的(这些库函数只是为⽤⼾提供⽅便),⽽ 是通过⽂件相关的系统调⽤接⼝来实现的
2. 回顾C⽂件接⼝
2-1 hello.c打开⽂件
#include <stdio.h>
int main()
{
FILE *fp = fopen("myfile", "w");
if(!fp){
printf("fopen error!\n");
}
while(1);
fclose(fp);
return 0;
}代码逐行说明
#include <stdio.h>:引入标准输入输出头文件,提供printf、fopen、fclose等函数的声明。int main():主函数,程序的入口。FILE *fp = fopen("myfile", "w");:以 ** 写模式("w")** 打开名为myfile的文件,返回文件指针给fp;若文件不存在则创建,若存在则清空原有内容。if(!fp){ printf("fopen error!\n"); }:判断文件是否打开失败(fp为NULL时表示失败),失败则打印错误提示。while(1);:死循环,程序会一直停在这里,永远不会执行后面的fclose(fp);。fclose(fp);:关闭文件指针,释放文件资源,但因死循环永远无法执行。return 0;:主函数正常结束的返回值,同样永远无法执行。
打开的myfile⽂件在哪个路径下?
- 在程序的当前路径下,那系统怎么知道程序的当前路径在哪⾥呢?
可以使⽤ ls /proc/[ 进程 id] -l 命令查看当前正在运⾏进程的信息:
[tom@iZ2vc37q0l74k6cf7tfz4tZ ~]$ ps ajx | grep hello
26573 27131 27131 26573 pts/0 27131 R+ 1002 0:34 ./hello
[tom@iZ2vc37q0l74k6cf7tfz4tZ ~]$ ls /proc/27131 -l
......
lrwxrwxrwx 1 tom tom 0 May 12 17:06 cwd -> /home/tom/git-use-first/lesson-12_basic_IO
-r-------- 1 tom tom 0 May 12 17:06 environ
lrwxrwxrwx 1 tom tom 0 May 12 17:04 exe -> /home/tom/git-use-first/lesson-12_basic_IO/hello
dr-x------ 2 tom tom 0 May 12 17:04 fd
......其中:
cwd: 指向当前进程运⾏⽬录的⼀个符号链接。exe:指向启动当前进程的可执⾏⽂件(完整路径)的符号链接。
打开⽂件,本质是进程打开,所以,进程知道⾃⼰在哪⾥,即便⽂件不带路径,进程也知道。由此OS 就能知道要创建的⽂件放在哪⾥。
2-2 hello.c写文件
// 引入标准输入输出头文件,提供 printf、fopen、fwrite、fclose 等函数
#include <stdio.h>
// 引入字符串处理头文件,提供 strlen 函数
#include <string.h>
int main()
{
// 1. 以"只写"模式打开名为"myfile"的文件
// 若文件不存在则创建;若文件已存在,则清空文件原有内容
FILE *fp = fopen("myfile", "w");
// 2. 检查文件是否打开失败
// 若 fopen 失败,会返回 NULL,此时 !fp 条件成立
if(!fp){
printf("fopen error!\n");
}
// 定义要写入文件的字符串常量
const char *msg = "hello bit!\n";
// 定义写入次数,这里设置为写入5次
int count = 5;
// 循环写入 5 次
while(count--){
// 3. 使用 fwrite 向文件写入数据
// 参数说明:
// msg:要写入的数据的起始地址
// strlen(msg):单次写入的每个数据块的大小(字节数)
// 1:要写入的数据块的数量
// fp:目标文件指针
fwrite(msg, strlen(msg), 1, fp);
}
// 4. 关闭文件指针,释放文件资源
// 注:文件使用完毕后必须关闭,否则可能导致数据未写入磁盘、资源泄漏
fclose(fp);
// 程序正常结束,返回 0
return 0;
}2-3 hello.c读⽂件
// 引入标准输入输出头文件,提供 fopen、fread、printf、feof 等函数
#include <stdio.h>
// 引入字符串处理头文件,提供 strlen 函数
#include <string.h>
int main()
{
// 1. 以"只读"模式打开名为"myfile"的文件
// 若文件不存在,fopen 会直接返回 NULL
FILE *fp = fopen("myfile", "r");
// 2. 检查文件是否打开失败
if(!fp){
printf("fopen error!\n");
// 打开失败时直接退出程序,避免后续对 NULL 指针操作
return 1;
}
// 定义缓冲区,用于存储从文件读取的数据,大小为1024字节
char buf[1024];
// 定义一个参考字符串,用于后续读取时的大小参考(实际读取与该字符串无关)
const char *msg = "hello bit!\n";
// 循环读取文件内容,直到文件结束
while(1){
// 注意返回值和参数,此处有坑,仔细查看man手册关于该函数的说明
// 3. 使用 fread 从文件中读取数据
// 参数说明:
// buf:存储读取结果的缓冲区地址
// 1:每个数据块的大小为1字节
// strlen(msg):本次希望读取的数据块数量(即读取 strlen(msg) 个字节)
// fp:源文件指针
// 返回值 s:实际成功读取的数据块数量(即成功读取的字节数)
ssize_t s = fread(buf, 1, strlen(msg), fp);
// 4. 如果成功读取到数据
if(s > 0){
// 在读取到的数据末尾添加字符串结束符 '\0',避免 printf 越界访问
buf[s] = 0;
// 输出读取到的内容
printf("%s", buf);
}
// 5. 判断是否到达文件末尾
// feof(fp) 为真表示上一次读取操作已经到达文件末尾
if(feof(fp)){
break;
}
}
// 6. 关闭文件指针,释放文件资源
fclose(fp);
// 程序正常结束,返回 0
return 0;
}稍作修改,实现简单 cat 命令:
// 引入标准输入输出头文件,提供 printf、fopen、fread、feof、fclose 等函数
#include <stdio.h>
// 引入字符串处理头文件,本代码中主要用于配合文件读写逻辑(此处未直接使用,但保留头文件)
#include <string.h>
// 主函数:实现简易 cat 命令,通过命令行参数接收文件名
// argc:命令行参数个数,argv:命令行参数数组
int main(int argc, char* argv[])
{
// 1. 检查命令行参数个数,简易 cat 命令只接收1个文件名参数(共2个参数:程序名+文件名)
if (argc != 2)
{
printf("argv error!\n");
// 参数错误,直接退出程序,返回错误码1
return 1;
}
// 2. 以只读模式打开命令行参数指定的文件(argv[1]是用户传入的文件名)
FILE *fp = fopen(argv[1], "r");
// 3. 检查文件是否打开失败(如文件不存在、权限不足等)
if(!fp){
printf("fopen error!\n");
// 文件打开失败,直接退出程序,返回错误码2
return 2;
}
// 定义缓冲区,用于存储从文件读取的数据,大小为1024字节
char buf[1024];
// 循环读取文件内容,直到文件结束
while(1){
// 4. 使用 fread 从文件中读取数据
// 参数说明:
// buf:存储读取结果的缓冲区地址
// 1:每个数据块的大小为1字节
// sizeof(buf):本次希望读取的数据块数量(即读取最多1024个字节,填满缓冲区)
// fp:源文件指针
// 返回值 s:实际成功读取的数据块数量(即成功读取的字节数,因为size=1)
int s = fread(buf, 1, sizeof(buf), fp);
// 5. 如果成功读取到数据
if(s > 0){
// 在读取到的数据末尾添加字符串结束符 '\0',避免 printf 越界访问乱码
buf[s] = 0;
// 输出读取到的内容,实现和 cat 命令一样的文件打印效果
printf("%s", buf);
}
// 6. 判断是否到达文件末尾
// feof(fp) 为真表示上一次读取操作已经到达文件末尾
if(feof(fp)){
// 到达文件末尾,退出循环
break;
}
}
// 7. 关闭文件指针,释放文件资源,避免资源泄漏
fclose(fp);
// 程序正常结束,返回0
return 0;
}2-4 输出信息到显⽰器,你有哪些⽅法
// 引入标准输入输出头文件,提供 fwrite、printf、fprintf、stdout 等函数/宏
#include <stdio.h>
// 引入字符串处理头文件,提供 strlen 函数
#include <string.h>
int main()
{
// 定义要输出的字符串常量
const char *msg = "hello fwrite\n";
// 1. 使用 fwrite 向标准输出(stdout)写入数据
// 参数说明:
// msg:要写入的数据的起始地址
// strlen(msg):每个数据块的大小(字节数)
// 1:要写入的数据块数量(即写1个块)
// stdout:目标文件流,stdout 代表标准输出(终端屏幕)
fwrite(msg, strlen(msg), 1, stdout);
// 2. 使用 printf 向标准输出格式化输出字符串
// printf 是 fprintf(stdout, ...) 的简化版,默认输出到 stdout
printf("hello printf\n");
// 3. 使用 fprintf 向指定文件流格式化输出字符串
// 第一个参数指定目标流,这里 stdout 表示输出到终端,和 printf 效果相同
fprintf(stdout, "hello fprintf\n");
// 程序正常结束,返回 0
return 0;
}2-5 stdin & stdout &stderr
-
C默认会打开三个输⼊输出流,分别是stdin,stdout,stderr
-
仔细观察发现,这三个流的类型都是FILE*,fopen返回值类型,⽂件指针
// 引入标准输入输出头文件,该头文件中定义了 stdin/stdout/stderr 这三个标准流
#include <stdio.h>// 声明外部变量 stdin,它是一个 FILE* 类型的文件指针,代表标准输入流
// 程序默认关联到键盘输入
extern FILE *stdin;// 声明外部变量 stdout,它是一个 FILE* 类型的文件指针,代表标准输出流
// 程序默认关联到终端屏幕
extern FILE *stdout;// 声明外部变量 stderr,它是一个 FILE* 类型的文件指针,代表标准错误流
// 程序默认也关联到终端屏幕,专门用于输出错误信息
extern FILE *stderr;
2-6 打开⽂件的⽅式

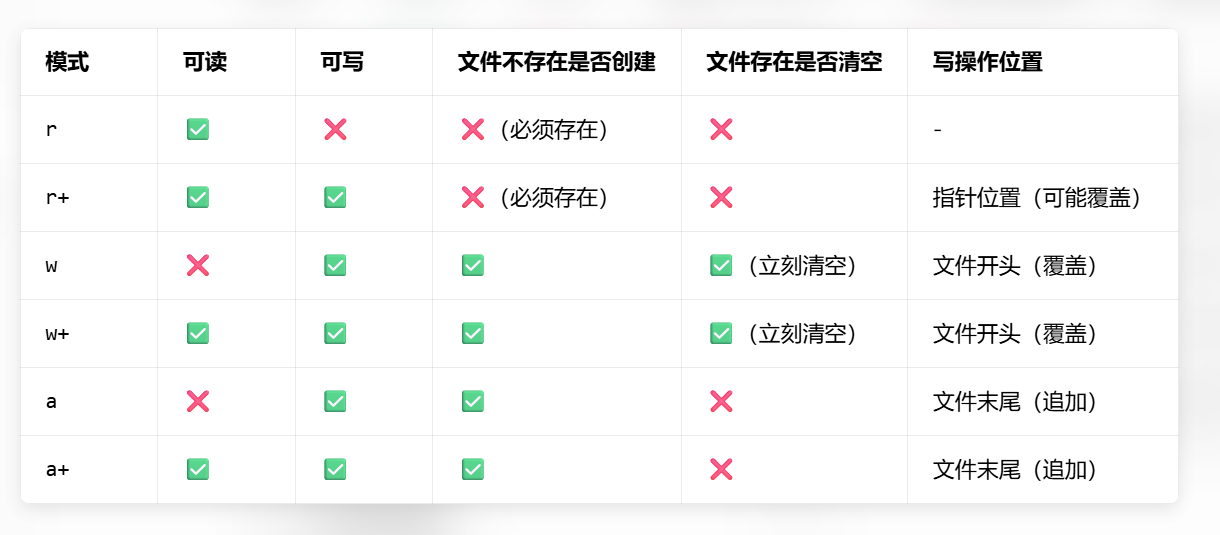
1. rewind 函数
原型(公式)
void rewind(FILE *stream);解释
- 功能 :将文件的读写位置指针 强制重置到文件起始位置。
- 附加作用 :同时清除该文件流的错误标志。
- 等价逻辑 :等同于
fseek(stream, 0L, SEEK_SET);,但无返回值、无法判断错误。 - 参数 :
stream→ 目标文件流指针。 - 返回值:无返回值。
2. ftell 函数
原型(公式)
long ftell(FILE *stream);解释
-
功能 :获取当前文件读写指针的位置。
-
返回值:
- 成功:返回一个
long型整数,表示当前指针相对于文件开头的字节偏移量。 - 失败:返回
-1L。
- 成功:返回一个
-
参数 :
stream→ 目标文件流指针。 -
核心用途:获取位置、计算文件大小、记录指针位置。
3. fseek 函数(核心指针移动函数)
原型(公式)
int fseek(FILE *stream, long offset, int whence);参数解释
-
stream:目标文件流指针 -
offset:偏移量(long型)
- 正数:向文件末尾方向移动
- 负数:向文件开头方向移动
- 0:不移动
-
whence:基准位置(固定三个宏)
SEEK_SET:以 文件开头 为基准SEEK_CUR:以 当前指针位置 为基准SEEK_END:以 文件末尾 为基准
返回值
- 成功:返回
0 - 失败:返回 非 0 值
功能解释
手动修改文件读写指针的位置,支持文件内任意位置跳转。
极简总结
rewind(fp)→ 指针回到文件开头ftell(fp)→ 返回当前指针的字节偏移量fseek(fp, 偏移量, 基准点)→ 移动指针到指定位置
3. 系统文件I/O
打开⽂件的⽅式不仅仅是fopen,ifstream等流式,语⾔层的⽅案,其实系统才是打开⽂件最底层的⽅ 案。不过,在学习系统⽂件IO之前,先要了解下如何给函数传递标志位,该⽅法在系统⽂件IO接⼝中 会使⽤到:
3-1 ⼀种传递标志位的⽅法
// 引入标准输入输出头文件,提供 printf 函数
#include <stdio.h>
// 定义标志位宏,每个标志位对应一个独立的二进制位(2的幂次方)
#define ONE 0001 // 二进制:0000 0001,仅第0位为1,代表标志ONE
#define TWO 0002 // 二进制:0000 0010,仅第1位为1,代表标志TWO
#define THREE 0004 // 二进制:0000 0100,仅第2位为1,代表标志THREE
// 函数:通过位运算判断传入的 flags 参数包含哪些标志位,并打印结果
void func(int flags) {
// 用按位与(&)判断 flags 是否包含 ONE 标志
// 原理:若 flags 的 ONE 对应位为1,则 flags & ONE 的结果非0,条件成立
if (flags & ONE) printf("flags has ONE! ");
// 判断 flags 是否包含 TWO 标志
if (flags & TWO) printf("flags has TWO! ");
// 判断 flags 是否包含 THREE 标志
if (flags & THREE) printf("flags has THREE! ");
// 输出换行,分隔不同调用的结果
printf("\n");
}
int main() {
// 仅传入 ONE 标志,函数将检测到 ONE
func(ONE);
// 仅传入 THREE 标志,函数将检测到 THREE
func(THREE);
// 传入 ONE | TWO(按位或操作),同时设置 ONE 和 TWO 位,函数将检测到两个标志
func(ONE | TWO);
// 传入 ONE | THREE | TWO(按位或操作),同时设置三个位,函数将检测到所有标志
func(ONE | THREE | TWO);
return 0;
}操作⽂件,除了上⼩节的C接⼝(当然,C++也有接⼝,其他语⾔也有),我们还可以采⽤系统接⼝来 进⾏⽂件访问,先来直接以系统代码的形式,实现和上⾯⼀模⼀样的代码。
3-2 hello.c 写⽂件:
// 引入标准输入输出头文件,提供 perror 函数用于打印错误信息
#include <stdio.h>
// 引入系统数据类型头文件,定义了系统调用所需的基础数据类型(如 mode_t、ssize_t)
#include <sys/types.h>
// 引入文件状态头文件,定义了文件权限相关的宏与类型
#include <sys/stat.h>
// 引入文件控制头文件,提供 open 函数及文件打开标志(如 O_WRONLY、O_CREAT)
#include <fcntl.h>
// 引入标准系统调用头文件,提供 write、close、umask 等系统调用函数
#include <unistd.h>
// 引入字符串处理头文件,提供 strlen 函数计算字符串长度
#include <string.h>
int main()
{
// 1. 设置文件创建掩码为 0
// umask 会屏蔽 open 函数中设置的权限位,设置为 0 表示不屏蔽任何权限,最终文件权限完全由 0644 决定
umask(0);
// 2. 系统调用 open 打开/创建文件
// 参数说明:
// "myfile":要打开/创建的文件名
// O_WRONLY:以只写模式打开文件
// O_CREAT:如果文件不存在则创建该文件
// 0644:文件创建权限(八进制表示,即 rw-r--r--,所有者读写,组和其他用户只读)
// 返回值:成功返回文件描述符(非负整数),失败返回 -1
int fd = open("myfile", O_WRONLY|O_CREAT, 0644);
// 3. 检查文件是否打开失败
if(fd < 0){
// perror:根据 errno 打印对应的错误信息,会自动在冒号后显示系统错误描述
perror("open");
// 打开失败,直接退出程序,返回错误码 1
return 1;
}
// 定义写入次数,这里设置为写入 5 次
int count = 5;
// 定义要写入文件的字符串常量
const char *msg = "hello bit!\n";
// 计算字符串的长度(不包含字符串结束符 '\0'),作为 write 函数的写入长度
int len = strlen(msg);
// 循环写入 5 次
while(count--){
// 4. 系统调用 write 向文件写入数据
// 参数说明:
// fd:目标文件的文件描述符(open 返回的句柄)
// msg:要写入的数据的缓冲区首地址
// len:本次期望写入的字节数
// 返回值:实际成功写入的字节数(可能小于 len,例如磁盘满、信号中断等情况)
write(fd, msg, len);
}
// 5. 系统调用 close 关闭文件描述符,释放文件资源
close(fd);
// 程序正常结束,返回 0
return 0;
}3-3 hello.c读⽂件
// 引入标准输入输出头文件,提供 printf、perror 等函数
#include <stdio.h>
// 引入系统数据类型头文件,定义系统调用所需的基础类型(如 ssize_t)
#include <sys/types.h>
// 引入文件状态头文件
#include <sys/stat.h>
// 引入文件控制头文件,提供 open 函数及文件打开标志
#include <fcntl.h>
// 引入系统调用头文件,提供 read、close 等函数
#include <unistd.h>
// 引入字符串处理头文件,提供 strlen 函数
#include <string.h>
int main()
{
// 1. 以只读模式打开文件 myfile
int fd = open("myfile", O_RDONLY);
// 判断文件打开是否失败
if(fd < 0){
perror("open failed"); // 打印打开失败的原因
return 1;
}
// 参考字符串,固定单次读取长度
const char *msg = "hello bit!\n";
// 定义缓冲区,存储读取的数据
char buf[1024];
// 循环读取文件
while(1){
// 2. 调用read系统调用读取数据
ssize_t s = read(fd, buf, strlen(msg));
if(s > 0){
// 手动添加字符串结束符 \0,解决printf乱码问题
buf[s] = '\0';
// 正常打印读取到的内容
printf("%s", buf);
}
else if(s == 0){
// 读取到文件末尾(EOF),正常退出循环
printf("\n读取文件完成!\n");
break;
}
else{
// 处理read读取错误的情况
perror("read failed");
break;
}
}
// 3. 关闭文件描述符,释放资源
close(fd);
return 0;
}3-4 接口介绍
open man open

open() 是打开 / 创建文件的系统调用,核心参数为 pathname(路径)、flags(打开方式)、mode(初始权限,仅创建文件时生效)。
mode_t 本质是无符号整数,用于表示文件权限模板,支持八进制数和系统宏两种表示方式。
实际文件权限 = mode & (~umask),受系统 umask 影响,创建文件时需注意 umask 的默认值。
mode 仅控制新文件的初始权限,不影响已存在文件的权限,与 flags(打开方式)完全独立。
3-5 open函数返回值
在认识返回值之前,先来认识⼀下两个概念: 系统调用 和 库函数
- 比如
fopenfclosefreadfwrite等都是C标准库当中的函数,我们称之为库函数 (libc)。 - 而
openclosereadwritelseek都属于系统提供的接⼝,称之为系统调⽤接⼝
还记得我们讲操作系统概念时,画的⼀张图:
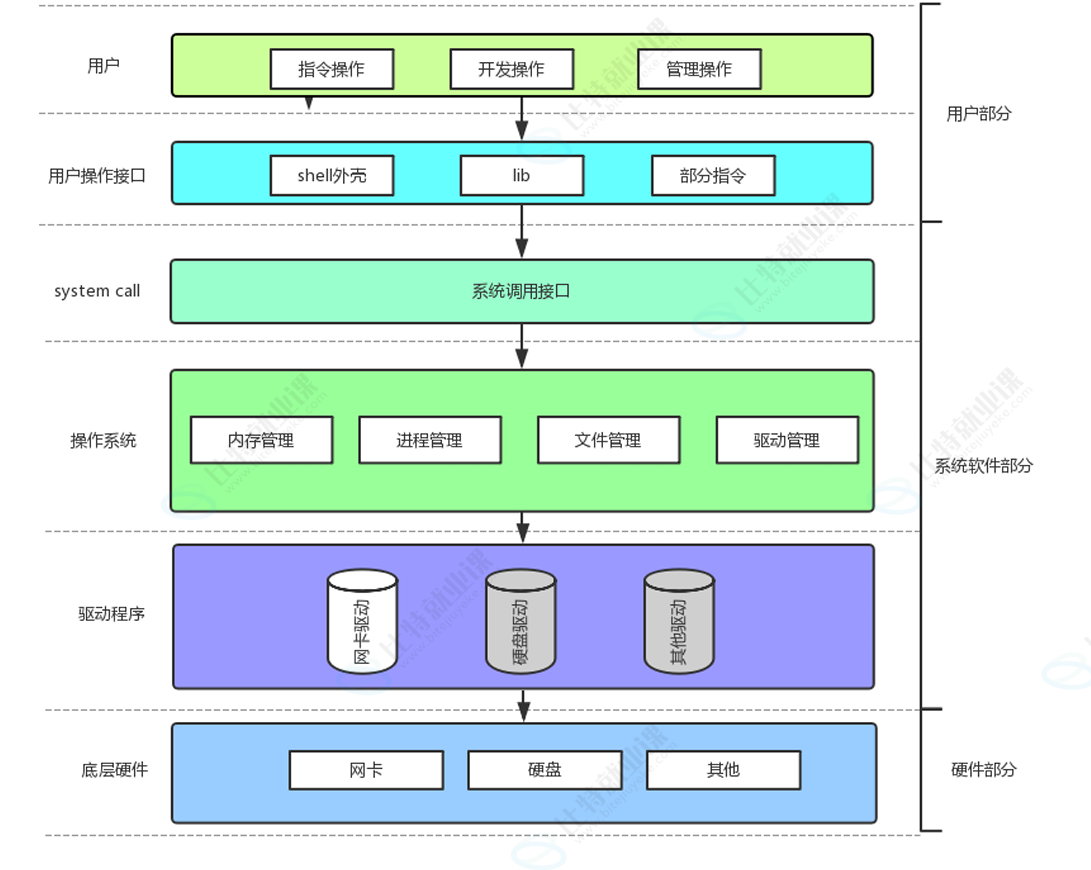
系统调⽤接⼝和库函数的关系,⼀⽬了然,即:
库函数是上层工具,系统调用是底层内核入口;库函数靠调用系统调用完成真正的底层操作。
所以,**库函数在上,系统调用在下;库函数封装,系统调用干活。**而 f# 系列的函数,都是对系统调⽤的封装,⽅便⼆次开发。
3-6 ⽂件描述符 fd
文件描述符就是内核分配给进程的、用于标识「已打开文件」的非负小整数。
核心要点(结合 open 函数)
-
来源 :调用
open()成功打开 / 创建文件后,内核直接返回这个小整数; -
作用 :进程不直接操作文件,而是用这个整数告诉内核要操作哪个文件(read/write/close 都靠它);
-
默认规则
:每个进程启动就自带 3 个固定文件描述符
0:标准输入(键盘)1:标准输出(屏幕)2:标准错误
-
本质 :内核中「进程文件表」的索引编号,简单高效。
文件描述符 = 进程打开文件的「身份证号(小整数)」,open 拿到它,就能操作文件。
3-7 打开文件的流程
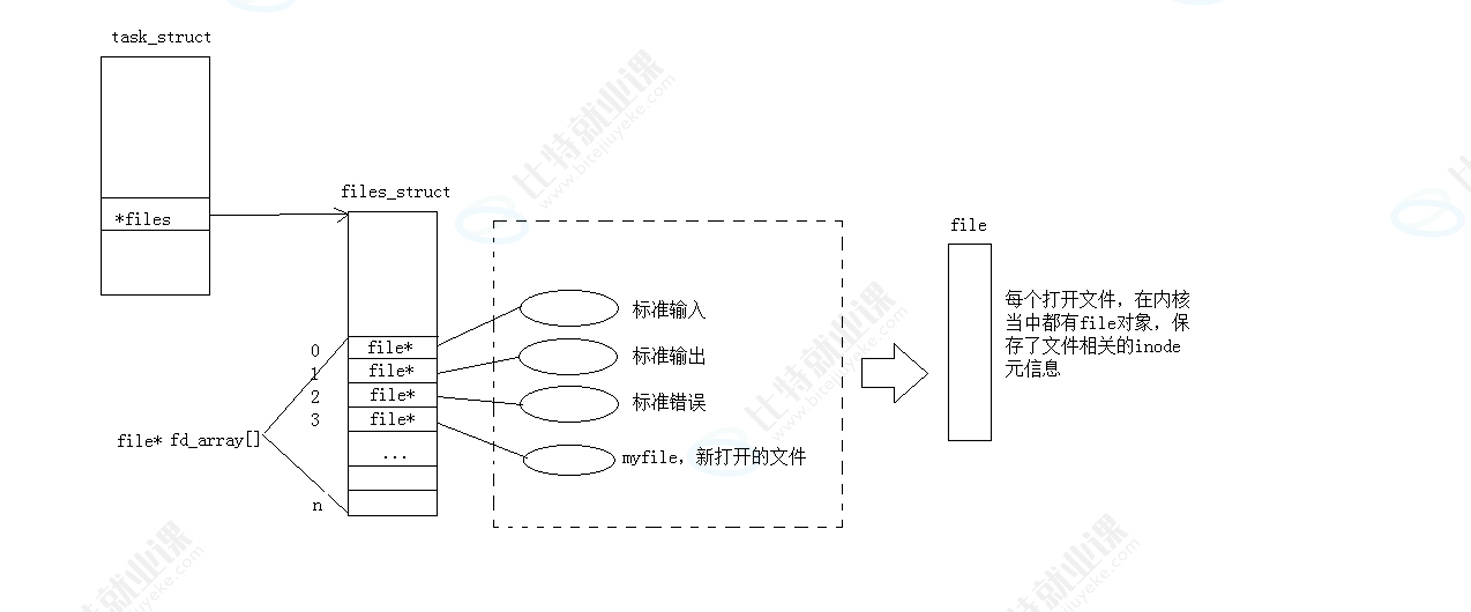
一、先理清楚:整个结构的链式关系(顺着图的箭头走)
进程(task_struct) → 文件管理表(files_struct) → 文件描述符表(fd_array数组) → 内核文件对象(file结构体)
我们逐个拆解每个环节:
1.第一步:进程的 "大本营"------task_struct
每个进程在内核中都有一个进程控制块(PCB) ,也就是task_struct结构体,它是进程的 "所有信息集合",包含进程 ID、状态、内存信息,以及 ------文件相关的管理信息。
- 图中
task_struct里的*files指针,就是进程指向自己文件管理表的入口。
2.第二步:进程的 "文件管理本"------files_struct
files_struct是进程的文件管理核心结构,它的作用是:统一管理这个进程打开的所有文件。
它最重要的组成,就是图中的fd_array[]------文件描述符表(一个指针数组)。
3.第三步:文件描述符表 ------fd_array[]
fd_array是一个数组,数组的每个元素都是一个file\*指针 ,指向内核中真正的文件对象(也就是图里的椭圆,最终指向file结构体)。
-
数组的下标 ,就是我们说的文件描述符(fd)!
-
数组默认前 3 个下标(0、1、2)是固定的:
-
fd=0:标准输入(stdin,默认对应键盘) -
fd=1:标准输出(stdout,默认对应屏幕) -
fd=2:标准错误(stderr,默认对应屏幕)这也是为什么进程启动后,不用
open就能直接用printf/scanf的原因 ------ 这三个文件默认是打开的。
-
4.第四步:内核的 "文件本体"------file结构体
当你调用open()打开 / 创建文件时,内核会做两件事:
-
在内核中创建一个
file结构体,用来保存这个文件的元数据(比如文件的 inode 地址、读写偏移量、访问权限等); -
在进程的
fd_array中,找一个空闲的下标(比如 3,因为 0/1/2 被占用了),把指向这个file结构体的指针填进数组,然后把这个下标(3)返回给进程 ------ 这就是open函数返回的文件描述符!
二、一句话点破文件描述符的本质
文件描述符(fd),就是进程的文件描述符表(fd_array)的数组下标。
进程拿着这个 "下标数字",就能顺着task_struct → files_struct → fd_array[fd] → file结构体的链条,快速定位到内核中对应的文件对象,执行后续的读写操作。
三、重点强调:文件描述符的核心作用
1.进程内文件的「唯一标识」
一个进程中,每个打开的文件都对应唯一的 fd,内核通过这个数字,能O (1) 时间定位到对应的file结构体,不用每次都传递文件路径或结构体地址,高效且安全。
注意:fd 的作用域是进程内的,不同进程的 fd=3,可能指向完全不同的文件==(每个进程有自己的files_struct和fd_array)==。
2.跨系统调用函数应用的「通用钥匙」
read()/write()/close()/dup()等所有文件操作系统调用,都只需要传入 fd,就能操作文件。它屏蔽了内核file结构体的实现细节,用户进程不用关心内核怎么管理文件,只要拿这个 "数字钥匙" 就行。
read/write/close 这些不同的函数,都可以用同一个 fd 操作目标文件。
3.进程资源管理的「入口」
内核通过fd_array管理进程的所有打开文件:
- 进程退出时,内核会遍历
fd_array,把所有未关闭的 fd 对应的文件关闭,释放内核资源; - 可以通过
dup2()修改fd_array中元素的指向,实现文件重定向(比如把fd=1指向一个文件,就能让printf输出到文件,而不是屏幕)。
4.特殊 fd 的「默认绑定」
0/1/2这三个默认 fd,实现了进程和终端的默认交互:
- 程序不用手动打开终端,就能直接通过
fd=0读输入、fd=1写输出,这也是命令行程序能直接和用户交互的基础。
3-8 ⽂件描述符的分配规则
-
默认占用
进程启动时,内核固定分配 3 个文件描述符:
0(标准输入)、1(标准输出)、2(标准错误),这三个永远优先被占用。 -
核心规则:最小未使用分配
调用
open()打开新文件时,内核从 0 开始查找 ,选择当前最小的、空闲的整数作为新的文件描述符返回。 -
释放复用
调用
close(fd)关闭文件后,该 fd 会被回收;下次open()会优先复用这个刚释放的最小空闲 fd。 -
上限约束
每个进程能打开的文件描述符有最大数量限制(默认通常为 1024),达到上限后无法分配新 fd。
总结:先占 0/1/2,新 fd 永远找「当前最小的空闲数字」,关闭后可复用。
代码示例:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("myfile", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}输出发现是 fd: 3
关闭0 或者 2,再看:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
//close(2)
int fd = open("myfile", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}发现是结果是: fd: 0 或者 fd 2 ,可⻅,⽂件描述符的分配规则:在files_struct数组当中,找到 当前没有被使⽤的最⼩的⼀个下标,作为新的⽂件描述符。
3-9 重定向
那如果关闭1呢? 看代码:
#include <stdio.h> // 标准输入输出库,提供printf、perror、fflush等函数
#include <sys/types.h> // 系统数据类型定义(如mode_t)
#include <sys/stat.h> // 文件状态/权限相关的宏与函数
#include <fcntl.h> // open()系统调用及文件控制选项(O_WRONLY/O_CREAT等)
#include <stdlib.h> // 提供exit()函数,用于进程退出
int main()
{
// 关闭文件描述符1(标准输出stdout),释放该文件描述符的位置
close(1);
// 打开/创建文件myfile:
// - O_WRONLY:以只写方式打开
// - O_CREAT:文件不存在时创建,需要配合第三个参数指定权限
// - 00644:新文件的权限(八进制表示,对应所有者读写、组/其他只读)
int fd = open("myfile", O_WRONLY|O_CREAT, 00644);
// 检查open是否调用失败(返回-1表示失败)
if(fd < 0){
perror("open"); // 打印错误信息(包含系统错误描述)
return 1; // 出错时返回非0状态码
}
// 打印新分配的文件描述符值(此时会输出到刚打开的myfile文件中)
printf("fd: %d\n", fd);
// 强制刷新stdout缓冲区,确保printf的数据立即写入文件
fflush(stdout);
// 关闭文件描述符fd,释放内核文件资源
close(fd);
// 正常退出程序,状态码0表示成功
exit(0);
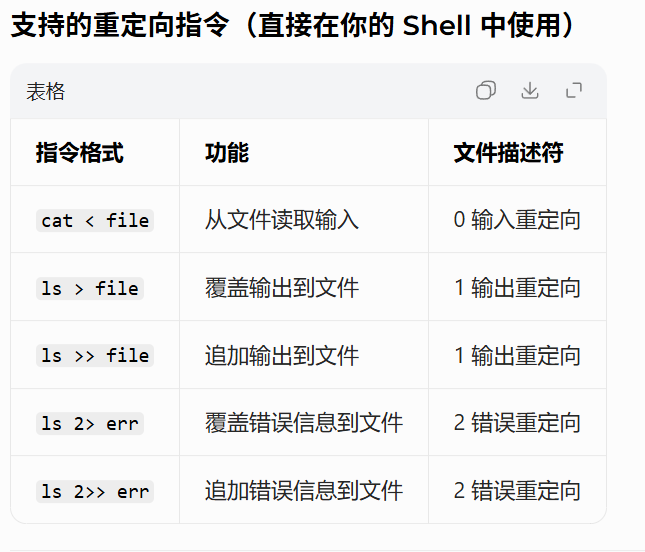
}此时,我们发现,本来应该输出到显示器上的内容,输出到了文件 myfile 当中,其中,这种现象叫做输出重定向。常见的重定向有: >, >>, <
那重定向的本质是什么呢?
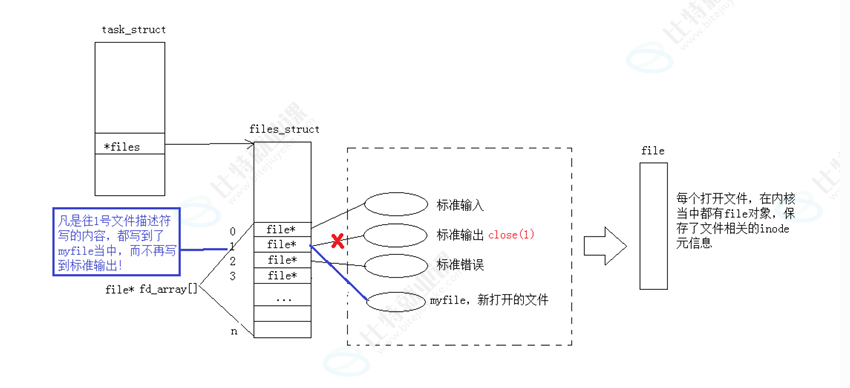
3-10 使⽤dup2系统调⽤
函数原型如下:
#include <unistd.h>
int dup2(int oldfd, int newfd);⽰例代码
#include <stdio.h> // 标准输入输出库(printf、perror等)
#include <unistd.h> // 系统调用库(close、read、dup2等)
#include <fcntl.h> // 文件控制库(open函数及标志位)
int main() {
// 打开/创建文件 ./log,权限为读写(O_RDWR),不存在则创建(O_CREAT)
int fd = open("./log", O_CREAT | O_RDWR);
if (fd < 0) { // 检查open是否失败(返回-1表示失败)
perror("open"); // 打印错误信息
return 1; // 出错时返回非0状态码
}
close(1); // 关闭文件描述符1(标准输出stdout),释放该位置
dup2(fd, 1); // 复制文件描述符fd到fd=1,让stdout指向log文件
// 循环读取标准输入并写入文件
for (;;) {
char buf[1024] = {0}; // 定义缓冲区,初始化为0
// 从标准输入(fd=0)读取数据到buf,最多读取sizeof(buf)-1字节(留空终止符位置)
ssize_t read_size = read(0, buf, sizeof(buf) - 1);
if (read_size < 0) { // 读取失败处理
perror("read");
break;
}
printf("%s", buf); // 输出读取的内容(此时stdout已被重定向到log文件)
fflush(stdout); // 强制刷新stdout缓冲区,确保数据写入文件
}
return 0; // 程序正常退出
}不要被这串代码吓到了,这有啥难度啊。实质上他的功能就是:
关闭标准输出的文件描述符 1 使其空闲,dup2(fd, 1) 让 fd=1 与原 fd 指向同一个 log 文件;原本绑定 fd=1 的标准输出,所有内容都会写入文件,最终实现输出重定向。
同理我们也可以实现输入重定向,错误重定向,这里不再赘述。
3-11 在minishell里面实现 0 1 2 重定向
// 标准输入输出流头文件,用于cout/cin等基础IO操作
#include <iostream>
// C标准输入输出头文件,用于printf、scanf、fflush等底层IO操作
#include <cstdio>
// C标准库头文件,用于malloc、free、exit等内存/进程操作
#include <cstdlib>
// C字符串处理头文件,用于memset、strlen、strcmp等字符串函数
#include <cstring>
// C++字符串类头文件,提供string类型的便捷操作
#include <string>
// Linux系统头文件,提供unix标准函数,如close、read、write
#include <unistd.h>
// Linux系统头文件,定义进程ID类型(pid_t)
#include <sys/types.h>
// Linux系统头文件,提供进程等待函数(waitpid),用于回收子进程
#include <sys/wait.h>
// C字符处理头文件,用于isspace判断空白字符
#include <ctype.h>
// open系统调用需要的头文件
#include <fcntl.h>
#include <sys/stat.h>
using namespace std;
const int basesize = 1024;
const int argvnum = 64;
const int envnum = 64;
char *gargv[argvnum];
int gargc = 0;
int lastcode = 0;
char *genv[envnum];
char pwd[basesize];
char pwdenv[basesize];
// 重定向配置结构体:存储输入/输出/错误重定向的文件和模式
typedef struct {
char *in_file; // 输入重定向文件(<)
char *out_file; // 输出重定向文件(> / >>)
char *err_file; // 错误重定向文件(2> / 2>>)
int append_out; // 输出是否追加(1=追加,0=覆盖)
int append_err; // 错误是否追加(1=追加,0=覆盖)
} Redirect;
Redirect redirect = {nullptr, nullptr, nullptr, 0, 0};
#define TrimSpace(pos) do{\
while(isspace(*pos)){\
pos++;\
}\
}while(0)
// 函数功能:获取当前登录的用户名
string GetUserName()
{
string name = getenv("USER");
return name.empty() ? "None" : name;
}
// 函数功能:获取当前主机名
string GetHostName()
{
string hostname = getenv("HOSTNAME");
return hostname.empty() ? "None" : hostname;
}
// 函数功能:获取当前工作路径,并更新系统PWD环境变量
string GetPwd()
{
if(nullptr == getcwd(pwd, sizeof(pwd))) return "None";
snprintf(pwdenv, sizeof(pwdenv), "PWD=%s", pwd);
putenv(pwdenv);
return pwd;
}
// 函数功能:截取当前工作路径的最后一级目录名
string LastDir()
{
string curr = GetPwd();
if(curr == "/" || curr == "None") return curr;
size_t pos = curr.rfind("/");
if(pos == std::string::npos) return curr;
return curr.substr(pos+1);
}
// 函数功能:拼接格式化的命令提示符字符串
string MakeCommandLine()
{
char command_line[basesize];
snprintf(command_line, basesize, "[%s@%s %s]# ",
GetUserName().c_str(), GetHostName().c_str(), LastDir().c_str());
return command_line;
}
// 函数功能:打印命令行提示符
void PrintCommandLine()
{
printf("%s", MakeCommandLine().c_str());
fflush(stdout);
}
// 函数功能:从标准输入读取用户输入的命令行
bool GetCommandLine(char command_buffer[], int size)
{
char *result = fgets(command_buffer, size, stdin);
if(!result) return false;
command_buffer[strlen(command_buffer)-1] = 0;
if(strlen(command_buffer) == 0) return false;
return true;
}
// 函数功能:解析命令行字符串,分割为命令参数数组
void ParseCommandLine(char command_buffer[], int len)
{
(void)len;
memset(gargv, 0, sizeof(gargv));
gargc = 0;
const char *sep = " ";
gargv[gargc++] = strtok(command_buffer, sep);
while((bool)(gargv[gargc++] = strtok(nullptr, sep)));
gargc--;
}
// 函数功能:调试打印解析后的命令参数
void debug()
{
printf("argc: %d\n", gargc);
for(int i = 0; gargv[i]; i++)
{
printf("argv[%d]: %s\n", i, gargv[i]);
}
}
// 函数功能:解析命令中的重定向符号,清理参数列表
void ParseRedirect() {
memset(&redirect, 0, sizeof(Redirect));
int new_argc = 0;
char *new_argv[argvnum] = {nullptr};
for (int i = 0; gargv[i]; i++) {
if (strcmp(gargv[i], "<") == 0 && gargv[i+1]) {
redirect.in_file = gargv[++i];
continue;
}
if (strcmp(gargv[i], ">>") == 0 && gargv[i+1]) {
redirect.out_file = gargv[++i];
redirect.append_out = 1;
continue;
}
if (strcmp(gargv[i], ">") == 0 && gargv[i+1]) {
redirect.out_file = gargv[++i];
redirect.append_out = 0;
continue;
}
if (strcmp(gargv[i], "2>>") == 0 && gargv[i+1]) {
redirect.err_file = gargv[++i];
redirect.append_err = 1;
continue;
}
if (strcmp(gargv[i], "2>") == 0 && gargv[i+1]) {
redirect.err_file = gargv[++i];
redirect.append_err = 0;
continue;
}
new_argv[new_argc++] = gargv[i];
}
memcpy(gargv, new_argv, sizeof(new_argv));
gargc = new_argc;
}
// 函数功能:创建子进程,执行外部命令(支持重定向)
bool ExecuteCommand()
{
pid_t id = fork();
if(id < 0) return false;
if(id == 0) {
// 输入重定向 0
if (redirect.in_file) {
int fd = open(redirect.in_file, O_RDONLY);
if (fd < 0) { perror("open in"); exit(1); }
dup2(fd, 0);
close(fd);
}
// 输出重定向 1
if (redirect.out_file) {
int flags = O_WRONLY | O_CREAT;
flags |= redirect.append_out ? O_APPEND : O_TRUNC;
int fd = open(redirect.out_file, flags, 0666);
if (fd < 0) { perror("open out"); exit(1); }
dup2(fd, 1);
close(fd);
}
// 错误重定向 2
if (redirect.err_file) {
int flags = O_WRONLY | O_CREAT;
flags |= redirect.append_err ? O_APPEND : O_TRUNC;
int fd = open(redirect.err_file, flags, 0666);
if (fd < 0) { perror("open err"); exit(1); }
dup2(fd, 2);
close(fd);
}
execvpe(gargv[0], gargv, genv);
exit(1);
}
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid > 0) {
if(WIFEXITED(status)) lastcode = WEXITSTATUS(status);
else lastcode = 100;
return true;
}
return false;
}
// 函数功能:向全局环境变量表中添加自定义环境变量
void AddEnv(const char *item)
{
int index = 0;
while(genv[index]) index++;
genv[index] = (char*)malloc(strlen(item)+1);
strncpy(genv[index], item, strlen(item)+1);
genv[++index] = nullptr;
}
// 函数功能:判断并执行内建命令(cd/export/env/echo)
bool CheckAndExecBuiltCommand()
{
if(strcmp(gargv[0], "cd") == 0) {
if(gargc == 2) chdir(gargv[1]);
lastcode = 0;
return true;
}
else if(strcmp(gargv[0], "export") == 0) {
if(gargc == 2) AddEnv(gargv[1]);
lastcode = 0;
return true;
}
else if(strcmp(gargv[0], "env") == 0) {
for(int i = 0; genv[i]; i++) printf("%s\n", genv[i]);
lastcode = 0;
return true;
}
else if(strcmp(gargv[0], "echo") == 0) {
if(gargc == 2 && gargv[1][0] == '$' && gargv[1][1] == '?') {
printf("%d\n", lastcode);
}
lastcode = 0;
return true;
}
return false;
}
// 函数功能:初始化shell环境变量,继承系统环境变量
void InitEnv()
{
extern char **environ;
int index = 0;
while(environ[index]) {
genv[index] = (char*)malloc(strlen(environ[index])+1);
strncpy(genv[index], environ[index], strlen(environ[index])+1);
index++;
}
genv[index] = nullptr;
}
// 函数功能:shell主函数,程序入口,循环处理命令
int main()
{
InitEnv();
char command_buffer[basesize];
while(true)
{
PrintCommandLine();
if( !GetCommandLine(command_buffer, basesize) ) continue;
ParseCommandLine(command_buffer, strlen(command_buffer));
ParseRedirect();
if ( CheckAndExecBuiltCommand() ) continue;
ExecuteCommand();
}
return 0;
}- 输入重定向(0) :
open文件 →dup2(fd, 0)→ 程序从文件读,而非键盘 - 输出重定向(1) :
open文件 →dup2(fd, 1)→ 打印内容写入文件,而非屏幕 - 错误重定向(2) :
open文件 →dup2(fd, 2)→ 报错信息写入文件,而非屏幕 - 重定向仅作用于子进程,不影响父 Shell,完全符合 Linux 标准行为
4. 理解"⼀切皆⽂件"
⾸先,在windows中是⽂件的东西,它们在linux中也是⽂件;其次⼀些在windows中不是⽂件的东 西,⽐如进程、磁盘、显⽰器、键盘这样硬件设备也被抽象成了⽂件,你可以使⽤访问⽂件的⽅法访 问它们获得信息;甚⾄管道,也是⽂件;将来我们要学习⽹络编程中的socket(套接字)这样的东西, 使⽤的接⼝跟⽂件接⼝也是⼀致的。
这样做最明显的好处是,开发者仅需要使⽤⼀套API和开发⼯具,即可调取Linux系统中绝⼤部分的 资源。举个简单的例⼦,Linux中⼏乎所有读(读⽂件,读系统状态,读PIPE)的操作都可以⽤read 函数来进⾏;⼏乎所有更改(更改⽂件,更改系统参数,写PIPE)的操作都可以⽤ write 函 数来进⾏。
之前我们讲过,当打开一个文件时,操作系统为了管理所打开的文件,都会为这个文件创建一个file结构体,该结构体定义在 /usr/src/kernels/3.10.0-1160.71.1.el7.x86_64/include/linux/fs.h 下,以下展示了该结构部分我们关心的内容:

值得关注的是 struct file 中的 f_op 指针指向了一个 file_operations 结构体,这个结构体中的成员除了 struct module* owner 其余都是函数指针。该结构和 struct file 都在 fs.h。


file_operation 就是把系统调用和驱动程序关联起来的关键数据结构,这个结构的每一个成员都对应着一个系统调用。读取 file_operation 中相应的函数指针,接着把控制权转交给函数,从而完成了Linux设备驱动程序的工作。
一、完整调用流程(以用户态read(fd, buf, len)为例)
步骤 1:用户态发起统一的系统调用
用户程序(比如你的 shell、cat命令)调用read(fd, buf, len),完全不关心fd对应的是什么设备:
- 读磁盘文件:
read(file_fd, buf, 1024) - 读键盘输入:
read(0, buf, 1024)(fd=0标准输入,对应键盘) - 读网卡数据:
read(net_fd, buf, 1024) - 读串口设备:
read(uart_fd, buf, 1024)
用户态的代码完全一致,都是用同一个read系统调用,只是传入的fd不同。
步骤 2:系统调用陷入内核,通过fd找到对应的struct file
当用户调用read时,CPU 从用户态切换到内核态,内核开始处理请求:
- 内核根据传入的
fd(文件描述符),在进程的files_struct里的fd_array数组中,找到对应的struct file结构体。 - 每个打开的文件 / 设备,内核都会为它创建一个独立的
struct file,不管它是普通文件、终端、磁盘还是网卡。
步骤 3:通过struct file的f_op,找到对应设备的file_operations
struct file结构体里有一个关键成员:struct file_operations *f_op;,它是一个指向file_operations结构体的指针。
不同设备的file_operations是完全不同的:

这就是图中展示的:每个struct file的f_op,都指向自己设备的file_operations,不同设备的函数指针,指向不同的驱动实现。
步骤 4:内核调用file_operations里的函数指针,分发到对应驱动
内核拿到struct file后,通过f_op找到对应的file_operations,然后直接调用里面的read函数指针:
// 内核伪代码:read系统调用的核心逻辑
ssize_t sys_read(int fd, void *buf, size_t count) {
struct file *file = fdget(fd); // 步骤2:通过fd找到struct file
if (!file || !file->f_op || !file->f_op->read) {
return -EINVAL;
}
// 步骤4:调用对应驱动的read函数
return file->f_op->read(file, buf, count, &file->f_pos);
}这一步就是多态分发 :同样的read系统调用,内核会根据fd对应的struct file,自动调用不同设备的驱动函数,完全不用用户态参与。
步骤 5:驱动函数操作硬件,完成实际的读写
驱动实现的read/write函数,会和硬件设备交互,完成实际的操作:
- 磁盘驱动的
read:向磁盘控制器发送命令,把磁盘扇区的数据读到内核缓冲区; - 键盘驱动的
read:等待键盘中断,把按键的扫描码转换成字符,读到内核; - 显卡驱动的
write:把用户态的字符数据,写入显卡的显存,控制显示器显示; - 网卡驱动的
read:从网卡的接收队列中取出数据包,拷贝到内核。
驱动完成硬件操作后,会把读取到的数据(或错误码)返回给内核。
步骤 6:内核把数据拷贝回用户态,系统调用返回
内核把驱动返回的数据,从内核空间拷贝到用户态的buf中,然后read系统调用返回,用户程序就拿到了数据。
二、为什么这就是「一切皆文件」?
核心就是 「统一接口,屏蔽差异」:
- 用户态视角 :所有资源(文件、终端、键盘、磁盘、网卡、串口),都被抽象成了 "文件",都可以用
open/read/write/close这一套统一的系统调用来操作,用户态代码完全不用关心底层差异。 - 内核态视角 :通过
struct file+file_operations的多态机制,把不同设备的操作,分发到对应的驱动实现中,底层的差异被内核屏蔽了。 - 驱动视角 :不同的设备驱动,只需要实现
file_operations里的函数指针,就能接入 Linux 的文件系统框架,被用户态以文件的方式操作。
三、前面的例子:输出重定向
之前写的 shell 里的输出重定向,就是这个机制的典型应用:
- 正常情况下,
fd=1(标准输出)对应的struct file,是终端设备的file_operations,所以printf调用的write,会把数据写到终端屏幕; - 重定向后,
fd=1被dup2指向了磁盘文件的struct file,对应的file_operations是文件系统的,所以printf调用的write,会把数据写到磁盘文件里; - 而用户态的
printf代码完全没有变化,只是内核通过fd分发到了不同的驱动实现,这就是「一切皆文件」的魔力。
5. 缓冲区
5-1 什么是缓冲区
缓冲区是内存空间的⼀部分。也就是说,在内存空间中预留了⼀定的存储空间,这些存储空间⽤来缓 冲输⼊或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输⼊设备还是输出设 备,分为输⼊缓冲区和输出缓冲区
5-2 为什么要引⼊缓冲区机制
读写⽂件时,如果不会开辟对⽂件操作的缓冲区,直接通过系统调⽤对磁盘进⾏操作(读、写等),那么 每次对⽂件进⾏⼀次读写操作时,都需要使⽤读写系统调⽤来处理此操作,即需要执⾏⼀次系统调 ⽤,执⾏⼀次系统调⽤将涉及到CPU状态的切换,即从⽤⼾空间切换到内核空间,实现进程上下⽂的 切换,这将损耗⼀定的CPU时间,频繁的磁盘访问对程序的执⾏效率造成很⼤的影响。
为了减少使⽤系统调⽤的次数,提⾼效率,我们就可以采⽤缓冲机制。⽐如我们从磁盘⾥取信息,可 以在磁盘⽂件进⾏操作时,可以⼀次从⽂件中读出⼤量的数据到缓冲区中,以后对这部分的访问就不 需要再使⽤系统调⽤了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数, 再加上计算机对缓冲区的操作⼤⼤快于对磁盘的操作,故应⽤缓冲区可⼤⼤提⾼计算机的运⾏速度。
⼜⽐如,我们使⽤打印机打印⽂档,由于打印机的打印速度相对较慢,我们先把⽂档输出到打印机相 应的缓冲区,打印机再⾃⾏逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是⼀ 块内存区,它⽤在输⼊输出设备和CPU之间,⽤来缓存数据。它使得低速的输⼊输出设备和⾼速的 CPU能够协调⼯作,避免低速的输⼊输出设备占⽤CPU,解放出CPU,使其能够⾼效率⼯作。
5-3 缓冲类型
标准I/O提供了3种类型的缓冲区(默认)。
-
全缓冲区:这种缓冲⽅式要求填满整个缓冲区后才进⾏I/O系统调⽤操作。对于磁盘⽂件的操作通 常使⽤全缓冲的⽅式访问。
-
⾏缓冲区:在⾏缓冲情况下,当在输⼊和输出中遇到换⾏符时,标准I/O库函数将会执⾏系统调⽤ 操作 。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使⽤⾏缓冲⽅式。因为标准 I/O库每⾏的缓冲区⻓度是固定的,所以只要填满了缓冲区,即使还没有遇到换⾏符,也会执⾏ I/O系统调⽤操作,默认(现代linux)⾏缓冲区的⼤⼩为4096B。
-
⽆缓冲区:⽆缓冲区是指标准I/O库不对字符进⾏缓存 ,直接调⽤系统调⽤。标准出错流stderr通 常是不带缓冲区的,这使得出错信息能够尽快地显⽰出来。
除了上述列举的默认刷新⽅式,下列特殊情况也会引发缓冲区的刷新:
- 缓冲区满时;
- 执⾏flush语句;
- 进程结束
⽰例如下:
#include <stdio.h> // 标准输入输出库,提供printf、perror等函数
#include <string.h> // 字符串处理库(本代码中未直接使用,通常用于字符串操作)
#include <sys/types.h> // 系统数据类型定义(如文件描述符、权限类型)
#include <sys/stat.h> // 文件状态与权限相关定义(如文件模式位)
#include <fcntl.h> // 文件控制库,提供open系统调用及标志位(O_WRONLY/O_CREAT/O_TRUNC)
#include <unistd.h> // Unix标准库,提供close等系统调用函数
int main() {
// 关闭文件描述符1(标准输出stdout),释放该文件描述符的位置
close(1);
// 打开/创建文件log.txt:
// - O_WRONLY:以只写方式打开文件
// - O_CREAT:如果文件不存在则创建,需配合第三个参数指定权限
// - O_TRUNC:如果文件已存在,则清空文件内容(覆盖模式)
// - 0666:新文件的权限(八进制表示,对应所有者/组/其他用户均可读写)
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
// 检查open是否调用失败(返回-1表示失败)
if (fd < 0) {
perror("open"); // 打印错误信息(包含系统错误描述,如权限不足)
return 0; // 出错时直接退出程序
}
// 输出字符串到标准输出(此时stdout已被重定向到log.txt文件)
// 注:fd的值为1(因为close(1)后,open分配了当前最小的空闲文件描述符1)
printf("hello world: %d\n", fd);
// 关闭文件描述符fd(即文件描述符1,此时指向log.txt),释放内核资源
close(fd);
return 0;
}我们本来想使⽤重定向思维,让本应该打印在显⽰器上的内容写到"log.txt"⽂件中,但我们发现, 程序运⾏结束后,⽂件中并没有被写⼊内容:
[tom@iZ2vc37q0l74k6cf7tfz4tZ lesson-12_basic_IO]$ ls
hello hello.c Makefile myfile myfile.c myfile.o test test.c test.o
[tom@iZ2vc37q0l74k6cf7tfz4tZ lesson-12_basic_IO]$ ./myfile
[tom@iZ2vc37q0l74k6cf7tfz4tZ lesson-12_basic_IO]$ ls
hello hello.c log.txt Makefile myfile myfile.c myfile.o test test.c test.o
[tom@iZ2vc37q0l74k6cf7tfz4tZ lesson-12_basic_IO]$ cat log.txt这是由于我们将1号描述符重定向到磁盘⽂件后,缓冲区的刷新⽅式成为了全缓冲。⽽我们写⼊的内容 并没有填满整个缓冲区,导致并不会将缓冲区的内容刷新到磁盘⽂件中。怎么办呢?可以使⽤fflush强 制刷新下缓冲区。
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 0;
}
printf("hello world: %d\n", fd);
fflush(stdout);
close(fd);
return 0;
}还有⼀种解决⽅法,刚好可以验证⼀下stderr是不带缓冲区的,代码如下
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
close(2);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 0;
}
perror("hello world");
close(fd);
return 0;
}这种⽅式便可以将2号⽂件描述符重定向⾄⽂件,由于stderr没有缓冲区,"helloworld"不⽤fflash 就可以写⼊⽂件:
[tom@iZ2vc37q0l74k6cf7tfz4tZ lesson-12_basic_IO]$ gcc test.c -o test
[tom@iZ2vc37q0l74k6cf7tfz4tZ lesson-12_basic_IO]$ ./test
[tom@iZ2vc37q0l74k6cf7tfz4tZ lesson-12_basic_IO]$ cat log.txt
hello world: 15-4 FILE
- 因为IO相关函数与系统调⽤接⼝对应,并且库函数封装系统调⽤,所以本质上,访问⽂件都是通 过fd访问的。
- 所以C库当中的FILE结构体内部,必定封装了fd。
请研究下面的代码:
#include <stdio.h>
#include <string.h>
int main()
{
const char *msg0="hello printf\n";
const char *msg1="hello fwrite\n";
const char *msg2="hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
}运⾏出结果:
hello printf
hello fwrite
hello write但如果对进程实现输出重定向呢? ./hello > file ,我们发现结果变成了:
hello write
hello printf
hello fwrite
hello printf
hello fwrite诶,为什么 printf 和 fwrite(库函数)都输出了2次,而 write 只输出了一次(系统调用)
为什么呢?肯定和fork有关!
- ⼀般C库函数写⼊⽂件时是全缓冲的,⽽写⼊显⽰器是⾏缓冲
printffwrite库函数+会⾃带缓冲区(进度条例⼦就可以说明),当发⽣重定向到普通⽂ 件时,数据的缓冲⽅式由⾏缓冲变成了全缓冲。- ⽽我们放在缓冲区中的数据,就不会被⽴即刷新,甚⾄fork之后
- 但是进程退出之后,会统⼀刷新,写⼊⽂件当中。
- 但是fork的时候,⽗⼦数据会发⽣写时拷⻉,所以当你⽗进程准备刷新的时候,⼦进程也就有了 同样的⼀份数据,随即产⽣两份数据。
- write 没有变化,说明没有所谓的缓冲。
综上: printf fwrite 库函数会⾃带缓冲区,⽽ write 系统调⽤没有带缓冲区。另外,我们这 ⾥所说的缓冲区,都是**⽤⼾级缓冲区** 。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过 不再我们讨论范围之内。
那这个缓冲区谁提供呢?printf fwrite 是库函数, 的"上层",是对系统调⽤的"封装" ,但是 write 是系统调⽤,库函数在系统调⽤ write 没有缓冲区,⽽ printf fwrite 有,⾜以 说明,该缓冲区是⼆次加上的,⼜因为是C ,所以由C标准库提供。
如果有兴趣,可以看看FILE结构体:
typedef struct _IO_FILE FILE; 在/usr/include/stdio.h
// 在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
// 缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The the following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; // 封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};5-5 简单设计⼀下libc库
my_stdio.h
#pragma once
// 定义缓冲区大小为1024字节
#define SIZE 1024
// 刷新模式枚举:对应无缓冲、行缓冲、全缓冲
#define FLUSH_NONE 0 // 无缓冲:数据直接写入文件,不经过缓冲区
#define FLUSH_LINE 1 // 行缓冲:遇到换行符或缓冲区满时刷新
#define FLUSH_FULL 2 // 全缓冲:仅当缓冲区满或手动刷新时才写入文件
// 自定义文件流结构体,模拟C标准库的FILE
struct IO_FILE
{
int flag; // 刷新模式:存储当前流的缓冲类型(无/行/全缓冲)
int fileno; // 文件描述符:内核侧标识打开文件的句柄
char outbuffer[SIZE];// 输出缓冲区:暂存待写入文件的数据
int cap; // 缓冲区容量:表示outbuffer的最大可存储字节数(这里固定为SIZE)
int size; // 缓冲区当前大小:记录outbuffer中已存储的数据长度
// TODO: 可扩展输入缓冲区、读写指针位置、错误标志等字段
};
// 类型别名:将struct IO_FILE重命名为mFILE,方便后续使用
typedef struct IO_FILE mFILE;
// 模拟fopen:打开文件,初始化自定义文件流对象
// 参数:filename-文件名,mode-打开模式(如"r"/"w"/"a")
// 返回值:成功返回自定义文件流指针,失败返回NULL
mFILE *mfopen(const char *filename, const char *mode);
// 模拟fwrite:将数据写入自定义文件流的缓冲区
// 参数:ptr-待写入数据的地址,num-数据字节数,stream-目标文件流
// 返回值:成功写入的字节数
int mfwrite(const void *ptr, int num, mFILE *stream);
// 模拟fflush:强制刷新文件流缓冲区,将数据写入文件
// 参数:stream-目标文件流
void mfflush(mFILE *stream);
// 模拟fclose:关闭文件流,刷新缓冲区并释放资源
// 参数:stream-目标文件流
void mfclose(mFILE *stream);my_stdio.c
#include "my_stdio.h"
#include <string.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <unistd.h>
// 模拟C标准库的fopen,实现文件打开与自定义文件流初始化
mFILE *mfopen(const char *filename, const char *mode)
{
int fd = -1;
// 处理"r"模式:只读打开文件
if(strcmp(mode, "r") == 0)
{
fd = open(filename, O_RDONLY);
}
// 处理"w"模式:只写打开,文件不存在则创建,存在则清空(覆盖模式)
else if(strcmp(mode, "w") == 0)
{
fd = open(filename, O_CREAT|O_WRONLY|O_TRUNC, 0666);
}
// 处理"a"模式:追加写打开,文件不存在则创建,存在则从末尾写入
else if(strcmp(mode, "a") == 0)
{
fd = open(filename, O_CREAT|O_WRONLY|O_APPEND, 0666);
}
// 若open失败(返回-1),直接返回NULL
if(fd < 0) return NULL;
// 为自定义文件流对象分配内存
mFILE *mf = (mFILE*)malloc(sizeof(mFILE));
if(!mf)
{
// 内存分配失败,需先关闭已打开的文件描述符,避免资源泄漏
close(fd);
return NULL;
}
// 初始化自定义文件流对象
mf->fileno = fd; // 绑定文件描述符
mf->flag = FLUSH_LINE; // 默认设置为行缓冲模式
mf->size = 0; // 缓冲区当前数据长度初始化为0
mf->cap = SIZE; // 缓冲区容量设置为定义的SIZE(1024)
return mf;
}
// 模拟C标准库的fflush,强制刷新自定义文件流的缓冲区
void mfflush(mFILE *stream)
{
// 若缓冲区中有数据,则执行刷新操作
if(stream->size > 0)
{
// 1. 将缓冲区数据写入内核文件缓冲区
write(stream->fileno, stream->outbuffer, stream->size);
// 2. 调用fsync强制将内核数据刷新到磁盘设备(确保数据落盘)
fsync(stream->fileno);
// 3. 清空缓冲区数据长度标记,表示数据已全部写入
stream->size = 0;
}
}
// 模拟C标准库的fwrite,实现数据写入自定义文件流(带缓冲逻辑)
int mfwrite(const void *ptr, int num, mFILE *stream)
{
// 1. 将数据拷贝到自定义文件流的输出缓冲区中
memcpy(stream->outbuffer + stream->size, ptr, num);
// 更新缓冲区当前数据长度
stream->size += num;
// 2. 行缓冲模式下,若写入的数据包含换行符,则立即刷新缓冲区
if(stream->flag == FLUSH_LINE && stream->size > 0 &&
stream->outbuffer[stream->size-1] == '\n')
{
mfflush(stream);
}
// 返回成功写入的数据字节数(简化实现,直接返回传入的num)
return num;
}
// 模拟C标准库的fclose,关闭自定义文件流并释放资源
void mfclose(mFILE *stream)
{
// 关闭前先刷新缓冲区,确保未写入的数据全部落盘
if(stream->size > 0)
{
mfflush(stream);
}
// 关闭文件描述符,释放内核文件资源
close(stream->fileno);
// (注:简化实现中未包含free(stream),实际使用时需补充以避免内存泄漏)
}main.c
#include "my_stdio.h" // 包含自定义文件流实现(mFILE、mfopen/mfwrite等)
#include <stdio.h> // 标准C库输入输出头文件(printf等)
#include <string.h> // 字符串处理头文件(strlen等)
#include <unistd.h> // Unix系统调用头文件(sleep等)
int main()
{
// 1. 以追加模式打开文件,使用自定义的mfopen初始化mFILE流
// 路径:./log.txt,模式:"a"(追加写,文件不存在则创建,存在则从末尾写入)
mFILE *fp = mfopen("./log.txt", "a");
if(fp == NULL)
{
// 打开失败,直接退出程序
return 1;
}
int cnt = 10; // 循环次数:写入10条消息
while(cnt)
{
// 标准输出打印当前循环次数,用于控制台显示进度
printf("write %d\n", cnt);
char buffer[64]; // 临时缓冲区,存储要写入文件的格式化字符串
// 将"hello message, number is : %d"格式化为字符串,存入buffer
snprintf(buffer, sizeof(buffer), "hello message, number is : %d", cnt);
cnt--; // 循环计数减1
// 2. 调用自定义的mfwrite,将buffer中的数据写入自定义文件流
// 数据会先写入用户态缓冲区outbuffer,根据缓冲模式决定是否立即写入内核
mfwrite(buffer, strlen(buffer), fp);
// 3. 手动调用自定义的mfflush,强制刷新缓冲区,将数据写入文件
// 确保数据立即落盘,不留在用户态缓冲区
mfflush(fp);
sleep(1); // 暂停1秒,模拟任务执行间隔,方便观察写入过程
}
// 4. 关闭自定义文件流,刷新剩余数据并释放资源
mfclose(fp);
}num, mFILE *stream)
{
// 1. 将数据拷贝到自定义文件流的输出缓冲区中
memcpy(stream->outbuffer + stream->size, ptr, num);
// 更新缓冲区当前数据长度
stream->size += num;
// 2. 行缓冲模式下,若写入的数据包含换行符,则立即刷新缓冲区
if(stream->flag == FLUSH_LINE && stream->size > 0 &&
stream->outbuffer[stream->size-1] == '\n')
{
mfflush(stream);
}
// 返回成功写入的数据字节数(简化实现,直接返回传入的num)
return num;}
// 模拟C标准库的fclose,关闭自定义文件流并释放资源
void mfclose(mFILE *stream)
{
// 关闭前先刷新缓冲区,确保未写入的数据全部落盘
if(stream->size > 0)
{
mfflush(stream);
}
// 关闭文件描述符,释放内核文件资源
close(stream->fileno);
// (注:简化实现中未包含free(stream),实际使用时需补充以避免内存泄漏)
}
main.c#include "my_stdio.h" // 包含自定义文件流实现(mFILE、mfopen/mfwrite等)
#include <stdio.h> // 标准C库输入输出头文件(printf等)
#include <string.h> // 字符串处理头文件(strlen等)
#include <unistd.h> // Unix系统调用头文件(sleep等)
int main()
{
// 1. 以追加模式打开文件,使用自定义的mfopen初始化mFILE流
// 路径:./log.txt,模式:"a"(追加写,文件不存在则创建,存在则从末尾写入)
mFILE *fp = mfopen("./log.txt", "a");
if(fp == NULL)
{
// 打开失败,直接退出程序
return 1;
}
int cnt = 10; // 循环次数:写入10条消息
while(cnt)
{
// 标准输出打印当前循环次数,用于控制台显示进度
printf("write %d\n", cnt);
char buffer[64]; // 临时缓冲区,存储要写入文件的格式化字符串
// 将"hello message, number is : %d"格式化为字符串,存入buffer
snprintf(buffer, sizeof(buffer), "hello message, number is : %d", cnt);
cnt--; // 循环计数减1
// 2. 调用自定义的mfwrite,将buffer中的数据写入自定义文件流
// 数据会先写入用户态缓冲区outbuffer,根据缓冲模式决定是否立即写入内核
mfwrite(buffer, strlen(buffer), fp);
// 3. 手动调用自定义的mfflush,强制刷新缓冲区,将数据写入文件
// 确保数据立即落盘,不留在用户态缓冲区
mfflush(fp);
sleep(1); // 暂停1秒,模拟任务执行间隔,方便观察写入过程
}
// 4. 关闭自定义文件流,刷新剩余数据并释放资源
mfclose(fp);}